| 编辑推荐: |
本文主要介绍了如何高效微调
LLM等相关知识。希望对你的学习有帮助。
本文来自于腾讯云开发者社区,由火龙果软件Linda编辑,推荐。 |
|
当前以 ChatGPT 为代表的预训练语言模型(PLM)规模变得越来越大,在消费级硬件上进行全量微调(Full
Fine-Tuning)变得不可行。此外,为每个下游任务单独存储和部署微调模型变得非常昂贵,因为微调模型与原始预训练模型的大小相同。
参数高效微调方法(Parameter-Efficient Fine-Tuning,PEFT) 方法被提出来解决这两个问题,
PEFT 可以使 PLM 高效适应各种下游应用任务,而无需微调预训练模型的所有参数 。
微调大规模 PLM 所需的资源成本通常高得令人望而却步。 在这方面, PEFT 方法仅微调少量或额外的模型参数,固定大部分预训练参数,大大降低了计算和存储成本
,同时最先进的 PEFT 技术也能实现了与全量微调相当的性能。
Huggface 开源的一个高效微调大模型的库PEFT[1] ,该算法库支持以下四类方法:
LoRA: LoRA: Low-Rank Adaptation of Large Language
Models[2]
Prefix Tuning: Prefix-Tuning: Optimizing Continuous
Prompts for Generation[3], P-Tuning v2: Prompt Tuning
Can Be Comparable to Fine-tuning Universally Across
Scales and Tasks[4]
P-Tuning: GPT Understands, Too[5]
Prompt Tuning: The Power of Scale for Parameter-Efficient
Prompt Tuning[6]
LLM-Adapters[7] 是对 PEFT 库的扩展,是一个简单易用的框架,将各种适配器集成到
LLM 中,可针对不同的任务执行 LLM 的基于适配器的 PEFT 方法,除了 PEFT 支持的 LoRA、Prefix
Tuning、P-Tuning、Prompt Tuning 方法外,主要扩增了 AdapterH、AdapterP
和 Parallel 三种方法。
AdapterH: Parameter-Efficient Transfer Learning for
NLP[8]
