| БрМЭЦМі: |
БОЮФжївЊНщЩмСЫздЖЏМнЪЛИажЊЪ§ОнБеЛЗЯрЙижЊЪЖЁЃЯЃЭћЖдФњЕФбЇЯАгаЫљАяжњЁЃ
БОЮФРДзджЧМнзюЧАбиЃЌгЩЛ№СњЙћШэМўLindaБрМЁЂЭЦМіЁЃ |
|
дкздЖЏМнЪЛММЪѕжаЃЌШэМўЯЕЭГЪЧзюОпгаММЪѕБкРнЕФСьгђжЎвЛЁЃНќФъРДЃЌЙњФкЭтГЩСЂСЫВЛЩйздЖЏМнЪЛДДвЕЙЋЫОЃЌЛЈЗбСЫДѓСПШЫСІЮяСІЭЖШыЕНздЖЏМнЪЛШэМўЯЕЭГЕФПЊЗЂжаЃЌУПвЛааДњТыЁЂУПвЛИізЈРћЃЌЖМЪЧЫќУЧЮДРДОКељЕФЕзЦјКЭзЪБОЁЃПЩвдЫЕЃЌздЖЏМнЪЛШэМўЯЕЭГЪЧЩЯЪіЙЋЫОзюКЫаФЕФзЪВњжЎвЛЁЃ
АйЖШЪЧЙњФкзюдчЭЖШыздЖЏМнЪЛММЪѕбаЗЂЕФЙЋЫОжЎвЛЁЃApolloЪЧАйЖШЗЂВМЕФЯђЦћГЕаавЕМАздЖЏМнЪЛСьгђКЯзїЛяАщЬсЙЉЕФШэМўЦНЬЈЃЌВЛНідкШЋЧђИїжжШЈЭўздЖЏМнЪЛАёЕЅжаГЩМЈьГШЛЃЌвВдкЩЬвЕЛЏЭЦНјЩЯгазХОЊШЫЕФЫйЖШЁЃЯТЭМЪЧApolloПЊдДЯюФПЕФЯЕЭГМмЙЙЁЃ 
ЭМ1. Apollo 6.0 Architecture
ЭМЦЌРДдДЃКApolloЯюФПGitHubЕижЗhttps://github.com/ApolloAuto/apollo
МђЕЅНтЮівЛЯТApolloПђМмЁЃ
ЦфжаЃЌOpen Software PlatformжИЕФЪЧApolloПЊдДШэМўЦНЬЈЃЌЫќЪЧЭМжаЮЛгкгвВрЕФИїИізгФЃПщЕФзмГЦЁЃRTOSЃЈreal-time
operating systemЃЉЪЧЪЕЪБВйзїЯЕЭГЃЌЪЕЪБадЪЧЫќЕФзюДѓЬиеїЃЌЫќЮЊЩЯВуЙІФмФЃПщЕФИпаЇжДааЬсЙЉЕзВуЛЗОГЁЃ
Map EngineЪЧЕиЭМв§ЧцЃЌдкШэМўжаИКд№ЛёШЁИїРрЕиЭМЪ§ОнЃЌВЂЬсЙЉЯргІЕФЕиЭМЪ§ОнЙІФмНгПкЁЃLocalizationКЭPerceptionЗжБ№ЪЧЖЈЮЛКЭИажЊФЃПщЃЌЪЧДІРэЦћГЕжмЮЇЛЗОГаХЯЂЕФЙІФмФЃПщЃЌИКд№НЋИїРрДЋИаЦїЪеМЏЕНЕФЪ§ОнНјааМгЙЄКЭДІРэЃЌгУНсЙЙЛЏЕФНсЙћРДУшЪіЦћГЕжмЮЇЕФГЁОАЁЃPlanningЪЧЙцЛЎФЃПщЃЌИКд№ЖдНсЙЙЛЏЕФГЁОАаХЯЂНјааЯТвЛВНЕФДІРэЃЌЭЈЙ§МЦЫуЕУЕНвЛЬѕАВШЋПЩЭЈааЕФТЗОЖЁЃControlЪЧПижЦФЃПщЃЌИКд№АбЙцЛЎЕФНсЙћзЊЛЛГЩЖдЕчзггЭУХЁЂЕчзгЩВГЕКЭЕчзгзЊЯђЕФПижЦаХКХЃЌзюжеЪЕЯжЖдГЕСОдЫЖЏЕФПижЦЁЃ
етЦфжаЃЌИажЊФЃПщашвЊЖдДѓСПЕФДЋИаЦїЪ§ОнНјааЪЕЪБДІРэЃЌашвЊзМШЗЧвИпаЇЕиЪЖБ№ГЁОАаХЯЂЃЌвђДЫЪЧзюгаЙЄГЬЬєеНЕФзгФЃПщжЎвЛЁЃ
ЯТЭМЪЧApolloПЊдДЯюФПЕФИажЊПђМмЭМЃЌПЩвдПДЕНећИіИажЊВПЗжЕФНсЙЙЪЧБШНЯИДдгЕФЃЌЖрЬѕЪ§ОнДІРэТЗЯпВЂааеЙПЊЃЌУПвЛИіНкЕузгФЃПщЖМЛсЩцМАЕНКмЖрЫуЗЈДІРэЃЌЭЌЪБЃЌетаЉТЗЯпжЎМфЛЙЛсгаЯрЛЅЕФЪ§ОнНЛЛЛЃЌзюКѓЃЌзлКЯДІРэЖрЬѕТЗЯпЕФНсЙћЕУЕНИажЊФЃПщЕФЪфГіЁЃ

ЭМ2. Apollo 6.0АцБОИажЊПђМмЭМ
ЭМЦЌРДдДЃКApolloЯюФПGitHubЕижЗhttps://github.com/ApolloAuto/apollo
ЯТЮФНЋМђЕЅЕиЦЪЮівЛЯТИажЊФЃПщЕФПђМмЃЌДгЪ§ОнСїЖЏЕФЮЌЖШНВЪіИажЊФЃПщЪЧШчКЮдЫааЕФЁЃ
