| 编辑推荐: |
本文主要介绍了语音及其对应文本的分析、应用,有助于识别风险,加强风控管理,主要包括:
基于语音的风险特征提取、单通道语音分离技术、语音文本打标、总结与展望。希望对你的学习有帮助。
本文来自于微信公众号DataFunSummit,由火龙果软件Linda编辑,推荐。 |
|
导读:在金融场景下,与客户交互过程中会涉及音频、视频、图片等多种模态的数据,本次分享题目为语音分析在金融风控的探索应用,着重介绍语音及其对应文本的分析、应用,有助于识别风险,加强风控管理,主要包括:
基于语音的风险特征提取
单通道语音分离技术
语音文本打标
总结与展望
01基于语音的风险特征提取
在实际应用场景中,有大量客户与客服沟通的未打标的语音文件,这些语音资源如果不能充分利用,会造成数据资产的浪费。为了提升语音数据的利用,我们对对话语音数据进行分析,将语音文件分别转换为客户、客服的时序信号,并提取时域特征,如语音振幅、振幅差异、语音时长、平均音量等特征。基于这些特征对语音文件进行打标,标签可分为AI接听、无效语音、无效通话等,这些标签可有效的应用于风险管理。
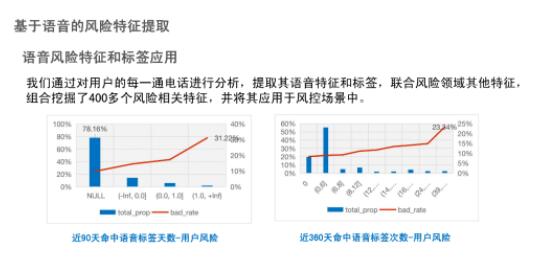
在提取的语音特征和标签基础上,我们融合了400多个风险领域相关特征,应用于实际风控场景下。下图展示了我们实际应用的情况,分别统计、分析了90天和360天内,通话记录命中语音标签数量与用户风险对应关系,可以看出命中语音标签的数量与用户风险成正比关系,这充分说明了语音标签可以用来预测用户真实风险。
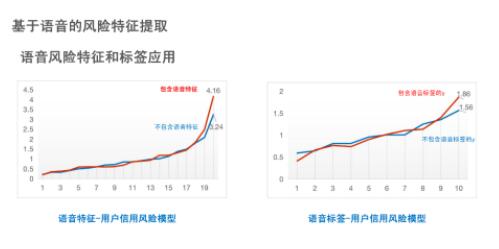
此外,通过传统模型,如XGBoost模型、LR模型等进行实验验证,在加入语音特征后,模型对高风险用户的识别率有显著提升,由原本3.24倍提升到4.16倍。将现有语音标签作为其他风险场景的标签,训练新的子模型,并将子模型的得分应用于信用风险模型。可以看到,使用语音标签对识别高风险用户也有一定提升。
02单通道语音分离技术
以上是基于双通道语音进行的分析,在实际应用中,语音文件并非都为双通道,对于单声道语音文件,需要利用单通道语音分离技术进行处理。
单通道语音分离问题在业界又称为“鸡尾酒会”问题,即在嘈杂的环境中,分理出目标声音,或提取背景声等,其难点在于输入的声源数量以及要分离的语音目标,比如两人对话的语音分离和三人对话的语音,甚至多人对话上的语音分离都是难度不同的场景,其所用的技术方案也不尽相同。我们的场景主要涉及客服和客户之间的对话,因此重点在于将客服和客户的声音从混合语音中分离开。
1. 单通道语音分离技术
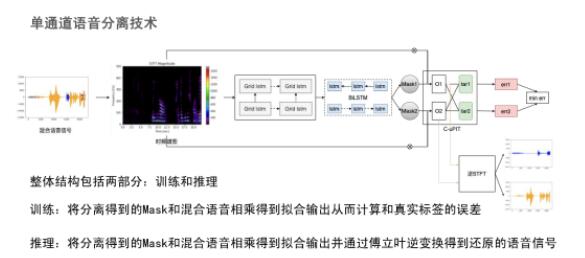
上图是我们进行单通道语音分离使用的模型。
输入混合语音信号后,通过短时傅里叶变换得到时频谱图,借助深度学习模型,如Grid LSTM等提取高维特征,根据高维特征映射得到Mask矩阵,将Mask和输入混合语音信号相乘即可得到分离后的时频谱图,再通过傅里叶逆变换即可得到分离后的语音信号,而是否需要还原语音可根据具体场景需求而定。
整体结构包括两部分:训练和推理。
训练:将分离得到的Mask和混合语音相乘得到拟合输出从而计算和真实标签的误差。
推理:将分离得到的Mask和混合语音相乘得到拟合输出,并通过傅里叶逆变换得到还原的语音信号。

