| 编辑推荐: |
本文来自于个人博客,本文是结合性能测试过程中的loadrunner工具,总结出的经验文档,包括了安装、编写脚本、运行场景3个过程中的注意事项。
|
|
1. 引言
1.1. 简介 loadrunner是一种预测系统行为和性能的负载测试工具,它可以轻松创建虚拟用户、创建真实的负载、定位性能问题、重复测试保证系统的高性能
globa-100的注册码:AEAMAUIK-YAFEKEKJJKEEA-BCJGI
web-10000的注册码:AEABEXFR-YTIEKEKJJMFKEKEKWBRAUNQJU-KBYGB
对于mms协议: mms-1000:AEACFSJI-YASEKJJKEAHJD-BCLBR mms-6.5w的注册码AEACFSJI-YJKJKJJKEJIJD-BCLBR
1.2. 组成 1.1.1. Vuser Generator c语言脚本开发的
1.1.2. Controller 指挥官的作用,控制执行场景
1.1.3. Analysis
收集测试数据,进行结果分析的
1.3. 文档说明 本博客是结合我所在公司性能测试过程中使用loadrunner工具,总结出的经验文档,包括了安装、编写脚本、运行场景3个过程中的注意事项
2. 注意事项 2.1. 安装过程总结 2.1.1. 安装成功loadrunner后启动录制脚本,浏览器总是出不来 这个问题为什么我放到文档第一个,因为这个问题是几乎所有的使用loadrunner的新人都是会碰到的,这个也是一个老生长谈的问题了,所以我把它放到了第一位
出现这个问题的原因,无非就是你的浏览器启动了第三方插件或者PC机有些杀毒软件没有关闭,比如360。所以为了避免出现这个问题,我推荐安装一个VMware
Workstation虚拟机中安装XP系统,然后在XP中安装loadrunner,这个可以保证每次使用loadrunner的时候避免因为环境问题,导致碰到困难
