| 编辑推荐: |
本文是文档加载器、嵌入向量、向量存储和提示模板技术应用的教程指南。希望对你的学习有帮助。
本文来自于知乎,由火龙果软件Linda编辑,推荐。 |
|
本文是文档加载器、嵌入向量、向量存储和提示模板技术应用的教程指南。
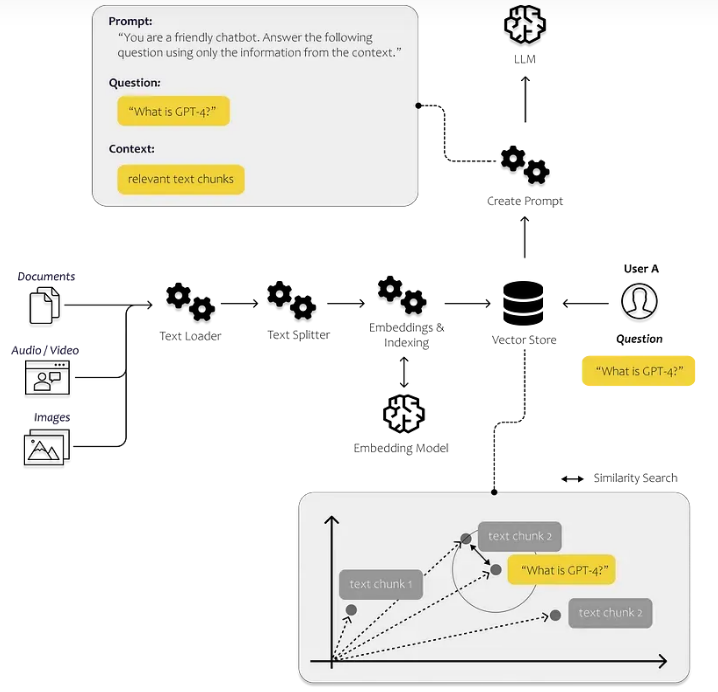
通过上下文注入构建一个聊天机器人
目录
如果您只是在寻找解释如何构建简单的 LLM 应用程序的简短教程,您可以跳至“6. 构建向量存储”,您将拥有构建带有向量存储、提示模板和
LLM 调用的简约 LLM 应用程序所需的所有代码片段。
介绍
为什么我们需要 LLM
Fine-Tuning vs. Context Injection
什么是 LangChain?
分步教程
1. 使用 LangChain 加载文档
2. 将文档拆分为文本块
3. 从文本块到嵌入向量
4. 定义要使用的 LLM
5. 定义提示模板
6. 构建向量存储

目录
为什么我们需要 LLM
语言的进化至今已经为人类带来了令人难以置信的进步。它使我们能够以我们今天所知的形式有效地共享知识和协作。因此,我们的大部分集体知识继续通过无组织的书面文本保存和传播。
过去二十年中为实现信息和流程数字化而采取的举措往往侧重于在关系数据库中积累越来越多的数据。这种方法使传统的分析机器学习算法能够处理和理解我们的数据。
然而,尽管我们付出了巨大的努力以结构化的方式存储越来越多的数据,但我们仍然无法捕获和处理我们的全部知识。
公司中大约 80% 的数据是非结构化的,例如工作描述、简历、电子邮件、文本文档、PowerPoint
幻灯片、录音、视频等 ……
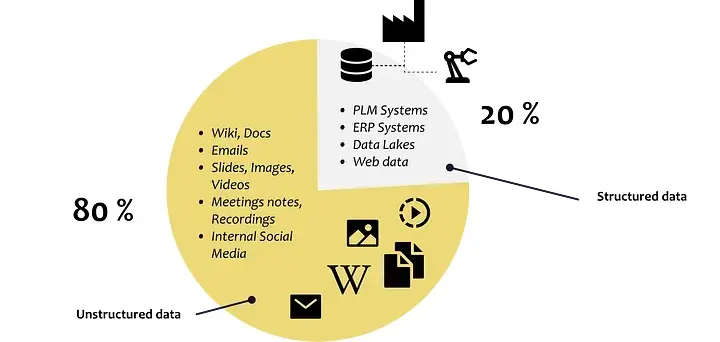
公司中数据的分布
GPT3.5 的开发和进步标志着一个重要的里程碑,因为它使我们能够有效地解释和分析不同的数据集,无论其结构或缺乏结构化。如今,我们拥有可以理解和生成各种形式内容的模型,包括文本、图像和音频文件。
那么我们如何利用他们的功能来满足我们的需求和数据呢?
微调与上下文注入(Fine-Tuning vs. Context Injection)
一般来说,我们有两种根本不同的方法来使大型语言模型能够回答LLM无法知道的问题:模型微调和上下文注入。
微调(Fine-Tuning)
微调是指使用额外的数据训练现有的语言模型,以针对特定任务对其进行优化。
不是从头开始训练语言模型,而是使用 BERT 或 LLama 等预训练模型,然后通过添加用例特定的训练数据来适应特定任务的需求。
斯坦福大学的一个团队使用了LLM Llama,并通过使用 50,000 个用户/模型交互的示例对其进行了微调。微调训练结果是一个与用户交互并回答查询的聊天机器人。这一微调步骤改变了模型与终端用户交互的方式。
→ 关于微调的误解
PLLMs(预训练语言模型)的微调是针对特定任务调整模型的一种方法,但它并不能真正允许您将自己的领域知识注入到模型中。这是因为模型已经接受了大量通用语言数据的训练,而您的特定领域数据通常不足以覆盖模型已经学到的内容。
因此,当您微调模型时,它偶尔可能会提供正确的答案,但通常会失败,因为它严重依赖于预训练期间学到的信息,而这些信息可能不准确或与您的特定任务不相关。换句话说,微调有助于模型适应其如何对话(HOW
it communicates),但不一定适应其对话内容(WHAT it communicates)。(Porsche
AG,2023 年)
这就是上下文注入发挥作用的地方。
上下文学习/上下文注入(In-context learning / Context Injection)
当使用上下文注入时,我们不会修改LLM,我们专注于提示本身并将相关上下文注入到提示中。
所以我们需要思考如何为提示提供正确的信息。在下图中,您可以示意性地看到整个过程是如何工作的。我们需要一个能够识别最相关数据的流程。为此,我们需要使计算机能够相互比较文本片段。
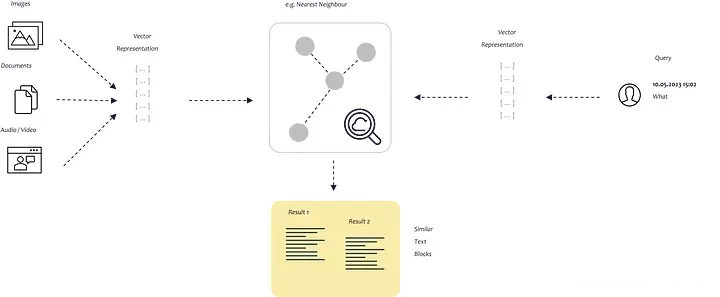
非结构化数据中的相似性搜索
这可以通过嵌入向量来完成。通过嵌入,我们将文本转换为向量,从而允许我们在多维嵌入空间中表示文本。空间上彼此距离较近的点通常用于相同的上下文中。为了防止这种相似性搜索永远持续下去,我们将向量存储在向量数据库中并为其建立索引。
微软向我们展示了如何将其与 Bing Chat 配合使用。Bing 将LLM理解语言和上下文的能力与传统网络搜索的效率结合起来。
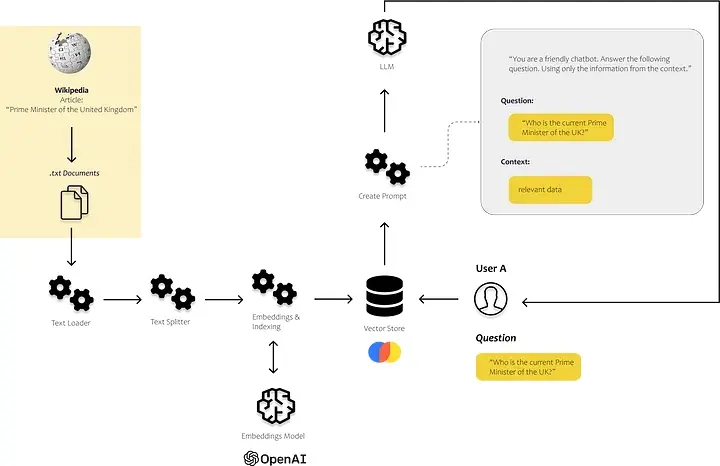
本文的目的是演示创建一个简单的解决方案的过程,该解决方案使我们能够分析我们自己的文本和文档,然后将从中获得的见解合并到我们的解决方案返回给用户的答案中。我将描述实施端到端解决方案所需的所有步骤和组件。
那么我们如何利用LLM的能力来满足我们的需求呢?让我们一步一步地看一下。
分步教程——您的第一个LLM应用
