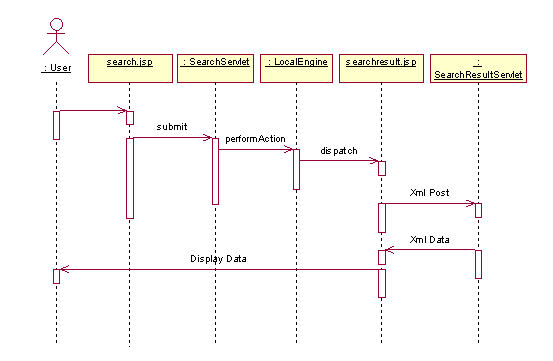
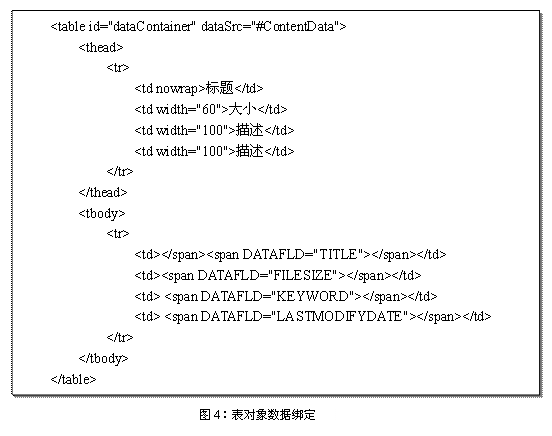
| 网络检索无处不在!无论是显而易见的搜索引擎,还是论坛、网上购物目录等,都频繁地使用网络检索。因此,我们这里的“网络检索”定义为用户通过网络提交一定的检索条件(如关键词信息)到服务器上的检索应用中,并获取和呈现检索应用所返回的结果。 检索方式 一般来说,当检索的结果集过大时(经常出现非常大的情况),采取分页数据显示的策略,即每次返回结果集中的小部分数据,通过类似“上一页”、“下一页”的操作来查看更多的结果。用户的期望是提交的检索能够很快得到响应,而且进行“上一页”、“下一页”的操作时也能够很快得到响应。因此,问题的关键在于根据用户提供的记录起始位置和需要记录数量来获取每一次所需要使用的结果数据。目前存在一些使用较多的方式。 1) 用户提交的检索条件每次都被重新执行,然后获取检索结果集的一个子集。用户的检索条件被保存在Cookie、Session或者HTML的表单隐藏元素(“<input type=hidden value=条件>”)中。由于检索操作需要对服务器和数据库资源的大量使用,因此,每次执行检索无疑会增加这种负担,降低检索应用的效率。 2) 将全部的检索结果取出放到一个大的对象中,该对象实现了对记录的各种操作。同时如果将该对象缓存在服务器上,那么以后的翻页操作都不需要重新执行检索条件而直接从该对象中获取结果的子集。然而,将全部检索结果保存到对象中的操作本身就比较复杂,而且如果结果集很大,则意味着缓存该对象需要占用大量宝贵的服务器资源。同时,首次结果的显示速度可能不会令人满意。 3) 一次获取“几页”的结果子集并保存到对象中并缓存起来,如果用户的“下一页”操作超出了当前对象提供的数据,则再次执行检索条件,获取满足条件的“又几页”并保存到同一个对象中。出现这种情况的考虑是,用户在使用检索时,可能只会查看最开始的一些记录,而很少进行到相对后面的记录。从这种意义上看,不失为一种比较好的方式。但如果移动到未缓存的记录时,又必须重新执行查询,同时降低结果显示的速度。 4) 在首次执行检索时,先将全部能够唯一确定每条记录的编号(如主键)保存到对象中并缓存起来,以后对每一页的请求首先在缓存的主键对象中找出满足条件的主键集合,再重新建立查询语句(使用IN关键字)取得该页需要的记录,这样能够准确定义每次需要的检索范围,从而也只是取得所需要的数据。当然,如果某个表不存在这种唯一编号或者主键就无法进行。 5) 在一些检索应用中,如论坛的帖子显示,可以用一个公共的缓存区来保存部分的帖子,当用户请求某一页时执行的查询仅仅取得帖子的主键,根据这些主键到公共缓存区中去取得记录。如果对应主键的记录不存在,则使用该主键查询出记录同时保存该记录到公共缓存区。这种方式适用于多个用户检索的结果大部分相同的情况,正如论坛帖子的显示。 6) 如果是在J2EE体系结构中,使用EJB的Finder方法也可以返回对象的集合,而这样的一个对象封装了每条记录的数据。但是,大量对象的生成和存在于服务器内存中无疑也是对服务器资源的巨大消耗。因此,对于存在大量记录的结果集使用实体Bean来代表每条记录会耗尽系统资源而且实际上并不能够获得太多的好处。 网络检索的关键在于检索的执行效率、网络传输速度和结果集的使用方式。综合来看,网络检索的模式都是通过提供的检索条件,来构建一个能够被数据库使用的、优化的SQL查询语句,由数据库执行并返回记录集,再根据这些记录集来生成显示页面。 因此,在中间层及数据层,我们着重考虑如何高效地生成每次所需的结果数据;在表示层,即面向用户的层面则需要提供友好、方便的显示和操作界面。 实现机制 |