2.1.2. 安装出现Microsoft Visual c++2005 sp1安装失败? 1、进入loadrunner-11\Additional Components\IDE Add-Ins\MS
Visual Studio .NET
2、安装:LRVS2005IDEAddInSetup.exe
3、再安装loadrunner
2.1.3. 安装出现“计算机缺少vc2005_sp1_with_atl_fix_redist” 在lr安装包里面下“loadrunner-11\lrunner\En\prerequisites\vc2005_sp1_redist”有
vcredist_x86.exe 安装下就可以了
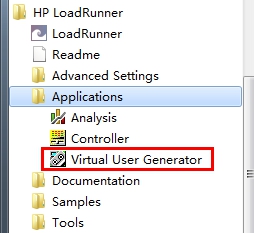
2.2. 编写脚本过程总结 2.2.1. 如何使用录制 1. 在本机的所有程序中打开Vuser Generator,如下图
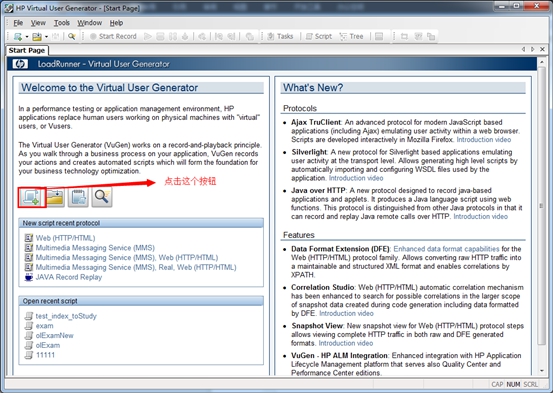
2. 如下图,在弹出的窗口中,点击New Script按钮
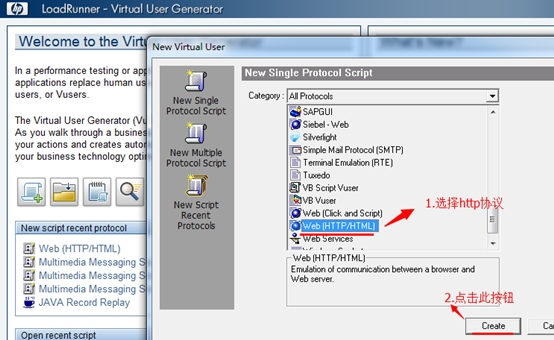
3. 如下图,在弹出的窗口中,选择HTTP/HTML协议后点击Create按钮
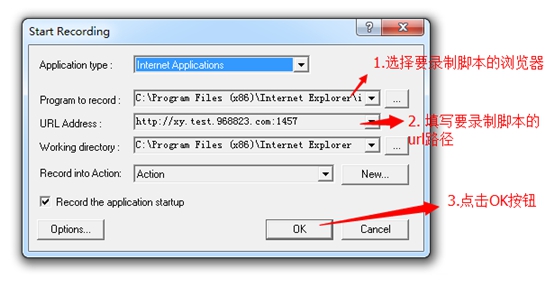
4. 如下图,在弹出的窗口选择浏览器和url地址后,点击OK按钮,然后等待弹出浏览器并打开url地址后,就可以进行脚本的录制了
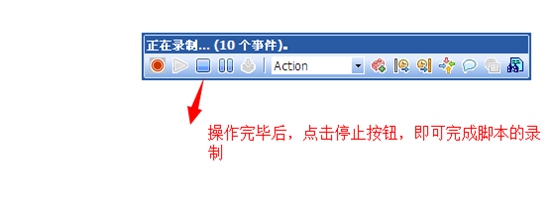
5. 如下图,在进行操作完毕后,点击停止按钮,即可完成录制,loadrunner会自动生成c语言脚本
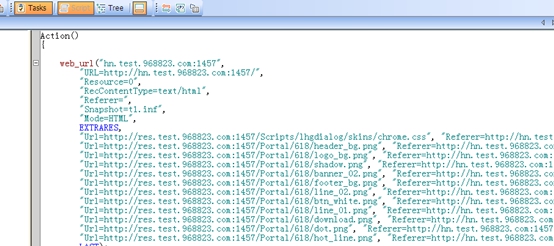
6. 如下图,即为loadrunner录制的脚本截图,录制的脚本自动在Action()中显示,我们可以参考录制脚本中客户端和服务器之间的数据交互,自己重新编写测试脚本
