| 编辑推荐: |
本文主要介绍了盘古大模型的微调实践,这里的大模型主要是指自然语言大模型。希望对你的学习有帮助。
本文来自于微信公众号DataFunSummit,由火龙果软件Linda编辑,推荐。 |
|
导读 本次分享的主题是盘古大模型的微调实践,这里的大模型主要是指自然语言大模型。华为文本机器翻译实验室是一个既做学术创新,又做产品落地的部门,主要工作为大模型机器翻译、语音识别相关的产品落地,也曾在
ACL、EMNLP 等会议发表论文,并在国内外一些 NLP 相关比赛中取得优异成绩。
01 什么是大模型
首先来介绍一下什么是大模型,主要从四个方面来衡量。
首先是参数规模。大模型通常是指参数量在亿级到万亿级,以及更大参数规模的模型,比如 GPT-3 的参数量就达到了
1750 亿,华为盘古 Sigma 大模型最大一个型号的参数量已经达到了 1 万亿的规模。

第二,从模型架构来看,Transformer 架构是参数量在100 亿以上的大模型的基本框架,其中
decoder only 的 transformer 架构是目前大模型的一个主流技术路线,其结构主要是下图左边框出来的两部分,即除了输入输出以外,其中间每一层都是由一个掩码多头注意力层加上一个前馈网络层组成的。
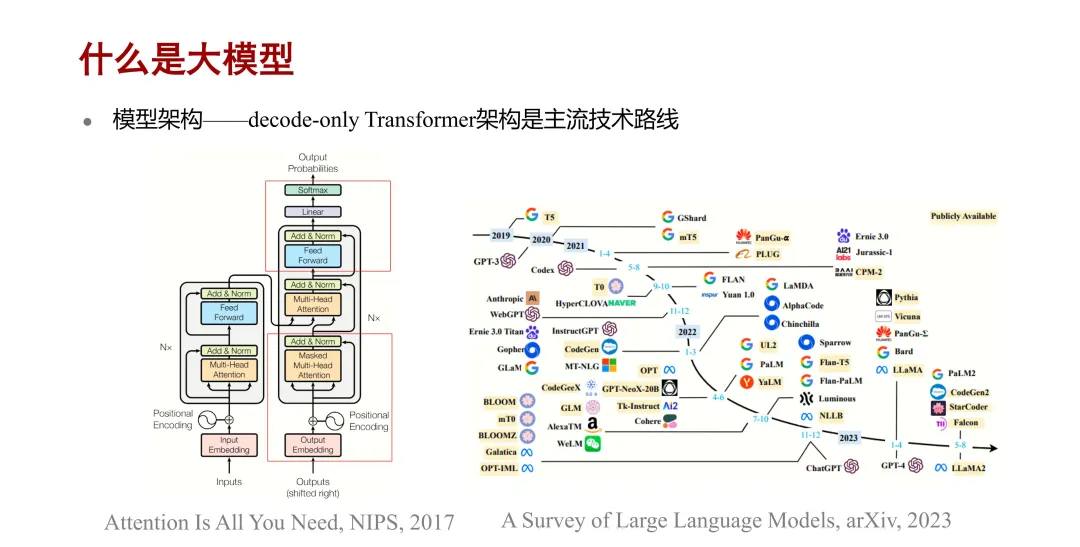
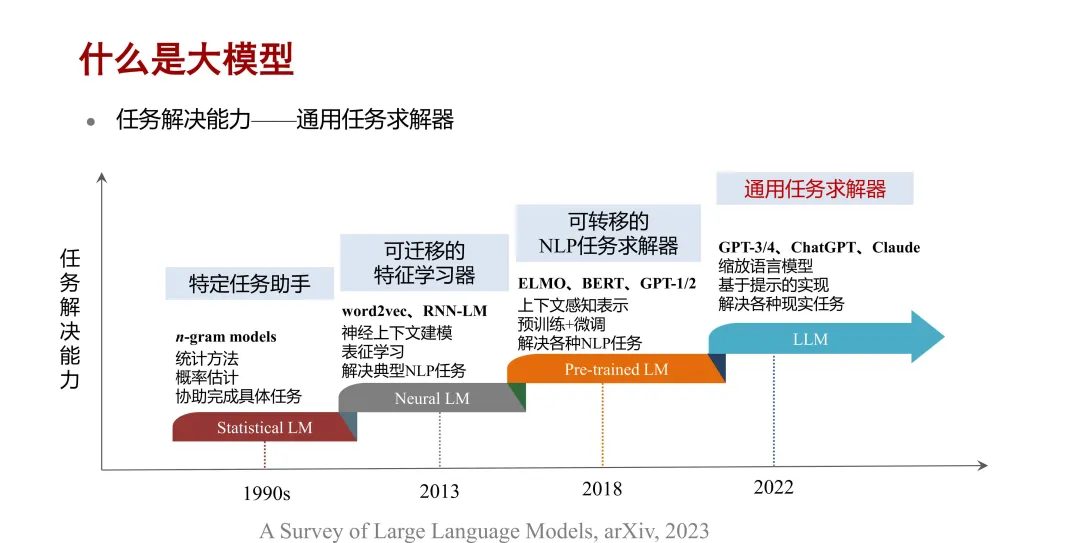
第三,从任务解决能力方面看,大语言模型是从统计语言模型发展到神经语言模型,再到预训练的语言模型,然后到现在的大语言模型。其任务解决能力已经从特定任务的助手,演变成通用任务的求解器。
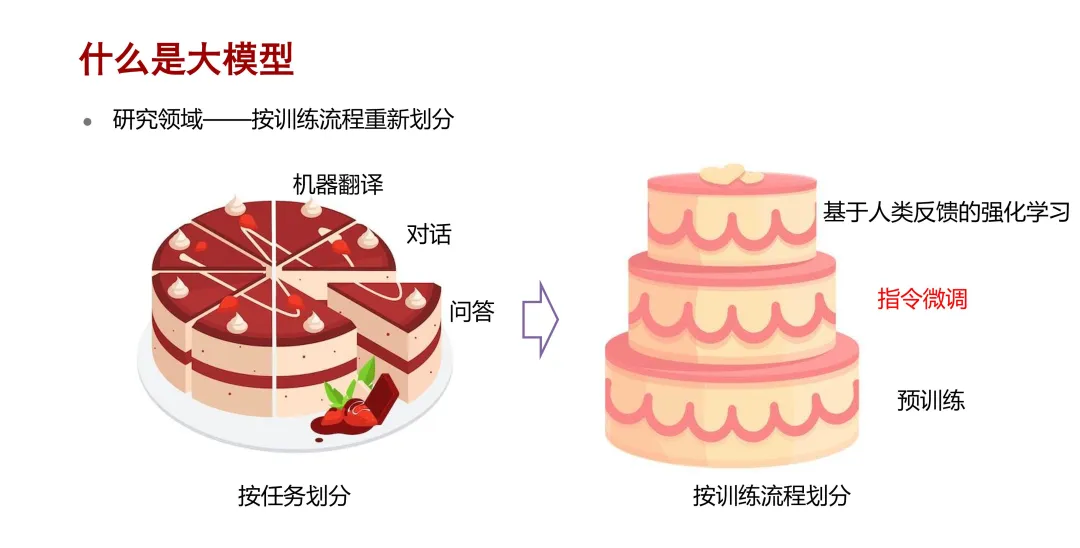