接下来,我们希望利用LLM回应有关我们个人数据的询问。为了实现这一目标,我首先将我们的个人数据内容传输到矢量数据库中。这一步至关重要,因为它使我们能够有效地搜索文本中的相关部分。我们将使用我们的数据中的信息和LLM的能力来解释文本以回答用户的问题。
我们还可以引导聊天机器人根据我们提供的数据专门回答问题。这样可以确保聊天机器人始终专注于手头的数据并提供准确且相关的响应。
为了实现我们的用例,我们将严重依赖 LangChain。
什么是 LangChain?
“LangChain 是一个用于开发由语言模型驱动的应用程序的框架。” (Langchain,2023)
因此,LangChain 是一个 Python 框架,旨在支持创建各种 LLM 应用程序,例如聊天机器人、摘要工具以及基本上任何您想要创建以利用
LLM 功能的工具。该库结合了我们需要的各种组件。我们可以将这些组件连接到所谓的链中。
Langchain最重要的模块是(Langchain,2023):
模型(Models):各种模型类型的接口
提示(Prompts):提示管理、提示优化、提示序列化
索引(Indexes):文档加载器、文本拆分器、矢量存储 — 实现更快、更高效地访问数据
链(Chains):链超越了单个 LLM 调用,允许我们设置调用序列
在下图中,您可以看到这些组件的作用。我们使用索引模块中的文档加载器和文本分割器加载和处理我们自己的非结构化数据。提示模块允许我们将找到的内容注入到我们的提示模板中,最后,我们使用模型的模块将提示发送到我们的模型。
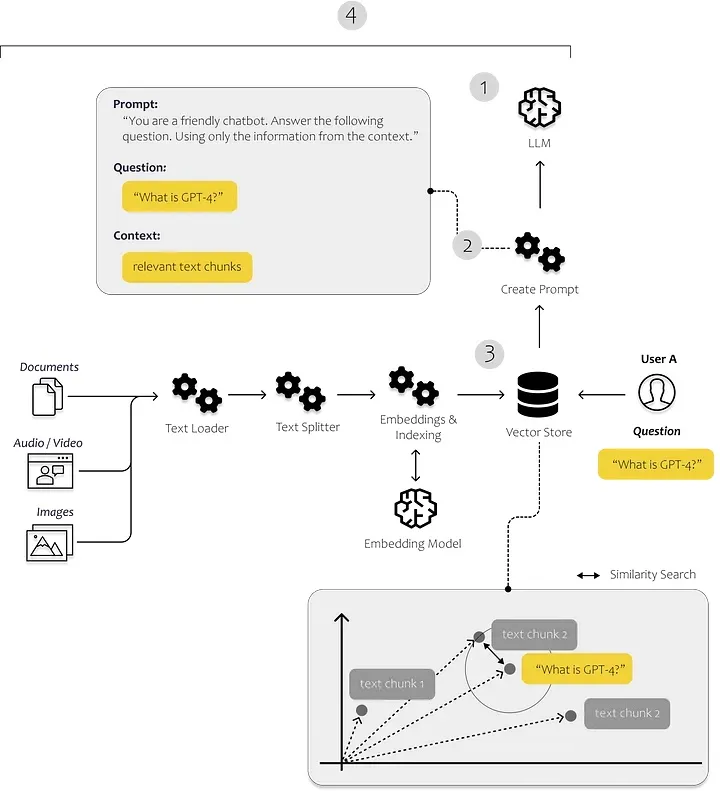
LLM 应用程序所需的组件
5. 代理人:代理人是使用LLM来选择要采取的行动的实体。采取行动后,他们观察该行动的结果并重复该过程,直到任务完成。
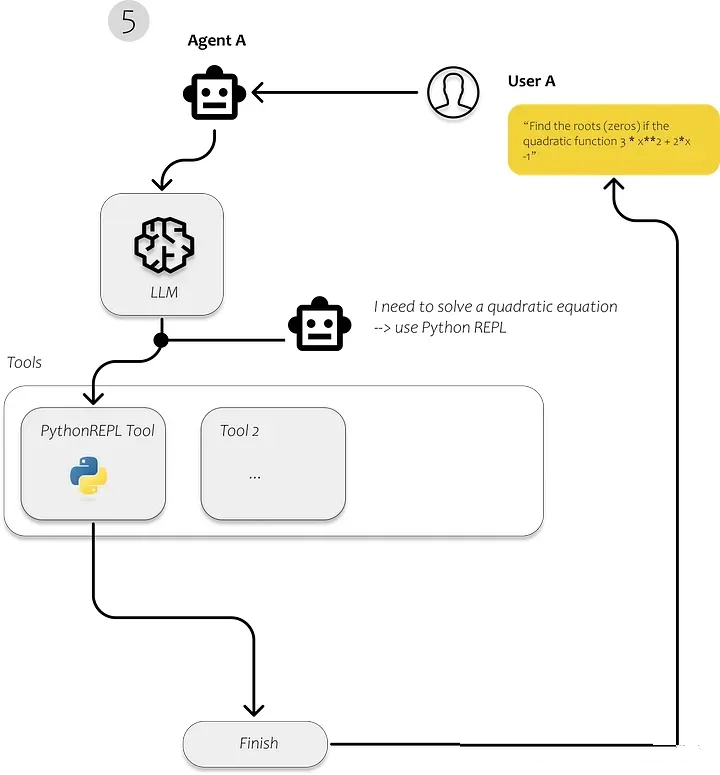
代理自主决定如何执行特定任务
我们在第一步中使用 Langchain 来加载文档、分析它们并使其可有效搜索。在我们对文本建立索引后,识别与回答用户问题相关的文本片段应该会变得更加有效。
我们简单的应用所需要的当然是LLM。我们将通过 OpenAI API 使用 GPT3.5。然后我们需要一个向量存储,允许我们向
LLM 提供我们自己的数据。如果我们想对不同的查询执行不同的操作,我们需要一个代理来决定每个查询应该发生什么。
让我们从头开始。我们首先需要导入我们自己的文档。
下面介绍 LangChain 的 Loader Module 包含哪些模块来从不同来源加载不同类型的文档。
1.使用Langchain加载文档
LangChain能够从各种来源加载大量文档。您可以在 LangChain文档中找到可能的文档加载器列表。其中包括
HTML 页面、S3 存储桶、PDF、Notion、Google Drive 等的加载器。
对于我们的简单示例,我们使用的数据可能未包含在 GPT3.5 的训练数据中。我使用有关 GPT4
的维基百科文章,因为我认为 GPT3.5 对 GPT4 的了解有限。
对于这个最小的例子,我没有使用任何 LangChain 加载器,我只是使用BeautifulSoup直接从维基百科
[许可证:CC BY-SA 3.0] 抓取文本。
请注意,抓取网站只能根据网站的使用条款以及您希望使用的文本和数据的版权/许可状态进行。
import requests
from bs4 import BeautifulSoup
url = "https://en.wikipedia.org/wiki/GPT-4"
response = requests.get(url)
soup = BeautifulSoup(response.content, 'html.parser')
# find all the text on the page
text = soup.get_text()
# find the content div
content_div = soup.find('div', {'class': 'mw-parser-output'})
# remove unwanted elements from div
unwanted_tags = ['sup', 'span', 'table', 'ul', 'ol']
for tag in unwanted_tags:
for match in content_div.findAll(tag):
match.extract()
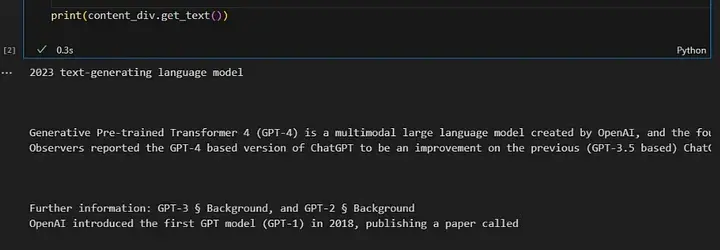
print(content_div.get_text())
|
2. 将文档分割成文本片段
接下来,需要将文本分成更小的部分,称为文本块。每个文本块代表嵌入空间中的一个数据点,允许计算机确定这些块之间的相似性。
以下文本片段利用了 langchain 的文本分割器模块。在这种特殊情况下,我们指定块大小为 100,块重叠为
