| 编辑推荐: |
本文主要介绍了如何动手写一个Transformer。希望对您的学习有所帮助 。
本文来自于微信公众号阿里开发者,由火龙果软件Alice编辑、推荐。 |
|
作为工程同学,学习Transformer中,不动手写一个,总感觉理解不扎实。纸上得来终觉浅,绝知此事要躬行,抽空多debug几遍!
注:不涉及算法解释,仅是从工程代码实现去加强理解。
一、准备知识
以预测二手房价格的模型,先来理解机器学习中的核心概念。
1.1、手撸版
1、准备训练数据
num_examples = 1000num_input = 2
true_w = [2, -3.4]true_b = 4.2
features = torch.
randn(num_examples, num_input, dtype=torch.float32)
labels = true_w[0] * features[:,
0] + true_w[1] * features[:, 1] + true_b_temp = torch.tensor(np.
random.normal(0, 0.01, size=labels.size()),
dtype=torch.float32)labels = labels + _temp
|
2、定义模型
w = torch.tensor
(np.random.normal(0, 0.01, (num_input, 1)), dtype=torch.float32)
b = torch.zeros(1, dtype=torch.float32)
w.requires_grad_(requires_grad=True)
b.requires_grad_(requires_grad=True)
def linreg(X, w, b): return torch.mm(X, w) + b
def squared_loss(y_pred, y):
return (y_pred - y.view(y_pred.size())) ** 2 / 2
def sgd(params, lr, batch): for param in params:
param.data -= lr * param.grad / batch
|
3、训练模型
lr = 0.03epoch = 5net = linregloss = squared_lossbatch_size = 10
for epoch in
range(epoch): for
X, y in data_iter(batch_size, features,
labels):
ls = loss(net(X, w, b), y).sum()
ls.backward()
sgd([w, b], lr, batch_size)
w.grad.data.zero_() b.grad.data.zero_()
train_l = loss(net(features, w, b),
labels) print('epoch %d, loss %f'
% (epoch + 1, train_l.mean().item()))
|