最后,从研究领域看,随着大模型从一个专才成长为一个通才,它的研究领域也不再是按照以前的任务来划分,而是可以按照训练流程来重新划分预训练、指令微调和基于人类反馈的强化学习。本次分享主要聚焦于指令微调领域。
02 指令微调介绍
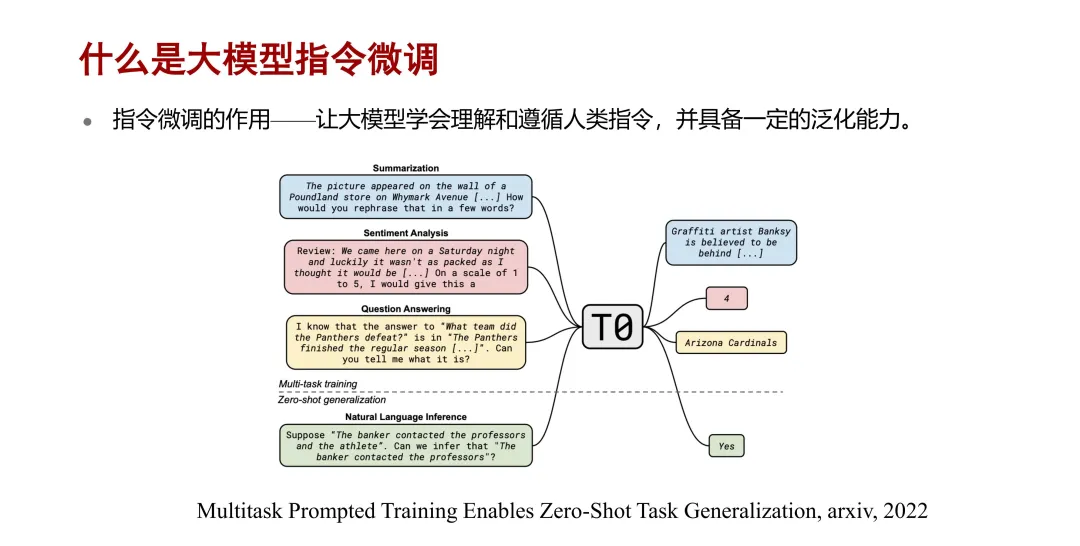
指令微调也被称为有监督的微调,即 SFT。大模型的指令微调,即用有监督的指令数据对大模型做微调,让大模型来学习特定的知识,以释放潜在的能力。大模型从指令中学习要做什么事,也就是当前要做的任务,然后从数据中去学习,根据不同的输入生成相应的输出反馈。在下图例子中,大模型通过指令微调,可以从这个指令中理解到是要做一个情感分类的任务,然后根据不同的输入文本输出相应的情感标签。

为什么要做大模型的指令微调呢?因为大模型在预训练阶段的训练任务是去学习预测下一个 token,这种形式的训练无法让大模型做对话式的问答。引入大模型指令微调的一个作用就是让大模型去学会理解和遵循人类的指令,并具备一定的泛化能力。在下面的这个例子中,我们用摘要、情感分析、问答这三种指令的数据对大模型做指令微调,大模型不仅可以覆盖到这三种类型的任务,还可以泛化到其他领域去做其他一些
NLP 相关的任务,比如自然语言的推理,这就是泛化的能力。
03 盘古大模型指令微调实践
下面正式介绍盘古大模型上的指令微调实践。
1. 算力基础和训练策略
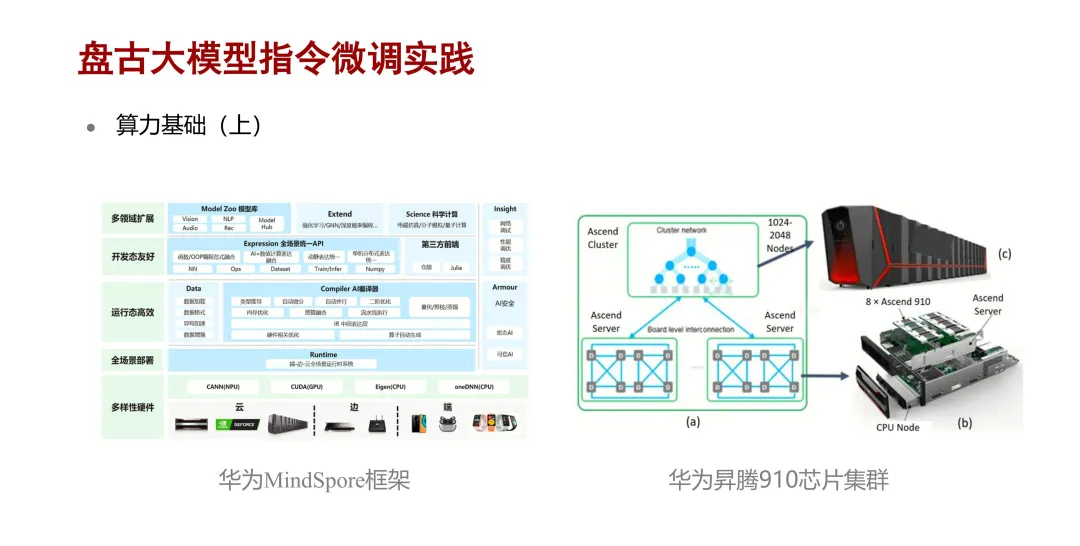
在算力基础方面,主要依托于 MindSpore 框架加上昇腾 910 芯片集群对盘古大模型做指令微调。其中,MindSpore
框架是华为自研的一款 AI 全场景框架,其与 PyTorch 等框架对标。昇腾 910 芯片是华为自研的一款高性能芯片,其性能介于
V100 和 A100 GPU 之间。MindSpore 主要提供神经网络的推理与训练的基础功能,并支持
CPU、GPU 和 NPU 等芯片计算。
