| БрМЭЦМі: |
БОЦЊЮФеТЭЈЙ§ЭЦМіФЃаЭАИР§ШЋУцЕиНЋAIВњЦЗОРэашвЊЖЎЕФЫуЗЈКЭФЃаЭНјааСЫЯЕЭГЕФНВНтЁЃ
БОЮФРДздгкИіШЫЭМЪщЙн ЃЌгЩЛ№СњЙћШэМўAliceБрМЃЌЭЦМіЁЃ |
|

ЮФеТвдВњЦЗОРэгІИУЖЎФФаЉОЋзМЭЦМіЫуЗЈФЃаЭЮЊжїЯпЃЌЫГЕРдкЩЯЦЊжаЯШНЋЫуЗЈАДееЛњЦїбЇЯАЗчИёНјааЛЎЗжЃЌЯТЦЊАДееЙІФмЯрЫЦадНјааЛЎЗжЃЌДгВњЦЗОРэБиЖЎЕФОЋзМЭЦМіЫуЗЈФЃаЭеЙПЊЃЌЪЕжЄДЋЭГЫуЗЈФЃаЭЖдВњЦЗОЋзМЭЦМіЕФЙІгУКЭШБЯнЃЌШЛКѓзмНсГівЛЬзAI-UTAUTФЃаЭЃЌМДећКЯAIММЪѕОЋзМЭЦМіФЃаЭЙЉЖСепТфЕиОпЬхВњЦЗЪЕеНВЮПМЁЃ
МДБОЦЊЯЃЭћвдОЋзМЭЦМіФЃаЭЮЊАИР§ЭЈЙ§ШЋУцЕФзЋаДНЋAIВњЦЗОРэашвЊЖЎЕФЫуЗЈКЭФЃаЭНјааСЫЯЕЭГЕФШыУХНВНтЁЃ
СэЭтЮвдкзЋЮФжЎЧАЯШЫЕУїЃКвЛИіВњЦЗОРэОГЃвЩЛѓЕФИХФюЃКЫуЗЈКЭФЃаЭЕФЙиЯЕЃЌВњЦЗОРэЖЎЕУНтОіЮЪЬтЪБНЋЮЪЬтГщЯѓЮЊФЃаЭЃЌЖдФЃаЭЧѓНтгУЫуЗЈЃЌУЛгаЫДѓЫаЁЃЌЫуЗЈКЭФЃаЭУЛгаОјЖдЕФЗжНчЯпЁЃ
ЩЯЦЊЮвУЧНВНтСЫГЃгУЕФОЋзМЭЦМіФЃаЭКЭДгЛњЦїбЇЯАбЇЯАЗчИёЕФНЧЖШзЋаДСЫФкШнЃЌетЦЊНЋжївЊДгЪБЯТИїжжЫу ЗЈФЃаЭгУгкОЋзМЭЦМіЖМгаЦфИїздЕФгХЕуКЭШБЕуДјГіЮвздДДЕФОЋзМЭЦМіФЃаЭAI-UTAUTФЃаЭКЭЪЕР§НтЮіЃЌЫГЕРНВНтДгЫуЗЈФЃаЭЙІФмЕФЯрЫЦадЕФНЧЖШЮЊШыУХAIВњЦЗОРэЕФЭЌбЇНВНтЫуЗЈФЃаЭЕФСэЭтвЛИіЮЌЖШЁЃ
вЛЁЂДЋЭГЕФUTAUTЭЦМіФЃаЭ
ЪВУДНаUTAUTЃЌДЋЭГЩЯUTAUTжИЕФЪЧећКЯаЭПЦММНгЪмФЃЪНЃЌМДЭЈЙ§етИіФЃаЭИїИівђзгРДЙлВьОЋзМЭЦМіФЃаЭжагУЛЇЕФНгЪмвтдИЁЃ
ећКЯММЪѕНгЪмгыЪЙгУФЃаЭЃЈUnified theory of Acceptance and Use
of TechnologyЃЌМђГЦUTAUTЃЉЪЧгЩ Venkatesh and Davis ЮФПЈЫўЪВКЭДїЮЌЫЙећКЯСЫММЪѕЪЪХфФЃаЭЃЈTask
techfitЃЌTTFЃЉЁЂРэадааЮЊРэТл(Theory of Reasoned ActionЃЌTRAЃЉЁЂМЦЛЎааЮЊРэТл(Throry
of Planned BehaviorЃЌTPB)ЁЂДДаТРЉЩЂРэТл(InnovationDiffusionTheoryЃЌIDT)ЁЂЩчЛсШЯжЊРэТл(SocialCongnitive
TheoryЃЌSCT)ЁЂPCРћгУФЃаЭ(Model of PCU tilizationЃЌMPCU)ЁЂИДКЯ
ЃдЃСЃЭЃІЃдЃаЃТФЃаЭ(Combined TAM and TPBЃЌC&TAM&TPB)ЁЂЖЏЛњФЃаЭ(Motivational
modelЃЌMM)ЃЌЬсСЖГіСЫЫФИіКЫаФБфСПКЭЫФИіПижЦБфСПЁЃ
ЫФИіКЫаФБфСПЪЧЃКХЌСІЦкЭћ(Effort Expectancy)ЁЂМЈаЇЦкЭћ(PerformanceExpectancy)ЁЂЩчЛсгАЯь(Social
influence)КЭБуРћЬѕМў(Facilitating Condition)ЁЃ
ЫФИіПижЦБфСПЪЧЃКФъСфЁЂадБ№ЁЂОбщКЭзддИадЁЃ
ШчЯТЭМЫљЪОЃК
дкашЖрДѓГЇЕФВњЦЗОРэжаОГЃВЩгУUTAUTФЃаЭРДзіОЋзМЭЦМіФЃаЭвђзгЗжЮіЁЃвђЮЊУПвЛИіЭјТчгУЛЇЕФЩњЛюЙьМЃЖМБЛЛЅСЊЭјжвЪЕЕиМЧТМзХЃЌЭјТчЗўЮёЩЬзЅШЁгыЭкОђСЫетаЉЙьМЃЃЌаЮГЩЁАЪ§ОнКлМЃЁБЃЌПАГЦЁАДѓЪ§ОнЁБЁЃ
ИљОнетаЉДѓЪ§ОнЃЌВњЦЗдЫгЊПЩвдЖдЯћЗбепЕФаЫШЄАЎКУЁЂЙКТђааЮЊНјааПЦбЇЕФЗжЮіКЭдЄВтЃЌЭИЙ§ДѓЪ§ОневЕНЩЬвЕМлжЕЃЌДгЖјЯђЯћЗбепНјааОЋзМЖЈЯђЭЦМіЁЃЫфШЛВњЦЗдЫгЊРћгУДѓЪ§ОнЪЕЪЉОЋзМЭЦМіКѓЃЌДѓЗљЬсЩ§СЫгЊЯњаЇЙћЃЌИФБфСЫЦѓвЕЁАжЊЯўРЫЗбСЫ50%ЕФЙуИцЗбЃЌШДВЛжЊЯўФФ50%БЛРЫЗбЁБЕФоЯоЮОжУцЃЌЕЋдЫгЊЕФОЋзМЭЦМіВЛНіИјгУЛЇДјРДСЫЁАШЗЪЕЯывЊЕФЖЋЮїЁБЃЌвВДјРДСЫРЌЛјаХЯЂЁЂЮогУаХЯЂЃЌМШИјгУЛЇДјРДСЫБуРћгждьГЩСЫРЇШХЁЃ
