| 编辑推荐: |
本文主要介绍了LLM-GPT原理与本地(M1)微调实战等相关知识。希望对你的学习有帮助。
本文来自于知乎,由火龙果软件Linda编辑,推荐。 |
|
自ChatGPT发布以来,AI领域真的是引燃了大家的热情。 尤其是三月份围绕整个AI大模型领域发布了非常多的重磅产品,导致像我这样的技术追新患者,产生了极大的焦虑。
相信作为技术同学,大家跟我一样,3月份都被相关的文章跟新闻轰炸了。 从GPT-4发布,到微软Copilot-X,再到基于Meta
LLaMa的斯坦福Alpaca,后来像Google Bard、百度文心一言、ChatGLM-6B等等一众模型让大家眼花缭乱。伴随着这些重磅发布的,是圈内大佬们拥抱AI浪潮的冲锋的身姿。
像我们熟知的华人大佬李沐、贾扬清也都已经加入到了大模型创业的浪潮中。
当然了,作为技术人,我第一时间也去试用了这些大模型,这一个多月的时间里面,我俨然已经成为了Chat-GPT的深度用户,
尤其是当我用了ChatGPT Coding以及BugFix的能力之后,脑子里面时常会一闪而过。这玩意真是太强大了,在某些场景下完全可以替代掉我了。怎么办?
怎么办? 的焦虑困扰着我。
脑海里面偶尔也会冒出几个词。搞算法的这群同学怎么搞的,不讲武德。 这是要干掉我们开发的饭碗啊, 我劝你们耗子尾汁,不要做的太过分了!
这不行,必须搞懂它,所以也就有了后面的故事。 当然了,作为非算法同学,很多知识都是现学现卖,如果有不对的地方,欢迎大家指正,如果能产生交流那就更好不过了。
Transformer
我们将时间拉回到2017年。2017年绝对是一个好年份,移动互联网大爆发,人工智能也是刚刚进入商业化应用不久,当时人脸识别还经常出错,自动驾驶也还在试验阶段,深度学习认猫的能力才首次超过人类,
在AI领域机器学习与深度学习还基本是对半开, 深度学习的影响力,远没今天这么大。 彼时深度学习让大家熟知的应该是AlphaGo击败围棋冠军李世石。但相比Google系DeepMind的风光无限,
围绕另一条支线前进的OpenAI受到的关注要少的多。
但当时整个业界还是争议不断,深度学习算法也是层出不穷。 从最经典的MLP(多层感知机)到卷积神经网络(CNN)、再到循环神经网络(RNN),在到后来的现代卷机神经网络、现代循环神经网络,以及各种变体。大家能做的事情好像很多,科研界跟工业界都搞的热热闹闹。
搞算法的跟搞工程的之间也围绕有用论跟无用论各持见解。 搞算法的研究生也不用像现在一样,看着大模型望洋兴叹。
但这一年对今天大模型,甚至是整个AI领域来讲,埋下了重大的伏笔。 Google发布了Transformer深度学习网络架构,或许彼时谁都没想到,Transformer会成为截止今天,最类人脑的数学表达。
Transformer后来的事情,想必大家已经都知道了。后来OpenAI基于Transformer搞了GPT-1,Google不甘示弱,搞了BERT,当然BERT的影响力大家也是知道的,在一段时间内几乎统治了整个深度学习领域,大有一种万物皆可BERT微调的架势。但无论你如何优秀,OpenAI的目标跟思路一直都未曾改变。
再后来GPT-2、GPT-3、再到GPT-3.5也就是ChatGPT出现之后,整个世界都沸腾了,原来AI真的可以,它真的行了,它行了啊。
作为最直接的竞争对手,Google我相信一开始看到对手变得强大也是比较激动的, 但是当回头看了ChatGPT的论文以及关键信息的含糊其辞之后,我相信Google的内心是崩溃的。
早知如此,当时就应该在摇篮当中"掐死"这个老六。
但恨归恨,悔归悔,都为时已晚。 只能奋起直追,迎头赶上。 心里的伤痛就交给时间慢慢愈合吧~
讲到这里前面的废话部分基本进入尾声了,相信搞技术的大家已经急不可奈了。
Talk is cheap,show me the code
你们内心的声音,隔着屏幕我都已经听见了。 好,接下来让我们进入硬核部分。
什么是Transformer?