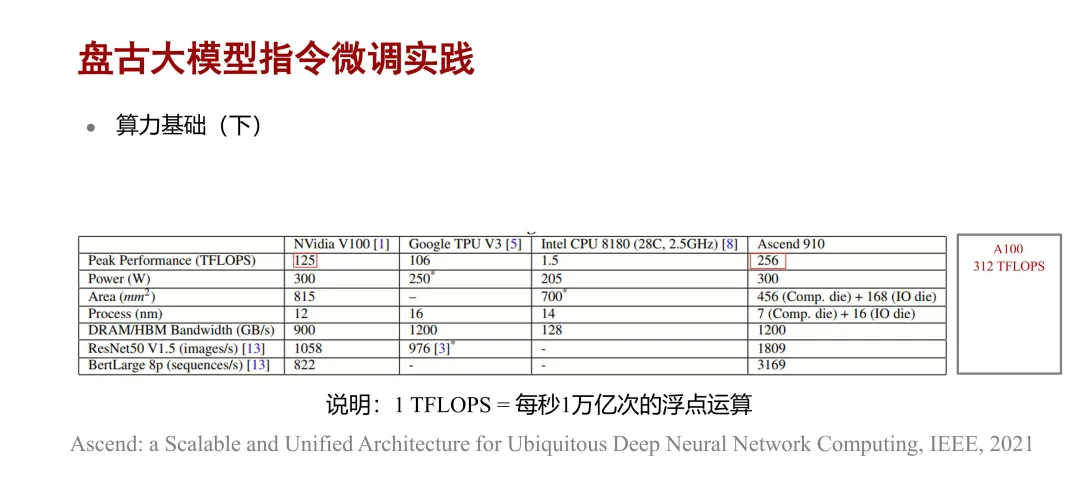
下图是昇腾 910 与 V100、A100 的算力对比,其中昇腾 910 的单精度浮点算力是 256TFlops,是
V100 的两倍,但略低于 A100 的算力,即 312TFlops。TFlops 是指每秒 1 万亿次的浮点计算。
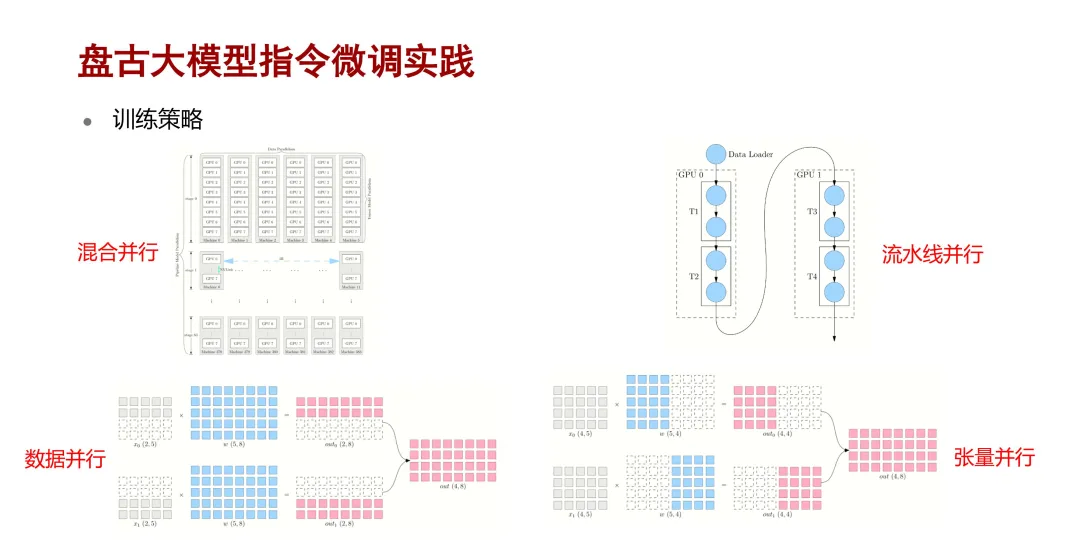
在训练策略方面,如果是对盘古大模型进行全参数微调或增量预训练,通常采用混合并行的训练策略,因为这个时候模型和数据都比较大。如果是对盘古大模型进行高效的参数微调,则会根据数据的大小和模型大小选择相应的并行策略。当数据量比较大时,会选择数据并行,如果是模型比较大时,可以考虑流水线并行或者张量并行。在这几种训练策略中,混合并行是指用这三种策略做组合,比如以
GPT-3.5 的训练策略为例,它是先进行流水线并行,再数据并行和张量并行。
这里简单说明下这三种并行策略的基本概念。流水线并行是指把模型的网络参数按层划分到不同的计算设备上,各个计算设备以接力的方式去完成训练。数据并行是指把数据分发到不同的设备上,且每个设备上的模型参数是完整的,需要在各个设备上进行梯度计算再做一个聚合才能完成训练。张量并行是指每个设备上的数据是完整的,需要把模型的参数矩阵拆分到不同的计算设备上,然后对各个设备的输出结果进行合并才能获取到真正逻辑意义上的一个输出。
2. 中英翻译全参数微调项目
接下来分享两个在盘古大模型上做指令微调实践的具体项目。指令微调方法按照参数规模可以分为全参数微调和高效参数微调两种方法,首先分享的是一个全参数微调的项目。
盘古大模型在 L0 层有五种大模型。这里选择的是盘古自然语言大模型,具体来讲,是以盘古-Sigma
