| 编辑推荐: |
本文先介绍了基于图像或视频的2D物体检测和跟踪,以及2D场景的语义分割,又介绍一些经典的算法,以脉络和方向的梳理为主。
本文来自微信公众号汽车电子与软件,由火龙果软件Linda编辑、推荐。 |
|
1 前言
自动驾驶中的视觉感知模块通过图像或视频数据来了解车辆周围环境,具体的任务包括物体检测和跟踪(2D或3D物体),语义分割(2D或3D场景),深度估计,光流估计等。
这篇文章里我们先介绍一下基于图像或视频的2D物体检测和跟踪,以及2D场景的语义分割。这几个任务在自动驾驶中应用的非常广泛,各种综述文章也已经非常多了,所以这里我只选择介绍一些经典的算法,以脉络和方向的梳理为主。
深度学习自从2012年在图像分类任务上取得突破以来,就迅速的占领了图像感知的各个领域,所以下面的介绍也以基于深度学习的算法为主。
2 物体检测
2.1 两阶段检测
传统的图像物体检测算法大多是滑动窗口,特征提取和分类器的组合,比如Haar特征+AdaBoost分类器,HOG特征+SVM分类器。这类方法的一个主要问题在于针对不同的物体检测任务,需要手工设计不同的特征。因此,在深度学习兴起之前,特征设计是物体检测领域的主要增长点。
R-CNN[1]作为深度学习在物体检测领域的开创性工作,其思路还是有着很多传统方法的影子。首先,选择性搜索(Selective
Search)代替了滑动窗口,以减少窗口的数量。其次,也是最重要的一点改变,采用卷积神经网络(CNN)提取每个窗口的图像特征,以代替手工特征设计。这里的CNN在ImageNet上进行预训练,对于通用图像特征的提取非常有效。最后,每个窗口的特征采用SVM进行分类,以完成物体检测的任务。
R-CNN的一个主要问题在于选择性搜索得到的窗口数量重叠太多,这样导致特征提取部分做了很多的冗余的操作,严重影响了算法的运行效率(一张图片大约2000个候选框,GPU上也需要10秒以上的运行时间)。

R-CNN
为了重复利用不同位置的特征,Fast R-CNN[2]提出首先由CNN提取图像特征,然后再将选择性搜寻得到的候选框进行ROI
Pooling,得到同样长度的特征向量。最后采用全连接网络进行候选框分类和边框回归。这样就避免了重叠候选框的冗余运算,大幅提高了特征提取的效率。