ЮвУЧЯШДгМђЕЅЕФФЃаЭШыЪжЃЌАбИажЊФЃПщВ№ЗжГЩЪ§ОнЪфШыЁЂЪ§ОнДІРэЁЂЪ§ОнЪфГіШ§ИіВПЗжЃЌдйЗжБ№ЖдУПИіВПЗжНјааЩюШыЬНЬжЁЃ
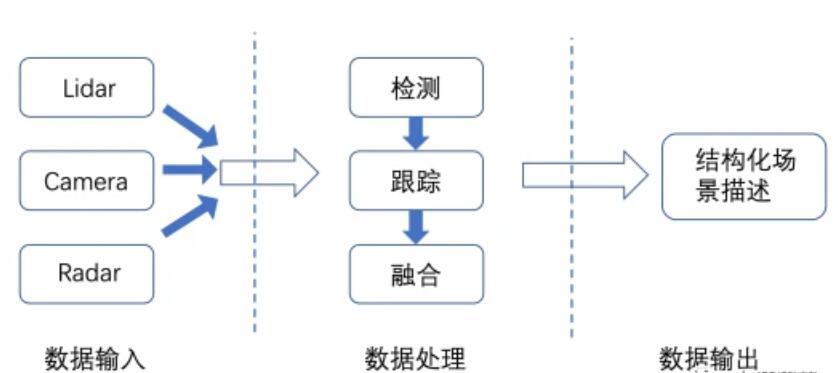
ЭМ3. ИажЊФЃПщЪ§ОнСїЖЏМђЭМ
Ъ§ОнЪфШыЙ§ГЬ
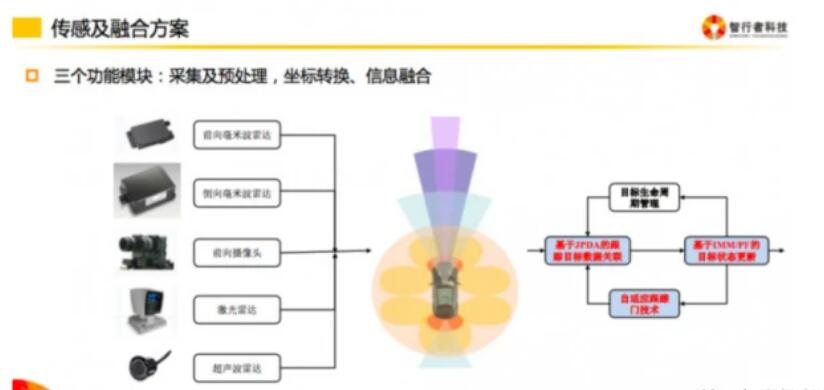
ЪзЯШЪЧЪ§ОнЪфШыЖЫЁЃЪ§ОнЪфШыжївЊАќРЈМЄЙтРзДяЁЂГЕдиЯрЛњЁЂКСУзВЈРзДяЃЈвдЯТЗжБ№МђГЦLidarЁЂCameraЁЂRadarЃЉЕШДЋИаЦїЕФГЁОАЪ§ОнВЩМЏЃЌвдМАДгГЕСОЕзХЬЛёШЁздГЕаХКХЃЈЫйЖШЁЂМгЫйЖШЁЂзЊЯђЕШЃЉЁЃДЫЭтЃЌИажЊЛЙЛсвРРЕЕНИпОЋЕиЭМЕШаХЯЂЁЃ
ЯТУцжївЊЬНЬжLidarКЭCameraЕФЪ§ОнЪфШыЙ§ГЬЁЃ
LidarЪ§ОнЪфШы
LidarЕФЙЄзїдРэЃЌЪЧЭЈЙ§МЄЙтееЩфЕНЮяЬхБэУцНгЪеЕНЗДЩфЙтЃЌДгЖјМЦЫуЗДЩфЕуЯрЖдЗЂЩфЦїЕФПеМфзјБъЁЃВЛТлЪЧФФжжРраЭЁЂФФИіГЇМвЕФLidarЃЌзюжеЪфГіЕФЪ§ОнБОжЪЩЯЖМЪЧДѓСПЗДЩфЕуЕФаХЯЂМЏКЯЁЃетаЉПеМфжаДѓСПЕФЗДЩфЕуМЏКЯдквЛЦ№ОЭЪЧЮвУЧОГЃГЦКєЕФЕудЦЃЈpoint
cloudЃЉЁЃ

ЭМ4. ЕудЦПЩЪгЛЏЭМЯё
ЭМЦЌРДдДЃКVelodyneЙйЭј https://velodynelidar.com/
ЩЯЭМЪЧНЋLidarЕудЦПЩЪгЛЏвдКѓЕФНсЙћЃЌЮЊСЫжБЙлЃЌЭМжагУСЫбеЩЋЬнЖШРДБэЪОЕуЕФОрРыЁЃLidarЩшБИЖЫПкЗЂГіРДЕФдЪМЪ§ОнВЂВЛЪЧЮвУЧдкЭМжаПДЕНЕФетбљЃЌИажЊФЃПщашвЊЖддЪМЪ§ОнНјааДІРэВХФмЕУЕНКЯЪЪЕФЪ§ОнаЮЪНЁЃ
етРяЯШНщЩмвЛЯТЕуЕФУшЪіВЮЪ§ЁЃШчЯТЭМЫљЪОЃЌЕЅИіЗДЩфЕуЕФаХЯЂжївЊАќРЈПеМфаХЯЂЁЂЪБМфДСКЭЗДЩфЧПЖШЁЃЦфжаЃЌгЩгкLidarЕФЙЄзїдРэВЛЭЌЃЌЛњаЕа§зЊЪНLidarЭЈГЃЛсЪЙгУОЖЯђОрРыЃЈradiusЃЉЁЂИЉбіНЧЃЈelevationЃЉЁЂЗНЮЛНЧЃЈazimuthЃЉРДБэЪОЕуЕФПеМфЮЛжУЃЌЖјАыЙЬЬЌ/ЙЬЬЌLidarЃЌЭЈГЃЪЙгУЕбПЈЖћзјБъЯЕЯТxyzРДБэЪОЕуЕФПеМфЮЛжУЁЃ 
ЭМ5. LidarЗДЩфЕуЕФаХЯЂ
ЫфШЛВЛЭЌЕФLidarЩшБИГЇМвУшЪіЕудЦЕФЪ§ОнаЮЪНВЛЭЌЃЌЗЂЫЭГіРДЕФИёЪНВЛЭЌЃЌЕЋОПЦфБОжЪЖМЪЧЖдЕудЦЕФЪ§ОнУшЪіЁЃвђДЫЃЌИїДѓГЇЩЬЕФLidarЗЂЫЭГіРДЕФЪ§ОнНсЙЙЖМЪЧРрЫЦЕФЁЃдкДЫЃЌЮвУЧвдVelodyne
16ЯпLidarЮЊР§НВЪіЁЃ
ЯТЭМЫљЪОЪЧVelodyne 16ЯпLidarдкЕЅЛиВЈФЃЪНЯТЗЂЫЭЕФЪ§ОнНсЙЙЁЃУПвЛИіЧјгђРяЖМДцЗХзХЙЬЖЈзжНкДѓаЁЕФЪ§ОнЃЌећИіЧјгђзщГЩСЫЪ§ОнАќЃЈData
BlockЃЉЁЃУПИі Data BlockРяУцАќРЈСЫHeadЃЈЪ§ОнЭЗВПЧјгђЃЉЃЌDataЃЈЕудЦЪ§ОнДцЗХЧјЃЉКЭTailЃЈЪ§ОнЮВВПЧјгђЃЌгааЉLidarгВМўВЛЗЂЫЭЮВВПЪ§ОнгђЃЉЁЃHeadКЭTailРяУцЭЈГЃДцДЂвЛаЉгУРДЭЈаХаЃбщЕФЪ§ОнвдМАLidarЕФздЩэЙЄзїзДЬЌВЮЪ§ЕШЃЌDataгђРяАќКЌКмЖрChannelгђЃЌУПвЛИіChannelРяДцЗХзХвЛИіЕуЕФаХЯЂЁЃЙЬЖЈЪ§СПЕФЕудЦЪ§ОнећЦыЖјНєУмЕиХХСадквЛЦ№ЃЌзщГЩСЫжаМфЕФDataгђЁЃзюКѓДђАќГЩЕФData
