| 编辑推荐: |
本文将以案例的形式介绍Efficient Perception在全景分割、单目深度估计、红绿灯识别、点云运动预测和点云中3D多物体跟踪方面的应用。希望对您的学习有所帮助。
本文来自于微信公众号我爱计算机视觉,由火龙果软件Linda编辑、推荐。 |
|
这里面Efficient Perception集中表现在两个方面,分别是:Data-Efficient和Model-Efficient。
Data-Efficient:目的是通过机器学习的方法,来利用和挖掘海量未标注的自动驾驶的数据,来加快感知模型的开发。
Model-Efficient:目的是利用数据驱动的学习方式,来替代工程师的手动设计以及手动调参,使得感知模型可以更方便、更快捷地部署到新的场景,解决新的类别。
本文将以案例的形式介绍Efficient Perception在全景分割、单目深度估计、红绿灯识别、点云运动预测和点云中3D多物体跟踪方面的应用。内容有点多,但绝对是干货,无论是对做开发还是做研究的同学!
Data-Efficient
为什么要有 Data-Efficient Learning?这和在真实算法研发中面对的数据困境有很大关系。

轻舟智航自动驾驶车辆传感器方案
以轻舟智航自动驾驶车的硬件配置为例,它的传感器通常包括了激光雷达、相机、毫米波雷达、IMU、GPS等,其中激光雷达和相机往往有多个。统计发现平均每天一辆自动驾驶的车辆产生4TB的数据,但只有不到5%的数据最终用于开发端,其中被用作最终标注来进行模型训练的更是少之又少,而这只是一辆车的数据情况。考虑到整个无人驾驶产业,像轻舟智航这样的无人驾驶的公司,自动驾驶车队在不断扩张,面临严重的数据挖掘和利用的问题。
如下图,是数据挖掘和标注中的常见的一些难题:
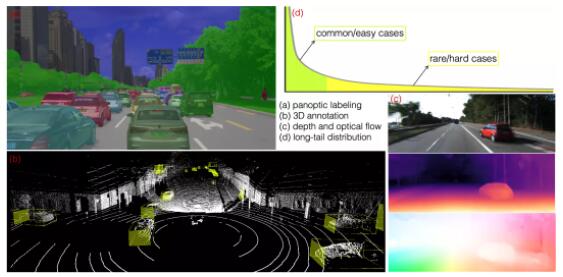
自动驾驶场景下数据挖掘和标注中的常见难题
例如(a)图是展示的全景分割的图像,统计发现对全景分割复杂的场景,比如大于50个物体的时候,仅仅对一幅图像进行精细的像素级标注,就需要超过数十分钟的时间,如果对一个自动驾驶车队的所有数据进行标注,将会是特别耗费人力、财力的事情。
(b)图表示的是在点云中进行3D的标注,包括所感兴趣的物体的3D位置、大小和朝向的信息。在点云中进行标注是非常困难的,经常会出现错误,而且非常费时。
(a)和(b)虽然比较困难,但是还是比较可行的,但是对于有些任务,例如(c)图所示的通过单目相机或者是多帧进行深度估计或者光流估计,甚至几乎没办法提供标注。
(d)图展示的是感知数据中的分布情况,是很明显的长尾分布。这意味着标注的数据,很大程度上是在重复一些比较常见或者是比较简单的一些情况。而对于真正困难和少见的数据,一般情况下标注的效率是非常低的。
