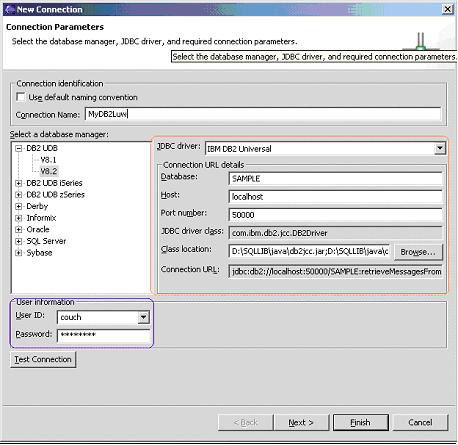
| 概述 我们的场景是一个 DB2 UDB 的端到端的任务流,您在其中开发和调试一个 SQL 的存储过程。开始建立一个到 DB2 LUW 数据库的连接,该数据库提供数据开发工程的环境,在其中您将开发一个过程。开发工程连接到此连接上,所以您可以获得创建 SQL 的完整帮助,及部署和调试存储过程的功能。您将生成一条包含于您将开发的 SQL 存储过程中的 SQL 语句。 此场景中的步骤包括: 连接到 DB2 数据库 第一步是添加一个到数据库的连接。您将利用 IBM DB2 Universal JDBC 驱动器连接到 SAMPLE1 数据库。 在 Database Explorer 中,单击 New Connection 创建一个新的连接。 图 1. Database Explorer 图 2. New Connection
图 3. Test Connection 成功 单击 OK 然后单击 Finish,完成数据库的连接。Database Explorer 刷新了,连接文件夹添加到了连接树上。当点击该连接时,Properties 浏览器中显示出连接的信息。 图 4. 激活的 Connection 属性 既然您有了到 DB2 的连接,那么就创建一个数据开发工程: 在 File 菜单中选择 New > Data Development Project。
图 5. New Data Development Project 新建的工程加入到了 Data Project Explorer 中。 图 6. Data Project Explorer 中的新工程 生成一条 SQL 语句 利用 EmpAnalysis 工程创建一条 SQL 语句。 展开 EmpAnalysis 工程并右键单击 SQL Scripts 文件夹,打开 New
SQL Statement 窗口。在第一个面板中单击 Next,在 EmpAnalysis 工程中进行开发。为创建的 SQL
语句输入一个名称,如 MinSalary。保留 Statement Template 和编辑器的默认值,并单击 Finish。SQL
构造器在编辑器窗格中打开。 图 7. 向 SQL 构造器中添加表格 在适当的表格中选择列。如图 8 所示,在 EMPLOYEE 表格中选择列 FRSTNAME 和 LASTNAME。在 DEPARTMENT 表格中选取DEPTNAME。 图 8. 在表格中选取的列 利用表达式构造器可以向查询结果中加入一个表达式。 在列格中,双击 DEPARTMENT.DEPTNAME 之后的行。下滚到底部,并在列表中选择
Build Expression...,并选择Enter。Expression Builder 启动了。选择最后一个单选按钮,Build
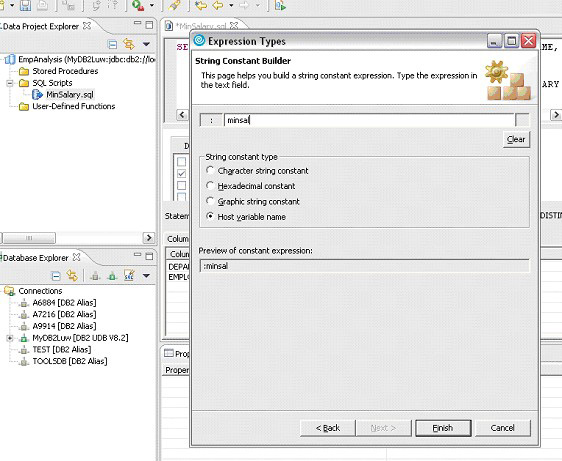
up expression by operators。 选择 Next 转到 Expressions by Operators 面板。 图 10. Expression Builder 必要时增加条件和主机变量,如 图 11 所示。例如, 图 11. 添加条件和主变量 在 Expression Types 面板中,选择 Constant-numeric, string
or host variable,然后选择 Next。 图 12. String Constant Builder 执行 SQL 语句 在 Data Project Explorer 下的 SQL 语句(MinSalary.sql)上单击右键,并选择
Run SQL 执行该语句。如果需要一个主变量值,就会打开一个窗口,用来输入主变量的值,如图 13 所示。输入值 50000,按下