вђДЫЃЌВњЦЗдЫгЊгУДѓЪ§ОнОЋзМЭЦМіаХЯЂЭЦЫЭЕФНсЙћЪЧЃЌВЂВЛЪЧЫљгаНгДЅЕНОЋзМЭЦМіаХЯЂЕФгУЛЇЖМЛсНгЪмВЂВЩШЁЙКТђВњЦЗЕФааЖЏЁЃЯћЗбепЖдДѓЪ§ОнОЋзМЭЦМіЕФНгЪмвтдИЕФгАЯьвђЫигаФФаЉЃПUTAUTФЃаЭЛиД№СЫвЛВПЗжЃЌЕЋЪЧвВВЛГфзуЁЃ
дРДЕФUTAUTФЃаЭдкЪБЯТЕФВњЦЗдЫгЊашЧѓжаЮЪЬтШчЯТЃК
ЦфвЛЃЌUTAUTФЃаЭЖдБуРћЬѕМўвРРЕеМОн1/4етЪЧЮоБивЊЕФЃЌвђЮЊВњЦЗдЫгЊгУДѓЪ§ОнОЋзМЭЦМіЪЧЭЈЙ§ЪжЛњЖЬаХЁЂЕчзггЪМўЙуИцЁЂЫбЫїв§ЧцЁЂИіадЛЏв§ЧцЭЦМіЁЂУХЛЇЭјеОЁЂЮЂаХЁЂЮЂВЉЁЂОКМлХХУћЫбЫїЁЂЙиМќДЪЫбЫїЙуИцЁЂЕуИцЁЂеИцЕШЙЄОпЯђЯћЗбепНјааОЋзМаХЯЂЭЦЫЭЕФЃЌЖјЕБНёЩчЛсЃЌжЧФмЪжЛњКЭ
PCЛњвбОНјШыЧЇМвЭђЛЇЃЌЫљвдЯћЗбепПЩвдНшжњжЧФмЪжЛњКЭ PCЛњНгЪеЦѓвЕЯђздМКЭЦЫЭЕФОЋзМгЊЯњаХЯЂЃЌБуРћадВЛДцдкЮЪЬтЁЃ
ЦфЖўЃЌЙ§гквРРЕФъСфНсЙЙвђЫиЃЌЮвЙњЭјУёЕФФъСфНсЙЙвРШЛЦЋЯђФъЧсЃЌвд10~39ЫъШКЬхЮЊжїЃЌеМећЬхЕФ72.1%ЁЃвђДЫЃЌВњЦЗЕФДѓЪ§ОнОЋзМгЊЯњЕФжївЊЖдЯѓвдФъЧсШЫЮЊжїЁЃ
ЦфШ§ЃЌИјгшадБ№вђзгЕФБШжиЙ§ИпЃЌдкЮвЕФаТAI-UTAUTФЃаЭжаЪЧШЈжиНЕЕЭЕФЃЌдвђЪЧгЩгкВњЦЗдЫгЊДѓЪ§ОнОЋзМЭЦМіЕФЬиЕуЪЧдкКЯЪЪЕФЪБМфЁЂКЯЪЪЕФЕиЕуЃЌЦОНшКЯЪЪЕФУННщЃЌЭЈЙ§КЯЪЪЕФЧўЕРЃЌНЋКЯЪЪЕФЩЬЦЗЯњЪлИјКЯЪЪЕФЯћЗбепЃЌвђДЫЃЌжЛвЊЦѓвЕДѓЪ§ОнЭЦЫЭЕФаХЯЂЪЧОЋзМЕФЃЌЮоТлФаХЎЃЌНдФмНгЪмЁЃ
ЖўЁЂДДаТЕФAI-UTAUTФЃаЭ-вдAIаТСуЪлЦѓвЕЮЊР§
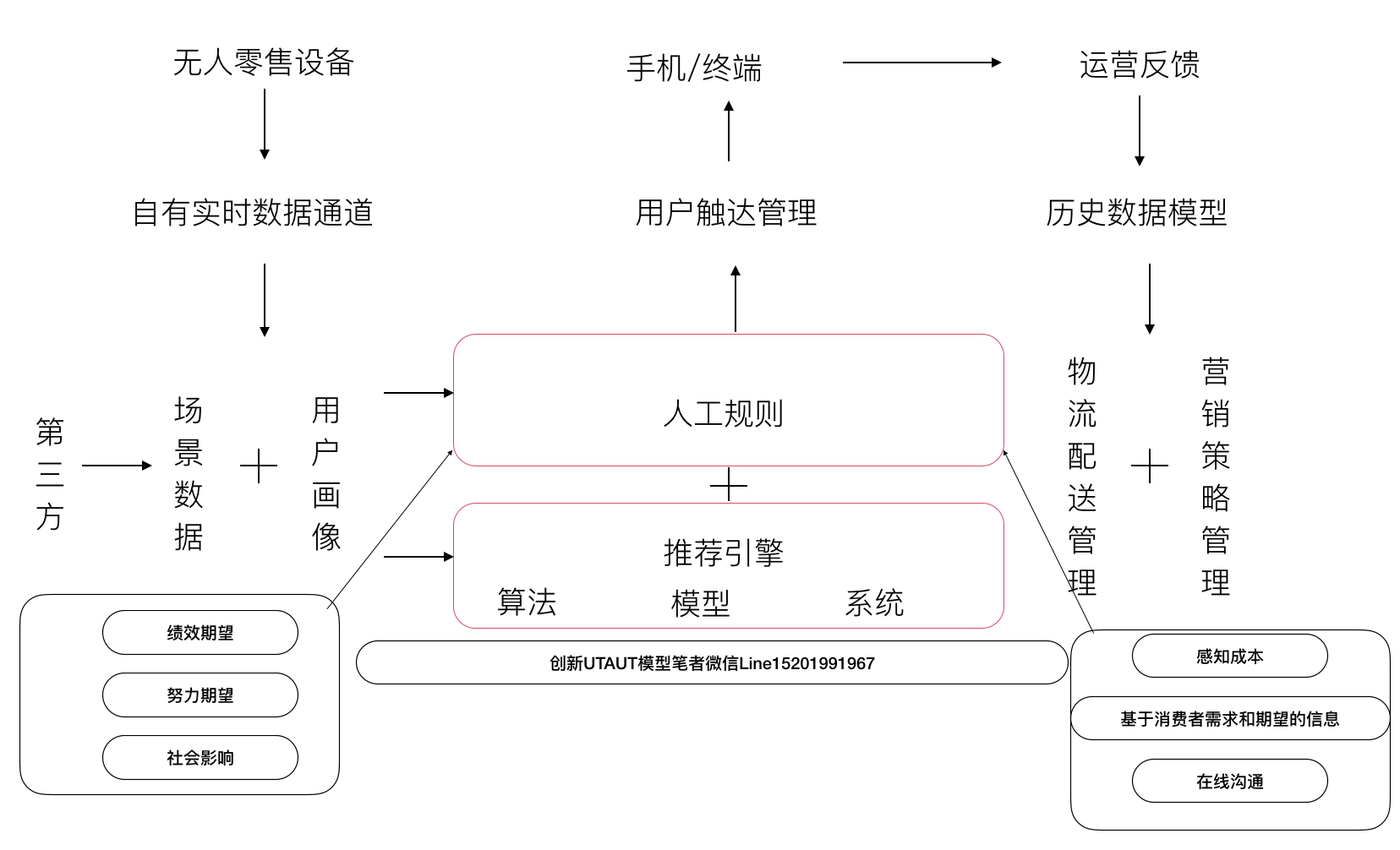
ЯШНщЩмвЛЯТЭЖзЪЕФетМвЦѓвЕЕФВњЦЗаЮЬЌЃЌетМвЦѓвЕгаЯпЯТВПЗжжАФмСуЪлЕъЃЌвВгаЯпЩЯВПЗжШэМўВњЦЗАќКЌЃЌаЁГЬађAPPЁЂERPЁЂCRMЕШЯЕЭГВњЦЗЁЃЬиБ№НщЩмвЛЯТетМвВњЦЗЕФГЁОАЪЧдкЕиЬњКЭЕиЬњеОИННќЕФДѓаЭShoppingMallЁЃгУЛЇжївЊЪЧОгзЁЙЄзїдкГЧЪаЕФАзСьЮЊжїЁЃ
ОЋзМЭЦМіЕФФПБъЪЧЃКгУздгаЕФгУЛЇЮЊЛљДЁЪ§ОнбЕСЗЫуЗЈФЃаЭЃЌетИіФЃаЭЪЧЕБгУЛЇЕНДяФГИіаЫШЄЕуЮЛИННќЪБПЩвдОЋзМЮЊЦфЯЃЭћЫбЫїЕНЕФЦЗХЦЧЁЧЩдЫгУЯЕЭГЭЦМігУЛЇИааЫШЄЕФЦЗХЦЃЌетИіФЃаЭднЪБУќУћЮЊAILBAЁЃ
1. ФЃаЭЙЙНЈ
РћгУAIММЪѕећКЯUTAUTФЃаЭгы4CРэТлЕФНгЪмвтдИгАЯьвђЫиФЃаЭЃЌЫфШЛUTAUTФЃаЭБЛЦеБщЕигІгУгкММЪѕНгЪмвђЫиЕФбаОПЃЌЕЋЖдгкДѓЖрЪ§ЪЕМЪЧщПіЯТЁЊЁЊЁЊгУЛЇЖдДѓЪ§ОнОЋзМЭЦМіЕФНгЪмвтдИЕФгАЯьвђЫиЃЌЦфВЛНіЪмФЃаЭжавђЫиЕФгАЯьЃЌЛЙЪмЯћЗбепашЧѓЪЧЗёЕУвдТњзуЕФгАЯьЁЃ
вђДЫЃЌдкФЃаЭЩшМЦЙ§ГЬжаЃЌЮвЮЊЫљЭЖзЪЕФЦѓвЕВњЦЗДюНЈСЫAIММЪѕЮЊв§ЧцвдUTAUTФЃаЭЮЊПђМмЃЌНсКЯ4CРэТлЃЌМгвдаоИФЃЌЙЙНЈећКЯСЫAI-UTAUTФЃаЭвдЦкД§ИУФЃаЭОЋзМЕФЮЊгУЛЇЭЦМіЗћКЯЯћЗбепашЧѓЕФВњЦЗЁЃФЃаЭШчЯТЭМЃК
2. ФЃаЭНтЪЭ
ИУФЃаЭжївЊЙЄзїеОЪЧЭЦМів§ЧцКЭШЫЙЄЙцдђЃЌЭЦМів§ЧцжаЫљгУЕФЫуЗЈНЋдкЯТвЛИіЖЮТфИљОнЫуЗЈЕФЙІФмЯрЫЦадвЛНкРяУцЯИНВЁЃ
ГЁОАЪ§ОнЪЧжИгУЛЇЫљДІЕФЛЗОГР§ШчгУЛЇИеИеЯТЕиЬњЃЌгУЛЇИеИедкФГИіЙКЮяжааФФГМвЕъгаЙ§ЯћЗбЙ§ФГИіЩЬЦЗAЃЌИљОнЩЯЦЊНВЪіЕФНЛВцЙиСЊЯњЪлПЩвдЮЊгУЛЇЭЦМіЙиСЊЩЬЦЗBЁЃ