与R-CNN相比,Fast R-CNN将VOC07数据集上的mAP从58.5%提高到70.0%,检测速度则提高了约200倍。但是,Fast
R-CNN仍然采用选择性搜索来得到候选区域,这个过程还是比较慢,处理一张图片大约需要2秒,这对于对实时性要求较高的应用来说还是远远不够的。
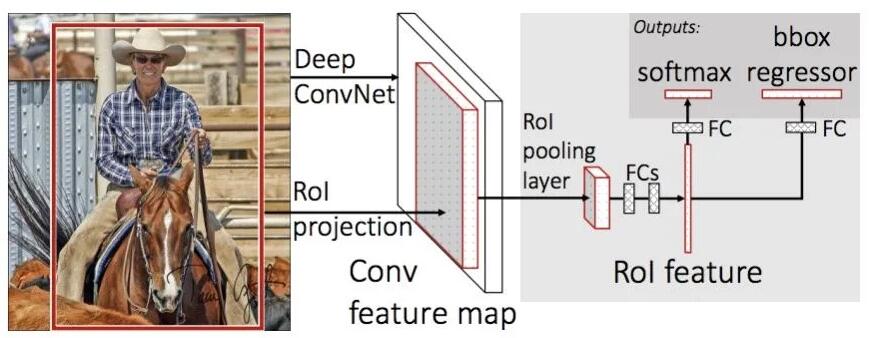
Fast R-CNN
既然选择性搜索是算法速度的瓶颈,那么人们自然就会想到,能否用神经网络来完成这个步骤呢?问题的答案就是Faster
R-CNN[3]。它利用一个区域候选网络(RPN)在特征图的基础上生成候选框。接下来的步骤与Fast
R-CNN类似,都是ROI Pooling生成候选框的特征,然后再用全连接层来做分类和回归。
Faster RCNN里出现了一个重要的概念,也就是Anchor。特征图的每个位置会生成不同大小,不同长宽比的Anchor,用来作为物体框回归的参考。Anchor的引入,使得回归任务只用处理相对较小的变化,因此网络的学习会更加容易。
Faster RCNN是第一个端到端的物体检测网络,VOC07上的mAP达到73.2%,速度也达到了17
FPS,接近于实时。
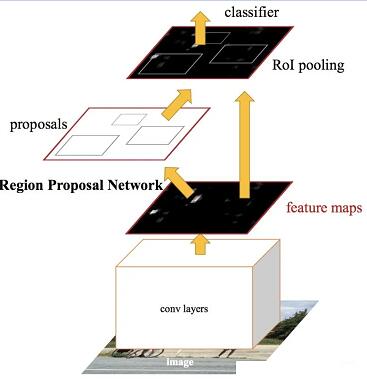
Faster R-CNN
后续的FPN[4](Feature Pyramid Network)在特征提取阶段又进行了优化,采用了类似U-Shape网络的特征金字塔结构,来提取多尺度的信息,以适应不同大小的物体检测。
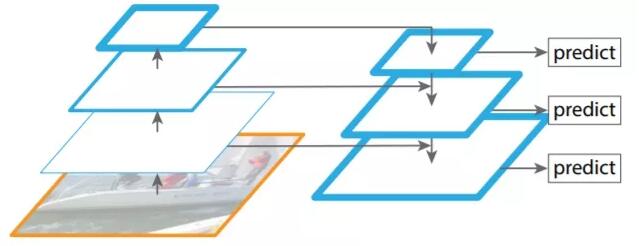
FPN
2.2 单阶段检测
两阶段的检测器需要处理大量的物体候选框,每个候选框通过ROI Pooling来生成统一长度的特征,这个过程相对比较耗时,因此影响了算法的整体速度。单阶段检测器的主要思路是利用全卷积网络,在特征图的每个位置进行物体分类和边框回归。这其实相当于在每个位置都生成候选框,但是因为省略了费时的ROI
Pooling,而只采用标准的卷积操作,因此算法的运行速度得到了提升。
SSD[5]采用了上述全卷积网络的思路,并且在多个分辨率的特征图上进行物体检测,以提高对物体尺度变化的适应能力。同时,在特征图的每个位置上采用不同尺度和长宽比的Anchor来做边框回归。
