| БрМЭЦМі: |
БОЮФжївЊНщЩмСЫОэЛ§ЩёОЭјТчМђНщЁЂОэЛ§ЩёОЭјТчЕФЁАОэЛ§ЁБ
ЁЂОэЛ§ЩёОЭјТчМАCNNЭМЯёЗжРр-keras ЁЃЯЃЭћЖдФњЕФбЇЯАгаЫљАяжњЁЃ
БОЮФРДздЮЂаХЙЋжкКХCSDNММЪѕЩчЧјЃЌгЩЛ№СњЙћШэМўLindaБрМЁЂЭЦМіЁЃ |
|
вЛЁЂОэЛ§ЩёОЭјТчМђНщ
ОэЛ§ЩёОЭјТчЃЈConvolutional Neural Networks,
CNNЃЉЪЧвЛРрАќКЌОэЛ§МЦЫуЕФЧАРЁЩёОЭјТчЃЌЪЧЛљгкЭМЯёШЮЮёЕФЦНвЦВЛБфадЃЈЭМЯёЪЖБ№ЕФЖдЯѓдкВЛЭЌЮЛжУгаЯрЭЌЕФКЌвхЃЉЩшМЦЕФЃЌЩУГЄгІгУгкЭМЯёДІРэЕШШЮЮёЁЃдкЭМЯёДІРэжаЃЌЭМЯёЪ§ОнОпгаЗЧГЃИпЕФЮЌЪ§ЃЈИпЮЌЕФRGBОиеѓБэЪОЃЉЃЌвђДЫбЕСЗвЛИіБъзМЕФЧАРЁЭјТчРДЪЖБ№ЭМЯёНЋашвЊГЩЧЇЩЯЭђЕФЪфШыЩёОдЊЃЌГ§СЫЯдЖјвзМћЕФИпМЦЫуСПЃЌЛЙПЩФмЕМжТаэЖргыЩёОЭјТчжаЕФЮЌЪ§джФбЯрЙиЕФЮЪЬтЁЃ
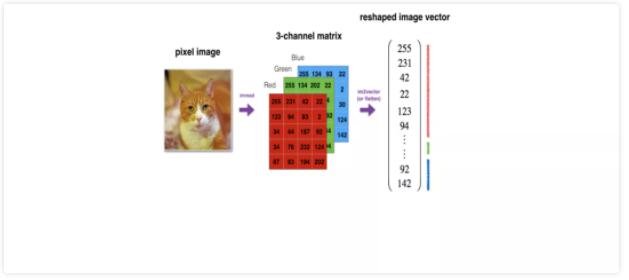
ЖдгкИпЮЌЭМЯёЪ§ОнЃЌОэЛ§ЩёОЭјТчРћгУСЫОэЛ§КЭГиЛЏВуЃЌФмЙЛИпаЇЬсШЁЭМЯёЕФживЊЁАЬиеїЁБЃЌдйЭЈЙ§КѓУцЕФШЋСЌНгВуДІРэЁАбЙЫѕЕФЭМЯёаХЯЂЁБМАЪфГіНсЙћЁЃЖдБШБъзМЕФШЋСЌНгЭјТчЃЌОэЛ§ЩёОЭјТчЕФФЃаЭВЮЪ§ДѓДѓМѕЩйСЫЁЃ 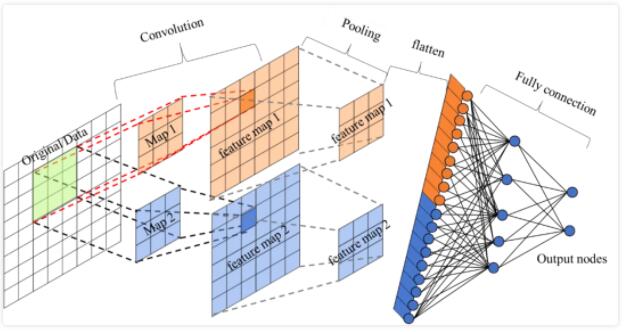
ЖўЁЂОэЛ§ЩёОЭјТчЕФЁАОэЛ§ЁБ
2.1 ОэЛ§дЫЫуЕФдРэ
дкаХКХДІРэЁЂЭМЯёДІРэКЭЦфЫќЙЄГЬ/ПЦбЇСьгђЃЌОэЛ§ЖМЪЧвЛжжЪЙгУЙуЗКЕФММЪѕЃЌОэЛ§ЩёОЭјТчЃЈCNNЃЉетжжФЃаЭМмЙЙОЭЕУУћгкОэЛ§МЦЫуЁЃЕЋЪЧЃЌЩюЖШбЇЯАСьгђЕФЁАОэЛ§ЁББОжЪЩЯЪЧаХКХ/ЭМЯёДІРэСьгђФкЕФЛЅЯрЙиЃЈcross-correlationЃЉЃЌЛЅЯрЙигыОэЛ§ЪЕМЪЩЯЛЙЪЧгааЉВювьЕФЁЃОэЛ§ЪЧЗжЮіЪ§бЇжавЛжжживЊЕФдЫЫуЁЃМђЕЅЖЈвхf