BlockЪЧвЛПщBytesДѓаЁЙЬЖЈЕФЪ§ОнЧјЁЃ 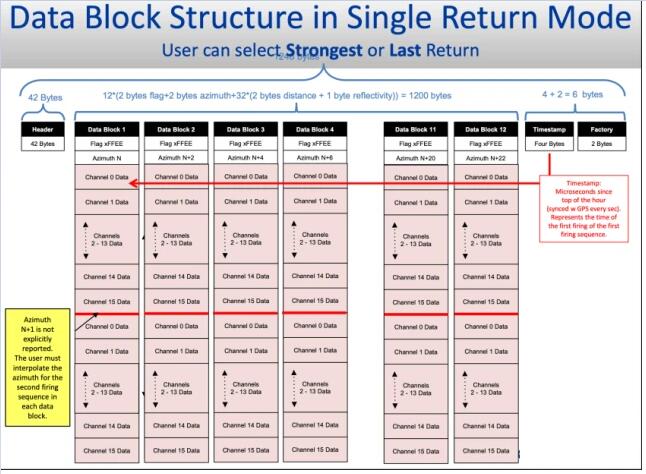
ЭМ6. Velodyne 16ЯпLidarЗЂЫЭЕФЪ§ОнАќНсЙЙЪОвтЭМ
ЭМЦЌРДдДЃКVelodyneЙйЭј
LidarЕФЙЄзїФЃЪНгаЕЅЛиВЈКЭЫЋЛиВЈжЎЗжЁЃМђЕЅРДНВЃЌLidarЗЂЩфГіРДЕФМЄЙтЪјЪЧгаУцЛ§ЕФЃЌДђдкЮяЬхБэУцЕФЪЧвЛаЁЦЌЧјгђЃЌШчЙћМЄЙтЪјИеКУДђдкСЫЮяЬхБпНчЃЌФЧУДОЭЛсгавЛВПЗжСєдкНќДІЕФЮяЬхЩЯЃЌСэвЛВПЗжДЅХіЕНИќдЖЕФЮяЬхЃЌетЪБвЛИіЗЂЩфаХКХОЭЛсгаСНИіЛиВЈаХКХЃЌетОЭЪЧЫЋЛиВЈдРэЁЃдкЕЅЛиВЈФЃЪНЯТЃЌПЩвдбЁдёЙтЧПИпЛђЕЭЃЌОрРыНќЛђдЖЕФЛиВЈЁЃЖјЭЈГЃЧщПіЯТЃЌЫЋЛиВЈФЃЪНЕФЪ§ОнДѓЖрЖМЪЧжиИДЕФЃЌЫљвдЃЌвЛАуЖМЛсбЁдёШУLidarдкЕЅЛиВЈФЃЪНЯТЙЄзїЃЌВЂбЁдёЙтЧПИп&ОрРыНќЕФЛиВЈзїЮЊдЪ§ОнЁЃ
дкЪ§ОнЗЂЫЭЗНЪНЩЯЃЌгааЉLidarГЇЩЬбЁгУЭјЯпСЌНгЙЄПиЛњЃЌЛљгкUDPДЋЪфавщЃЈUser Datagram
ProtocolЃЉЗЂЫЭLidarгВМўДђАќКУЕФData BlockЁЃ 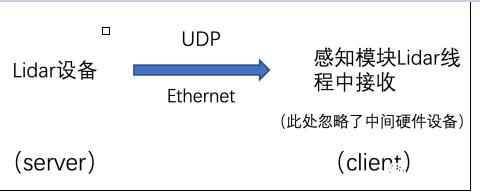
ЭМ7. LidarЪ§ОнЗЂЫЭЛњжЦ
UDPЪЧвЛИіЮоСЌНгавщЃЌДЋЪфЪ§ОнжЎЧАЕФдДЖЫКЭжеЖЫВЛНЈСЂСЌНгЃЌВЛЮЌЛЄСЌНгзДЬЌвдМАЪеЗЂзДЬЌЃЌвВОЭЪЧЫЕЃЌдкUDPЗНЪНЯТLidarЩшБИжЛашвЊЕЅЗНУцЗЂЫЭЪ§ОнЃЌВЂВЛашвЊПМТЧЭЈаХЪЧЗёГЩЙІЁЃбЁдёетбљЕФЗЂЫЭЗНЪНПЩвдБЃжЄLidarЯђЯТгЮЕФЗЂЫЭВЛМфЖЯЁЂЮобгГйЃЌдкЬсИпЗЂЫЭаЇТЪЕФЭЌЪБЃЌвВБЃжЄСЫLidarгВМўКЭЯТгЮЯЕЭГЕФЖРСЂадЁЃ
ЭЈЙ§етжжЗНЪНЃЌLidarЩшБИНЋДђАќКУЕФЕудЦЪ§ОнЗЂЫЭГіШЅЃЌЯТгЮЯЕЭГЭЈЙ§дЄЯШЩшжУКУЕФЭЈаХавщНгЪеЪ§ОнВЂНјШыЕудЦЪ§ОнЕФДІРэСїГЬЁЃ
CameraЪ§ОнЪфШы
ЪзЯШНщЩмвЛЯТЭМЯёЪ§ОнЁЃ
вдRGBЭМЯёЮЊР§ЃЌвЛеХЭМЯёЪЧгЩКьТЬРЖШ§жжбеЩЋЭЈЕРЕўМгЖјГЩЕФЃЈМћЯТЭМЃЉЁЃдквЛИіЭЈЕРФкЪЙгУЪ§зжРДБэЪОбеЩЋЃЌБШШчдкКьЭЈЕРжагУ8ЮЛbitРДБэЪОКьЩЋЃЌвВОЭЪЧгУЪЎНјжЦЯТЕФ0ЁЋ255ЃЈ28=256ЃЉРДБэЪОКьЩЋЁЃШчЙћвЛеХееЦЌЕФЯёЫиЪЧ1280*960ЃЌФЧУДетеХееЦЌЕФКьЩЋЭЈЕРЃЈRЭЈЕРЃЉОЭЪЧ1280*960ДѓаЁЕФЪ§зжОиеѓЃЌОиеѓжаУПИіЮЛжУЩЯЖМЬюаДзХ0ЁЋ255ЕФЪ§зжЁЃдйНсКЯТЬЩЋКЭРЖЩЋЭЈЕРЃЌетеХRGBЭМЯёОЭПЩвдгУ1280*960*3ДѓаЁЕФЪ§зжОиеѓРДБэЪОЁЃ 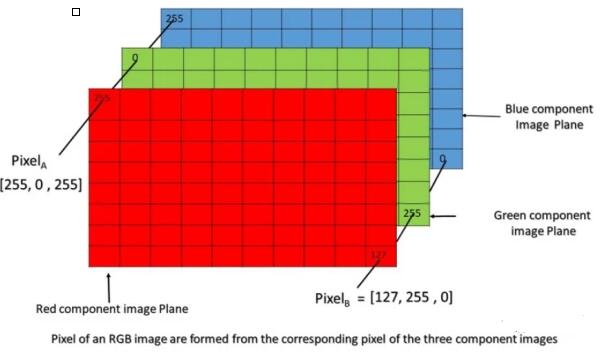
ЭМ8. RGBЭМЯёНсЙЙ
ЭМЦЌРДдДЃКhttps://www.geeksforgeeks.org/matlab-rgb-image-representation/
НгРДЯТЃЌНВЪівЛЯТCameraЪ§ОнЕФЪфШыЙ§ГЬЁЃ
ГЕдиЯрЛњжївЊгЩОЕЭЗЁЂИаЙтДЋИаЦїКЭЭМЯёаХКХДІРэЦїЃЈISPЃЉзщГЩЁЃЦфжаИаЙтДЋИаЦїжївЊЪЧгУCMOSЃЌЫќЕФзїгУЪЧНЋГЁОАЕФЙтаХКХЃЈФЃФтаХКХЃЉзЊЛЛГЩЖдгІЕФЕчаХКХЁЃНгЯТРДЃЌЕчаХКХдйЭЈЙ§ADCЃЈФЃЪ§зЊЛЛЦїЃЉзЊЛЏГЩЪ§зжаХКХЪфЫЭИјISPЃЌдкISPЩЯНјааЭМЯёДІРэЃЈздЖЏЦиЙтЁЂздЖЏАзЦНКтЁЂздЖЏЖдНЙЁЂАЕНЧаоИДЕШЃЉЃЌДІРэЭъГЩКѓЭЈЙ§БъзМЕФSCCBзмЯпЃЈI2CзмЯпЃЉНгПкКЭЭтВПНјааЭЈаХЃЌЪфГіRGBИёЪНЃЈЛђYUVИёЪНЃЉЕФЭМЯёЁЃ