AdapterP: GMAD-X: An Adapter-Based Framework for Multi-Task
Cross-Lingual Transfer[9]
Parallel: Towards a Unified View of Parameter-Efficient
Transfer Learning[10]
如下图所示,PEFT 方法可以分为三类,不同的方法对 PLM 的不同部分进行下游任务的适配:
Prefix/Prompt-Tuning :在模型的输入或隐层添加 k 个额外可训练的前缀 tokens(这些前缀是连续的伪
tokens,不对应真实的 tokens),只训练这些前缀参数;
Adapter-Tuning :将较小的神经网络层或模块插入预训练模型的每一层,这些新插入的神经模块称为
adapter(适配器),下游任务微调时也只训练这些适配器参数;
LoRA :通过学习小参数的低秩矩阵来近似模型权重矩阵 W 的参数更新,训练时只优化低秩矩阵参数。
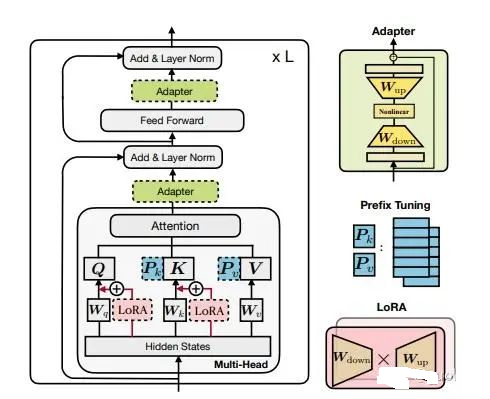
Transformer 结构和最先进的 PEFT 方法
一. Prefix Tuning
Prefix-Tuning 在模型输入前添加一个连续的且任务特定的向量序列 (continuous
task-specific vectors),称之为 前缀(prefix) 。前缀被视为一系列“虚拟
tokens”,但是它由不对应于真实 tokens 的自由参数组成。
与更新所有 PLM 参数的全量微调不同, Prefix-Tuning 固定 PLM 的所有参数,只更新优化特定任务的
prefix 。因此,在生产部署时,只需要存储一个大型 PLM 的副本和一个学习到的特定任务的 prefix,每个下游任务只产生非常小的额外的计算和存储开销。
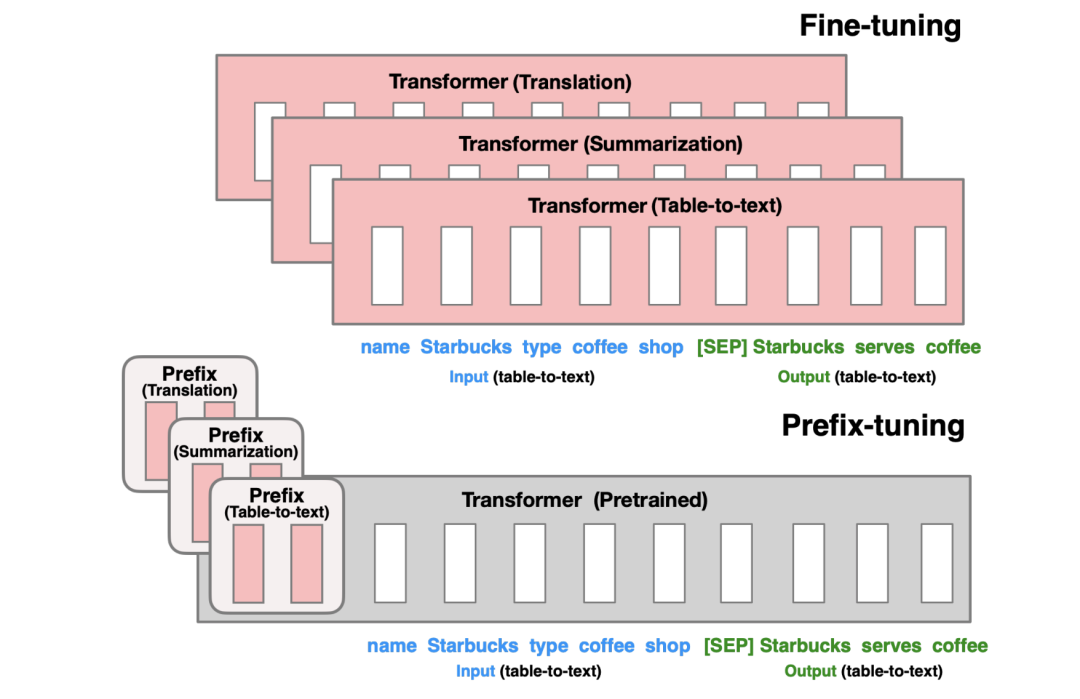
Fine-tuning 更新所有 PLM 参数,并且需要为每个任务存储完整的模型副本。Prefix-tuning
冻结了 PLM 参数并且只优化了 prefix。因此,只需要为每个任务存储特定 prefix,使 Prefix-tuning
模块化且节省存储空间。
如下图所示,以 GPT2 的自回归语言模型为例,将输入 x 和输出 y 拼接为
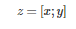