20。通常使用较大的文本块,但您可以进行一些试验来找到适合您的用例的最佳大小。您只需要记住,每个 LLM
都有token限制(GPT 3.5 为 4000 个token)。由于我们要将文本块插入提示中,因此需要确保整个提示不超过
4000 个token。
from langchain.text_splitter import RecursiveCharacterTextSplitter
article_text = content_div.get_text()
text_splitter = RecursiveCharacterTextSplitter(
# Set a really small chunk size, just to show.
chunk_size = 100,
chunk_overlap = 20,
length_function = len,
)
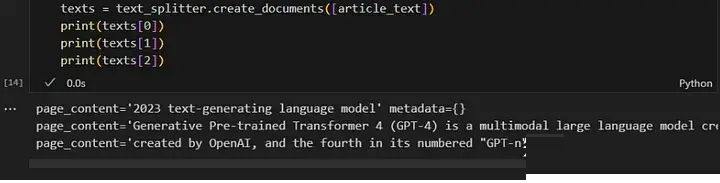
texts = text_splitter.create_documents([article_text])
print(texts[0])
print(texts[1])
|
这将我们的整个文本分割如下:

Langchain 文本分割器
3.从文本块到嵌入向量
现在我们需要使文本组件易于理解并可用算法进行比较。需要找到一种方法将人类语言转换为以位和字节表示的数字形式。
该图像提供了一个对大多数人来说似乎显而易见的简单示例。然而,我们需要找到一种方法让计算机理解“查尔斯”这个名字与男性而不是女性相关,如果查尔斯是男性,他就是国王而不是王后。
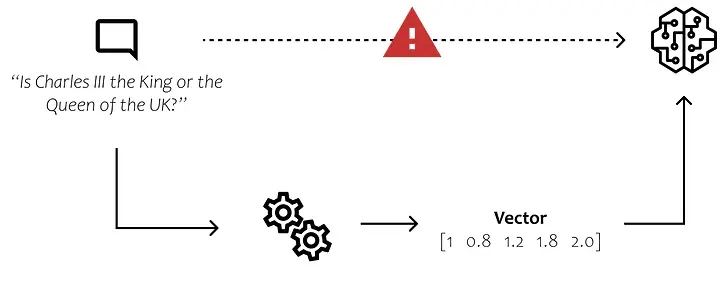
让计算机能够理解语言
在过去的几年里,出现了可以做到这一点的新方法和模型。我们想要的是一种能够将单词的含义转换为 n 维空间的方法,这样我们就能够相互比较文本块,甚至计算它们相似性的度量。
嵌入模型试图通过分析单词通常使用的上下文来准确地学习这一点。由于茶、咖啡和早餐经常在相同的上下文中使用,因此它们在
n 维空间中比茶和豌豆等彼此更接近。茶和豌豆听起来很相似,但很少一起使用。(AssemblyAI,2022)
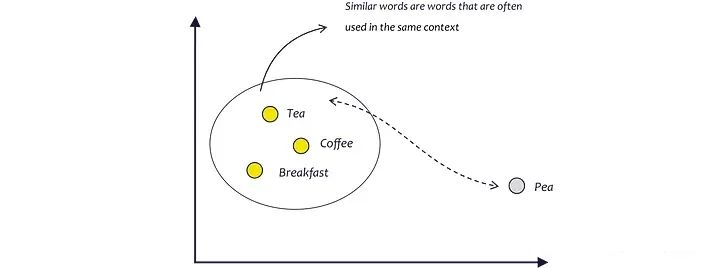
嵌入分析单词使用的上下文,而不是单词本身
嵌入模型为我们提供了嵌入空间中每个单词的向量。最后,通过使用向量表示它们,我们能够执行数学计算,例如计算单词之间的相似度作为数据点之间的距离。
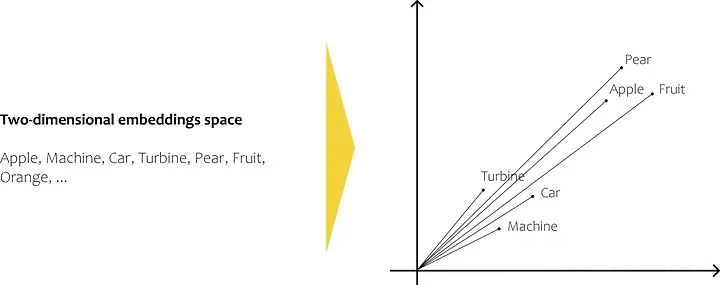
二维嵌入空间中的随机英语单词
要将文本转换为嵌入,有多种方法,例如 Word2Vec、GloVe、fastText 或 ELMo。
嵌入模型(Embedding Models)
为了捕获嵌入中单词之间的相似性,Word2Vec 使用简单的神经网络。我们用大量文本数据训练这个模型,并希望创建一个能够将
n 维嵌入空间中的点分配给每个单词的模型,从而以向量的形式描述其含义。
对于训练,我们将输入层中的神经元分配给数据集中的每个唯一单词。在下图中,您可以看到一个简单的示例。在这种情况下,隐藏层仅包含两个神经元。第二,因为我们想要将单词映射到二维嵌入空间中。(现有模型实际上要大得多,因此表示更高维度空间中的单词
- 例如 OpenAI 的 Ada 嵌入模型,使用 1536 个维度)训练过程结束后,各个权重描述了嵌入空间中的位置。
在这个例子中,我们的数据集由一个句子组成:“Google is a tech company.”
句子中的每个单词都充当神经网络 (NN) 的输入。因此,我们的网络有五个输入神经元,每个单词一个。
在训练过程中,我们专注于预测每个输入单词的下一个单词。当我们从句子开头开始时,与单词“Google”对应的输入神经元接收值
1,而其余神经元接收值 0。我们的目标是训练网络来预测单词“is”这个特定的场景。
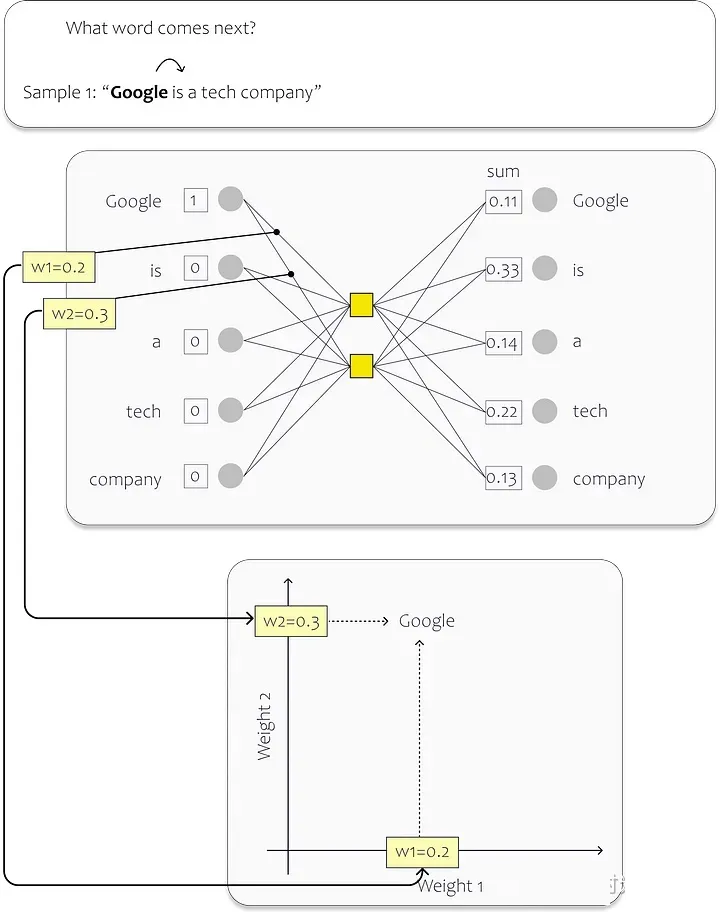
Word2Vec:学习词嵌入
实际上,学习嵌入模型的方法有多种,每种方法都有自己独特的方式来预测训练过程中的输出。两种常用的方法是CBOW(连续词袋)和Skip-gram。
在 CBOW 中,我们将周围的单词作为输入,旨在预测中间的单词。相反,在 Skip-gram 中,我们将中间的单词作为输入,并尝试预测出现在其左侧和右侧的单词。不过,我不会深入研究这些方法的复杂性。可以说,这些方法为我们提供了嵌入向量,它们是通过分析大量文本数据的上下文来捕获单词之间关系的表示。
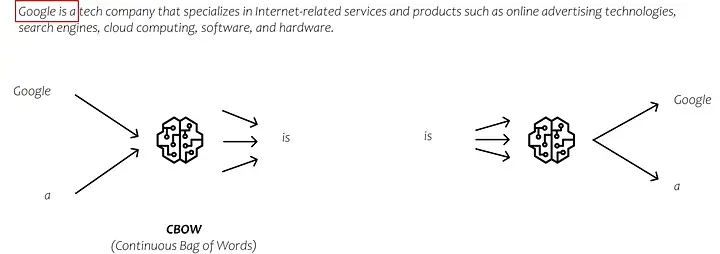
CBOW 与 Skip-gram
如果您想了解有关嵌入向量的更多信息,互联网上有大量信息。但是,如果您更喜欢直观的分步指南,您可能会发现观看
Josh Starmer 的 StatQuest on Word Embedding 和 Word2Vec很有帮助。