1.2、pytorch版
1、准备训练数据
同上
2、定义模型
class LinearNet(nn.Module):
def __init__(self, n_feature):
super(LinearNet, self).__init__() self
.linear = nn.Linear(n_feature, 1)
def forward
(self, x): y = self.linear(x) return y
net = LinearNet(num_input)
init.normal_(net[0].weight, mean=0, std=0.01)
init.constant_(net[0].bias, val=0)
loss = nn.MSELoss()
optimizer
= optim.SGD(net.parameters(), lr=0.03)
|
3、训练模型
num_epochs = 3for epoch in range(1, num_epochs + 1): for X,
y in data_iter: output = net(X) l_sum = loss(output, y.view(-1, 1))
l_sum.backward()
optimizer.step()
optimizer.zero_grad() print('epoch %d,
loss: %f' % (epoch, l_sum.item()))
|
batch 读取数据
batch_size = 10
data_set = Data.TensorDataset(features, labels)
data_iter = Data.DataLoader(data_set, batch_size,
shuffle=True)
|
在用torch框架,进一步要理解:
a、nn.Module 和 forward() 函数:表示神经网络中的一个层,覆写 init 和 forward
方法(提问:实现2层网络怎么做?)
b、debug 观察下数据变化,和 手撸版 对比着去理解
二、手写Transformer
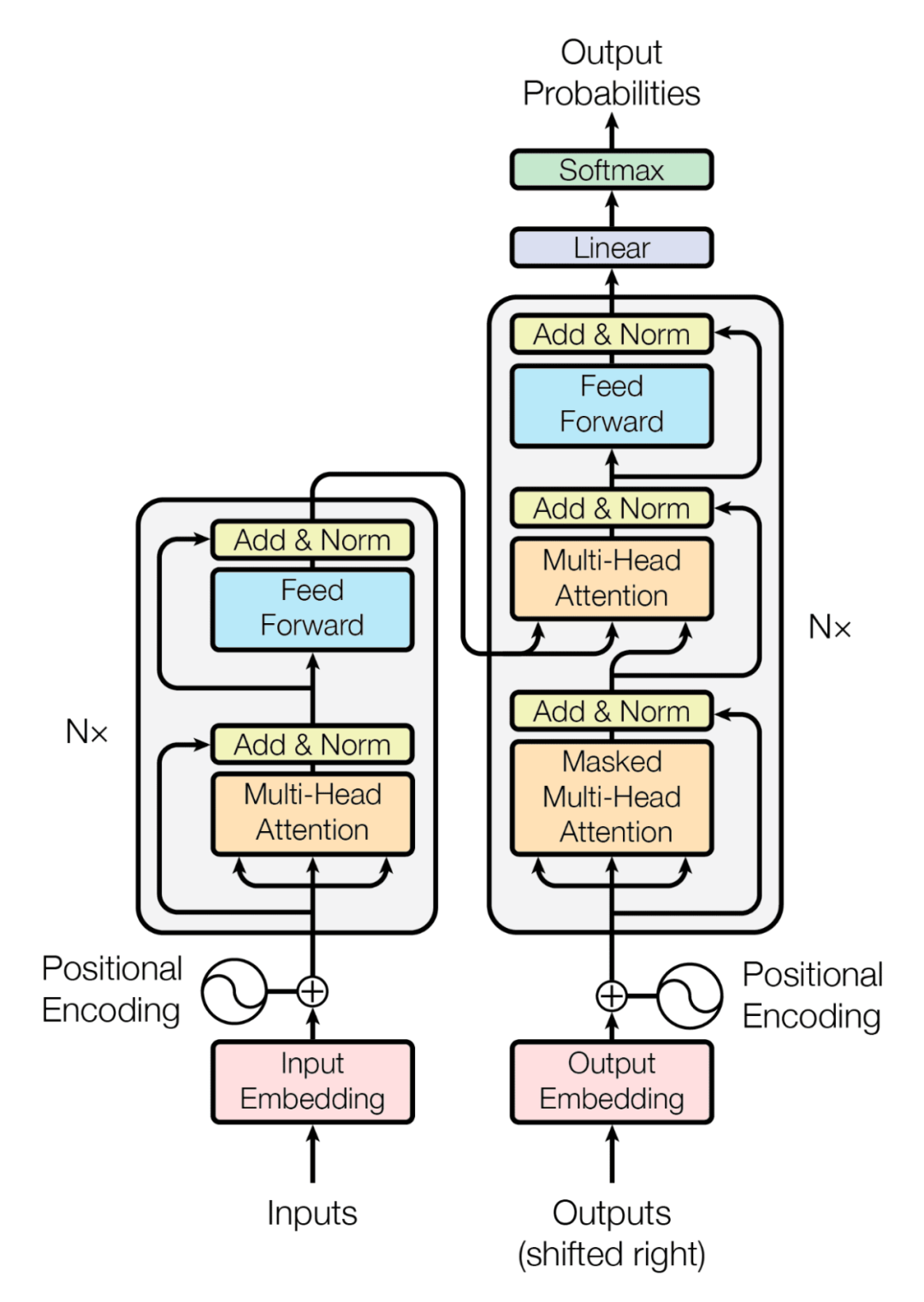
上面这是一个"逻辑"示意图。印象中,第1次看时,以为 "inputs
& outputs" 是并行计算、但上面又有依赖,很糊涂。
这不是一个技术架构图,上图有很多概念,attention、multi-head等。先尝试转换为面向对象的类图,如下:
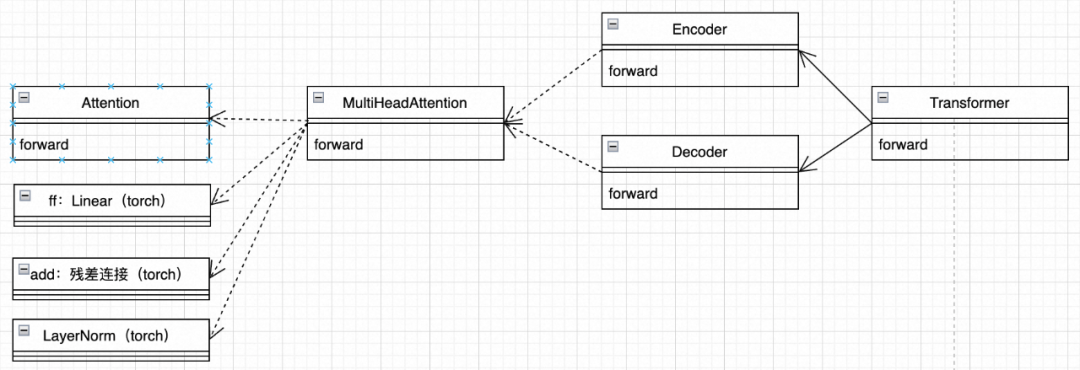
2.1、例子:翻译
source_vocab = {'E': 0, '我': 1, '吃': 2, '肉'
: 3}target_vocab = {'E': 0, 'I': 1, 'eat': 2, 'meat': 3, 'S': 4}
encoder_input = torch.LongTensor([[1, 2, 3,
0]]).to(device) # 我 吃 肉 E, E代表结束词decoder_input