所以在轻舟智航,Data-Efficient Learning应运而生,希望通过半监督学习、自监督学习和数据合成的方式,充分利用海量的未标注或者弱标注的数据,实现高效感知的开发。
半监督学习全景分割
全景分割大体上可以分解为两个子模块:语义分割和实例分割,但在开发过程中对于一张图像进行完全标注是非常费时费力的,为了省时省力又最大化利用数据,轻舟智航团队进行了如下半监督学习与全景分割结合的探索:
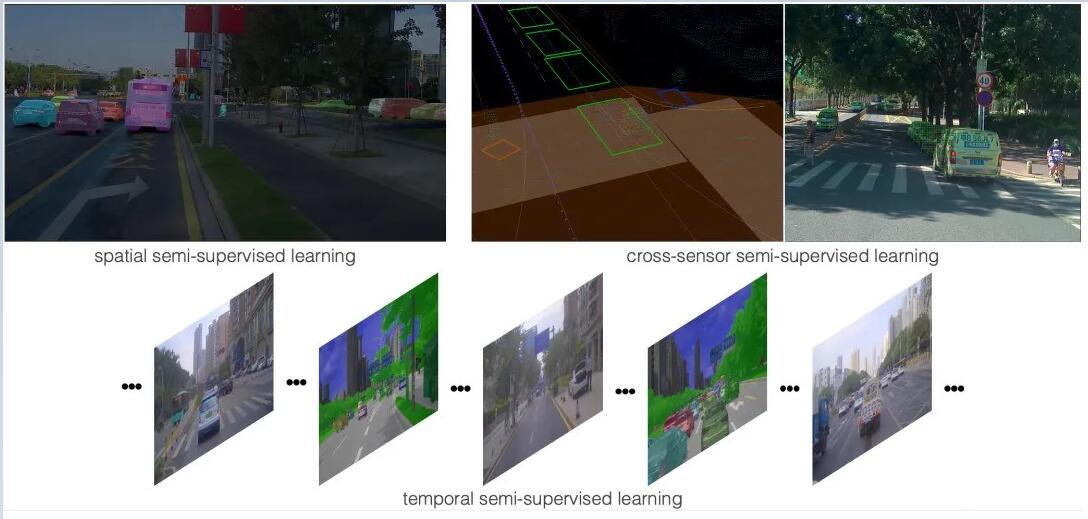
三种半监督方案示例
1)Spatial Semi-Supervised Learning(空间半监督学习):即通过大量图像的统计分析,选择性地在一张图片里进行区域标注。尽管看起来简单直接,但实践表明可以减少80%的标注成本,同时可以保证全景分割模型的效果。
2)Temporal Semi-Supervised Learning(时序半监督学习):在一些长的序列里面,通常选择关键帧来进行标注,但是这些关键帧在整个序列里所占的比例非常低。为了更好利用非关键帧的数据,通过性能更强的offboard
teacher model,在未标注的帧上生成伪标签,并将这些伪标签标注的数据和人标注的数据混合在一起,进行onboard模型的训练,可以大幅度提升全景分割模型的效果。
3) Cross-Sensor Semi-Supervised Learining(跨传感器半监督学习):以3D点云和图像数据为例,3D点云里的标注数据,包括物体的3D的bounding
box,而对于一个box内部的点,可以认为它们和box所拥有的label是一致的,所以可以利用激光雷达和相机之间的关系,将点云投射到图像上,这样就可以将点云里面标注的labels利用在图像上。
综合利用这三种半监督的形式,可以利用不同模态数据的标注,提升最终全景分割模型的开发。

以上展示的是全景分割模型的结果
上半部分是语义分割的结果,下半部分是全景分割的结果
该模型不仅精确度高,而且运行速度很快,经过优化以后,在1024×1920分辨率的图像上可以跑到200FPS。
自监督学习单目相机深度估计
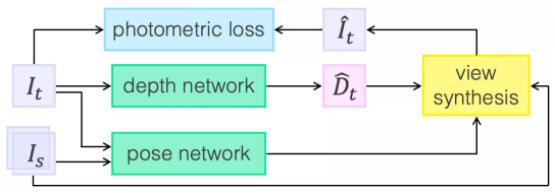
整体算法框架
上图展示了单目深度估计的一个常用框架,输入数据target image和source image,主要模块为:
a)pose network,估计target image到source image的位姿变换;
b)depth network,估计target image的depth信息;
c)view synthesis合成模块,通过结合估计出来depth、pose以及source image,合成一个新的target
