| UML软件工程组织 | |||
| |
|||
|
|||
准备 XML 及相关技术认证考试,第 5 部分: XML 测试和调优
作者:Mark Lorenz 来源:IBM
| 选择适当的 XML 技术 下面几节讨论选择 XML 技术时应考虑和权衡的几种选择。 W3CDOM DOM 是 XML 或 HTML 文档的树状数据结构表示。现代 DOM 解析器包括 API 并符合一系列 W3C 标准规范。这样的解析器称为 W3CDOM 解析器。它独立于计算机语言和平台。较早的 DOM 解析器是厂商专有的,不像现在的 W3CDOM 解析器那样具有可移植性。本教程中提到 DOM 解析器或者 DOM 的时候,指的就是 W3CDOM。为了保证跨平台和语言的独立性,处理 DOM 的时候最好使用标准的 W3CDOM 解析器。 CRUD 创建 DOM 树可以使用解析器识别 XML 流,编程创建节点和属性,或者结合使用两种方法。DOM 解析器支持创建、读取、更新和删除(CRUD)DOM 元素的完整功能。如果使用 DOM API,创建和更新 XML 文档时不需要处理尖括号和 XML 语法。采取编程方式从字符串数据创建 XML 通常比较麻烦,而且容易出错。也可使用 XSLT 创建 XML 文档,但是它需要一个基础文档。如果不想创建或者把基础 XML 文档转换成新的文档,建议使用 DOM 解析器 API 创建和更新 XML 文档。 推与拉 Simple API for XML (SAX) 是一种 XML 串行流解析器。SAX 解析器应用程序使用推式数据模型,即目标元素或属性在 XML 输入流中出现的时候解析器调用应用程序。应用程序为每个需要处理的 SAX 事件注册一个回调方法。把这种推式模型和 DOM 的拉式模型相比,在后者,应用程序从 DOM 树中拉出需要的节点。 面向 SAX 的应用程序可以处理大型 XML 文档,只受到如何处理推出的数据的限制。应用程序仅对必要的节点或属性注册回调函数。解析操作中的其他元素被忽略,因此不会导致内存资源耗尽的问题。 有限的内存限制了面向 DOM 的应用程序,因为 DOM 解析器将整个文档都转换成内存中的树。另一方面,面向 DOM 的应用程序可以按照任意的顺序访问 XML DOM 节点。此外,如前所述,它还可以增加、修改或删除这些节点。SAX 应用程序不能直接修改节点或者按照自然文档顺序以外的顺序访问它们。 对于大型只读文档应该选择 SAX 解析器。如果需要随机访问 DOM 节点则应选择 DOM 解析器。叙述性文档与数据文档 XML 是一种标准化的元语言,用于创建定制的文档文法。它源自标准通用标记语言(SGML),一种复杂的文档标记语言。表 1 列出了叙述性 XML 文档的一些特点。 表 1. 叙述性 XML
我们发表的这一系列 XML developerWorks 教程都属于这一类。这篇教程文档是一篇未经雕琢的 XML 源文档,符合严格的叙述性 XML 模式。您看到的呈现结果是用 XSL 转换成的 HTML(在 Web 上呈现)或者 XSL 格式化对象(XSL-FO,PDF版本)。 XML 的标准化特性吸引了需要处理严格的层次化格式的数据的程序员。现在使用 XML 描述数据的应用程序无所不在。表 2 列出了用于描述数据的 XML 的一些特点。 表 2. 数据 XML
表 3 总结了表 1 和表 2 的不同。 表 3. 叙述性 XML 与数据 XML