, g ЪЧПЩЛ§ЗжЕФКЏЪ§ЃЌСНепЕФОэЛ§дЫЫуШчЯТЃК 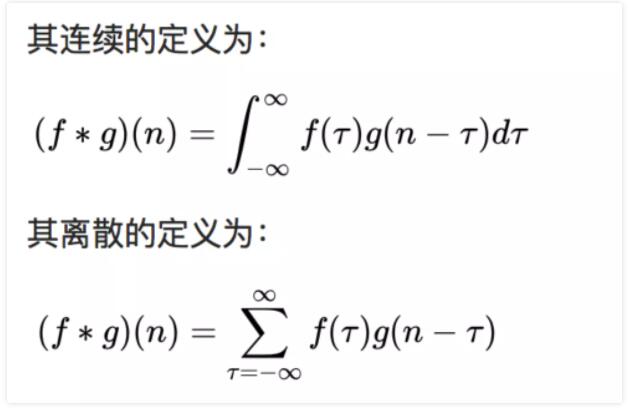
ЦфЖЈвхЪЧСНИіКЏЪ§жавЛИіКЏЪ§ЃЈgЃЉОЙ§ЗДзЊКЭЮЛвЦКѓдйЯрГЫЕУЕНЕФЛ§ЕФЛ§ЗжЁЃШчЯТЭМЃЌКЏЪ§ g ЪЧЙ§ТЫЦїЁЃЫќБЛЗДзЊКѓдйбиЫЎЦНжсЛЌЖЏЁЃдкУПвЛИіЮЛжУЃЌЮвУЧЖММЦЫу
f КЭЗДзЊКѓЕФ g жЎМфЯрНЛЧјгђЕФУцЛ§ЁЃетИіЯрНЛЧјгђЕФУцЛ§ОЭЪЧЬиЖЈЮЛжУГіЕФОэЛ§жЕЁЃ 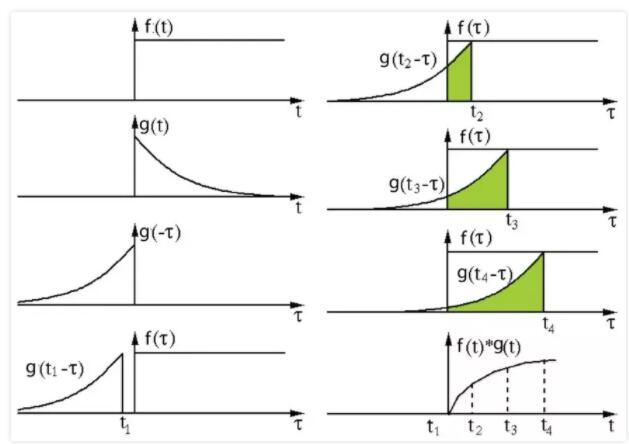
ЛЅЯрЙиЪЧСНИіКЏЪ§жЎМфЕФЛЌЖЏЕуЛ§ЛђЛЌЖЏФкЛ§ЁЃЛЅЯрЙижаЕФЙ§ТЫЦїВЛОЙ§ЗДзЊЃЌЖјЪЧжБНгЛЌЙ§КЏЪ§ fЃЌf гы
g жЎМфЕФНЛВцЧјгђМДЪЧЛЅЯрЙиЁЃ 
ЯТЭМеЙЪОСЫОэЛ§гыЛЅЯрЙидЫЫуЙ§ГЬЃЌЯрНЛЧјгђЕФУцЛ§БфЛЏЕФВювьЃК 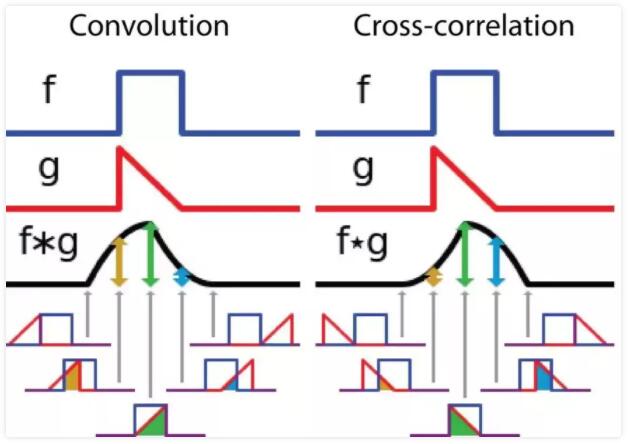
дкОэЛ§ЩёОЭјТчжаЃЌОэЛ§жаЕФЙ§ТЫЦїВЛОЙ§ЗДзЊЁЃбЯИёРДЫЕЃЌетЪЧРыЩЂаЮЪНЕФЛЅЯрЙидЫЫуЃЌБОжЪЩЯЪЧжДааж№дЊЫиГЫЗЈКЭЧѓКЭЁЃЕЋСНепЕФаЇЙћЪЧвЛжТЃЌвђЮЊЙ§ТЫЦїЕФШЈжиВЮЪ§ЪЧдкбЕСЗНзЖЮбЇЯАЕНЕФЃЌОЙ§бЕСЗКѓЃЌбЇЯАЕУЕНЕФЙ§ТЫЦїПДЦ№РДОЭЛсЯёЪЧЗДзЊКѓЕФКЏЪ§ЁЃ
2.2 ОэЛ§дЫЫуЕФзїгУ
CNNЭЈЙ§ЩшМЦЕФОэЛ§КЫЃЈconvolution filterЃЌвВГЦЮЊkernelЃЉгыЭМЦЌзіОэЛ§дЫЫуЃЈЦНвЦОэЛ§КЫШЅж№ВНзіГЫЛ§ВЂЧѓКЭЃЉЁЃ 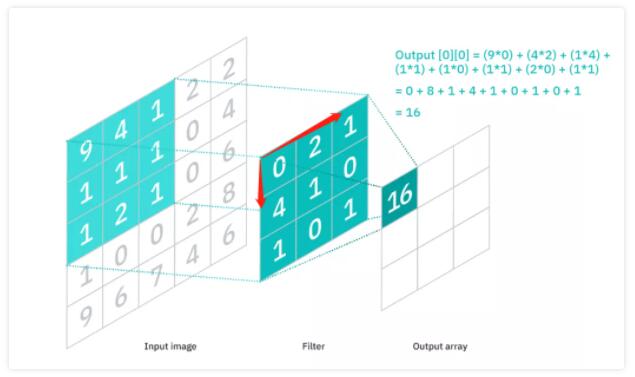