回到嵌入模型
我刚刚尝试使用二维嵌入空间中的简单示例来解释的内容也适用于更大的模型。例如,标准 Word2Vec
向量有 300 维,而 OpenAI 的 Ada 模型有 1536 维。这些预先训练的向量使我们能够精确地捕获单词及其含义之间的关系,以便我们可以用它们进行计算。例如,使用这些向量,我们可以发现法国+柏林-德国=巴黎,并且更快+温暖-快速=更温暖。(塔兹曼,ND)
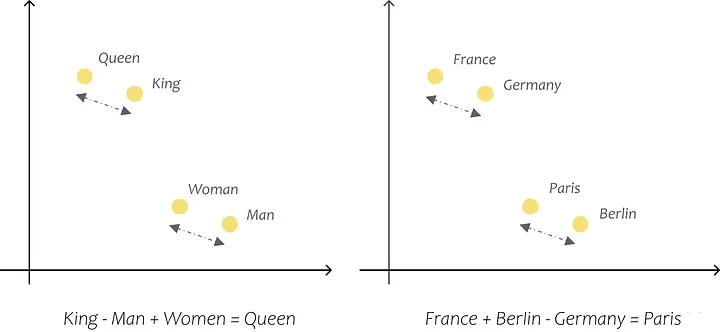
使用嵌入向量进行计算
在下文中,我们不仅要使用 OpenAI API 来使用 OpenAI 的 LLM,还要利用其嵌入模型。
注意:嵌入模型和LLM之间的区别在于,嵌入模型专注于创建单词或短语的向量表示以捕获它们的含义和关系,而LLM是经过训练的多功能模型,可根据提供的提示或查询生成连贯且上下文相关的文本。
OpenAI 嵌入模型
与 OpenAI 的各种 LLM 类似,您也可以在各种嵌入模型之间进行选择,例如 Ada、Davinci、Curie
和 Babbage。其中,Ada-002是目前速度最快、性价比最高的模型,而达芬奇一般提供最高的精度和性能。但是,您需要亲自尝试并找到适合您的用例的最佳模型。如果您有兴趣详细了解
OpenAI Embeddings,可以参考OpenAI 文档。
我们嵌入模型的目标是将文本块转换为向量。对于第二代 Ada,这些向量具有 1536 个输出维度,这意味着它们表示
1536 维空间内的特定位置或方向。
OpenAI 在其文档中对这些嵌入向量的描述如下:
“数字上相似的嵌入向量在语义上也相似。例如,“canine companies say”的嵌入向量将更类似于“woof”的嵌入向量,而不是“meow”的嵌入向量。(OpenAI,2022)
试一试吧。我们使用 OpenAI 的 API 将文本片段转换为嵌入,如下所示:
import openai
print(texts[0])
embedding = openai.Embedding.create(
input=texts[0].page_content, model="text-embedding-ada-002"
)["data"][0]["embedding"]
len(embedding)
|
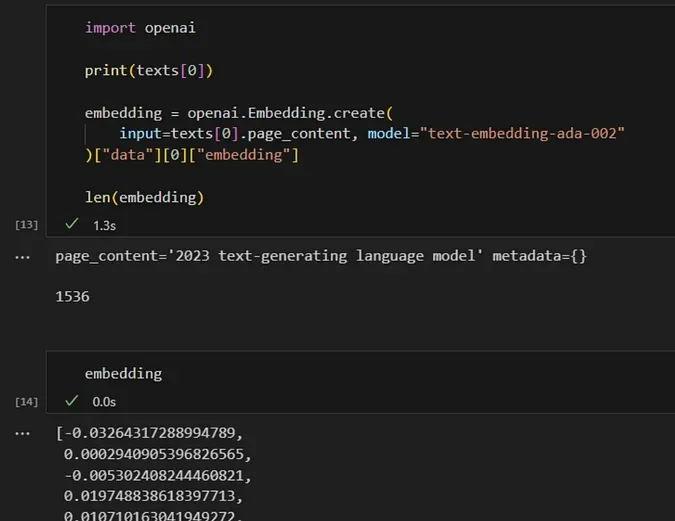
我们将文本(例如包含“2023 text-generating language model”的第一个文本块)转换为
1536 维的向量。通过对每个文本块执行此操作,我们可以在 1536 维空间中观察哪些文本块彼此更接近且更相似。
试一试吧。我们的目标是通过生成问题的嵌入向量,然后将其与空间中的其他数据点进行比较,将用户的问题与文本块进行比较。

哪个文本片段在语义上更接近用户的问题?
当我们将文本块和用户的问题表示为向量时,就获得了探索各种数学运算可能性的能力。为了确定两个数据点之间的相似性,需要计算它们在多维空间中的接近度,这是使用距离度量来实现的。有多种方法可用于计算点之间的距离。Maarten
Grootendorst 在他的一篇 Medium 帖子中总结了其中的九个。
常用的距离度量是余弦相似度。因此,让我们尝试计算问题和文本块之间的余弦相似度:
import numpy as np
from numpy.linalg import norm
from langchain.text_splitter import RecursiveCharacterTextSplitter
import requests
from bs4 import BeautifulSoup
import pandas as pd
import openai
####################################################################
# load documents
####################################################################
# URL of the Wikipedia page to scrape
url = 'https://en.wikipedia.org/wiki/Prime_Minister_of_the_United_Kingdom'
# Send a GET request to the URL
response = requests.get(url)
# Parse the HTML content using BeautifulSoup
soup = BeautifulSoup(response.content, 'html.parser')
# Find all the text on the page
text = soup.get_text()