在设计文档 XML 模式或文档对象类型(DTD)时应考虑到这些区别。事实上,面临的第一个选择是用 XML 模式还是 DTD 来约束文档。 XML 模式与 DTD 模式可以细粒度地控制文档格式 ―― 通常与叙述性形式有关,但是对数据文档也很重要。假设文档中包含邮政编码,并要求该元素只能使用五位或九位的数字。可能希望修改该模型来验证其他国家的邮政编码。比如,加拿大使用包含六个数字或字母的邮政编码。包含段落的文档不会对段落元素有任何长度或类型的要求。 显然,叙述性文档往往比类似数据库的文档更宽松。通常不需要在 XML 模式中设置很严格的规则。因此,叙述性文档通常选择 DTD 而不是模式定义文法。此外,人们常常匿名修改这些文档,因此标准的文法非常重要。有大量的标准 DTD 可以选择。HTML DTD 是叙述性 DTD 的一个例子。很多 DTD 都是针对专门的学科的。 奇怪的是,XML 模式很难定义一般实体,即类似符号宏的可重用数据定义。这些通常在面向叙述的文档中最有用。对叙述性 XML 文档应寻找和结合使用现成的 DTD 和词汇表。为了实现细粒度的控制,任何像数据库一般严格的词汇表都应该通过 XML 模式而不是 DTD 定义。 平面文件与 DBMS 可以在位于平面文件中的 XML 文档中存储复杂的数据。但是这可能只适用于少量的、只读数据。如果数据非常多或需要反复修改,或者需要并发访问,使用数据库管理系统(DBMS)可能更合适。如果需要繁重的 CRUD 或并发请求,或者要求可缩放,应考虑在 DBMS 中存储 XML 数据。 接下来要决定将数据转化成原生的关系表塞到 XML 二进制大对象(BLOB)中,还是放进 XML 字符串列中。应该仔细判断应用程序对数据的使用,要记住每个 XML 文档在使用的时候都需要解析。如果需要经常访问或更新 XML 文档中的一个小子集,最好将这些数据以关系形式保存并使用 SQL 访问。 DBMS 厂商对 XML 提供的支持越来越多,使 XQuery 越来越有吸引力。如果经常需要以只读的方式访问整个 XML 文档,可考虑将文档存储为 BLOB 或者字符列中,然后使用厂商的 XQuery DBMS 访问。 XML 和非 XML 数据的交换方法 简单对象访问协议(SOAP)、Really Simple Syndication 或 Rich Site Summary(RSS)、Electronic Business using eXtensible Markup Language (ebXML)以及 Value Object 设计模式都是使用面向数据的 XML 文档进行数据交换的例子。数据可能很复杂,数据的格式可以通过复杂的方案来约束。使用 XML 进行数据交换可以让不同的平台和语言能够创建或识别这些数据,因为 XML 是标准化的。XML 数据包含大量的统计冗余,在存储和传输的时候可进行压缩。 使用 XML 交换数据也有不利的一面。XML 非常罗嗦,特别是用元素而不是属性包含元数据的时候。软件更适合处理对象和 DOM 树而不是尖括号。序列化和逆序列化(也称为创建和解析,或编组与解组)的代价可能很高。 可以选择功能少但是更为简单的方法来代替 XML 数据交换模型,尤其是在能够控制交换的双方的情况下。逗号分隔的值(CSV)可以分隔简单重复或者位置敏感的数据,比如数据库表行或者电子表格数据。名值对可以定义和传递可操作的属性或者非类型化数据。JSON 是一种在许多其他语言中都有绑定的 JavaScript 数据结构。 这些方法都比不上 XML 与 XML 模式结合那么强大,但是从简化的角度出发都值得考虑。在考虑替代方案的时候,要记住 XML 提高了跨平台、跨语言、跨项目、跨数据格式的可移植性。