| 编辑推荐: |
文章主要介绍AI语音预处理,包括
预滤波
、
A/D转化
、
预加重
、
分帧
、
加窗
、
端点检测
,希望对您的学习有所帮助。
本文来自于CSDN,由火龙果软件Alice编辑、推荐。 |
|
1 预滤波
CODEC(所谓Codec,就是编码-解码器“Coder-Decoder”的缩写。说得通俗一点,对于音频就是A/D和D/A转换。)前端带宽为300-3400Hz(语音能量主要集中在250~4500Hz)。的抗混叠滤波器。
工程测量中采样频率不可能无限高也不需要无限高,因为一般只关心一定频率范围内的信号成份。为解决频率混叠,在对模拟信号进行离散化采集前,采用低通滤波器滤除高于1/2采样频率的频率成份。实际仪器设计中,这个低通滤波器的截止频率(fc) 为:
截止频率(fc)= 采样频率(fs) / 2.56
2 A/D转化
8kHz的采样频率,12bit的线性量化精度。
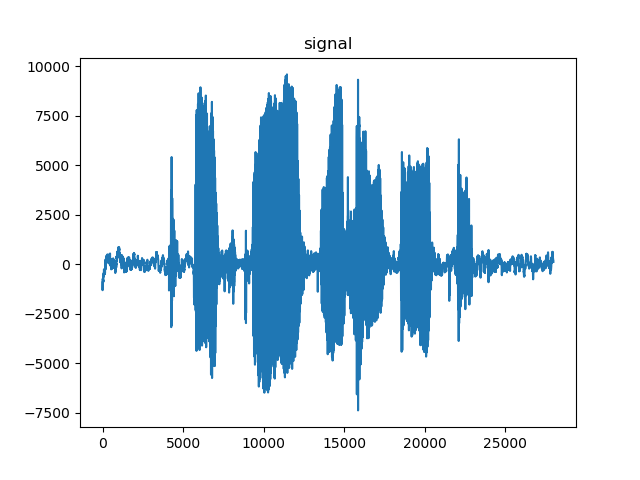
一段3.5秒的语音,经过A/D转化后共28000个点的数据。
signal: [ -919 -1314 -1049 ..., 148 136 120]
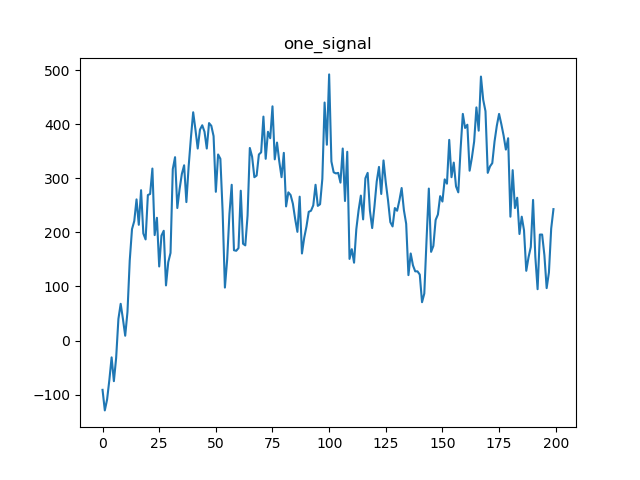
一帧25毫秒的语音,经过A/D转化后共200个点的数据。
3 预加重
为什么要预加重?
