| БрМЭЦМі: |
БОЮФжївЊНщЩмДгСљИіЮЪЬтГіЗЂЃЌЖд
React Fiber НјааРэНтгыШЯЪЖЃЌЭЌЪБЖдЪБЯТШШУХЕФЧАЖЫПђМмSvelteНјааМђвЊНщЩмгыЦЪЮіЁЃ
БОЮФРДздгкЧАЖЫгЁЯѓ ,гЩЛ№СњЙћШэМўAliceБрМЭЦМіЁЃ |
|
React ЕФЩшМЦРэФюЪЧЪВУДЃП
ReactЙйЭјдкReactембЇ[4]вЛНкПЊЦЊЬсЕНЃК
ЮвУЧШЯЮЊЃЌReact ЪЧгУ JavaScript ЙЙНЈПьЫйЯьгІЕФДѓаЭ Web гІгУГЬађЕФЪзбЁЗНЪНЁЃЫќдк
Facebook КЭ Instagram ЩЯБэЯжгХауЁЃReact зюАєЕФВПЗжжЎвЛЪЧв§ЕМЮвУЧЫМПМШчКЮЙЙНЈвЛИігІгУЁЃ
гЩДЫПЩМћЃЌReact зЗЧѓЕФЪЧ ЁАПьЫйЯьгІЁБЃЌФЧУДЃЌЁАПьЫйЯьгІЁАЕФжЦдМвђЫиЖМгаЪВУДФиЃП
ЁЄCPUЕФЦПОБЃКЕБЯюФПБфЕУХгДѓЁЂзщМўЪ§СПЗБЖрЁЂгіЕНДѓМЦЫуСПЕФВйзїЛђепЩшБИадФмВЛзуЪЙЕУвГУцЕєжЁЃЌЕМжТПЈЖйЁЃ
ЁЄ IOЕФЦПОБЃКЗЂЫЭЭјТчЧыЧѓКѓЃЌгЩгкашвЊЕШД§Ъ§ОнЗЕЛиВХФмНјвЛВНВйзїЕМжТВЛФмПьЫйЯьгІЁЃ
БОЮФвЊСФЕФfiber МмЙЙжївЊОЭЪЧгУРДНтОі CPU КЭЭјТчЕФЮЪЬтЃЌетСНИіЮЪЬтвЛжБвВЪЧзюгАЯьЧАЖЫПЊЗЂЬхбщЕФЕиЗНЃЌвЛИіЛсдьГЩПЈЖйЃЌвЛИіЛсдьГЩАзЦСЁЃЮЊДЫ
react ЮЊЧАЖЫв§ШыСЫСНИіаТИХФюЃКTime Slicing ЪБМфЗжЦЌКЭSuspenseЁЃ
ReactЕФЁАЯШЬьВЛзуЁБ ЁЊЁЊ Ь§ЫЕ Vue 3.0 ВЩгУСЫЖЏОВНсКЯЕФ Dom diffЃЌReact
ЮЊКЮВЛИњНјЃП
Vue 3.0 ЖЏОВНсКЯЕФ Dom diff
Vue3.0 ЬсГіЖЏОВНсКЯЕФ DOM diff ЫМЯыЃЌЖЏОВНсКЯЕФ DOM diffЦфЪЕЪЧдкдЄБрвыНзЖЮНјааСЫгХЛЏЁЃжЎЫљвдФмЙЛзіЕНдЄБрвыгХЛЏЃЌЪЧвђЮЊ
Vue core ПЩвдОВЬЌЗжЮі templateЃЌдкНтЮіФЃАцЪБЃЌећИі parse ЕФЙ§ГЬЪЧРћгУе§дђБэДяЪНЫГађНтЮіФЃАхЃЌЕБНтЮіЕНПЊЪМБъЧЉЁЂБеКЯБъЧЉКЭЮФБОЕФЪБКђЖМЛсЗжБ№жДааЖдгІЕФЛиЕїКЏЪ§ЃЌРДДяЕНЙЙдь
AST ЪїЕФФПЕФЁЃ
НшжњдЄБрвыЙ§ГЬЃЌVue ПЩвдзіЕНЕФдЄБрвыгХЛЏОЭКмЧПДѓСЫЁЃБШШчдкдЄБрвыЪББъМЧГіФЃАцжаПЩФмБфЛЏЕФзщМўНкЕуЃЌдйДЮНјаафжШОЧА
diff ЪБОЭПЩвдЬјЙ§ЁАгРдЖВЛЛсБфЛЏЕФНкЕуЁБЃЌЖјжЛашвЊЖдБШЁАПЩФмЛсБфЛЏЕФЖЏЬЌНкЕуЁБЁЃетвВОЭЪЧЖЏОВНсКЯЕФ
DOM diff НЋ diff ГЩБОгыФЃАцДѓаЁе§ЯрЙигХЛЏЕНгыЖЏЬЌНкЕуе§ЯрЙиЕФРэТлвРОнЁЃ
React ФмЗёЯё Vue ФЧбљНјаадЄБрвыгХЛЏЃП
Vue ашвЊзіЪ§ОнЫЋЯђАѓЖЈЃЌашвЊНјааЪ§ОнРЙНиЛђДњРэЃЌФЧЫќОЭашвЊдкдЄБрвыНзЖЮОВЬЌЗжЮіФЃАцЃЌЗжЮіГіЪгЭМвРРЕСЫФФаЉЪ§ОнЃЌНјааЯьгІЪНДІРэЁЃЖј
React ОЭЪЧОжВПжиаТфжШОЃЌReact ФУЕНЕФЛђепЫЕеЦЙмЕФЃЌЫљИКд№ЕФОЭЪЧвЛЖбЕнЙщ React.createElement
ЕФжДааЕїгУЃЈВЮПМЯТЗНОЙ§BabelзЊЛЛЕФДњТыЃЉЃЌЫќЮоЗЈДгФЃАцВуУцНјааОВЬЌЗжЮіЁЃJSX КЭЪжаДЕФ render
function[5] ЪЧЭъШЋЖЏЬЌЕФЃЌЙ§ЖШЕФСщЛюадЕМжТдЫааЪБПЩвдгУгкгХЛЏЕФаХЯЂВЛзуЁЃ
JSX аДЗЈЃК
<div>
<h1>СљИіЮЪЬтжњФуРэНт React Fiber</h1>
<ul>
<li>React</li>
<li>Vue</li>
</ul>
</div> |
ЕнЙщ React.createElementЃК
// BabelзЊЛЛКѓ
React.createElement(
"div",
null,
React.createElement(
"h1",
null,
"\u516D\u4E2A\u95EE\u9898\u52A9\u4F60\u7406\u89E3
React Fiber"
),
React.createElement(
"ul",