= torch.LongTensor([[4, 1, 2, 3]]).to(device) # S I eat meat,
S代表开始词, 并右移一位,用于并行训练target =
torch.LongTensor([[1, 2, 3, 0]]).to(device)
# I eat meat E, 翻译目标
|
2.2、定义模型
按照上面类图,我们来一点点实现
1、Attention
class ScaledDotProductAttention(nn.Module):
def __init__(self):
super(ScaledDotProductAttention, self).__init__()
def forward(self, Q, K, V, attn_mask):
scores = torch.matmul
(Q, K.transpose(-1, -2)) / np.sqrt(d_k)
scores.masked_fill_
(attn_mask, -1e9) attn = nn.Softmax(dim=-1)(scores)
prob = torch.matmul(attn, V)
return prob
|
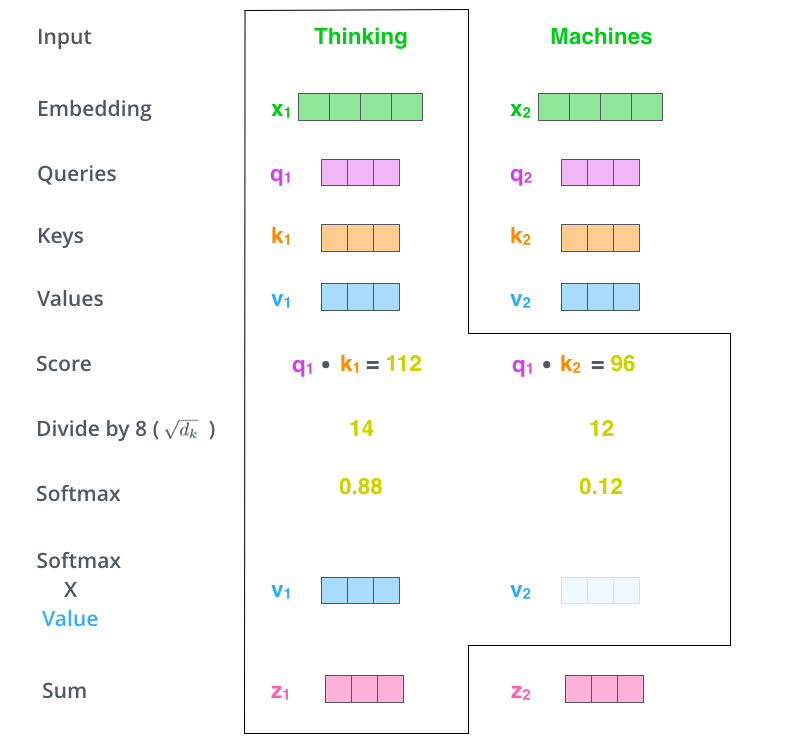
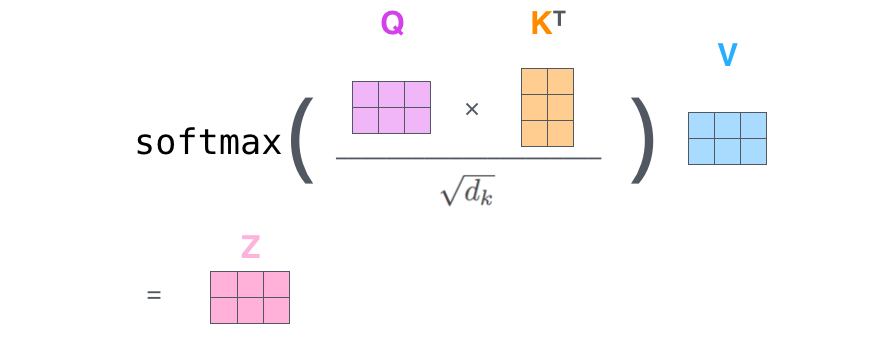
2、MultiHeadAttention
通用变量定义
d_model = 6 d_ff = 12 d_k = d_v = 3 n_heads = 2 p_drop = 0.1 device = "cpu"
|
注1:按惯性会想,会有多个head、串行循环计算,不是,多个head是一个张量输入
注2:FF 全连接、残差连接、归一化,35、38 行业代码,pytorch框架带来的简化
class MultiHeadAttention(nn.Module): def __init__
(self): super(MultiHeadAttention, self)
.__init__() self.n_heads = n_heads
self.W_Q = nn.Linear(d_model, d_k * n_heads,
bias=False) self.W_K = nn.Linear
(d_model, d_k * n_heads, bias=False)
self.W_V = nn.Linear(d_model, d_v * n_heads, bias=False)
self.fc = nn.Linear(d_v * n_heads,
d_model, bias=False)
self.layer_norm = nn.LayerNorm(d_model)
def forward(self, input_Q, input_K, input_V,
attn_mask):
residual, batch = input_Q, input_Q.size(0)
Q = self.W_Q(input_Q)
Q = Q.view(batch, -1, n_heads, d_k).
transpose(1, 2) K = self.