为了更好理解单通道语音分离方法,需要介绍理想相位敏感掩码(IPSM)、损失函数和评估方法。
理想相位敏感掩码(IPSM)
理想相位敏感掩码(IPSM)是指每通电话语音中,每道纯净语音信号和混合语音信号的比例关系,即Xs表示一道语音信号,Y表示混合语音信号,cos表示混合语音信号相位和纯净语音信号相位的差值,公式的含义即纯净语音信号和混合语音信号的差异。训练过程中,神经网络拟合的Mask值,要尽量逼近IPSM。
损失函数
损失函数可理解为,预测Mask值与混合语音信号相乘得到的预测输出值与真实标签值的差。损失函数的公式中,WD和WA为增加的正则项,表示语音信号随时间变化的波动,WD表示纯净语音信号的一阶偏导数,WA表示二阶偏导数。
单通道语音分离技术评估方法

采用SDR进行评估,即输入信号的功率与输入信号与重构信号之差的功率之比,SDR越大越好,反映了整体的分离性能。在我们的场景中,SDR指标在16左右,分离效果明显。但需要指出的是,由于没有尝试其他语音分离技术来对比效果,SDR值不足以完全说明效果好坏。
所以我们在应用SDR指标评估的基础上,采用了人工评测的方式,从样本中抽样,人工评估样本分离后的语音信号,如果能明显区分出客户和客服声音,说明模型效果良好。在更多场景的应用中,评估还需要结合具体的应用场景,如语音识别场景,还需要看语音转文字的实际效果。
2. 单通道语音分离方案实施