вЛАуЧщПіЯТЃЌашвЊЧ§ЖЏЃЈdriverЃЉРДПижЦCMOSФЃзщЙЄзїЃЌЯрЛњГЇЩЬвЛАуЛсАбПЊЗЂКУЕФЧ§ЖЏЬсЙЉИјЪЙгУепЁЃНЋdriverВПЪ№дкздЖЏМнЪЛЦНЬЈЕФШэМўЖЫЃЌОЭПЩвдПижЦЭтНгCMOSФЃзщЕФЙЄзїзДЬЌСЫЁЃЭЈЙ§ЕїгУЯрЛњГЇЩЬЬсЙЉЕФAPIЃЈapplication
programming interfaceЃЌгІгУГЬађНгПкЃЉЃЌИажЊФЃПщПЩвдЗУЮЪетаЉдЪМЭМЯёЪ§ОнЃЌетбљЃЌCameraЪ§ОнОЭДЋШыСЫИажЊФЃПщжаЁЃећИіЙ§ГЬПЩвдгУЯТЭММђЕЅБэЪОЁЃ
ЭМ9. CameraЪфГіЭМЯёЕФСїГЬ
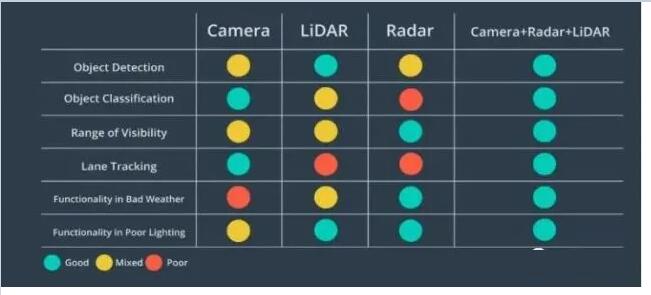
LidarЪ§ОнгЕгаЗсИЛЕФПеМфаХЯЂЃЌЖјЭМЯёЪ§ОнгЕгазХЮяЬхМИКЮЁЂЩЋВЪЮЦРэЕФЬиеїЁЃ
ЯТЭМЪЎЗжЧхГўЕиеЙЪОСЫШ§РрДЋИаЦїжЎМфЕФгХСгЪЦЁЃCameraдкЮяЬхЗжРрКЭГЕЕРЯпМьВтжаБэЯжНЯКУЃЌЕЋЪЧдкЖёСгЬьЦјЁЂШѕЙтЬѕМўЯТБэЯжВЛМбЃЛLidarдкЮяЬхМьВтКЭШѕЙтЬѕМўЯТЕФадФмНЯКУЃЌЕЋЪЧдкГЕЕРМьВтЩЯБэЯжНЯВюЃЛRadarдкЖёСгЬьЦјКЭШѕЙтЬѕМўЯТБэЯжНЯКУЃЌЕЋЪЧдкЮяЬхЗжРрКЭГЕЕРЯпМьВтЩЯБэЯжВЛааЁЃЪЙгУЖржжДЋИаЦїЪ§ОнЃЌИљОнЫќУЧИїздЕФЙЄзїЬиЕуЃЌгХЪЦЛЅВЙЃЌПЩвдЪЙећЬхЪ§ОндкЖрИіКтСПЮГЖШЩЯБэЯжгХвьЃЌЬсИпЖдГЁОАЕФЪ§ОнБэЪОадКЭЪ§ОнТГАєадЁЃ
ЭМ10 .ИїРрДЋИаЦїЪ§ОнЖдБШ
ЭМЦЌРДдДЃКApolloПЊЗЂепжааФ
НгЯТРДЃЌДЋИаЦїНЋДѓСПЕФдЪМЪ§ОнДЋЪфИјЯТгЮЃЌгЩИажЊФЃПщвРППЗсИЛЕФЫуЗЈЪжЖЮНјааНјвЛВНДІРэЁЃ
Ъ§ОнДІРэЙ§ГЬ
ДгЩЯгЮЛёШЁЕНИажЊФЃПщашвЊЕФЪ§ОнвдКѓЃЌИажЊФЃПщОЭашвЊЖдетаЉЪ§ОнНјааДІРэЁЃВЮПМApolloПЊдДЯюФПЕФИажЊПђМмЭМЃЌЮвУЧПЩвдПДЕНLidarЁЂCameraЁЂRadarЕФЪ§ОнЪЧЯШЗжГЩШ§ЬѕЯпТЗДІРэЕФЃЌШЛКѓдйАбИїЬѕТЗЯпЕФЪ§ОнНјааШкКЯЃЌЕУЕНзюжеЕФЪфГіЁЃ
МђЕЅРДНВЃЌПЩвдЗжЮЊДЋИаЦїЪ§ОндЄДІРэЁЂМьВтЁЂИњзйКЭШкКЯЁЃ
дЄДІРэФЃПщ
дЄДІРэФЃПщжївЊЪЧНЋДгЩЯгЮНгЪеЕНЕудЦКЭЭМЯёЪ§ОнНјвЛВНзЊЛЏГЩЫуЗЈашвЊЕФаЮЪНЁЃ
ЪзЯШЪЧЕудЦЕФдЄЯШДІРэЁЃАбЩЯгЮЗЂЫЭРДЕФData BlockШЅГ§HeadКЭTailвдКѓЃЌАДееЖЈГЄзжНкЖСШЁЃЌОЭПЩвдЛёЕУУПвЛИіЕуЕФдЊЪ§ОнЃЌЭЈЙ§ПеМфБфЛЛПЩвдМЦЫуГіЕуЯрЖдLidarЩшБИЕФПеМфзјБъxyzЃЌжЎКѓдйАбзјБъЁЂЪБМфДСЁЂЧПЖШЕШаХЯЂДцДЂдкЬиЖЈЕФЪ§ОнгђЛђНсЙЙЬхжаЁЃзюКѓЃЌАбLidarЭъећзпЭъвЛжмЕФЪ§ОнЗХШыМЏКЯжазїЮЊвЛжЁЕудЦЪ§ОнЁЃЪЙгУПЩЪгЛЏЙЄОпЛђПЊдДПтЃЈР§ШчPCLЃЌhttps://pointclouds.orgЃЉОЭЛсГЪЯжГіРрЫЦЭМ3ЕФЕудЦЭМЁЃ