Transformer的论文的题目是这样的:《Attention is all you need》。
是的,正如题目所言,Transformer是完全基于自注意力机制的基于编码器与解码器的深度网络架构。如下图所示,是整个Transformer的网络架构。

当然了,这个图片或许看着没那么直观,我们将其转换成中文版本来看。
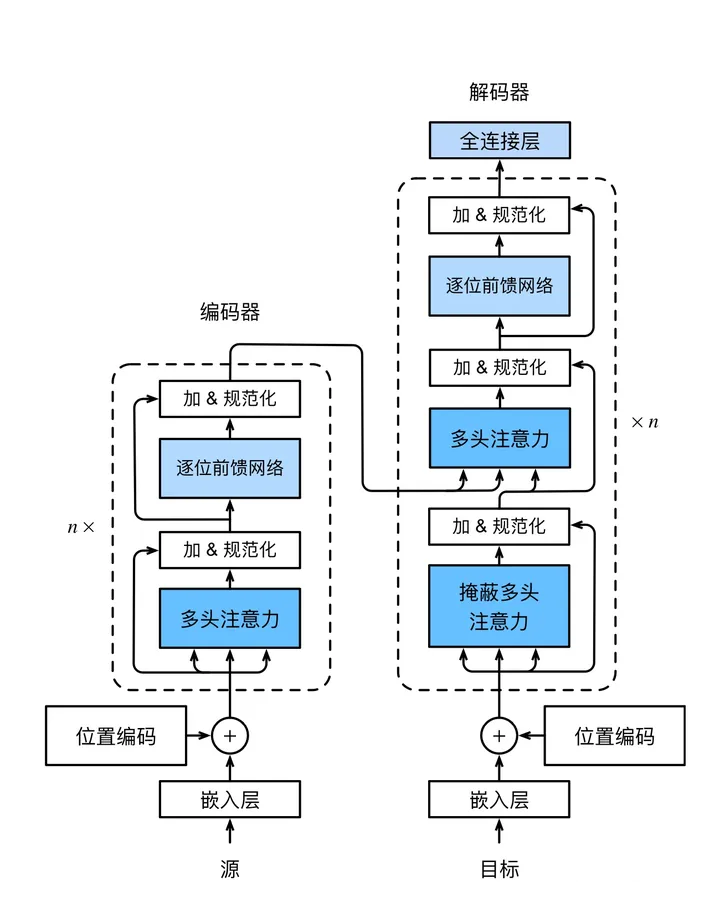
如图所示,是Transformer的整个架构。从宏观角度看,Transformer是由编码器与解码器两部分组成,其编码器又是由多个相同的层叠加而成的,每个层都有两个子层(子层表示为sublayer)。
第一个子层是多头注意力(multi-head self-attention)汇聚;第二个子层是基于位置的前馈网络(positionwise
feed-forward network)。 具体来说,在计算编码器的自注意力时,查询、键和值(Q、K、V)都来自前一个编码层的输出。
每个子层都采用了残差连接(residual connection)。 在Transformer中,对于序列中任何位置输入对于序列中任何位置的任何输入x
∈ R^d,都要求满 足sublayer(x) ∈ R^d,以便残差连接满足x + sublayer(x)
∈ R^d。在残差连接的加法计算之后,紧接着应用层 规范化(layer normalization)。因此,输入序列对应的每个位置,Transformer编码器都将输出一个d维表示向量。
Transformer解码器也是由多个相同的层叠加而成的,并且层中使用了残差连接和层规范化。除了编码器中
描述的两个子层之外,解码器还在这两个子层之间插入了第三个子层,称为编码器-解码器注意力(encoder-
decoder attention)层。在编码器-解码器注意力中,查询来自前一个解码器层的输出,而键和值来自整个编码器的输出。在解码器自注意力中,查询、键和值都来自上一个解码器层的输出。但是,解码器中的每个位
置只能考虑该位置之前的所有位置。这种掩蔽(masked)注意力保留了自回归(auto-regressive)属性,确保预测仅依赖于已生成的输出词元。
当然了,看完以上的解释描述, 对于理解整个Transformer还是比较困难。因为如果作为一个非算法同学,这里面有太多的词汇。什么Q、K、V啊,残差连接啊、
SoftMax啊、规范化啊,等等的吧,都比较陌生。 那么要怎么才能快速学会呢? 请看下面的视频。
是的,你没看错。Learn from ChatGPT, 找ChatGPT学。 下面我贴出来Transformer的代码实现。至于这个代码怎么解读,请用ChatGPT。
此刻它可以扮演一个导师,Standby在你的旁边,回答你一切的What、How?
代码我贴在下面了,如果要直接下载源码的同学,也可以访问github仓库
#!/usr/bin/env python3
# -*- coding: utf-8
import math
import torch
from torch import nn
from d2l import torch as d2l
## 多头注意力实现
class MultiHeadAttention(nn.Module):
"""多头注意力"""
def __init__(self, key_size, query_size, value_size, num_hiddens,
num_heads, dropout, bias=False, **kwargs):
super(MultiHeadAttention, self).__init__(**kwargs)
self.num_heads = num_heads
self.attention = d2l.DotProductAttention(dropout)
self.W_q = nn.Linear(query_size, num_hiddens, bias=bias)
self.W_k = nn.Linear(key_size, num_hiddens, bias=bias)
self.W_v = nn.Linear(value_size, num_hiddens, bias=bias)
self.W_o = nn.Linear(num_hiddens, num_hiddens, bias=bias)
def forward(self, queries, keys, values, valid_lens):
queries = transpose_qkv(self.W_q(queries), self.num_heads)
print("Query Shape:", queries.shape)
keys = transpose_qkv(self.W_k(keys), self.num_heads)
values = transpose_qkv(self.W_v(values), self.num_heads)
if valid_lens is not None:
valid_lens = torch.repeat_interleave(
valid_lens, repeats=self.num_heads, dim=0
)
output = self.attention(queries, keys, values, valid_lens)
output_concat = transpose_output(output, self.num_heads)
return self.W_o(output_concat)
def transpose_qkv(X, num_heads):
""" 为了多注意力头的并行计算而变换形状"""
# [2, 4, 100]
X = X.reshape(X.shape[0], X.shape[1], num_heads, -1)
print("X shape:", X.shape)
X = X.permute(0, 2, 1, 3)
return X.reshape(-1, X.shape[2], X.shape[3])
def transpose_output(X, num_heads):
X = X.reshape(-1, num_heads, X.shape[1], X.shape[2])
X = X.permute(0,2,1,3)
return X.reshape(X.shape[0], X.shape[1], -1)
# 基于前反馈的网络
class PositionWiseFFN(nn.Module):
def __init__(self, ffn_num_input, ffn_num_hiddens, ffn_num_outputs,
**kwargs):
super(PositionWiseFFN, self).__init__(**kwargs)
self.dense1 = nn.Linear(ffn_num_input, ffn_num_hiddens)
self.relu = nn.ReLU()
self.dense2 = nn.Linear(ffn_num_hiddens, ffn_num_outputs)
def forward(self, X):
return self.dense2(self.relu(self.dense1(X)))
class AddNorm(nn.Module):
def __init__(self, normalized_shape, dropout, **kwargs):