ШчЯТЪОР§ЩшМЦвЛИіЃЈЬиЖЈВЮЪ§ЃЉЕФ3ЁС3ЕФОэЛ§КЫЃК 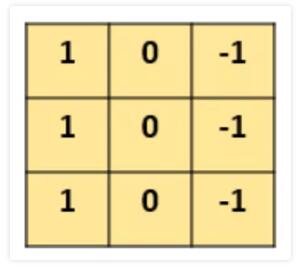
ШУЫќШЅИњЭМЦЌзіОэЛ§ЃЌОэЛ§ЕФОпЬхЙ§ГЬЪЧЃК
гУетИіОэЛ§КЫШЅИВИЧдЪМЭМЦЌЃЛ
ИВИЧвЛПщИњОэЛ§КЫвЛбљДѓЕФЧјгђжЎКѓЃЌЖдгІдЊЫиЯрГЫЃЌШЛКѓЧѓКЭЃЛ
МЦЫувЛИіЧјгђжЎКѓЃЌОЭЯђЦфЫћЧјгђХВЖЏЃЈМйЩшВНГЄЪЧ1ЃЉЃЌМЬајМЦЫуЃЛ
жБЕНАбдЭМЦЌЕФУПвЛИіНЧТфЖМИВИЧЕНЮЊжЙЃЛ
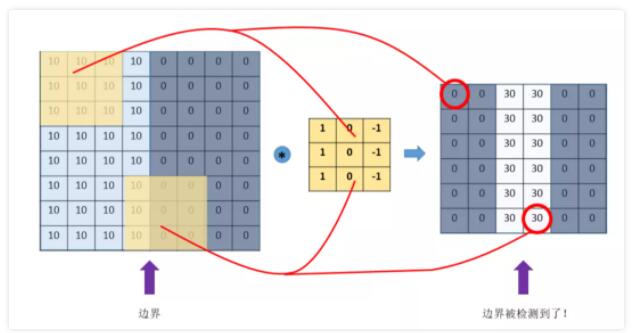
ПЩвдЗЂЯжЃЌЭЈЙ§ЬиЖЈЕФfilterЃЌШУЫќШЅИњЭМЦЌзіОэЛ§ЃЌОЭПЩвдЬсШЁГіЭМЦЌжаЕФФГаЉЬиеїЃЌБШШчБпНчЬиеїЁЃ
НјвЛВНЕФЃЌЮвУЧПЩвдНшжњХгДѓЕФЪ§ОнЃЌзуЙЛЩюЕФЩёОЭјТчЃЌЪЙгУЗДЯђДЋВЅЫуЗЈШУЛњЦїШЅздЖЏбЇЯАетаЉОэЛ§КЫВЮЪ§ЃЌВЛЭЌВЮЪ§ОэЛ§КЫЬсШЁЬиеївВЪЧВЛвЛбљЕФЃЌОЭФмЙЛЬсШЁГіОжВПЕФЁЂИќЩюВуДЮКЭИќШЋОжЕФЬиеївдгІгУгкОіВпЁЃ 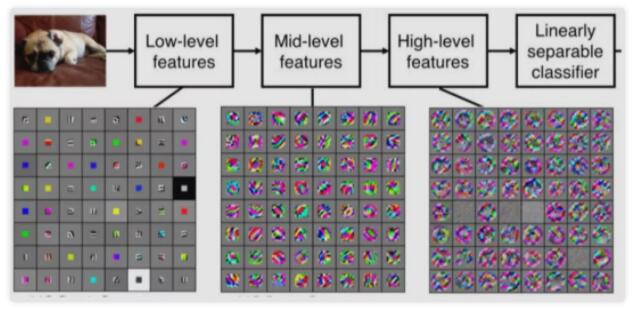
ОэЛ§дЫЫуЕФБОжЪадзмНсЃКЙ§ТЫЦї(g)ЖдЭМЦЌ(f)жДааж№ВНЕФГЫЗЈВЂЧѓКЭЃЌвдЬсШЁЬиеїЕФЙ§ГЬЁЃОэЛ§Й§ГЬПЩЪгЛЏПЩЗУЮЪЃКhttps://poloclub.github.io/cnn-explainer/
Лђ https://github.com/vdumoulin/conv_arithmetic
Ш§ЁЂОэЛ§ЩёОЭјТч
ОэЛ§ЩёОЭјТчЭЈГЃгЩ3ИіВПЗжЙЙГЩЃКОэЛ§ВуЃЌГиЛЏВуЃЌШЋСЌНгВуЁЃМђЕЅРДЫЕЃЌОэЛ§ВуИКд№ЬсШЁЭМЯёжаЕФОжВПМАШЋОжЬиеїЃЛГиЛЏВугУРДДѓЗљНЕЕЭВЮЪ§СПМЖ(НЕЮЌ)ЃЛШЋСЌНгВугУгкДІРэЁАбЙЫѕЕФЭМЯёаХЯЂЁБВЂЪфГіНсЙћЁЃ