2.2.2. 事物 为什么用事物 事物Transaction,一般我们用来衡量一个action所消耗的时间,通过它,可以知道一个操作的消耗相应时间,它是作为度量系统性能的唯一指标
如何使用事物 在需要插入事物的请求前面使用快捷键Ctrl+T,然后填写事物名称,点击确定即可完成事物的插入
使用的注意点 1.为事物取名要有意义,比如登入事物,我们一般就用login
2.建议是一个请求设定为一个事物,这样我们分析结果的时候可以更好定位哪个环节的事物耗时多,需要性能调优
3.设置事物后,一定要判断事物成功和失败的条件,既获取请求的返回值是否是预期的结果。是,则事物PASS,否则,事物FAIL
2.2.3. 脚本参数化 为什么要参数化 为了让脚本有更好的适应环境的变化,比如userName、password的变化,于是我们就把userName、password设定为“参数”,然后“参数”通过读取txt等方式获取预制数据,提高脚本适应能力
如何参数化 使用鼠标选择需要作为“参数”的字符串,鼠标右键“Replace with a parameter”,然后在弹出窗口填写参数名、选择类型,再点击【Properties】按钮,在弹出框中设置参数内容和取值方式,即可完成参数化
参数化注意点 1.完成某个字符串参数化后,在调试脚本的过程中,建议直接用快捷键Ctrl+L,打开参数列表
2.在为运行场景的时候,我们一般希望每个用户都是用不同的参数数据,所以在参数列表中我们会预制足够多的数据,并且一般我们会设定读取参数的方式为

Ps:这个可以根据具体情况,自定义
3.loadrunner对于参数的引用是用“{}”作为表示的,所以引用参数的话,不要忘记“{}”
2.2.4. 关联 为什么要关联 对于脚本,很多时候,我们处理数据的时候,是需要对服务端返回的数据进行解析,而服务端返回的数据如果每次都是变化的话,每次我们都是需要动态获取,这个时候就需要关联。简单来说,就是处理服务端返回的动态数据
