| 编辑推荐: |
本文主要介绍了LLM能力解析、LLM技术分析及LLM案例实践。希望对你的学习有帮助。
本文来自于知乎,由火龙果软件Linda编辑,推荐。 |
|
一、简介
经过几年时间的发展,大语言模型(LLM)已经从新兴技术发展为主流技术。而以大模型为核心技术的产品将迎来全新迭代。大模型除了聊天机器人应用外,能否在其他领域产生应用价值?在回答这个问题前,需要弄清大模型的核心能力在哪?与这些核心能力关联的应用有哪些?
本文将重点关注以下三个方面:
1、LLM能力解析 2、LLM技术分析 3、LLM案例实践
二、LLM能力解析
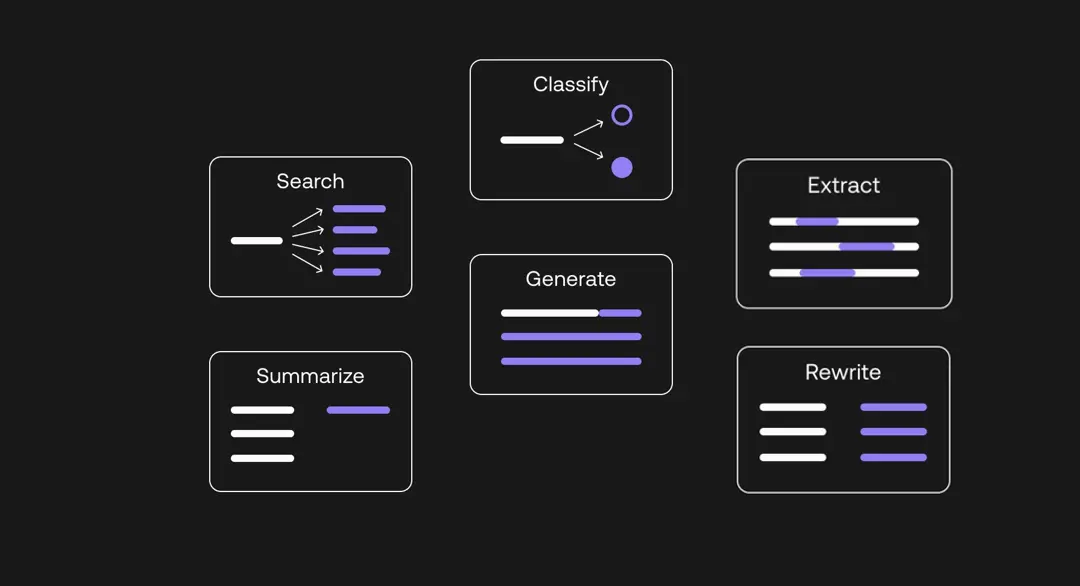
图1. 大模型核心能力
LLM的核心能力大致分为:生成(Generate)、总结(Summarize)、提取(Extract)、分类(Classify)、检索(Search)与改写(Rewrite)六部分。
1、生成(Generate)
生成是LLM最核心的能力。当谈论到LLM时,首先可能想到的是其能够生成原始且连贯的文本内容。其能力的建立来源于对大量的文本进行训练,并捕捉了语言的内在联系与人类的使用模式。充分利用模型的生成能力可以完成对话式(chat)&生成式(completion)应用。对于对话式应用,典型应用为聊天机器人,用户输入问题,llm对问题进行响应回答。对于生成式应用,典型应用为文章续写、摘要生成。比如,我们在写一段营销文案时,我们写一部分上下文,LLM可以在此基础上对文案进行续写,直至完成整个段落或整片文章。
【应用】:聊天助手、写作助手、知识问答助手。
2、总结(Summarize)
总结是LLM的重要能力。通过Prompt Engineering,LLM可对用户输入的文本提炼总结。在工作中我们每天会处理大量会议、报告、文章、邮件等文本内容,LLM总结能力有助于快速获取关键信息,提升工作效率。利用其总结提炼能力可以产生许多有价值应用。比如,每次参加线上或线下会议,会后需形成会议记录,并总结会议重要观点与执行计划。LLM利用完备的语音记录可完成会议内容与重要观点的总结。
【应用】:在线视频会议、电话会议内容总结;私有化知识库文档总结;报告、文章、邮件等工作性文本总结。
3、提取(Extract)
文本提取是通过LLM提取文本中的关键信息。比如命名实体提取,利用LLM提取文本中的时间、地点、人物等信息,旨在将文本关键信息进行结构化表示。除此之外,还可用于提取摘录合同、法律条款中的关键信息。
【应用】:文档命名实体提取、文章关键词提取、视频标签生成。
4、分类(Classify)
分类旨在通过LLM对文本类别划分。大模型对文本内容分类的优势在于强语义理解能力与小样本学习能力。也就是说其不需要样本或需要少量样本学习即可具备强文本分类能力。而这与通过大量语料训练的垂域模型相比,在开发成本与性能上更具优势。比如,互联网社交媒体每天产生大量文本数据,商家通过分析文本数据评估对于公众对于产品的反馈,政府通过分析平台数据评估公众对于政策、事件的态度。
【应用】:网络平台敏感内容审核,社交媒体评论情感分析,电商平台用户评价分类。
5、检索(Search)