super(AddNorm, self).__init__(**kwargs)
self.dropout = nn.Dropout(dropout)
self.ln = nn.LayerNorm(normalized_shape)
def forward(self, X, Y):
return self.ln(self.dropout(Y) + X)
class EncoderBlock(nn.Module):
def __init__(self, key_size, query_size, value_size, num_hiddens,
norm_shape, ffn_num_input, ffn_num_hiddens, num_heads,
dropout, use_bias=False, **kwargs):
super(EncoderBlock, self).__init__(**kwargs)
self.attention = d2l.MultiHeadAttention(
key_size, query_size, value_size, num_hiddens, num_heads, dropout, use_bias
)
self.addnorm1 = AddNorm(norm_shape, dropout)
self.ffn = PositionWiseFFN(ffn_num_input, ffn_num_hiddens, num_hiddens)
self.addnorm2 = AddNorm(norm_shape, dropout)
def forward(self, X, valid_lens):
Y = self.addnorm1(X, self.attention(X, X, X, valid_lens))
return self.addnorm2(Y, self.ffn(Y))
class TransformerEncoder(d2l.Encoder):
def __init__(self, vocab_size, key_size, query_size, value_size,
num_hiddens, norm_shape, ffn_num_input, ffn_num_hiddens,
num_heads, num_layers, dropout, use_bias=False, **kwargs):
super(TransformerEncoder, self).__init__(**kwargs)
self.num_hiddens= num_hiddens
self.embedding = nn.Embedding(vocab_size, num_hiddens)
self.pos_encoding = d2l.PositionalEncoding(num_hiddens, dropout)
self.blks = nn.Sequential()
for i in range(num_layers):
self.blks.add_module("block" + str(i),
EncoderBlock(key_size, query_size, value_size, num_hiddens,
norm_shape, ffn_num_input, ffn_num_hiddens,
num_heads, dropout, use_bias))
def forward(self, X, valid_lens, *args):
X = self.pos_encoding(self.embedding(X) * math.sqrt(self.num_hiddens))
self.attention_weights = [None] *len(self.blks)
for i, blk in enumerate(self.blks):
X = blk(X, valid_lens)
self.attention_weights[
i] = blk.attention.attention.attention_weights
return X
class DecoderBlock(nn.Module):
def __init__(self, key_size, query_size, value_size, num_hiddens,
norm_shape, ffn_num_input, ffn_num_hiddens, num_heads,
dropout, i, **kwargs):
super(DecoderBlock, self).__init__(**kwargs)
self.i = i
self.attention1 = d2l.MultiHeadAttention(
key_size, query_size, value_size, num_hiddens, num_heads, dropout
)
self.addnorm1 = AddNorm(norm_shape, dropout)
self.attention2 = d2l.MultiHeadAttention(
key_size, query_size, value_size, num_hiddens, num_heads, dropout
)
self.addnorm2 = AddNorm(norm_shape, dropout)
self.ffn = PositionWiseFFN(ffn_num_input, ffn_num_hiddens, num_hiddens)
self.addnorm3 = AddNorm(norm_shape, dropout)
def forward(self, X, state):
enc_outputs, enc_valid_lens = state[0], state[1]
if state[2][self.i] is None:
key_values = X
else:
key_values = torch.cat((state[2][self.i], X), axis=1)
state[2][self.i] = key_values
if self.training:
batch_size, num_steps, _ = X.shape
dec_valid_lens = torch.arange(
1, num_steps + 1, device = X.device).repeat(batch_size, 1)
else:
dec_valid_lens = None
# 自注意
X2 = self.attention1(X, key_values, key_values, dec_valid_lens)
Y = self.addnorm1(X, X2)
Y2 = self.attention2(Y, enc_outputs, enc_outputs, enc_valid_lens)
Z= self.addnorm2(Y, Y2)
return self.addnorm3(Z, self.ffn(Z)), state
class TransformerDecoder(d2l.AttentionDecoder):
def __init__(self, vocab_size, key_size, query_size, value_size,
num_hiddens, norm_shape, ffn_num_input, ffn_num_hiddens,