如果使用 CSV,每一方都必须就逗号之间文本的含义达成一致。数据交换设计人员应该在数据交换设计中评估 XML 和替代方案,但是要记住 XML 可以传递语义或结构,能够方便地定义命名的数据片断。 XSLT 与 CSS 级联样式表(CSS)主要用于设置网页中格式美化和内容定位方面的样式。这种简单的语法不是 XML。它仅仅列出一些接收样式的 XML 元素。如果元素在名称空间中,则必须使用限定名。将 CSS 样式表附加到 XML 文档中需要使用下面这样的处理指令:
要注意,类型是 “text/css” 而非 “text/xsl”。可选的 media 属性使样式表只能用于给定的媒体类型。CSS 转换是关于呈现的 ―― 供人类阅读。 和 CSS 不同的是,应用 XSLT 样式表是为了创建 XML 文档。目标文档可以是其他数据描述或者可视化的 HTML,这要视具体的应用而定。因此,CSS 和 XSLT 都能创建可视化的呈现。哪种样式表合适呢?一般来说,XSLT 可以把语义数据转化成可视形式,而 CSS 仅用于可视化效果和对象的放置。通常使用 XSLT 而不是 CSS 将 XML 数据转化到可视层 HTML/XHTML。建议仅在设置 HTML 视觉特效或者对象放置的时候使用 CSS 转换,而不要用于后台数据的转换。 属性与元素 开发人员经常对使用属性还是元素感到迷惑。标准的回答是属性是元数据,即关于数据的数据,而元素定义文档结构。实际上区别并没有这么明显。比方说,也可以说所有 XML 组件都是元数据。 显然,属性是没有层次之分的扁平字符串。也没有先后顺序。如果某项内容需要这些特征,则它应该作为元素。 有人宣称所有的内容都应该是元素。元素的层次性通常更便于阅读。这是 XML 的设计标志之一。但是元素的层次结构要比属性占用更多的空间。如果认为 XML 过于冗长,可以设想一下不带属性的 HTML 是什么样子。在这种极端情况下,原始文档可能就不那么容易读了。 这一选择通常归结为审美观和风格 ―― 除非有顺序或层次的要求,或者需要类型约束,那么只能选择元素。 优化转换,精化设计 下面几小节讨论 XML 转换优化和细化的问题。 XLST XPath 表达式 XPath 是一种用于定位 XML 文档中特定部分的简洁的(非 XML)语法。应该考虑如何使用 XPath 表达式来访问文档。比如 // 运算符确定了从当前位置开始所有的后代节点。这种方法比有意地通过孩子节点导航的成本要高得多。同样的建议也适合查询中的通配符星号(*)。目标是尽量避免处理程序反复遍历整个文档。从 XPath 的性能出发,最好不要使用节点聚合的表达式。为提高性能应避免使用可能会盲目遍历大量节点的表达式:
相反应该使用准确匹配节点的元素:
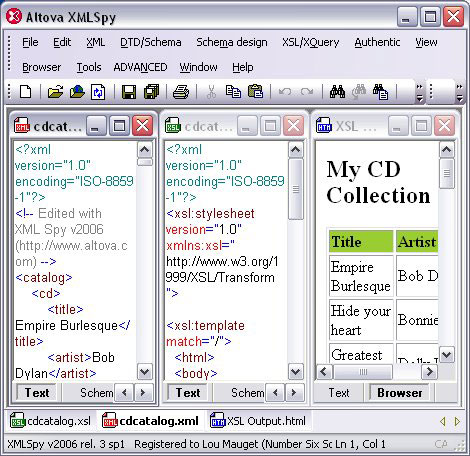
一种好的做法是用 <xsl:key /> tab 和 key() 函数建立名值对以便在复杂的文档中查找。 客户机还是服务器执行转换 在多层应用程序中,必须选择在什么地方执行可视化呈现的 XSLT 转换。如果在服务器上转换,跨客户浏览器可移植性的问题就简单一些。可以通过智能缓冲来优化操作,但另一方面可能要考虑并发请求的规模问题。 相反,也可以把转换周期转移到客户机上。对于公司内部的广域网(WAN)来说这可能是一种不错的选择,因为可以规定统一的浏览器。每个浏览器请求都加载一个 XML 文档和一个 XSLT 样式表(也可能是 CSS 样式表)。如果用户联在 Internet 上,可能会遇到各种各样的浏览器。