3.1 ОэЛ§ВуЃЈCONVЃЉ
3.1.1 ОэЛ§ВуЛљБОЪєад
ОэЛ§ВужївЊЙІФмЪЧЖЏЬЌЕиЬсШЁЭМЯёЬиеїЃЌгЩТЫВЈЦїfiltersКЭМЄЛюКЏЪ§ЙЙГЩЁЃвЛАувЊЩшжУЕФГЌВЮЪ§АќРЈfiltersЕФЪ§СПЁЂДѓаЁЁЂВНГЄЃЌМЄЛюКЏЪ§РраЭЃЌвдМАpaddingЪЧЁАvalidЁБЛЙЪЧЁАsameЁБЁЃ
ОэЛ§КЫДѓаЁЃЈKernelЃЉЃКжБЙлРэНтОЭЪЧвЛИіТЫВЈОиеѓЃЌЦеБщЪЙгУЕФОэЛ§КЫДѓаЁЮЊ3ЁС3ЁЂ5ЁС5ЕШЁЃдкДяЕНЯрЭЌИаЪмвАЕФЧщПіЯТЃЌОэЛ§КЫдНаЁЃЌЫљашвЊЕФВЮЪ§КЭМЦЫуСПдНаЁЁЃОэЛ§КЫДѓаЁБиаыДѓгк1ВХгаЬсЩ§ИаЪмвАЕФзїгУЃЌЖјДѓаЁЮЊХМЪ§ЕФОэЛ§КЫМДЪЙЖдГЦЕиМгpaddingвВВЛФмБЃжЄЪфШыfeature
mapГпДчКЭЪфГіfeature mapГпДчВЛБфЃЈМйЩшnЮЊЪфШыПэЖШЃЌdЮЊpaddingИіЪ§ЃЌmЮЊОэЛ§КЫПэЖШЃЌдкВНГЄЮЊ1ЕФЧщПіЯТЃЌШчЙћБЃГжЪфГіЕФПэЖШШдЮЊnЃЌЙЋЪНЃЌn+2d-m+1=nЃЌЕУГіm=2d+1ЃЌашвЊЪЧЦцЪ§ЃЉЃЌЫљвдвЛАуЖМгУ3зїЮЊОэЛ§КЫДѓаЁЁЃ
ОэЛ§КЫЪ§ФПЃКжївЊЛЙЪЧИљОнЪЕМЪЧщПіЕїећЃЌ вЛАуЖМЪЧШЁ2ЕФећЪ§ДЮЗНЃЌЪ§ФПдНЖрМЦЫуСПдНДѓЃЌЯргІФЃаЭФтКЯФмСІдНЧПЁЃ
ВНГЄЃЈStrideЃЉЃКОэЛ§КЫБщРњЬиеїЭМЪБУПВНвЦЖЏЕФЯёЫиЃЌШчВНГЄЮЊ1дђУПДЮвЦЖЏ1ИіЯёЫиЃЌВНГЄЮЊ2дђУПДЮвЦЖЏ2ИіЯёЫиЃЈМДЬјЙ§1ИіЯёЫиЃЉЃЌвдДЫРрЭЦЁЃВНГЄдНаЁЃЌЬсШЁЕФЬиеїЛсИќОЋЯИЁЃ