目的是为了对语音的高频部分进行加重,去除口唇辐射的影响,增加语音的高频分辨率。因为高频端大约在800Hz以上按6dB/oct (倍频程)衰减,频率越高相应的成分越小,为此要在对语音信号进行分析之前对其高频部分加以提升。
一般通过传递函数为高通数字滤波器来实现预加重,其中a为预加重系数,0.9<a<1.0。设n时刻的语音采样值为x(n),经过预加重处理后的结果为y(n))=x(n)-ax(n-1),这里取a=0.97。
传递函数为:
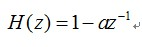
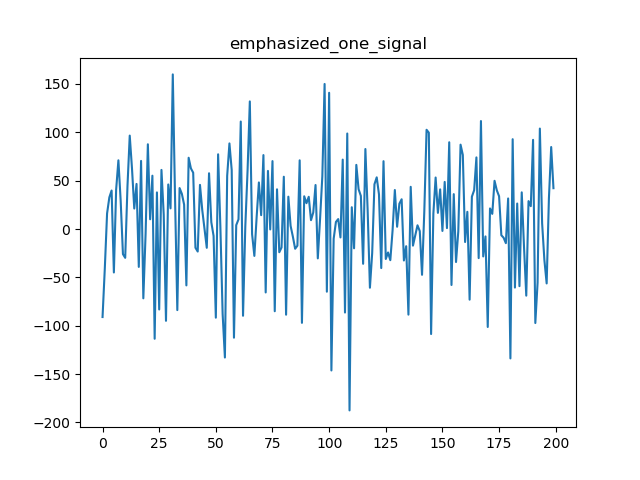
经过预加重后整体语音信号和一帧语音时域效果:
emphasized_signal: [-919. -422.57 225.58 ..., -12.05 -7.56 -11.92]
-1314-0.97*(-919)=-422.57
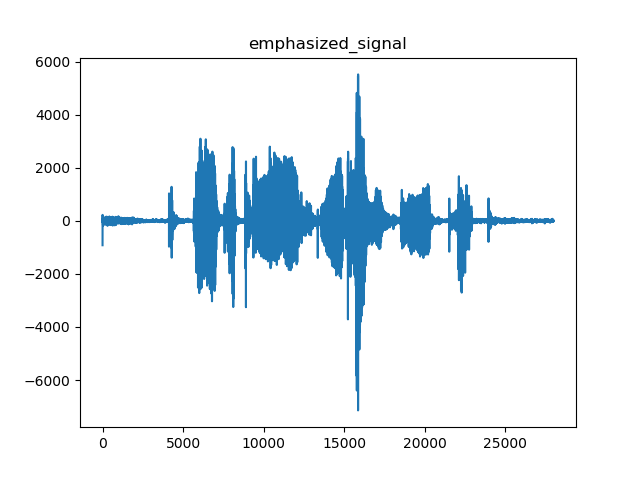
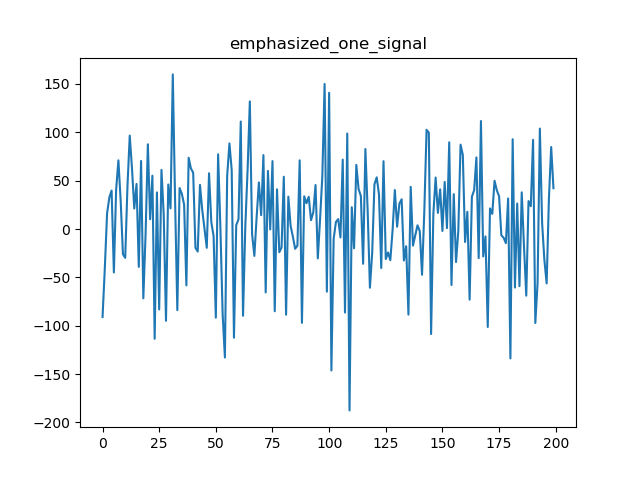
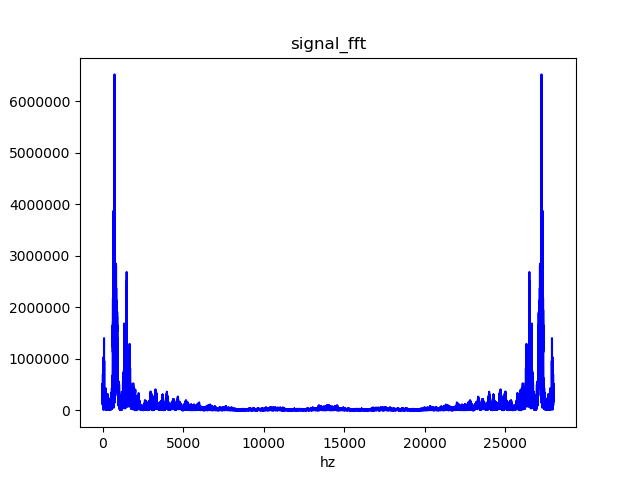
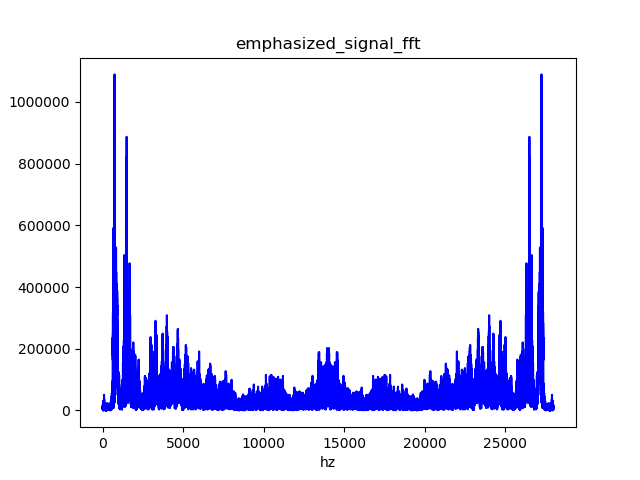