гУЛЇЛЯёШЫШЫЖМдкЫЕЃЌгУЛЇЛЯёЙѓдкзМЁЃ
ЙувхЩЯЃЌЁБ гУЛЇЛЯё ЁБ жИЕФЪЧЦѓвЕДгИїИіЧўЕРЪеМЏгУЛЇаХЯЂЃЌдйИљОнЫљЛёаХЯЂЖдгУЛЇНјааШЫИёЛЏЗжЮіЃЌАќРЈШЫПкЪєадЁЂаЫШЄАЎКУЁЂЙКЮяЦЋКУЁЂЩчНЛЪєадЕШЕШЃЌЮЊУПвЛЮЛгУЛЇДђЩЯзЈЪєБъЧЉЁЃ
гУЛЇЛЯёЕФЗжЮіЮЌЖШЃК
ЦфвЛЁЂШЫПкЪєадЃК
ЕигђЁЂФъСфЁЂадБ№ЁЂЮФЛЏЁЂжАвЕЁЂЪеШыЁЂЩњЛюЯАЙпЁЂЯћЗбЯАЙпЕШ;
ЦфЖўЁЂВњЦЗааЮЊЃК
ВњЦЗРрБ№ЁЂЛюдОЦЕТЪЁЂЭЃСєЪБМфЁЂЮЪЬтзЩбЏЁЂВњЦЗЯВКУЁЂВњЦЗЧ§ЖЏЁЂЪЙгУЯАЙпЁЂВњЦЗЯћЗбЕШ;
гУЛЇЛЯёЖдОЋзМЭЦМіЕФКУДІЃЌЫцзХвЦЖЏЛЅСЊЭјЕФЗЂеЙЃЌИїРрЪжЛњгІгУЕФЦЕЗБЪЙгУЃЌгУЛЇЕФЪБМфдНРДдНЧїгкЫщЦЌЛЏЃЌИїЮЌЖШЕФаХЯЂвВИќЗсИЛЃЌвЦЖЏгІгУПЊЗЂепУЧвВДгвдММЪѕЮЊжааФЕФВњЦЗЩшМЦНЅНЅзЊЯђСЫвдгУЛЇЮЊжааФЁЃ
ЖдгУЛЇЕФОЋзМЛЯёЃЌвЛЗНУцПЩвдКмКУЕиУшЪігУЛЇЕФаэЖрЬиеїЃЌгажњгкВњЦЗШЫдБеЙПЊеыЖдадЕФЩшМЦВњЦЗ;СэвЛЗНУцЃЌЖддЫгЊШЫдБПЊеЙОЋзМЛЏгЊЯњЁЂИіадЛЏЭЦМівВЦ№ЕНСЫжСЙиживЊЕФзїгУЁЃ
ШчНёЃЌЁБгУЛЇЛЯёЁББЛдНРДдНЖрЕФЬИМАЃЌЫќЪЧВњЦЗОРэЁЂдЫгЊепУЧНђНђРжЕРЕФБІБДЁЃзїЮЊЯњЪлдБУЧЯВАЎЕФвЛПюЙЄОпЃЌЮвУЧРДПДПДЮвЫљЭЖзЪЦѓвЕШЫЙЄжЧФмЭЦМів§ЧцЪЧШчКЮНјаагУЛЇЛЯёЃЌАяжњЦѓвЕЪЕЯжОЋзМгЊЯњЕФЁЃ
ЦѓвЕЙмРэепЛђЯњЪлШЫдБНшжњЮвДюНЈЕФAI-UTAUTФЃаЭЃЌБуФмЙЛЪЕЪБЛёШЁПЭЛЇЕФаХЯЂКЭааЮЊЙьМЃЃЌАќРЈЫћУЧЕФЛљБОЬиеїЁЂСЊЯЕЗНЪНЃЌЫћУЧфЏРРЙ§ФФИівГУцЃЌЫћУЧЯВЛЖЕуЛїЁЂЗжЯэдѕбљЕФФкШнЃЌЫћУЧЛсзЩбЏЪВУДбљЕФЮЪЬтЁЃ
AI-UTAUTФЃаЭЛЙФмЪЕЪБАбПЭЛЇЕФааЮЊгыЯњЪлдБНјааЙиСЊЃЌР§ШчвЛЕЉМрВтЕНПЭЛЇЕуЛїаЁГЬађжаЕФШЮКЮвГУцЃЌМДЛсЭЈжЊЯњЪлШЫдБЃЌАяжњЯњЪлЛёШЁЧБдкПЭЛЇЃЌЪЕЯжБъЧЉЛЏЙмРэЁЃЯњЪлдБЛЙПЩвдгыПЭЛЇЗЂЮЂаХЯћЯЂЃЌЖјЧвЮоашМгКУгбЁЂВЛгУЬјзЊЃЌМДПЩЫцаФЪЕЯжЁЃ
ИљОнПЭЛЇЕФааЮЊЗжЮі,AI-UTAUTФЃаЭдЫгУЖРЬиЕФШЫЙЄжЧФмЫуЗЈ,ПЩвдздЖЏЩњГЩГЩНЛМИТЪдЄВт,вдТЉЖЗЭМЕФаЮЪНЃЌАбПЭЛЇАДееГЩЙІТЪгЩИпЭљЕЭХХ,ШУЯњЪлдБвЛблБуФмжЊЕРЫВХЪЧЧБдкгУЛЇЃЌБмУтЯњЪлШЫдБЖрзіЮогУЙІЁЃ
Р§ШчЃЌФГЦћГЕ4SЕъЯњЪлдБаЁЭѕжмвЛЩЯЮчЕНДяЙЋЫОКѓЃЌЕквЛМўЪТОЭЪЧДђПЊздМКЕФЮЂаХЃЌетЪБЫћПДЕНAI-UTAUTФЃаЭжњРэвбОЭЦЫЭСЫМИЪЎЬѕЯњЪлЯпЫїЁЃЕБЫћЕуПЊЁБПЭЛЇЁБ,ПЩвдВщПДAIЫљЗжЮіЕФдЄМЦГЩЙІТЪ,ВЂЧвЯЕЭГвбОздЖЏАДГЩЙІТЪИпЕЭХХГіПЭЛЇЕФгХЯШМЖЁЃ
етЪБЯЕЭГЯдЪОвЛЮЛНаАЂСЋЕФХЎЪПЕФдЄМЦГЩНЛТЪдк85%,Ы§СєбдбЏЮЪФГПюSUVЪЧЗёгаИќНєДеЕФаЭКХ,аЁЭѕСЂТэНјааЛиИДЁЃ5ЗжжгКѓ,ЫћЕФЪжЛњСхЩљЯьЦ№,РДЕчЯдЪОе§ЪЧАЂСЋЁЃЖЬЖЬ5ЗжжгЃЌвЛБЪ20ЭђвдЩЯЕФвЕЮёОЭБЛЧУЖЈСЫЁЃ
ДЫЭтЃЌгУЛЇЛЯёГ§СЫдкЙЕЭЈКЭЪЖБ№ПЭЛЇЗНУцгаАяжњЭтЃЌЛЙФмЖдЮЌЯЕРЯПЭЛЇКЭДйНјЖўДЮзЊЛЏЃЌЗЂЛгИќЖрМлжЕЁЃ
Р§ШчЃЌЮвУЧЛЙПЩвддкAI-UTAUTКѓЬЈбЁШЁвЛХњгУЛЇЕФФГаЉЪєадЃЌзівЛаЉдЄВтЙІФмЃЌР§ШчдЄВтгУЛЇЪЧЗёЛсСїЪЇ;ЛђепдЄВтгУЛЇЪЧЗёЛсЖдаТЩЯЯпЕФЙІФмИааЫШЄЁЃЖдгІЕФЃЌдЄВтГіКмПЩФмЛсСїЪЇЕФгУЛЇЃЌеыЖдадНјааЭьСєЕФгЊЯњЛюЖЏЃЌБШШчЗЂКьАќЁЂЗЂгХЛнШЏЕШЁЃеыЖдЛсЖдаТЙІФмИааЫШЄЕФгУЛЇЃЌПЩвдИјЦфЭЦЫЭаТЙІФмЃЌРДдіМггУЛЇЕФеГадЁЃ