在特征图的每个位置上进行稠密的物体检测,这样做虽然省略了ROI Pooling,但会带来一个新的问题,那就是正负样本的不平衡。稠密的采样导致负样本(非物体)的数量远远大于正样本(物体)的数量,在训练中大量容易分类的负样本所产生的Loss会起支配作用,而真正有价值的困难样本反而得不到很好的学习。

SSD
为了解决这个问题,RetinaNet[6]提出了Focal Loss,根据Loss的大小自动调节权重,以代替标准的Cross
Entropy,使得训练过程更多的关注困难样本。在特征提取方面,RetinaNet也采用了FPN的结构。
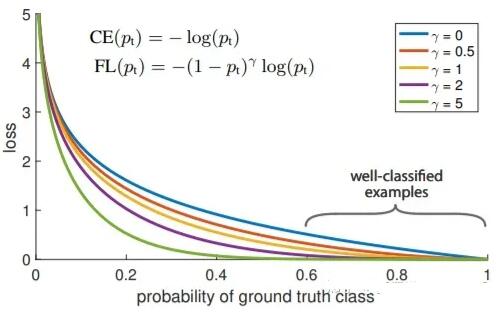
Focal Loss vs. Cross Entropy
最后,还是得说一下YOLO[7]系列的检测器,这也是工业界使用最广泛的算法,甚至可以不加之一。YOLOv1采用卷积和Pooling结合提取特征,最后的特征图空间大小为7*7。与SSD和RetinaNet不同,YOLOv1采用全连接层直接输出每个7*7位置的物体类别和边框,并不需要Anchor的辅助。每个位置输出两个物体,并选择置信度较大的那一个。当场景中小物体比较多的时候,相近位置的物体有可能会被丢掉,这也是YOLOv1的一个主要问题。
之后YOLO又推出四个改进的版本(v2-v5),增强了特征提取网络,采用多尺度特征图,利用了Anchor和IOU
Loss来辅助边框回归,以及很多其他物体检测领域的Trick,大幅提高了检测的准确率,在运行速度和部署的灵活性上也仍然保持了YOLO一贯的优势。
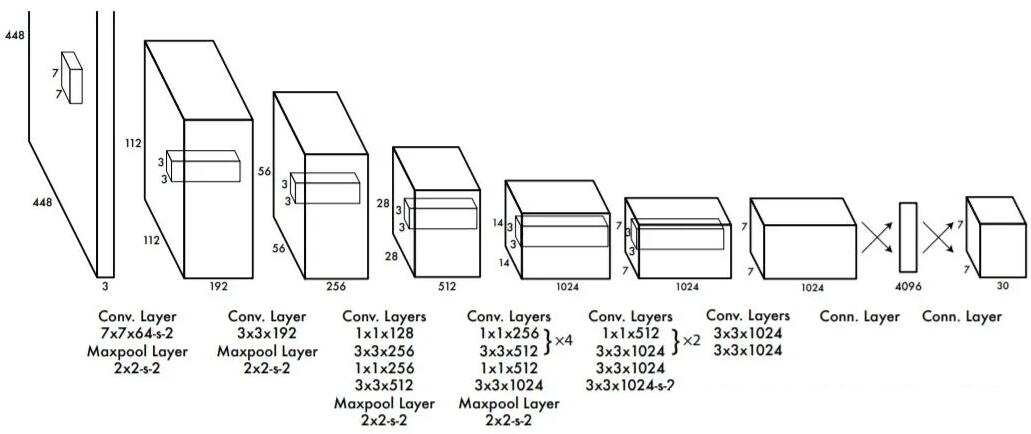
YOLO
2.3 无Anchor检测
之前介绍的方法大都采用Anchor来辅助物体框的回归。Anchor的参数是需要手工设计的,通常需要根据不同的检测任务设计不同的Anchor,影响了算法的通用性。此外,为了覆盖任务中的所有物体,Anchor的数量会比较大,对算法的速度也有一定影响。