image,合成结果和原始的target image进行计算loss,就可以驱动整个深度估计自监督学习的过程。
轻舟智航团队结合自动驾驶系统和环境特点,对上述算法做了改进,取得了更好的效果。上述自监督学习方式,假设环境是静止的,即图像中的每个pixel,它们拥有同样的位姿变化,但是这样的假设在场景中有移动的物体时,并不成立。尤其是当运动的物体与自车形成相对静止的状态时,会出现对运动物体非常错误的深度估计,形成无限远的空洞。为克服这一问题,轻舟智航团队提出了hybird-pose的方法,让不同的运动物体拥有自己的pose,这样可以大幅度改善对运动物体的效果。

与之前工作的结果比较,深度估计的“黑洞”消失了
通过上述改进,获得了更精确的深度估计结果,对于相对静止的运动车辆也不会出现类似黑洞的错误。
数据合成红绿灯识别
数据合成是强有力的增加训练数据的方法,低成本合成带标签的数据可大大提升模型训练效率,降低模型部署成本。
针对数据难以收集的闪烁的红绿灯(出现短时,且往往在临时设置的红绿灯上)识别,下图展示了轻舟智航团队使用的生成模型框架:
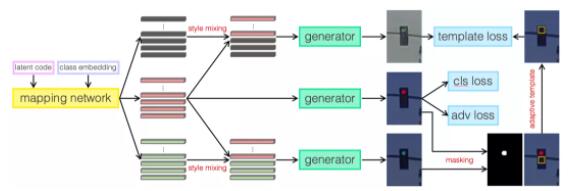
红绿灯生成算法框架
其特点有:
1)通过在输入端加入class embedding,在loss上加入classification
loss,将经典的unconditional generation,扩展到conditional generation,实现可控的图像生成。生成类别红灯、绿灯、黄灯,是程序可控制的,无需人工检查、标注。
2)通过style mixing和masking操作,可以很好地将一个亮的红绿灯状态转成灭的状态,将亮灯和灭灯组合在一起,就可以生成大量的闪烁的红绿灯的数据,而且闪烁频率也是可以控制的。
3)上述masking 操作可以让程序非常方便的获取灯体的bounding box,这可以将红绿灯分类的任务转变成检测的任务,对于相距较近的红绿灯的识别很有帮助,因为此时仅使用分类模型会造成混乱。

合成结果示例
实验证明,将上述方法大量合成的闪烁的红绿灯与真实标注的数据一同加入模型训练,可以大幅度提升红绿灯识别的性能。
自监督学习点云运动状态
自动驾驶汽车的运动状态估计是一个非常重要的课题,实时理解各种交通参与者的运动,对于各个技术模块来说都非常重要,涉及诸多任务,如检测、跟踪、预测、规划等。针对不同的点云运动预测方法,仍存在诸多挑战。
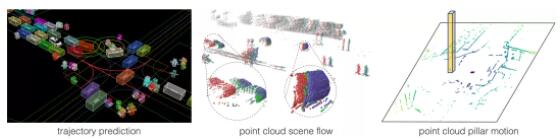
点云运动预测的3种方法示例
1)通过点云物体识别,观测历史信息,来获取运动信息,缺点是系统设计者永远无法定义所有可能出现的类别。