如何关联 1.录制2次脚本
2.通过loadrunner自带的工具WinDiff对比2次脚本的不同,如下图
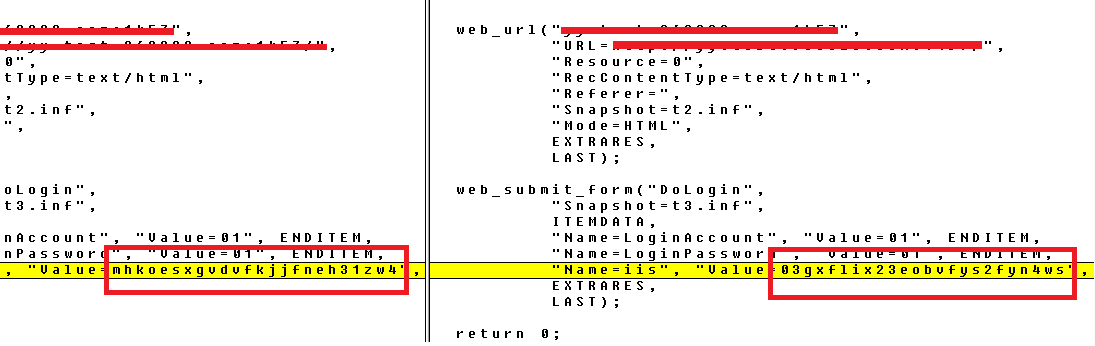
3.因为2次脚本操作步骤一样,不同的内容可以根据录制业务分析出得出需要关联地方,如下图1,黄色高亮的地方就是2个相同操作步骤,但是录制脚本对比不同的地方,这个时候我们只要在操作网页中找到出现不同点的html源码处,如下图2;或者也是可以启用Run-time
Settrings中所有log设置,然后在进行录制过程中output window找到不同点出现的地方

4.使用函数web_reg_save_param关联动态数据,保存参数,供其他地方使用,这个时候注意使用函数的过程左右边界范围,通过web_reg_save_param关联代码如下,这样就完成了手动关联
关联注意点 1.关联函数是在请求函数之前定义的
2.关联数据的时候注意关联函数的左右边界不要写错了
2.2.5. 集合点注意点 集合点就是为了让Vuser集合,然后同时做某个操作,只要在相应的请求前设定有意义的集合点lr_rendezvous即可
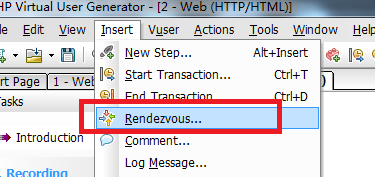
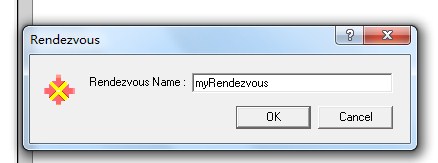
2.2.6. 如何使用集合点 1.如图1,在需要集合点的脚本出前点击菜单栏的Insert-Rendezvous,然后在弹出的窗口中,如图2,填写自定义的集合点名称即可完成集合点设置
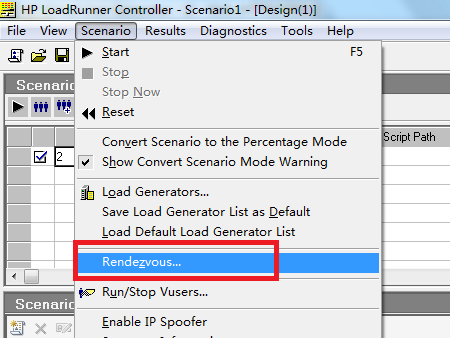
2.如下图3,将步骤1中的脚本在Controller中打开,在Controller界面,点击菜单栏Scenario-Rendezvous,然后在弹出的窗口中自定义设置集合点的使用方式,即可完成集合点的简单使用