因此,如何避免使用Anchor或者说让网络自动的学习Anchor参数,目前受到了越来越多的重视。这类方法一般是将物体表示为一些关键点,CNN被用来回归这些关键点的位置。关键点可以是物体框的中心点(CenterNet),角点(CornerNet)或者代表点(RepPoints)。
CenterNet[8]采用多层卷积神经网络处理输入图像,将其转换成物体类别的Heatmap,其上的Peak位置对应物体中心。中心点处的特征被用来进行边框的回归。整个网络可以完全通过卷积操作来实现,非常的简洁。

Objects as Center Points
只用物体中心点的特征来回归物体框是有一定局限性的,因为中心点处的特征有时并不能够很好的描述这个物体,尤其是当物体比较大的时候。CornerNet[9]通过卷积神经网络和Corner
Pooling操作预测物体框的左上角和右下角,同时输出每个角点的特征向量,用于匹配属于同一物体的角点。
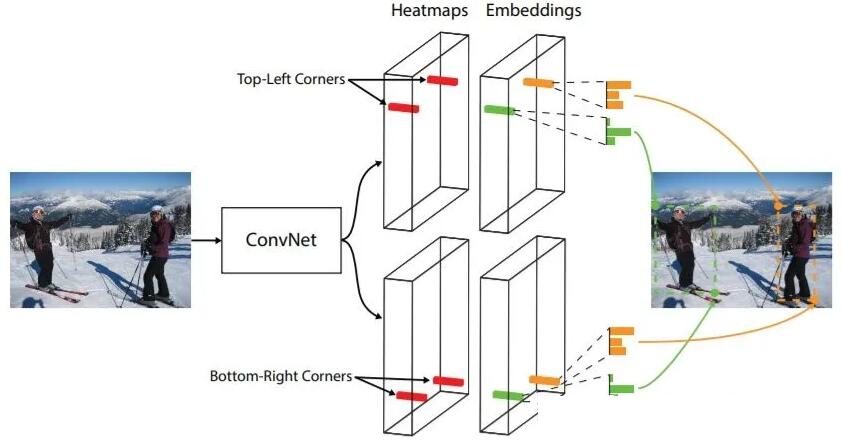
CornerNet
无论是中心点还是角点,物体都是被表示为矩形框。这种表示方法虽然有利于计算,但是没有考虑到物体的形状变化,矩形框内也包含了很多来自背景的特征,从而影响物体识别的准确率。RepPoints[10]提出将物体表示为一个代表性点集,并且通过可变形卷积来适应物体的形状变化。点集最后被转换为物体框,用于计算与手工标注的差异。

最后来说一下物体检测领域的最新趋势,那就是采用在自然语言处理(NLP)中取得巨大成功的Transformer结构。Transformer是完全基于自注意力机制的深度学习网络,在大数据和预训练模型的辅助下,性能超过经典的循环神经网络方法。2020年以来,Transformer在各种视觉任务中被应用,取得了不错的效果。Transformer在NLP任务中可以提取单词的长时间依赖关系(或者说上下文信息),对应到图像中就是提取像素的长距离依赖(或者说扩大的感受野)。
DETR[11]是Transformer在物体检测领域的代表性工作。前面介绍的所有物体检测网络无论两阶段还是单节段,无论采用Anchor与否,都是在图像空间上进行稠密的检测。而DETR将物体检测看作set