ЬюГфЃЈPaddingЃЉЃКДІРэЬиеїЭМБпНчЕФЗНЪНЃЌвЛАугаСНжжЃЌвЛжжЪЧЁАvalidЁБЃЌЖдБпНчЭтЭъШЋВЛЬюГфЃЌжЛЖдЪфШыЯёЫижДааОэЛ§ВйзїЃЌетбљЛсЪЙЪфГіЬиеїЭМЯёГпДчБфЕУИќаЁЃЌЧвБпдЕаХЯЂШнвзЖЊЪЇЃЛСэвЛжжЪЧЛЙЪЧЁАsameЁБЃЌЖдБпНчЭтНјааЬюГфЃЈвЛАуЬюГфЮЊ0ЃЉЃЌдйжДааОэЛ§ВйзїЃЌетбљПЩЪЙЪфГіЬиеїЭМЕФГпДчгыЪфШыЬиеїЭМЕФГпДчвЛжТЃЌБпдЕаХЯЂвВПЩвдЖрДЮМЦЫуЁЃ
ЭЈЕРЃЈChannelЃЉЃКОэЛ§ВуЕФЭЈЕРЪ§ЃЈВуЪ§ЃЉЁЃШчВЪЩЋЭМЯёвЛАуЖМЪЧRGBШ§ИіЭЈЕРЃЈchannelЃЉЁЃ
МЄЛюКЏЪ§ЃКжївЊЛЙЪЧИљОнЪЕМЪбщжЄЃЌЭЈГЃбЁдёReluЁЃ
СэЭтЕФЃЌОэЛ§ЕФРраЭГ§СЫБъзМОэЛ§ЃЌЛЙбнБфГіСЫЗДОэЛ§ЁЂПЩЗжРыОэЛ§ЁЂЗжзщОэЛ§ЕШИїжжРраЭЃЌПЩвдздаабщжЄЁЃ
3.1.2 ОэЛ§ВуЕФЬиЕу
ЭЈЙ§ОэЛ§дЫЫуЕФНщЩмЃЌПЩвдЗЂЯжОэЛ§ВугаСНИіжївЊЬиЕуЃКОжВПСЌНгЃЈЯЁЪшСЌНгЃЉКЭШЈжЕЙВЯэЁЃ
ОжВПСЌНгЃЌОЭЪЧОэЛ§ВуЕФНкЕуНіНіКЭЦфЧАвЛВуЕФВПЗжНкЕуЯрСЌНгЃЌжЛгУРДбЇЯАОжВПЧјгђЬиеїЁЃЃЈОжВПСЌНгИажЊНсЙЙЕФРэФюРДдДгкЖЏЮяЪгОѕЕФЦЄВуНсЙЙЃЌЦфжИЕФЪЧЖЏЮяЪгОѕЕФЩёОдЊдкИажЊЭтНчЮяЬхЕФЙ§ГЬжаЦ№зїгУЕФжЛгавЛВПЗжЩёОдЊЁЃЃЉ
ШЈжЕЙВЯэЃЌЭЌвЛОэЛ§КЫЛсКЭЪфШыЭМЦЌЕФВЛЭЌЧјгђзїОэЛ§ЃЌРДМьВтЯрЭЌЕФЬиеїЃЌОэЛ§КЫЩЯУцЕФШЈжиВЮЪ§ЪЧПеМфЙВЯэЕФЃЌЪЙЕУВЮЪ§СПДѓДѓМѕЩйЁЃ 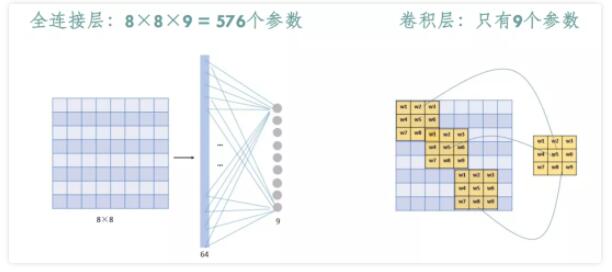
гЩгкОжВПСЌНгЃЈЯЁЪшСЌНгЃЉКЭШЈжЕЙВЯэЕФЬиЕуЃЌЪЙЕУCNNОпгаЗТЩфЕФВЛБфад(ЦНвЦЁЂЫѕЗХЕШЯпадБфЛЛ)
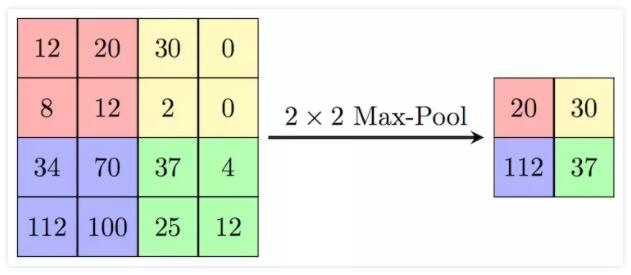
3.2 ГиЛЏВуЃЈPoolingЃЉ