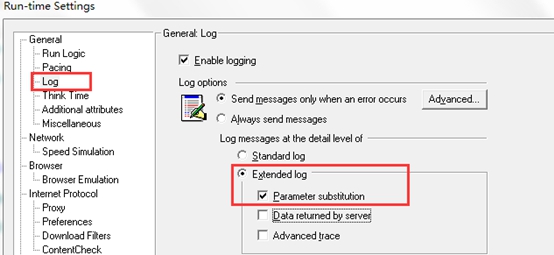
2.2.6. 脚本调试注意点 1.如下图,在运行时设置窗口,开启日志,这样有利于我们调试脚本
2.如下图,设置回放的时候,打开浏览器快照,在调试脚本的时候,我们可以知道对应脚本相应的界面,图形界面有利于我们调试
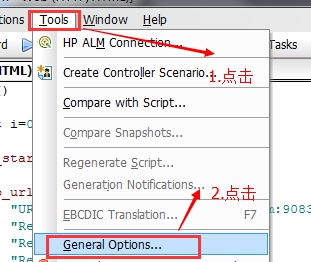

2.3. 执行场景过程总结 2.3.1. 执行场景前需要注意点 1.如下图,进入脚本的运行时设置窗口,设置日志为标准。解释:当运行场景时候,假如大量用户碰到异常,如果此时选择输出日志信息,这个输出操作会消耗负载机的资源,使得定位系统性能瓶颈,不能准确判断是负载机问题还是被测系统的问题
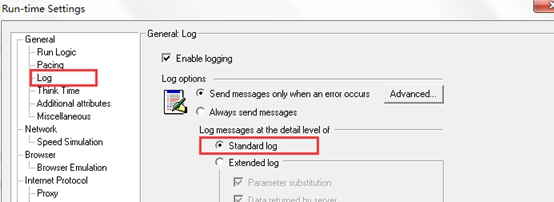
2.如下图,在运行时设置中,选择“每次迭代清除高速缓存”。解释:因为压力测试的时候,是模拟不同用户访问服务器,此时不同用户访问肯定会从服务器中下载资源,此时我们就要保证每个用户访问浏览器都是不存在缓存的
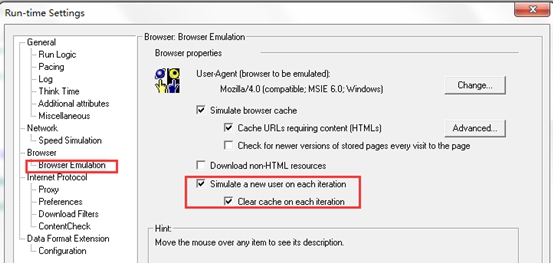
3.如下图,在运行设置中,设定脚本的思考时间为“按照录制时记录时间”,因为我们是模拟用户操作,所以操作过程中是需要思考时间
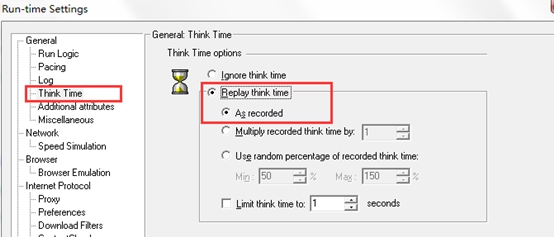
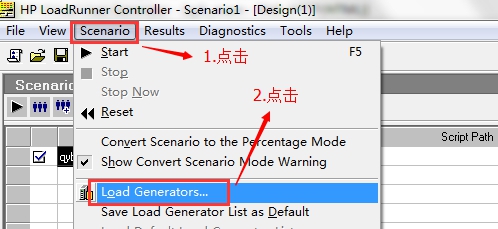
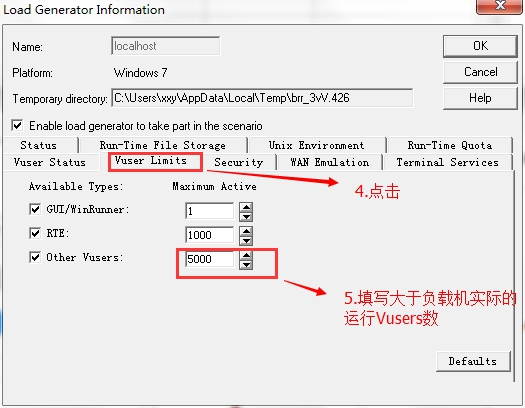
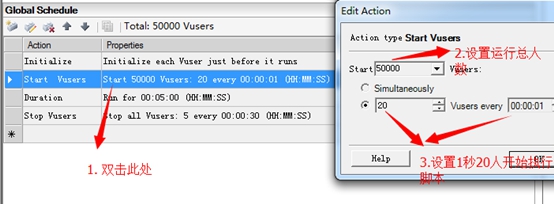
4.如下图,这个也是比较重要的在场景窗口,设置大于负载机实际运行的Vuser数