2)通过点云对整个场景理解,获取场景流,从而获得运动信息,这看起来是一个不错的方案,但目前场景流计算往往非常耗时,无法满足自动驾驶车对实时性的要求,暂时不具备实用价值。
3)基于BEV(Bird’s Eye View)的方式,把激光雷达点云画成一个个小网格(每个网格单元被称为体柱),点云运动信息可以通过所有体柱的位移向量来描述,该位移向量描述了每个体柱在地面上的移动大小和方向。这种方法虽然简化了点云运动信息,计算速度很快,但需要依靠大量带有标注的点云数据,而点云数据的标注成本比普通图像更高。
轻舟智航研发人员通过结合激光雷达和相机数据,改进了第三种方法,使用物体结构一致性和跨传感器正则化作为物体运动监督信息,使监督学习变成自监督学习,避免大量的点云标注,巧妙的解决了这个问题。
如下图所示,为了充分利用BEV中运动表征的优点,研究团队将点云组织成体柱(Pillar),并将与每个体柱相关的运动信息称为体柱运动(Pillar
Motion)
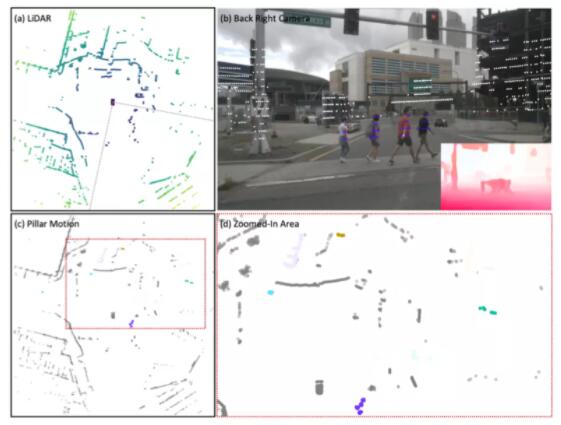
该研究提出的自监督体柱运动学习概览
研究团队先引入了一种基于点云的自监督学习方法,假设连续两次扫描之间的体柱或物体的结构形状是不变的。然而,这在大多数情况下是不成立的,因为激光雷达的稀疏扫描,连续的两个点云缺乏精确的点与点的对应。
解决方案是利用从相机图像中提取的光流来提供跨传感器正则化。如下图所示,这种设计形成了一个统一的学习框架,包括激光雷达和配对相机之间的交互:
(1)点云有助于将自车运动(Ego-Motion)导致的运动从光流中分解出来;
(2)光流为点云中的体柱运动学习提供了辅助正则化;
(3)反投影(Back-Projected)光流形成的概率运动掩膜(Probabilistic Motion
Masking)提升了点云结构的一致性。
另外,因为与相机相关的模块仅用于训练,在推理阶段不会被使用,因此,在运行时不会对相机相关的模块引入额外的计算。
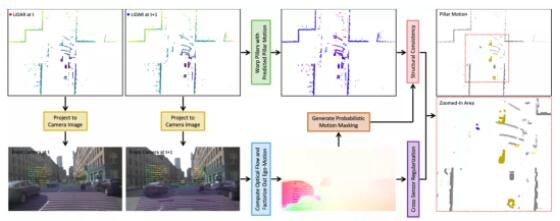
用于点云体柱运动估计的自监督学习框架

概率运动掩膜说明,
左:投影点在前向相机图像上的光流(已将自车运动分解)。
右:点云的一部分,颜色表示非空体柱的静态概率。
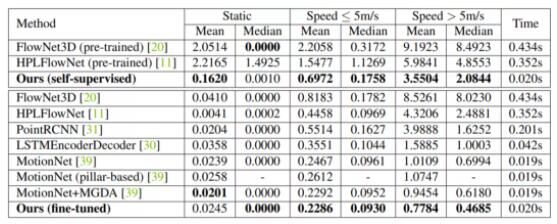
与其他SOTA方法的比较
这项工作发表于 CVPR 2021,代码和模型均已开放:
论文链接:https://arxiv.org/pdf/2104.08683.pdf
项目链接:https://github.com/qcraftai/pillar-motion
无需人工标注,效果又快又好!这项工作可说是自监督学习成功的典范了!