ГиЛЏВуПЩЖдЬсШЁЕНЕФЬиеїаХЯЂНјааНЕЮЌЃЌвЛЗНУцЪЙЬиеїЭМБфаЁЃЌМђЛЏЭјТчМЦЫуИДдгЖШЃЛСэвЛЗНУцНјааЬиеїбЙЫѕЃЌЬсШЁжївЊЬиеїЃЌдіМгЦНвЦВЛБфадЃЌМѕЩйЙ§ФтКЯЗчЯеЁЃЕЋЦфЪЕГиЛЏИќЖрГЬЖШЩЯЪЧвЛжжМЦЫуадФмЕФвЛИіЭзаЃЌЧПгВЕибЙЫѕЬиеїЕФЭЌЪБвВЫ№ЪЇСЫвЛВПЗжаХЯЂЃЌЫљвдЯждкЕФЭјТчБШНЯЩйгУГиЛЏВуЛђепЪЙгУгХЛЏКѓЕФШчSoftPoolЁЃ
ГиЛЏВуЩшЖЈЕФГЌВЮЪ§ЃЌАќРЈГиЛЏВуЕФРраЭЪЧMaxЛЙЪЧAverageЃЈAverageЖдБГОАБЃСєИќКУЃЌMaxЖдЮЦРэЬсШЁИќКУЃЉЃЌДАПкДѓаЁвдМАВНГЄЕШЁЃШчЯТЕФMaxPoolingЃЌВЩгУСЫвЛИі2ЁС2ЕФДАПкЃЌВЂШЁВНГЄstride=2ЃЌЬсШЁГіИїИіДАПкЕФmaxжЕЬиеїЃЈAveragePoolingОЭЪЧЦНОљжЕЃЉЃК
3.3 ШЋСЌНгВуЃЈFCЃЉ
дкОЙ§Ъ§ДЮОэЛ§КЭГиЛЏжЎКѓЃЌЮвУЧзюКѓЛсЯШНЋЖрЮЌЕФЭМЯёЪ§ОнНјаабЙЫѕЁАБтЦНЛЏЁБЃЌ вВОЭЪЧАб (height,width,channel)
ЕФЪ§ОнбЙЫѕГЩГЄЖШЮЊ height ЁС width ЁС channel ЕФвЛЮЌЪ§зщЃЌШЛКѓдйгыШЋСЌНгВуСЌНгЃЈетвВОЭЪЧДЋЭГШЋСЌНгЭјТчВуЃЌУПвЛИіЕЅдЊЖМКЭЧАвЛВуЕФУПвЛИіЕЅдЊЯрСЌНгЃЌашвЊЩшЖЈЕФГЌВЮЪ§жївЊЪЧЩёОдЊЕФЪ§СПЃЌвдМАМЄЛюКЏЪ§РраЭЃЉЃЌЭЈЙ§ШЋСЌНгВуДІРэЁАбЙЫѕЕФЭМЯёаХЯЂЁБВЂЪфГіНсЙћЁЃ 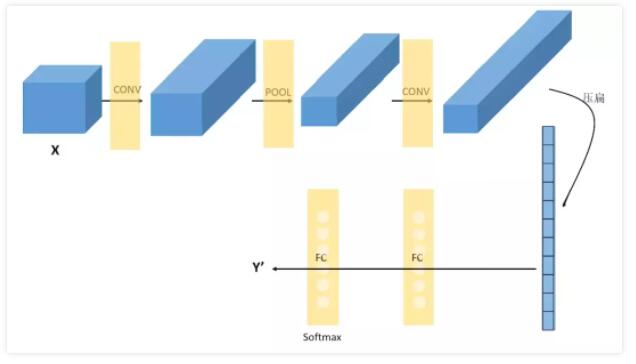
3.4 ЪОР§ЃКОЕфCNNЕФЙЙНЈЃЈLenet-5ЃЉ

LeNet-5гЩYann LeCunЩшМЦгк 1998ФъЃЌЪЧзюдчЕФОэЛ§ЩёОЭјТчжЎвЛЁЃЫќЪЧеыЖдЛвЖШЭМНјаабЕСЗЕФЃЌЪфШыЭМЯёДѓаЁЮЊ32321ЃЌВЛАќКЌЪфШыВуЕФЧщПіЯТЙВга7ВуЁЃЯТУцж№ВуНщЩмLeNet-5ЕФНсЙЙЃК