num_heads, num_layers, dropout, **kwargs):
super(TransformerDecoder, self).__init__(**kwargs)
self.num_hiddens = num_hiddens
self.num_layers = num_layers
self.embedding = nn.Embedding(vocab_size, num_hiddens)
self.pos_encoding = d2l.PositionalEncoding(num_hiddens, dropout)
self.blks = nn.Sequential()
for i in range(num_layers):
self.blks.add_module("block"+str(i),
DecoderBlock(key_size, query_size, value_size, num_hiddens,
norm_shape, ffn_num_input, ffn_num_hiddens,
num_heads, dropout, i))
self.dense = nn.Linear(num_hiddens, vocab_size)
def init_state(self, enc_outputs, enc_valid_lens, *args):
return [enc_outputs, enc_valid_lens, [None] * self.num_layers]
def forward(self, X, state):
X = self.pos_encoding(self.embedding(X) * math.sqrt(self.num_hiddens))
self._attention_weights = [[None] * len(self.blks) for _ in range(2)]
for i, blk in enumerate(self.blks):
X, state = blk(X, state)
self._attention_weights[0][i] = blk.attention1.attention.attention_weights
self._attention_weights[1][i] = blk.attention2.attention.attention_weights
return self.dense(X), state
@property
def attention_weights(self):
return self.attention_weights
if __name__ == "__main__":
num_hiddens, num_layers, dropout, batch_size, num_step = 32, 2, 0.1, 64, 10
lr, num_epochs = 0.005, 200
ffn_num_input, ffn_num_hiddens, num_heads = 32, 64, 4
key_size, query_size, value_size = 32, 32, 32
norm_shape = [32]
train_iter, src_vocab, tgt_vocab = d2l.load_data_nmt(batch_size, num_step)
encoder = TransformerEncoder(
len(src_vocab), key_size, query_size, value_size, num_hiddens,
norm_shape, ffn_num_input, ffn_num_hiddens, num_heads,
num_layers, dropout)
decoder = TransformerDecoder(
len(tgt_vocab), key_size, query_size, value_size, num_hiddens,
norm_shape, ffn_num_input, ffn_num_hiddens, num_heads,
num_layers, dropout)
net = d2l.EncoderDecoder(encoder, decoder)
d2l.train_seq2seq(net, train_iter, lr, num_epochs, tgt_vocab, "cpu")
|
以上就是Transformer,我相信你还意犹未尽。 其实关于Transformer的介绍有很多的文章跟视频,我们站内也有船涨的深度解读:
人工智能 LLM 革命系列 1 前夜:一文读懂横扫自然语言处理的 Transformer 模型
大语言模型
Transformer博大精深,我们用以上只言片语,算是草草讲完了。 那么接下来,我们上主菜。 ChatGPT的发布无疑是开启了一个大的技术浪潮。
甚至不仅仅是技术浪潮,是整个社会变革的浪潮也说不定。
主流的大模型介绍
当前要说主要的大模型,影响力最大的,当属于OpenAI系列与马系列(LLaMA、Alpaca、Vicuna)了。
OpenAI系列我估计大家都比较熟悉了,但是马系列是个啥? 这里我重点介绍一下马系列的由来。 今年在ChatGPT火热之后,Meta也推出了自己的大语言模型LLaMA,
但跟OpenAI的Close不同。 Meta的模型参数被泄漏了,使得它不得不开源。 但是Meta呢,我估计是不想开源的,因为在开源协议上明确写着不能用于商用。所以反过来我们也能理解为什么要起这样的名字了,LLaMA(草泥马)。
是谁? 哪个老六泄漏了我们的参数! 所以半遮半掩、半推半就的开源了。
但按照目前LLaMA在整个大模型领域的影响力来看,Meta或许无心插柳柳成荫,有意外收获。
OpenAI GPT系列与马(LLaMA、Alpaca、Vicuna)
OpenAI GPT系列,从2018年开始的GPT-1、再到后来的GPT-2、在到GPT-3、3.5,
以及上个月刚刚发布的GPT-4, 大家对其历程跟能力应该都非常熟悉了,相信绝大多数同学,尤其是作为技术的同学来说,应该也都已经用过了,所以不做过多赘述。
马系列呢?上面我们也简单的介绍了其由来,下面我们在讲一下每匹马都是什么?
LLaMA
正如前面所说,LLaMa是Meta发布的一款大语言模型(LLM)。 其论文题目如是: 《LLaMA:
Open and Efficient Foundation Language Models》 重要的几个词相信大家也都已经看到了。
Open(开放)、 Efficient(高效)、 Foundation(基础)、Language Models(语言模型)。开放的原因前面我们已经做出猜测了,这里我们聊聊高效率跟基础。
高效也很好理解,跟OpenAI GPT系列相比,更小的模型具有更好的效果。 那么基础是什么呢? 是的,我觉得基础表达了整个Meta的战略,当然也不止是Meta。各个发布大模型的公司都有一样的想法,就是成为Base
Model,成为Fundarion,整个大模型领域最基石的那个东西。 最好其他人都是从我之上长出来。
Alpaca
那么Alpaca这匹又是什么马? Alpaca是斯坦福大学基于LLaMA-7B进行微调之后发布的一款大语言模型,反正大家都是同出一脉,叫马肯定没毛病。
那么Alpaca具体是怎么进行微调的呢? 数据集是怎么准备的,都调节了哪些参数呢?