新浏览器所支持的特性开始呈现出融合的趋势,但是要知道并非所有的 Internet 客户都有最新版本的浏览器。在考虑将转换移到客户浏览器上的时候,建议评估一下可缩放性和可移植性。 链接样式表与脚本转换 如果使用 XSLT 转换把数据呈现为 HTML 并决定在客户端执行 XSLT 转换,还需要做进一步的选择。XML 数据文档可以使用链接样式表。这种情况下,浏览器将尝试加载该样式表、执行转换并呈现结果。但 XML 文档是数据。不应该规定它的可视化呈现。实际上,它有可能在应用程序的不同地方呈现为不同的形式。比如,一个页面可能像 清单 1 那样显示整个 CD 目录,而下一个页面可能通过层层选择只显示 Bonnie Tyler 的 CD。 可以将视图和数据分开,通过客户机 JavaScript 执行转换。JavaScript 决定执行什么样的转换或者通过提供转换参数来控制它。 这里判断浏览器的类型非常重要。Internet Explorer 6.0 及以下版本通过私有的 ActiveX 控件执行 XSLT,而 Mozilla 和 Opera 使用内建的 XSLTProcessor 对象。Internet Explorer 7.0 将支持 XSLTProcessor,但是您不能指望整个公共 Web 社区都装上了新的浏览器。 另一方面,如果企业 WAN 指定了某种浏览器,就可以把内部应用程序设计成与这种浏览器捆绑在一起。当然,如果企业要发布新的指定,您可能会后悔引入了这种依赖性。这些是在设计应用程序时必须要考虑和权衡的。 例子 我们用脚本来实现一个 XSLT 转换。可以从 W3Schools 获得 清单 1 所示的 cdcatalog.xml(详情参阅 参考资料)。 清单 1. cdcatalog.xml
然后再从 W3Schools 下载 cdcatalog.xsl,如 清单 2 所示。该样式表生成一个 HTML 文件表格,按照在文档中存在的顺序(如果需要也可以在转换中增加排序)列出了收藏的 CD。 清单 2. cdcatalog.xsl
然后建立 ajax.js 脚本,如 清单 3 所示,保存在和 XML 文件与 XSL 文件相同的工作目录中。该脚本是独立于浏览器的。Mozilla 或 Opera 浏览器使用的 createRequest 函数返回一个 XMLHttpRequest 对象,通过 URL 请求一个文件。请注意,对于 Internet Explorer 浏览器,它返回一个 Microsoft ActiveX? 对象。 清单 3. ajax.js
现在创建 清单 4 所示的 HTML 文件,其中的 JavaScript 代码创建了两个异步请求对象。它使用一个请求对象加载 XML 文件,另一个请求对象加载 XSL 文件。这些对象不能重用,因此需要两个。 脚本使用 XSLTProcessor 对象应用转换,然后创建 DOM 节点。它将该 DOM 节点插入 HTML div 节点,完成 CD 目录的呈现。要在文档加载过程中调用 render 函数,因此调用必须出现在文档快结束的时候,在 div 标签之后,以便能够访问这个标记。 清单 4. catalog.html
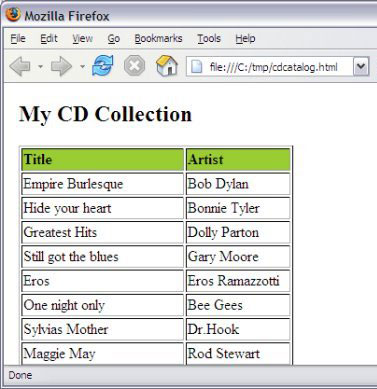