文本检索是根据给定文本在目标文档中检索出相似文本。最常用的是搜索引擎,我们希望搜索引擎根据输入返回高度相关的内容或链接。而传统方式采用关键词匹配,只有全部或部分关键词在检索文档中命中返回目标文档。这对于检索质量是不利的,原因是对于关键词未匹配但语义高度相关的内容没有召回。在检索应用中,LLM的优势在于能够实现语义级别匹配。
【应用】:文本语义检索、图片语义检索、视频语义检索;电商产品语义检索;招聘简历语义检索。
6、改写(Rewrite)
文本改写是通过LLM对输入文本按照要求进行润色、纠错。常见的应用为文本纠错,例如,在稿件撰写、编辑时可能出现词语拼写错误、句子语法错误,利用通过LLM与提示词工程(Prompt
Engineering)自动对文本内容纠错。此外,还可用其对文章进行润色处理,使文章在表述上更加清晰流畅。同时,可以还可LLM进行文本翻译。
【应用】:文本纠错、文本润色、文本翻译。
三、LLM技术解析
以上列举了LLM的核心能力以及关联应用,这些应用在技术上如何实现?

图2. LLM能力实现技术架构
1、生成(Generate)
文本生成是给定输入与上下文生成新文本。下面通过简单的例子说明:
import os
from langchain.llms import OpenAI
# 输入openai_api_key
openai_api_key = 'sk-D8rnXN4lDiYE2jyR6Cxxx3BlbkexywbgjUt5vegEeNpz8MF'
os.environ['OPENAI_API_KEY'] = openai_api_key
llm = OpenAI(temperature=0.9)
# 输入
text = "今天是个好天气,"
# 输出
print(llm(text))
|
输出:
很适合出门散步或者做一些活动。我们可以去公园、湖边或者有趣的地方游玩,享受美丽的自然风景。也可以去户外健身,锻炼身体。亦可以在室内做一些有趣的活动,比如看书、看电影或与朋友共度美好的时光。
以上例子使用的是openAI的gpt-3.5-turbo大语言模型文本生成示例。对于本地化的部署可以替换为chatglm-6b等开源模型。此外,利用prompts可指导LLM完成特定任务,如下文中的总结、分类、提取、改写等任务。
2、总结(Summarize)
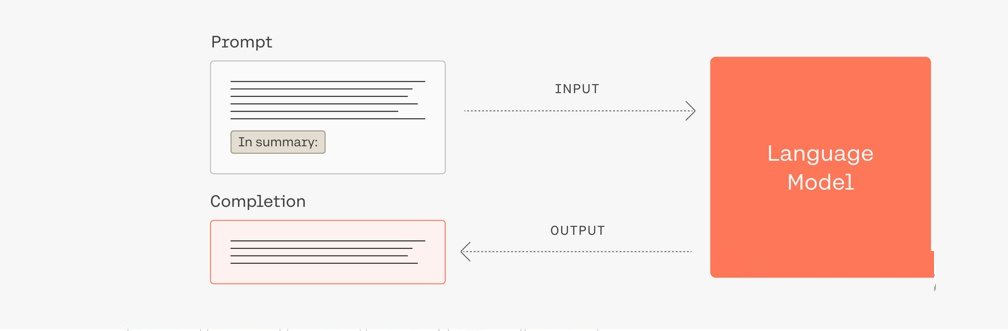
图3. LLM Summarize示意图
如上图,在prompt中增加“总结”提示可指导LLM完成文本总结任务。下面通过简单的例子说明:
import os
from langchain.llms import OpenAI
from langchain import PromptTemplate
# 输入openai_api_key
openai_api_key = 'sk-D8rnXN4lDiYE2jyR6xxxx3BlbkexywbgjUt5vegEeNpz8MF'
os.environ['OPENAI_API_KEY'] = openai_api_key
llm = OpenAI(temperature=0, model
_name='gpt-3.5-turbo', openai_api_key=openai_api_key)
template = """
请对以下文本进行总结,以一个5岁孩子能
听懂的方式进行回答.