相比与Google、Meta这些大厂的财大气粗。 斯坦福显然是没那么多钱的,那怎么办呢? 既然OpenAI、Meta你们将AI领域的参与水位拉的这么高,并且已经发布了Base
Model。 那么我作为一个中厂级别的玩家, 我就Building ON Your Top(站在巨人的肩膀上)。
一开始就表明态度, 是的我玩不起了。我现在就要明确立场,引领整个科研领域,基于你们的基础模型搞效果。
所以Alpaca出来了,Alpaca也确实优秀,其技术路线给其他玩家,尤其是科研领域的玩家打了一个榜样。
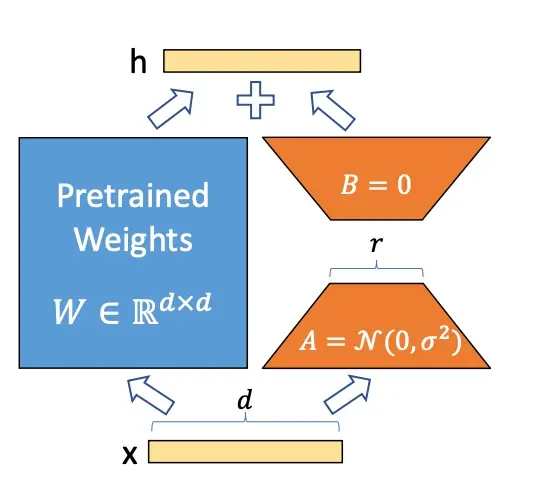
利用self-instruct技术,首先自己构造几十个训练任务指令,然后在用这些指令让GPT-4帮我干活,生成52K的训练数据(完全省去了人工数据标记)。
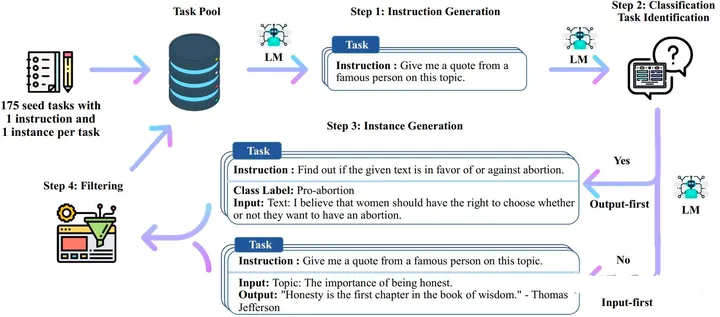
然后在利用LoRA技术,训练自己Care的那些参数。 对,你是基础模型,你帮我干好的那些活我就直接用了,这70亿的参数里面,其他的参数我都不动,我只动对我这个领域会带来显著效果的那些参数,训练完成之后,我一个相对较小模型在具体任务上的表现,甚至不输你数千亿的模型。
训练的成本一下子就降低到可研究水平了。
Vicuna
在开始Vicuna之前,其实我对其了解的也不是特别多,因为它是一匹很新的马。 你知道的,很新的话要了解它还是要花一点时间的,但总之它也是基于LLaMA微调而来的。那么它做了一件什么事情呢?如下图所示,它让GPT-4来对效果进行评估。
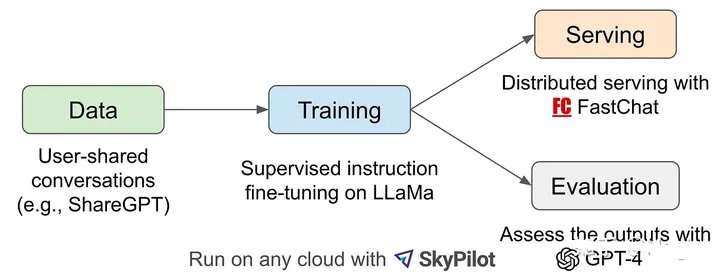
这三匹马非常有意思,第一匹马是直接对标OpenAI GPT系列,要成为整个大模型领域的基石。 后两者更是过分都是让GPT-4来干活来提高自己的效果,
做完之后拿着结果跟GPT系列比。 你看,我模型比你小,训练参数比你少,成本比你低,但是效果比你好。
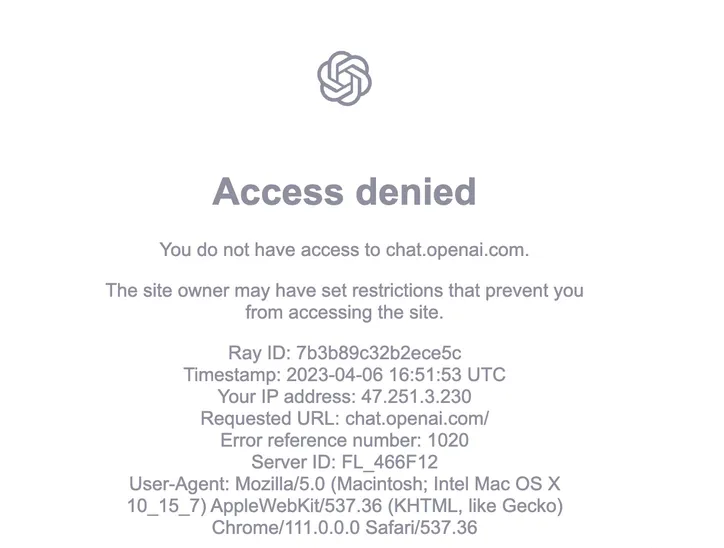
你气不气、气不气、气不气,啦啦啦啦~ 这能忍吗? 肯定不能忍, 叔可忍,婶不能忍。 所以OpenAI大面积限流,关账号。
这个也直接导致我刚刚充值好的Plus变成了Access denied。 我真的是,R N M 退钱!!!
