| 摘 要:简要介绍了一种通用的,动态树型结构的实现方案,该方案基于Asynchronous
JavaScript and XML,结合Struts框架设计实现了结构清晰、扩展性良好的多层架构,数据存储于数据库,结合XML描述树的节点信息,使得任何按预定的XML文档描述的信息都可以通过动态树来展现。
关键词:MVC模式;Ajax;树型结构;字典序
树型结构是一类应用非常广泛的数据结构。人类社会中宗族的族谱和现代企业的组织形式都是树型结构。在计算机领域中,文件系统中文件的管理结构、存储器管理中的页表、数据库中的索引等也都是树型结构。随着Internet的飞速发展,树型结构在浏览器/服务器(Browser/Server,简称B/S)应用系统的应用也越来越广泛。
目前,在互联网上广泛存在、应用的树型结构一般分为两种:静态和动态结构。静态结构存在最多、实现简单,但是静态导致不能改变树的结构和内容,无法反映树的节点信息的变化;而实现相对复杂的动态构造树,虽然可以动态增加、删除、更新节点信息,但是大部分不能直接拖放节点来改变树的结构以及节点间的次序,并且反复刷新整个页面,给用户维护带来了许多不便。本文提出了一种基于Ajax(Asynchronous
JavaScript and XML)通用的、动态加载节点的解决方案。实现上采用J2EE多层架构,树节点的描述信息采用数据库存储,以可扩展标记语言(eXtensible
Markup Language,简称XML)展现给JavaScript解析,支持无刷新地增加、删除、更新节点信息,以及拖放节点来改变树的结构和节点间的次序。文中第1部分简要介绍了Ajax技术;第2部分详细介绍了该方案的技术实现过程;第3部分分析了该方案的效率。
1、Ajax简介
Ajax概念的最早提出者Jesse James Garrett认为:Ajax并不是一门新的语言或技术,它实际上是几项技术按一定的方式组合在共同的协作中发挥各自的作用,它包括:
・使用扩展超媒体标记语言(eXtended Hypertext Markup Language,简称XHTML)和级联样式单(Cascading
Style Sheet,简称CSS)标准化呈现;
・使用文档对象模型(Document Object Model,简称DOM)实现动态显示和交互;
・使用可扩展标记语言(eXtensible Markup Language,简称XML)和可扩展样式表转换(eXtensible
Stylesheet Language Transformation,简称XSLT)进行数据交换与处理;
・使用XMLHTTP组件XMLHttpRequest对象进行异步数据读取;
・最后用JavaScript绑定和处理所有数据。
Ajax的工作原理如图1所示,它相当于在用户和服务器之间加了一个中间层,使用户操作与服务器响应异步化。并不是所有的用户请求都提交给服务器,像―些数据验证和数据处理等都交给Ajax引擎处理,只有确定需要从服务器读取新数据时再由Ajax引擎代为向服务器提交请求。这样就把一些服务器负担的工作转嫁到客户端,利用客户端闲置的处理能力来处理,减轻服务器和带宽的负担,从而达到节约ISP的空间及带宽租用成本的目的。
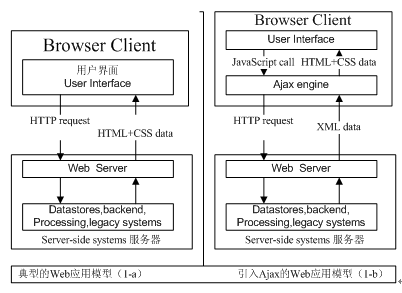
图 1 未使用Ajax(a)和使用Ajax(b)的web应用比较
2、总体设计方案
传统的服务器程序采用Model 1开发模型,通常将业务逻辑、服务器端处理过程和HTML代码集中在一起表示,快速完成应用开发。Model
1 在小规模应用开发时优势明显,但是应用实现一般是基于过程的,一组服务器页面实现一个流程,如果流程改动将导致多个地方修改,非常不利于应用的扩展和更新。此外业务逻辑和表示逻辑混合在服务器页面中,耦合紧密,无法模块化,导致代码无法复用。
Model 2则解决了这些问题,它是面向对象的MVC模式(Model-View-Controller,模型-视图-控制器)在Web开发中的应用,Model表示应用的业务逻辑,View是应用的表示层页面,Controller是提供应用的处理过程控制。通过这种MVC设计模式把应用逻辑,处理过程和显示逻辑划分成不同的组件、模块实现,组件间可以进行交互和重用。
本方案是采用J2EE的多层架构,设计时结合Struts框架将表示层、业务逻辑层和数据层划分成不同的模块。表示层专注于树的外观显示,业务逻辑层为服务器端处理程序,处理树的生成、变化,为减少耦合性,该程序全部模块化实现,不在表示页面嵌入服务器程序;模型层是数据的存储和表示。下面分别介绍各层实现。
2.1 表示层实现
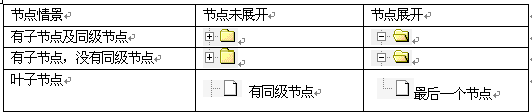
类似Windows资源管理器的文件夹模式,节点的图片样式如表1所示。对于每个节点的DHTML 代码,需要包含节点的位置、前导图片、样式、针对该节点的其他操作等。同时为了节点显示的连贯性,还需一些前导图片。
表1 树节点的前的图片样式表
对于树的非叶子节点,图片和节点信息等,采用一个DIV ( division) 容器包含。DIV 等容器是DHTML