null,
React.createElement("li", null, "React"),
React.createElement("li", null, "Vue")
)
); |
JSX vs Template

jsx and Templates
JSX Опга JavaScript ЕФЭъећБэЯжСІЃЌПЩвдЙЙНЈЗЧГЃИДдгЕФзщМўЁЃЕЋЪЧСщЛюЕФгяЗЈЃЌвВвтЮЖзХв§ЧцФбвдРэНтЃЌЮоЗЈдЄХаПЊЗЂепЕФгУЛЇвтЭМЃЌДгЖјФбвдгХЛЏадФмЁЃ
Template ФЃАхЪЧвЛжжЗЧГЃгадМЪјЕФгябдЃЌФужЛФмвдФГжжЗНЪНШЅБраДФЃАхЁЃ
МШШЛДцдквдЩЯБрвыЪБЯШЬьВЛзуЃЌдкдЫааЪБгХЛЏЗНУцЃЌReactвЛжБдкХЌСІЁЃБШШчЃЌReact15ЪЕЯжСЫbatchedUpdatesЃЈХњСПИќаТЃЉЁЃМДЭЌвЛЪТМўЛиЕїКЏЪ§ЩЯЯТЮФжаЕФЖрДЮsetStateжЛЛсДЅЗЂвЛДЮИќаТЁЃ
ЕЋЪЧЃЌШчЙћЕЅДЮИќаТОЭКмКФЪБЃЌвГУцЛЙЪЧЛсПЈЖйЃЈетдквЛИіЮЌЛЄЪБМфКмГЄЕФДѓгІгУжаЪЧКмГЃМћЕФЃЉЁЃетЪЧвђЮЊReact15ЕФИќаТСїГЬЪЧЭЌВНжДааЕФЃЌвЛЕЉПЊЪМИќаТжБЕНвГУцфжШОЧАЖМВЛФмжаЖЯЁЃ
ДгМмЙЙбнБфПДВЛЖЯНјЛїЕФ React ЖМзіЙ§ФФаЉгХЛЏЃП
ReactфжШОвГУцЕФСНИіНзЖЮ
ЕїЖШНзЖЮЃЈreconciliationЃЉЃКдкетИіНзЖЮ React ЛсИќаТЪ§ОнЩњГЩаТЕФ Virtual
DOMЃЌШЛКѓЭЈЙ§DiffЫуЗЈЃЌПьЫйевГіашвЊИќаТЕФдЊЫиЃЌЗХЕНИќаТЖгСажаШЅЃЌЕУЕНаТЕФИќаТЖгСаЁЃ
фжШОНзЖЮЃЈcommitЃЉЃКетИіНзЖЮ React ЛсБщРњИќаТЖгСаЃЌНЋЦфЫљгаЕФБфИќвЛДЮадИќаТЕНDOMЩЯЁЃ
React 15 МмЙЙ
React15МмЙЙПЩвдЗжЮЊСНВуЃК
ReconcilerЃЈаЕїЦїЃЉЁЊЁЊ ИКд№евГіБфЛЏЕФзщМўЃЛ
RendererЃЈфжШОЦїЃЉЁЊЁЊ ИКд№НЋБфЛЏЕФзщМўфжШОЕНвГУцЩЯЃЛ
дкReact15МАвдЧАЃЌReconcilerВЩгУЕнЙщЕФЗНЪНДДНЈащФтDOMЃЌЕнЙщЙ§ГЬЪЧВЛФмжаЖЯЕФЁЃШчЙћзщМўЪїЕФВуМЖКмЩюЃЌЕнЙщЛсеМгУЯпГЬКмЖрЪБМфЃЌЕнЙщИќаТЪБМфГЌЙ§СЫ16msЃЌгУЛЇНЛЛЅОЭЛсПЈЖйЁЃ
ЮЊСЫНтОіетИіЮЪЬтЃЌReact16НЋЕнЙщЕФЮоЗЈжаЖЯЕФИќаТжиЙЙЮЊвьВНЕФПЩжаЖЯИќаТЃЌгЩгкдјОгУгкЕнЙщЕФащФтDOMЪ§ОнНсЙЙвбОЮоЗЈТњзуашвЊЁЃгкЪЧЃЌШЋаТЕФFiberМмЙЙгІдЫЖјЩњЁЃ
React 16 МмЙЙ
ЮЊСЫНтОіЭЌВНИќаТГЄЪБМфеМгУЯпГЬЕМжТвГУцПЈЖйЕФЮЪЬтЃЌвВЮЊСЫЬНЫїдЫааЪБгХЛЏЕФИќЖрПЩФмЃЌReactПЊЪМжиЙЙВЂвЛжБГжајжСНёЁЃжиЙЙЕФФПБъЪЧЪЕЯжConcurrent
ModeЃЈВЂЗЂФЃЪНЃЉЁЃ
Дгv15ЕНv16ЃЌReactЭХЖгЛЈСЫСНФъЪБМфНЋдДТыМмЙЙжаЕФStack ReconcilerжиЙЙЮЊFiber
ReconcilerЁЃ
React16МмЙЙПЩвдЗжЮЊШ§ВуЃК
SchedulerЃЈЕїЖШЦїЃЉЁЊЁЊ ЕїЖШШЮЮёЕФгХЯШМЖЃЌИпгХШЮЮёгХЯШНјШыReconcilerЃЛ
ReconcilerЃЈаЕїЦїЃЉЁЊЁЊ ИКд№евГіБфЛЏЕФзщМўЃКИќаТЙЄзїДгЕнЙщБфГЩСЫПЩвджаЖЯЕФбЛЗЙ§ГЬЁЃReconcilerФкВПВЩгУСЫFiberЕФМмЙЙЃЛ
RendererЃЈфжШОЦїЃЉЁЊЁЊ ИКд№НЋБфЛЏЕФзщМўфжШОЕНвГУцЩЯЁЃ
React 17 гХЛЏ
React16ЕФexpirationTimesФЃаЭжЛФмЧјЗжЪЧЗё >=expirationTimes
ОіЖЈНкЕуЪЧЗёИќаТЁЃReact17ЕФlanesФЃаЭПЩвдбЁЖЈвЛИіИќаТЧјМфЃЌВЂЧвЖЏЬЌЕФЯђЧјМфжадіМѕгХЯШМЖЃЌПЩвдДІРэИќЯИСЃЖШЕФИќаТЁЃ
LaneгУЖўНјжЦЮЛБэЪОШЮЮёЕФгХЯШМЖЃЌЗНБугХЯШМЖЕФМЦЫуЃЈЮЛдЫЫуЃЉЃЌВЛЭЌгХЯШМЖеМгУВЛЭЌЮЛжУЕФЁАШќЕРЁБЃЌЖјЧвДцдкХњЕФИХФюЃЌгХЯШМЖдНЕЭЃЌЁАШќЕРЁБдНЖрЁЃИпгХЯШМЖДђЖЯЕЭгХЯШМЖЃЌаТНЈЕФШЮЮёашвЊИГгшЪВУДгХЯШМЖЕШЮЪЬтЖМЪЧLaneЫљвЊНтОіЕФЮЪЬтЁЃ
