| 编辑推荐: |
在本文中,让我们探索几种从图像中提取颜色、形状和纹理特征的方法。这些方法基于处理图像的经验,希望对您的学习有所帮助。
本文来自于
深度学习与计算机视觉
,由火龙果软件Alice编辑、推荐。 |
|

如何从图像中提取特征?第一次听说“特征提取”一词是在 YouTube 上的机器学习视频教程中,它清楚地解释了我们如何在大型数据集中提取特征。 很简单,数据集的列就是特征。然而,当我遇到计算机视觉主题时,当听说我们将从图像中提取特征时,吃了一惊。是否开始浏览图像的每一列并取出每个像素? 一段时间后,明白了特征提取在计算机视觉中的含义。特征提取是降维过程的一部分,其中,原始数据的初始集被划分并减少到更易于管理的组。 简单来说,对于图像,每个像素都是一个数据,图像处理所做的只是从图像中提取有用的信息,从而减少了数据量,但保留了描述图像特征的像素。 图像处理所做的只是从图像中提取有用的信息,从而减少数据量,但保留描述图像特征的像素。 在本文中,让我们探索几种从图像中提取颜色、形状和纹理特征的方法。这些方法基于处理图像的经验,如果有任何错误,请随时添加或纠正它们!
1. 颜色
每次处理图像项目时,色彩空间都会自动成为最先探索的地方。了解设置图像环境的色彩空间对于提取正确的特征至关重要。 使用 OpenCV,我们可以将图像的颜色空间转换为提供的几个选项之一,如 HSV、LAB、灰度、YCrCb、CMYK 等。每个颜色空间的简单分解: a. HSV(色相饱和度值)
色调 :描述主波长,是指定颜色的通道
饱和度 :描述色调/颜色的纯度/色调
值 :描述颜色的强度
import cv2
from google.colab.patches import cv2_imshow
image = cv2.imread(image_file)
hsv_image = cv2.cvtColor(image, cv2.COLOR_BGR2HSV)
cv2_imshow(hsv_image) |

RGB 与 HSV 颜色空间 b. LAB
L :描述颜色的亮度,与强度互换使用
A : 颜色成分范围,从绿色到品红色
B :从蓝色到黄色的颜色分量
import cv2
from google.colab.patches import cv2_imshow
image = cv2.imread(image_file)
lab_image = cv2.cvtColor(image, cv2.COLOR_BGR2LAB)
cv2_imshow(lab_image) |

RGB 与 LAB 色彩空间 YCrCb
Y : 伽马校正后从 RGB 颜色空间获得的亮度
Cr :描述红色 (R) 分量与亮度的距离
Cb :描述蓝色 (B) 分量与亮度的距离
import cv2
from google.colab.patches import cv2_imshow
image = cv2.imread(image_file)
ycrcb_image = cv2.cvtColor(image, cv2.COLOR_BGR2YCrCb)
cv2_imshow(ycrcb_image) |

RGB 与 YCrCb 颜色空间 这些颜色空间的重要性有时会被低估。为了从图像中获得相关信息,这些颜色空间提供了一个机会来识别特征是否在每个图像中看起来更不同。关于色彩空间最疯狂的事情是我们可以用不同的色彩空间执行加法/减法,结果你会感到惊讶! 探索图像色彩空间的另一个有用函数是简单地使用*numpy.mean()*,它给出图像数据集中色彩空间中每个通道的平均值。如果我们想查看颜色空间中的哪个通道主导数据集,这将特别有用。
import cv2
from google.colab.patches import cv2_imshow
import numpy as np
import plotly.figure_factory as ff
# Check the distribution of red values
red_values = []