ЮвЫљДюНЈЕФAI-UTAUTФЃаЭдкЫљЭЖзЪЕФетМве§КУНтОіСЫдРДЩЬМвЕФгХЛнШЏЪЙгУТЪЕЭЁЂгУЛЇеГадЕЭЕФЮЪЬтЁЃ
злКЯРДПДAI-UTAUTФЃаЭВЛНіНіАяЮвЫљЭЖзЪЕФетМвЦѓвЕЕФЯњЪлЖюЬсЩ§ЃЌЭЌЪБетЬзФЃаЭЫуЗЈвВЮЊжмБпЕФЩЬМвНјааСЫИГФмЁЃР§ШчЩЯЮФжаЫљОйЕФР§згИГФм4SЕуЯњЪлШЫдБИќКУЕФЗўЮёПЭЛЇЕФР§згЁЃ
Ш§ЁЂAI-UTAUTФЃаЭЩюЖШНтЮі 1. ФЃаЭжаЕФМЈаЇЦкЭћвђЫи
МЈаЇЦкЭће§ЯђгАЯьЯћЗбепНгЪмЦѓвЕДѓЪ§ОнОЋзМЭЦМівтдИЪЧвђЮЊЯћЗбепНгЪмЦѓвЕДѓЪ§ОнОЋзМЭЦМіЕФаХЯЂгаПЩФмЬсИпЦфаХЯЂЫбЫїЕФаЇТЪЁЃЦѓвЕвЊЭЦЫЭЧаЪЕТњзуЯћЗбепашЧѓЕФаХЯЂЃЌЦѓвЕОЭБиаызіКУЯћЗбепЛЯёЕФЪЖБ№ЙЄзїЃЌЭъЩЦЪ§ОнЗжЮіЭЦМіФЃаЭЃЌМАЪБИљОнЯћЗбепЖрдЊЁЂЖЏЬЌЁЂВЛПЩГжајЕФашЧѓНјааЪ§ОнЭЦМіФЃаЭЕФЭъЩЦКЭаое§ЃЌзіКУЯћЗбепЛЯёЬиеїЗжЮіЙЄзїЃЌБЃжЄЯђЯћЗбепЭЦЫЭЕФаХЯЂЪЧЯћЗбепашЧѓЕФЃЌецеце§е§ЕиЬсИпЯћЗбепаХЯЂЫбЫїЕФаЇТЪЁЃ
2. ФЃаЭжаЕФЛљгкЯћЗбепашЧѓКЭЦкЭћЕФаХЯЂЗНУц
ЛљгкЯћЗбепашЧѓКЭЦкЭћЕФаХЯЂе§ЯђгАЯьЯћЗбепНгЪмЦѓвЕДѓЪ§ОнОЋзМЭЦМівтдИЪЧвђЮЊЛљгкЯћЗбепашЧѓКЭЦкЭћЕФаХЯЂЪЧЪЪЕБЕФЁЂзМШЗЕФЁЂгажЪСПЕФаХЯЂЁЃЦѓвЕвЊИљОнЯћЗбепОфЏРРЁЂЗУЮЪЁЂЙКТђаЮГЩЕФИїЪНДѓЪ§ОнНјааЯИжТЗжЮіЃЌЖДВьЯћЗбепЕФЯдадашЧѓКЭЧБдкашЧѓЃЌзіКУЯћЗбепВњЦЗЯВКУЁЂаФРэНгЪмМлЮЛЁЂВњЦЗЦЗХЦЕШаХЯЂЕФдЄВтЃЌМАЪБЕивдКЯЪЪЕФЗНЪНЃЌдкКЯЪЪЕФЪБМфЃЌНЋКЯЪЪЕФВњЦЗаХЯЂЭЦЫЭИјЯћЗбепЃЌЬсИпЯћЗбепКЭВњЦЗЕФЦЅХфЖШЃЌЬсИпЯћЗбепзЊЛЏТЪЁЃ
3. ФЃаЭжадкЯпМАЪБЙЕЭЈЗНУц
дкЯпЙЕЭЈе§ЯђгАЯьЯћЗбепНгЪмЦѓвЕДѓЪ§ОнОЋзМгЊЯњвтдИЪЧвђЮЊдкЯпЙЕЭЈФмЫѕЖЬЯћЗбепгыЦѓвЕШЫдБЕФЙЕЭЈОрРыЃЌдкБмУтЯђЯћЗбепЕЅЯђЭЦЯњЃЌСюЯћЗбепЗДИаЕФЭЌЪБЃЌЛЙПЩвдШУЯћЗбепЛЅЯрСЫНтЙККѓИаЪмЃЌНЕЕЭаХЯЂВЛЖдГЦИјЯћЗбепДјРДЕФИКУцгАЯьЕФИХТЪЁЃ
ЦѓвЕвЊДюНЈгЊЯњШЋЙ§ГЬЕФЯћЗбепВЮгыЛЅЖЏЦНЬЈЁЃЦѓвЕПЩЭЈЙ§ЮЂВЉЁЂЮЂаХгыЯћЗбепНјааЛЅЖЏЃЌвВПЩЭЈЙ§ЩшжУЩЬЦЗЦРМлЧјЁЂЬжТлЧјШУЯћЗбепСєбдЃЌдкМАЪБСЫНтЯћЗбепЖдЦѓвЕВњЦЗЛђЗўЮёЦРМлЕФЭЌЪБЃЌвВПЩЮЊЦѓвЕВњЦЗЛђЗўЮёгЊдьСМКУЕФПкБЎЁЃ
ЕБШЛЃЌЯћЗбепЖдЦѓвЕЕФВњЦЗЛђЗўЮёВЛТњвтЪБЃЌвВПЩЭЈЙ§ЛЅЖЏЦНЬЈМАЪБЗДРЁЃЌЦѓвЕвВПЩМАЪБДІРэЃЌНЕЕЭВЛСМПкБЎЖдЦѓвЕЕФгАЯьЁЃЦѓвЕЛЙПЩЙФРјЯВЛЖЙККѓЗжЯэЁЂгаЙЋжкгАЯьСІЕФЯћЗбепНјааЗжЯэЃЌвдЦкДјЖЏЦфЫћЯћЗбепбЁдёЦѓвЕЕФВњЦЗЛђЗўЮёЁЃ
ЮвРћгУAI-UTAUTФЃаЭЫљИГФмЕФЕиЬњаТСуЪлЦѓвЕЦьЯТЕФвЛРрЪЧжЧФмЗЗЪлЛњЃЌЮвНЈвщГЇМвдкЛњЦїЩЯАВзАвЛМќдкЯпЙЕЭЈЙІФмЃЌОЭЪЧЮЊСЫЩЯЪідвђЁЃ
ЦѓвЕдкПЊеЙОЋзМЭЦМіЕФЙ§ГЬжаЃЌШєЦѓвЕШЫдБФмгыЯћЗбепНјааЙЕЭЈЃЌОЭПЩНЋЕЅЯђДйЯњзЊЛЛЮЊЁАЛЅЖЏЁЂЫЋгЎЁЂЙиСЊЙиЯЕЁБЕФЙЕЭЈЃЌзюДѓЛЏЕиЫѕЖЬСЫЦѓвЕКЭЯћЗбепМфЕФЙЕЭЈОрРыЃЌБмУтвЛЮЖЕиЯђЯћЗбепНјааЕЅЯђЭЦЯњЃЌдкЮоЗЈДЅМАЯћЗбепашЧѓЕуЕФЧщПіЯТЃЌЪЙЯћЗбепВњЩњЗДИаЁЂЕжДЅЕФЧщаїЁЃ
ЕБШЛЃЌЦѓвЕПЊеЙЕФДѓЪ§ОнОЋзМЭЦМіВЂВЛЪЧвЛДЮадЕФЛюЖЏЃЌЖјЪЧвЛИібЛЗЭљИДЕФЙ§ГЬЃЌЦѓвЕШЫдБдкгыЯћЗбепжмЖјИДЪМЕФЙЕЭЈжаФмВЛЖЯЕиЪеМЏЯћЗбепЕФаХЯЂЃЌЖдздЩэЕФОЋзМЭЦМіФЃаЭЫуЗЈВЛЖЯЕїећКЭгХЛЏЃЌНјЖјЬсЩ§ЯћЗбепНгЪмЦѓвЕДѓЪ§ОнОЋзМЭЦМіЕФвтдИЃЌЬсЩ§ЖдЦѓвЕВњЦЗЛђЗўЮёЕФЙКТђвтдИЁЃ