Concurrent ModeЕФФПЕФЪЧЪЕЯжвЛЬзПЩжаЖЯ/ЛжИДЕФИќаТЛњжЦЁЃЦфгЩСНВПЗжзщГЩЃК
вЛЬзаГЬМмЙЙЃКFiber Reconciler
ЛљгкаГЬМмЙЙЕФЦєЗЂЪНИќаТЫуЗЈЃКПижЦаГЬМмЙЙЙЄзїЗНЪНЕФЫуЗЈ
фЏРРЦївЛжЁЖМЛсИЩаЉЪВУДвдМАrequestIdleCallbackЕФЦєЪО
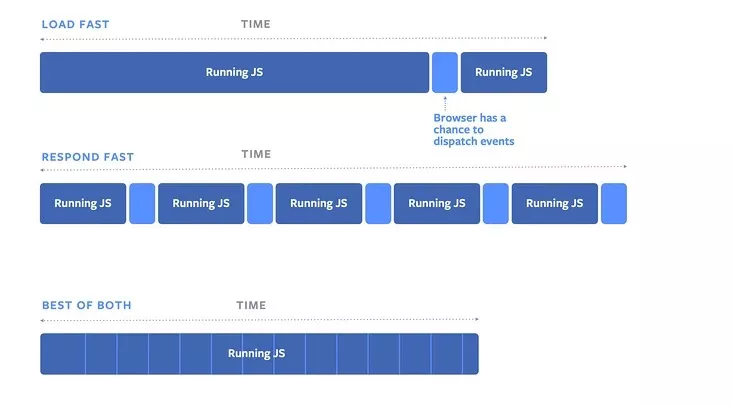
фЏРРЦївЛжЁЖМЛсИЩаЉЪВУДЃП
ЮвУЧЖМжЊЕРЃЌвГУцЕФФкШнЖМЪЧвЛжЁвЛжЁЛцжЦГіРДЕФЃЌфЏРРЦїЫЂаТТЪДњБэфЏРРЦївЛУыЛцжЦЖрЩйжЁЁЃддђЩЯЫЕ 1s
ФкЛцжЦЕФжЁЪ§вВЖрЃЌЛУцБэЯжОЭвВЯИФхЁЃФПЧАфЏРРЦїДѓЖрЪЧ 60HzЃЈ60жЁ/sЃЉЃЌУПвЛжЁКФЪБвВОЭЪЧдк 16.6ms
зѓгвЁЃФЧУДдкетвЛжЁЕФЃЈ16.6msЃЉ Й§ГЬжафЏРРЦїгжИЩСЫаЉЪВУДФиЃП
ЭМЦЌфЏРРЦївЛжЁЖМЛсИЩаЉЪВУД

ЭЈЙ§ЩЯУцетеХЭМПЩвдЧхГўЕФжЊЕРЃЌфЏРРЦївЛжЁЛсОЙ§ЯТУцетМИИіЙ§ГЬЃК
1.НгЪмЪфШыЪТМў
2.жДааЪТМўЛиЕї
3.ПЊЪМвЛжЁ
4.жДаа RAF (RequestAnimationFrame)
5.вГУцВМОжЃЌбљЪНМЦЫу
6.ЛцжЦфжШО
7.жДаа RIC (RequestIdelCallback)
ЕкЦпВНЕФ RIC ЪТМўВЛЪЧУПвЛжЁНсЪјЖМЛсжДааЃЌжЛгадквЛжЁЕФ 16.6ms жазіЭъСЫЧАУц 6 МўЪТЖљЧвЛЙгаЪЃгрЪБМфЃЌВХЛсжДааЁЃШчЙћвЛжЁжДааНсЪјКѓЛЙгаЪБМфжДаа
RIC ЪТМўЃЌФЧУДЯТвЛжЁашвЊдкЪТМўжДааНсЪјВХФмМЬајфжШОЃЌЫљвд RIC жДааВЛвЊГЌЙ§ 30msЃЌШчЙћГЄЪБМфВЛНЋПижЦШЈНЛЛЙИјфЏРРЦїЃЌЛсгАЯьЯТвЛжЁЕФфжШОЃЌЕМжТвГУцГіЯжПЈЖйКЭЪТМўЯьгІВЛМАЪБЁЃ
requestIdleCallback ЕФЦєЪО
ЮвУЧвдфЏРРЦїЪЧЗёгаЪЃгрЪБМфзїЮЊШЮЮёжаЖЯЕФБъзМЃЌФЧУДЮвУЧашвЊвЛжжЛњжЦЃЌЕБфЏРРЦїгаЪЃгрЪБМфЪБЭЈжЊЮвУЧЁЃ
requestIdleCallback((deadline) => {
// deadline гаСНИіВЮЪ§
// timeRemaining(): ЕБЧАжЁЛЙЪЃЯТЖрЩйЪБМф
// didTimeout: ЪЧЗёГЌЪБ
// СэЭт requestIdleCallback КѓШчЙћИњЩЯЕкЖўИіВЮЪ§ {timeout:
...} дђЛсЧПжЦфЏРРЦїдкЕБЧАжЁжДааЭъКѓжДааЁЃ
if (deadline.timeRemaining() > 0) {
// TODO
} else {
requestIdleCallback(otherTasks);
}
});
// гУЗЈЪОР§
var tasksNum = 10000
requestIdleCallback(unImportWork)
function unImportWork(deadline) {
while (deadline.timeRemaining() && tasksNum
> 0) {
console.log(`жДааСЫ ${10000 - tasksNum + 1}ИіШЮЮё`)
tasksNum--
}
if (tasksNum > 0) { // дкЮДРДЕФжЁжаМЬајжДаа
requestIdleCallback(unImportWork)
}
} |
ЦфЪЕВПЗжфЏРРЦївбОЪЕЯжСЫетИіAPIЃЌетОЭЪЧrequestIdleCallbackЁЃЕЋЪЧгЩгквдЯТвђЫиЃЌFacebook
ХзЦњСЫ requestIdleCallback ЕФдЩњ APIЃК
фЏРРЦїМцШнадЃЛ
ДЅЗЂЦЕТЪВЛЮШЖЈЃЌЪмКмЖрвђЫигАЯьЁЃБШШчЕБЮвУЧЕФфЏРРЦїЧаЛЛtabКѓЃЌжЎЧАtabзЂВсЕФrequestIdleCallbackДЅЗЂЕФЦЕТЪЛсБфЕУКмЕЭЁЃ
ЛљгквдЩЯдвђЃЌдкReactжаЪЕЯжСЫЙІФмИќЭъБИЕФrequestIdleCallbackpolyfillЃЌетОЭЪЧSchedulerЁЃГ§СЫдкПеЯаЪБДЅЗЂЛиЕїЕФЙІФмЭтЃЌSchedulerЛЙЬсЙЉСЫЖржжЕїЖШгХЯШМЖЙЉШЮЮёЩшжУЁЃ