Enter,并选择 Finish。 输入视图显示出执行状态和结果。 图 14. 执行状态和结果 创建一个 SQL 存储过程 既然您已经创建并执行了一条 SQL 语句,那么是时候创建一个存储过程了。 在工程 EmpAnalysis 中右键单击 Stored Procedures 文件夹,并选择
New > Stored Procedure。New Stored Procedure 向导启动了。(或者,您可以通过
File > New > Stored Procedure。) 图 15. 导入 SQL 语句 在 Parameters 面板中,验证表格中出现参数 In,如图 16 所示。该参数用作 SQL 语句中的主变量。选择 Next。 图 16. 参数 在 Deploy Options 面板中,选择 Deploy 复选框,并选择 Finish。新的过程出现在工程及
SQL 编辑器中。 图 17. Data Output 视图 编辑 SQL 过程 要编辑一个 SQL 过程: 双击 Data Project Explorer 中的存储过程,以在编辑器中打开。 添加一个
OUT 参数。例如, OUT MINPAY DECIMAL(9,2) 图 18. 在 SQL 存储过程中插入一条新的 SQL 语句 部署存储过程 在数据开发工程中创建的过程可以通过 Deploy Routines 向导部署到目标数据库上。 在创建的 SQL 存储过程上单击右键,上下文菜单启动了。选择 Deploy...。 图 19. Data output 视图 调试存储过程 要设置断点: 如果存储过程没打开,就在编辑器中打开该存储过程(本例中为 MINPAID)。 右键单击存储过程(MINPAID),并选择 Debug。一个新的 Stored Procedure Debugger 启动配置打开了。 图 20. Stored Procedure Debugger 启动配置 如果该过程有输入参数,那么在 Main 选项卡上,Argument 列表右边选择 Edit...,并输入值。对于此实例,输入工资 50000.00,如图 20 所示。 在 Preference 选项卡上,可以变更过程应返回的最大行数。选择 Apply,然后选择 Debug。 如果提示切换到 Debug 透视图,就选择OK。调试器打开过程源码,并且执行到断点处停止。
执行存储过程 仅仅执行存储过程的测试调用来确保其工作情况而不是对其调试是可能的。要通过执行测试调用来运行存储过程: 选择工程中的存储过程(本实例中是 EmpAnalysis 和 MINPAID),单击右键并选择
Run(或者在 Database Explorer 视图中,方案和存储过程文件夹下选择 Run a procedure,只要列表中的已部署的过程定位了)。
此部分罗列出在 CVS 中共享一个工程所需的步骤(如果您有权访问 CVS)。Rational Data Architect 还与 IBM Rational ClearCase 充分集成。 启用 Team 功能: Rational Data Architect 是数据建模和集成设计工具,其特定的集成使您通过一个单一的界面建模、构建、测试并部署 DB2 数据库。本教程介绍了有关利用 Rational Data Architect 执行数据库开发的基本概念。然而,本教程中的信息只是对 Rational Data Architect 丰富的功能走马观花。 如果您是一个数据架构师或数据库管理员,我强烈推荐您更详细地研究 Rational Data Architect 的其他特性。这些特性包括发现、映射、建模,和集成设计。要充分了解 Rational Data Architect 提供的所有功能,请下载试用代码并研究此产品的功能。 |