ЫФЁЂЩшМЦAI-UTAUTФЃаЭЪБЫљбаОПЙ§ЕФЫуЗЈФЃаЭ
ЫуЗЈФЃаЭдкЁЖAIВњЦЗОРэДгЖЎОЋзМЭЦМіФЃаЭЕНВњЦЗДДаТЁЗЩЯЦЊжаАДAIЛњЦїбЇЯАЗчИёНјааЙ§ЗжРрЃЌепЯТЦЊжаЮвУЧНЋАДЙІФмЯрЫЦадНВНтЫуЗЈФЃаЭЃЌетРяЫљНВНтЕФФЃаЭЫуЗЈЪЧЮвдкДДдьAI-UTAUTФЃаЭЙ§ГЬжаЖрЪ§МьбщЙ§ЕФЁЃЫљвддкНВНтЫуЗЈФЃаЭЕФЪБКђЛсзмНсФФаЉЫуЗЈФЃаЭгУдкФФИіГЁОАБШНЯЖрЃЌФФаЉЫуЗЈФЃаЭЪЧAIВњЦЗОРэОГЃЛсгіЕНЕФЁЃ
гЩЙІФмЕФЯрЫЦадЗжзщЕФЫуЗЈФЃаЭШчЯТЃК
ЛњЦїбЇЯАЫуЗЈЭЈГЃИљОнЦфЙІФмЕФЯрЫЦадНјааЗжзщЁЃР§ШчЃЌЛљгкЪїЕФЗНЗЈвдМАЩёОЭјТчЕФЗНЗЈЁЃЕЋЪЧЃЌШдгаЫуЗЈПЩвдЧсЫЩЪЪгІЖрИіРрБ№ЁЃШчбЇЯАЪИСПСПЛЏЃЌетЪЧвЛИіЩёОЭјТчЗНЗЈКЭЛљгкЪЕР§ЕФЗНЗЈЁЃ
дкЖСепдФЖСБОЖЮЮФзжЕФЪБКђШчЙћгааЉЪєгкВЛЬЋЪьЯЄЃЌЛђепгааЉФЃаЭЫуЗЈЬ§ЕНЕФБШНЯЩйЧыВЛгУЕЃаФЃЌвЛЗНУцПЩФмЪЧетРрЫуЗЈФЃаЭвдКѓвВКмКУгУЃЌШчЙћашвЊгУЕНЕФЛАЃЌЕНЪБКђдйеыЖдадЕФбЇЯАетРрЫуЗЈФЃаЭвВВЛГйЁЃСэЭтвЛЗНУцЮвЛсОЁСПжИУїетаЉЫуЗЈгІгУЕФГЁОАЁЃ
1. ЛиЙщЫуЗЈ
ЛиЙщЫуЗЈЩцМАЖдБфСПжЎМфЕФЙиЯЕНјааНЈФЃЃЌЮвУЧдкЪЙгУФЃаЭНјааЕФдЄВтжаВњЩњЕФДэЮѓЖШСПРДИФНјЁЃетаЉЗНЗЈЪЧЪ§ОнЭГМЦЕФжїСІЃЌЫљвдЛиЙщЫуЗЈгжГЦЮЊЛиЙщЗжЮіЁЃДЫЭтЃЌЫќУЧвВвбБЛбЁШыЭГМЦЛњЦїбЇЯАЁЃ
ГЃгУЕФЕФЛиЙщЫуЗЈЪЧЃК
ЦеЭЈзюаЁЖўГЫЛиЙщЃЈOLSRЃЉЃЛ
ЯпадЛиЙщЃЛ
LogisticЛиЙщЃЛ
ж№ВНЛиЙщЃЛ
ЖрдЊздЪЪгІЛиЙщбљЬѕЃЈMARSЃЉЃЛ
ОжВПЙРМЦЕФЩЂЕуЭМЦНЛЌЃЈLOESSЃЉЃЛ
гУЭОГЁОАЃКдЄВтЮДРДЃЌдЄВтЯњСПЕШЕШЁЃ
Р§згЃКШчЯТЭМЃКЕБвЛЬьжадчИпЗхЛђепЭэИпЗхЕФЪБКђЪЕМЪЩЯЪЧЩЬГЁРяУцЕФЦЗХЦЩЬЯњСПМѕЩйЕФЪБКђЃЌетвЛЕуПЩвдЭЈЙ§ЮвЕФAI-UTAUTФЃаЭЪ§ОнЪЕжЄЁЃ

2. ЛљгкЪЕР§ЕФЫуЗЈ
ИУРрЫуЗЈЪЧНтОіЪЕР§бЕСЗЪ§ОнЕФОіВпЮЪЬтЁЃетаЉЗНЗЈЙЙНЈСЫЪОР§Ъ§ОнЕФЪ§ОнПтЃЌЫќашвЊНЋаТЪ§ОнгыЪ§ОнПтНјааБШНЯЁЃЮЊСЫБШНЯЃЌЮвУЧЪЙгУЯрЫЦадЖШСПРДевЕНзюМбЦЅХфВЂНјаадЄВтЁЃГігкетИідвђЃЌЛљгкЪЕР§ЕФЗНЗЈвВГЦЮЊгЎепЭЈГдЗНЗЈКЭЛљгкМЧвфЕФбЇЯАЃЌжиЕуЗХдкДцДЂЪЕР§ЕФБэЪОЩЯЁЃвђДЫЃЌдкЪЕР§жЎМфЪЙгУЯрЫЦадЖШСПЁЃ
ГЃгУЕФЛљгкЪЕР§ЕФЫуЗЈЪЧЃК
k-зюНќСкЃЈkNNЃЉЃЛ
бЇЯАЪИСПСПЛЏЃЈLVQЃЉЃЛ
здзщжЏЬиеїгГЩфЃЈSOMЃЉЃЛ
БОЕиМгШЈбЇЯАЃЈLWLЃЉЃЛ
е§дђЛЏЫуЗЈЃЛ
гУЭОГЁОАЃКЩЬЦЗЩЯаТЫЋ11ЧАЯІИпДяЧЇЭђМЖЁЃвђЮЊЕкШ§ЗНPOPЩЬЦЗЩЯаТУЛгаШЫЙЄЩѓКЫЛЗНкЃЌЩЬЛсгавтЁЂЮовтЕиНЋЩЬЦЗЗЂВМЕНДэЮѓРрФПЃЌИќгаЩѕепЃЌВПЗжЩЬМвВЩгУХњСПЩЯаТКЭХњСПАсМвЙЄОпЃЌЕМжТДѓЙцФЃДэЙвЩЬЦЗЕФГіЯжЃЌВЛЖЯГхЛїзХЩЬЦЗЩњЬЌЗРЯпЃЌгАЯьгУЛЇЙКЮяЬхбщЃЌВЂДјРДСЫжюШчЪГЦЗЁЂвЉЦЗКЭГЩШЫгУЦЗЕШЯрЙиЕФвЛЯЕСаМрЙмЗчЯеЁЃ
УцЖдКЃСПМЖЕФЩЬЦЗЪ§ОнКЭИпДяЩЯЧЇИіРрФПЕФЩЬЦЗВуМЖЗжРрЬхЯЕЃЌШчКЮВХФмгааЇХаБ№ЩЬЦЗРрФПЙвППЕФе§ШЗгыЗёЃЌЪЕЯжШЋЗНЮЛКЭИпаЇЕФМрПиЁЃ