Fiber ЮЊЪВУДЪЧ React адФмЕФвЛИіЗЩдОЃП
ЪВУДЪЧ Fiber
Fiber ЕФгЂЮФКЌвхЪЧЁАЯЫЮЌЁБЃЌЫќЪЧБШЯпГЬЃЈThreadЃЉИќЯИЕФЯпЃЌБШЯпГЬЃЈThreadЃЉПижЦЕУИќОЋУмЕФжДааФЃаЭЁЃдкЙувхМЦЫуЛњПЦбЇИХФюжаЃЌFiber
гжЪЧвЛжжазїЕФЃЈCooperativeЃЉБрГЬФЃаЭЃЈаГЬЃЉЃЌАяжњПЊЗЂепгУвЛжжЁОМШФЃПщЛЏгжазїЛЏЁПЕФЗНЪНРДБрХХДњТыЁЃ
дк React жаЃЌFiber ОЭЪЧ React 16 ЪЕЯжЕФвЛЬзаТЕФИќаТЛњжЦЃЌШУ React ЕФИќаТЙ§ГЬБфЕУПЩПиЃЌБмУтСЫжЎЧАВЩгУЕнЙщашвЊвЛЦјКЧГЩгАЯьадФмЕФзіЗЈЁЃ
React Fiber жаЕФЪБМфЗжЦЌ
АбвЛИіКФЪБГЄЕФШЮЮёЗжГЩКмЖраЁЦЌЃЌУПвЛИіаЁЦЌЕФдЫааЪБМфКмЖЬЃЌЫфШЛзмЪБМфвРШЛКмГЄЃЌЕЋЪЧдкУПИіаЁЦЌжДааЭъжЎКѓЃЌЖМИјЦфЫћШЮЮёвЛИіжДааЕФЛњЛсЃЌетбљЮЈвЛЕФЯпГЬОЭВЛЛсБЛЖРеМЃЌЦфЫћШЮЮёвРШЛгадЫааЕФЛњЛсЁЃ
React Fiber АбИќаТЙ§ГЬЫщЦЌЛЏЃЌУПжДааЭъвЛЖЮИќаТЙ§ГЬЃЌОЭАбПижЦШЈНЛЛЙИј React ИКд№ШЮЮёаЕїЕФФЃПщЃЌПДПДгаУЛгаЦфЫћНєМБШЮЮёвЊзіЃЌШчЙћУЛгаОЭМЬајШЅИќаТЃЌШчЙћгаНєМБШЮЮёЃЌФЧОЭШЅзіНєМБШЮЮёЁЃ
Stack Reconciler
ЛљгкеЛЕФ ReconcilerЃЌфЏРРЦїв§ЧцЛсДгжДааеЛЕФЖЅЖЫПЊЪМжДааЃЌжДааЭъБЯОЭЕЏГіЕБЧАжДааЩЯЯТЮФЃЌПЊЪМжДааЯТвЛИіКЏЪ§ЃЌжБЕНжДааеЛБЛЧхПеВХЛсЭЃжЙЁЃШЛКѓНЋжДааШЈНЛЛЙИјфЏРРЦїЁЃгЩгк
React НЋвГУцЪгЭМЪгзївЛИіИіКЏЪ§жДааЕФНсЙћЁЃУПвЛИівГУцЭљЭљгЩЖрИіЪгЭМзщГЩЃЌетОЭвтЮЖзХЖрИіКЏЪ§ЕФЕїгУЁЃ
ШчЙћвЛИівГУцзуЙЛИДдгЃЌаЮГЩЕФКЏЪ§ЕїгУеЛОЭЛсКмЩюЁЃУПвЛДЮИќаТЃЌжДааеЛашвЊвЛДЮаджДааЭъГЩЃЌжаЭОВЛФмИЩЦфЫћЕФЪТЖљЃЌжЛФм"вЛаФвЛвт"ЁЃНсКЯЧАУцЬсЕНЕФфЏРРЦїЫЂаТТЪЃЌJS
вЛжБжДааЃЌфЏРРЦїЕУВЛЕНПижЦШЈЃЌОЭВЛФмМАЪБПЊЪМЯТвЛжЁЕФЛцжЦЁЃШчЙћетИіЪБМфГЌЙ§ 16msЃЌЕБвГУцгаЖЏЛаЇЙћашЧѓЪБЃЌЖЏЛвђЮЊфЏРРЦїВЛФмМАЪБЛцжЦЯТвЛжЁЃЌетЪБЖЏЛОЭЛсГіЯжПЈЖйЁЃВЛНіШчДЫЃЌвђЮЊЪТМўЯьгІДњТыЪЧдкУПвЛжЁПЊЪМЕФЪБКђжДааЃЌШчЙћВЛФмМАЪБЛцжЦЯТвЛжЁЃЌЪТМўЯьгІвВЛсбгГйЁЃ
Fiber Reconciler
СДБэНсЙЙ
дк React Fiber жагУСДБэБщРњЕФЗНЪНЬцДњСЫ React 16 жЎЧАЕФеЛЕнЙщЗНАИЁЃдк React
16 жаЪЙгУСЫДѓСПЕФСДБэЁЃ
ЪЙгУЖрЯђСДБэЕФаЮЪНЬцДњСЫдРДЕФЪїНсЙЙЃЛ
<div id="A">
A1
<div id="B1">
B1
<div id="C1"></div>
</div>
<div id="B2">
B2
</div>
</div> |
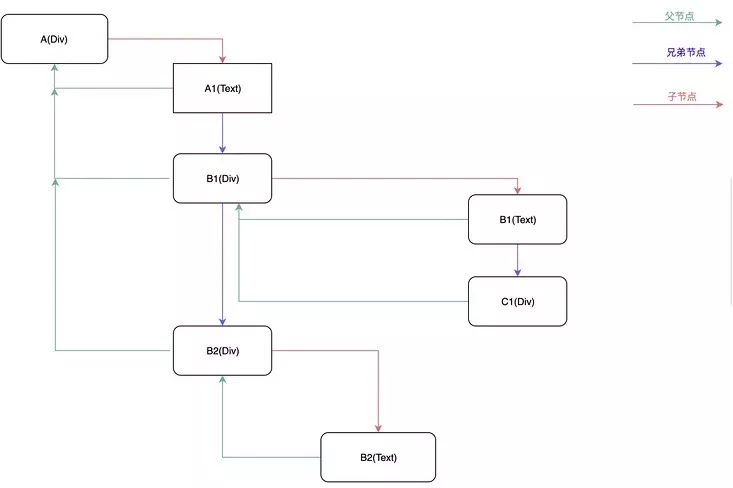
ЖрЯђСДБэ
ИБзїгУЕЅСДБэЃЛ
ИБзїгУЕЅСДБэ
зДЬЌИќаТЕЅСДБэЃЛ
зДЬЌИќаТЕЅСДБэ
СДБэЪЧвЛжжМђЕЅИпаЇЕФЪ§ОнНсЙЙЃЌЫќдкЕБЧАНкЕужаБЃДцзХжИЯђЯТвЛИіНкЕуЕФжИеыЃЛБщРњЕФЪБКђЃЌЭЈЙ§ВйзїжИеыевЕНЯТвЛИідЊЫиЁЃ

СДБэ
СДБэЯрБШЫГађНсЙЙЪ§ОнИёЪНЕФКУДІОЭЪЧЃК
1.ВйзїИќИпаЇЃЌБШШчЫГађЕїећЁЂЩОГ§ЃЌжЛашвЊИФБфНкЕуЕФжИеыжИЯђОЭКУСЫЁЃ
2.ВЛНіПЩвдИљОнЕБЧАНкЕуевЕНЯТвЛИіНкЕуЃЌдкЖрЯђСДБэжаЃЌЛЙПЩвдевЕНЫћЕФИИНкЕуЛђепажЕмНкЕуЁЃ
ЕЋСДБэвВВЛЪЧЭъУРЕФЃЌШБЕуОЭЪЧЃК
1.БШЫГађНсЙЙЪ§ОнИќеМгУПеМфЃЌвђЮЊУПИіНкЕуЖдЯѓЛЙБЃДцгажИЯђЯТвЛИіЖдЯѓЕФжИеыЁЃ