ЖдЭМЯёЕФдЄДІРэжївЊАќРЈЖдЭМЯёЕФМєВУЁЂЭМЦЌЛвЖШДІРэЁЂЫѕЗХЁЂЪ§ОндіЧПЕШВйзїЃЌетвЛВНЕФФПЕФЪЧЪЪХфЩёОЭјТчЪфШыЪ§ОнЕФГпДчКЭаЮЪНЃЌЭЌЪБвВМѕЩйСЫЪфШыЩёОЭјТчЕФЪ§ОнСПЃЌДгЖјМѕЩйМЦЫузЪдДеМгУЁЃ
дЄДІРэФЃПщЖМЪЧЖдгкИїРрДЋИаЦїЪ§ОнЕФМђЕЅДІРэЃЌеМгУМЦЫузЪдДНЯЩйЃЌЪЕЯжЙ§ГЬвВБШНЯШнвзЁЃ
ЮяЬхМьВтФЃПщ
ЕудЦЪ§ОнДјгаУїШЗЕФПеМфЮЛжУаХЯЂЃЌЙЄГЬЪІУЧЭЈГЃЪЙгУЫќРДМьВтГЕСОЁЂааШЫЁЂТЗВрРИИЫЕШЮяЬхЁЃЕудЦЪ§ОнЕФМьВтПЩвдвРРЕДЋЭГЫуЗЈКЭЩюЖШбЇЯАЭјТчЁЃДЋЭГЕФеЯАЮяЕудЦМьВтЫуЗЈЃЌвРППЕудЦЕФМИКЮЬиеїЃЌЭЈЙ§ЗжИюОлРрЕШЗНЗЈЪфГіеЯАЮяЃЛЩюЖШбЇЯАЫуЗЈдђЪЧЭЈЙ§ЖдБъзЂЕФеЯАЮяЕудЦНјааФЃаЭбЕСЗЃЌдйЪЙгУФЃаЭМьВтЪЕМЪГЁОАЕудЦЪ§ОнЁЃЪЕМЪЙЄГЬжаПЩвдНіЪЙгУЩюЖШбЇЯАЫуЗЈЃЌвВПЩвдНЋДЋЭГЫуЗЈКЭЩюЖШбЇЯАЫуЗЈНсКЯдЫгУЁЃ

ЭМ11. ЕудЦМьВт
ЭМЦЌРДдДЃКwaymoдкCVPR 2020ЕФБЈИц
ЖдгкЭМЯёЪ§ОнЃЌЙЄГЬЪІУЧжївЊвРППЩюЖШбЇЯАЕФЗНЗЈРДДІРэЁЃздЖЏМнЪЛЙЋЫОДѓЖМЛсбЁдёзджїПЊЗЂМьВтФЃаЭЃЌЭЈЙ§бЕСЗБъзЂКУЪ§ОнЕФецжЕЭМЯёЃЌЕїећЩёОЭјТчЕФНсЙЙКЭВЮЪ§ЃЌвдДяЕНзюгХЕФМьВтНсЙћЁЃ
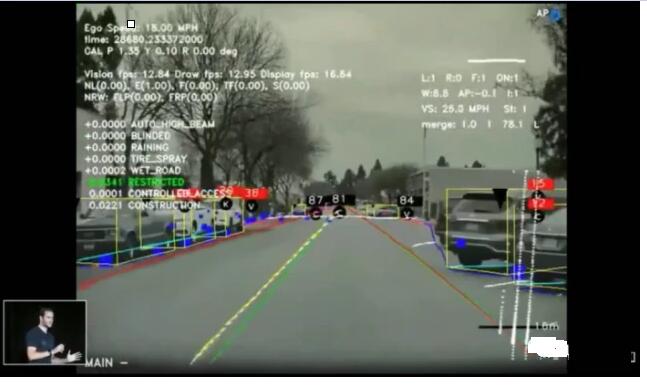
ЭМ12. ЭМЯёМьВт
ЭМЦЌРДдДЃКTesla AI Day 2021
ЮяЬхМьВтЪЧзюОпЙЄГЬЬєеНЕФВПЗжжЎвЛЁЃдкГЕСОИпЫйааЪЛЕФЙ§ГЬжаЃЌШчЙћДэЮѓЕиМьВтСЫФГИіеЯАЮяЬхЃЌЛсЕМжТДэЮѓЕФГЕСОПижЦЃЌзюжеПЩФмДјРДЗЧГЃбЯжиЕФКѓЙћЁЃШчКЮПьЫйЧвзМШЗЕиЪЖБ№еЯАЮяЪЧвЛЯюМЋОпЬєеНЕФШЮЮёЁЃ
ДЋЭГЕФМЦЫуЛњЪгОѕЫуЗЈЃЈHarrisНЧЕуМьВтЁЂSIFTЫуЗЈЁЂSURFЫуЗЈЁЂORBЫуЗЈЕШЃЉЯрБШгкЩюЖШбЇЯАЫуЗЈЃЌМьВтЫйЖШТ§ЁЂзМШЗТЪЕЭЃЌКмФбТњзуДѓЖрЪ§ГЁОАЯТздЖЏМнЪЛЕФашЧѓЁЃДЫЭтЃЌетаЉДЋЭГЕФЪгОѕЫуЗЈЖМашвЊЖдЭМЯёЬсШЁЬиеїЃЌЛЛОфЛАЫЕОЭЪЧЃЌЖдЪ§ОндкИќИпЁЂИќЖрЕФЮЌЖШЩЯбАевЬиЕуЃЌЬсШЁЬиеїЕФЙ§ГЬЭЈГЃБШНЯИДдгЁЃЯрБШгкЩюЖШбЇЯАетжжДгЖЫЕНЖЫЕФЫуЗЈЃЌДЋЭГЕФЪгОѕЫуЗЈФбвдПЊЗЂЃЌВЛОпгХЪЦЁЃЩюЖШбЇЯАЫуЗЈЕФгІгУЃЌМЋДѓЕиМгЫйСЫЮяЬхМьВтСьгђЕФЗЂеЙЃЌЭЌЪБЃЌетвВЖдЩюЖШбЇЯАЫуЗЈЙуЗКгІгУгкздЖЏМнЪЛММЪѕЃЌЦ№ЕНСЫжСЙиживЊЕФзїгУЁЃ
ЩюЖШбЇЯАЫуЗЈШЗЪЕгаКмЖргХЕуЃЌЕЋЭЌЪБЦфЪфГіНсЙћЪЧИХТЪЗжВМЪНЕФЃЌВЛФмБЃжЄМьВтЕФЭъШЋзМШЗадЁЃдкНёЬьЃЌетжжЖЫЕНЖЫЫуЗЈЕФжаМфЙ§ГЬШдШЛЪЧВЛПЩНтЪЭЕФЃЌДѓМвЮоЗЈНтЪЭЮЊЪВУДЪфШывЛеХееЦЌЃЌОЭЛсдкЫќЕФФГИіЧјгђФкМьВтЕНФГИіЮяЬхЁЃЖјДЋЭГЕФЪгОѕЫуЗЈШДОпгаГЩЪьЕФРэТлжЇГХЁЂЭИУїЕФжаМфЙ§ГЬКЭЮШЖЈЕФадФмЁЃ
БЪепБШНЯПДКУДЋЭГМЦЫуЛњЪгОѕЫуЗЈКЭЩюЖШбЇЯАЫуЗЈСНепНсКЯЃЌПЩвдГфЗжРћгУСНжжЗНЗЈЕФгХЪЦЁЃ

ЭМ13. TeslaМьВтФЃаЭПђМм