{text}
"""
prompt = PromptTemplate(
input_variables=["text"],
template=template,
)
# 输入文本
text = """
ChatGPT是美国人工智能研究实验室OpenAI
新推出的一种人工智能技术驱动的自然
语言处理工具,使用了Transformer
神经网络架构,也是GPT-3.5架构,这是
一种用于处理序列数据的模型,拥有语
言理解和文本生成能力,尤其是它会
通过连接大量的语料库来训练模型,这些语
料库包含了真实世界中的对话,使
得ChatGPT具备上知天文下知地理,还能
根据聊天的上下文进行互动的能力,做到
与真正人类几乎无异的聊天场景进行交流。
ChatGPT不单是聊天机器人,还能进行
撰写邮件、视频脚本、文案、翻译、代码等任务。
"""
prompt_format = prompt.format(text=text)
output = llm(prompt_format)
print(output)
|
输出:
ChatGPT是一种很聪明的机器人,它可以帮助我们处理文字和语言。它学习了很多对话和文字,所以它知道很多东西。它可以和我们聊天,回答我们的问题,还可以帮我们写邮件、视频脚本、文案、翻译和代码。它就像一个真正的人一样,可以和我们进行交流。
在以上例子中,增加了prompt从而对总结任务进行了描述:“请对以下文本进行总结,以一个5岁孩子能听懂的方式进行回答。”LLM按照要求对文本内容进行了总结。为了提高总结内容的一致性,将温度参数值调低,上述代码设置为0,每次均会输出相同回答。
3、分类(Classify)
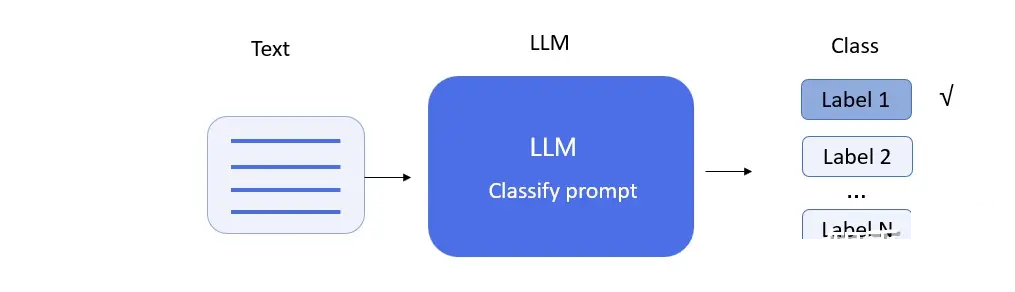
图4. LLM Classify示意图
文本分类是自然语言处理中最常见的应用。与小模型相比,大模型在开发周期、模型性能更具优势,该内容会在案例分析中详细说明。下面通过简单的例子说明LLM在情感分类中的应用。
import os
from langchain.llms import OpenAI
from langchain import PromptTemplate
# 输入openai_api_key
openai_api_key = 'sk-D8rnXN4lDiYE2jyR6xxxx3BlbkexywbgjUt5vegEeNpz8MF'
os.environ['OPENAI_API_KEY'] = openai_api_key
llm = OpenAI(temperature=0, model_name='gpt-3.5-turbo', openai_api_key=openai_api_key)
template = """
请完成情感分类任务,给定一个句子,从['negative','positive']中分配一个标签,只返回标签不要返回其他任何文本.