,经过 LM 的某一层计算隐层表示
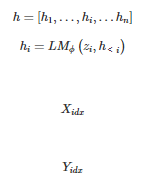
其中 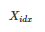
和 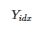
分别为输入和输出序列的索引。
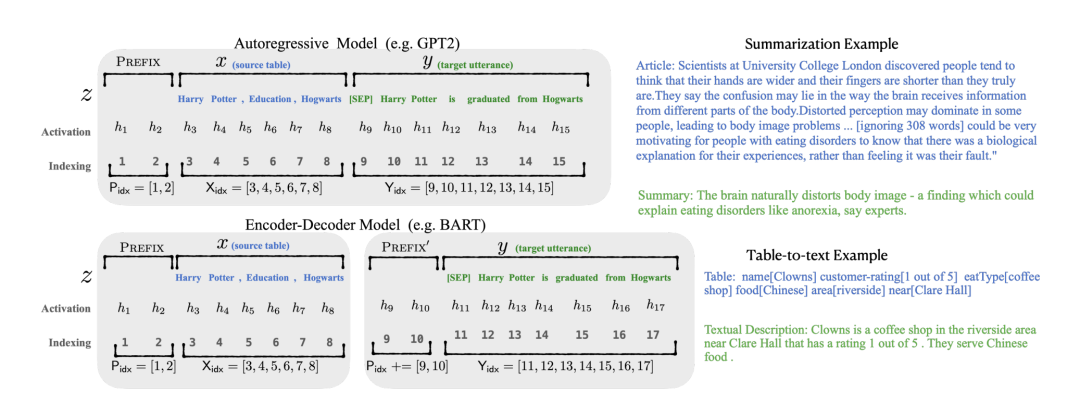
Prefix-Tuning 示例图
Prefix-Tuning 在输入前添加前缀,即

,即 通过前缀来影响后续的序列隐层激化值 。

在实验中,作者进行了两组方法变体的对比分析:
[ Full vs Embedding-only ]: Embedding-only 方法只在
embedding 层添加前缀向量并优化,而 Full 代表的 Prefix-tuning 不仅优化
embedding 层添加前缀参数,还在模型所有层的激活添加前缀并优化。实验得到一个不同方法的 表达能力增强链条:discrete
prompting < embedding-only < prefix-tuning 。同时,Prefix-tuning
可以直接修改模型更深层的表示,避免了跨越网络深度的长计算路径问题。
[ Prefix-tuning vs Infix-tuning ]: 通过将可训练的参数放置在
x 和 y 的中间来研究可训练参数位置对性能的影响,即 [x;Infix;y] ,这种方式成为 Infix-tuning。实验表明
Prefix-tuning 性能好于 Infix-tuning ,因为 prefix 能够同时影响
x 和 y 的隐层激活,而 infix 只能够影响 y 的隐层激活。
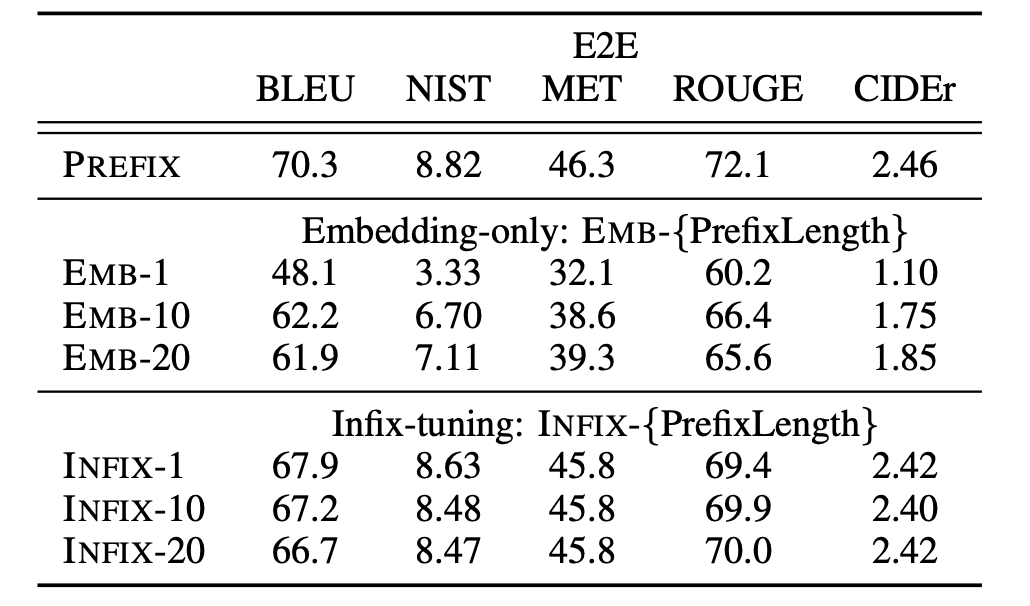
同时,研究表明前缀的 embedding 使用词表中真实单词的激活来初始化明显优于随机初始化。
二. P-Tuning
P-Tuning 的方法思路与 Prefix-Tuning 很相近,P-Tuning 利用少量连续的
embedding 参数作为 prompt 使 GPT 更好的应用于 NLU 任务,而 Prefix-Tuning
是针对 NLG 任务设计 。同时, P-Tuning 只在 embedding 层增加参数,而 Prefix-Tuning
在每一层都添加可训练参数 。