prediction问题,直接输出稀疏的物体检测结果。具体的流程是先采用CNN提取图像特征,然后用Transformer对全局的空间关系进行建模,最后得到的输出通过二分图匹配算法与手工标注进行匹配。DETR一般需要更长的训练收敛时间,由于感受野的扩大,在大物体的检测上效果较好,而在小物体上相对较差。

DETR
2.4 性能对比
下面我们来对比一下以上介绍的部分算法,准确度采用MS COCO数据库上的mAP作为指标,而速度则采用FPS来衡量。从下表的对比中可以看出,YOLOv4在准确率和速度上表现都很好,因此也是目前工业界采用最广泛的模型。最新的DETR模型也有着非常不错的准确率,后续应该还有更多的改进工作出现。这里需要说一下的是,由于网络的结构设计中存在很多不同的选择(比如不同的输入大小,不同的Backbone网络等),各个算法的实现硬件平台也不同,因此准确率和速度并不完全可比,这里只列出来一个粗略的结果供大家参考。
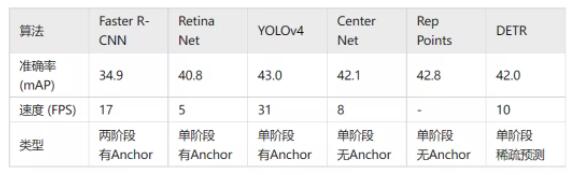
3 物体跟踪
在自动驾驶应用中,输入的是视频数据,需要关注的目标有很多,比如车辆,行人,自行车等等。因此,这是一个典型的多物体跟踪任务(MOT)。对于MOT任务来说,目前最流行的框架是Tracking-by-Detection,其流程如下:
由物体检测器在单帧图像上得到物体框输出。
提取每个检测物体的特征,通常包括视觉特征和运动特征。
根据特征计算来自相邻帧的物体检测之间的相似度,以判断其来自同一个目标的概率。
将相邻帧的物体检测进行匹配,给来自同一个目标的物体分配相同的ID。
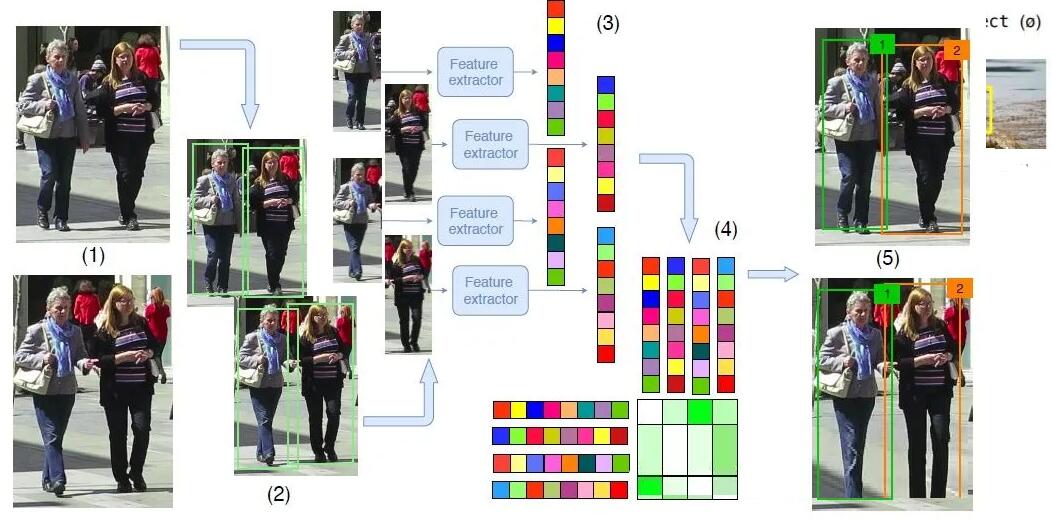
Tracking-by-Detection方法流程[12]
深度学习在以上这四个步骤中都有应用,但是以前两个步骤为主。
在步骤1中,深度学习的应用主要在于提供高质量的物体检测器。理论上说,所有的物体检测器都可以用来提供检测框,但是由于检测的质量对Tracking-by-Detection方法来说非常重要,因此一般都选择准确率较高的方法,比如说Faster
R-CNN。SORT[13]是这个方向早期的工作之一,作者采用Faster R-CNN代替ACF物体检测器,在MOT15数据库上将物体跟踪准确率指标(MOTA)的绝对值提高了18.9%。SORT采用卡尔曼滤波来预测目标的运动(得到运动特征),并采用匈牙利算法来计算物体的匹配。