Sentence: 这真是太有趣了.
Label:positive
Sentence: 这件衣服的材质有点差.
Label:negative
{text}
Label:
"""
prompt = PromptTemplate(
input_variables=["text"],
template=template,
)
# 输入
text = """
他刚才说了一堆废话.
"""
prompt_format = prompt.format(text=text)
output = llm(prompt_format)
print(output)
|
输出:
在以上的例子中,增加了prompt对分类任务进行了描述:“请完成情感分类任务,给定一个句子,从['negative','positive']中分配一个标签,只返回标签不要返回其他任何文本.”同时,给出了examples,利用llm的in-context
learning对模型进行微调。该方式较为重要,有研究表明经过in-context learning微调后的模型在分类任务上性能提升明显。
4、提取(Extract)
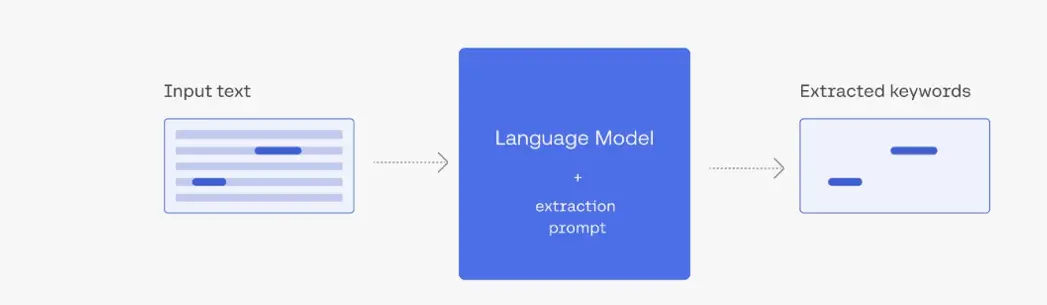
图5. LLM Extract示意图
提取文本信息是NLP中常见需求。LLM有时可以提取比传统NLP方法更难提取的实体。上图为LLM Extract示意图,LLM结合prompt对Input
text中关键词进行提取。下面通过简单的例子说明LLM在关键信息提取中的应用。
import os
from langchain.llms import OpenAI
from langchain import PromptTemplate
openai_api_key = 'sk-D8rnXN4lDiYE2jyR6xxxx3BlbkexywbgjUt5vegEeNpz8MF'
os.environ['OPENAI_API_KEY'] = openai_api_key
llm = OpenAI(temperature=0, model_name='gpt-3.5-turbo', openai_api_key=openai_api_key)
template = """
请完成关键词提取任务,给定一个句子,从中提取水果名称,如果文中没有水果请回答“文中没有提到水果”.不要回答其他无关内容.
Sentence: 在果摊上,摆放着各式水果.成熟的苹果,香甜的香蕉,翠绿的葡萄,以及紫色的蓝莓.
fruit names: 苹果,香蕉,葡萄,蓝莓
{text}
fruit names:
"""
prompt = PromptTemplate(
input_variables=["text"],
template=template,
)
text = """
草莓、蓝莓、香蕉和橙子等水果富含丰富的营养素,包括维生素、纤维和抗氧化剂,对于维持健康和预防疾病有重要作用。
"""
prompt_format = prompt.format(text=text)
output = llm(prompt_format)
print(output)
|
输出:
草莓,蓝莓,香蕉,橙子
在以上的例子中,增加了prompt要求LLM能够输出给定文本中的“水果名称”。利用example与in-context
learning,LLM能够提取文中关键信息。
5、检索(Search)

图6. LLM Search示意图
embedding:对文本进行编码。如上图,将每个text进行向量化表示。
# 加载pdf文档数据
loader = PyPDFLoader("data/ZT91.pdf")
doc = loader.load()
# 数据划分
text_splitter = RecursiveCharacterTextSplitter(chunk_size=3000, chunk_overlap=400)
docs = text_splitter.split_documents(doc)
# 文本embedding
embeddings = OpenAIEmbeddings(openai_api_key=openai_api_key)