预加重后的语音信号频域效果对比:
4 分帧
傅里叶变换要求输入信号是平稳的,但是语音信号从整体上来讲是不平稳的,嘴巴一动,就game over,如果把不平稳的信号作为输入,傅里叶变换将无意义。虽然语音信号具有时变特性,但是在一个短时间范围内(一般认为在10~30ms),其特性基本保持不变即相对稳定,因而可以将其看作是一个准稳态过程,即语音信号具有短时平稳性。,因此我们需要将语音信号进行分帧处理。
分帧一般采用交叠分段的方法,这是为了使帧与帧之前平滑过渡,保持其连续性。前一针和后一帧的交叠部分称为帧移。帧移与帧长的比值一般取为0~1/2。
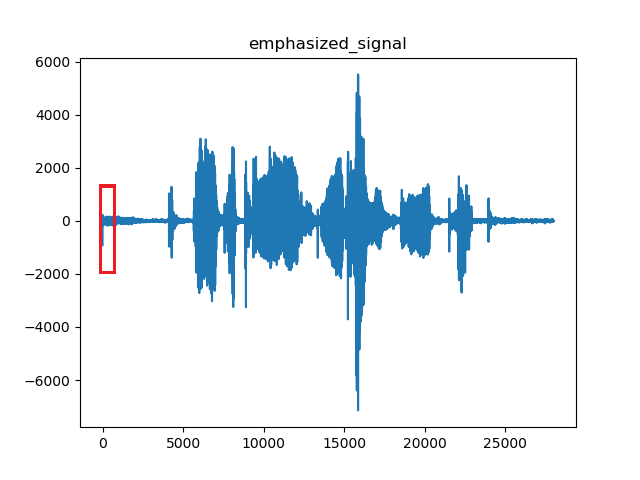
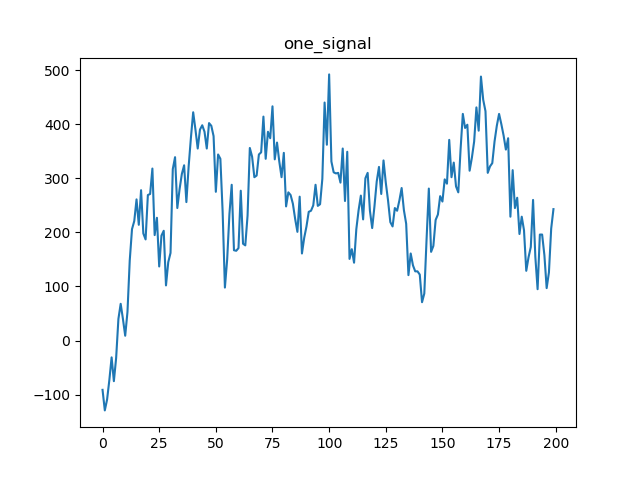
取一帧25毫秒的语音。
帧长:0.025*8KHZ=200
帧移:80
帧数:(28000-200)/80=347.5,取348帧。
补零:348*80+200=28040
28040-28000=40
多出40要补0, 填充信号以确保所有帧具有相同数量的样本,而不会截断原始信号中的任何样本。
5 加窗
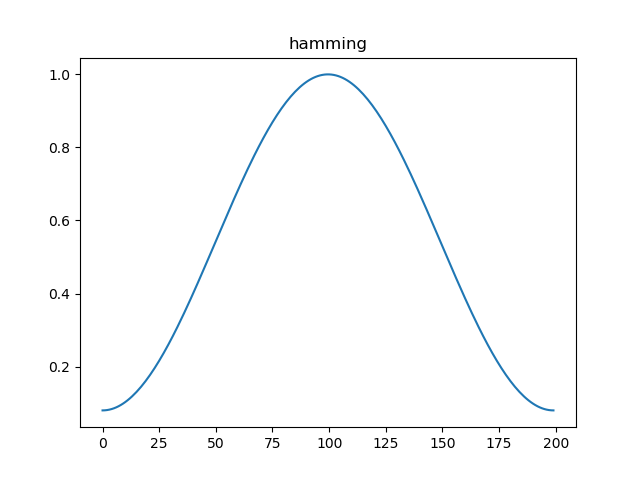
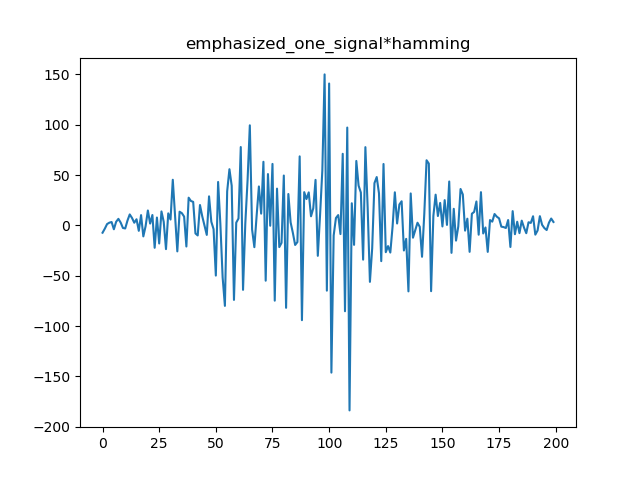