1ЁЂC1-ОэЛ§Ву
ЕквЛВуЪЧОэЛ§ВуЃЌгУгкЙ§ТЫдывєЃЌЬсШЁЙиМќЬиеїЁЃЪЙгУ5 * 5ДѓаЁЕФЙ§ТЫЦї6ИіЃЌВНГЄs = 1ЃЌpadding
= 0ЁЃ
2ЁЂS2-ВЩбљВуЃЈЦНОљГиЛЏВуЃЉ
ЕкЖўВуЪЧЦНОљГиЛЏВуЃЌРћгУСЫЭМЯёОжВПЯрЙиадЕФдРэЃЌЖдЭМЯёНјаазгГщбљЃЌПЩвдМѕЩйЪ§ОнДІРэСПЭЌЪББЃСєгагУаХЯЂЃЌНЕЕЭЭјТчбЕСЗВЮЪ§МАФЃаЭЕФЙ§ФтКЯГЬЖШЁЃЪЙгУ2
* 2ДѓаЁЕФЙ§ТЫЦїЃЌВНГЄs = 2ЃЌpadding = 0ЁЃГиЛЏВужЛгавЛзщГЌВЮЪ§pool_size
КЭ ВНГЄstridesЃЌУЛгаашвЊбЇЯАЕФФЃаЭВЮЪ§ЁЃ
3ЁЂC3-ОэЛ§Ву
ЕкШ§ВуЪЙгУ5 * 5ДѓаЁЕФЙ§ТЫЦї16ИіЃЌВНГЄs = 1ЃЌpadding = 0ЁЃ
4ЁЂS4-ЯТВЩбљВуЃЈЦНОљГиЛЏВуЃЉ
ЕкЫФВуЪЙгУ2 * 2ДѓаЁЕФЙ§ТЫЦїЃЌВНГЄs = 2ЃЌpadding = 0ЁЃУЛгаашвЊбЇЯАЕФВЮЪ§ЁЃ
5ЁЂC5-ОэЛ§Ву
ЕкЮхВуЪЧОэЛ§ВуЃЌга120Иі5 * 5 ЕФЕЅдЊЃЌВНГЄs = 1ЃЌpadding = 0ЁЃ
6ЁЂF6-ШЋСЌНгВу
га84ИіЕЅдЊЁЃУПИіЕЅдЊгыF5ВуЕФШЋВП120ИіЕЅдЊжЎМфНјааШЋСЌНгЁЃ
7ЁЂOutput-ЪфГіВу
OutputВувВЪЧШЋСЌНгВуЃЌВЩгУRBFЭјТчЕФСЌНгЗНЪНЃЈЯждкжївЊгЩSoftmaxШЁДњЃЌШчЯТЪОР§ДњТыЃЉЃЌЙВга10ИіНкЕуЃЌЗжБ№ДњБэЪ§зж0ЕН9ЃЈвђЮЊLenetгУгкЪфГіЪЖБ№Ъ§зжЕФЃЉЃЌШчЙћНкЕуiЕФЪфГіжЕЮЊ0ЃЌдђЭјТчЪЖБ№ЕФНсЙћЪЧЪ§зжiЁЃ
ШчЯТKerasИДЯжLenet-5ЃК 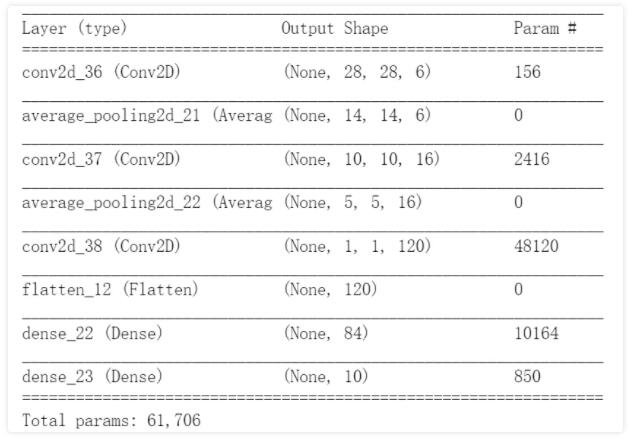
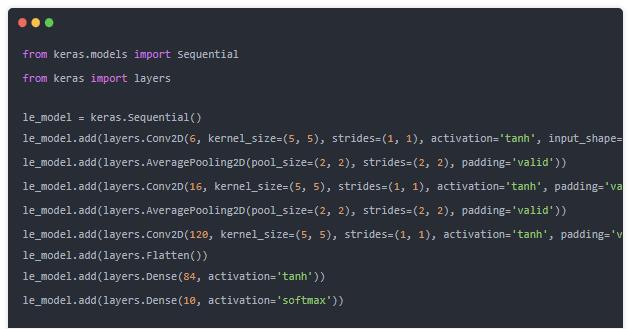
ЫФЁЂCNNЭМЯёЗжРр-keras