由于内部双通道语音数据量不多,不能完全满足模型训练的要求。模型训练需要大量的混合语音信号和分离后的纯净语音信号,为解决这个问题,我们先在公开数据集上做模型预训练,再基于具有混合语音和纯净语音的双通道语音训练数据做fine-tune。整个过程即输入单通道语音训练数据,配置超参数、提取声学特征后进行模型训练,使用公开数据集和小样本双通道数据集进行验证。模型部署上线后,生产上的语音数据首先进行预处理,进而通过模型分离得到纯净语音文件,并应用于具体业务场景。
以上为单通道语音分离技术的介绍,该技术可以很好的服务于语音特征和标签提取。
03语音文本打标
除了无标签的语音文件可以进行分析利用,语音文件对应的文本数据同样可以进行分析利用,提高数据的利用率。我们通过一个基于语音文本数据识别用户的动支意愿的场景介绍语音文本打标方法。动支意愿在风控场景有很多应用,如动支意愿与风险交叉,借助策略,对用户开展个性化营销等。
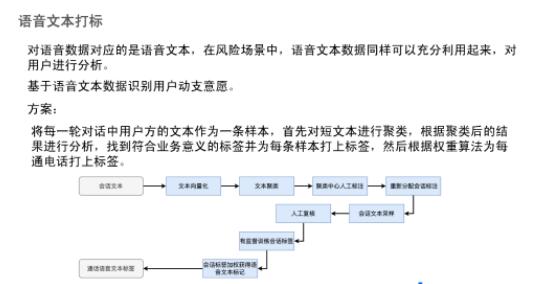
为了识别用户的动支意愿,我们采用上图所示方案。
具体而言,将通话语音文本转为文本向量,对文本进行无监督聚类,对聚类中心进行人工标注,依据人工打标后的聚类中心,再对文本进行重新分配,然后再对新的聚类类别进行采样,并人工抽样复核现有标签是否与文本对应。人工复核后,进行有监督训练,核实人工标记的类别是否可以合理覆盖所有文本。最后,对会话标签加权可以获得通话文本标签,用于用户动支意愿的识别。
过程中涉及的比较重要的两点是,文本的无监督聚类和有监督的会话标签训练。
1. 无监督聚类
为了满足性能要求、更快地找到聚类中心,我们自定义了无监督聚类方法,基于快速社区发现算法进行改进。在输入样本时,不需要一次性输入所有样本聚类,可先对样本下采样,在小样本集上计算相似性矩阵,得到相似性矩阵后,根据TopK原则得到一组类簇,迭代删除重复的类簇得到新的类簇。之后将剩下的样本根据相似性加入到类簇中。如果发现的新类簇个数为空,且相似性阈值过低,则聚类完成;如果发现的新类簇个数为空,且当前相似性阈值足够高,则降低阈值,重新聚类。通过多轮迭代,可以快速完成聚类。具体算法如下图:

2. 有监督聚类
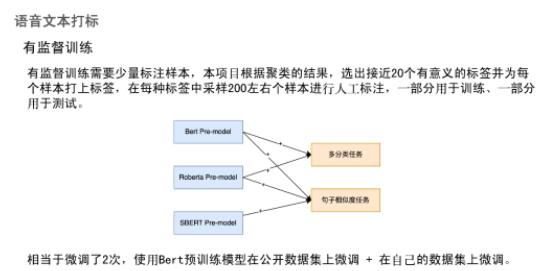
由于现有语音文本文件大多缺少标签,故先采用了无监督聚类得到聚类中心。若采用有监督训练,需要人工标注,本项目根据聚类的结果,选出接近20个有意义的标签并为每个样本打上标签,在每种标签中采样200左右样本进行人工标注,一部分用于训练,一部分用于测试。训练用到两种方法,多分类任务和句子相似度任务,基于Bert模型训练,并在私有数据集上进行微调。
3. 效果对比
通过对比可以发现,在无监督聚类任务中,Chinese-roberta-wwm-ext+whitening+fstlstavg和Sentence_transformers_paraphrase-multilingual-MiniLM-L12-v2+lstavg模型效果较好。在有监督训练,正则表达+Sentence_transformers_paraphrase-multilingual-MiniLM-L12-v2+lstavg和Chinese-roberta-wwm-ext+句子相似度任务微调+lstavg模型效果较好。
需要注意的是,有监督训练过拟合较明显,训练样本F1-score值比测试样本高很多,这是因为有监督模型训练需要大量样本集,当样本数量不足时,很有可能会出现过拟合现象,因此需要根据实际应用进行调整。


04总结与展望

本次主要基于语音特征提取、单通道语音分离和语音文本打标三个方面进行分享,目前我们的探索处于基础阶段,仍有很多优化、改进的空间。
语音特征提取除了规则挖掘外,可以基于深度学习、强化学习进行更深层次的挖掘,提升现有数据价值,提高数据利用率,更好地应用于风控领域。
现有方法仍需要人工打标,即使采用无监督训练,在评估模型效果时,仍需要打标数据。数据打标会耗费很多人力,是无监督训练一个亟待解决的问题。
目前模型无法实现语音通道数的泛化,现实中可能有单通道、双通道或者多通道,目前模型只基于特定一种通道数,其余通道数量样本需要经过处理才可输入模型。
|






 订阅
订阅