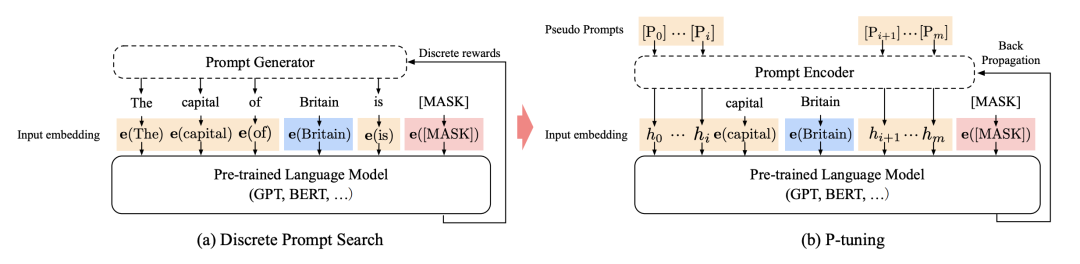
如下图所示,具体的 NLU 任务以预测一个城市的首都为例,
一个离散的 prompt 模板 T 可以写为:"The capital of Britain
is [MASK].",其中"Britain"为输入的上下文 x ,"[MASK]"位置为需要输出的目标
y 。
而对于连续的 prompt 模板可以表示为:

P-Tuning 示例图
直接优化连续的 prompt 参数面临两个挑战:一是预训练模型原始的词向量已经高度离散,若随机初始化
prompt 向量并进行 SGD 优化,也只会在小范围内优化并陷入局部最小值;二是 prompt 向量之间是相互关联而不是独立的。论文中
设计了一个 prompt 编码器,该编码器由一个 Bi-LSTM 和一个两层的前馈神经网络组成,对
prompt embedding 序列进行编码后再传入到语言模型中 。
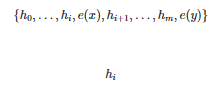
论文的实验主要表明了:在 SuperGLUE 基准测试中,P-tuning 使得 GPT-style
的生成式模型与相同大小的 BERT 在 NLU 方面实现可比较,有时甚至更好的性能。
P-Tuning V2 方法的思路其实和 Prefix-Tuning 相似,在 模型的每一层都应用连续的
prompts 并对 prompts 参数进行更新优化。同时,该方法是 针对 NLU 任务优化和适配
的。
P-Tuning V2 示例图
三. Prompt Tuning
Prompt Tuning 方式可以看做是 Prefix Tuning 的简化, 固定整个预训练模型参数,只允许将每个下游任务的额外k个可更新的
tokens 前置到输入文本中,也没有使用额外的编码层或任务特定的输出层 。
如下图所示,在模型大小增加到一定规模时,仅仅使用 Prompt Tuning 就足以达到 Fine
Tuning 的性能。
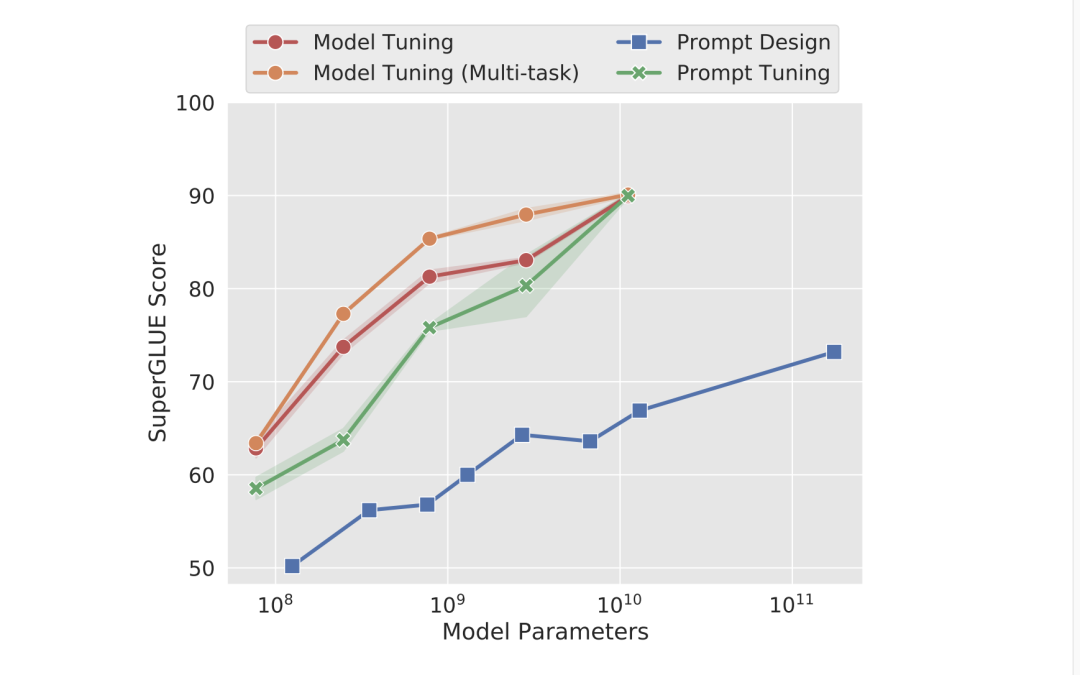
T5 的 Model Tuning 实现了强大的性能,但需要为每个任务存储单独的模型副本。 随着模型规模的增加,对
T5 的 Prompt Tuning 与 Model Tuning 的性能相当,同时允许所有任务复用同一固定模型。Prompt
Tuning 方法明显优于使用 GPT-3 的少样本 Prompt Design。