加窗的目的是可以认为对抽样n附近的语音波形加以强调而对波形的其余部分加以减弱。对语音信号的各个短段进行处理,实际上就是对各个短段进行某种变换或施以某种运算,其实加窗相当于把每一帧里面对应的元素变成它与窗序列对应元素的乘积。用得最多的三种窗函数是矩形窗、汉明窗(Hamming)和汉宁窗(Hanning);以汉明窗举例如下:
汉明窗函数如下:
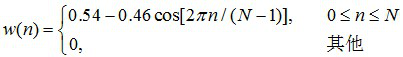
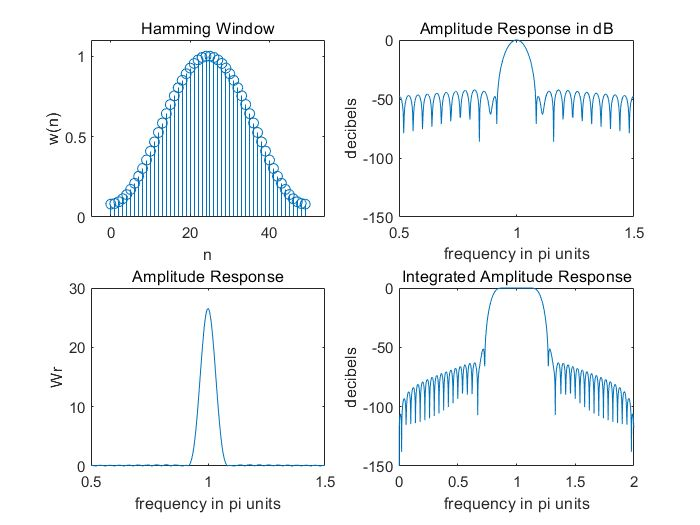
汉明窗的时域和频域波形,窗长N=200,窗函数的宽度其实就是帧长。
加窗即与一个窗函数相乘,加窗之后是为了进行傅里叶展开,
使全局更加连续,避免出现吉布斯效应;加窗时候,原本没有周期性的语音信号呈现出周期函数的部分特征。
加窗的代价是一帧信号的两端部分被削弱了,所以在分帧的时候,帧与帧之间需要有重叠。
(吉布斯效应: 将具有不连续点的周期函数(如矩形脉冲)进行傅立叶级数展开后,选取有限项进行合成。当选取的项数越多,在所合成的波形中出现的峰起越靠近原信号的不连续点。当选取的项数很大时,该峰起值趋于一个常数,大约等于总跳变值的9%。这种现象称为吉布斯现象。)
6 端点检测