本地如何跑LLaMA?
前面洋洋洒洒几千字,铺垫了这么多,到这里我们也进入到文章高潮阶段了。 接下来,不要走开,让我们来演示一下,如何在本地M1的电脑上运行LLaMA-7B的模型并跟它拉家常。
首先你需要克隆这样一个项目
git clone https://github.com/nomic-ai/gpt4all.git
|
接下来的事情,就请看动图吧。 当然了,因为这个模型是本地部署的,所以你想怎么聊就怎么聊,想聊点啥就聊点啥。
本地如何微调Alpaca-7B
既然本地都可以运行一个大模型了,那我本地能不能进行微调? 我自己训练一个属于自己的大模型,训练他说一些只能两个人之间知道的话。
既然话到这份上了,那答案当然不是否定的,但是过程可能是漫长的,你要经的住煎熬。 毕竟两个人的世界,熬的住的是芬芳,熬不住的是满口芬芳。
同上,代码部分大家也可以直接访问github仓库
环境配置
Alpaca LoRA仓库提供了基于低秩适应(LoRA)重现斯坦福Alpaca大模型效果的处理代码。包括一个效果类GPT-3(text-davinci-003)的指令模型。模型参数可以扩展到13b,
30b, 以及65b, 同时Hugging Face的PEFT以及Dettmers提供的bitsandybytes被用于在大模型微调中的提效与降本。
我们将在一个特定数据集上对Alpaca LoRA进行一次完整的微调,首先从数据准备开始,最后是我们对模型的训练。
本教程将会覆盖数据处理、模型训练、以及使用最普世的自然语言处理库比如Transformers和Hugging
Face进行结果评估。此外我们也会通过使用Gradio来介绍模型的部署以及测试。
在开始教程之前, 首先需要安装依赖包, 在本文中用到的依赖包如下:
pip install -U pip
pip install accelerate==0.18.0
pip install appdirs==1.4.4
pip install bitsandbytes==0.37.2
pip install datasets==2.10.1
pip install fire==0.5.0
pip install git+https://github.com/huggingface/peft.git
pip install git+https://github.com/huggingface/transformers.git
pip install torch==2.0.0
pip install sentencepiece==0.1.97
pip install tensorboardX==2.6
pip install gradio==3.23.0
|
在安装好以上依赖之后, 即可开始我们本次的课程之旅了, 首先让我们来引入对应的依赖包
import json
import transformers
import textwrap
from transformers import LlamaTokenizer, LlamaForCausalLM
import os
import sys
from typing import List
from peft import (
LoraConfig,
get_peft_model,
get_peft_model_state_dict,
prepare_model_for_int8_training,
)
import fire
import torch
from datasets import load_dataset
import pandas as pd
import matplotlib.pyplot as plt
import matplotlib as mpl
import seaborn as sns
from pylab import rcParams
# 设置是用GPU还是CPU, 如果是mac M1芯片可以尝试mps
device = "cuda" if torch.cuda.is_available() else "mps"
|
数据
本文中我们使用的数据是BTC推特上的情绪分析数据集, 在Kaggle网站上就可以下载到对应的数据集,
本数据集包含了50000+BTC相关的推文。为清洗这些数据, 本文中移除了所有'RT'开始以及包含链接的数据。OK,
首先我们来下载数据集。在Kaggle网站上,直接选择到对应的数据集,下载即可。 当然也可以使用命令来下载。

!gdown 1xQ89cpZCnafsW5T3G3ZQWvR7q682t2BN
我们可以通过Pandas来加载CSV文件数据
df = pd.read_csv("../../data/BTC_Tweets_Updated.csv")
df.head()
|
在数据集上, 因为我们是作为演示,所以对数据没做什么处理,直接使用原始数据。 其中数据中的情绪标签通过数字来表示,-1表示消极情绪,
0表示中性情绪, 1表示积极情绪。首先看一下数据分布
def.sentiment.value_counts()
['positive'] 22937
['neutral'] 21932
['negative'] 5983
Name: Sentiment, dtype: int64
df.Sentiment.value_counts().plot(kind="bar")
|
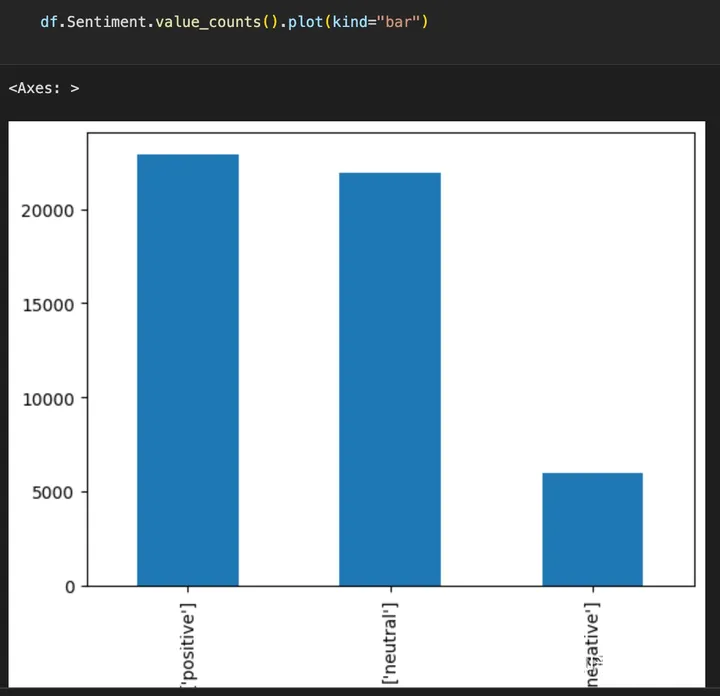
通过数据分布我们可以看出, 负面情绪的分布明显较低,在评估模型的效果时我们应该重点考虑。
构建JSON数据集
在原始的alpaca仓库中,用到的数据集是JSON文件,是一份包含instruction、input、以及output的数据列表。接下来我们将数据转换为对应的json格式。
def sentiment_score_to_name(score: float):
if score > 0:
return "Positive"
elif score < 0:
return "Negative"
return "Neutral"
dataset_data = [
{
"instruction": "Detect the sentiment of the tweet.",
"input": row_dict["tweet"],
"output": sentiment_score_to_name(row_dict["sentiment"])
}
for row_dict in df.to_dict(orient="records")
]
dataset_data[0]