####################################################################
# split text
####################################################################
text_splitter = RecursiveCharacterTextSplitter(
# Set a really small chunk size, just to show.
chunk_size = 100,
chunk_overlap = 20,
length_function = len,
)
texts = text_splitter.create_documents([text])
####################################################################
# calculate embeddings
####################################################################
# create new list with all text chunks
text_chunks=[]
for text in texts:
text_chunks.append(text.page_content)
df = pd.DataFrame({'text_chunks': text_chunks})
####################################################################
# get embeddings from text-embedding-ada model
####################################################################
def get_embedding(text, model="text-embedding-ada-002"):
text = text.replace("\n", " ")
return openai.Embedding.create(input = [text], model=model)['data'][0]['embedding']
df['ada_embedding'] = df.text_chunks.apply(lambda x: get_embedding(x, model='text-embedding-ada-002'))
####################################################################
# calculate the embeddings for the user's question
####################################################################
users_question = "What is GPT-4?"
question_embedding = get_embedding(text=users_question, model="text-embedding-ada-002")
# create a list to store the calculated cosine similarity
cos_sim = []
for index, row in df.iterrows():
A = row.ada_embedding
B = question_embedding
# calculate the cosine similarity
cosine = np.dot(A,B)/(norm(A)*norm(B))
cos_sim.append(cosine)
df["cos_sim"] = cos_sim
df.sort_values(by=["cos_sim"], ascending=False)
|
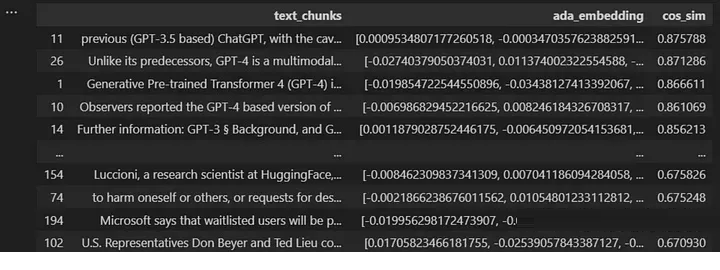
现在,我们可以选择要提供给LLM的文本块数量,以回答问题。
下一步是确定我们想要使用哪个LLM。
4. 定义您要使用的模型
Langchain提供了多种模型和集成,包括OpenAI的GPT和Huggingface等。如果我们决定使用
OpenAI 的 GPT 作为我们的大型语言模型,第一步就是定义我们的 API 密钥。目前,OpenAI
提供了一些免费使用容量,但是一旦我们每月超过一定数量的token,我们就需要切换到付费帐户。
如果我们使用 GPT 来回答类似于如何使用 Google 的简短问题,成本仍然相对较低。然而,如果我们使用
GPT 来回答需要提供广泛上下文的问题,例如个人数据,则查询可以快速积累数千个token。这大大增加了成本。但不用担心,您可以设置成本限制。
什么是token?