大模型作为基座,并使用中英双语数据来构建翻译指令,对基座大模型做全参数微调,以提升盘古大模型的中英翻译能力。并且在华为翻译和同城会议等业务场景做了落地。该项目主要在数据格式、数据质量、数据大小和模型大小这四个方面进行了实践。

在数据格式方面,通常一个指令微调的数据格式如下图左侧所示,上面是指令,下面是输入和输出,中间有时会在指令中增加几个示例。我们在构建中英翻译示例时,将指令构建成一个翻译的指令,把原文作为输入、译文作为输出,并会随机选择一些双语作为可选的翻译示例。

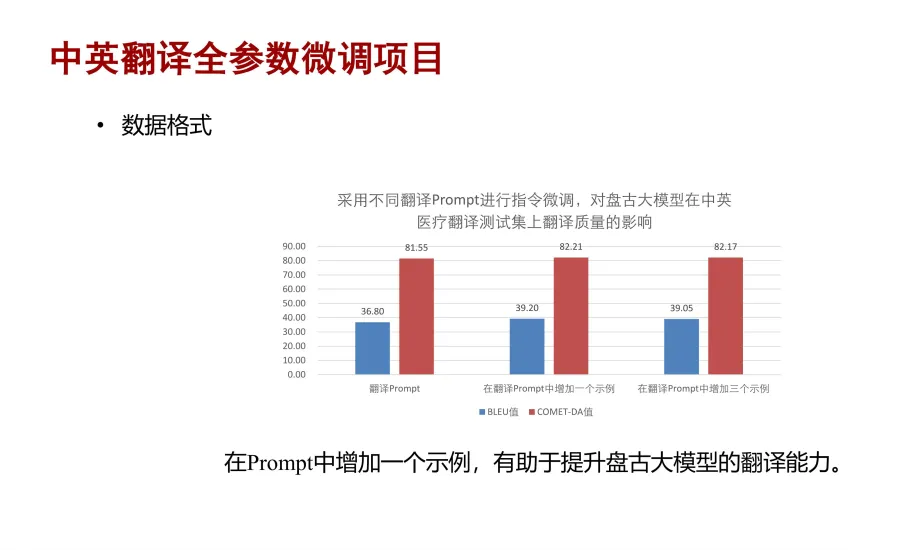
在数据部分,我们探索了在指令中增加一个或者多个翻译示例带来的影响。我们采用不同的翻译指令对盘古大模型做全参数微调,下图中展示了对模型在中英医疗翻译测试集上翻译质量进行的评测,主要采用自动评测指标
BLEU、人工评测指标 COMET-DA 来进行分析。从实验结果可以看到,在翻译中增加一个示例能够带来明显的提升,增加多个示例就没有再进一步的提升了。因此结论为,在指令中增加一个示例时有助于提升盘古大模型的翻译能力,即提升微调效果。
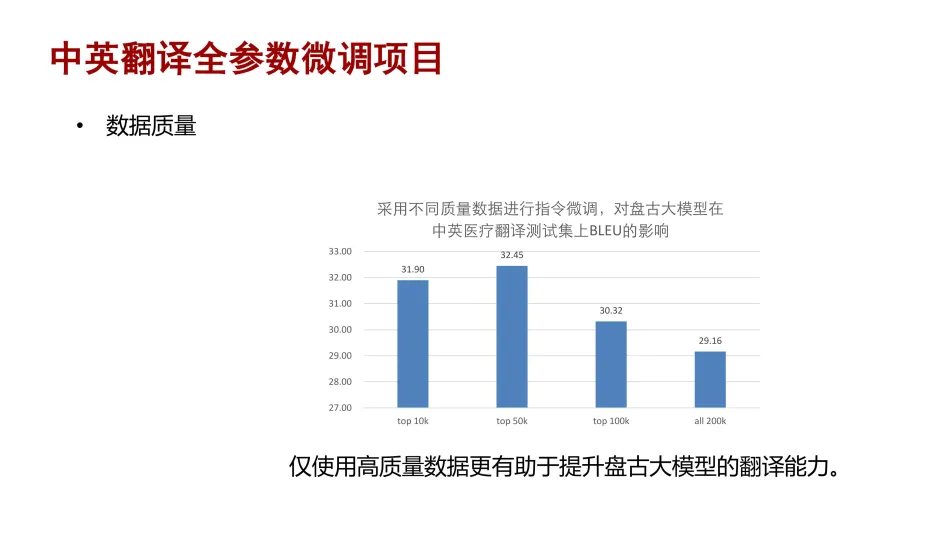
在数据质量方面,对于大模型而言,不管是预训练还是指令微调,数据质量过滤是数据处理环节中必不可少的一个环节。我们在去重和基于一定规则的数据质量过滤的基础上,探索了基于相似度对数据进行筛选。
具体的实验为:选择了一个 20 万的中英双语数据集,基于语义相似度对该数据进行打分排序,并选择不同的
top-K 数据分别对盘古大模型做全参数微调,之后评测微调后的模型在中英医疗翻译测试机上自动测评指标
BLEU 的变化。从实验结果中可以看到,只需要使用 25% 的全量数据就能达到最优的性能,也就是仅使用高质量的数据更有助于提升微调后的盘古大模型的翻译能力。
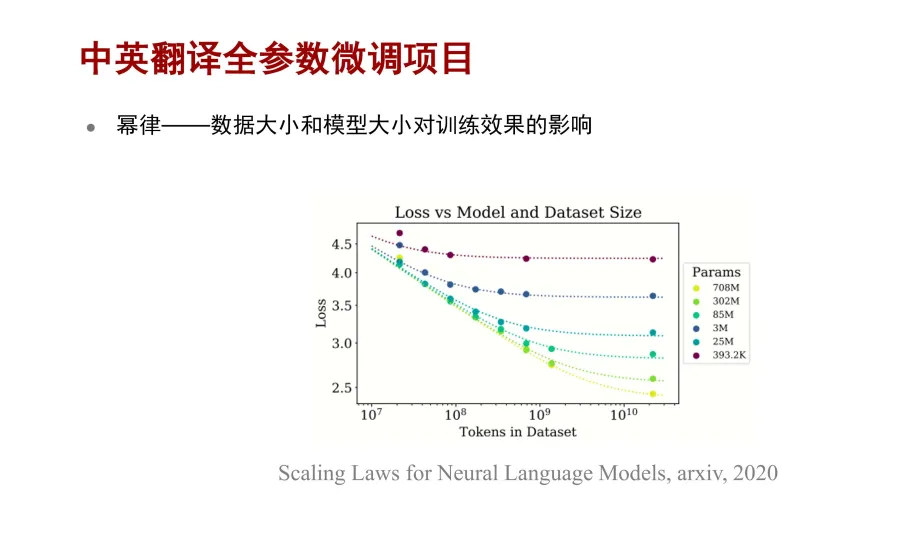
