| UML����������֯ | |||
| |
|||
|
|||
IBM Rational Purify �ĸ�����: ���� Purify
��������
2008-08-14 ���ߣ�Satish Chandra Gupta,Anand Gaurav ��Դ��IBM ��
IBM ®Rational® Purify®��һ���ܹ���ȷ����ڴ�й¶����Ĺ��ߣ�����Ҫ����ȷ����Щ�������൱���ѵġ�����ز�����һ�����������ʹ���ڴ����������������Դ�������ı��棬��ȷ��������������ԭ��;���λ�á�����ƪ�����У�����ѧϰ������������� Rational Purify API �ʹ��е������Ĺ۲���������ڴ��еĴ��� �ڴ�������������������ѷ��������Ĵ�������֮һ����Ϊ����ڴ�й¶Դ�ʹ���ı����Ƿ����Զ�ģ�ʹ���Ǻ��ѽ����´����ԭ������յ�Ч����ϵ���������⣬��Щ����ͨ�������ں��ر�������£���˺��Ѹ������ǡ�һ������£���Щ�����������ij�����Ԫ�������Լ�����ϵͳ֮�临�ӵĹ�ϵ��ɵġ���ˣ�����ͨ�����Դ�����Ǻ���Ԥ���������Щ�������Ŀ����Ժͷ������龰�ġ�ͨ��������Ҫ�൱��ĵ��Ժ͵������˽���ڴ����ij���������ơ� IBM® Rational® Purify®��һ�����ڴ���Թ��ߣ����������ٲ�ȷ��λ�����ڴ�й¶�����ԭ��Ҫʹ��������ߣ�������Ҫ���� Purity ���������ij���Ȼ��������������Թ��ij���ʱ��Purify �ͻ�ͨ�����ij�����ϸ����ڴ���ʺͲٿأ�������Ҫ�������ڴ���������������˵���ʱ������ԡ� ������ѧϰ�����ڴ��������ͣ��Լ�ͨ���Ķ� �ο����� �е� IBM developerWorks ���¡�Ҫ��һ������©�ġ����е�����C�������� Purify�����ο��������˽�������� Purify ��������ǡ�������� Purify ���ڴ����ʮ����Ϥ�������Կ����������������ƪ���¡� Purify ӵ�м������صĸ������ܸ߰����������ڴ��������ƪ�����У�����������ѧϰ Purify �е�Ӧ�ó����̽ӿ� ��API���Լ�����ڵ�������ʹ�����ǡ�Ȼ������ѧϰ API �����ڴ�۲��������ԡ� Ӧ�ó����̽ӿ�Purify �ṩ�˸��ָ��������Դ����ij�����ߵ����������õ� API��������һ�������������ڴ����⡣���磬����������purify_what_colors�������ҳ��ڴ淶Χ��״̬��
Purify �ܹ��������������ڴ�ʹ�õ�ÿ���ֽڵ�״̬���������������ɫ��������ͬ��״̬����ɫ����ɫ����ɫ����ɫ����������е��ڴ涼�Ǻ�ɫ�����ʾ�ڴ滹û�б�����Ҳû�г�ʼ�������������ڴ��Ժ����ͱ�ɻ�ɫ��������Ѿ������䵫��û�г�ʼ����������ʼ��һ���ڴ浥Ԫ�����ͻ�����ɫ��������ڴ汻����ͳ�ʼ���������ͷ��ڴ�ʱ�����ͱ����ɫ���������ʼ������������ͷš��������������ʾ�������ͼ 1�С�
������һ���ڴ�й¶ʱ�������Դӵ������е���purify_what_colorsAPI ���鿴��Ȥ���ڴ浥Ԫ�� Purify ��ɫ״̬�����������ʾ��һ���˸��ֽڻ��嵥Ԫ����ɫ״̬��������ֻ�п�ʼ�����Ѿ�����ʼ����
API ��ӡ���� sizeof(buf)+1 bytes ���ڴ�״̬�����ڴ��ַ buf ��ʼ��ÿ���ڴ��ֽڵ��ڴ�״̬�����������ĸ����ʾ R��Y��G������ B����Щ��ĸ��Ӧ����Ŀ�ֱ�������Ǻ�ɫ����ɫ����ɫ�Լ���ɫ�� ͼ 1. �ڴ浥Ԫ����������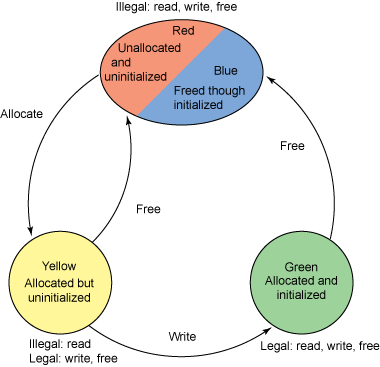
���ô��е������� Rational Purify���������£�Purify �ṩ���㹻����һ���ڴ�������Ϣ�������Ը�����Щ��Ϣ���������ԭ��������������Щʱ����������Ҫ�������Ϣ��Ϊһ����ʼ�㣬Ҫ�������������֪�����е�ԭ�����磬�����Ǽ��� Purify ������һ�������Ծ��� UMR ������Ϊ��ȷʵ����һ����ʼ�����ij������䡣����Ȼ������һ������·���������·����Ҫô�dz�ʼ�����û��ִ�У�Ҫô�Ƕ���һ���ڴ滺���ָ�룬���ָ�뱻���½�������һ������û�б���ʼ�����ڴ滺�塣 ����������£�����Ҫ�������ij������ҵ�ȷ��ԭ�����˸��˵��ǣ����ǵ������ij����ǵ����DZ����� Purify ����Purify �����ڴ��������Ǵ�����֮ǰ�ı��档���������������ͷ�����صı����͵��������ڴ��״̬��Purify ��Ϊ�������ڴ浥Ԫ��״̬�ṩ�� API�� ����������Ϊ�DZ��� Purify ����ʹ�õ������ķ�����
������һ���������У����������ø��� Purify API �������о������ڴ浥Ԫ��״̬���ͣ�f
�������е���ʱ����������Ҫ������һЩ����Ƭ���ϣ������Ͳ���Գ�����Ƶ������Ƭ��֮ǰ����� Purify �������Ȥ��Purify �ṩ API ���رջ��߿������棨ע���ڴ�ʹ�ü��û�йرգ���
�ڴ�۲��Purify�ṩ�������Դӵ������е��õķ�Χ�ϴ���ڴ�۲�㼯�ϣ��Ӷ����������ij����е����ڴ�й¶���⡣��ʾ���б� 1�еĴ���չʾ��һ���ڴ���©��һ�����ϰڶ���ָ�롣 �б� 1.����һ���ڴ���©��һ�����ϰڶ���ָ��Ĵ��� (mem_errors.c)��
��Ȥ���ǣ�������ֱ�������� main() ���� foo()������������������������ȷ�ġ�������� main() �����ڴ棬���� foo()��ʹ�÷�����ڴ棬Ȼ���ͷ������˳���������� foo() ���ó��� strdup()���������ڴ棬ʹ������ڴ棬Ȼ���ͷ�����Ȼ������������������������ã�����һ��ȫ���Ե�ָ���������namestr�����ᵼ����©�Ͳ��ϰڶ���ָ�롣�� strdup() �� foo() �б����ã���� namestr����ֵ�ͻᱻ��д���Ӷ���ʧ main() ���ڴ�����ָ�룬������©���� main �У����� foo() ���غ�namestrʵ����ʱһ���ڶ���ָ�룬��Ϊ foo()�Ѿ��ڷ���ǰ�ͷ����Ǹ��ڴ档 ������������У�ͨ������������Ϳ����ϳ�����Ĵ��ڡ������ڽϴ����и��ӿ������̵ij����оͲ������ˣ��������ij�����������ĺ����������ڲ�ͬ�ĺ������С�Ҳ���ǵ� Purify �������ڴ�۲�� API ��÷����ʱ�� ����������������ܹ������������
������������������ij���ʱ��Purify �������������Щ���� ��Ҳ�뿴ͼ 3����
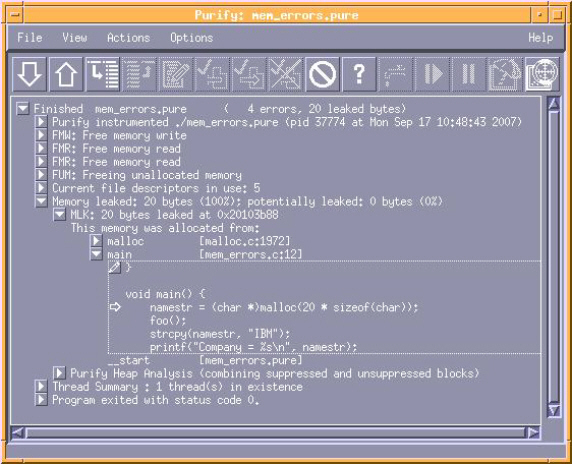
�������С��������˵��ͨ��ʹ�ð��� Purify �����ṩ����Ϣ���Ժ������������������Ƕ���һ�����ӵij���һ�������� foo() �����ĺ������ܻ�Ӹ��ֵ�Ԫ�е��ã���������һ��ѭ��Ȧ�У�ͨ��ʹ�� Purify �ڴ�۲�� API �������������ʮ�����á� ����۲������ʹ��Ҫ�� Purify �ر��עһ���ڴ������ֻҪ�Ǹ��ڴ汻��ȡʱ�ͻᷢ��һ�����棨WPR: Watch Point Read����д�루WPW: Watch Point Write���������ͷţ�WPF: Watch Point Free���������ַ����������Իش����������⣬���磺�������������������ʲôλ�ñ���д�������ߡ����������ʲôλ�ñ�ʹ�ã����Լ�������ۼƵ��ڴ��У����ĸ������ͷ�������ڴ棿�� ������������ܹ�����������һ��������������������� ��gdb�����ﱻ��������������̣����������������κ���ϲ���ĵ���������
�鿴һ�� Purify �����ڴ���©�� FMR��FMW�� ���� FUM�������ܻ��ʵ�������Ȥ�����⣺
������ͨ��������һ���۲������ main() ������ malloc���ó���֮��Ϳ��Իش���Щ���⣨�� 13�У���Ȼ������ Purify ������һ���۲���� &namestr �ϣ��Ӷ��������з����� namestr �����ı�д���������ۺ�ʱ��ַ����д�� namestr ��������� Purify �۲�㶼����ʾһ�� WPW ��Watch Point Write�� ��Ϣ�� Purify ������У�
��� purify_watch_n() ����ʹ����ڴ浥Ԫ�ĵ�ַ����أ�&namestr������ȡ�Ĵ�С ��4���ֽڣ�ָ��Ĵ�С���Լ��۲��ģʽ ��r����д�Ĵ�Сģʽ w���Լ���ȡ�ͱ�д�Ĵ�С��ģʽ rw������һ���µ�ַ������ namestr ʱ�� Purify ����������������ʾһ�� WPW ��Watch Point Write�� �����������չ���������������Ϣ��
�����Ϣ������ foo() �� 6 ���еķ�������һ����ַ������ namestr �С�����������ڴ��ͷ�֮ǰ��namestr ֵ��һ���Ѿ����������Ҳ��Ϊʲô Purify ����һ�� MLK ���ڴ���©�� �����ԭ���������Ǹõ��� FMR ��Free Memory Read�� �� FMW ��Free Memory Write�� �����ԭ���ˡ������� FMR ���� FMW ʱ��Purify Ҳ��ϸ˵��������ڴ���ʲô�ط������䡣����������ӣ�Purify ��ζ�� FMW �� FMR ������ main() ��ʽ�ֱ��� 14 �� 1 �з��������ڷ��ʵ��Ѿ��ͷ��ڴ����� foo() ��ʽ������ strdup() �����еĵ�6�еġ���ˣ�����Ҫ�����ڴ��������з����ڵ�6�еĶ�ȡ��д����Ϊ �����������ָ�룩��������ͨ����һ����ȡ��д��۲������strdup()���ó���֮����������
��Ϊ����һ����ȡ��д��۲�㣬�κγ��Զ�ȡ����������� namestr ָ��ָ����ڴ������ݵ���Ϊ�������ֱ�һ�� WPR ���� WPW ��Ϣ��ע��ʹ������� namestr ����ǰʹ�õ� &namestr ��������ǰ�������ǹ�ע֧�� namestr ָ�뱾�����ڴ棻����������ע�������� &namestr �ṩ�ġ��뷨���ڶ��������ǹ�ע���� namestr ָ����ڴ档 WPR ��ʾ�� printf() ���ó���ĵ�7�У�WPF ��Watch Point Free�� ��ʾ��free()���ó���ĵ�8�С�����������Ԥ��֮�У��������ڣ������� WPF ֮����Ӧ�ø���С�ĵ���ѭ�������·���� ��ʵ�ϣ�������Ϊ Purify �� purify_stop_here ����һ���۲�㣨������ǰ���������������ڡ�ʹ�ô��е������� Purify�����֣�����ÿ���˵������ʱ��ֹͣ ��������Ϣ�����κζ�����ڴ�ķ��ʴӴ��Ժ��Ǵ�����Ϊ����ڴ��� namestr ָ����ڴ��Ѿ��ͷš���ˣ�������������ʱ���ڵ�14�н����� һ�� WPW ��Ϣ����Ϊ����Ѿ����ͷŵ��ڴ���ͨ��һ�� strcpy() �������д�뵽�Ǹ���Ϣ�С���� WPW ������ Purify ����� FMW ��Free Memory Write����
ͬ�����������̵ĵ�15�н������һ�� WPR ��Ϣ�����Ҳ��һ�� FMR ���������Լ���������ĩβ�ĵ�16���б���� FUM ��������Ҳ�Զ����ˣ���Ϊ��� namestr �ڴ棨һ����ֵ strdup ���䣩�Ѿ��� foo �����ĵ�18�б��ͷ��ˣ��������һ�� WPF ��Ϣ�����棩�� ͼ 4��ʾ��һ�� Purify ���ں�������Щ�۲�������������ܵ���˵���ڴ�۲�㽫�����������ض��ڴ����ʹ��������������Ǻ���������������������ٴ��г���ִ�е��ڴ棬�����һ���ڴ���� ͼ 4. �� Purify ����Ĺ۲����Ϣ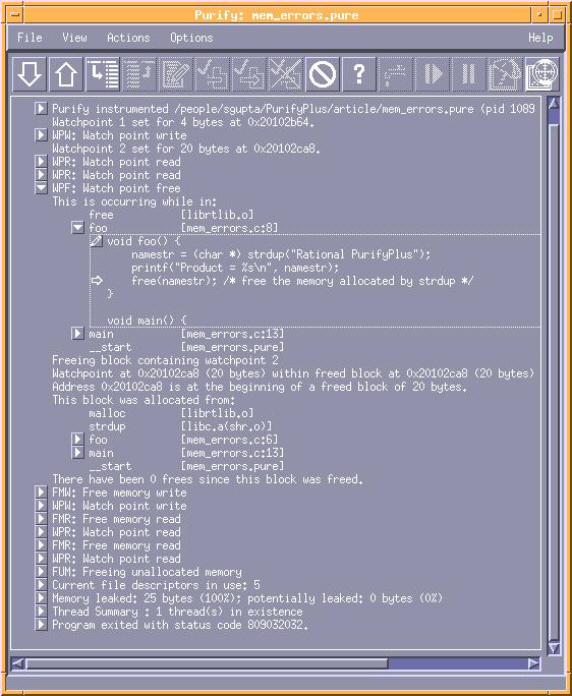
Purify �۲�����Ϊ�ض��ڴ��ַ�������µ���Ϣ��
�����м�������ʹ�õĹ۲�� API ���� ������ 1���������purify_watch(addr)�������ض���ַ���ĸ��ֽ���������һ����ȡ��д��۲�㡣���ù۲���API ������һ��������ֵ�����ո����õĹ۲�����֡�������ʹ�������ֵ���ݵ�watchpoint_remove������������б����������ȼ���ʹ�ô��к��ʵ�ַ����С���Լ����͵�purify_watch_n�� ���� 1. API �����ù۲����
��ȡ���ڹ۲�����Ϣ��������ǣ���������������� API��
�����������е� Purify API����ʹ������������е� Purify API �⣬�������Խ�����Ƕ�������У�����ͱ���������Ϣ������������£���ʹ����һ���Զ�����ϵͳ���������ľ�������һ��������ʱ�������������Ϣת���� Purify ��־�У��ǽ�����������������⡣ �����ֽ� Purifying API Ƕ�뵽�������еķ�����
���� �б� 2 ����������ʾ��������������ͨ���������� #ifdef���屣����Χ��һ�𣬴Ӷ������ij����б��� Purify API ���ó��������ַ�����������Ҫ�������Դ����������������������� Purify API �Ŀ�ִ�г���Ҳ����Ҫ����һ����������Ʒ����Ŀ�ִ�г��� ���������һ�� strncpy ���ߣ������������Դ��Ŀ���ַ������ȱ��ֱ�˲飬ʹ���ܹ�����ȡ��д�롣����κ�һ������ʧ�ܣ��ͻ���һ���ʵ�����Ϣ����ͨ������ purify_printf ��ӡ�� Purify ����̨������־�С�Ȼ�� purify_describe�ͻᱻ���ã������ӡ��ϸ�Ĺ�������ڴ��ַ����Ϣ���������Ĵ��浥Ԫ���ѡ�ջ���ı����Լ�������ջ���ڴ棬����λ��������ʱ���������������free() ������ʷ�����purify_what_colors ����������ӡ����ڴ滺�����ɫ��ֻ�е�û�д�����ʱ�Ż�ִ�и��ƵIJ����� �б� 2:mystring.c �IJ����ļ��������˴��б����� API��
makefile ��ʾ�� �б� 3�У���ʾ��������ܹ�ͨ������ -DPURIFY ������� Purify API ���ã��Ӷ�Ϊ����һ�������汾�Ŀ�ִ���ļ� (�μ� mystring.pure �Ĺ���)�����ҽ����� Purify API ���ݿ����������� �б� 3. ���� mystring �� mystring.pure �IJ��� makefile��
ʹ��һ������װ�õ�ȱ���ǣ����������±���������������������У�ֻ��һ�� C �ļ���ʹ�ã������ڽϴ��ϵͳ�У�ͨ���Ǹ������ݿⱻ�������������ӵ������ִ���ļ��С������������£��������Ҫ�������ij������������±�������ʹ�ñ���װ�õ� C �ļ��� ��һ����ѡ�ķ����ǣ�ͨ�������б� 3�еĹ����������ӵ����ĸ��� libpurify_stubs.a ��Ӧ�ó����ϣ��Ӷ�����mystring��
��� libpurify_stubs.a ��һ����С�����ݿ⣬���й� Purify API �������õĿհ״���������������ij���ʱ��Purify �����ṩ������ʵ�� API �������壬������ᱻ���ӡ� �������� if(purify_is_running()) ����Χ��� Purify API ���Ӷ�ʹ Purify �������������δ���Եij����б�û������뿴�б� 4���� �б� 4. ʹ�ô��б���װ�õ� Purify API �IJ���mystring.c�ļ���
ʹ�� #ifdef �� Purify ����������ǣ�ǰ����Ҫ������ �CDPURIFY �ź����±������ij������߰���һ������ purify_is_running ������ʱ��ɱ����ǿ��Ժ��Բ��ƣ����������ij����Բ�Ʒ�������ʽ���ӵ� Purify �Ŀհ״������������ʺ�������ķ����� �ܽ�����ƪ���У���ѧϰ�� Purify �й����ڴ���ɫ�ĸ��API���Լ��ڴ�۲�㡣������ʹ����Щ���Ե������� API�����߷������������Խ�����Ƕ�뵽���ij����С��������������� Purify API ���ڴ�۲��İ����������Ը���Ч�������ij����е����ڴ���� �ο�����ѧϰ
|
��֯��� | ��ϵ���� | Copyright 2002 ® UML����������֯ ��ICP��10020922�� ������������110108001071�� |