端点检测,也叫语音活动检测,Voice Activity Detection,VAD,它的目的是对语音和非语音的区域进行区分。通俗来理解,端点检测就是为了从带有噪声的语音中准确的定位出语音的开始点,和结束点,去掉静音的部分,去掉噪声的部分,找到一段语音真正有效的内容。
VAD 算法可以粗略的分为三类:基于阈值的 VAD、作为分类器的 VAD、模型 VAD。
基于阈值的 VAD: 通过提取时域(短时能量、短期过零率等)或频域(MFCC、谱熵等)特征,通过合理的设置门限,达到区分语音和非语音的目的。这是传统的 VAD 方法。
作为分类器的 VAD:可以将语音检测视作语音/非语音的两分类问题,进而用机器学习的方法训练分类器,达到检测语音的目的。
模型 VAD:可以利用一个完整的声学模型(建模单元的粒度可以很粗),在解码的基础,通过全局信息,判别语音段和非语音段。
双门限法有三个阈值,前两个是语音能量的阈值,最后一个是语音过零率的阈值。浊音的能量高于清音,清音的过零率高于无声部分。这样的话,我们就可以先利用能量,将浊音部分区分出来,再利用过零率,将清音也提取出来,就完成了端点检测。
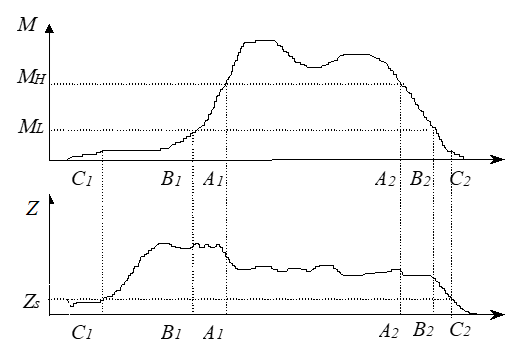
33秒原始信号端点检测结果:
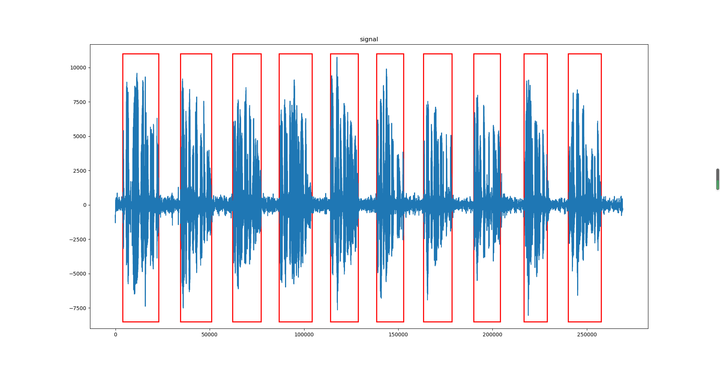
附录(魔鬼写手)




| 





 订阅
订阅