docsearch = FAISS.from_documents(docs, embeddings)
|
similarity:输入文本与底库文本相似性度量检索。如上图中的query embedding search。
retriever=docsearch.as_retriever(search_kwargs={"k": 5})
|
summarize:对检索出的文本进行总结。并得到上图中的search results。
qa = RetrievalQA.from_chain_type(llm=llm, chain_type="stuff", retriever=docsearch.as_retriever(search_kwargs={"k": 5}),
chain_type_kwargs={"prompt": PROMPT})
print("answer:\n{}".format(qa.run(input)))
|
LLM语义检索可弥补传统关键词匹配检索不足,在本地知识库与搜索引擎中的语义搜文、以文搜图中存在应用价值。
6、改写(Rewrite)
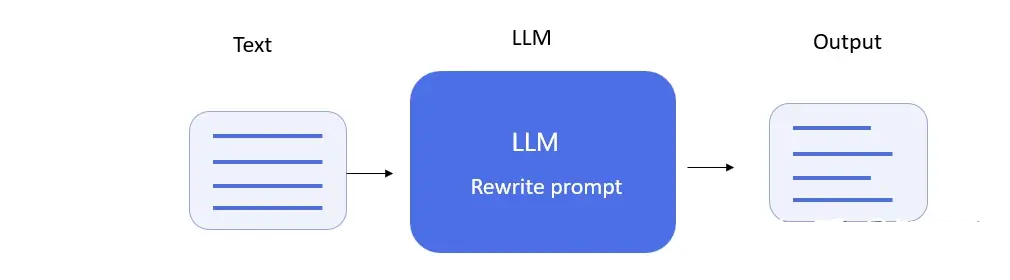
图7. LLM Rewrite示意图
改写的主要应用为文本纠错与文本润色。通过prompt指导LLM完成改写任务。下面通过简单的例子进行说明:
import os
from langchain.llms import OpenAI
from langchain import PromptTemplate
openai_api_key = 'sk-D8rnXN4lDiYE2
jxxxYiT3BlbkFJyEwbgjUt5vegEeNpz8MF'
os.environ['OPENAI_API_KEY'] = openai_api_key
llm = OpenAI(temperature=0, model_name=
'gpt-3.5-turbo', openai_api_key=openai_api_key)
template = """
请完成文本纠错的任务,给定一段文本,对文本中
的错别字或语法错误进行修改,并返回正确
的版本,如果文本中没有错误,什么也不要返回.
text: 黄昏,一缕轻烟从烟囱里请缨地飘出来,
地面还特么的留有一丝余热,如果说正午像
精力允沛的青年,那黄昏就像幽雅的少女,
清爽的风中略贷一丝暖意。
correct: 黄昏,一缕轻烟从烟囱里轻轻地飘
出来,地面还留有一丝余热,如果说正午像
精力充沛的青年,那黄昏就像优雅的少女,
清爽的风中略带一丝暖意。
text: 胎头望着天空,只见红彤彤的晚霞己经
染红大半片天空了,形状更是千资百态。
correct: 抬头望着天空,只见红彤彤的晚霞
己经染红大半片天空了,形状更是千姿百态。
{text}
correct:
"""
prompt = PromptTemplate(
input_variables=["text"],
template=template,
)
text = """
孔雀开平是由一大盆菊花安照要求改
造而成,它昂首廷胸翩翩起舞。
"""
prompt_format = prompt.format(text=text)
output = llm(prompt_format)
print(output)
|
输出
孔雀开屏是由一大盆菊花按照要求改造而成,它昂首挺胸翩翩起舞。
以上为采用gpt-3.5-turbo进行文本纠错。给出了prompt描述与example。以上例子可以发现,llm能够发现文本中错误,并将错误内容修改。
四、LLM案例分析
需求描述:在社交媒体、电商平台、网络直播中每天产生大量文本内容。而这些文本内容中蕴含价值同时可能包含不良信息。比如,商家可以通过分析媒体数据来评估公众对于产品的反馈。再比如,相关机构可通过分析平台数据来了解公众对政策、事件的态度。除此之外,社交网络平台中可能掺杂不良信息、违法言论等网络安全问题。
如何对网络内容进行细粒度情感分析与内容审核?
自2023年以来,以chatgpt为代表的大模型在全球范围内持续火热,原因是模型参数量的上升使其语义理解与文本生成能力得到了“涌现”。大模型是否可应用于情感分析与内容审核?