ЭМЦЌРДдДЃКTesla AI Day 2021
здЖЏМнЪЛЙЋЫОвЛАуЖМЛсЛЈЗбДѓСПСІЦјЭЖШыЕНМьВтФЃаЭЕФПЊЗЂжаЁЃЭЌбљЃЌЭјЩЯвВгаКмЖрПЊдДЕФЭМЯёМьВтФЃаЭКЭЕудЦМьВтФЃаЭЃЌЮЊбЇепЁЂЙЄГЬЪІУЧЬсЙЉвЛаЉПЊЗЂжЇГжЁЃ
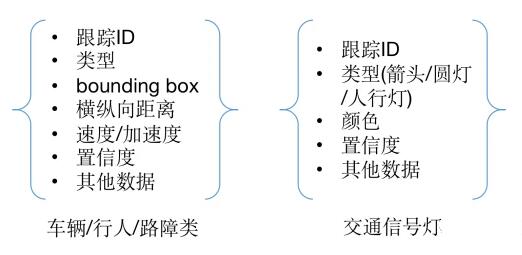
LidarКЭCameraЕФЮяЬхМьВтЃЌЫфШЛЪ§ОнЪфШыЖЫВЛЭЌЃЌЕЋЪЧЭЈЙ§ЩёОЭјТчКѓЃЌЪфГіЕФМьВтЮяЬхЖМОпгаЭЌбљЕФЪ§ОнНсЙЙЁЃЦфжажївЊАќРЈБЛМьВтЮяЬхЕФРраЭЁЂIDЁЂАќЮЇПђЃЈbounding
boxЃЌПђЖЅЕуМЏКЯЃЌ2DЛђ3DаЮЪНЃЉЁЂКсзнЯђОрРыЁЂЫйЖШЁЂМгЫйЖШЁЂжУаХЖШЕШЕШЁЃЕБШЛЃЌВЛЭЌРраЭЕФБЛМьВтЮяЬхвВЛсДцдкВЛвЛбљЕФУшЪіЬиеїЃЌБШШчКьТЬЕЦРраЭЕФеЯАЮяОЭашвЊбеЩЋаХЯЂЃЌГЕЕРЯпРраЭЕФЮяЬхВЛЪЧЪфГіАќЮЇПђЃЌЖјЪЧЪфГіШєИЩИіГЕЕРЯпЩЯЕФЙиМќЕуЃЈЭЈЙ§СЌНгетаЉЕуЙЙГЩЭъећЕФГЕЕРЯпЃЉЁЃ

ЭМ14. МьВтФЃПщЪфГіЪ§ОнНсЙЙЪОР§
ИњзйФЃПщ
дкЕЅжЁЪ§ОнжаМьВтЕНЮвУЧЙизЂЕФЮяЬхКѓЃЌЮвУЧШдШЛашвЊжЊЕРеЯАЮяЃЈГЕСОЁЂааШЫЃЉЪЧШчКЮдЫЖЏЕФЃЌГЁОАжаеЯАЮяЕФдЫЖЏаХЯЂЃЈЙьМЃЁЂЫйЖШБфЛЏЕШЃЉЖдгкКѓУцдЄВтетаЉеЯАЮядЫЖЏЙьМЃКЭПижЦздГЕдЫЖЏжСЙиживЊЁЃЯывЊЕУЕНеЯАЮяЕФРњЪЗдЫЖЏзДЬЌЃЌОЭашвЊвЛаЉРњЪЗжЁаХЯЂЃЌДгСЌЙсЕФРњЪЗжЁаХЯЂЃЈР§ШчЃЌбаОПДгРњЪЗЕк10жЁЕНЕБЧАжЁетвЛЖЮСЌајЪБађЙ§ГЬЃЉжаЭкОђГіЮяЬхЕФдЫЖЏзДЬЌЁЃ
ЭЈГЃЪЙгУЕФЗНЗЈЪЧЃЌЗжЮіЧАКѓжЁФкМьВтЕНЕФЭЌвЛеЯАЮяЁЃШчЙћЩЯвЛжЁГіЯжЕФЮяЬхдкЯТвЛжЁвВГіЯжСЫЃЌФЧУДЧАКѓжЁФкГіЯжЕФЭЌвЛИіЮяЬхПЩвдгУЯрЭЌЕФIDРДБэЪОЃЌВЂАбМьВтНсЙћАДееЪБМфађСаДцДЂЃЌетбљОЭЕУЕНСЫФГЮяЬхдкСНжЁЪБМфФкЕФдЫЖЏзДЬЌЃЌАќРЈЫйЖШБфЛЏЁЂЮЛжУБфЛЏЁЂЗНЯђБфЛЏЕШЕШЁЃдкСЌајжЁФкВЛЖЯЪЙгУЩЯЪіЙ§ГЬЃЌОЭФмЕУЕНЮяЬхЕФРњЪЗдЫЖЏзДЬЌЁЃвдЩЯОЭЪЧвЛИіИњзйЙ§ГЬЁЃ
ФЧУДЙЄГЬЪІУЧЪЧШчКЮШЗШЯЧАКѓжЁжаЕФЭЌвЛИіЮяЬхФиЃПЭЈГЃЧщПіЯТЃЌЪЧЪЙгУROIЃЈЧАКѓжЁФкЮяЬхАќЮЇПђЕФНЛВЂБШЃЉетвЛжИБъРДЦЅХфЁЃвдЭМ14ЮЊР§ЃЌдкTЪБПЬМьВтЕНСЫAКЭBСНИіеЯАЮяЃЌдкT+1ЪБПЬМьВтЕНСЫCЁЂDКЭEШ§ИіеЯАЮяЁЃЦфжаАќЮЇПђЃЈbounding
boxЃЉПЩвдБэЪОБЛМьВтЮяЬхдкЭМжаЕФЮЛжУЁЃИљОнbounding boxЕФЮЛжУЃЌКмШнвзЗЂЯжAгыCЕФжиЕўЖШКмДѓЃЌBгыEЕФжиЕўЖШвВКмДѓЃЌФЧУДОЭгаРэгЩЯраХЃЌдкетСЌајЕФСНИіЪБПЬФкЃЌAгыCЃЌBгыEЖМЗжБ№ДњБэСЫЭЌвЛИіЮяЬхЁЃ
ЕБШЛЃЌетжжЗНЗЈГЩСЂгавЛИіЧАЬсЃЌвЛАудк10жЁТЪЕФМьВтЙ§ГЬжаЃЌвВОЭЪЧ0.1sФкЃЌБЛМьВтЮяЬхЕФдЫЖЏЮЛжУБфЛЏВЛЪЧзуЙЛДѓЃЌетбљВХФмгаЧАКѓжЁbounding
boxЕФжиЕўЖШЃЌВХФмгУРДКтСПЦЅХфЙ§ГЬЁЃ

ЭМ15. ЛљгкIOUЕФЦЅХфЙ§ГЬ