在数据大小和模型大小方面,之前已经有论文提出了幂律,也就是当计算量固定的时候,数据大小应该随模型大小一起增长,模型的训练才能达到更好的效果。从实验结果来看,先看横坐标,随着数据量的增长,模型训练的
loss 是更低的,也就说明了它的训练效果是更好的。再从纵坐标来看,模型的参数量在增长,模型的损失也在下降,这也说明了训练效果是更好的。最后综合来看,数据量越大,模型越大,训练效果越好。
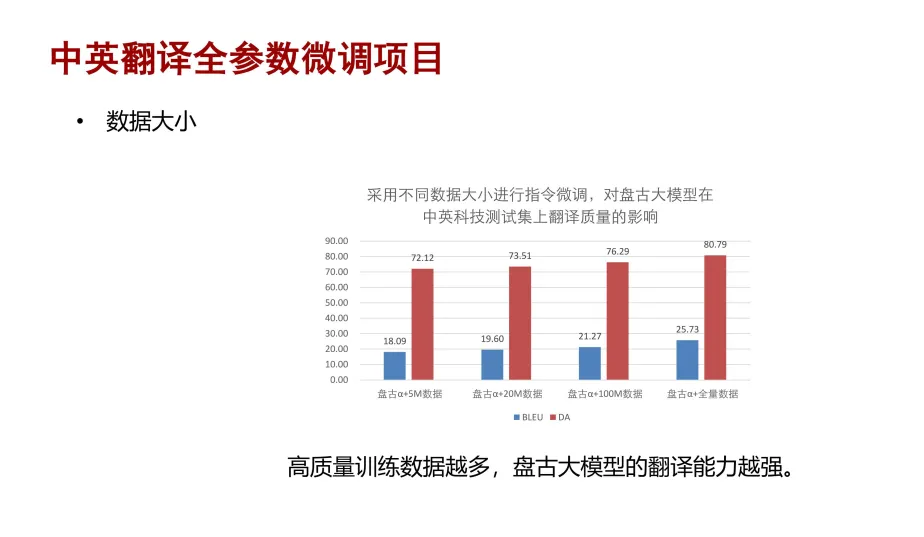
针对不同数据我们也展开了一系列实践,选择不同的数据大小(500 万、2000万、1 亿及全量的中英双语数据),对盘古大模型做全参数微调。从实验结果可以看到,更多的高质量的训练数据,更有助于盘古大模型提升翻译能力。
在模型大小方面,我们采用相同的全量数据,对两个不同参数规模的盘古大模型(38B 和 2.6B)做了全参数微调,并与线上的华为翻译做了对比。从对比结果上看,更大参数量的模型的翻译质量更优,最终超越了华为翻译的线上模型。但从训练成本的角度来看,更大的参数量意味着训练成本更高。例如对
38B 的一个盘古–Sigma 模型全参数微调,26B token 的数据,需要在 128 张 D910
上训练 11 天,而如果是相同数据量在对 2.6B 的盘古 –alpha 大模型做全参数微调,则只需要在
8 张 A100 上训练 9 天。

该项目的工作可以总结为以下四个方面:
首先,在数据格式上探索了在指令中加入示例的影响,发现加入一个翻译示例对指令微调的效果是更好的。
第二,在数据质量方面,采用不同的数据质量进行微调,发现仅使用高质量的数据指令微调的效果是更好的。
第三,在数据大小方面,使用不同的数据对盘古大模型做了微调,发现使用更多的高质量数据指令微调的效果更好。