2.ВЛФмздгЩЖСШЁЃЌБиаыевЕНЫћЕФЩЯвЛИіНкЕуЁЃ
React гУПеМфЛЛЪБМфЃЌИќИпаЇЕФВйзїПЩвдЗНБуИљОнгХЯШМЖНјааВйзїЁЃЭЌЪБПЩвдИљОнЕБЧАНкЕуевЕНЦфЫћНкЕуЃЌдкЯТУцЬсЕНЕФЙвЦ№КЭЛжИДЙ§ГЬжаЦ№ЕНСЫЙиМќзїгУЁЃ
ьГВЈФЧЦѕЪ§СаЕФ Fiber
ЕнЙщаЮЪНЕФьГВЈФЧЦѕЪ§СааДЗЈЃК
function fib(n) {
if (n <= 2) {
return 1;
} else {
return fib(n - 1) + fib(n - 2);
}
} |
ВЩгУ Fiber ЕФЫМТЗНЋЦфИФаДЮЊбЛЗЃЈетИіР§згВЂВЛФмКЭ React Fiber ЕФЖдЕШЃЉЃК
function fib(n) {
let fiber = { arg: n, returnAddr: null, a: 0 },
consoled = false;
// БъМЧбЛЗ
rec: while (true) {
// ЕБеЙПЊЭъШЋКѓЃЌПЊЪММЦЫу
if (fiber.arg <= 2) {
let sum = 1;
// бАевИИМЖ
while (fiber.returnAddr) {
if(!consoled) {
// дкетРяДђгЁВщПДаЮГЩЕФСДБэаЮЪНЕФ fiber ЖдЯѓ
consoled=true
console.log(fiber)
}
fiber = fiber.returnAddr;
if (fiber.a === 0) {
fiber.a = sum;
fiber = { arg: fiber.arg - 2, returnAddr: fiber,
a: 0 };
continue rec;
}
sum += fiber.a;
}
return sum;
} else {
// ЯШеЙПЊ
fiber = { arg: fiber.arg - 1, returnAddr: fiber,
a: 0 };
}
}
} |
React Fiber ЪЧШчКЮЪЕЯжИќаТЙ§ГЬПЩПиЃП
ИќаТЙ§ГЬЕФПЩПижївЊЬхЯждкЯТУцМИИіЗНУцЃК
ЁЄШЮЮёВ№Зж
ЁЄШЮЮёЙвЦ№ЁЂЛжИДЁЂжежЙ
ЁЄШЮЮёОпБИгХЯШМЖ
ШЮЮёВ№Зж
дк React Fiber ЛњжЦжаЃЌЫќВЩгУ"ЛЏећЮЊСу"ЕФЫМЯыЃЌНЋЕїКЭНзЖЮЃЈReconcilerЃЉЕнЙщБщРњ
VDOM етИіДѓШЮЮёЗжГЩШєИЩаЁШЮЮёЃЌУПИіШЮЮёжЛИКд№вЛИіНкЕуЕФДІРэЁЃ
ШЮЮёЙвЦ№ЁЂЛжИДЁЂжежЙ
workInProgress tree
workInProgress ДњБэЕБЧАе§дкжДааИќаТЕФ Fiber ЪїЁЃдк render Лђеп setState
КѓЃЌЛсЙЙНЈвЛПХ Fiber ЪїЃЌвВОЭЪЧ workInProgress treeЃЌетПУЪїдкЙЙНЈУПвЛИіНкЕуЕФЪБКђЛсЪеМЏЕБЧАНкЕуЕФИБзїгУЃЌећПУЪїЙЙНЈЭъГЩКѓЃЌЛсаЮГЩвЛЬѕЭъећЕФИБзїгУСДЁЃ
currentFiber tree
currentFiber БэЪОЩЯДЮфжШОЙЙНЈЕФ Filber ЪїЁЃдкУПвЛДЮИќаТЭъГЩКѓ workInProgress
ЛсИГжЕИј currentFiberЁЃдкаТвЛТжИќаТЪБ workInProgress tree дйжиаТЙЙНЈЃЌаТ
workInProgress ЕФНкЕуЭЈЙ§ alternate ЪєадКЭ currentFiber ЕФНкЕуНЈСЂСЊЯЕЁЃ
дкаТ workInProgress tree ЕФДДНЈЙ§ГЬжаЃЌЛсЭЌ currentFiber ЕФЖдгІНкЕуНјаа
Diff БШНЯЃЌЪеМЏИБзїгУЁЃЭЌЪБвВЛсИДгУКЭ currentFiber ЖдгІЕФНкЕуЖдЯѓЃЌМѕЩйаТДДНЈЖдЯѓДјРДЕФПЊЯњЁЃвВОЭЪЧЫЕЮоТлЪЧДДНЈЛЙЪЧИќаТЁЂЙвЦ№ЁЂЛжИДвдМАжежЙВйзїЖМЪЧЗЂЩњдк
workInProgress tree ДДНЈЙ§ГЬжаЕФЁЃworkInProgress tree ЙЙНЈЙ§ГЬЦфЪЕОЭЪЧбЛЗЕФжДааШЮЮёКЭДДНЈЯТвЛИіШЮЮёЁЃ
ЙвЦ№
ЕБЕквЛИіаЁШЮЮёЭъГЩКѓЃЌЯШХаЖЯетвЛжЁЪЧЗёЛЙгаПеЯаЪБМфЃЌУЛгаОЭЙвЦ№ЯТвЛИіШЮЮёЕФжДааЃЌМЧзЁЕБЧАЙвЦ№ЕФНкЕуЃЌШУГіПижЦШЈИјфЏРРЦїжДааИќИпгХЯШМЖЕФШЮЮёЁЃ
ЛжИД
дкфЏРРЦїфжШОЭъвЛжЁКѓЃЌХаЖЯЕБЧАжЁЪЧЗёгаЪЃгрЪБМфЃЌШчЙћгаОЭЛжИДжДаажЎЧАЙвЦ№ЕФШЮЮёЁЃШчЙћУЛгаШЮЮёашвЊДІРэЃЌДњБэЕїКЭНзЖЮЭъГЩЃЌПЩвдПЊЪМНјШыфжШОНзЖЮЁЃ