Prompt Tuning 以 T5 为基础,将所有任务转化成文本生成任务,表示为

模型微调需要制作整个预训练模型的任务特定副本,推理分批执行。Prompt
tuning 只需为每个任务存储一个 Task Prompts,并使用原始预训练模型进行混合任务推理。
Prompt Tuning 提出了 Prompt Ensembling 方法来集成预训练语言模型的多种
prompts。 通过在同一任务上训练 N 个 prompts,为一个任务创建了 N 个单独的模型,同时在整个过程中共享核心的预训练语言建模参数。
除了大幅降低存储成本外,提示集成还使推理更加高效。 处理一个样例时,可以执行批此大小为N的单个前向传递,而不是计算
N 次不同模型的前向传递,跨批次复制样例并改变 prompts。在推理时可以使用 major voting
方法从 prompt ensembling 中得到整体的预测。
四. Adapter Tuning
与 Prefix Tuning 和 Prompt Tuning 这类在输入前可训练添加 prompt
embedding 参数来以少量参数适配下游任务, Adapter Tuning 则是在预训练模型内部的网络层之间添加新的网络层或模块来适配下游任务
。
假设预训练模型函数表示为

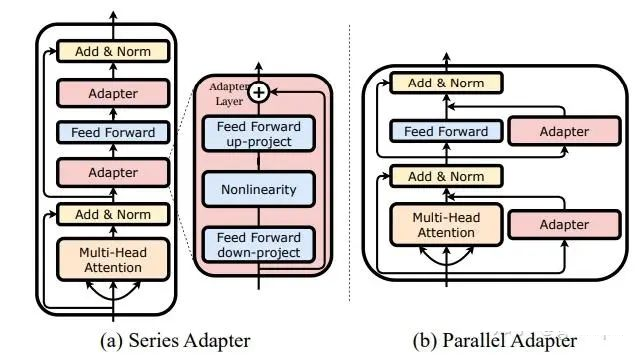
Adapter 主要包括 Series Adapter(串行) 和
Parallel Adapter(并行):
Series Adapter 的适配器结构和与 Transformer 的集成如下图(a)所示。
适配器模块被添加到每个 Transformer 层两次:多头注意力映射之后和两层前馈神经网络之后 。适配器是一个
bottleneck(瓶颈)结构的模块,由一个两层的前馈神经网络(由向下投影矩阵、非线性函数和向上投影矩阵构成)和一个输出输出之间的残差连接组成。
Parallel Adapter如下图(b)所示。 将适配器模块与每层 Transformer 的多头注意力和前馈层并行计算集成
。
五. LoRA
现有的 PEFT 方法主要有两类:Adapter Tuning 和 Prefix Tuning。
Adapter Tuning 在 PLM 基础上添加适配器层会引入额外的计算,带来推理延迟问题;
而 Prefix Tuning 难以优化,其性能随可训练参数规模非单调变化,更根本的是,为前缀保留部分序列长度必然会减少用于处理下游任务的序列长度。