在步骤2中,深度学习的应用主要在于利用CNN提取物体的视觉特征。SORT算法后续采用CNN进行特征提取,这个扩展算法被称为DeepSORT[14]。
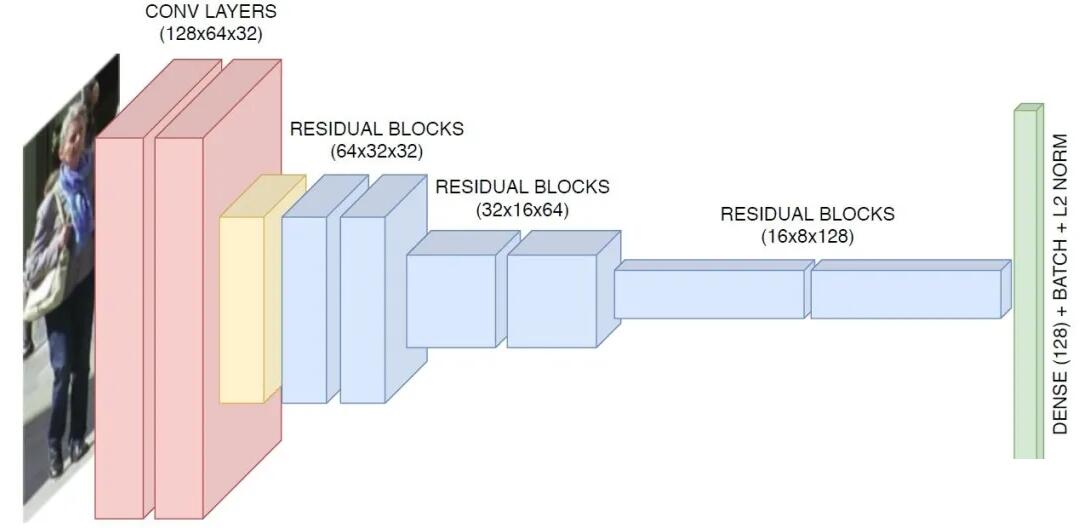
DeepSORT中的视觉特征提取网络
深度学习在步骤3和4中的应用较少。其中一个比较典型的方法由Milan等人[15]提出的一个端对端的物体跟踪算法。在这个算法中,一个RNN网络被用来模拟贝叶斯滤波器,完成主要的检测工作,其包含运动运动预测模块,状态更新模块和Track管理模块。其中状态更新模块可以完成物体匹配(Association)的工作,Association向量则由一个LSTM来提供。这个方法的跟踪效果并不是很好,但是由于特征简单,速度可以达到165FPS
(不包含物体检测模块)。

Milan等人提出的端对端物体跟踪网络
除了Tracking-by-Detection以外,还有一种框架称之为Simultaneous Detection
and Tracking,也就是同时进行检测和跟踪。CenterTrack[16]是这个方向的代表性方法之一。CenterTrack来源于之前介绍过的单节段无Anchor的物体检测算法CenterNet。与CenterNet相比,CenterTrack增加了前一帧的RGB图像和物体中心Heatmap作为额外输入,增加了一个Offset分支用来进行前后帧的Association。与之前介绍的多个阶段Tracking-by-Detection策略相比,CenterTrack将检测和匹配阶段用一个网络来实现,提高了MOT系统的速度。

CenterTrack
4 语义分割
深度学习在语义分割上最早的应用比较直接,也就是对固定大小的图像块进行语义分类。这里对图像块进行分类的网络其实就是一些全连接层,因此块的大小需要固定。显然,这种简单粗暴的方式不是最优的,尤其是无法有效的利用空间上下文信息,而这个信息对于语义分割来说是非常重要的。