图 1 显示了在 Firefox 浏览器中的执行结果。在 Opera 上应该也能正常运行。但是在 Internet Explorer 6.0 或更低版本中不能工作,因为缺少 XSLTProcessor 对象。 图 1. W3Schools 脚本例子在 Firefox 中的运行结果 清单 5 显示的 catalogIE.html 按照 Internet Explorer 的方式执行同样的转换。该页面只能在 Internet Explorer 中打开,而不能用于 Firefox 或 Opera。如何将两个 JavaScript 控制的转换结合起来留给读者作为练习。如果使用 JavaScript 执行客户端转换,应小心地处理和测试浏览器的依赖问题。 清单 5. catalogIE.html
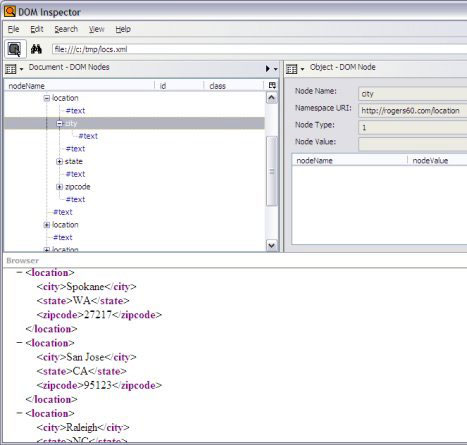
测试 XML 测试 XML这个短语常常指测试结构良好的文档、测试有效的文档、测试 XSLT 转换、测试 XQuery 查询等等。下面几小节考察了执行这些任务的免费工具或者商业工具的评估版本。认证考试不涉及到具体的工具,但是知道如何使用工具创建、转换、检查和验证 XML 文件以及相关的 DTD 和模式非常重要。 Firefox DOM Inspector 免费的 Mozilla Firefox 1.5 Web 浏览器安装包中带有一个 DOM Inspector,可用于查看和编辑任何 XML 或 HTML 文档的 DOM。在 Windows 安装程序包中该工具是可选的,请选择 Custom installation 选项然后在 Select components 对话框中单击 Developer Tools。检查 DOM 的时候只要打开目标文档。要调用 DOM Inspector,请访问 Tools > DOM Inspector 菜单,按 Ctrl+Shift+I,或者在命令行中输入 firefox -inspect c:\tmp\locs.xml。 图 2 显示了 DOM Inspector 中显示的 locs.xml 文档。该工具提供了几种显示模式,允许显示和编辑当前浏览器 DOM 中的任何部分,包括样式表和 JavaScript。更多信息请访问 Firefox DOM Inspector FAQ(详情参阅 参考资料)。 图 2. Firefox DOM Inspector
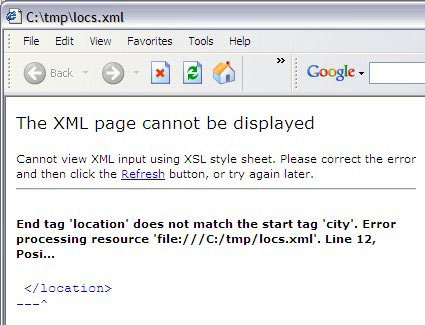
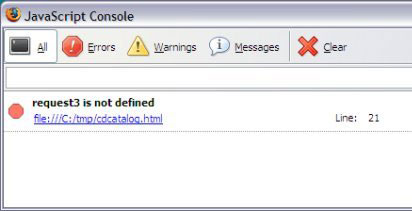
检查语法和有效性 如果浏览器能够执行通过/中止的 XML 语法检查和有效性检查,那么它就可以成为很好的帮手。只要让浏览器打开需要检查的本地或远程文档即可。出现语法错误的时候会显示类似 图 3 所示的页面。有效性错误也会导致浏览器显示和语法错误类似的结果,包含错误的说明。使用浏览器可以迅速检查文档的结构良好性和有效性。 图 3. Internet Explorer 中显示结构不良的 XML 文档 正确的文档呈现为一个可折叠的层次结构,如 图 4 所示,除非有链接的样式表或者 JavaScript 控制的能够生成 HTML 的转换。在这种情况下,结果会类似于本教程最后的 图 15,但前提是要保证一切正常。 图 4. Internet Explorer 中呈现结构良好的 XML 使用 Firefox JavaScript Console 如果存在简单的 JavaScript 错误,就无法从 JavaScript 执行 XSLT 转换请求。应用程序常常会悄悄地出现故障而不能正常工作。您知道有地方错了,但是在哪儿呢?Firefox JavaScript Console 可以列出需要修改的错误、警告和消息。要调用 JavaScript Console,请访问 Tools > JavaScript Console 菜单项。 每条消息都链接到引起该消息的源代码。图 5 在控制台中显示了一条错误消息,它指出了用于执行 链接样式表与脚本转换 一节中的 XSLT 转换的脚本中有意留下的错误。 图 5. Firefox JavaScript Console 图 6 显示了单击控制台中这条消息之后出现的错误。 图 6. JavaScript 错误