дкЩЬЦЗРрФПдЄВтетИіЮЪЬтЩЯЃЌКмЖрЕчЩЬЙЋЫОдкЙ§ШЅЕФ10ФъРявЛжБдкВЛЖЯЬНЫїКЭИФНјЃЌЙЋПЊзЪСЯЯдЪОЃЌЕчЩЬОоЭЗeBayЯШКѓВЩгУСЫДЋЭГЕФЙцдђКЭЭГМЦЕШФЃаЭЁЂШчKNNЁЂKNN+SLMКЭDNNМИжжЗНЗЈЃЌзМШЗТЪДгзюГѕЕФ50%вЛВНВНЬсИпЕНСЫ90%+ЁЃ
3. ОіВпЪїЫуЗЈ
ОіВпЪїЗНЗЈгУгкЙЙНЈОіВпФЃаЭЃЌетЪЧЛљгкЪ§ОнЪєадЕФЪЕМЪжЕЁЃОіВпдкЪїНсЙЙжаНјааЗжВцЃЌжБЕНЖдИјЖЈМЧТМзіГідЄВтОіЖЈЁЃОіВпЪїЭЈГЃПьЫйзМШЗЃЌетвВЪЧЛњЦїбЇЯАДгвЕепЕФзюАЎЕФЫуЗЈЁЃ
ГЃгУЕФЕФОіВпЪїЫуЗЈЪЧЃК
ЗжРрКЭЛиЙщЪїЃЈCARTЃЉЃЛ
ЕќДњDichotomiser 3ЃЈID3ЃЉЃЛ
C4.5КЭC5.0ЃЛ
ПЈЗНздЖЏНЛЛЅМьВтЃЈCHAIDЃЉЃЛ
ОіВпЪїзЎЃЛ
M5ЃЛ
ЬѕМўОіВпЪїЃЛ
гУЭОГЁОАЃКгавЛИіОЕфЕФАИР§ХаЖЯвЛИіЮїЙЯЪЧЗёЪЧКУЙЯОЭЪЧЕфаЭЕФОіВпЪїЫуЗЈФЃаЭЕФгІгУЁЃ
Р§згШчЯТЭМЃК

ЩЯЭМЫЕУїЃК
гавЛИізюжБЙлЕФНтЪЭЃЌШчЙћФуГдЕФДѓВПЗжЕФКУЙЯЮЦРэЖМКмЧхЮњЃЌФЧУДФуПЯЖЈЪзЯШШЅХаЖЯУцЧАЕФЙЯЮЦРэЪЧВЛЪЧЧхЮњЃЌШчЙћВЛЧхЮњФЧМЋгаПЩФмВЛЪЧКУЙЯЁЃЕЋЪЧЛЙгавЛИіЮЪЬтЃЌКУЙЯДѓЖМЮЦРэЧхЮњЃЌЕЋВЂВЛЪЧЫљгаЮЦРэЧхЮњЕФЙЯЖМЪЧКУЙЯЃЌФуашвЊМЬајИљОнЦфЫћЬиеїШЅХаЖЯЁЃ
МйЩшФуУцЧАЕФЙЯЮЦРэЧхЮњЃЌФЧУДФуЛиШЅЯыФуГдЙ§ЕФЮЦРэЧхЮњЕФКУЙЯжаЃЌЛЙгаЪВУДШУФугЁЯѓЩюПЬЕФЬиеїЃПЖдСЫЃЌФуЯыЦ№РДИљЕйђщЫѕЕФЮЦРэЧхЮњЕФЙЯЪЧДѓЖМЪЧКУЙЯЁЃ
ЩЯУцЮвУЧНВЙ§СЫдѕУДХаЖЯвЛИіЙЯЪЧКУЙЯЁЃШчЙћШУМЦЫуЛњШЅбЇЯАШчКЮХаЖЯКУЙЯЃЌФЧУДЮвУЧашвЊИјЫќКмЖрЕФбљР§ЁЃетаЉбљР§Ъ§ОнжаЃЌгаКУЙЯгаЛЕЙЯЃЌУПИібљР§ЖМИјГіСЫЙЯЕФЮЦРэЁЂИљЕйЁЂЩЋдѓЁЂДЅИаЁЂЧУЩљЕШЕШЬиеїЁЃгаСЫбљР§Ъ§ОнЃЌМЦЫуЛњШчКЮЕУЕНвЛИіЯёШЫРрХаЖЯЙ§ГЬжаЕФФЧжжЫГађХаЖЯЕФЫМТЗФиЃПД№АИОЭЪЧОіВпЪїЁЃ
4. БДвЖЫЙЫуЗЈ
етаЉЗНЗЈЪЪгУгкБДвЖЫЙЖЈРэЕФЮЪЬтЃЌШчЗжРрКЭЛиЙщЁЃ
ГЃгУЕФБДвЖЫЙЫуЗЈЪЧЃК
ЦгЫиБДвЖЫЙЃЛ
ИпЫЙЦгЫиБДвЖЫЙЃЛ
ЖрЯюЦгЫиБДвЖЫЙЃЛ
ЦНОљвЛвРРЕЙРМЦСПЃЈAODEЃЉЃЛ
БДвЖЫЙаХФюЭјТчЃЈBBNЃЉЃЛ
БДвЖЫЙЭјТчЃЈBNЃЉЃЛ
гУЭОГЁОАЃКР§ШчХаЖЯЭјТчЛЗОГЪЧЗёвьГЃЃЌЪЙгУЮоМрЖНбЇЯАЛёЕУУПИіЩшБИЁЂУПИіШЫдБЕФЭјТчааЮЊФЃЪНЃЌНсКЯааЮЊЗжЮігыИпЕШЪ§бЇЃЌдЫгУЕнЙщБДвЖЫЙЙРМЦЃЈRecursive
Bayesian EstimationЃЌRBEЃЉРэТлЃЌЬсЙЉЖдЪТМўЕФЙРМЦИХТЪВЂЫцзХаТЬиеїЕФЗЂЯжВЛЖЯИќаТЃЌздЖЏХаЖЯЭјТчааЮЊЪЧЗёДцдквьГЃЁЃ
5. ОлРрЫуЗЈ
МИКѕЫљгаЕФОлРрЫуЗЈЖМЩцМАЪЙгУЪ§ОнжаЕФЙЬгаНсЙЙЃЌеташвЊНЋЪ§ОнзюМбЕизщжЏГЩзюДѓЙВадЕФзщЁЃ
ГЃгУЕФОлРрЫуЗЈЪЧЃК
K-ОљжЕЃЛ
K-ЦНОљЃЛ
ЦкЭћзюДѓЛЏЃЈEMЃЉЃЛ
ЗжВуОлРрЃЛ
гУЭОГЁОАЃКдкгУЛњЦїзіОлРрбЇЯАЕФЪБКђЃЌЮвУЧУПжжЫуЗЈЖМЖдгІгаЯргІЕФМЦЫуддђЃЌПЩвдАбЪфШыЕФИїжжПДЩЯШЅБЫДЫЁАЯрНќЁБЕФЯђСПЗждквЛИіШКзщжаЁЃШЛКѓЯТвЛВНЃЌШЫУЧЭЈГЃИќгаеыЖдадЕиШЅбаОПУПвЛзщОлдквЛЦ№ЕФЖдЯѓЫљгЕгаЕФЙВадвдМАФЧаЉдЖРыИїИіШКзщЕФЙТСЂЕуЁЊЁЊетжжЙТСЂЕубаОПдкаЬеьЁЂЬиЪтМВВЁХХВщКЭгУЛЇШКЬхЛЎЗжЕШЗНУцЖМгагІгУЁЃ
6. ЙиСЊЙцдђбЇЯАЫуЗЈ
ЙиСЊЙцдђбЇЯАЗНЗЈЬсШЁЙцдђЃЌЫќПЩвдЭъУРЕФНтЪЭЪ§ОнжаБфСПжЎМфЕФЙиЯЕЁЃетаЉЙцдђПЩвддкДѓаЭЖрЮЌЪ§ОнМЏжаБЛЗЂЯжЪЧЗЧГЃживЊЕФЁЃ
ГЃгУЕФЙиСЊЙцдђбЇЯАЫуЗЈЪЧЃК
AprioriЫуЗЈЃЛ