简单来说,一个token基本上是一个单词或一组单词。然而,在英语中,单词可以有不同的形式,例如动词时态、复数或复合词。为了解决这个问题,我们可以使用子词标记化,它将一个单词分解成更小的部分,比如它的词根、前缀、后缀和其他语言元素。例如,单词“tiresome”可以分为“tire”和“some”,而“tired”可以分为“tire”和“d”。如此一来,我们就可以认识到“tiresome”和“tired”同根同源,有相似的派生关系。(Wang,2023)
OpenAI 在其网站上提供了一个token生成器,以了解token是什么。根据 OpenAI 的说法,对于常见的英语文本,一个token通常对应于约
4 个字符的文本。这相当于大约 3/4 个单词(因此 100 个标记 ~= 75 个单词)。您可以在
OpenAI 网站上找到一个Tokenizer 应用程序,它可以让您了解什么才是真正的token。
设置使用限制
如果您担心费用,您可以在 OpenAI 用户门户中找到一个选项来限制每月费用。
您可以在 OpenAI 的用户帐户中找到 API 密钥。最简单的方法是在 Google 中搜索“OpenAI
API 密钥”。这将直接带您进入设置页面,以创建新密钥。
要在 Python 中使用,您必须将密钥保存为名称为“OPENAI_API_KEY”的新环境变量:
import os
os.environment[ "OPENAI_API_KEY" ] = "testapikey213412"
|
import os
os.environment[ "OPENAI_API_KEY" ] = "testapikey213412"
定义模型时,您可以设置一些首选项。OpenAI Playground使您可以在决定要使用哪些设置之前尝试一下不同的参数:
在 Playground WebUI 的右侧,您会发现 OpenAI 提供的几个参数,使我们能够影响
LLM 的输出。值得探索的两个参数是模型选择和温度。
您可以从各种不同的型号中进行选择。Text-davinci-003模型是目前最大、最强大的。另一方面,像
Text-ada-001 这样的型号更小、更快、更具成本效益。
下面,您可以看到OpenAI 定价列表的摘要。与最强大的模型 Davinci 相比,Ada 更便宜。因此,如果
Ada 的性能满足我们的需求,我们不仅可以节省资金,还可以实现更短的响应时间。
您可以从使用 Davinci 开始,然后评估我们是否也可以使用 Ada 获得足够好的结果。
那么让我们在 Jupyter Notebook 中尝试一下。我们正在使用 langchain 连接到
GPT。
from langchain.llms import OpenAI
llm = OpenAI(temperature=0.7)
|
如果您想查看包含所有属性的列表,请使用 __dict__:
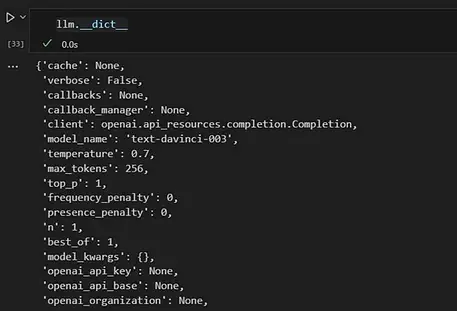
如果我们不指定特定模型,langchain 连接器默认使用“text-davinci-003”。
现在,我们可以直接在Python中调用该模型。只需调用 LLM 函数并提供提示作为输入即可。
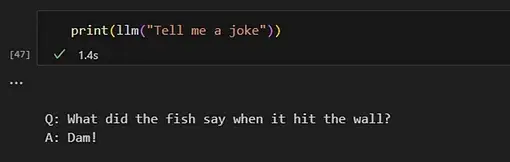
您现在可以向 GPT 询问任何有关人类常识的问题。
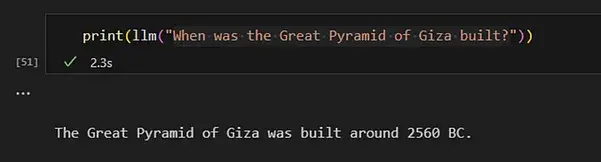
对于那些在训练数据中未包含的主题(topic),GPT 只能提供这些相关主题的有限信息。这包括未公开的具体细节或上次更新训练数据后发生的事件。
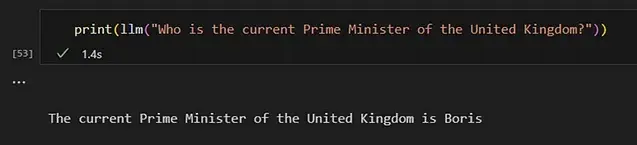
那么,我们如何确保模型能够回答有关时事的问题?
正如前面提到的,有一种方法可以做到这一点。我们需要在提示中为模型提供必要的信息。
为了回答有关英国现任首相的问题,我向提示提供了维基百科文章“英国首相”中的信息。总结一下这个过程,我们是:
加载文章
将文本拆分为文本块
计算文本块的嵌入向量
计算所有文本块与用户问题之间的相似度
import requests
from bs4 import BeautifulSoup
from langchain.text_splitter import RecursiveCharacterTextSplitter
import numpy as np
from numpy.linalg import norm
import pandas as pd
import openai
####################################################################
# load documents
####################################################################
# URL of the Wikipedia page to scrape
url = 'https://en.wikipedia.org/wiki/Prime_Minister_of_the_United_Kingdom'
# Send a GET request to the URL
response = requests.get(url)
# Parse the HTML content using BeautifulSoup
soup = BeautifulSoup(response.content, 'html.parser')
# Find all the text on the page
text = soup.get_text()
####################################################################
# split text
####################################################################
text_splitter = RecursiveCharacterTextSplitter(
# Set a really small chunk size, just to show.
chunk_size = 100,
chunk_overlap = 20,
length_function = len,
)
texts = text_splitter.create_documents([text])
####################################################################
# calculate embeddings
####################################################################
# create new list with all text chunks
text_chunks=[]
for text in texts:
text_chunks.append(text.page_content)
df = pd.DataFrame({'text_chunks': text_chunks})
# get embeddings from text-embedding-ada model
def get_embedding(text, model="text-embedding-ada-002"):
text = text.replace("\n", " ")
return openai.Embedding.create(input = [text], model=model)['data'][0]['embedding']
df['ada_embedding'] = df.text_chunks.apply(lambda x: get_embedding(x, model='text-embedding-ada-002'))
####################################################################
# calculate similarities to the user's question
####################################################################
# calcuate the embeddings for the user's question
users_question = "Who is the current Prime Minister of the UK?"