1. 方法原理


LoRA重参数化示意图,预训练模型的参数W固定,只训练A和B参数
2. 方法优点
全量微调的一般化 :LoRA 不要求权重矩阵的累积梯度更新在适配过程中具有满秩。当对所有权重矩阵应用
LoRA 并训练所有偏差时,将 LoRA 的秩 r 设置为预训练权重矩阵的秩,就能大致恢复了全量微调的表现力。也就是说,随着增加可训练参数的数量,训练
LoRA 大致收敛于训练原始模型。
没有额外的推理延时 :在生产部署时,可以明确地计算和存储

的优化器状态,可以用更少的GPU进行大模型训练。在 GPT-3 175B 上,训练期间的 VRAM
消耗从 1.2TB 减少到 350GB。在 r=4 且只有query 和 value 矩阵被调整的情况下,checkpoint
的大小大约减少了 10,000 倍(从 350GB 到 35MB)。另一个好处是,可以在部署时以更低的成本切换任务,只需更换
LoRA 的权重,而不是所有的参数。可以创建许多定制的模型,这些模型可以在将预训练的权重存储在 VRAM
中的机器上进行实时切换。在 GPT-3 175B 上训练时,与完全微调相比,速度提高了25%,因为我们不需要为绝大多数的参数计算梯度。
3. 实验分析
实验将五种方法进行对比,包括:Fine-Tuning (全量微调)、Bias-only or BitFit(只训练偏置向量)、Prefix-embedding
tuning (PreEmbed,上文介绍的 Prefix Tuning 方法,只优化 embedding
层的激活)、Prefix-layer tuning (PreLayer,Prefix Tuning
方法,优化模型所有层的激活) 、 Adapter tuning(不同的 Adapter 方法:

实验结果以 LoRA 在 GPT-3 175B 上的验证分析为例。如下表所示, LoRA 在三个数据集上都能匹配或超过微调基准,证明了
LoRA 方法的有效性 。
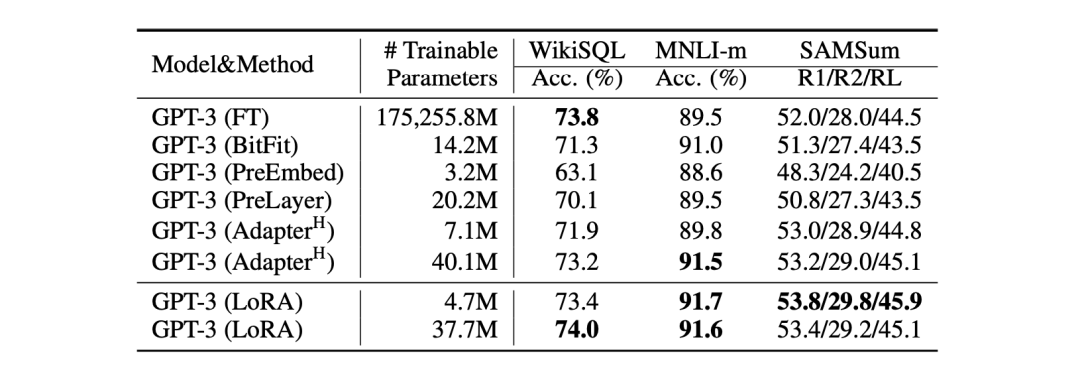
GPT-3 上不同适配方法性能。展示了 WikiSQL 上的逻辑形式验证精度,MultiNLI-matched
上的精度,以及SAMSum上 的 Rouge-1/2/L 值。LoRA 比之前的方法表现更好,包括全量微调。在
WikiSQL 上的结果有 ±0.5% 左右的波动,MNLI-m 有 ±0.1% 左右的波动,SAMSum