第四,在模型大小方面,通过实验证明了更大的模型指令微调的效果更好,但训练成本也会更大一些。在实际业务中需要权衡训练成本和最终预期的效果。

3. 泰语大模型高效参数微调项目
第二个分享的项目是泰语大模型的一个高效参数微调项目,它同样是以盘古–Sigma 大模型作为基座模型,不同的是它以泰语为切入点,主要进行高效参数微调,聚焦于扩展盘古-Sigma
大模型的多语言能力。
在这个项目上我们主要针对三个难点问题展开实践:
第一个难点问题是词表问题,因为基座模型是只在中英上训练的,采用的是中英混合词表,泰语字符是不在这个词表里面的,所以没有直接训练,如何对它进行训练是需要考虑的问题;
第二个难点问题是方法选型的问题,现在有很多高效参数微调的方法,需要选择一种比较合适的方法;
第三个问题是数据的问题,泰语的指令数据相对较少,且质量参差,如何对其进行筛选与扩充也是值得探索的。

针对第一个问题,即词表问题,我们参考了 Chinese LLaMA,它的训练策略就是选择扩充词表来增加模型的参数,然后进行增量预训练。具体的过程分为三步,第一步是训练泰语分词器,统计泰语的词表,与基座大模型的词表进行融合;第二步是扩充基座大模型的输入输出层,及其关联模块的参数矩阵,具体来说就是复制已有的参数矩阵,去随机初始化新增的一些参数;最后,收集泰语的数据与中英数据做混合,用于对基座大模型做增量预训练。
下面是对泰语分词进行优化的效果展示。对一个 139 个字符的泰语句子,在对泰语分词优化前,因为 SPM
分词器是不支持泰语分词的,所以分的很乱。我们重新训练了一个泰语分词器后,把 139 个字符的一个泰语句子切成了
21 个 token 的一个序列,这样更加合理。最终,将词表扩充了 1 万左右。

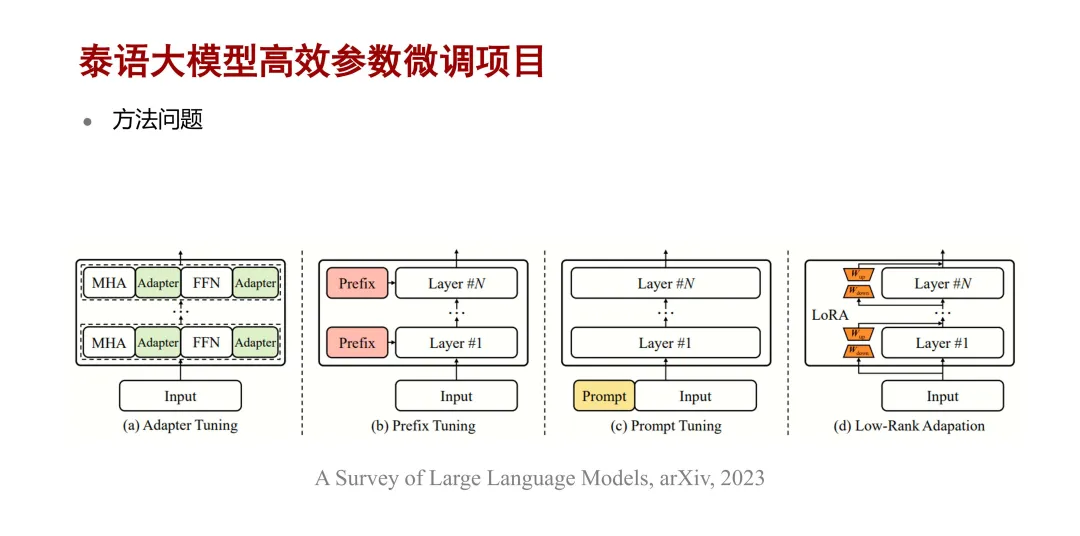
