| 编辑推荐: |
文章主要针对一类X-former模型,例如Reformer, Linformer, Performer, Longformer为例,这些对原版Transformer做了改进,提高了其计算和内存的效率。
,希望对您的学习有所帮助。
本文来自于51CTO,由火龙果软件Alice编辑、推荐。 |
|
Transformer回顾
self-attention是Transformer模型的关键定义特征。该机制可以看作是类似graph的归纳偏差(inductive bias),它可将序列中的所有token与基于相关的pooling操作相联系。self-attention 的一个众所周知的问题是quadratic级别的 时间和内存复杂度 ,阻碍许多设置的模型规模化(scalability)。所以,最近提出了解决该问题的大量变型,这里将这类模型称为 efficient Transformers 。
efficient self-attention模型在长序列建模的应用中至关重要,例如文档、图像和视频通常都由相对大量的像素或token组成。因此,处理长序列的效率对于Transformers的广泛采用至关重要。
如图是一个标准的Transformer架构:

Transformer是通过将Transformer blocks彼此堆叠而形成的多层体系结构。Transformer blocks的特点包括 multi-head self-attention 机制、positionwise前馈网络(feed-forward network)、层归一化(LN)模块和残差连接器(residual connectors)。
Transformer模型的输入通常是形状为BxN的张量,其中B是批处理(batch)大小,N是序列长度。该输入先穿过一个嵌入层,该层将每个one-hot token表示转换为d-维的嵌入向量,即BxNxd。然后,新张量与位置编码相加,并通过一个multi-head self-attention模块。
位置编码可以是正弦输入形式或者可训练的嵌入方式。multi-head self-attention模块的输入和输出通过残差连接器和层归一化层(LN)模块连接。然后,将multi-head self-attention模块的输出传递到两层前馈网络(FFN),类似于以残差方式连接层归一化(LN)模块。
带层归一化模块的残差连接器定义为:

而在Multi-Head Self-Attention的单个head操作定义为:

Attention矩阵A = QK^T主要负责学习序列中token之间的校准分。这会推动self-attention的自我校准过程,从而token学习彼此之间的聚类。不过,这个矩阵计算是一个效率的瓶颈。
FFN的层操作定义为:

这样整个Transformer block的操作定义是:

下面要注意的是Transformer模块使用方式的不同。Transformer主要使用方式包括:(1) 编码器 (例如用于分类),(2) 解码器 (例如用于语言建模)和(3) 编码器-解码器 (例如用于机器翻译)。
在编码器-解码器模式下,通常有多个multi-head self-attention模块,包括编码器和解码器中的标准self-attention,以及允许解码器利用来自解码器的信息的编码器-解码器cross-attention。这影响了self-attention机制的设计。
在编码器模式中,没有限制或self-attention机制的约束必须是因果方式,即仅取决于现在和过去的token。
在编码器-解码器设置中,编码器和编码器-解码器cross-attention可能是无因果方式,但解码器的self attention必须是因果方式。设计有效的self attention机制,需要支持AR(auto-regressive)解码的因果关系,这可能是一个普遍的限制因素。
Efficient Transformers
Efficient Transformers的分类如图,其对应的方法在近两年(2018-2020)发表的时间、复杂度和类别见表:


注:FP = Fixed Patterns/Combinations of Fixed Patterns, M = Memory, LP = Learnable Pattern, LR = Low Rank, KR = Kernel, RC = Recurrence.
除segment-based recurrence外,大多数模型的主要目标是对attention matrix做quadratic级别开销近似。每种方法都将稀疏的概念应用于原密集的attention机制。
Fixed patterns(FP):self attention的最早改进是将视场限制为固定的、预定义模式(例如局部窗和固定步幅的块模式)来简化attention matrix。
- Blockwise Patterns这种技术在实践中最简单的示例是blockwise(或chunking)范式,将输入序列分为固定块,考虑局部接受野(local receptive fields)块。这样的示例包括逐块和/或局部attention。将输入序列分解为块可将复杂度从N^2降低到B^2(块大小),且B << N,从而显著降低了开销。这些blockwise或chunking的方法可作为许多更复杂模型的基础。
- Strided patterns是另一种方法,即仅按固定间隔参与。诸如Sparse Transformer和/或Longformer之类的模型,采用“跨越式”或“膨胀式“视窗。
- Compressed Patterns是另一条进攻线,使用一些合并运算对序列长度进行下采样,使其成为固定模式的一种形式。例如,Compressed Attention使用跨步卷积有效减少序列长度。
Combination of Patterns (CP):其关键点是通过组合两个或多个不同的访问模式来提高覆盖范围。例如,Sparse Transformer 将其一半的头部分配给模式,结合strided 和 local attention。类似地,Axial Transformer 在给定高维张量作为输入的情况下,沿着输入张量的单轴应用一系列的self attention计算。本质上,模式组合以固定模式相同的方式降低了内存的复杂度。但是,不同之处在于,多模式的聚集和组合改善了self attention机制的总覆盖范围。
Learnable Patterns (LP):对预定FP模式的扩展即可学习。毫不奇怪,使用可学习模式的模型旨在数据驱动的方式学习访问模式。LP的关键是确定token相关性,将token分配给buckets 或者clusters。值得注意的是,Reformer引入了基于哈希的相似性度量,有效地将token聚类为chunks。类似地,Routing Transformer在token上采用在线的k-means聚类。同时,Sinkhorn排序网络(Sorting Network)通过学习对输入序列的blocks排序来显露attention weight的sparsity。所有这些模型中,相似性函数与网络的其它部分一起进行端到端训练。LP的关键点仍然是利用固定模式(chunked patterns)。但是,此类方法学会对输入token进行排序/聚类,即保持FP方法效率优势的同时,得到更优的序列全局视图。
Memory:另一种表现突出的方法,用一个side memory模块,可以一次访问多个token。通用形式是全局存储器,能够访问整个序列。全局token充当记忆的一种形式,从输入序列的token中学习聚集。这是最早在Set Transformers中引入的inducing points方法。这些参数通常被解释为“memory”,并用作将来处理的临时上下文信息。这可以看作是parameter attention的一种形式。全局内存也用于ETC和Longformer。借着数量有限的内存(或者inducing points),对输入序列采用类似pooling操作进行压缩,这是设计有效的self attention模块时可以使用的技巧。
Low-Rank方法:另一种新兴技术,利用self attention矩阵的低秩近似来提高效率。关键点是假设NxN矩阵的低秩结构。Linformer是此技术的经典示例,将keys和values的长度维投影到较低维的表示形式(N-》 k)。不难发现,由于NxN矩阵现在已分解为Nxk,因此该方法改善了self attention的存储复杂性问题。
Kernels:另一个最近流行的提高Transformers效率的方法,通过核化(kernelization)查看attention机制。核的使用使self attention机制能够进行巧妙的数学重写,避免显式地计算NxN矩阵。由于核是attention矩阵的一种近似形式,因此也可以视为Low Rank方法的一种。
Recurrence:blockwise方法的直接扩展是通过递归连接这些块。Transformer-XL提出了一种segment-level 递归机制,该机制将多个segment和block连接起来。从某种意义上说,这些模型可以看作是FP模型。
内存和计算复杂度分析
该综述对以下17个方法进行了内存和计算复杂度分析,即
1、 Memory Compressed Transformer :“Generating wikipedia by summarizing long sequences” 如图

2、 Image Transformer :“Image Transformer” 如图

3、 Set Transformer :“Set transformer: A framework for attention-based permutation-invariant neural networks“ 如图

4、 Sparse Transformer :“Generating long sequences with sparse transformers”如图

5、 Axial Transformer :“Axial attention in multidimensional transformers.“如图

6、 Longformer :“Longformer: The long-document transformer“如图

7、 Extended Transformer Construction (ETC):“Etc: Encoding long and structured data in transformers“如图