有 ±0.2/±0.2/±0.1 左右的三个指标
但是, 并不是所有方法都能从拥有更多的可训练参数中获益,而 LoRA 表现出更好的可扩展性和任务性能
。当使用超过256个特殊token进行 Prefix-embedding tuning 或使用超过32个特殊
tokens 进行 Prefix-layer tuning时,可以观察到性能明显下降。
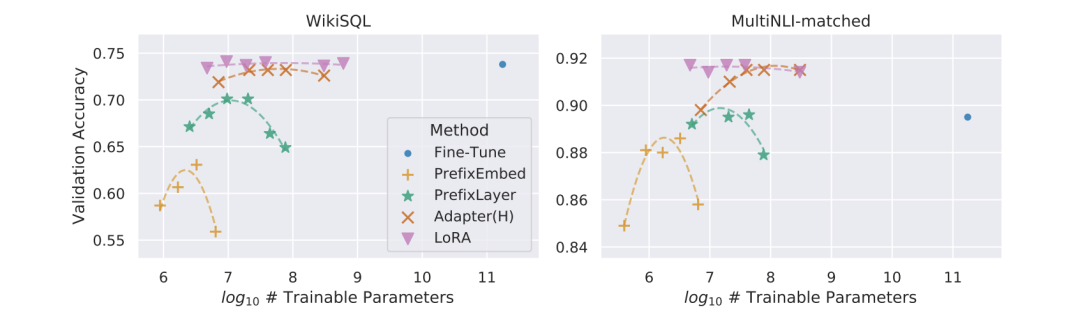
GPT-3 175B 准确率与WikiSQL和MNLI匹配的几种适配方法的可训练参数数的关系
[ 应该对 Transformer 中的哪些权重矩阵应用 LoRA ?] 把所有的参数放在

中捕捉到足够的信息,因此, 适配更多的权重矩阵比适配具有较大秩的单一类型的权重矩阵更可取 。

在可训练参数量相同的情况下,将LoRA应用于GPT-3中不同类型的注意力权重后,WikiSQL和MultiNLI的验证准确率
[ LORA的最佳秩是什么? ] LoRA 在很小的 r 下已经有了很好的表现了(适配
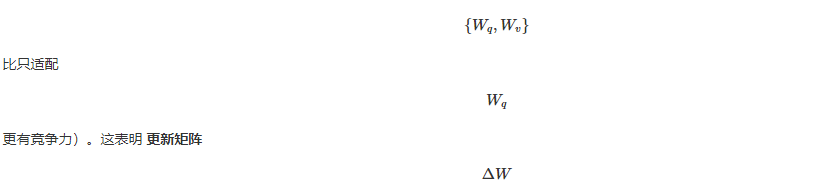
可能有一个很小的 "intrinsic rank",增加秩 r 不一定能够覆盖一个更有意义的子空间,一个低秩的适配矩阵已经足够
。
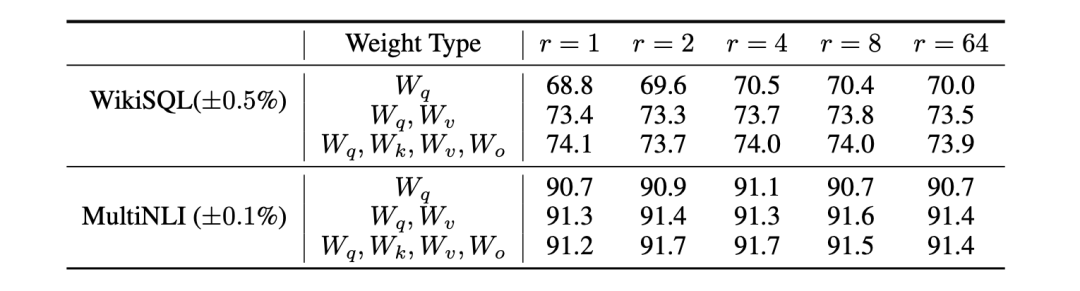
在WikiSQL和MultiNLI上用不同的秩 r 进行验证的准确性
[适配矩阵 \Delta W 与 W 关系如何?] 通过计算 U^{T}WV^{T} 将 W 投射到
\Delta W 的 r 维子空间, U/V 是 \Delta W 的左/右奇异向量矩阵。然后,比较
||U^{T}WV^{T}||_{F} 和 ||W||_{F} 之间的 Frobenius 范数。作为比较,还计算了将
||U^{T}WV^{T}||_{F}中 U 、 V 替换为 W 的前 r 个奇异向量或一个随机矩阵。
与随机矩阵相比, \Delta W 与 W 有更强的相关性,表明 \Delta W 放大了 W 中已有的一些特征;
\Delta W 没有重复 W 的顶级奇异方向,而只是放大了 W 中没有强调的方向;
低秩适配矩阵可能会放大特定下游任务的重要特征,而这些特征在一般的预训练模型中没有得到强调 。

不同秩下 Frobenius 范式。
|






 订阅
订阅