дкИњзйФЃПщЃЌЭЈГЃЪЙгУЕФЗНЗЈгаПЈЖћТќТЫВЈКЭайбРРћЦЅХфЫуЗЈЁЃЕквЛВНЃЌЪЙгУПЈЖћТќТЫВЈНзЖЮвЛЖдЩЯвЛжЁЮяЬхНјаадЫЖЏЙРМЦЃЌЙРМЦГіЦфЕБЧАЪБПЬЕФЮЛжУКЭЫйЖШЁЃНгЯТРДЃЌЪЙгУайбРРћЫуЗЈЖдЩЯвЛВНжадЫЖЏЙРМЦГіЕФЮяЬхКЭЕБЧАжЁМьВтЕНЕФЮяЬхНјааЦЅХфЃЌайбРРћЫуЗЈжаЪЙгУЕФЦЅХфШЈжиОЭПЩвдНсКЯЩЯУцЫљНВЕФIOUЗНЗЈРДЩшМЦЃЌГЩЙІЦЅХфДњБэИњзйГЩЙІЁЃЕкШ§ВНЃЌЭЈЙ§ПЈЖћТќТЫВЈНзЖЮЖўИќаТБЛИњзйЮяЬхЕБЧАЕФзюгХЮЛжУКЭзюгХЫйЖШЁЃ

ЭМ16. ЕфаЭЕФИњзйЕќДњЙ§ГЬ
ДЫЭтЃЌЛЙгаЪЙгУЩёОЭјТчжБНгМьВтеЯАЮяВЂЪфГіИњзйНсЙћЕФЗНЗЈЃЌвВОЭЪЧЫЕЃЌИњзйЙ§ГЬвВЪЧдкЩёОЭјТчжаЭъГЩЕФЁЃетжжЗНЗЈашвЊЪЙгУСЌајжЁЪ§ОнбЕСЗЭјТчЃЌдкЪЙгУИУРрЩёОЭјТчЪБЃЌЪфШыЖЫОЭЪЧСЌајжЁЕФЭМЯёЛђЕудЦЃЌЪфГіЖЫШдШЛЪЧвЛЯЕСаБЛМьВтЕНЕФЮяЬхЃЌЖюЭтЕФаХЯЂЪЧетаЉЮяЬхвбООпгаСЫБЛИњзйЕФЪєадЃЌдкЪБМфађСаЩЯЃЌЭЌвЛИіЮяЬхОпгаЭЌвЛИіИњзйЪЖБ№IDЁЃдкЭјЩЯЃЌКмШнвзФмевЕНвЛаЉПЊдДЕФИњзйЭјТчФЃаЭЁЃ
ШкКЯФЃПщ
ЕБЧАЃЌздЖЏМнЪЛММЪѕашвЊЪЙгУЖржжДЋИаЦїЃЌВЂЖдетаЉВЛЭЌДЋИаЦїЪ§ОнНјааДІРэЃЌзюжеЪфГіЕЅвЛНсЙћЃЌетОЭЩцМАЕНЪ§ОнШкКЯЁЃШкКЯгжПЩвдЗжЮЊЧАШкКЯКЭКѓШкКЯЃЌЫќУЧЕФЧјБ№дкгкЃЌШкКЯЙ§ГЬЪЧдкМьВтКЭИњзйЙ§ГЬжЎЧАЛЙЪЧжЎКѓЁЃдкApolloИажЊШэМўПђМмжаЃЌШкКЯЙ§ГЬЮЛгкВЛЭЌДЋИаЦїЪ§ОнИњзйДІРэжЎКѓЃЌЪЧвЛИіЕфаЭЕФКѓШкКЯЙ§ГЬЁЃећИіЙ§ГЬОЭЪЧНЋLidarЁЂCameraЁЂRadarШ§ЬѕДІРэТЗЯпЪфГіЕФзЗзйНсЙћНјааШкКЯЃЌаое§БЛзЗзйЮяЬхЕФИїЯюВЮЪ§Ъ§ОнЁЃ
ОйИіМђЕЅЕФР§згЃЌМйЩшLidarЁЂCameraЁЂRadarШ§жжДЋИаЦїЕФЪБМфвбОЭЌВНЃЌЖдгкЭЌвЛжЁФкЕФБЛМьВтЮяЬхAРДЫЕЃЌЪЙгУLidarЪ§ОнМьВтГіСЫНсЙћa1ЃЌЪЙгУCameraЪ§ОнМьВтГіСЫНсЙћa2ЃЌЪЙгУRadarЪ§ОнМьВтГіСЫНсЙћa3ЃЌШкКЯЙ§ГЬОЭЪЧдкетШ§ИіНсЙћжаЃЌЭЈЙ§вЛЖЈЕФВпТдЕУЕНзюгХЕФМьВтНсЙћЁЃ
етРяЕФШкКЯВпТдЛсзлКЯПМТЧИїРрДЋИаЦїЕФгХСгЪЦЃЌБШШчLidarдкВтОрЗНУцЕФБэЯжадФмИќКУЃЌФЧУДЖдгкОрРыЛђепПеМфЮЛжУЕФВЮЪ§ЃЌОЭЛсИќЧуЯђгкбЁдёЭЈЙ§LidarЪ§ОнЕУЕНЕФНсЙћЁЃЖдгкНЛЭЈБъжОЁЂКьТЬЕЦЁЂГЕЕРЯпетРрЮяЬхЃЌКѓШкКЯЕФЙ§ГЬЛсИќЧуЯђгкбЁдёЭЈЙ§CameraЪ§ОнЕУЕНЕФНсЙћЁЃЛљгкетбљЕФПМСПЃЌОЭПЩвдНЋЖрРрДЋИаЦїЪ§ОнЕФИажЊНсЙћНјааШкКЯЃЌДгЖјЕУЕНзюгХНтЁЃ
СэвЛжжЧАШкКЯЕФЗНЪНЪЧЃЌдкЪ§ОнЪфШыЖЫОЭНЋLidarЁЂCameraЕШЪ§ОнзщКЯЦ№РДЃЌаЮГЩвЛжжаТЕФЪ§ОнЬхЃЌетИіЪ§ОнРяМШгаЭМЯёЮЦРэЁЂбеЩЋетбљЕФаХЯЂЃЌЭЌЪБвВАќКЌСЫ3DПеМфжаЕФОрРыаХЯЂЃЌетжжЪ§ОнНсЙЙМгЧПСЫВЛЭЌДЋИаЦїЪ§ОнжЎМфЕФЪ§ОнЙиСЊадЁЃ

ЭМ17. LidarКЭRadarЪ§ОнЕФЧАШкКЯТпМ
ЭМЦЌРДдДЃКгХДябЇГЧЮоШЫМнЪЛЙЄГЬЪІбЇЮЛ