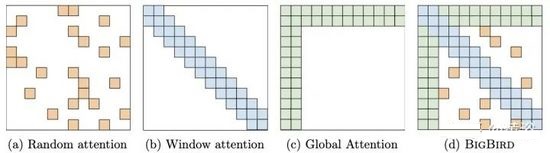
8、 BigBird :“Big Bird: Transformers for Longer Sequences“如图
9、 Routing Transformer :“Efficient content-based sparse attention with routing transformers“如图

10、 Reformer :“Reformer: The efficient transformer“如图


11、 Sparse Sinkhorn Transformer :“Sparse sinkhorn attention“如图

12、 Linformer :“Hat: Hardware-aware transformers for efficient natural language processing“如图




13、 Linear Transformer :“Transformers are rnns: Fast autoregressive transformers with linear attention“ 如图是其算法伪代码

14、 Performer :“Masked language modeling for proteins via linearly scalable long-context transformers“ 如图是Fast Attention via Orthogonal Random Features (FAVOR)的算法伪代码

15、 Synthesizer :“Synthesizer: Rethinking self-attention in transformer models.“如图

16、 Transformer-XL :“Transformer-xl: Attentive language models beyond a fixed-length context“如图

17、 Compressive Transformers :“Compressive transformers for long-range sequence modelling“如图

评估基准
尽管该领域忙于使用新的Transformer模型,但几乎没有一种简单的方法可以将这些模型比较。许多研究论文选择自己的基准来展示所提出模型的功能。再加上不同的超参数设置(例如模型大小和配置),可能难以正确地找到性能提升的原因。此外,一些论文将其与预训练相提并论,使区分这些不同模型相对性能的难度更大。 考虑使用哪个基本高效的Transformer block,仍然是一个谜。
一方面,有多种模型集中在 generative modeling ,展示了提出的Transformer单元在序列AR(auto-regressive)建模上的能力。为此,Sparse Transformers, Adaptive Transformers, Routing Transformers 和 Reformers主要集中在generative modeling任务。这些基准通常涉及在诸如Wikitext、enwik8和/或ImageNet / CIFAR之类的数据集上进行语言建模和/或逐像素生成图像。而segment based recurrence模型(例如Transformer-XL和Compressive Transformers)也专注于大范围语言建模任务,例如PG-19。
一方面,一些模型主要集中于**编码(encoding only)**的任务,例如问题解答、阅读理解和/或从Glue基准中选择。例如ETC模型仅在回答问题基准上进行实验,如NaturalQuestions或TriviaQA。另一方面,Linformer专注于GLUE基准测试子集。这种分解是非常自然和直观的,因为ETC和Linformer之类的模型无法以AR(auto-regressive)方式使用,即不能用于解码。这加剧了这些编码器模型与其他模型进行比较的难度。
有些模型着眼于上述两者的平衡。Longformer试图通过在生成建模和编码器任务上运行基准来平衡这一点。Sinkhorn Transformer对生成建模任务和仅编码任务进行比较。
此外,还值得注意的是,尽管Seq2Seq任务的**机器翻译(MT)**是普及Transformer模型的问题之一,但这些有效的Transformer模型没有能对MT进行多些的评估。这可能是因为MT的序列长度不足以保证这些模型的使用。
尽管generative modeling、**GLUE(General Language Understanding Evaluation)**和/或question answering,似乎是这些应用的通用评估基准,但仍有一些基准可供小部分论文单独进行评估。首先,Performer模型会对masked language modeling进行评估,和其他有效的Transformer模型进行了正面对比。而且Linear Transformer还对语音识别进行评估,这是比较罕见的了。
效率方面的比较
另外,论文最后还对这些效率提高的方法做了分析比较,主要是几个方面:
- Weight Sharing
- Quantization / Mixed Precision
- Knowledge Distillation (KD)
- Neural Architecture Search (NAS)
- Task Adapters
| 





 订阅
订阅