W_K(input_K).view(batch, -1, n_heads, d_k).
transpose(1, 2) V = self.W_V(input_V).view(batch,
-1, n_heads, d_v).transpose(1, 2)
attn_mask = attn_mask.unsqueeze(1).repeat
(1, n_heads, 1, 1)
prob = ScaledDotProductAttention
()(Q, K, V, attn_mask)
prob = prob.transpose(1, 2).
contiguous() prob = prob.view(batch, -
1, n_heads * d_v).contiguous()
output = self.fc(prob)
res =
self.layer_norm(residual + output) return res
|
3、Encoder
在 attention 概念中,有很关键的 "遮盖" 概念,先不细究,你debug一遍会更理解
def get_attn_pad_mask(seq_q, seq_k): batch, len_q = seq_q.size()
batch, len_k = seq_k.size()
pad_attn_mask = seq_k.data.eq(0).unsqueeze(1)
return pad_attn_mask.
expand(batch, len_q, len_k)
def get_attn_subsequent_mask(seq):
attn_shape = [seq.size(0), seq.size(1),
seq.size(1)] subsequent_mask = np.triu(np.ones(attn_shape),
k=1) subsequent_mask = torch.from_numpy
(subsequent_mask) return subsequent_mask
|
class Encoder(nn.Module): def __init__(self
): super(Encoder, self).__init__()
self.source_embedding = nn.Embedding
(len(source_vocab), d_model)
self.attention = MultiHeadAttention()
def forward(self, encoder_input):
embedded = self.
source_embedding(encoder_input)
mask = get_attn_pad_mask(encoder_input,
encoder_input) encoder_output = self
.attention(embedded, embedded, embedded, mask)
return encoder_output
|
4、Decoder
class Decoder(nn.Module):
def __init__(self): super
(Decoder, self).__init__() self.target_
embedding =
nn.Embedding(len(target_vocab),
d_model) self.attention =
MultiHeadAttention()
def forward(self, decoder_input,
encoder_input, encoder_output):
decoder_embedded =
self.target_embedding(decoder_input)
decoder_self_attn_mask = get_attn_pad
_mask(decoder_input, decoder_input)
decoder_subsequent_mask = get_attn_subsequent
_mask
(decoder_input)
decoder_self_mask = torch.gt
(decoder_self_attn_mask + decoder_subsequent_mask, 0)
decoder_output = self.
attention(decoder_embedded, decoder_
embedded, decoder_embedded, decoder_self_mask)
decoder_encoder_attn_mask = get_attn_pad_mask
(decoder_input, encoder_input) decoder_output = self.attention
(decoder_output, encoder_output, encoder_
output, decoder_encoder_attn_mask) return decoder_output
|
5、Transformer
class Transformer(nn.Module): def __init__(self):
super(Transformer, self).__init__()
self.encoder = Encoder() self.decoder =
Decoder() self.fc = nn.Linear
(d_model, len(target_vocab), bias=False)
def forward(self, encoder_input, decoder_input)
:
encoder_output = self.encoder(encoder_input)
decoder_output = self.decoder(decoder_input,
encoder_input, encoder_output)
decoder_logits = self.fc(decoder_output)
res = decoder_logits.view(-1,
decoder_logits.size(-1)) return res
|
2.3、训练模型
model = Transformer().to(device)criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=1e-1)
for epoch in range(10): output = model
(oencder_input, decoder_input) loss =
criterion(output, target.view(-1))
print('Epoch:', '%04d' % (epoch + 1),
'loss =', '{:.6f}'.format(loss)) optimizer.zero_grad
() loss.backward() optimizer.step()
|
2.4、使用模型
target_len = len(target_vocab) encoder_output =
model.encoder(encoder_input) decoder_input = torch.zeros(1,
target_len).type_as(encoder_input.data) next_symbol = 4
for i in range(target_len):
decoder_input[0][i] = next_symbol
decoder_output =
model.decoder(decoder_input, encoder_input,
encoder_output)
logits =
model.fc(decoder_output).squeeze(0)
prob = logits.max(dim=1, keepdim=False)[1]
next_symbol = prob.data[i].item()
for k, v in target_vocab.items():
if v == next_symbol: print('第', i, '轮:', k) break
if next_symbol == 0: break
|
|






 订阅
订阅