ЁЄШчКЮХаЖЯвЛжЁЪЧЗёгаПеЯаЪБМфЕФФиЃП
ЪЙгУЧАУцЬсЕНЕФ RIC (RequestIdleCallback) фЏРРЦїдЩњ APIЃЌReact
дДТыжаЮЊСЫМцШнЕЭАцБОЕФфЏРРЦїЃЌЖдИУЗНЗЈНјааСЫ PolyfillЁЃ
ЁЄЛжИДжДааЕФЪБКђгжЪЧШчКЮжЊЕРЯТвЛИіШЮЮёЪЧЪВУДФиЃП
Д№АИЪЧдкЧАУцЬсЕНЕФСДБэЁЃдк React Fiber жаУПИіШЮЮёЦфЪЕОЭЪЧдкДІРэвЛИі FiberNode
ЖдЯѓЃЌШЛКѓгжЩњГЩЯТвЛИіШЮЮёашвЊДІРэЕФ FiberNodeЁЃ
жежЙ
ЦфЪЕВЂВЛЪЧУПДЮИќаТЖМЛсзпЕНЬсНЛНзЖЮЁЃЕБдкЕїКЭЙ§ГЬжаДЅЗЂСЫаТЕФИќаТЃЌдкжДааЯТвЛИіШЮЮёЕФЪБКђЃЌХаЖЯЪЧЗёгагХЯШМЖИќИпЕФжДааШЮЮёЃЌШчЙћгаОЭжежЙдРДНЋвЊжДааЕФШЮЮёЃЌПЊЪМаТЕФ
workInProgressFiber ЪїЙЙНЈЙ§ГЬЃЌПЊЪМаТЕФИќаТСїГЬЁЃетбљПЩвдБмУтжиИДИќаТВйзїЁЃетвВЪЧдк
React 16 вдКѓЩњУќжмЦкКЏЪ§ componentWillMount гаПЩФмЛсжДааЖрДЮЕФдвђЁЃ

workInProgress tree ЙЙНЈ
ШЮЮёОпБИгХЯШМЖ
React Fiber Г§СЫЭЈЙ§ЙвЦ№ЃЌЛжИДКЭжежЙРДПижЦИќаТЭтЃЌЛЙИјУПИіШЮЮёЗжХфСЫгХЯШМЖЁЃОпЬхЕуОЭЪЧдкДДНЈЛђепИќаТ
FiberNode ЕФЪБКђЃЌЭЈЙ§ЫуЗЈИјУПИіШЮЮёЗжХфвЛИіЕНЦкЪБМфЃЈexpirationTimeЃЉЁЃдкУПИіШЮЮёжДааЕФЪБКђГ§СЫХаЖЯЪЃгрЪБМфЃЌШчЙћЕБЧАДІРэНкЕувбОЙ§ЦкЃЌФЧУДЮоТлЯждкЪЧЗёгаПеЯаЪБМфЖМБиаыжДааИУШЮЮёЁЃЙ§ЦкЪБМфЕФДѓаЁЛЙДњБэзХШЮЮёЕФгХЯШМЖЁЃ
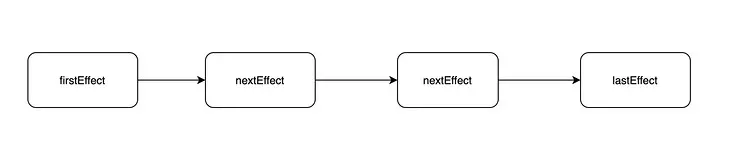
ШЮЮёдкжДааЙ§ГЬжаЫГБуЪеМЏСЫУПИі FiberNode ЕФИБзїгУЃЌНЋгаИБзїгУЕФНкЕуЭЈЙ§ firstEffectЁЂlastEffectЁЂnextEffect
аЮГЩвЛЬѕИБзїгУЕЅСДБэ A1(TEXT)-B1(TEXT)-C1(TEXT)-C1-C2(TEXT)-C2-B1-B2(TEXT)-B2-AЁЃ
ЦфЪЕзюжеЖМЪЧЮЊСЫЪеМЏЕНетЬѕИБзїгУСДБэЃЌгаСЫЫќЃЌдкНгЯТРДЕФфжШОНзЖЮОЭЭЈЙ§БщРњИБзїгУСДЭъГЩ DOM ИќаТЁЃетРяашвЊзЂвтЃЌИќаТецЪЕ
DOM ЕФетИіЖЏзїЪЧвЛЦјКЧГЩЕФЃЌВЛФмжаЖЯЃЌВЛШЛЛсдьГЩЪгОѕЩЯЕФВЛСЌЙсЃЈcommitЃЉЁЃ
<div id="A1">
A1
<div id="B1">
B1
<div id="C1">C1</div>
<div id="C2">C2</div>
</div>
<div id="B2">
B2
</div>
</div> |

ИБзїгУСД
жБЙлеЙЪО
ЮЊСЫЗНБуДѓМвЖдБШЃЌЮвОЭжБНгЗХЩЯСНеХЖдБШЭМАЩЃЌДѓМвздааБШЖдЃЌВюБ№ЛЙЪЧКмУїЯдЕФ


Fiber НсЙЙГЄЪВУДбљЃП
ЛљгкЪБМфЗжЦЌЕФдіСПИќаТашвЊИќЖрЕФЩЯЯТЮФаХЯЂЃЌжЎЧАЕФvDOM treeЯдШЛФбвдТњзуЃЌЫљвдРЉеЙГіСЫfiber
treeЃЈМДFiberЩЯЯТЮФЕФvDOM treeЃЉЃЌИќаТЙ§ГЬОЭЪЧИљОнЪфШыЪ§ОнвдМАЯжгаЕФfiber treeЙЙдьГіаТЕФfiber
treeЃЈworkInProgress treeЃЉЁЃ
FiberNode ЩЯЕФЪєадгаКмЖрЃЌИљОнБЪепЕФРэНтЃЌвдЯТетУДМИИіЪєадЪЧжЕЕУЙизЂЕФЃКreturnЁЂchildЁЂsiblingЃЈжївЊИКд№fiberСДБэЕФСДНгЃЉЃЛstateNodeЃЛeffectTagЃЛexpirationTimeЃЛalternateЃЛnextEffectЁЃИїЪєадНщЩмВЮПДЯТУцЕФclass
FiberNodeЃК
class FiberNode {
constructor(tag, pendingProps, key, mode) {
// ЪЕР§Ъєад
this.tag = tag; // БъМЧВЛЭЌзщМўРраЭЃЌШчКЏЪ§зщМўЁЂРрзщМўЁЂЮФБОЁЂдЩњзщМў...