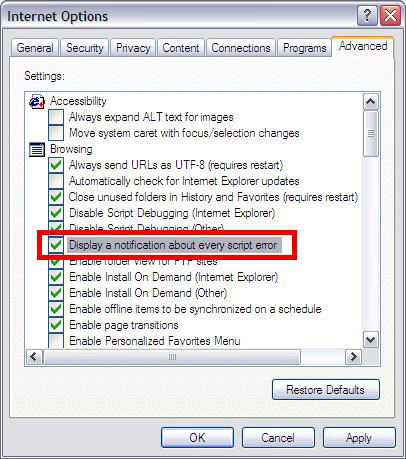
Internet Explorer 脚本调试 Internet Explorer 提供了 JavaScript(以及 VBScript)错误通知特性,可以警告脚本中发现的错误。从主菜单中单击 Tools > Internet Options,然后选择 Advanced 选项卡。启用 Browsing > Display a notification about every script error,如 图 7 所示。 图 7. 启用 Internet Explorer 脚本调试
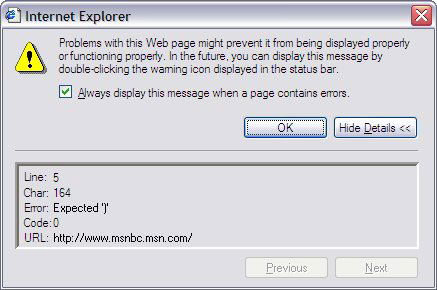
图 8 显示了脚本错误引起的弹出窗口。如果错误很少并且不想放过的话,这种弹出式的通知很方便。否则在开发周期中,Firefox JavaScript Console 会更有帮助。 图 8. Internet Explorer 中的脚本错误
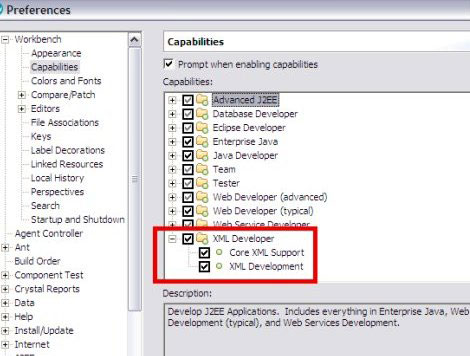
IBM Rational Application Developer 建立在 Eclipse IDE 基础上的 IBM Rational Application Developer 有一个 XML 编辑器,提供了网格视图和文本视图。还提供了运行 XSLT 的功能和一个调试器,能够运行转换或者为转换设置断点和单步执行方式,和其他应用程序的调试类似。 为了应用这些特性,需要启用 Rational Application Developer for XML。从 Window > Preferences 菜单中打开 Preferences 对话框。选择 Workbench > Capabilities,然后选中所有的 XML 项目,最后单击 Apply 或 OK。如 图 9 所示。 图 9. 启用 XML Developer 功能
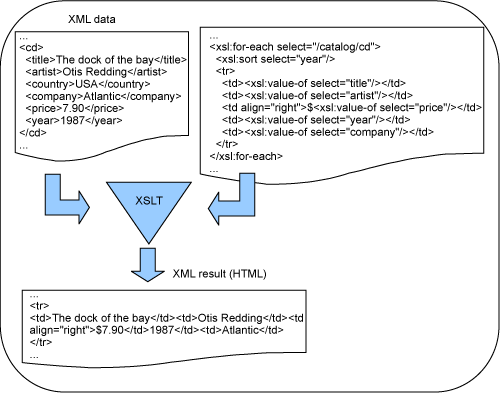
要获得帮助信息,请参阅 Rational Application Developer 帮助中的 Transforming and debugging XML and XSL files。 图 10 显示了使用 XSLT 样式表 cdcatalog.xsl 将 W3Schools 的 cdcatalog.xml 转化成 HTML 的基本流程。 图 10. XML 转换
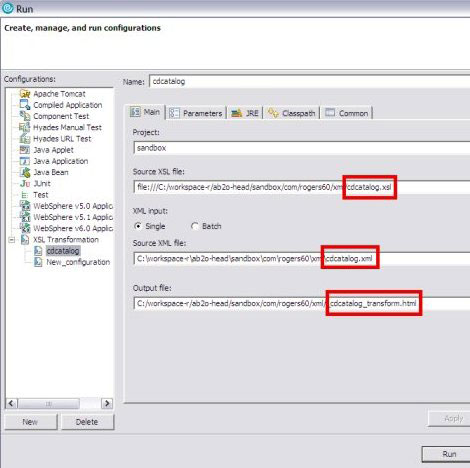
要在 Rational Application Developer 内运行或调试 XSLT 转换,可以在 Package Explorer 或 Navigator 视图下 XML 编辑器中右击 XML 文件。选择 Run > XSL Transformation 运行转换并创建可重用的配置文件。 下一次编辑该配置文件的时候可选择 Run 菜单。可以将输出文件的扩展名改成任何文件类型。请参阅 图 11 所示的 cdcatalog Run 配置文件。 图 11. XSLT Run 配置文件