for i in range(len(images)):
red_value = np.mean(images[i][:, :, 0 ])
red_values.append(red_value)
# Check the distribution of green values
green_values = []
for i in range(len(images)):
green_value = np.mean(images[i][:, :, 1 ])
green_values.append(green_value)
# Check the distribution of blue values
blue_values = []
for i in range(len(images)):
blue_value = np.mean(images[i][:, :, 2 ])
blue_values.append(blue_value)
# Plotting the histogram
fig = ff.create_distplot([red_values, green_values,
blue_values], group_labels=[ "R" , "G" , "B" ],
colors=[ 'red' , 'green' , 'blue' ])
fig.update_layout(showlegend= True , template= "simple_white" )
fig.update_layout(title_text= 'Distribution of
channel values across images in RGB' )
fig.data[ 0 ].marker.line.color = 'rgb(0, 0, 0)'
fig.data[ 0 ].marker.line.width = 0.5
fig.data[ 1 ].marker.line.color = 'rgb(0, 0, 0)'
fig.data[ 1 ].marker.line.width = 0.5
fig.data[ 2 ].marker.line.color = 'rgb(0, 0, 0)'
fig.data[ 2 ].marker.line.width = 0.5
fig |
一旦我们已经识别或探索了足够多的图像色彩空间,并确定我们只对单个通道感兴趣,我们就可以使用*cv2.inRange()*来屏蔽不需要的像素。这在 HSV 颜色空间中尤其实用。
import cv2
from google.colab.patches import cv2_imshow
# Reading the original image
image_spot = cv2.imread(image_file)
cv2_imshow(image_spot)
# Converting it to HSV color space
hsv_image_spot = cv2.cvtColor(image_spot, cv2.COLOR_BGR2HSV)
cv2_imshow(hsv_image_spot)
# Setting the black pixel mask and perform bitwise_and to get only the black pixels
mask = cv2.inRange(hsv_image_spot, ( 0 , 0 , 0 ), ( 180 , 255 , 40 ))
masked = cv2.bitwise_and(hsv_image_spot, hsv_image_spot, mask=mask)
cv2_imshow(masked) |