为了更好的提取上下文信息,神近网络需要更大的感受野。全卷积网络(FCN)[17]通过叠加多个卷积层和下采样层,不断地扩大感受野,提取高层次空间上下文特征,最终的特征图经过反卷积上采样后恢复到原始图像的分辨率,其每个位置的输出对应了该位置的语义分类。虽然下采样操作有利于上下文特征提取并降低计算量,但也存在一个问题,那就是空间细节信息的丢失,这会影响最终的语义分割结果在位置上的分辨率和正确性。

FCN
U-Net[18]采用了类似编码器-解码器的结构,但是在同样分辨率的特征图之间,增加了Skip连接。这样做的好处是可以同时保留高层的上下文特征和底层的细节特征,让网络通过学习来自动的平衡上下文和细节信息的比重。
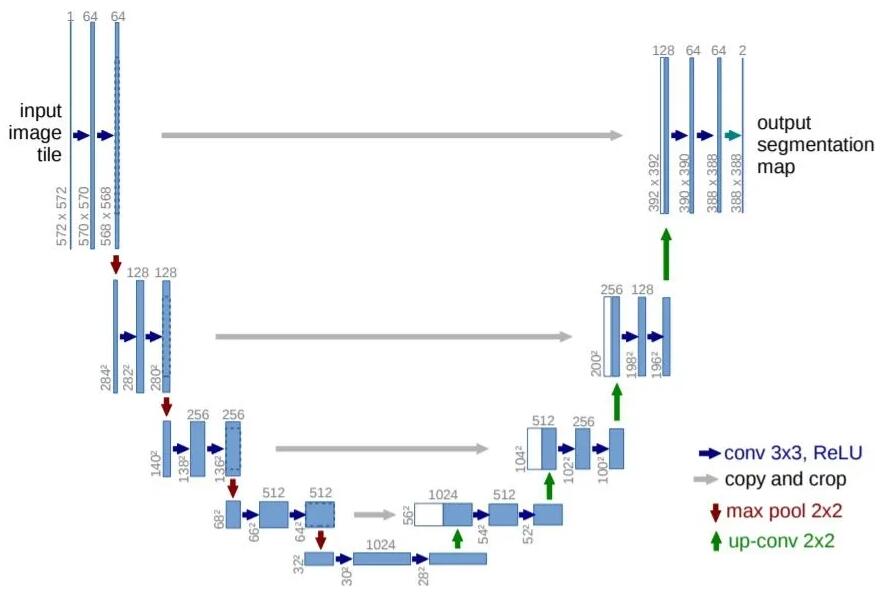
U-Net
在语义分割中,上下文信息和细节信息都很重要。FCN只关注了上下文信息,而U-Net则通过层间的Skip连接同时保留了两种信息。语义分割领域后续的大部分工作都是在致力于更好的保留这两种信息。
空洞卷积(Dilated/Atrous Convolution)对标准卷积操作的卷积核进行了修改,使其覆盖更大的空间位置。空洞卷积可以用来代替了下采样,一方面可以保持空间分辨率,另一方面也可以在不增加计算量的前提下扩大感受野,以更好的提取空间上下文信息。
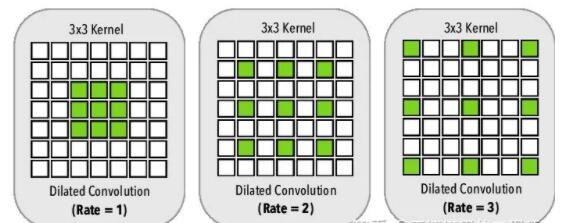
Dilated Convolution
DeepLab[18]系列的方法使用扩张卷积和ASPP(Atrous Spatial Pyramid
Pooling )结构,对输入图像进行多尺度处理。最后采用传统语义分割方法中常用的条件随机场(CRF)来优化分割结果。CRF作为后处理的步骤单独训练。
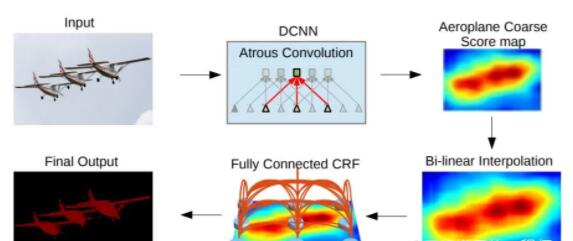
DeepLab
最后一个介绍的方法是采用大卷积核。这是一种很自然的增加感受野的方法,并且在Stride不变的情况下卷积结果的空间分辨率也不会受影响。但是大卷积核会显著的增加计算量,这也是为什么要采用空洞卷积的原因。Large
Kernel Matters[19]这篇文章提出将二维的大卷积核(KxK)分解为两个一维的卷积核(1xK和Kx1),二维卷积的结果用两个一维卷积结果的和来模拟。这样做可以将计算量由O(KxK)降低到O(K)。

一个二维卷积分解为两个一维卷积
| 





 订阅
订阅