在介绍方法选型之前,先来介绍一下什么是高效微调的方法。其基本思想就是引入一些额外的参数,保持大模型原有的参数不变,通过微调新增的参数来适配下游任务。有几种典型的高效参数微调方法,第一种是
Adapter 微调,即在掩码多头注意力和前馈网络层后加一个轻量级的 adapter 组件。第二种方法是
prefix 微调,在中间每一层增加一段与任务相关联的 tokens。第三种,prompt 微调,是只在输入的
embedding 层增加一些提示的 token。第四种,LoRA 微调,是在模型的中间层,基于大模型的内在低秩特性,去增加一个小的旁路矩阵来模拟全参数微调。
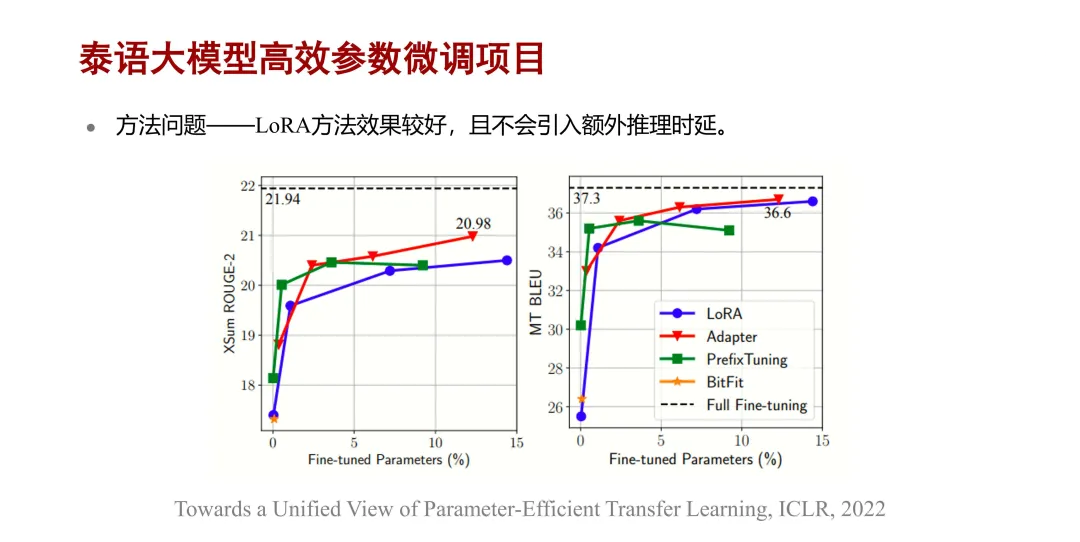
下面是几种典型的高效参数微调方法在摘要任务和机器翻译任务上的对比评测结果。从实验结果可以看出,Adapter
方法和 LoRA 方法的效果相对较好,可以做到只微调少量参数即可接近全参数微调的性能。在这两种方法中,因为
Adapter 方法增加的组件是与模型串联的,会增加模型的深度,因此会引入额外的推理时延。而 LoRA
增加的是一个并联的旁路矩阵,不会增加额外的推理时延,所以我们最终采用了 LoRA 方法去做高效参数微调。
针对数据问题,一方面要筛选高质量的指令数据,我们引入了一种自引导的数据选择方法,主要分为三步,第一步是随机挑选一些指令数据去微调大模型,然后再去用这个微调后的大模型来计算指令数据的学习难度,最后选择那些学习难度排在前面的指令数据去重新微调大模型。在这个论文中,只需要用到
10% 的数据就能达到最优的性能,我们在实践过程中也是参考了这样的做法。

另一方面,还需要扩充数据的大小,所以我们采用了指令反译的方法,类似于机器翻译里面的 TAGBT 方法,即加标签的反向翻译方法,同样也是分为三步,第一步是先训练指令生成模型,然后基于无标签的数据生成伪指令数据,第二步用真实数据微调大模型来对这个伪指令数据打分,挑选出更高质量的伪指令数据,最后再以加标签的方式来混合使用高质量的伪指令数据和真实数据去重新微调大模型。在实践过程中,我们发现这种方法可以增加指令数据的多样性,会生成一些新的动词和名词。