Ps:假如忘记设置,loadrunner默认一个负载机最大运行Vuser为5000人,当你设置Vuser超过5000人后,运行场景后,超过5000的Vuser会自动失败
2.3.2. 如何使用场景 1. 如下图,在本机的所有程序中打开Controller
2. 如下图,在弹出的窗口中点击Browser按钮,在弹出窗口选择脚本后点击OK
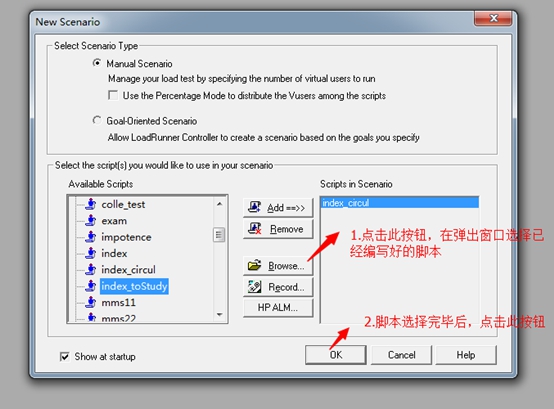
3. 如下图,新增负载机
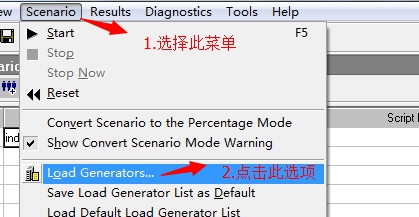
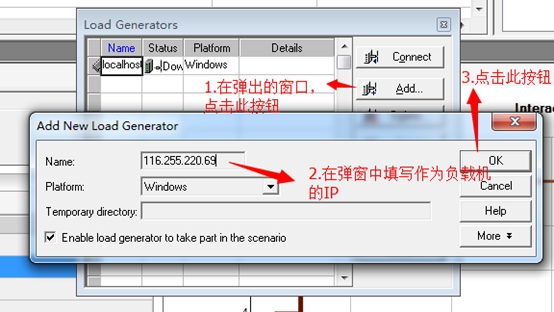
4. 如下图,在弹出窗口执行下图操作
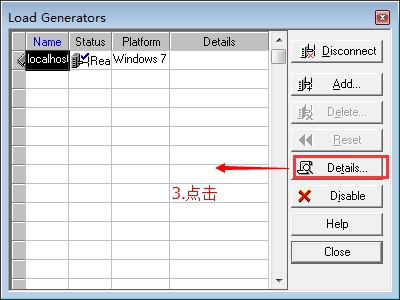
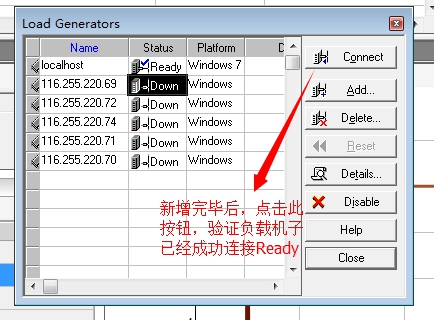
5. 如下图,验证负载机连接状态
6. 如下图,选择百分比模式,为了可以方便均衡分配负载机人数
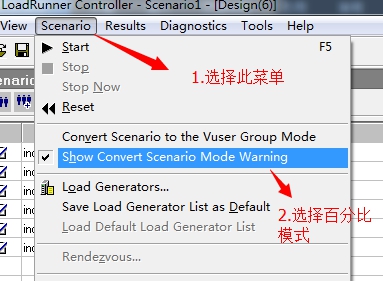
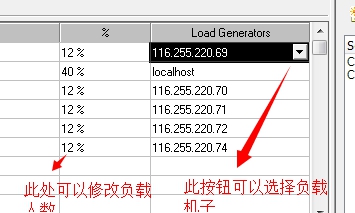
7. 如下图,选择负载机和负载机人数
8. 如下图,设置5w人执行脚本,1s/20人的速度开始执行场景
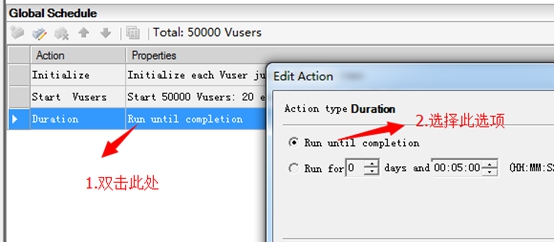
9. 如下图,设置场景执行:一直运行,直到所有人脚本执行完毕
10. 如下图,点击按钮,弹出框点击确定,即可开始执行场景

11. 如下图1,在切换至Run,可以查看运行过程中,所有Vuser运行情况,如图2;日志查看如图3
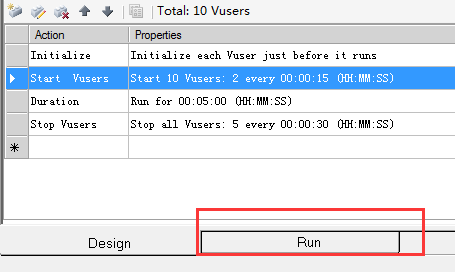
图1
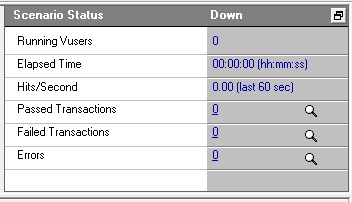
图2
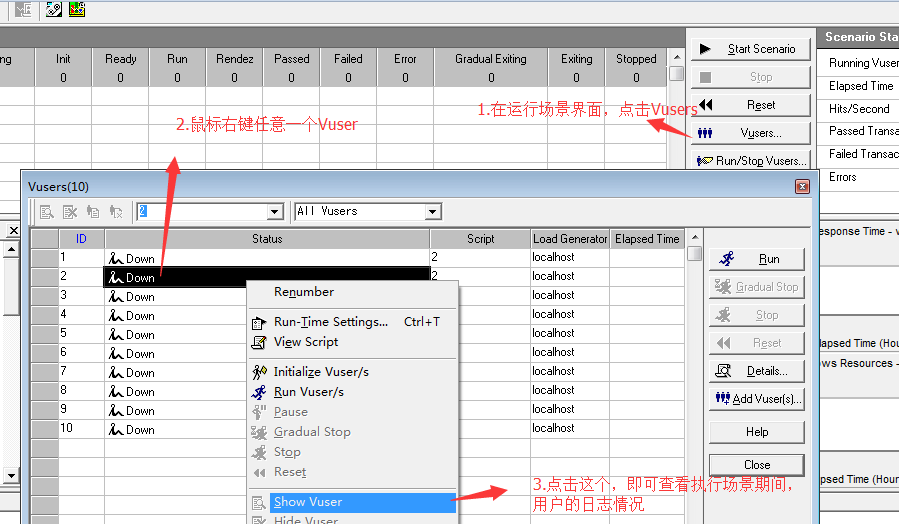
|