{
"instruction": "Detect the sentiment of the tweet.",
"input": "@p0nd3ea Bitcoin wasn't built to live on exchanges.",
"output": "Positive"
}
|
最后我们将数据保存到文件,用于之后的模型训练。
import json
with open("alpaca-bitcoin-sentiment-dataset.json", "w") as f:
json.dump(dataset_data, f)
|
模型权重
虽然没有最原始的LLaMA模型的权重可以使用, 但它们被泄漏了并且被改编为HuggingFace的模型库可以跟Transformers一起使用。在这里我们使用decapoda研究的权重。
BASE_MODEL = "decapoda-research/llama-7b-hf"
model = LlamaForCausalLM.from_pretrained(
BASE_MODEL,
load_in_8bit=True,
torch_dtype=torch.float16,
device_map="auto",
)
tokenizer = LlamaTokenizer.from_pretrained(BASE_MODEL)
tokenizer.pad_token_id = (
0
)
tokenizer.padding_side = "left"
|
这段使用LlamaForCausalLM类来加载预训练的Llama模型,LlamaForCausalLM类被HuggingFace的Transformers库所实现。
load_in_8bit=True参数使用8位量化加载模型以减少内存使用并提高推理速度。
同时以上代码也加载了分词器通过同样的LLaMA模型, 使用Transformers的LlamaTokenizer类,
并且设置了一些额外的属性比如pad_token_id设置为了0来表现未知的token, 设置了padding_side
设置为了left, 为了在左侧填充序列。
数据集
现在我们已经加载了模型和分词器, 我们可以通过HuggingFace提供的load_dataset()方法来处理我们之前保存的数据了。
data = load_dataset("json", data_files="alpaca-bitcoin-sentiment-dataset.json")
data["train]
Dataset({
features: ['instruction', 'input', 'output'],
num_rows: 1897
})
|
接下来, 我们需要需要从数据集中构建提示词,并进行标记。
def generate_prompt(data_point):
return f"""Below is an instruction that
describes
a task, paired with an input that provides
further context. Write a response
that appropriately completes the request. # noqa: E501
### Instruction:
{data_point["instruction"]}
### Input:
{data_point["input"]}
### Response:
{data_point["output"]}"""
def tokenize(prompt, add_eos_token=True):
result = tokenizer(
prompt,
truncation=True,
max_length=CUTOFF_LEN,
padding=False,
return_tensors=None,
)
if (
result["input_ids"][-1] != tokenizer.eos_token_id
and len(result["input_ids"]) < CUTOFF_LEN
and add_eos_token
):
result["input_ids"].append(tokenizer.eos_token_id)
result["attention_mask"].append(1)
result["labels"] = result["input_ids"].copy()
return result
def generate_and_tokenize_prompt(data_point):
full_prompt = generate_prompt(data_point)
tokenized_full_prompt = tokenize(full_prompt)
return tokenized_full_prompt
|
上述第一个函数generate_prompt 从数据集里面取一个数据点并通过组合instruction、input、以及output值来生成一个提示。
第二个函数tokenize获取生成的提示词并对其进行分词。它也会给词追加一个结束序列并设置一个标签,
保持跟输入序列一致。第三个函数generate_and_tokenize_prompt 组合了第一个和第二个函数在一个步骤里面生成并且分词提示词。
数据准备的最后一步是将数据拆分为单独的训练集和验证集
train_val = data["train"].train_test_split(
test_size = 200, shuffer=True, seed=42
)
train_data = (
train_val["train"].map(generate_and_tokenize_prompt)
)
val_data = (
train_val["test"].map(generate_and_tokenize_prompt)
)
|
我们使用200条数据作为验证数据集并将数据打撒。generate_and_tokenize_prompt函数被用于数据的每一个样本来生成标记好的提示词。
训练
训练过程需要依赖几个参数, 这些参数主要来自原始库中的微调脚本
LORA_R = 8
LORA_ALPHA = 16
LORA_DROPOUT= 0.05
LORA_TARGET_MODULES = [
"q_proj",
"v_proj",
]
BATCH_SIZE = 128
MICRO_BATCH_SIZE = 4