this.key = key; // react дЊЫиЩЯЕФ key ОЭЪЧ jsx ЩЯаДЕФФЧИі
key ЃЌвВОЭЪЧзюже ReactElement ЩЯЕФ
this.elementType = null; // createElementЕФЕквЛИіВЮЪ§ЃЌReactElement
ЩЯЕФ type
this.type = null; // БэЪОfiberЕФецЪЕРраЭ ЃЌelementType
ЛљБОвЛбљЃЌдкЪЙгУСЫРСМгдижЎРрЕФЙІФмЪБПЩФмЛсВЛвЛбљ
this.stateNode = null; // ЪЕР§ЖдЯѓЃЌБШШч class зщМў new
ЭъКѓОЭЙвдидкетИіЪєадЩЯУцЃЌШчЙћЪЧRootFiberЃЌФЧУДЫќЩЯУцЙвЕФЪЧ FiberRoot,ШчЙћЪЧдЩњНкЕуОЭЪЧ
dom ЖдЯѓ
// fiber
this.return = null; // ИИНкЕуЃЌжИЯђЩЯвЛИі fiber
this.child = null; // згНкЕуЃЌжИЯђздЩэЯТУцЕФЕквЛИі fiber
this.sibling = null; // ажЕмзщМў, жИЯђвЛИіажЕмНкЕу
this.index = 0; // вЛАуШчЙћУЛгаажЕмНкЕуЕФЛАЪЧ0 ЕБФГИіИИНкЕуЯТЕФзгНкЕуЪЧЪ§зщРраЭЕФЪБКђЛсИјУПИізгНкЕувЛИі
indexЃЌindex КЭ key вЊвЛЦ№зі diff
this.ref = null; // reactElement ЩЯЕФ ref Ъєад
this.pendingProps = pendingProps; // аТЕФ props
this.memoizedProps = null; // ОЩЕФ props
this.updateQueue = null; // fiber ЩЯЕФИќаТЖгСажДаавЛДЮ setState
ОЭЛсЭљетИіЪєадЩЯЙввЛИіаТЕФИќаТ, УПЬѕИќаТзюжеЛсаЮГЩвЛИіСДБэНсЙЙЃЌзюКѓзіХњСПИќаТ
this.memoizedState = null; // ЖдгІ memoizedPropsЃЌЩЯДЮфжШОЕФ
stateЃЌЯрЕБгкЕБЧАЕФ stateЃЌРэНтГЩ prev КЭ next ЕФЙиЯЕ
this.mode = mode; // БэЪОЕБЧАзщМўЯТЕФзгзщМўЕФфжШОЗНЪН
// effects
this.effectTag = NoEffect; // БэЪОЕБЧА fiber вЊНјааКЮжжИќаТЃЈИќаТЁЂЩОГ§ЕШЃЉ
this.nextEffect = null; // жИЯђЯТИіашвЊИќаТЕФfiber
this.firstEffect = null; // жИЯђЫљгазгНкЕуРяЃЌашвЊИќаТЕФ fiber
РяЕФЕквЛИі
this.lastEffect = null; // жИЯђЫљгазгНкЕужаашвЊИќаТЕФ fiber
ЕФзюКѓвЛИі
this.expirationTime = NoWork; // Й§ЦкЪБМфЃЌДњБэШЮЮёдкЮДРДЕФФФИіЪБМфЕугІИУБЛЭъГЩ
this.childExpirationTime = NoWork; // child Й§ЦкЪБМф
this.alternate = null; // current ЪїКЭ workInprogress
ЪїжЎМфЕФЯрЛЅв§гУ
}
}
|

fiber-tree
function performUnitWork(currentFiber){
//beginWork(currentFiber) //евЕНЖљзгЃЌВЂЭЈЙ§СДБэЕФЗНЪНЙвЕНcurrentFiberЩЯЃЌУПвЛХМЖљзгОЭевКѓУцФЧИіажЕм
//гаЖљзгОЭЗЕЛиЖљзг
if(currentFiber.child){
return currentFiber.child;
}
//ШчЙћУЛгаЖљзгЃЌдђевЕмЕм
while(currentFiber){//вЛжБЭљЩЯев
//completeUnitWork(currentFiber);//НЋздМКЕФИБзїгУЙвЕНИИНкЕуШЅ
if(currentFiber.sibling){
return currentFiber.sibling
}
currentFiber = currentFiber.return;
}
} |
Concurrent Mode ЃЈВЂЗЂФЃЪНЃЉ
Concurrent Mode жИЕФОЭЪЧ React РћгУЩЯУц Fiber ДјРДЕФаТЬиадЕФПЊЦєЕФаТФЃЪН
(mode)ЁЃreact17ПЊЪМжЇГжconcurrent modeЃЌетжжФЃЪНЕФИљБОФПЕФЪЧЮЊСЫШУгІгУБЃГжcpuКЭioЕФПьЫйЯьгІЃЌЫќЪЧвЛзщаТЙІФмЃЌАќРЈFiberЁЂSchedulerЁЂLaneЃЌПЩвдИљОнгУЛЇгВМўадФмКЭЭјТчзДПіЕїећгІгУЕФЯьгІЫйЖШЃЌКЫаФОЭЪЧЮЊСЫЪЕЯжвьВНПЩжаЖЯЕФИќаТЁЃconcurrent
modeвВЪЧЮДРДreactжївЊЕќДњЕФЗНЯђЁЃ
ФПЧА React ЪЕбщАцБОдЪаэгУЛЇбЁдёШ§жж modeЃК
1.Legacy Mode: ОЭЯрЕБгкФПЧАЮШЖЈАцЕФФЃЪН
2.Blocking Mode: гІИУЪЧвдКѓЛсДњЬц Legacy Mode ЖјГЄЦкДцдкЕФФЃЪН
