�����������Ĺ����У����ò��Ե�ͳ�����ݣ����������Ŀɿ��ԣ��Կ���������������������Ҫ�ġ�
(1) �Ʋ����IJ���Ƶ��
����������Ƶ�ȵ�һ�ַ����ǹ���ƽ��ʧЧ�ȴ�ʱ��MTTF��Mean
Time To Failure����MTTF���㹫ʽ��Shoomanģ�ͣ���
������������������ 
���У�K ��һ�����鳣��������һЩͳ�����ֱ�����K�ĵ���ֵ��200��
ET �Dz���֮ǰ������ԭ�еĹ���������
IT �dz��ȣ�����ָ���������������������
t�Dz��ԣ������Ŵ�����ʱ�䣻
EC (t) ����0��t�ڼ��ڼ�����ų��Ĺ���������
��ʽ�Ļ����ٶ��ǣ�
�� ��λ���������еĹ�����ET�MIT����Ϊ������������������Ŵ����ı䡣
ͳ�����ֱ�����ͨ��ET�MIT ֵ�ı仯��Χ��0.5��10-2��2��10-2֮�䣻
�� ���ϼ���������ڳ����в�������������MTTF������в��������������ȣ�
�� ���ϲ�������ȫ�������һ����������õ�������
����Դ�������һ������
��EC (��) ��0����ʱ���ڼ�����ų��Ĺ������������Dz���ʱ��(��)������ͬһ��ʱ��0�����ڵĵ���ָ���ۻ��淶���ų����������ߦ�c
(��) ��
��������c (��) = EC (��)�MIT
���������ڿ�ʼ�ʵ������ƣ�Ȼ���ͻ������������һˮƽ�Ľ�����ET�MIT�����ù�ʽ�Ļ����ٶ������ϼ���ʣ��Ŵ��ʣ������ڳ����в�����������������������������㣬�����Ƶ��ã�
�������������������������� 
����ǹ����ۻ���S������ģ�ͣ��ο�ͼ5.19��
����������������������������
ͼ5.19 �����ۻ���������ϼ������
��
���ϼ�����߷���ָ���ֲ�������ͼ5.19����ʾ��
��������������
(2) ���������й�������ET�ķ���
������Shoomanģ���������ԭ����������ET
��˲�����
��������������
���ԣ��� 
����T�������ܵ�����ʱ�䣬M�����������ʱ���ڵĹ��ϴ�������
��������T�MM = 1�M��= MTTF
���ڶԳ���������β�ͬ�Ļ�������Ĺ��ܲ��ԣ���Ӧ���ʱ���1
<��2������Ĵ�����EC (��1 ) < EC (��2 )������
��������

����������
������ ��
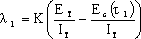
����������
�����������飬�õ�ET�Ĺ���ֵ��K�Ĺ���ֵ��
������������
��������  ��
��
�� ����ֲ����Ϸ����������ԭ�й�������ET �� �����ٲ��������
����NS���ڲ���ǰ��Ϊ���������ֲ��Ĺ��������Ʋ��ֹ��ϣ���nS�Ǿ���һ��ʱ����Ժ��ֵIJ��ֹ��ϵ���Ŀ��nO���ڲ������ַ��ֵij���ԭ�й��������������������ֲ����Ϻ�ԭ�й��ϵ�������ͬ���������ԭ�й�������ET�Ĺ���ֵΪ
��������
�ڴ˷�����Ҫ��Բ��ֹ��Ϻ�ԭ�й���ͬ�ȶԴ�����˿����ɶ���Щֲ�����֪����һ����֪�IJ���רҵС����в��ԡ�
���ֶԲ��ֹ��ϵIJ����ٲ���ij���������Ȼ��Ҫ��������ʱ���ڷ��ֺ��IJ��ֹ����ϣ����Ӱ�칤�̵Ľ��ȣ�����Ҫ��ʹֲ��Ĺ��������ھ�ȷ���Ʋ�ԭ�еĹ����������ѡ���ֲ����Щ���ֹ���Ҳ��һ�������ѵ����顣Ϊ�˻ر���Щ�ѵ㣬���������治�����貥�ֹ��ϵķ�����
�� Hyman�ֱ���Է�
���Ƕ�ֲ����Ϸ���һ�ֲ��䡣����������Աͬʱ��������ز���ͬһ�����������������t��ʾ����ʱ�䣨�£�����t
= 0ʱ��������ԭ�й���������B0��t = t1ʱ������Ա���ֵĹ���������B1������Ա�ҷ��ֵĹ���������B2���������˷��ֵ���ͬ������Ŀ��bc�����˷��ֵIJ�ͬ������Ŀ��bi��
�ڴ�������ʱ��ͷ�����������ֵĴ������ܵĴ����о��д����ԣ���������Ա���ԵĽ��Ӧ���ȽϽӽ���bi���Ǻܴ���ʱ��
��������������
���bi�Ƚ�������Ӧ��ÿ��һ��ʱ�䣬����������Ա�ٽ��зֱ���ԣ��������Խ��������B0�����bi��С���ι���ֵ�Ľ�����࣬�����B0��Ϊ������ԭ�д�������ET�Ĺ���ֵ��