GRADIENT_ACCUMULATION_STEPS = BATCH_SIZE // MICRO_BATCH_SIZE
LEARNING_RATE = 3e-4
TRAIN_STEPS = 300
OUTPUT_DIR = "experiments"
|
现在我们就可以准备模型来训练了
model = prepare_model_for_int8_training(model)
config = LoraConfig(
r=LORA_R,
lora_alpha=LORA_ALPHA,
target_modules=LORA_TARGET_MODULES,
lora_dropout=LORA_DROPOUT,
bias="none",
task_type="CAUSAL_LM",
)
model = get_peft_model(model, config)
model.print_trainable_parameters()
|
我们初始化并且准备好了模型来训练Lora算法, 这是一种量化形式,可以减少模型大小和内存使用量,而不会显著降低准确性。
LoraConfig 是一个LORA算法超参数的类,比如像正则化强度(lora_alpha), 丢弃概率(lora_dropout),
以及要压缩的目标模块(target_modules)
在训练过程中, 我们将使用来自HuggingFace的Transformers库中的Trainer类。
training_arguments = transformers.TrainingArguments(
per_device_train_batch_size=MICRO_BATCH_SIZE,
gradient_accumulation_steps=GRADIENT_ACCUMULATION_STEPS,
warmup_steps=100,
max_steps=TRAIN_STEPS,
learning_rate=LEARNING_RATE,
fp16=True,
logging_steps=10,
optim="adamw_torch",
evaluation_strategy="steps",
save_strategy="steps",
eval_steps=50,
save_steps=50,
output_dir=OUTPUT_DIR,
save_total_limit=3,
load_best_model_at_end=True,
report_to="tensorboard"
)
|
这段代码创建了一个TrainingArguments 训练参数对象, 其设定了一系列的变量以及超参数来训练基础模型,这些参数包括
gradient_accumulation_steps: 梯度下降的步长, 是指在训练神经网络时,累积多个小
batch 的梯度更新权重参数的方法, 主要在反向传播跟梯度更新。
warmup_steps: 优化器的预热步骤数。
max_steps: 训练模型的的步数上限
learning_rate: 优化器的学习率
fp16: 使用 16 位精度进行训练
data_collator = transformers.DataCollatorForSeq2Seq(
tokenizer, pad_to_multiple_of=8, return_tensors="pt", padding=True
)
|
DataCollatorForSeq2Seq 是来自Transformers库中的类, 创建批量的输入/输出给Seq2Seq模型。在本代码中,
DataCollatorForSeq2Seq是通过下列参数实例化的对象
pad_to_multiple_of: 表示最大序列长度的整数,四舍五入到最接近该值的倍数。
padding: 一个布尔值,指示是否将序列填充到指定的最大长度
现在我们有所有的必要条件了,接下来我们就可以训练我们的模型了。
trainer = transformers.Trainer(
model=model,
train_dataset=train_data,
eval_dataset=val_data,
args=training_arguments,
data_collector=data_collector
)
model.config.use_cache = False
old_state_dict = model.state_dict
model.state_dict=(
lamba self, *_, **__: get_peft_model_state_dict(
self, old_state_dict()
)
).__get__(model, type(model))
trainer.train()
model.save_pretrained(OUTPUT_DIR)
|
总结
综上所述,我们从大模型引出了人工智能近年来的发展。 在后来Google发布Transformer深度学习网络架构,再到后来OpenAI
ChatGPT横空出世。 紧接着Meta的LLaMA发布,以及衍生出的各种微调系列模型。可以说整个大模型领域现阶段的演进方向跟模式已经相对确定了。
尽管GPT系列发布之后,所有科技公司都提出AI First战略,整个AI领域的发展一日千里。 但整个大的框架基本固定了。现阶段,包括接下来一段时间的玩法都可以归纳为以下几类:
1. 大玩家继续在Transformer上卷大模型,训练自己的基础模型(Base Model),可以类比操作系统。代表像OpenAI、Google、Meta以及各个有钱的大厂。
2. 中型玩家在这些大模型之上做微调, 可以类比在基础操作系统上的各种魔改。代表有斯坦福Alpaca,后面如果像cerebras这样的玩家全部开源基础模型后,估计会有很多的中型玩家也发布自己的大模型。
3. 小玩家或者科研工作者,以及局部小业务场景,需要用大模型的能力,但是又想自主私有化部署,这部分玩家怎么办呢?
目前看整个开源社区演进的方案是在大模型的基础之上结合LoRA、Bitsandbytes、PEFT这些提效、降本的方案来搞一套自己的模型。
也就是在本文中实战部分本地微调Alpaca-7B模型演示的一样。 这些模型可以打包成一个私有模型,内嵌在一个需要进行隐私保护的OFFLINE(私有化)区域,比如一个音响里、学习机里、玩具里等等,
类比一个最小功能的操作系统。
在大模型领域,截止目前OpenAI GPT系列跟Meta LLaMA 一个作为闭源代表,一个作为开源代表,可谓是一时风光无限。
但这个浪潮才刚刚升起,以后是类似苹果与微软的故事重演。还是百花齐放,万家争鸣,让我们拭目以待。
|