的基础,使用它可以通过脚本程序对其属性进行操作,如设置其style 样式的display 属性来控制子节点的展开和隐藏。节点的位置、前导图片、样式、针对该节点的其他的操作等都放入容器中,例:
< DIV
id =mParentID>
< IMG align = center border = 0 onclick =″nodeExpand
(‘leafid’)″ name = m1Tree src =′Tplus.gif′>
< IMG align = center border = 0 name = m1Folder src
=′folderClosed. gif′> 计算机学院 </DIV> |
叶子节点无需容器直接输出即可。
当点击某节点前的“ + ”、“ - ”图片时通过DIV 的style 样式的display 属性控制子节点的展开和隐藏。display:“none”(隐藏,不可见),display:“block”(显示)
。相关JavaScript 代码如下:
if (expandChild.style.display
= =″none″){
// 当前为隐藏状态,执行展开动作
this.Loading(parentObject);//判断该分支的数据是否已经加载
expandChild.style.display =″block″;
if (para2 = =″last″)
parentObject.src =″Lminus. gif″; // 最后一个节点
else
parentObject.src = ″Tminus. gif″; // 显示┠
expandFolder.src = ″folderOpen. gif″;
}else {
// 将当前节点的子节点全部隐藏
expandChild.style.display = ″none″;
if (para2 = = ″last″)
parentObject.src = ″Lplus. gif″;
else
parentObject.src = ″Tplus. gif″;
expandFolder.src = ″folderClosed. gif″;
} |
2.2 树型表结构设计
我们以数据库为载体记录节点的变化,树型表结构至少要有以下字段:节点的编号(CLASSID) ,对节点的描述(ClassName),父节点的编号(ParentId),这些是构建树结构所必须的信息。同时引入节点的类别代码(ClassCode),节点的级别(ClassLevel),是否叶子节点
(Terminated)等辅助字段,记录节点次序,实体关系图如图3所示。
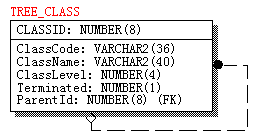
图 3 树型表结构示意图
树遍历的时间复杂度是O( n ),但是将树信息存放到数据库后,就不能按传统的方式遍历树,必须使用SQL 语句访问数据库表的内容,而一次性取的数据量越多,消耗的资源也越多,用户等待的时间就越长。如果将无序的数据从数据库中读出,在服务器端,必须将排序后的树送到客户端显示。因此,最好从数据库读出已排好序的树。
我们知道,字符串排序是按照字典序形式。结合SQL 语句的特点和树结构特点,数据库表中,节点的类别代码采用多级字符串形式,如AAABBBCCC,从树根节点开始,每向下一级字符串就增加一级,并且子节点类别代码以父节点类别代码开始,再开始本级的类别代码。同级的节点按照生成的顺序编号,如节点类别代码为AAA
的下一级孩子类别代码为AAAAAA,AAAAAB 等,AAAAAB 的孩子节点为AAAAABAAA、AAAAABAAB等。每一级编号字符的宽度与实际的应用关联,如AAA~ZZZ
一级则有263 个节点,如果不够用再增加一个字符用于编码。该巧妙的编号方式。使得在执行SQL 语句select
* from tree_class order by classcode 后,一次获得完整的先序树。
2.3 业务逻辑层设计
2.3.1 动态加载技术
如果一次性获取完整的先序树,构造成xml提供给JavaScript解析,数据量越大,消耗的资源越多,客户端响应延迟时间就越长,因此对于大数据量的树,采用动态加载方式,即每次单击“+”图片时,判断是否已加载子节点数据,如果未加载则通过Ajax的XMLHTTP组件XMLHTTPRequest对象异步发送请求,连接服务器执行SQL
语句“select * from tree_class where parent = ?order by classcode
”获取节点数据。相关JavaScript 代码如下:
/*判断是否已经加载数据,未加载则访问服务器加载数据*/
dhtmlTree.prototype.Loading=function(pObject){
if(((pObject.XMLload==0)&&(this.XMLsource))&&(!this.XMLloading)){
pObject.XMLload=1;
this.loadXML(this.XMLsource+getUrlSymbol(this.XMLsource)+"id="+escape(pObject.id));
}
}