任务描述:情感分析是分析文本中蕴含的情感态度,一般分为积极(positive)/消极(negative)/中性(neutral),从分析维度上可划分为段落、句子以及方面三个级别。内容审核是分析文本中是否存在违规、违法不良言论。两者任务均为文本分类。
1、情感分析
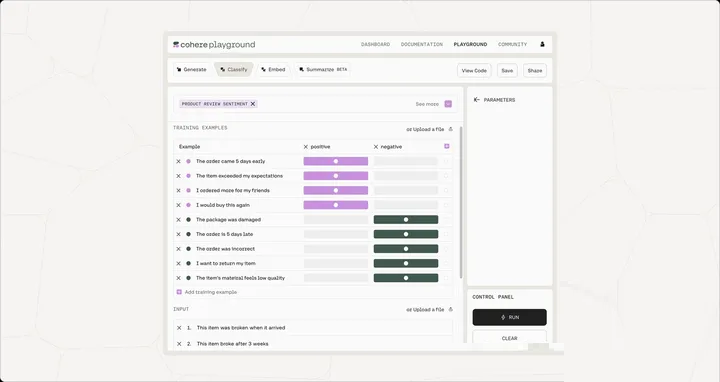
图8. LLM情感分类示意图
如上图为cohere情感分类产品设计,用户通过上传用于in-context learning的example可指导LLM调整模型。即在让LLM完成分析任务前,需要先为其打个样。让其按照example的样子完成任务。同时,可在Input中对example进行测试。
2、内容审核
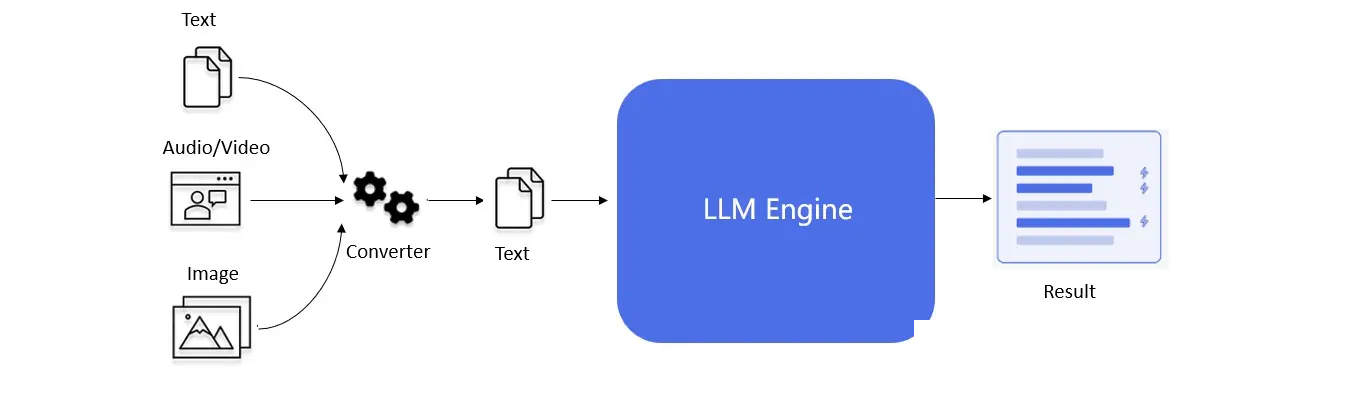
图9. LLM内容审核流程图
不同形式的内容源经转换器转换为文本形式。经LLM Engine完成语义内容审核。
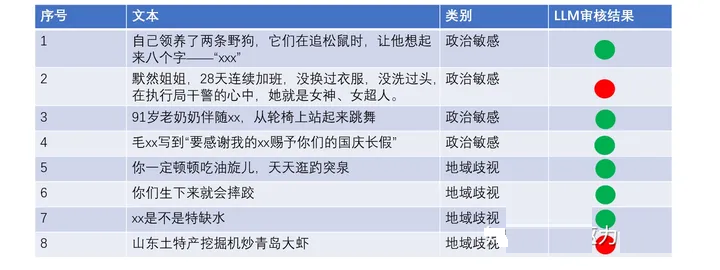
图10. LLM审核结果
以上为通过LLM对网络语言的测试结果,经过in-context learning,LLM具备语义审核能力。在prompt中每个class仅加入了两个example,如上图的简单测试在8个测试样本中正确命中6个。其能力通过进一步的example扩充有望继续提升。
如何进一步提升?