EclatЫуЗЈЃЛ
гУЭОГЁОАЃКдкЁЖ AIВњЦЗОРэДгЖЎОЋзМЭЦМіФЃаЭЕНВњЦЗДДаТЁЗЩЯЦЊжаНВЪіБШНЯЖрЃЌИааЫШЄЕФЖСепПЩвдЗдФЁЃ
7. ШЫЙЄЩёОЭјТчЫуЗЈ
етаЉЫуЗЈФЃаЭДѓЖрЪмЕНЩњЮяЩёОЭјТчНсЙЙЕФЦєЗЂЁЃЫќУЧПЩвдЪЧвЛРрФЃЪНЦЅХфЃЌПЩвдБЛгУгкЛиЙщКЭЗжРрЮЪЬтЁЃЫќгЕгавЛИіОоДѓЕФзгСьгђЃЌвђЮЊЫќгЕгаЪ§АйжжЫуЗЈКЭБфЬхЁЃ
ГЃгУЕФШЫЙЄЩёОЭјТчЫуЗЈЪЧЃК
ИажЊЛњЃЛ
ЗДЯђДЋВЅЃЛ
HopfieldЩёОЭјТчЃЛ
ОЖЯђЛљКЏЪ§ЩёОЭјТчЃЈRBFNЃЉЃЛ
гУЭОГЁОАЃКЪЙгУЩёОЭјТчЫуЗЈДггУЛЇЕФздХФжаЭъГЩШЫСГЪЖБ№ЃЌВЂздЖЏПйГіТжРЊЃЌВЂИљОнБОЕиЫуЗЈЃЌНЋздХФПьЫйзЊБфЮЊЖЏЛЗчИёЛђЦфЫќздЖЈвхЗчИёЕФБэЧщАќЁЃ
8. ЩюЖШбЇЯАЫуЗЈ
ЩюЖШбЇЯАЫуЗЈЪЧШЫЙЄЩёОЭјТчЕФИќаТЃЌЭЌЪБЩюЖШбЇЯАЫуЗЈвВЪЧЛњЦїбЇЯАЕФЕфаЭДњБэЫуЗЈЁЃЫћУЧИќЙиаФЙЙНЈИќДѓИќИДдгЕФЩёОЭјТчЁЃ
ГЃгУЕФЩюЖШбЇЯАЫуЗЈЪЧЃК
ЩюВЃЖћзШТќЛњЃЈDBMЃЉЃЛ
ЩюаХбіЭјТчЃЈDBNЃЉЃЛ
ОэЛ§ЩёОЭјТчЃЈCNNЃЉЃЛ
ЖбЕўЪНздЖЏБрТыЦїЃЛ
9. ГЃгУЛњЦїбЇЯАЫуЗЈСаБэ
ЦгЫиБДвЖЫЙЗжРрЦїЛњЦїбЇЯАЫуЗЈ
гІгУГЁОАЃКЭЈГЃЃЌЭјвГЁЂЮФЕЕКЭЕчзггЪМўНјааЗжРрНЋЪЧРЇФбЧвВЛПЩФмЕФЁЃетОЭЪЧЦгЫиБДвЖЫЙЗжРрЦїЛњЦїбЇЯАЫуЗЈЕФгУЮфжЎЕиЁЃЗжРрЦїЦфЪЕЪЧвЛИіЗжХфзмЬхдЊЫижЕЕФКЏЪ§ЁЃР§ШчЃЌРЌЛјгЪМўЙ§ТЫЪЧЦгЫиБДвЖЫЙЫуЗЈЕФвЛжжСїаагІгУЁЃвђДЫЃЌРЌЛјгЪМўЙ§ТЫЦїЪЧвЛжжЗжРрЦїЃЌПЩЮЊЫљгаЕчзггЪМўЗжХфБъЧЉЁАРЌЛјгЪМўЁБЛђЁАЗЧРЌЛјгЪМўЁБЁЃЛљБОЩЯЃЌЫќЪЧАДееЯрЫЦадЗжзщЕФзюСїааЕФбЇЯАЗНЗЈжЎвЛЁЃетЪЪгУгкСїааЕФБДвЖЫЙИХТЪЖЈРэЁЃ
K-meansЃКОлРрЛњЦїбЇЯАЫуЗЈ
ЭЈГЃЃЌK-meansЪЧгУгкОлРрЗжЮіЕФЮоМрЖНЛњЦїбЇЯАЫуЗЈЁЃДЫЭтЃЌK-MeansЪЧвЛжжЗЧШЗЖЈадКЭЕќДњЗНЗЈЃЌИУЫуЗЈЭЈЙ§дЄЖЈЪ§СПЕФДиkЖдИјЖЈЪ§ОнМЏНјааВйзїЁЃвђДЫЃЌK-MeansЫуЗЈЕФЪфГіЪЧОпгадкДижЎМфЗжРыЕФЪфШыЪ§ОнЕФkИіДиЁЃ
жЇГжЯђСПЛњбЇЯАЫуЗЈ
ЛљБОЩЯЃЌЫќЪЧгУгкЗжРрЛђЛиЙщЮЪЬтЕФМрЖНЛњЦїбЇЯАЫуЗЈЁЃSVMДгЪ§ОнМЏбЇЯАЃЌетбљSVMОЭПЩвдЖдШЮКЮаТЪ§ОнНјааЗжРрЁЃДЫЭтЃЌЫќЕФЙЄзїдРэЪЧЭЈЙ§ВщевНЋЪ§ОнЗжРрЕНВЛЭЌЕФРржаЁЃЮвУЧгУЫќРДНЋбЕСЗЪ§ОнМЏЗжГЩМИРрЁЃЖјЧвЃЌгааэЖретбљЕФЯпадГЌЦНУцЃЌSVMЪдЭМзюДѓЛЏИїжжРржЎМфЕФОрРыЃЌетБЛГЦЮЊБпМЪзюДѓЛЏЁЃSVMЗжЮЊСНРрЃКЯпадSVMЃКдкЯпадSVMжаЃЌбЕСЗЪ§ОнБиаыЭЈЙ§ГЌЦНУцЗжРыЗжРрЦїЁЃЗЧЯпадSVMЃКдкЗЧЯпадSVMжаЃЌВЛПЩФмЪЙгУГЌЦНУцЗжРыбЕСЗЪ§ОнЁЃ
AprioriЛњЦїбЇЯАЫуЗЈ
етЪЧвЛжжЮоМрЖНЕФЛњЦїбЇЯАЫуЗЈЁЃЮвУЧгУРДДгИјЖЈЕФЪ§ОнМЏЩњГЩЙиСЊЙцдђЁЃЙиСЊЙцдђвтЮЖзХШчЙћЗЂЩњЯюФПAЃЌдђЯюФПBвВвдвЛЖЈИХТЪЗЂЩњЃЌЩњГЩЕФДѓЖрЪ§ЙиСЊЙцдђЖМЪЧIF_THENИёЪНЁЃ
гІгУГЁОАЃКР§ШчЃЌШчЙћШЫУЧЙКТђiPadЃЌФЧУДЫћУЧвВЛсЙКТђiPadБЃЛЄЬзРДБЃЛЄЫќЁЃAprioriЛњЦїбЇЯАЫуЗЈЙЄзїЕФЛљБОдРэЃКШчЙћЯюФПМЏЦЕЗБГіЯжЃЌдђЯюФПМЏЕФЫљгазгМЏвВОГЃГіЯжЁЃ
ЯпадЛиЙщЛњЦїбЇЯАЫуЗЈ
ЫќЯдЪОСЫ2ИіБфСПжЎМфЕФЙиЯЕЃЌЫќЯдЪОСЫвЛИіБфСПЕФБфЛЏШчКЮгАЯьСэвЛИіБфСПЁЃ
ОіВпЪїЛњЦїбЇЯАЫуЗЈ