RGB vs HSV vs Masked 图像使用 cv2.inRange() 检索黑点 有时,我们甚至可以使用*cv2.kmeans() 来量化图像的颜色,从本质上将颜色减少到几个整洁的像素。根据我们的目标,我们可以使用 cv2.inRange()*来检索目标像素。通常,这个函数在识别图像的重要部分时很有魅力,我总是会在继续使用其他颜色特征提取方法之前检查这个函数。
import cv2
from google.colab.patches import cv2_imshow
image_spot_reshaped = image_spot.reshape
((image_spot.shape[ 0 ] * image_spot.shape[ 1 ], 3 ))
# convert to np.float32
Z = np.float32(image_spot_reshaped)
# define criteria, number of clusters(K) and apply kmeans()
criteria = (cv2.TERM_CRITERIA_EPS + cv2.TERM_CRITERIA_MAX_ITER, 10 , 1.0 )
K = 2
ret, label, center = cv2.kmeans(Z, K, None , criteria, 10 ,
cv2.KMEANS_RANDOM_CENTERS)
# Now convert back into uint8, and make original image
center = np.uint8(center)
res = center[label.flatten()]
res2 = res.reshape((image_spot.shape))
cv2_imshow(res2) |

使用 cv2.kmeans() 进行颜色量化 (K=2)
2. 形状
一旦我们充分探索了颜色特征,我们可能会在某个时候想要提取图像中的形状。 例如,你的任务是区分不同类型的酒杯。颜色在这里可能并不重要,但形状可以告诉我们很多关于它们的信息。 同样,我要做的是将图像转换为其他颜色空间,看看是否有任何颜色空间会使对象的边缘或形状更加突出。然后,我们可以使用*cv2.findContours()*来检索图像中的所有轮廓。从这里开始,我们将检查感兴趣轮廓的所有属性。 理想情况下,一旦我们能够提取定义轮廓形状的正确属性,我们会将其应用于数据集中的所有图像,提取的数字将成为我们新的非图像数据集。看看我们如何将数据量减少到只有一列形状特征,仍然可以解释我们的酒杯图像吗? 让我们探索一下我们可以使用 OpenCV 从轮廓中提取的许多属性。正如之前已经展示过的,我将在此处提供链接以供参考
矩
轮廓面积
轮廓周长
轮廓近似
凸包
凸性检测
矩形边界
最小外接圆
拟合椭圆
拟合直线
在很多情况下发现 cv2.HoughCircles() 和 cv2.SimpleBlobDetector() 在检测圆圈时都没有给出准确的结果,原因之一可能是预处理图像中的圆圈不够明显。但是,cv2.SimpleBlobDetector() 仍然提供一些方便的内置过滤器,如惯性、凸性、圆度和面积,以尽可能准确地检索圆。
3. 纹理
在某些时候,我们可能想要提取纹理特征,因为我们已经用尽了颜色和形状特征。灰度共生矩阵(GLCM)和局部二值模式(LBP)都是我用过的纹理特征,不过大家常用的其他纹理特征也可以在下方评论,我很想知道! a. GLCM 很难在图像方面特别理解 GLCM 的概念。从统计学上讲,GLCM 是一种考虑像素空间关系的纹理检查方法。它的工作原理是计算具有特定值和特定空间关系的像素对在图像中出现的频率,创建 GLCM,然后从该矩阵中提取统计度量。
a. GLCM 很难在图像方面特别理解 GLCM 的概念。从统计学上讲,GLCM 是一种考虑像素空间关系的纹理检查方法。它的工作原理是计算具有特定值和特定空间关系的像素对在图像中出现的频率,创建 GLCM,然后从该矩阵中提取统计度量。
import cv2
from google.colab.patches import cv2_imshow