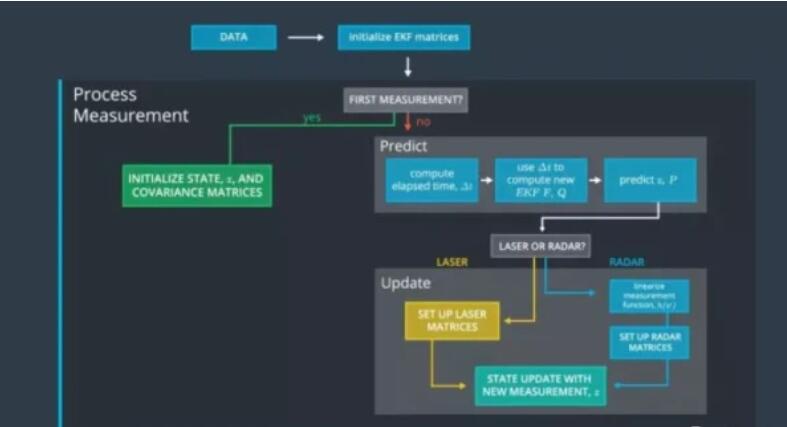
ЩЯЭММђЕЅНщЩмСЫLidarКЭRadarЪ§ОнШкКЯЕФТпМЁЃдкЪзДЮЛёШЁЪ§ОнЪБЃЌЯШГѕЪМЛЏKalmanТЫВЈЦїЕФИїИіОиеѓВЮЪ§ЃЌНгЯТРДЖдСНРрЪ§ОнНјаадЄВтКЭИќаТЃЌзюКѓЪфГіШкКЯКѓеЯАЮяЕФЮЛжУЁЂЫйЖШЁЃ

ЭМ18. Ъ§ОнЧАШкКЯЕФВНжш
ЭМЦЌРДдДЃКжЧааепПЦММ
ЩЯЭММђЕЅНщЩмСЫжЧааепПЦММдкДЋИаЦїЪ§ОнЧАШкКЯЙ§ГЬжаЕФВНжшЃЌАќРЈСЫВЩМЏМАдЄДІРэЁЂзјБъзЊЛЛКЭаХЯЂШкКЯЁЃЦфжазюгаФбЖШЕФВПЗжОЭЪЧаХЯЂШкКЯЃЌЫќАќРЈСЫЪ§ОнЙиСЊЁЂЪБМфЭЌВНЁЂЪ§ОнШкКЯЁЂФПБъЩњУќжмЦкЙмРэЫФИіВНжшЁЃЪзЯШЪЧдкЪ§ОнЙиСЊНзЖЮЃЌНЈСЂЦРМлжИБъВЂбЁдёШЋОжзюНќСкЦЅХфЗНЗЈЃЛЕкЖўВНЖдЖрДЋИаЦїНјааЪБМфЭЌВНЃЌбЁгУСЫЙЬЖЈЪБЦЏКЭЫцЛњЪБЦЏЕФЗНЗЈЃЛ
ЕкШ§ВНЃЌЪЙгУСЃзгТЫВЈЫуЗЈШкКЯЪ§Он;зюКѓЃЌЖдФПБъНјааЩњУќжмЦкЙмРэЃЌЬсИпШкКЯКѓЪ§ОнЕФТГАєадЁЃ
ЭЌбљЕиЃЌЭЈЙ§БъзЂЧАШкКЯЪ§ОнВЂбЕСЗФЃаЭЃЌПЩвдЕУЕНЪЪгУгкЧАШкКЯЪ§ОнЕФЩёОЭјТчЃЌетжжФЃаЭЕФЪфГіНсЙћвВЪЧЖдЭЌвЛЮяЬхЕФМьВтНсЙћЃЌШЛКѓдйНјааЮяЬхИњзйЃЌВЛЭЌЕФЪЧЃЌМьВтИњзйжЎКѓЃЌВЛашвЊдйДЮШкКЯЁЃ
ФПЧАЃЌКмЖржїСїЙЋЫОЖМдкГЏзХЧАШкКЯЕФЗНЪНбаОПЃЌетбљзіЕФКУДІжЎвЛОЭЪЧЬсЧАёюКЯСЫЖржжДЋИаЦїЕФЪ§ОнЃЌвђДЫЪ§ОнЮЌЖШИќМгЗсИЛЃЌИќФмецЪЕЕиЗДгГГЁОАЁЃ
Ъ§ОнЪфГі
дкApolloЕФИажЊПђМмжаЃЌзюжеЪфГіЕНЯТгЮЕФНсЙћПЩвдЗжЮЊСНВПЗжЃЌвЛВПЗжЪЧГЕСОЁЂааШЫЕШеЯАЮяЕФЪ§ОнЃЌСэвЛВПЗжЪЧНЛЭЈаХКХЕЦЕФНсЙћЁЃГЁОАжаеЯАЮяЕФЪ§ОнПЩвдЭЈЙ§ЩЯЪіЕФЪ§ОнДІРэЙ§ГЬЕУЕНЃЌЖјНЛЭЈаХКХЕЦЕФНсЙћдђЪЧЭЈЙ§вЛжжЖрЕЦЭЖЦБЛњжЦРДЕУЕНЕФЁЃМђЕЅРДНВЃЌОЭЪЧдквЛИіТЗПкДІЃЌвЛАуЛсгаЖрИіКьТЬЕЦБЛМьВтЕНЃЌетЦфжаМШгаКьЕЦгжгаТЬЕЦЃЌвВгаЦфЫћВЛЭЌРраЭЕФЕЦЃЈжБааЁЂзѓзЊЁЂЕєЭЗЕШЕШЃЉЃЌашвЊЩшМЦвЛжжЭЖЦБЛњжЦРДОіВпЕБЧАжБааЁЂзѓзЊЛђгвзЊЕФЕЅвЛЕЦзДЬЌЁЃ
ЭМ19. ИажЊЪфГіЪ§ОнНсЙЙЪОР§
дЪМЕФДЋИаЦїЪ§ОнОЙ§ИажЊФЃПщЕФДІРэЃЌЪфГіЕФНсЙћЛсДЋЕнЕНЯТгЮдЄВтФЃПщЁЃдЄВтФЃПщжївЊЪЧеыЖдГЕСОЁЂааШЫетРреЯАЮяЃЌдЄВтеЯАЮядкЮДРДвЛЖЮЪБМфФкЕФдЫЖЏЙьМЃЁЃШЛКѓБуНјШыСЫЙцЛЎФЃПщЃЌНсКЯГЁОАаХЯЂКЭеЯАЮядЄВтЙьМЃЃЌНјааздГЕЕФТЗЯпЙцЛЎЁЃ
ДгИїРрДЋИаЦїЪ§ОнВЩМЏПЊЪМЃЌЕНЪфШыЕНИажЊФЃПщЃЌдйОЙ§МьВтЁЂИњзйЁЂШкКЯетаЉЙ§ГЬЃЌзюжеЯђЯТгЮЪфГіГЁОАФкЕФБивЊаХЯЂЁЃБОЮФМђвЊЕиНщЩмСЫвЛЯТИажЊФЃПщЕФЪ§ОнСїЖЏЁЃ
ЕБШЛЃЌИажЊФЃПщЛЙЛсЩцМАКмЖрЦфЫћЙІФмЃЌБШШчРћгУЕиЭМЪ§ОндіЧПИажЊНсЙћЁЂздЖЏТМШыВЩМЏЪ§ОнЁЂЙІФмМрПиКЭЪЇаЇеяЖЯЕШЕШЁЃетаЉЙІФмжЎМфвВДцдкзХИДдгЕФЪ§ОнНЛЛЛЃЌдкИажЊФЃПщдЫааЕФЙ§ГЬжаЙВЭЌзїгУЁЃ
| 