ОіВпЪїЪЧЭМаЮБэЪОЃЌЫќРћгУЗжжЇЗНЗЈРДОйР§ЫЕУїОіВпЕФЫљгаПЩФмНсЙћЁЃдкОіВпЪїжаЃЌФкВПНкЕуБэЪОЖдЪєадЕФВтЪдЁЃвђЮЊЪїЕФУПИіЗжжЇДњБэВтЪдЕФНсЙћЃЌВЂЧввЖНкЕуБэЪОЬиЖЈЕФРрБъЧЉЃЌМДдкМЦЫуЫљгаЪєадКѓзіГіЕФОіЖЈЁЃДЫЭтЃЌЮвУЧБиаыЭЈЙ§ДгИљНкЕуЕНвЖНкЕуЕФТЗОЖРДБэЪОЗжРрЁЃ
ЫцЛњЩСжЛњЦїбЇЯАЫуЗЈ
ЫќЪЧЪзбЁЕФЛњЦїбЇЯАЫуЗЈЁЃЮвУЧЪЙгУЬзДќЗНЗЈДДНЈвЛЖбОпгаЫцЛњЪ§ОнзгМЏЕФОіВпЪїЁЃЮвУЧБиаыдкЪ§ОнМЏЕФЫцЛњбљБОЩЯЖрДЮбЕСЗФЃаЭЃЌвђЮЊЮвУЧашвЊДгЫцЛњЩСжЫуЗЈжаЛёЕУСМКУЕФдЄВтадФмЁЃДЫЭтЃЌдкетжжМЏГЩбЇЯАЗНЗЈжаЃЌЮвУЧБиаызщКЯЫљгаОіВпЪїЕФЪфГіЃЌзіГізюКѓЕФдЄВтЁЃДЫЭтЃЌЮвУЧЭЈЙ§ТжбЏУПИіОіВпЪїЕФНсЙћРДЭЦЕМГізюжедЄВтЁЃ
LogisticЛиЙщЛњЦїбЇЯАЫуЗЈ
етИіЫуЗЈЕФУћГЦПЩФмгаЕуСюШЫРЇЛѓЃЌLogisticЛиЙщЫуЗЈгУгкЗжРрШЮЮёЖјВЛЪЧЛиЙщЮЪЬтЁЃДЫЭтЃЌетРяЕФУћГЦЁАЛиЙщЁБвтЮЖзХЯпадФЃаЭЪЪКЯгкЬиеїПеМфЁЃИУЫуЗЈНЋТпМКЏЪ§гІгУгкЬиеїЕФЯпадзщКЯЃЌеташвЊдЄВтЗжРрвђБфСПЕФНсЙћЁЃ
аЁНсЃК
ЮвДюНЈЕФAI-UTAUTОЋзМЭЦМіФЃаЭгаAprioriЫуЗЈЁЂЩёОЭјТчЫуЗЈЁЂЛиЙщЫуЗЈЁЂОлРрЫуЗЈЁЂБДвЖЫЙЫуЗЈЃЌдЄВтЯњСПЕФгаЛиЙщЫуЗЈЃЌПЩвджБНгЕїгУЕФгаЭтУцГЩЪьЕФШЫСГЪЖБ№ЫуЗЈЁЂгявєЪЖБ№ЫуЗЈЕШЁЃ
ВњЦЗОРэШеГЃЙЄзїжазюГЃгУЕФЫуЗЈЪЧЃКAprioriЫуЗЈЁЂОлРрФЃаЭЁЂОіВпФЃаЭЁЂБДвЖЫЙЫуЗЈЁЂЙиСЊЙцдђЫуЗЈКЭЩюЖШбЇЯАЁЂЛњЦїбЇЯАЕШЁЃ
ЮхЁЂAIВњЦЗОРэШыУХБъзМКЭШыУХРраЭ
AIВњЦЗОРэШыУХЧАЬсЬѕМўжївЊЪЧЛљгкгаФФаЉРрБ№ЕФЦѓвЕЃЌЪБЯТКЭЮДРДЕФвЛЖЮЪБМфAIЦѓвЕжївЊгаЃК
ЕквЛРрЪЧДПДтЕФAIММЪѕЦѓвЕЃЌ
ЕкЖўРрЪЧ+AIЕФЦѓвЕЃЌ
ЕкШ§РрЪЧзлКЯаЭЦѓвЕAIзїЮЊжњЭЦЦїаЭЕФЦѓвЕЁЃ
AIВњЦЗОРэдкЕквЛРрЦѓвЕРяУцзіAIВњЦЗОРэШчЙћВњЦЗЪЧAIЫуЗЈБОЩэЃЌМДР§ШчФувЊЪфГіЕФВњЦЗЪЧШЫСГЪЖБ№ЯЕЭГЃЌетИіЪБКђашвЊAIВњЦЗОРэЖдЫуЗЈЖЎЕФвЊЩюПЬвЛаЉЃЌНЈвщМгШыДЫРрЦѓвЕЕФВњЦЗХѓгбПЩвдеыЖдадЕФВЙГфЫуЗЈжЊЪЖЁЃ
ШчЙћдкетРрЦѓвЕРяУцДгЪТЕФЪЧAI+ЕФЙЄзїЃЌФЧУДжївЊЕФжиЕуПЩвдЗХдкЮЊетРрAIЯЕЭГевЕНЪЪКЯЕФгІгУГЁОАЃЌВЂеМСьЪаГЁЯШЛњЃЌЯШбаЗЂГіРДПЩвдТфЕиЕФВњЦЗЁЃ
AIВњЦЗОРэдкЕкЖўРрЦѓвЕРяУцИќЖрЕФЪЧЛљгкаавЕОбщЃЌПДЕНаавЕФкВППЩвдБЛAIШЁДњЛђепЬсЩ§аЇТЪЕФЕуЃЌ+ЩЯAIЁЃЮЊаавЕИГФмЁЃ
ЕкШ§РрзлКЯадЦѓвЕжївЊЪЧBAT/TMDЕШДѓаЭПЦММЭјТчЙЋЫОЃЌвВАќКЌЙњгЊЦѓЪТвЕЕЅЮЛЁЃетРрЦѓвЕЭљЭљМШгаздМКЕФКЫаФЫуЗЈЃЌЭЌЪБгаЯЃЭћЦьЯТЯИЗжвЕЮё+ЩЯAIЁЃ
НЈвщМгШыДЫРрЙЋЫОЛђепЕЅЮЛЕФAIВњЦЗОРэПЩвдДгЪ§ОнаЭAIВњЦЗОРэзіЦ№ЃЌвђЮЊЮвУЧЖМжЊЕРAIАќКЌЪ§ОнЁЂЫуЗЈЁЂЫуСІЃЌЖјДѓаЭЦѓвЕКЫаФашЧѓЪЧДђЭЈЪ§ОнЪњОЎЃЌНЋРњЪЗЩЯРлМЦЕФДѓЪ§ОнгУКУЃЌгУAIММЪѕЕУЕНИќКУЕФдЫгУЃЌЫљвдAIВњЦЗОРэПЩвдЪЪЕБВЙГфЪ§ОнЗжЮіЗНУцЕФжЊЪЖЁЃ
БОЮФШЋЦЊУќУћЮЊ AIВњЦЗОРэДгЖЎОЋзМЭЦМіФЃаЭЕНВњЦЗДДаТЃЌЙВМЦЗжЩЯЦЊКЭЯТЦЊЁЃ
ЭЈЦЊвдОЋзМЭЦМіетвЛВњЦЗОРэОГЃУцСйЕФашЧѓЮЊР§ЃЌРДНВНтAIВњЦЗОРэШыУХашвЊЖЎЕУЕФЫуЗЈФЃаЭжЊЪЖЕуЃЌВЂЬсГіAIВњЦЗОРэШыУХЕФБъзМКЭAIЦѓвЕРраЭЁЃ
ЭЈЙ§ЛЎЗжУХРрКѓНЈвщAIВњЦЗОРэеыЖдадЕФВЙГфздМКЕФЫуЗЈЛђепЪ§ОнЗНУцЕФжЊЪЖЁЃ |