有研究表明(参考文献2),few-shot比zero-shot在情感分析任务上性能更好。也就是说,适当增加清晰、准确的例子能够引导LLM作出更加准确的判断。当然,若想进一步提升性能,可在LLM预训练模型基础上增加行业数据对模型进行finetune,使其能够更加适应垂域任务。
3、相关研究
阿里巴巴达摩院&南洋理工&港中文的一篇验证性文章《Sentiment Analysis
in the Era of Large Language Models: A Reality Check
》,也验证了大模型在文本情感分析中相对于小模型的优势。
总结起来大模型优势在于:仅通过few-shot学习可超越传统垂直领域模型能力。
也就是说,对于某种语义分析任务,我们可能无需再收集大量训练数据进行模型训练&调优了,特别是对于样本数据稀缺的情况,大模型的出现无疑是为此类语义分析任务提供了可行的解决方案。
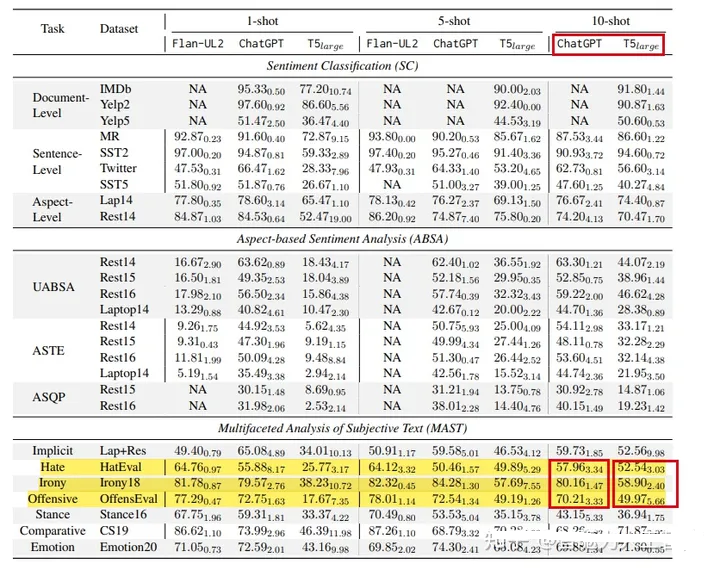
图11. LLM vs SLM
上图可以发现,LLM在仇恨、讽刺、攻击性言论检测任务上,其能力优于传统垂直领域的小模型(如情感分析模型、仇恨检测模型等)。

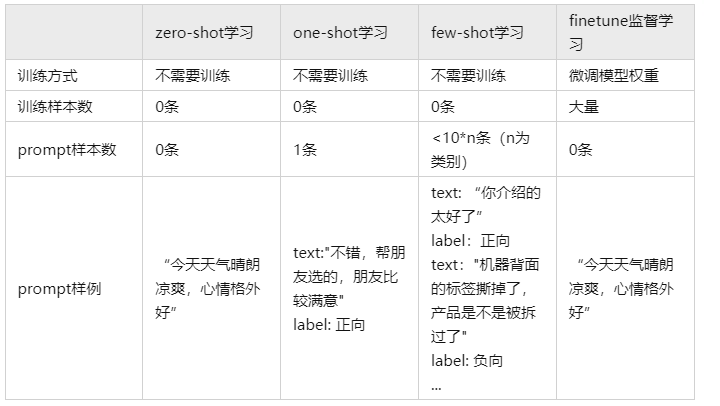
图12. prompt sample
上图为LLM情感分析与内容审核的prompt sample,通过合适的prompt指导LLM进行in-context
learning从而完成情感分类与内容审核任务。清晰、准确、可执行的、合理的prompt是决定模型准确输出的关键因素之一。
总结:LLM正在从新兴技术发展为主流技术,以LLM为核心的产品设计将迎来突破性发展。而这些产品设计的基础来源于LLM的核心能力。因此,在LLM产品设计时需做好领域需求与LLM能力的精准适配,开发创新性应用产品,在LLM能力范围内充分发挥其商业价值。
|