dtmlXMLObject.prototype.loadXML=function(url){//加载数据
try {
this.xmlDoc = new XMLHttpRequest();
/*通过GET方法异步连接到 url 加载数据*/
this.xmlDoc.open("GET", url,true);//true:异步;false:同步
this.xmlDoc.send(null);
} catch(e){
this.xmlDoc = new ActiveXObject("Microsoft.XMLHTTP");//使用IE
this.xmlDoc.open("GET", url,true);//true:异步;false:同步
this.xmlDoc.send(null);
}
return this.xmlDoc.responseXML;
} |
每次只取同一个父节点ParentId的子节点序列,按XML格式封装成树的文档结构,例如:
<tree id="0">
<leaf child=”1" name="国防科技大学" id="1"
im0="leaf.gif" im1="folderOpen.gif"
im2=" folderClosed.gif"/>
</tree> |
提供给JavaScript的dhtmlTreeObject.prototype.insertItem()解析并组织好html输出节点;其中child:1表示有子节点,0表示没有子节点;im0表示没有子节点时的图标;im1表示有子节点并且打开节点时的图标;im2表示有子节点并且关闭时的图标;所以还可以在构造XML时自定义图标。
2.3.2 树型结构的构造
从数据库中返回的是有序的先序树,而XML是完整的树型结构文档,所以将树型数据构造成预定义的XML格式,只需从根节点开始,遍历一遍树,即可将树全部生成。相关JavaScript代码如下:
/*动态加载树的构造方法*/
dtmlXMLObject.prototype.constructTree=function(){
//采用动态加载时获取的xml数据,解析树型数据
var node=this.XMLLoader.getXMLTopNode("tree");
var parentId=node.getAttribute("id");
for(var i=0;i<node.childNodes.length;i++) { //逐个解析xml文件的leaf节点
if((node.childNodes[i].nodeType==1)&&(node.childNodes[i].tagName
== "leaf")){
var name=node.childNodes[i].getAttribute("text");
…………
var temp=dhtmlObject.a0Find(parentId);//获取父节点对象
temp.XMLload=1;//已加载
//构造html输出节点
dhtmlObject.insertItem(parentId,cId,name,im0,im1,im2,chd);
dhtmlObject.addDragger = this;//设置可拖放的对象
};
}
|
2.3.3 树型结构的维护
在维护树型结构表时,删除节点较为简单,SQL 语句为: "delete from tree_class
where classcode like′"+ classcode +"%′",即可将其节点和孩子一并删除;增加节点时,分为前插、后插、和插入子节点三种情况,前两种情况需要更新递归更新类别代码,后者只需找到父节点的孩子的最大类别代码加1
后,作为增加节点的类别代码;通过拖放来改变树的结构时,只需将拖动节点的parentId更新为目标节点的Classid即可,对应的SQL语句为:"update
tree_class set parentId = "+ classidTo+" where
classid = "+ classidFrom。
3、效率分析
对于树的存储一般有两种形式:二维表和链表,遍历方式一般也有深度遍历和广度遍历两种方式,遍历的时间复杂度都是O(
n )。用二维表存储时,在内存中用数组的下标能准确定位节点的父节点、兄弟节点所在的数组下标。数据库中节点的定位也是准确的,但是将节点信息从数据库中读到内存中时,如果无法通过内存数组下标定位节点信息,那么就必须遍历一遍寻找一个节点,n
个节点中寻找一个节点的时间是O(n/2),n 个节点排序的时间复杂度将是O( n 2/2),这也是一般实现的B/S
模式的树结构效率低下的原因。本方案采用字典序编号方案,使得从数据库中取得的树是已经排序的,直接遍历生成客户页面程序,时间复杂度为O(
n )。
4、结 论
本文讨论了基于Ajax的动态树型结构的实现方案,支持无刷新动态维护树的节点信息,支持拖放节点改变树的节点结构以及次序;同时采用数据库存储节点信息,保证了该方案有一定的通用性,此外结合XML描述树的节点信息,使得任何按本方案预定的xml文档描述的信息都可以通过树来展现。本方案已经应用在我校的数字迎新系统以及老百姓大药房信息系统中。
|