image_spot = cv2.imread(image_file)
gray = cv2.cvtColor(image_spot, cv2.COLOR_BGR2GRAY)
# Find the GLCM
import skimage.feature as feature
# Param:
# source image
# List of pixel pair distance offsets - here 1 in each direction
# List of pixel pair angles in radians
graycom = feature.greycomatrix(gray, [ 1 ],
[ 0 , np.pi/ 4 , np.pi/ 2 , 3 *np.pi/ 4 ], levels= 256 )
# Find the GLCM properties
contrast = feature.greycoprops(graycom, 'contrast' )
dissimilarity = feature.greycoprops(graycom, 'dissimilarity' )
homogeneity = feature.greycoprops(graycom, 'homogeneity' )
energy = feature.greycoprops(graycom, 'energy' )
correlation = feature.greycoprops(graycom, 'correlation' )
ASM = feature.greycoprops(graycom, 'ASM' )
print( "Contrast: {}" .format(contrast))
print( "Dissimilarity: {}" .format(dissimilarity))
print( "Homogeneity: {}" .format(homogeneity))
print( "Energy: {}" .format(energy))
print( "Correlation: {}" .format(correlation))
print( "ASM: {}" .format(ASM)) |
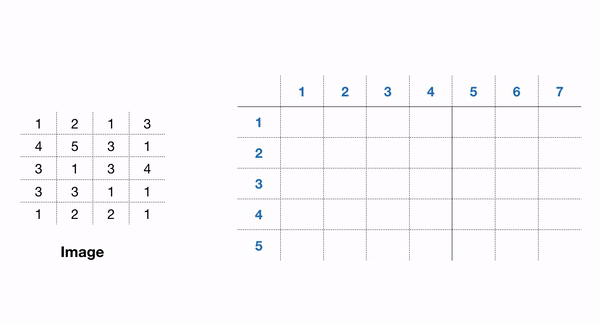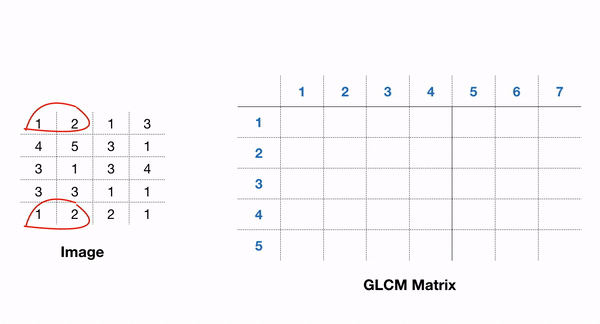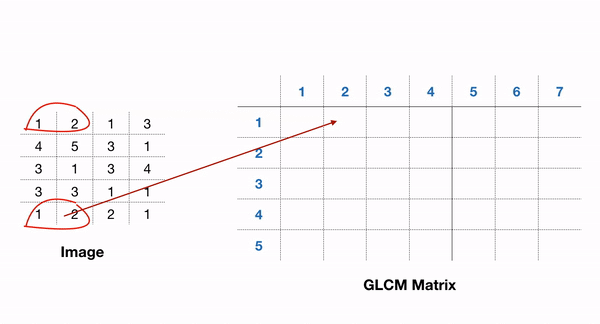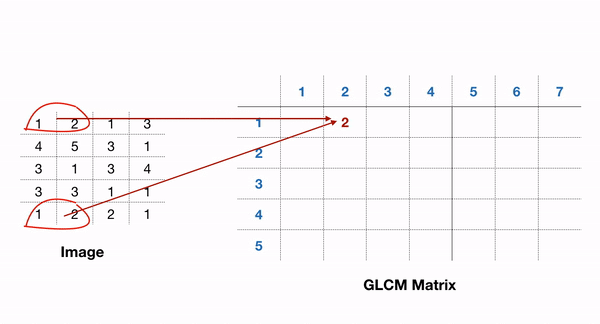
包含 GLCM 功能的一个易于使用的包是 scikit-image 包。在 GLCM 中,我们还可以推导出一些描述更多关于纹理的统计数据,例如:
对比度 :测量灰度共生矩阵的局部变化。
相关性 :测量指定像素对的联合概率出现。
平方 :提供 GLCM 中元素的平方和。也称为均匀性或角二阶矩。
同质性 :测量 GLCM 中元素分布与 GLCM 对角线的接近程度。
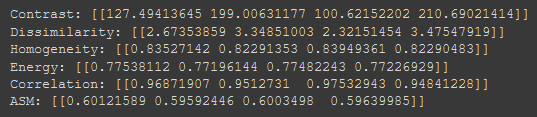
从灰度共生矩阵 (GLCM) 获得的特征 b. LBP 由于已经有很多文章解释了本地二进制模式,在这里节省你的时间并在此处分享参考链接:
https://www.pyimagesearch.com/2015/12/07/ local-binary-patterns-with-python-opencv/
https://towardsdatascience.com/face- recognition-how-lbph-works-90ec258c3d6b
简而言之,LBP 是一种纹理算子,它通过对周围像素进行阈值处理并以二进制数表示它们来标记图像的像素。LBP 让我们吃惊的是,该操作返回的灰度图像清晰地显示了图像中的纹理。在这里,我们尝试根据理解分解LBP内部的操作:
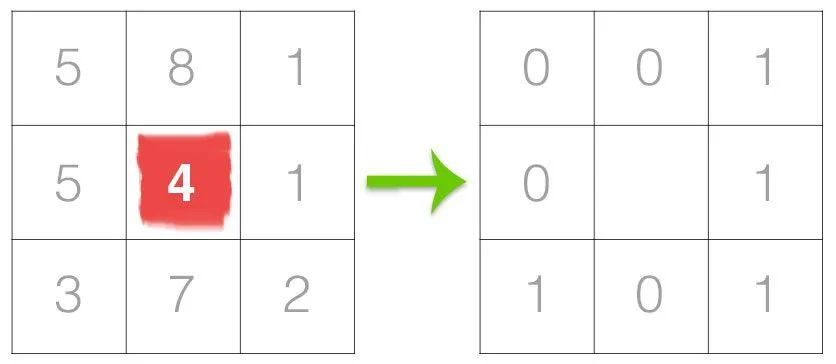
对于每个中心像素,我们尝试与周围像素进行比较,如果中心像素大于或小于周围像素,则给它们一个标签。结果,我们周围有 8 个标签,并且通过在整个图像中保持顺时针或逆时针方向的一致模式,我们将它们布置在 2d 数组中并将它们转换为二进制数。
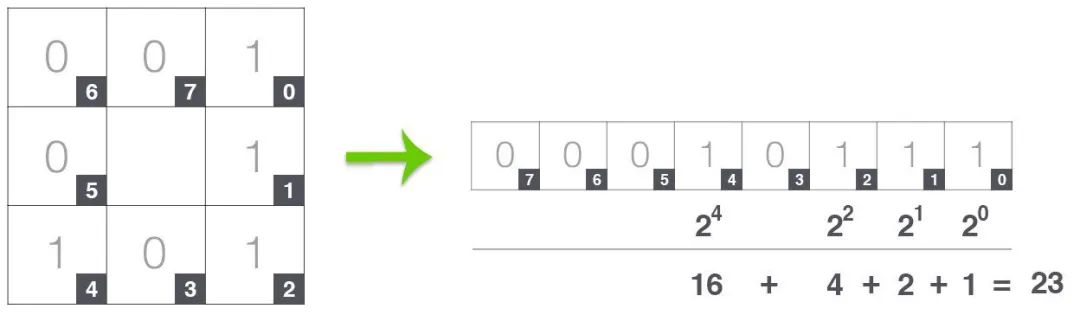
在我们对整个图像的每个像素执行操作后会出现这样的矩阵。
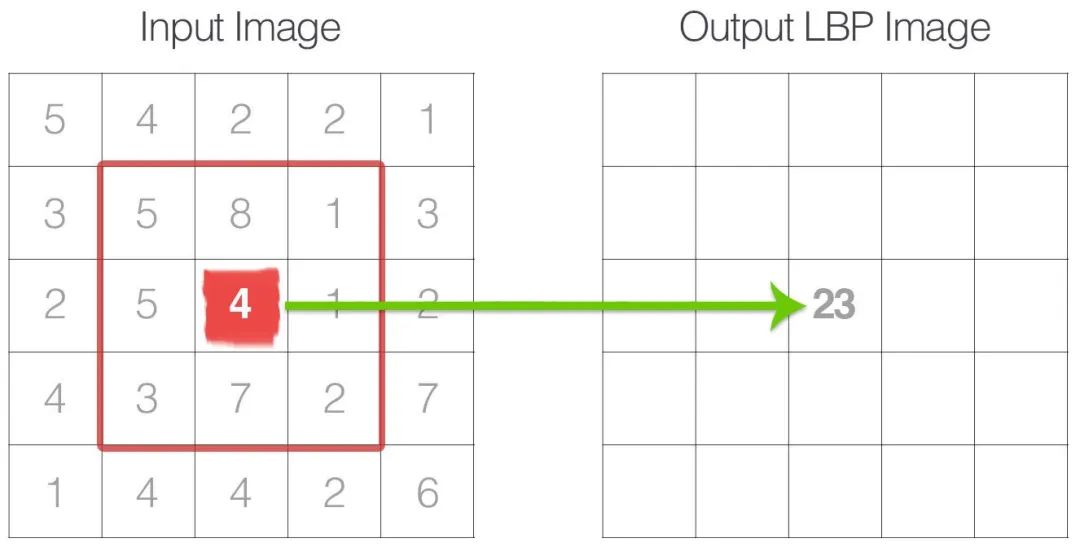
从这里,我们可以看到,生成的矩阵与我们的原始图像具有相同的形状,我们能够像绘制图像一样绘制和显示 LBP。
import cv2
from google.colab.patches import cv2_imshow
class LocalBinaryPatterns :
def __init__ (self, numPoints, radius) :
self.numPoints = numPoints
self.radius = radius
def describe (self, image, eps = 1e-7 ) :
lbp = feature.local_binary_pattern(image, self.numPoints,
self.radius, method= "uniform" )
(hist, _) = np.histogram(lbp.ravel(), bins=np.arange( 0 ,
self.numPoints+ 3 ), range=( 0 , self.numPoints + 2 ))
# Normalize the histogram
hist = hist.astype( 'float' )
hist /= (hist.sum() + eps)
return hist, lbp
image = cv2.imread(image_file)
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
desc = LocalBinaryPatterns( 24 , 8 )
hist, lbp = desc.describe(gray)
print( "Histogram of Local Binary Pattern value: {}" .format(hist))
contrast = contrast.flatten()
dissimilarity = dissimilarity.flatten()
homogeneity = homogeneity.flatten()
energy = energy.flatten()
correlation = correlation.flatten()
ASM = ASM.flatten()
hist = hist.flatten()
features = np.concatenate((contrast, dissimilarity,
homogeneity, energy, correlation, ASM, hist), axis= 0 )
cv2_imshow(gray)
cv2_imshow(lbp) |

灰度图像与 LBP 表示
类似地,我们可以将 LBP 存储在直方图中,并将其视为一个特征,我们可以将其输入分类器以进行分类。PyImageSearch 的 Adrian Rosebrock 在这方面做了一个惊人的例子!
我在纹理特征方面没有太多经验,但是在收集更多信息并尝试在项目中实现它们之后,我有兴趣深入研究它。
结论
总而言之,在这篇文章中,分享了在之前的项目中使用过的三个特征的经验,主要是颜色、形状和纹理特征。连同代码和结果,试图说明我采取每一步的原因。希望你能够从图像特征中学到一些东西,从颜色、形状和纹理开始。
|






 订阅
订阅