3.Concurrent Mode: вдКѓЛсБфГЩ default ЕФФЃЪН
Concurrent Mode ЦфЪЕПЊЦєСЫвЛЖбаТЬиадЃЌЦфжагаСНИізюживЊЕФЬиадПЩвдгУРДНтОіЮвУЧПЊЭЗЬсЕНЕФСНИіЮЪЬтЃК
1.Suspense ЪЧ React ЬсЙЉЕФвЛжжвьВНДІРэЕФЛњжЦ, ЫќВЛЪЧвЛИіОпЬхЕФЪ§ОнЧыЧѓПтЁЃЫќЪЧReact
ЬсЙЉЕФдЩњЕФзщМўвьВНЕїгУдгяЁЃ
2.ШУвГУцЪЕЯж Pending -> Skeleton ->
Complete ЕФИќаТТЗОЖ, гУЛЇдкЧаЛЛвГУцЪБПЩвдЭЃСєдкЕБЧАвГУцЃЌШУвГУцБЃГжЯьгІЁЃЯрБШеЙЪОвЛИіЮогУЕФПеАзвГУцЛђепМгдизДЬЌЃЌетжжгУЛЇЬхбщИќМггбКУЁЃ
Цфжа Suspense ПЩвдгУРДНтОіЧыЧѓзшШћЕФЮЪЬтЃЌUI ПЈЖйЕФЮЪЬтЦфЪЕПЊЦє concurrent
mode ОЭвбОНтОіЕФЃЌЕЋШчКЮРћгУ concurrent mode РДЪЕЯжИќгбКУЕФНЛЛЅЛЙЪЧашвЊЖдДњТызівЛЗЌИФЖЏЕФЁЃ
ЮДРДПЩЦк
Concurrent ModeжЛЪЧВЂЗЂЃЌМШШЛШЮЮёПЩВ№ЗжЃЈжЛвЊзюжеЕУЕНЭъећeffect listОЭааЃЉЃЌФЧОЭдЪаэВЂаажДааЃЌЃЈЖрИіFiber
reconciler + ЖрИіworkerЃЉЃЌЪзЦСвВИќШнвзЗжПщМгди/фжШОЃЈvDOMЩСжЁЃ
ВЂаафжШОЕФЛАЃЌОнЫЕFirefoxВтЪдНсЙћЯдЪОЃЌ130msЕФвГУцЃЌжЛашвЊ30msОЭФмИуЖЈЃЌЫљвддкетЗНУцЪЧжЕЕУЦкД§ЕФЃЌЖјReactвбОзіКУзМБИСЫЃЌетвВОЭЪЧдкReact
FiberЩЯЯТЮФОГЃЬ§ЕНЕФД§unlockЕФИќЖрЬиаджЎвЛЁЃ
isInputPending ЁЊЁЊ FiberМмЙЙЫМЯыЖдЧАЖЫЩњЬЌЕФгАЯь
Facebook дк Chromium жаЬсГіВЂЪЕЯжСЫ isInputPending() APIЃЌЫќПЩвдЬсИпЭјвГЕФЯьгІФмСІЃЌЕЋЪЧВЛЛсЖдадФмдьГЩЬЋДѓгАЯьЁЃFacebook
ЬсГіЕФ isInputPending API ЪЧЕквЛИіНЋжаЖЯЕФИХФюгУгкфЏРРЦїгУЛЇНЛЛЅЕФЕФЙІФмЃЌВЂЧвдЪаэ
JavaScript ФмЙЛМьВщЪТМўЖгСаЖјВЛЛсНЋПижЦШЈНЛгкфЏРРЦїЁЃ
ФПЧА isInputPending API Нідк Chromium ЕФ 87 АцБОПЊЪМЬсЙЉЃЌЦфЫћфЏРРЦїВЂЮДЪЕЯжЁЃ
isInputPending
Svelte ЖдЙЬгаФЃЪНЕФГхЛї
ЕБЯТЧАЖЫСьгђЃЌШ§ДѓПђМмReactЁЂVueЁЂAngularАцБОж№НЅЮШЖЈЃЌШчЙћЫЕЧАЖЫаавЕЛсГіЯжФФаЉПђМмгаПЩФмЛсЬєеНReactЛђепVueФиЃПКмЖрШЫШЯЮЊSvelte
гІИУЪЧЦфжаЕФбЁЯюжЎвЛЁЃ
SvelteНаЗЈЪЧ[Svelte], БОвтЪЧУчЬѕЯЫЪнЕФЃЌЪЧвЛИіаТаЫШШУХЕФЧАЖЫПђМмЁЃдкПЊЗЂепТњвтЖШЁЂаЫШЄЖШЁЂЪаГЁеМгаТЪЩЯОљУћСаЧАУЉЃЌЭЌЪБЃЌЫќгаИќаЁЕФДђАќЬхЛ§ЃЌИќЩйЕФПЊЗЂДњТыЪщаДЃЌдкадФмВтЦРжаЃЌгыReactЁЂVueЯрБШЃЌвВВЛхиЖрШУЁЃ
Svelte ЕФКЫаФЫМЯыдкгкЁКЭЈЙ§ОВЬЌБрвыМѕЩйПђМмдЫааЪБЕФДњТыСПЁЛЁЃ
Svelte гХЪЦгаФФаЉ
ЁЄNo Runtime ЁЊЁЊ ЮодЫааЪБДњТы
ЁЄLess-Code ЁЊЁЊ аДИќЩйЕФДњТы
ЁЄHight-Performance ЁЊЁЊ ИпадФм
Svelte СгЪЦ
ЁЄЩчЧј
ЁЄЩчЧј
ЁЄЩчЧј
дРэИХРР
Svelte дкБрвыЪБЃЌОЭвбОЗжЮіКУСЫЪ§Он КЭ DOM НкЕужЎМфЕФЖдгІЙиЯЕЃЌдкЪ§ОнЗЂЩњБфЛЏЪБЃЌПЩвдЗЧГЃИпаЇЕФРДИќаТDOMНкЕуЁЃ
ЁЄRich Harris дкНјааSvelteЕФЩшМЦЕФЪБКђУЛгаВЩгУ Virtual DOMЃЌжївЊЪЧвђЮЊЫћОѕЕУVirtual
DOM Diff ЕФЙ§ГЬЪЧЗЧГЃЕЭаЇЕФЁЃОпЬхПЩВЮПМVirtual Dom ецЕФИпаЇТ№[21]вЛЮФЃЛSvelte
ВЩгУСЫTemplatesгяЗЈЃЌдкБрвыЕФЙ§ГЬжаОЭНјаагХЛЏВйзїЃЛ
ЁЄSvelte МЧТМдрЪ§ОнЕФЗНЪНЃКЮЛбкТыЃЈbitMaskЃЉЃЛ
ЁЄЪ§ОнКЭDOMНкЕужЎМфЕФЖдгІЙиЯЕЃКReact КЭ Vue ЪЧЭЈЙ§ Virtual Dom Нјаа diff
РДЫуГіРДИќаТФФаЉ DOM НкЕуаЇТЪзюИпЁЃSvelte ЪЧдкБрвыЪБКђЃЌОЭМЧТМСЫЪ§Он КЭ DOM НкЕужЎМфЕФЖдгІЙиЯЕЃЌВЂЧвБЃДцдк
p КЏЪ§жаЁЃ
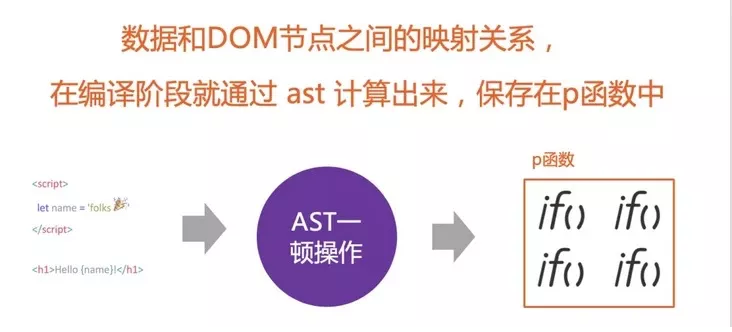
Ъ§ОнКЭDOMНкЕужЎМфЕФЖдгІЙиЯЕ
|








