| 兼谈基于业务需求驱动的设计模式创新
如何基于业务需求驱动理念来开展我们的模式创新,成为了当今架构师、设计师的重要职责之一。本文通过具体的
Checking Table 设计模式案例创新过程,阐述在核心业务需求分析中如何开展建模、设计并实现最合理并富弹性的设计模式,在设计模式创新方面展开思考和探索。
前言
GOF 基于经验总结并发明了很多设计模式,客观的说,都非常经典,具有重大的理论指导和实战运用价值。然而这些设计模式远远不能穷尽我们的业务需求,自然也不可能完全支撑我们的业务发展;另一方面,削足适履般生搬硬套设计模式,往往使项目在代码维护、需求变更方面耗费更大的精力和成本。
以本人多年的工作经验来看,知道设计模式是架构师或者核心设计人员的基本知识,但如何运用这些基本知识进行再创新并有效解决核心商业问题,才是真正的价值所在,而不是在一些无关紧要的技术面前玩杂耍。
如何基于业务需求驱动理念来开展我们的模式创新,成为了当今软件架构师、设计师的重要职责之一。
所以本文所要阐述的,就是基于本人所经历的具体项目案例,思考并总结如何基于业务需求驱动思想,开展有价值的设计模式创新。
项目背景
本人所参与的这个项目,是一个国家级的身份注册项目,叫 NRIC(National
Registration Identity Card)项目。本人的角色是项目唯一的架构师。
身份注册涉及很多的资格审核(Eligibility Verification),也就是说,系统需要检查这个那个一系列的条件,以确保在进行身份
IC 卡注册、二次 IC 卡更换 / 升级等一系列涉及公民身份管理的严格资格审查中,获得最快最准确的审核结果,以确定所能进行的下一步业务操作。对于这个移民国家而言,会涉及各种人员(学生、15
岁、30 岁、PR、罪犯等)的注册转换,也会有各种费用豁免、处罚等相关规则。
这里涉及到一个比较核心的业务问题,那就是面对一系列的资格审核,如何设计、开发、装配以满足不同的审核场景呢?
所以,项目中迫切需要有一个更有弹性、更具操作性的设计模式,以解决这种业务问题。
需求及其建模
要设计开发极具针对性的模式,首先必须深刻理解需求的本质,并加以充分的抽象和建模。
此需求的关键点可以大致罗列如下:
1.审核源,就是需要审核的核心实体对象,比如出生登记记录、费用豁免记录、身份证遗失记录等,我称之为
Source。
2.审核标称值,一般就是法律法规所表达的一些标准、阀值,比如年龄 15
岁、无犯罪记录、第 2 次身份证遗失等,我称之为 Checking Value。
3.审核表达式,就是用以表达审核源与标称值之间的关系,比如“年龄必须大于等于
15 岁”,我称之为 Expression。
4.审核结果,是指对于任何审核未通过的,都需要有明确的用以反馈给操作者和申请者的具体原因,我称之为
Message。
下表可作为一些实例化的需求来进行表达、阐述,当然了,这已经是经由需求建模思想加以抽象了的结果。
表 1.需求规格化描述表

为了更好表达上述需求模型,可进一步图示说明如下:

图 1. 需求模型
需要说明的是,这里我在原来的需求建模原型之上,抽象了更多的概念。
这些概念我统一在此加以描述,如下:
表 2. 需求概念表

说明:
1.审核属性(Property)、审核规则(Rule)和审核标称值(CheckingValue)构成了审核表达式(Expression)。
2.审核源(Source)、审核表达式(Expression)、消息模板(MessageTemplate)和消息实例(Message)构成了完整的审核点(CheckingPoint)。
3.审核表(CheckingTable)其实可以理解为我们通常意义上的检查表(Checklist),由一组审核点构成。
当然,我们不能过于乐观的假设所有的资格审核都是单个审核源单个审核表达式,应该要考虑多个审核源下的复杂组合表达式,如下图所示:

图 2. 高级需求模型
如此,我们就成功的对需求进行了完整的概念建模。也提出了一个全新的设计模式,为了更好的表达和引用,我称之为
Checking Table 设计模式――其实就是类似于检查表(Check List)概念,只是为了在系统中更好标识,而有此命名。
模式设计
把需求一个个进行了抽象、建模,只是完成了第一步工作,那就是认识了需求。接下来就需要开展具体的设计。
首先我们可以想到,对于简单的审核点(CheckingPoint),我们应该引入“规则引擎”的思想:通过简单的配置,即可自动完成审核点的逻辑,而不必兴师动众的进行编码,这个概念叫做
AutomaticCheckingPoint。
另外,我不赞成所谓的 All-or-Nothing 的粗暴做法――就是说这种设计要么全部需求适用,要么因为对某些特殊情况不适用时得从头再来――而应该充分尊重具体问题具体分析的哲学理念,提供对于复杂审核逻辑的编程,利用设计模式所提供的简单
APIs,快速实现更具弹性的审核点(CheckingPoint),从而实现各种复杂需求。
经过进一步分析设计,可以形成如下设计模型:

图 3. 设计概念模型
说明:
1.一个审核表(CheckingTable)包含 1 到 n 个审核点(CheckingPoint);
2.审核点(CheckingPoint)提供最基本的审核点接口;
3.基于审核点(CheckingPoint)接口可扩展成 AutomaticCheckingPoint
接口,并提供基于“规则引擎”的默认实现;
4.而直接基于审核(CheckingPoint)接口,可通过使用 APIs 开发自定义的审核点(Custom
CheckingPoint);
5.不管哪种审核点(CheckingPoint)的实现,都将使用基本的概念进行表达,这些基本概念包括审核源(Source)、审核属性(Property)、审核规则(Rule)、审核标称值(CheckingValue)、消息模板(MessageTemplate)和消息实例(Message)。
实现后的效果示意图,将如下图所示:
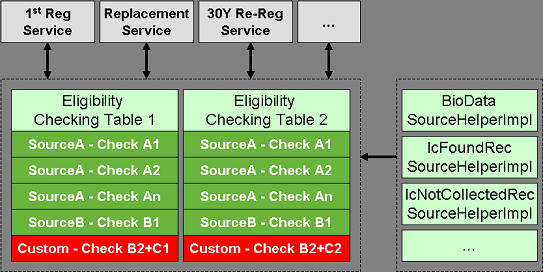
图 4. 设计效果示意图
表达了几个最基本的设计初衷:
1、审核点(CheckingPoint)可以高度重用,可自由装配在不同的审核表(CheckingTable);
2、自动化审核点(AutomaticCheckingPoint)和自定义审核点(Custom CheckingPoint)由于都基于统一的审核点(CheckingPoint)接口,所以可以混合组装在一个审核表(CheckingTable)里;
3、该模式以组装好的审核表(CheckingTable)来适应一个具体的业务场景,并为更高层的服务提供服务
模式实现
实现层面的几点考虑
在具体实现上,有几个关键点需要慎重考虑。
1、性能。基于上述的效果图可以很清晰的看到,一个审核表(CheckingTable)可能包括 1 到多个审核点(CheckingPoint),而这些审核点(CheckingPoint)中,存在一部分可能使用同一审核源(Source)。势必要考虑在线程安全的基础上,实现同一线程内同一审核源(Source)的共享,避免重复初始化审核源(Source)。尤其在这个项目中,涉及的多个审核源(Source)是需要通过外部系统的
WebService 获取,其性能影响必须高度重视。
2、规则引擎。市场上有很多成熟的规则引擎产品,开源社区也有很多值得一用。这里需要考虑两个原则:一是规则引擎不要太厚重,需要简单可行的解决方案从而实现架构
Make things simple 的优雅;二是要有足够的弹性,性能优异且学习曲线要足够低。
3、消息模板化。消息往往是业务术语,这种业务术语的表述,可能随着时间的推移、政策的变化和业务规则的发展,往往需要进行适应性的调整。所以消息模板化并外置,以提高配置能力,将进一步提高产品的可维护性。
4、异常控制。异常往往会在检查点中发生,不管是因为数据准备不当还是逻辑出现问题,从业务控制的角度上说,绝对不允许忽略这些异常而导致审核(Eligibility
Verification)出现控制失误,一旦出现异常,应该以异常消息来反馈给操作者,并可能在 UI 的处理上存在特殊的渲染逻辑(比如红色高亮显示)。故消息必须存在是否异常消息的明确标志。
经过需求论证和团队技能水平的多次权衡,最终确定上述几个考虑点。
1、关于性能。由于同一审核源(Source)下,针对每一个 key(如身份证号)所能确定的实例,在同一线程内唯一,故考虑通过
ThreadLocal 来存储。同时因为同一线程下可能存在多个不同的审核源(Source),故通过一个
ThreadLocal 的 HashMap 来缓存,该 HashMap 的 key 可用审核源(Source)的类名结合参数
key 确定;
2、关于规则引擎。此系统暂不考虑采用“正统”的规则引擎,比如 Drools,而是采用了 BeanShell
这个轻量级的脚本引擎来实现;
3、关于消息模板化。也不要想得过于复杂,简单的通过配置式的文本模板,并通过 java.text.TextFormat
进行文本内容的 format 即可满足需求。
类图(Class Diagram)
参考设计概念模型,即可轻松实现 Checking Table 设计模式的类图,如下:

图 5. Checking Table 设计模式类图
实现后的代码结构如下图所示:

图 6. Checking Table 设计模式代码结构图
接口定义
先来看看各个关键接口的定义。为了更透彻的理解设计意图,我将对每一个接口逐一展开描述。
1.CheckingPoint
/**
* 审核点接口
*
* @authorbright_zheng
*
*/
public interface CheckingPoint {
public Message check(String key) throws Exception;
public void setMessageTemplate(MessageTemplate messageTemplate);
} |
这里定义了一个最基本的审核点(CheckingPoint)接口。该接口只提供设置消息模板并真正开展审核的
check 方法。需要说明的是,check 方法只有一个参数,那就是用以确定审核对象的 key,在本项目中,一般为身份证号(NRIC)。
2.AutomaticCheckingPoint
/**
* 自动化审核点接口,通过扩展 CheckingPoint 提供更多的配置、注入能力,从而实现通过配置实现审核逻辑
*
* @author bright_zheng
*
*/
public interface AutomaticCheckingPoint extends CheckingPoint {
public void setRule(Rule rule);
public void setSourceHelper(SourceHelper sourceHelper);
public void setProperty(String property);
public void setCheckingValue(String[] checkingValue);
} |
自动审核点(AutomaticCheckingPoint)接口扩展了审核点(CheckingPoint)。为了实现“自动化”目的,自然需要更多的配置信息,这里可以设置规则(Rule)、审核源(Source)、审核属性(Property)和审核标称值(CheckingValue)。
配置、注入方式举例如何:
<bean name="cp_test"
class="bright.zheng.checkingTable.impl.AutomaticCheckingPointImpl">
<property name="sourceHelper"><ref bean="bioDataSourceHelper"/></property>
<property name="rule"><ref bean="xEquals"/></property>
<property name="property" value="typeReasonNRICTrx1"/>
<property name="checkingValue" value="ZQ"/>
<property name="messageTemplate">
<bean class="bright.zheng.checkingTable.impl.MessageTemplate">
<property name="template">
<value>Applicant has a record of 2nd Loss due
to Special Consideration</value>
</property>
</bean>
</property>
</bean> |
3.CheckingTable
/**
* 审核表接口
*
* @author bright_zheng
*
*/
public interface CheckingTable {
public List<Message> excute(String key) throws Exception;
public List<Message> excute(String key,boolean stopOnError) throws Exception;
public void setCheckingPoints(List<CheckingPoint> checkingPoints);
public List<CheckingPoint> getCheckingPoints();
} |
审核表(CheckingTable)接口主要实现两个目的:注入审核点(CheckingPoint)列表并执行系列审核逻辑。为了更准确的控制执行过程,提供了一个
stopOnError(即遇到审核失败即停止)参数,用以控制两种不同的场景:一种是只要有审核不通过的都打回,不负责告诉你哪些失败了;另一种更人性化,不管怎样,全部审核点都执行完,一次性告诉你哪些审核点没通过。默认情况下
stopOnError 为 false。
4.Rule
/**
* 规则接口
*
* @authorbright_zheng
*
*/
public interface Rule {
public boolean eval(Object instance, String property,
String[] checkingValue) throws Exception;
public void setExpression(String expression);
} |
规则(Rule)通过设置表达式(Expression),即可在运行期对对象实例(instance)的属性(property)与审核标称值(checkingValue)进行运算,其结果返回一个
boolean 值。在这里需要注意这个返回值的约定:true 表示检查结果有异常(检查未通过),而 false
表示检查结果无异常。检查点(CheckingPoint)将基于这个结果来判断是否要格式化并输出审核消息。
5.SourceHelper
/**
* 审核源接口
*
* @author bright_zheng
*
*/
public interface SourceHelper {
public Object currentSource(String key);
public void removeCurrentSource(String key);
public void putSource(String key, Object object);
} |
SourceHelper 是为审核源(Source)提供的一致性、高性能的接口。对外统一提供简单的存取方法。内部通过合理有效使用
ThreadLocal,以缓存同一 key 下的审核源(Source),确保在同一请求下审核源(Source)在不同审核点(CheckingPoint)之间的传承和共享。这一点在获取外部的审核源(Source)场景(如通过外部的
WebService 获得审核源)中非常重要,确保了本设计的高性能表现。
具体实现请参考附件代码中的 AbstractSourceHelperImpl.java。具体的 SourceHelper
可扩展这个抽象类,高效的实现真正的符合业务需要的 SourceHelper。
实现代码
本模式的实现,主要基于 JDK1.5 + Spring 2.5 + BeanShell2.0b4。
具体代码不在文中赘述,所有实现的代码可通过本文附件获取,包括完整的测试用例。
相关代码在此仅做简要说明,如下:

测试与性能表现
接下来大家当然关心几个问题:怎么使用这个模式?性能如何?
我们可以通过单元测试用例来加以深入的阐述,用代码表达思想,用数据事实说话。
要实现完整的单元测试用例,必须覆盖全部上述所有的概念及其实现。下面是本人用以覆盖测试的代码和配置文件清单。

本测试通过目前实现的各种 Rule 在循环 10000 次下的性能,测试结果统计表如下:

可以看出,xGreaterThan 最快而 xIn 最慢,即便这样,全部测试用例也说明了每次 Rule
的执行均低于 5 毫秒,而在实际生产环境中一般需要 20-30 个审核点(CheckingPoint),也就是说,即便在一台类似于本人笔记本电脑性能下的
Server,也可以在 100-150ms 内完成一个业务下所有审核规则的运算。此性能表现完全满足需求,更不用说在实际生产环境中我们将使用性能远胜于本人笔记本的
IBM 小型机了。
当然,这里需要说明的是,审核点(CheckingPoint)的性能,主要决定于审核源(Source)的获取性能,尤其是需要获取外部系统对象(比如通过
WebService 获取外部系统的审核源)。
附注:本人的笔记本电脑配置为:
1) 品牌 & 型号:Toshiba Satellite Pro
2) 操作系统:Windows XP SP3
3) CPU: Intel Core 2 Duo T6570 2.1GHz
4) 内存:3G
结束语
设计模式的创新,来源于对需求的深度思考、归纳、提炼和抽象,并充分融合自己的知识和经验。Checking
Table 设计模式,其实可以广泛应用于很多类似的需要执行系列基于条件“审核”的业务场景,当然要与自己所面临的业务场景得以更合理的融合,可以在这个基础上进行针对性的扩展、微调和优化。
不管怎样,有这样一个系统的概念抽象、需求建模、分析设计和模式实现的思维,在面对具体业务需求上开展创新应该会更为得心应手。
|