question_embedding = get_embedding(text=users_question, model="text-embedding-ada-002")
|
现在我们尝试找到与用户问题最相似的文本块:
from langchain import PromptTemplate
from langchain.llms import OpenAI
# calcuate the embeddings for the user's question
users_question = "Who is the current Prime Minister of the UK?"
question_embedding = get_embedding(text=users_question, model="text-embedding-ada-002")
# create a list to store the calculated cosine similarity
cos_sim = []
for index, row in df.iterrows():
A = row.ada_embedding
B = question_embedding
# calculate the cosine similiarity
cosine = np.dot(A,B)/(norm(A)*norm(B))
cos_sim.append(cosine)
df["cos_sim"] = cos_sim
df.sort_values(by=["cos_sim"], ascending=False)
|
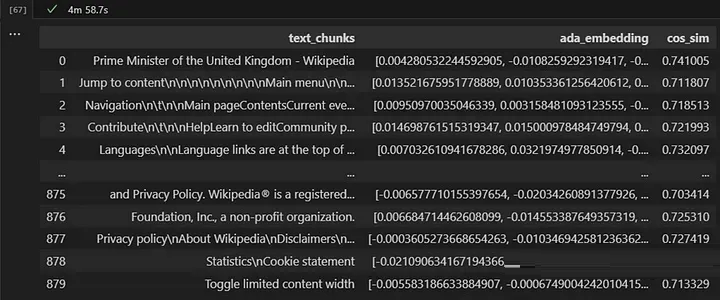
文本块看起来相当混乱,但让我们尝试一下看看 GPT 是否足够聪明来处理它。
现在我们已经确定了可能包含相关信息的文本片段,我们可以测试我们的模型是否能够回答问题。为了实现这一目标,我们必须以一种能够清楚地向模型传达我们期望的任务的方式构建我们的提示。
5. 定义我们的提示词模板( Prompt Template)
现在我们有了包含我们正在查找的信息的文本片段,我们需要构建一个提示。在提示中,我们还指定模型回答问题所需的模式。当我们定义模式时,我们指定了我们希望
LLM 生成答案的所遵循的行为风格。
LLM 可用于各种任务,以下是各种可能性的一些示例:
总结(Summarization): “将以下文本总结为 3 段,供高管使用:[TEXT]
知识提取(Knowledge extraction): “根据这篇文章:[TEXT],人们在购房之前应该考虑什么?”
编写内容(例如邮件、消息、代码)(Writing content):给 Jane 写一封电子邮件,要求更新我们项目的文档。使用非正式、友好的语气。”
语法和风格改进(Grammar and style improvements): “将其更正为标准英语并将语气更改为更友好的语气:[TEXT]
分类(Classification): “将每条消息分类为一种支持票证类型:[TEXT]”
对于我们的示例,我们希望实现一个从维基百科提取数据并像聊天机器人一样与用户交互的解决方案。我们希望它像积极主动、乐于助人的服务台专家一样回答问题。
为了引导 LLM 朝正确的方向发展,我在提示中添加以下说明:
“你是一个喜欢帮助别人的聊天机器人!仅使用所提供的上下文回答以下问题。如果您不确定并且上下文中没有明确答案,请说“抱歉,我不知道如何帮助您。”
通过这样做,我设置了一个限制,只允许 GPT 使用存储在我们数据库中的信息。这一限制使我们能够提供聊天机器人生成响应所依赖的来源,这对于可追溯性和建立信任至关重要。此外,它还帮助我们解决生成不可靠信息的问题,并使我们能够提供可在企业环境中用于决策目的的答案。
作为上下文,我只是使用与问题相似度最高的前 50 个文本块。文本块大一些可能会更好,因为我们通常会用一两个文本段落来回答大多数问题。但我将让您自行确定最适合您的用例的尺寸。
from langchain import PromptTemplate
from langchain.llms import OpenAI
import openai
import requests
from bs4 import BeautifulSoup
from langchain.text_splitter import RecursiveCharacterTextSplitter
import numpy as np
from numpy.linalg import norm
import pandas as pd
import openai
####################################################################
# load documents
####################################################################
# URL of the Wikipedia page to scrape
url = 'https://en.wikipedia.org/wiki/Prime_Minister_of_the_United_Kingdom'
# Send a GET request to the URL
response = requests.get(url)
# Parse the HTML content using BeautifulSoup
soup = BeautifulSoup(response.content, 'html.parser')
# Find all the text on the page
text = soup.get_text()
####################################################################
# split text
####################################################################
text_splitter = RecursiveCharacterTextSplitter(
# Set a really small chunk size, just to show.
chunk_size = 100,
chunk_overlap = 20,
length_function = len,
)
texts = text_splitter.create_documents([text])
####################################################################
# calculate embeddings
####################################################################
# create new list with all text chunks
text_chunks=[]
for text in texts:
text_chunks.append(text.page_content)
df = pd.DataFrame({'text_chunks': text_chunks})
# get embeddings from text-embedding-ada model
def get_embedding(text, model="text-embedding-ada-002"):
text = text.replace("\n", " ")
return openai.Embedding.create(input = [text], model=model)['data'][0]['embedding']
df['ada_embedding'] = df.text_chunks.apply(lambda x: get_embedding(x, model='text-embedding-ada-002'))
####################################################################
# calculate similarities to the user's question
####################################################################
# calcuate the embeddings for the user's question
users_question = "Who is the current Prime Minister of the UK?"
question_embedding = get_embedding(text=users_question, model="text-embedding-ada-002")
# create a list to store the calculated cosine similarity
cos_sim = []
for index, row in df.iterrows():
A = row.ada_embedding
B = question_embedding
# calculate the cosine similiarity
cosine = np.dot(A,B)/(norm(A)*norm(B))
cos_sim.append(cosine)
df["cos_sim"] = cos_sim
df.sort_values(by=["cos_sim"], ascending=False)
####################################################################
# build a suitable prompt and send it
####################################################################
# define the LLM you want to use
llm = OpenAI(temperature=1)
# define the context for the prompt by joining the most relevant text chunks
context = ""
for index, row in df[0:50].iterrows():
context = context + " " + row.text_chunks
# define the prompt template
template = """
You are a chat bot who loves to help people! Given the following context sections, answer the
question using only the given context. If you are unsure and the answer is not
explicitly writting in the documentation, say "Sorry, I don't know how to help with that."
