| �ڹ�ȥ�ļ����У������Ѿ�������������ڽ���Ԥ��ģ�͵����ݲ�Ʒ����Щ��Ʒ����������Ԥ�����Ƽ����棬�ٵ�������ʱ��Ԥ���������Ԥ�������Ⱥ��չ�˾������ȷ
�� ���ǣ���Щ��Ʒ��ֻ�ǽ���Ԥ�⣬�����Ǹ�֪�Դ�Ԥ�����ò�ȡ�������ж���Ԥ�⼼����������Ȥ�ģ����Ҿ�����ѧ�ϵ������ԣ���������Ҫ����һ������������������ǽ������ı�������ҵ�����ݲ�Ʒ����ʲô���ɲ�ȥ�����أ�
��Ϊ����������̵Ŀ�ʼ�������Ѿ��ı��˱���ҵ���IJ��������� ���ǰ�����Ϊ����ϵͳ���������Դ������������Լ�ʻ����������ʦ���Ƕ���һ����ȷ��Ŀ��
��������Ҫ���������˸�Ԥ������£���ȫ�ش�A����ʻ��B�㡣�ɹ���Ԥ�⽨ģ����һ���������Ϊ��Ҫ�IJ��֣������Ų�Ʒ���Ӷȵ���ߣ�����������һ�������IJ��֣��������뵽��Ʒ�ν����ˡ�һЩʹ�ùȸ���Զ���ʻ�������˲���֪����ʹ�������������䱳���ϰٳ�ǧ�ֵ�����ģ�ͺ�PB�������ݡ����ݿ�ѧ�ҹ����IJ�Ʒ���渴�ӣ�������Ҫһ��ϵͳ����Ʒ���������ϵͳ������һ������û�Ψһ�ķ��������ǵ�Ŀ���������ݿ�ѧ����ҵ����֮�佨����Ի������ƶ����ǹ�ͬ��Ŀ�ꡣ
����Ŀ������ݲ�Ʒ
�������ڽ�������������ʱ����ʹ�����ݲ�ֻ��Ϊ�˲�����������ݣ�����Ԥ�������ݣ������Ǵ�����֪���ò�ȡʲô�ж�������Ǵ���ϵͳ������Ŀ�ġ�Ϊ����õ�˵��������̣���������һ���dz���Ϥ�����ݲ�Ʒ���������档�ص�1997�꣬AltaVista�����㷨������������ߡ���Ȼ���ǵ�ģ������Ѱ�Ҿ�������Ե���վ�������û������Ȥ�Ľ��������������������еİ�ҳ�Ժ��û����������ܷ��ʵ���֮�ȸ����ˣ���һ��������ı�������������û���������ҪĿ����ʲô��

����ϵͳ�������IJ�����
�ȸ���ʶ��������Ŀ����Ϊ���ҵ�����ص��������������������˾��Ŀ�Ŀ��������������ƿͻ����顢�ҵ������˵����·�ߣ����Ƕ��������Ľ��и���ƽ�⡣һ�����Ƕ�����Ŀ��֮��
�ڶ����������ҳ�ϵͳ�пɿص����� ������Щ���Ե�����Ӱ�����յĽ���ĸܸ����ء����ڹȸ裬���ǿ��Կ�����������е�������
��������˼������������������Ҫʲô�������ݣ�������ʶ������ҳ�����ӵ���Щ������ҳ��һ��������Ϣ���Ա����ڴ�Ŀ�ġ�
ֻ����ǰ������������ǿ�ʼ˼������Ԥ��ģ�� ��
���ǵ�Ŀ�ꡢ���õĸܸ����ء����е����ݼ��������ռ��Ķ������ݣ������������ܽ�������ģ�͡��ɿظܸ����غ����в��ɿ����ض�����Ϊ��ģ�͵����룻ģ�͵����������������������Ԥ������Ŀ������������
�ȸ����õĴ���ϵͳ�����еĵ��IJ��������Ǹ߿Ƽ���ʷ��һ�����ˣ�������棨Larry Page����л���ǡ����֣�Sergey
Brin��������ͼ�ı����㷨PageRank�����ɴ˽����˸����Ե��������档���ǣ���Ҳ���Ƿǵ÷�����һ��PageRank���ܽ���һ���˲�������ݲ�Ʒ�����ǽ�����һ��ϵͳ���IJ����ķ�����û�м������ʿѧλҲ�������á�
ģ��װ���ߣ����ž�����İ����о�
�Ӻ��ʵ�Ԥ��ģ���Ż�����һ��������ж���������ǹ�˾����Ҫ��ս�Ծ��ߡ����ڱ��չ�˾���۸����߾������ǵIJ�Ʒ������һ�����ŵĶ���ģ��֮�����Ǿ���������װ��������֮�����������̡�����ҵ�м������Ԥ�⾭�飬���ڽ�ʮ�꣬���չ�˾��������ÿ���¿ͻ�����ȡ���ٷ���������һ����ҵ�����ŵ��жϡ����ǵľ���ʦ���Խ���ģ����Ԥ��ͻ������¹ʵĿ����Ժ���������Ԥ��ֵ��������Щģ�Ͳ����ܽ���������⣬���Ա��չ�˾ֻ���ڽ���г��о��Ļ����ϲ²�һ�����ۡ�
���������1999����Ϊһ����Ϊ���ž���С�� ��ODG���Ĺ�˾���õ��˸ı䡣��Ϊ����ϵͳ������һ���������ã�ODGʵ�������еIJ����ġ���������Ӧ���ںܶ�㷺�����⡣���ȣ����Ƕ����˱��չ�˾��Ŀ��
������¹˿���һ�������ڵ�������ֵ����ͬʱ��Ҫ���ǵ�һЩ�������أ����籣���г��ݶ�����������Ƿ�չ��һ���Ż��Ķ��۹��̣�Ϊ���չ�˾��������������Ԫ�ı�������[
ע�����ĵĹ�ͬ���߽����ס������£�Jeremy Howard��������ODG��
ODG ȷ������Щ���չ�˾�Ŀɿظܸ����أ���ÿ���ͻ���ȡ�ļ۸��ǵ��¹����ͣ����г�Ӫ���Ϳͻ������ϻ��Ļ��ѣ��Լ����Ӧ���侺�����ֵĶ��۷���������Ҳ�����˲��ɿ����أ��羺�����ֵ�ս�ԡ���۾��õ��������Ȼ�ֺ��Լ��ͻ��ġ�ճ�ԡ������ǻ���������Ҫʲô���Ķ����������Ԥ��ͻ����ڼ۸�䶯�ķ�Ӧ��Ϊ�˽�����Щ���ݼ�������б�Ҫ���������µ�����ı�ɰ���ǧ�����۲��ԡ���Ȼ���չ�˾��Ը����Щ��ʵ�ͻ�������ʵ�飬��Ϊ������Ȼ�����ʧȥһЩ�ͻ��������Ż��������߿��ܴ����ľ�������ǰ�����ǻ��Ƕ�ҡ�ˡ����գ�ODG��ʼ����ܹ�����չ�˾�����ģ��
��
����ϵͳ�������IJ���ģ��װ�������ߡ�ͼ�λ������ݲ�Ʒ��ģ��װ�������ߣ��ɽ�ԭʼ����ת��Ϊ��һ�����ж��������ģ����ԭʼ����ת�����Լ�������Ԥ�����ݡ�

ODG��ģ���еĵ�һ�������һ�������±����������ļ۸���ģ�ͣ��û�����һ�������۸�ĸ��ʣ����۸���ģ�ͷ�ӳ�����û����ܱ����ĸ��ʺͱ����۸�֮��Ĺ�ϵ���������ߴӵͼ�ʱ�ļ����϶�����һֱ����ʱ�ļ��������ܽ��ܡ�
ODG ��ģ���ڶ�������ڿ����ܹ����ܱ����۸�Ŀͻ�������£��ѱ��չ�˾������Ͳ�Ʒ�۸���й��������ͼ۸��µ������ڿ��ǵ�һ���Ԥ��������ϻ�ȡ��ά���¿ͻ��Ŀ����������������ʾΪ��ɫ��������������˽��õ�һ�����յ����ߣ���ʾ�˼۸���Ԥ������Ķ�Ӧ��ϵ�����·���Ԥ������ͼ
��������������һ�������ɱ�ľֲ����ֵ�������˵�һ��Ӧ�������û�����Ѽ۸�

Ԥ������
ODG�������˿ͻ��ҳ϶ȵ�ģ�͡���Щģ���ڿ��Ǽ۸�仯�Ϳͻ�תͶ�������ֹ�˾����Ը������£�Ԥ��ͻ��Ƿ����һ������������Щ�����ģ�ͽ�����ģ�ͽ��ܹ�Ԥ��δ��������һ�����û����ܴ���������
�����µ�ģ���Բ���һ�����մ𰸣���Ϊ��ֻ��ȷ��һ����������Ľ������װ�������ߡ�����һ������������һ��ģ����
��ͨ������ODG�����ʡ����硭���������������⣬���۲�ܸ����������Ӱ�����ս���ķֲ��ġ��ѿ��ܳ��ֵĽ����Ϊһ�����棬Ԥ���������߽�������������һ����Ƭ��Ҫ�����������棬ģ������Ҫ��ģ�������д�Χ�����롣����Ա���Ե�������ĸܸ����ظ����ش�һЩ�ض������⣬���硰�����˾�ڵ�һ��Ϊ�ͻ��ṩһ���ջ��Եĵͼۣ�Ȼ���ڵڶ�����۸����кνY����������Ҳ����̽Ѱ��Щ���ڱ��չ�˾��˵�IJ��ɿ����������Ӱ������ķֲ��ģ���������ñ������ҿͻ�ʧȥ�����Ĺ������ǻ�������������ļ������˰���һ���ĺ�ˮ����Σ����һ���¾����߽����г������ǹ�˾�ֲ���Ӧ�ԣ�������ǵĵ������������Ӱ�죿������ģ������ÿһ�����߲���ģ������̿��Կ���һ������ļ۸�䶯�����룬�г��ݶ����ʱ������ƺ�����ָ���Ӱ�졣
ģ�����Ľ�����������Ż��� ������ȷ�������������п��ܽ���������е���ߵ㡣�Ż�����������ý������Ҳ����ʶ����Щ�����Եĺ��������֪��α������ǡ��������кܶͬ���Ż������ɹ�ѡ������ı���
��������һ��Ϊ������֪������������ǿ�������õĽ����������ȻODG�ľ�������������ѵļ۸������õļ���������ͬ���������Ƴ���ͬ����һ������ȫ���Ե����ݲ�Ʒ��ʹ�ö�������ϵͳģ�ͺ�ģ��װ�������ϵ���Ҫ��ֵ���ڣ������Ϳ�����Ԥ��ģ�ͺͿɲ�ȡ���ж���֮�������һ��������
CloudPhysics��˾�����������������£�Irfan Ahmed ����Ԥ��ģ�ͽ��������õķ��࣬��������������װ���߹��̣�
������Ҫ�����ɰ���ǧ�����ģ�����˽�����ϵͳ����Ϊ��ʱ���������������DZ���ġ��Ұ���������һ�������ҿ��Ļ�ĸ��ӵĻ���������ϵͳ��ͨ���ܿص�ʵ�飬���Ƕ����������ÿ����Ҫ���ֽ�ģ��Ȼ��ģ�������֮�������á�ע������IJ�ͬ��Σ���������Ķ���ģ�ͣ���һ��������һ�������ģ�������������һ��ͨ�������Ż����ڲ�ͬ�����뼯���Ͻ����Ż�������
��������ʵ�����е��Ż�
�Ż���һ����������⣬��ţ�ٺ�˹��ʼֱ���ֽ����ѧ�Һ���ʦ�Ƕ��ڶԴ˽����о��������Ż������ǵ����ģ������������һС�����鿴���ǵĸ߶ȣ�Ȼ��������һС����ֱ�����Ǵﵽһ���������ĸ����������ϸ��ߵĵ㡣��һ��ɽ������Σ��֮�����ڣ��������̫С�ˣ����ǿ��ܻᶺ����ɽ���µľֲ����ֵ�У�������ҵ��ɿ������е���Ѽ��ϡ����кܶ༼�����Ա���������⣬һЩ�ǻ���ͳ��ѧ���ҰѶ���ѽ���IJ²ⷶΧ���ø��㣻����һЩ�ǻ�����Ȼ���м���ϵͳ������������������е�ԭ����ȴ���̡�
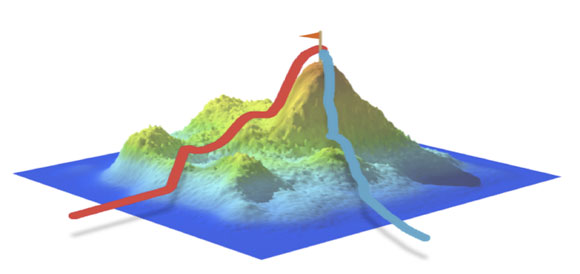
�Ż���һ���������ճ������ж�����Ϥ�Ĺ��̣���ʹ���Ǵ���û��ʹ�ù������ݶ��½�������ģ���˻���Ż��㷨��һ�������TechZing�����ṩ��һ����ʵ�������Ż��ķdz��õ�д�գ���ƪ���������������ھ�ľ���ƽ̨Kaggle�Ĺ�ͬ�����ˡ����ĵ�����֮һ������һ�ֵ����Ż�������Ȼ��������˵��������ˣ���һ�������Ͻ����ף�Jeremy������ķ�������������һ����ҵ��˾����
����һЩ����������Ȼ���ص������������ٵ�������һ�仰����������һ��С�ʹ�ҵ��˾������һ�ұ��վ�ͷ��������Ҫ�������ȥ������ȥ�ĵط���ʱ�����Ƕ��ڲ��Ծ���ʹ���Ż���
�Ƽ�ϵͳ�еĴ���ϵͳ����
��������������������ܹ�Ӧ�ô˹��̵���һ����ҵ���г�Ӫ�������ȣ����ǵĴ���ϵͳ����Ӧ�õ�һ����Ϥ�����ӣ��Ƽ����棬Ȼ���ɴ˽���һ���������Ż�Ӫ�����ԡ�
�Ƽ�������Ϊ����֪�����ݲ�Ʒ���ӣ����ǻ��ھ��Ĵ����Ԥ��ģ�͵ģ����Dz���ǣ��Ѱ����ѽ����Ŀǰ���㷨����ݿͻ��Լ��������ƵĿͻ�������ʷ��Ԥ��ͻ���ϲ��ʲô���IJ�Ʒ��������ѷ�����Ĺ�˾����ÿһ�ν��ױ�ʾ��һ�����ϡ��������ǿͻ���������Ʒ��һ�������������ָ�ʽ�����ݣ����ݿ�ѧ�ҾͿ���Ӧ��ij����ʽ��Эͬ����������д�������磬����û�A�����Ʒ1��10���ͻ�B�����Ʒ1��2��4��10���Ƽ�����Ὠ��A��2��4����Щģ���ܹ�������Ԥ��ͻ��Ƿ��ϲ��ij�������IJ�Ʒ���������Ƽ��IJ�Ʒ�����ǹ˿��Ѿ�֪�����Ѿ���������ˡ�����ѷ���Ƽ������������������õ�һ����������������ʾ���������⡣������ʾ���ࡣ�������Ž�ͼ�ǹ���������ѷ������̩��
��������Terry Pratchett���ġ�Discworldϵ��������ͼ��������˴���Ʒ���û��������ˡ���һ������ʾ�����ݡ�

���е��Ƽ�����ͬһϵ�е������鼮������һ���ܺõļ�����ǣ���Щ�����һ�������ˡ�̩�� ��������Terry
Pratchett�����Ŀͻ��������֪���˵��顣һЩԤ��֮��Ľ�����ܻ��������һ���ĵڶ�����ʮ��ҳ�����ж��ٿͻ�����䷳��һһ����ȥ�أ�
�������ַ������������ô���ϵͳ���������һ���Ľ������Ƽ����档���Ǵ����¿������ǵ�Ŀ�꿪ʼ ���Ƽ������Ŀ����ͨ���Ƽ�һЩ���û���Ƽ����û����ܲ��Ṻ�����������û���ϲ���˷ܵ��飬�Դ����ƶ���������ۡ�����������Ҫ����ģ�����ˡ�Լ��ѷ��Mark
Johnson Zite CEO�������� �����������TOC̸�� �й��ڡ��ͻ��Ƽ����鵽��Ӧ���������ġ�����һ�����õ����ӡ����߽�˹�����������ŦԼ�У���Ҫ��һ�������ݡ�Ī��ɭ��Toni
Morrison���ġ���������Beloved)�����Ƶ��顣��̨�����Ů���Ƽ��������������ɣ�William
Faulkner���ġ�Ѻɳ����Ѻɳ���� ��Absolom Absolom��������������ѷ�ϣ�һ����������������ǰ�Ķ������ݡ�Ī��ɭ����һЩ�������һЩд�й����廰���֪��Ů�����ҵ���Ʒ��˹���������̵��Ƽ����вţ�Ҳ��������������Ƽ����ܸ�����ǻ���Ī��ɭ���ı����ʶ��Ǻ��������ߵı����ϵ������ԡ���������ֱ�ﱾ�ʵ��Ƽ���ʹ�ͻ�����һ������ؼң������ڽ���һ���٣��ٶ����ػص�˹�����¡�
�ⲻ��˵������ѷ���Ƽ����治��������ͬ�����ԣ������������õ��Ƽ�������������������Ƽ���֮�£�Զ����Щ�͡����������������������Ե���֮�¡����ǵ�Ŀ����Ϊ�˱����Ƽ��Ĺ�����ĭ����һ������������������Eli
Pariser������������������Ի�������Դ������һ�������ԣ�������ʾһЩֻ��ƽ������Ĵ��ڹ۵�����»���ֻ�ǽ�һ��ȷ�϶�������ƫ�������¡�
���AltaVista-Google��������˵��һ�����̿��Կ��Ƹܸ����ؾ����Ƽ������������ռ��µ������������µ��Ƽ��Դ˴����µ����ۡ��⽫��Ҫ������������������ռ����ݣ���Щ������Ҫ���Ƕ��ڴ�Χ�ͻ���ȫ��λ�Ƽ���
����ϵͳ�����е����һ���ǽ���ģ��װ���� �������Ƽ���ĭ��һ�ַ����ǽ���һ���������ֹ������ģ�͵Ľ�ģ�����ֱ���Կ����Ƽ���û�п����Ƽ������������������֮����Ƕ���һ�������˿͵��Ƽ���Ч�ú��������·��Ƽ�����ͼ��������ֵ����������ºܵͣ����㷨�Ƽ�����һ��ͦ�����ģ��Ѿ����ͻ��ܾ��˵��飨�������ǵͺ���ֵ����һ����ʹ���Ƽ�����Ҳ������飨�������Ǹߺ���ֵ������ʾ��������
�����ǿ��Խ���һ��ģ�������������ǿ��������ͼ���Ч�ã�����ֻ�ǰ�Э������ģ�ͣ��й����ƿͻ��Ľ���ģ�ͣ������������´���һ�ߣ�Ȼ����һ�����Ż��������Ƽ���ͼ�鰴��ģ�����Ч����������ʾ��ͨ����˵��������ѡ��һ��Ŀ�꺯�����Ż�ʱ�����Ǹ���ǿ�����ǡ�Ŀbiao�����ǡ����ܡ���ʲô���������ݲ�Ʒ���û���Ŀ�ģ����ǵ����ڰ�������������ѡ��

�Ż��˿�������ֵ
��ͬ��ϵͳ�������Ա������Ż�����Ӫ�����ԡ����������������ʵ����������֮�����ͻ������л������Ƿ�����Ʒ�Ƽ��������ͻ��˽������̵��һ���¹��ܣ����Ƿ��ʹ������Ϣ��ѡ�����Ĵ��۶�����������ζ��������٣��������۲�û�д��������Ӫҵ�����ʧ����ɱ�����������ҳ�ϵ�ϡȱ�Է��ز���Ϣ���Լ��Ƽ���λ��һЩ�û���ϲ������ʹû���Ƽ�Ҳ��Ȼ�Ṻ��Ķ�����ռ�ݣ������ǵ��¿ͻ�����ʧ�������˹������õĵ����ʼ����������¿ͻ������н������ʼ����˳��������ʼ��������ǽ����������ȥ����һ���Ż���Ӫ�����ԣ���������ЩӰ�졣
��֮ǰ��ÿ�������У����Ƕ�������һ�����⣺��ʲô��Ӫ��������ͼ�ﵽ��Ŀ�ꣿ���𰸺ܼ�����ϣ���Ż�ÿ���ͻ���������ֵ���ڶ������⣺����ʲô�ܸ�����
�����ǿ��Լ�������ȥʵ����һĿ��ģ����в��٣��������磺
1.���ǿ���ʹ��Ʒ�Ƽ������˸е����Ⱥ����õģ�ʹ����һ�����г����Ż����飩��
2.���ǿ�����Թ˿Ͳ�û��ȫ��������ǻ�ȥ�����̼ҹ���IJ�Ʒ�ṩ�������Ƶ��ۿۻ�������Żݣ�
3.������������ͬ���ͻ��ػ��绰�������û��ж�ϲ�����ǵ���վ�������Ǿ������ǵ�������м�ֵ�ġ�
������Ҫ�ռ������������ݣ���ͬ����Ĵ𰸸�����ͬ������һ����һЩ��������������ȡ�����Եķ���������ʱ�������̵�Zafuչʾ����ι����ͻ���������ռ����̡�������ţ�в�����վ�ܶ࣬�����ںܶ�Ů����˵���ߵ�ţ�п�ķ�װ�����Ǵ���û������������ģ���Ϊ���Դ��Ļ����ҵ����ʵġ�Zafu�������Dz��ÿͻ�ֱ��ȥ���·���������һЩ��������Ϊ��ʼ��ͨ��ѯ�ʿͻ������ͣ��Լ�����ţ�п�ĺ�������������ǵ�ʱ��ƫ�á���Щ֮�ͻ��ſ�ʼ���Zafu
�ӿ����ѡ�����Ƽ��������ռ����Ƽ�������һ�����ӹ��ܣ������Ѿ���Zafu��������ҵģʽ ���� Ůʽţ�п�������ݲ�Ʒ��Zafu�������ǵ��Ƽ������þ��������ǵ�ţ�п�һ���ĺ�������Ϊ���ǵ�ϵͳ������ȷ�����⡣

��Ŀ����Ϊ��ʼ��ʹ���ݿ�ѧ���ǿ�ʼ����������ҪΪ��ģ��������Щ�����ģ�͡����ǿ��Ա����������еġ����ơ�ģ�ͣ��Լ�������Ƽ���û���Ƽ�����µ������ϵģ�ͣ�Ȼ���ȡ�ֽεķ�ʽ������������Ϊ�����Ƶ�Ӫ��Ч���Ķ����ģ�͡����ǿ�������һ���۸���ģ���������ṩ�ۿ۽����Ӱ���û�������Ʒ�ĸ��ʡ����ǿ��Զ��ڿͻ�������Բ�Ķ����������������һ������ģ�ͣ�����ʲôʱ������������������Ϣֱ�ӹ��˳������ʼ����������Hulu�ٸ��ҿ�һ�����������棬�Ҿ������ˣ�����һ�ֹ���˳�������ϵģ�Ϳ�������ʶ��ؼ��ġ������Բ�Ʒ�������磬һ����ţ�п��������ij�����´���������ijϵ��С˵�ĵ�һ���������ᵼ��֮����һϵ�е����׳��ۡ�
������Щģ�ͺ����ǾͿ��Թ�����һ��ģ�������Ż������������������������ģ�ͣ����ҳ�ʲô�Ƽ���ʵ�����ǵ�Ŀ�꣺�ƶ����ۺĽ��ͻ����顣
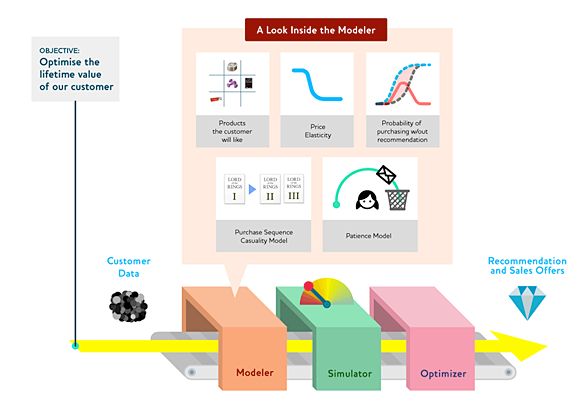
���ݲ�Ʒ�����ʵ��
���Ǻ���������������˼ά��������Ϊ���������洢��һЩ����ĵط���������һ�����ӱ����л����ƶ˵������У�������ݲ�ƷҲ����һЩ������㷨��Ϊ�ˣ�����ϣ������չʾ����Ŀ������ݲ�Ʒ������Ѿ���Ϊ������ε������һ���ֵġ���Щ��������Ҫ�ĵط��ǣ������Щ���ݲ�Ʒ�Ĺ���ʦ������һ��ʼ�����һ���������Ļ����ˣ�Ȼ���ٿ�����������Щʲô�����ǿ�ʼ��������Ŀ�꣺������Ҫ�ҵij�����ȥ��ͬ�ĵط�����Ȼ�������һ����Ϊ��֪���ݲ�Ʒ�������һ������ʦ�Ǿ������ĵ����㷨Ӧ���Ϸdz������ȣ���Ϊ���dz־õ�һֱ���Ի���Ŀ��ķ���˼���Լ��Ľ�ģ�е�������ս�����ȿ�ʼʹ��������ľ���רҵ����ʦ�ǣ�������Ӧ�õ�����װ�������ߵ��Ż���ƺ����������ϡ�����������������Brian
Ripley's�����й�ģʽʶ��Ŀ���������Ϊ�ܶ��20����70����������������Ĺ����ļ�Ӯ����Ӧ�е����������ǰ����������뷨�ͼ�����
�����һ����Ʒ�����������У���������ϵͳģ�͵ļ��ɣ�ģ����Ż��Ĺ��̣���ϵͳ����ʦ���߰���һ������Ϥ�IJ��֡��ڹ�����ͨ����Ҫ����������ģ��������һ���Ա���Զ�����һ�����ģ�⡢�Ż�����Щ��ҵ�г���ľ��飬Ϊ�����ղ�Ʒ��ÿһ��������ϵͳ����ģ�ͣ���������Ҫ�����һ��������Ⱥ��������ʽս���������ǿ��ܻ���һ����еϵͳ����ϸģ�ͣ�һ�������й���ϵͳ��һ��������ģ�ͣ�����һ����Ϊ����ϵͳ��Ƶ�ģ�ͣ��ȵȡ�������Щϵͳ�������������Ҫ�����á����磬�ڵ���ϵͳ�ĵ����������������Ϊһ�������뵼������ɢ����ȴģ�͡���������������ɻ�е�����ı��Σ�������Ҫ�����еģ�͵�ѹ����
����Ľ�ͼ�Ǵ��ɷ�˼�����Ƶ�ģ�ͼ��ɹ����н�ȡ�ġ���Ȼ����ͼ������һ����ȫ��ͬ�Ĺ���ѧ�ƣ�����ȴ�������Ƽ��������������ݲ�Ʒ�Ĵ���ϵͳ�����dz����ơ�Ŀ�������������һ���ɻ�������j���е���ư��������ȣ��ȱȺ��Ӷ���Щ�ܸ�����
�����ݴ����ڻ������ϵ���������֮�У��ɱ���������Ӧ�ó������һ��ѡ��С������һ�����ڿ�������ѧ���ܺͻ�е�ṹ�Ľ�ģ���������Ա����뵽һ��ģ�����������ؼ���������������ɱ�������������ϵ�����յ���������Щ��������������뵽һ���Ż����Խ���һ���������������ҳɱ�Ҳ�ܻ���Ļ�����

Ԥ���Խ�ģ���Ż��ڹ㷺�Ļ�б��Խ��Խ������Ҫ����������Ŀ�Դ���Щ�ܹ�������ҵ�Ĺ���ʦ�ǣ���Ȼ�Ⲣ������������������ҵ���С�����������ϵͳ����������У�
�Ѿ���ɽ���ǣ�Mountain View����·���ˣ����Ǻܺõ����� �������������������ģ��������ڿ����������������ǡ�
����������Ӿɽ�ɽȥʥ��������Santa Clara���μ�2012���Strata���� ���ʹˣ����Ǽ��ɽ���һ���йؾ���/���ٵļ�ģ����Ԥ���ʱ�䣬����Ҫһ�ѳߺ�·�ߵ�ͼ�Ϳ������ˡ��������ϣ����һ�������µ�ϵͳ�����ǿ����ٽ�һ����ͨ���������ģ�ͣ�Ȼ������һ��Ԥ����������Լ����������ȫ��ʻ�ٶ�Ӱ���ģ�͡�������Щģ�͵Ĺ����У���������ܶ�ܿ����ս�����������ǻ����ܴ����ǵ�Ŀ�ĵء������һЩ����ʽ�������㷨��Ԥ�ⲻͬ·�ߵļ�ʻʱ���Ǽ���������£�
ģ���� ����Ȼ������ڿ������硰������ŷѡ����ߡ�������͵�Ч�á�������������ѡ����̵�һ��·���� �Ż���
�����ǣ�Ϊʲô����ø���һЩ������ֻ��GPSװ�õ�Ů�����������������Ǹ�������·�ߣ���������ת�䣬��������һ���Լ��ͻ�����Щ������������Ϊʲô������һ����������ѷ�����Ż�����������һ��ͳͳ���������ĺں����
���������������Ǵ���ϵͳ������һ��������Ӧ�á������Ѿ����������ǵ�Ŀ�� ������һ���ܹ����м�ʻ���������ܸ����������Ƕ�����Ϥ�ij����Ŀ��Ʋ����������̣����ţ�ɲ���ȡ������������ǿ���������Ҫ�ռ�ʲô�������ݣ�����Ҫ�Ĵ��������ռ���·���ݣ�����Ҫ����ͷ������·��־����ƻ����̵ƣ��Լ����벻�����ϰ����������ˣ���������Ҫ�������ǻ��õ���ģ�ͣ�����Ԥ��ת��ɲ���ͼ�����ӦӰ�������ģ�ͣ��Լ�ģʽʶ���㷨����·��ת��������
��
����ȸ��Զ���ʻ������Ŀ��һ������ʦ�������һƪ�����ߡ���־��������д����������ÿ����Ҫ������Ԥ������20�Ρ�����仰��û���ᵽ��ǡǡ�����Ԥ������Ľ����������Ҫʹ��һ��ģ��������������ֿ�ѡ���ж����ᵼ�������Ľ���������������ת�����ײ�������أ����������������������55Ӣ��ÿСʱ���ٶ���ת�������أ�����Ԥ��ᷢ��ʲô�������á����м�ʻ��������Ҫ����һ������
ģ�������еĿ����Ժ����Ż�ģ��������ѡ�����١�ɲ����ת���Լ��źŵƵ������ϣ��Ӷ������ǰ�ȫ�صִ�ʥ��������Ԥ��ֻ�������ǽ�Ҫ�����¹ʡ��Ż��������������α����¹ʷ�����
���Ƶ������ռ���Ԥ��ģ���Ƿdz���Ҫ�ģ�������Ҫǿ���Զ���һ��������Ŀ����Ϊ��ʼ����Ҫ�ԣ�����Ŀ��Ҫ�����ܹ������ж���ĸܸ����ء����ݿ�ѧ�Ѿ���ʼ�鼰���������еķ������档���ڿ�ѧ�Һ���ʦ��ø�����Ԥ����Ż��ճ����⣬����������������ԣ�ȥ�Ż������Ǹ��˵Ľ��������������ķ��Ӻͳ��е�ÿһ������������ģ�����嶯����������ģ�ͱ����ڸ��ƽ�ͨ����������
�����еĸܸ����ؾ��dz��ڵ�����λ���Լ�������Ⱥ���ϰ��������˵���վ�Ľ�����ɢ�����������������������ڼ䷢����Ⱥ��̤��Σ�ա�Nest��˾������������¿��������ܹ�ѧϰ�������˶��¶�ƫ�ã�Ȼ���Ż���Դ���ġ�����������ͨ��IBM��˹�¸��Ħ�п�չ��һ����Ŀ���Ż���ͨ����������ӵ���̶ȼ����˽��ķ�֮һ�����ѳ������ĵĿ������������25������Ϊ����˼���ǣ��Ⲣû�б�Ҫ����һ���µľ�����Ƶ����ݲɼ�ϵͳ���κ�һ���ں��̵��ϴ��в���װ�õij��ж��Ѿ�ӵ�������б�Ҫ����Ϣ������ȱ�ٵ�ֻ�Ǵ��м�ȡ����ķ�����
����һ��������Ŀ������ݲ�Ʒ���Ÿı���������������ڼ�÷¡��ѧ��CMU����ȷ�У������һ����Ŀ�Դ������ݲ�Ʒȥ������Ȼ����Ϊ�ֺ��еļ�����Ա�����ͻ�÷¡��ѧ��ȷ�У��Jeannie
Stamberger�����ǽ���������Ԥ���㷨��Ӧ���ֺ��е�Ӧ�ã���ͨ�������أ�Twitter�����ı��ھ������������ȷ���ƻ��ij̶ȣ�����Ⱥ���������;�Ԯ�����������ˣ��ٵ��������˾����Ͻ��Э�����Ƿ�Ӧ�������Ż����ߡ���Щ����Ӧ���Ǻܺõ�������˵��Ϊʲô���ݲ�Ʒ��Ҫ�ġ�������õĽӿ����������Ľ��顣�ڽ�������£�һ��ֻ�Dz�����������ݵ����ݲ�Ʒ��û�ж���ô��ġ���ѧ����������Ԥ�����������Ʒ�Ը���Ҵ����ô�����������Ҫ��ʶ�����⽨����ģ���Dz����ģ����ǻ���Ҫ�ṩ���Ż����ģ�����ʵ�ֵ�������Ϊ�����
���ݲ�Ʒ��δ��
���ǽ����˴���ϵͳ�ķ����Դ�Ϊ�����һ����������ݲ�Ʒ�ṩ��һ����ܣ�����������һ�����ں��IJ�����������������Ż����������ϣ�������Ż���������ѧԺ��ͳ��ѧϵ�Ľ�ѧ�С�����ϣ���������ݿ�ѧ���Ƴ��IJ�Ʒ�����ʱ���ǵ�������������������ҵ�ɹ��ġ�����Ȼֻ�����ݿ�ѧ�ij��ڽΡ����Dz�֪��δ��������չ��ʲô������Ʒ�������Ŀǰ�����ݿ�ѧ���б�ҪΧ����һ����ͬ�Ĵʻ�Ͳ�Ʒ��ƹ��̣��Դ�������������δ����ǵ�Ԥ��ģ���л�ü�ֵ������������Ļ������ǻᷢ�֣����ǵ�ģ��ֻ��������������������ݣ�������ʹ�������������ж���������ҵ���ı���� |