вдkerasЪЕЯжОЕфЕФCIFAR10ЭМЯёЪ§ОнМЏЕФЗжРрЮЊР§ЃЌДњТыЃКhttps://github.com/aialgorithm/Blog
бЕСЗМЏЪфШыЪ§ОнЕФбљЪНЮЊЃК(50000, 32, 32, 3)ЖдгІ (бљБОЪ§, ЭМЯёИпЖШЃЌ ПэЖШ,
RGBВЪЩЋЭМЯёЭЈЕРЮЊ3) 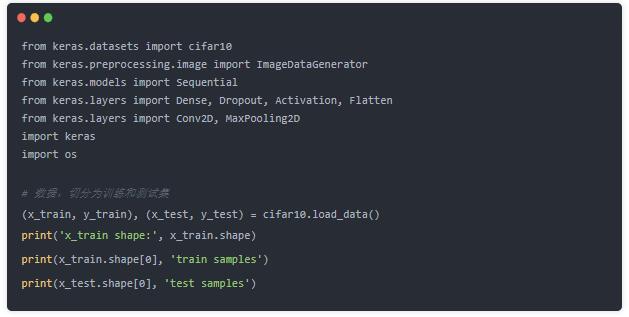
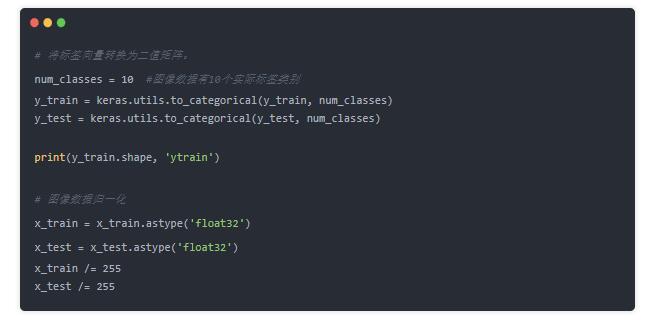
еЙЪОЪ§ОнМЏЃЌЙВга10РрЭМЯёЃК

Ъ§ОнМАБъЧЉдЄДІРэ
ЙЙдьОэЛ§ЩёОЭјТч: ЪфШыВу->ЖрзщОэЛ§МАГиЛЏВу->ШЋСЌНгЭјТч->softmaxЖрЗжРрЪфГіВуЁЃЃЈШчЯТЭМВПЗжЭјТчНсЙЙЃЉ 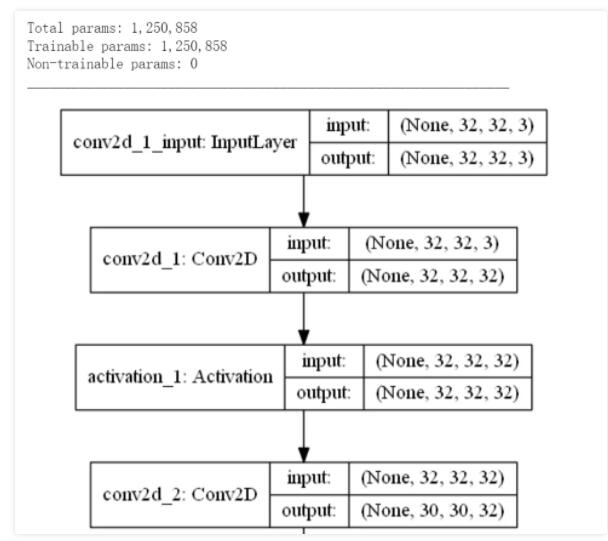
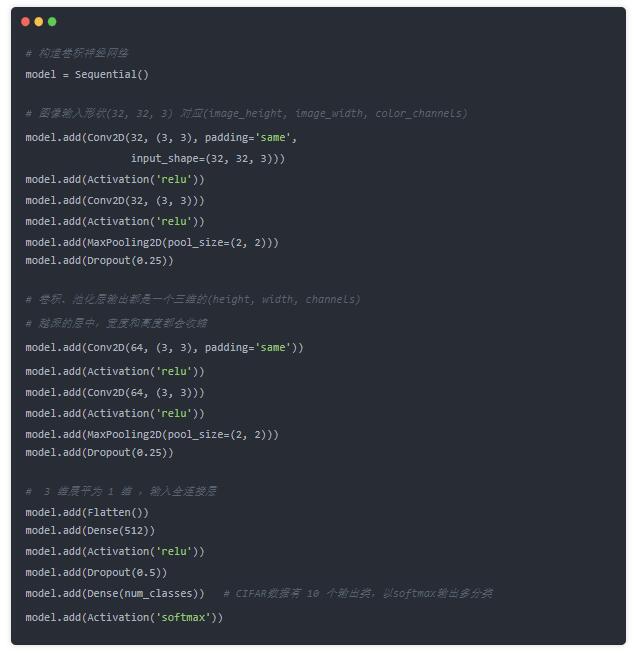
ФЃаЭБрвыЃКЩшЖЈRMSprop гХЛЏЫуЗЈЃЛЩшЖЈЗжРрЫ№ЪЇКЏЪ§.
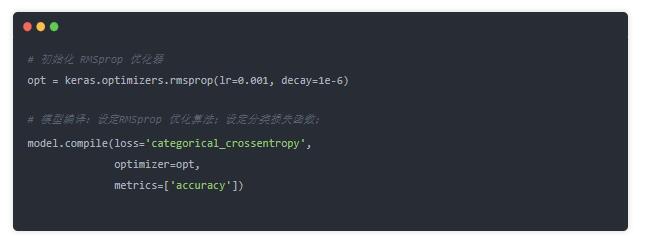
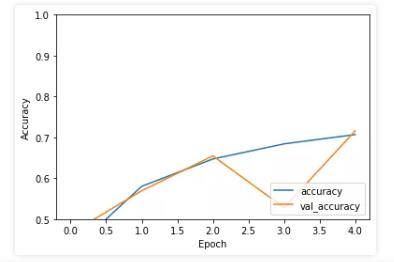
ФЃаЭбЕСЗ: МђЕЅбщжЄ5Иіepochs
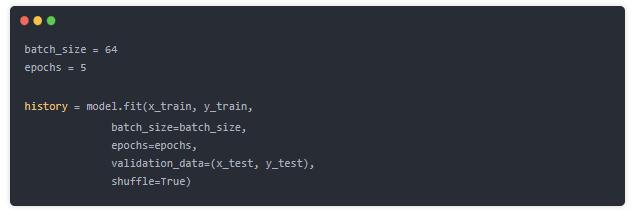
ФЃаЭЦРЙРЃКВтЪдМЏaccuracy: 0.716ЃЌПЩМћбЕСЗ/ВтЪдМЏећЬхЕФзМШЗТЪЖМВЛЬЋИпЃЈЧЗФтКЯЃЉЃЌПЩвддіМгepochЪ§ЁЂФЃаЭЕїгХбщжЄаЇЙћЁЃ
ИН ОэЛ§ЩёОЭјТчгХЛЏЗНЗЈЃЈtricksЃЉЃК
ГЌВЮЪ§гХЛЏЃКПЩвдгУЫцЛњЫбЫїЁЂБДвЖЫЙгХЛЏЁЃЭЦМіЗжВМЪНГЌВЮЪ§ЕїЪдПђМмKeras TunerАќРЈСЫГЃгУЕФгХЛЏЗНЗЈЁЃ
Ъ§ОнВуУцЃКЪ§ОндіЧПЙуЗКгУгкЭМЯёШЮЮёЃЌаЇЙћЬсЩ§ДѓЁЃГЃгУгаЭМЯёбљБОБфЛЛЁЂmixupЕШЁЃИќЖргХЛЏЗНЗЈОпЬхПЩМћЃКhttps://arxiv.org/abs/1812.01187
| 