Model-Efficient
关于Model-Efficient,主要的目的是通过数据驱动的方式,将很多工程师手动设计和调试的任务转化成一个可学习的过程,使模型在新的环境或者是增加新的类别时,快速地进行部署和训练,节省工程师设计和调试时间。
以点云中3D多物体的跟踪为例,tracking-by-detection的方法居于主导地位。但基于tracking-by-detection方法最大的弊端是,启发式匹配步骤(heuristic
matching)通常需要人工设计匹配规则和调试相关参数。这在实际的工程应用中带来了诸多困难:
人工设计的规则受限于工程师的领域和先验知识,其效果往往不如基于数据驱动的方法好,后者可以通过机器学习从大量数据中自主学习发掘规律;
调试匹配规则参数时,往往费时费力。比如在无人驾驶场景中需要检测和跟踪多种类别目标(车、行人、两轮车等等),手动调参时,需要针对每一类别进行特定调试。
传统方法可扩展性比较差,容易重复劳动——这个数据场景调好的参数,可能在另一个数据场景效果不佳,需要重新调试。
轻舟智航的研发人员尝试在点云3D多目标跟踪任务中去除启发式匹配步骤,如下图所示:
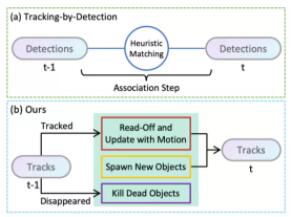
Tracking-by-Detection方法与SimTrack整体比较
给定原始点云数据,首先使用pillar或voxel方法将其体素化(voxelize),然后使用PointNet提取每个pillar或voxel的特征,在backbone中使用2D或3D卷积操作得到鸟瞰图特征。在detection
head中使用centerness map上的位置表示目标所在位置,除了输出centerness map外,detection
head还输出目标尺寸和朝向等信息。
算法的总体结构如下图所示:
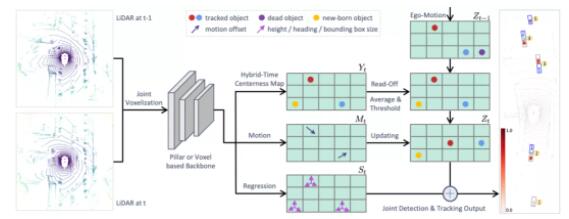
SimTrack算法总体框架
网络输出3个分支,其一为hybrid-time centerness map分支,用于检测目标在输入的多个点云中首次出现的位置;以方便读取目标的跟踪身份(tracking
identity);其二为motion updating分支,预测目标在输入的多个点云中的运动偏移量,用来把目标由首次出现的位置更新到当前所在位置;其三为回归分支,预测目标的其他属性,比如尺寸和朝向等。
在推理时,首先将上一时刻推理得到的 updated centerness map 通过自车位姿(ego-motion)转换到当前坐标系下,然后将其与当前时刻的hybrid-time
centerness map 融合,并进行阈值判断以去掉dead object;其次从上一时刻的updated
centerness map读取跟踪身份到当前时刻的hybrid-time centerness map;最后使用motion
updating分支输出的motion信息更新当前目标的位置,得到。
结合回归分支输出的目标属性信息,得到最终结果,如上图最右侧所示。在上图右侧框中,ID为1的目标表示dead
object,它有比较低的置信度;ID为2~4的目标为检测并跟踪到的目标,ID为5的目标为新出现的目标(new-born
object)。
在推理时,对于初始时刻的点云,只将该帧点云单独作为算法的输入,得到检测结果用于初始化 。

该方法SimTrack论文被 ICCV 2021 收录,将目标关联、dead object清除、new-born
object检测集成在了一起,显著降低了跟踪系统的复杂程度。
同样,论文和代码已经公开,感兴趣的同学可以参考:
论文链接:https://arxiv.org/pdf/2108.10312.pdf
项目链接:https://github.com/qcraftai/simtrack
总结
通过上述轻舟智航研发的真实案例,给我们带来很多启发:
在产品研发中实现Data-Efficient和Model-Efficient是非常重要的,这在做单一方向的学术研究中难以体会,但直接关系到成本和实际落地。
在我们认知中,单一算法往往是针对特定模式数据的,但在真实具体场景中挖掘多传感器数据的相互辅助作用,有时候会带来“奇效”,省却大量人力。
人工智能下半场,半监督学习和自监督学习越来越受到大家重视,但如何运用起来,需要深厚、细致的场景挖掘能力! | 





 订阅
订阅