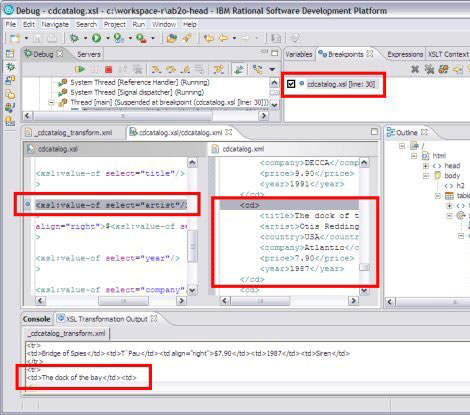
如果选择 xml,结果文件将显示在 XML Editor,如 图 12 所示。图 12 显示了 Rational Application Developer 在其 XSLT 调试器中执行转换时停到了一个断点上。请注意出现的 Run、Halt 和 Step 控件的用法与调试 Java 程序或 JavaServer Pages?(JSP)时相同。和通常一样,Breakpoints 视图允许禁用或者删除断点。 图 12. 用 Rational Application Developer 调试 XSLT
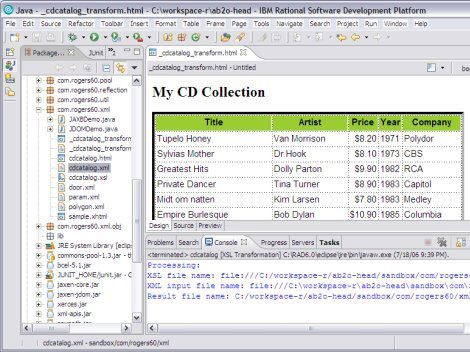
如果选择扩展名 html 或 htm,结果文件将作为 HTML 呈现在集成的浏览器中(如 图 13 所示)。 图 13. XSLT 转换所生成的 HTML
Altova XMLSpy Altova XMLSpy 是一种需要购买许可证的产品,它的主要特点是支持对 XML 文档、DTD、XML 模式、XSLT、XQuery、Web 服务描述语言(WSDL)及其他 XML 技术进行高级的结构化编辑、验证和测试。 如果暂时不想购买完整的产品,Altova 还提供了可免费下载的 XMLSpy Home Edition,其功能也比 Altova 的 circa 2001 完整版更丰富。安装过程中将在 Internet Explorer Web 浏览器中创建 Tools > Edit with Altova XMLSpy 菜单项。XMLSpy Home Edition 可执行下列测试和文档编辑任务:
清单 6 所示的 locs.xsd 模式和 清单 7 中所示对应的 locs.xml 示例文档,都是利用了 XMLSpy Home Edition 的主动帮助提示功能创建的(我曾经用它来编辑这篇教程)。当然,还有其他多种 XML 编辑器可供选择,比如 XMLBuddy(请参阅 参考资料)。 清单 6. locs.xsd
清单 7. locs.xml
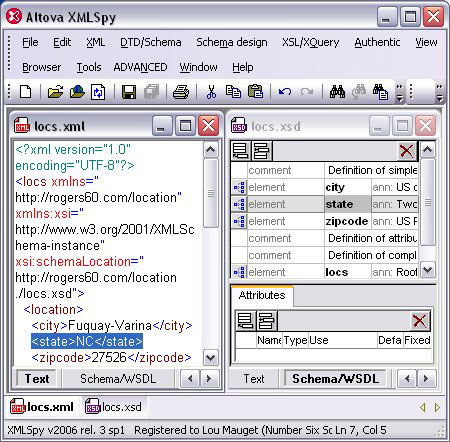
图 14 显示了 locs.xml 和关联的模式 locs.xsd。要针对模式验证文档,可以按 F8。 图 14. XMLSpy 显示的文档和模式 图 15. 呈现为 HTML 的 CD 目录
XMLSpy Home Edition 有一个高级菜单邀请您在一定时间内尝试其他的功能或者升级到完整版。可以购买的功能有:
结束语 总结 本系列教程的第 1 到第 4 部分讨论了 XML 及相关技术的的应用方面(参考资料)。本教程作为最后一部分,介绍了如何针对手头的问题选择适当的 XML 技术。还讨论了如何优化转换和细化设计以及不当的选择对性能的影响,并举例说明了如何使用常见的工具测试 XML 设计,以及使用常见的工具又该如何测试 XML。 学习完本系列教程后,您将具备足够的背景知识来参加 IBM 认证考试 142 “XML 及相关技术” 并通过 IBM Certified Solution Developer ―― XML 及相关技术认证。 |

组织简介 | 联系我们 | Copyright 2002 ® UML软件工程组织 京ICP备10020922号 京公海网安备110108001071号 |