Context sections:
{context}
Question:
{users_question}
Answer:
"""
prompt = PromptTemplate(template=template, input_variables=["context", "users_question"])
# fill the prompt template
prompt_text = prompt.format(context = context, users_question = users_question)
llm(prompt_text)
|
通过使用该特定模板,我将上下文和用户的问题合并到我们的提示中。结果响应如下:

令人惊讶的是,即使是这个简单的实现似乎也产生了一些令人满意的结果。让我们继续向系统询问一些有关英国首相的问题。我将保持一切不变,仅替换用户的问题:
users_question = "Who was the first Prime Minister of the UK?"
|

它似乎在某种程度上发挥了作用。然而,我们现在的目标是将这一缓慢的过程转变为稳健且高效的过程。为了实现这一目标,我们引入了一个索引步骤,将嵌入和索引存储在向量存储中。这将提高整体性能并减少响应时间。
6. 构建向量存储(向量数据库)
向量存储是一种数据存储类型,针对存储和检索可表示为向量的大量数据进行了优化。这些类型的数据库允许基于各种标准(例如相似性度量或其他数学运算)有效地查询和检索数据子集。
将我们的文本数据转换为向量是第一步,但这还不足以满足我们的需求。如果我们将向量存储在数据框中,并在每次收到查询时逐步搜索单词之间的相似性,那么整个过程将非常慢。
为了有效地搜索嵌入,我们需要对它们建立索引。索引是向量数据库的第二个重要组成部分。索引提供了一种将查询映射到向量存储中最相关的文档或项目的方法,而无需计算每个查询和每个文档之间的相似性。
近年来,已经发布了许多向量商店。尤其是在LLM领域,向量存储的关注度呈爆炸式增长:
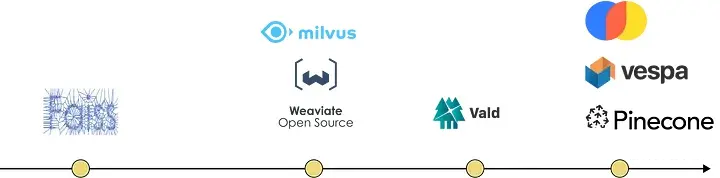
过去几年发布矢量商店
现在让我们选择一个并在我们的用例中尝试一下。与我们在前面几节中所做的类似,我们再次计算嵌入向量并将它们存储在向量存储中。为此,我们使用
LangChain 和 chroma 中的合适模块作为向量存储。
收集我们想要用来回答用户问题的数据:
import requests
from bs4 import BeautifulSoup
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.text_splitter import CharacterTextSplitter
from langchain.vectorstores import Chroma
from langchain.document_loaders import TextLoader
# URL of the Wikipedia page to scrape
url = 'https://en.wikipedia.org/wiki/Prime_Minister_of_the_United_Kingdom'
# Send a GET request to the URL
response = requests.get(url)
# Parse the HTML content using BeautifulSoup
soup = BeautifulSoup(response.content, 'html.parser')
# Find all the text on the page
text = soup.get_text()
text = text.replace('\n', '')
# Open a new file called 'output.txt' in write mode and store the file object in a variable
with open('output.txt', 'w', encoding='utf-8') as file:
# Write the string to the file
file.write(text)
|
2. 加载数据并定义如何将数据拆分为文本块
from langchain.text_splitter import RecursiveCharacterTextSplitter
# load the document
with open('./output.txt', encoding='utf-8') as f:
text = f.read()
# define the text splitter
text_splitter = RecursiveCharacterTextSplitter(
chunk_size = 500,
chunk_overlap = 100,
length_function = len,
)
texts = text_splitter.create_documents([text])
|
3. 定义要用于计算文本块嵌入的嵌入模型并将其存储在向量存储中(此处:Chroma)
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.vectorstores import Chroma
# define the embeddings model
embeddings = OpenAIEmbeddings()
# use the text chunks and the embeddings model to fill our vector store
db = Chroma.from_documents(texts, embeddings)
|
4. 计算用户问题的嵌入向量,在向量存储中找到相似的文本块并使用它们来构建我们的提示
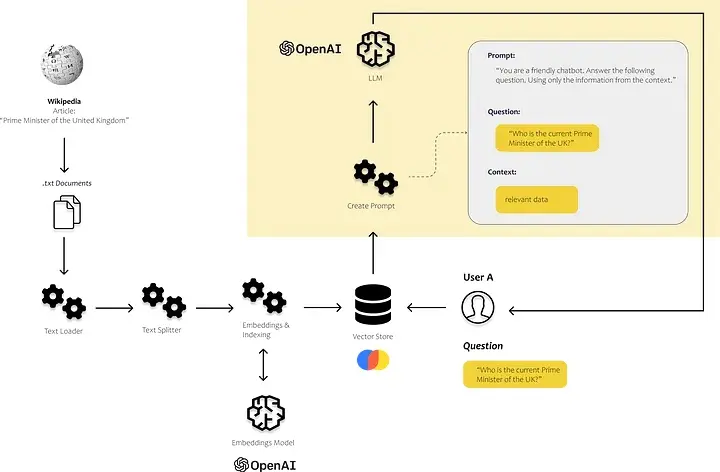
from langchain.llms import OpenAI
from langchain import PromptTemplate
users_question = "Who is the current Prime Minister of the UK?"
# use our vector store to find similar text chunks
results = db.similarity_search(
query=user_question,
n_results=5
)
# define the prompt template
template = """
You are a chat bot who loves to help people! Given the following context sections, answer the
question using only the given context. If you are unsure and the answer is not
explicitly writting in the documentation, say "Sorry, I don't know how to help with that."
Context sections:
{context}
Question:
{users_question}
Answer:
"""
prompt = PromptTemplate(template=template, input_variables=["context", "users_question"])
# fill the prompt template
prompt_text = prompt.format(context = results, users_question = users_question)
# ask the defined LLM
llm(prompt_text)
|

总结
为了使LLM能够分析和回答有关我们数据的问题,我们通常不会对模型进行微调。相反,在微调过程中,目标是提高模型有效响应特定任务的能力,而不是教给它新信息。
就 Alpaca 7B 而言,LLM (LLaMA) 经过微调,可以像聊天机器人一样进行行为和交互。重点是完善模型的响应,而不是教授它全新的信息。
因此,为了能够回答有关我们自己的数据的问题,我们使用上下文注入方法。使用上下文注入创建 LLM 应用程序是一个相对简单的过程。主要挑战在于组织和格式化要存储在向量数据库中的数据。此步骤对于有效检索上下文相似信息并确保结果可靠至关重要。
本文的目标是演示使用嵌入模型、向量存储和 LLM 处理用户查询的极简方法。它展示了这些技术如何协同工作,提供相关且准确的答案,甚至针对不断变化的事实。
|