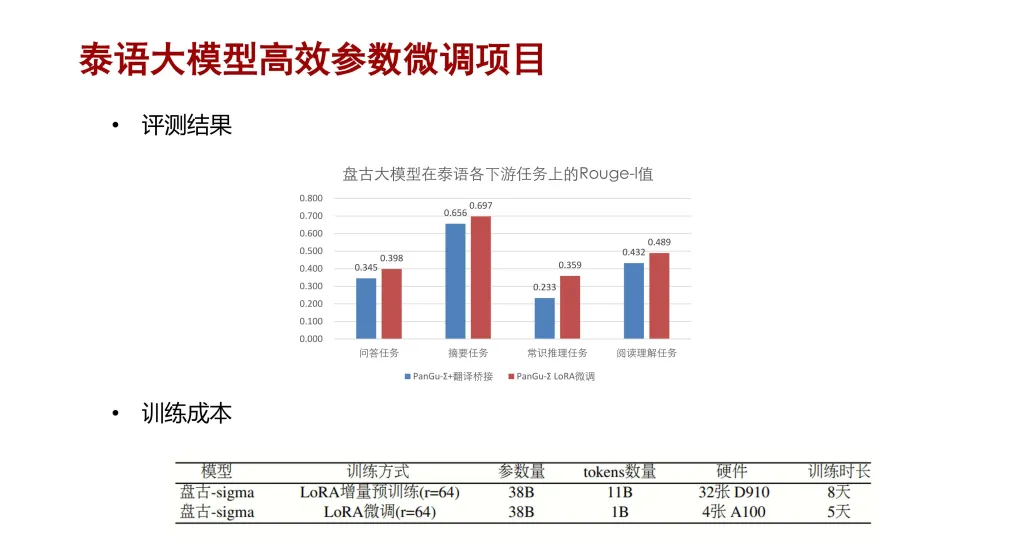
在评测中,针对第一阶段,为了评价 LoRA 方法微调的效果,我们先构建了一个基线。这个基线是采用微调前的一个盘古大模型来做的。因为微调前的这个盘古大模型是不支持泰语的,所以我们引入了一种翻译桥接的方法来近似模拟它在泰语上的标签。
具体的做法是先用华为翻译把泰语测试集的输入翻译成英文,然后喂给盘古大模型,让它去输出相应的结果。拿到结果后把它转换成泰语,这样就可以测出一个基线的性能,再与
LoRA 微调后的效果进行对比。我们从泰语的一些公开测试集,包括 NLG 和 NLU 任务中选取了几个常用的问答、摘要、常识推理、阅读理解等任务来做性能评测。最后发现我们的
LoRA 微调方法会比基线效果更好。训练成本方面,LoRA 增量预训练的成本会更高一些,因为其训练数据更大,比如
11B 的 token 和 38B 的模型做增量预训练时需要在 32 张 D910 上训练 8 天,而如果是
1B 的 token 做 LoRA 微调时只需要在 4 张 A100 上训练 5 天。
对该项目进行一个小结,我们针对三个难点问题展开了一些实践:
针对词表问题,通过词表扩充和增量预训练来适配新语言。
在方法选型上,选择 LoRA 微调方法,因为其效果相对较好,且不会引入额外的推理时延。
在数据问题上,一方面选择采用自引导的数据选择方法来筛选高质量的数据,另一方面通过指令反译来扩充数据大小。

最后,总结一下盘古大模型指令微调实践中获得的经验:
首先,数据是知识的载体,数据的质和量都至关重要,一方面我们要做好严格的质量把关,另一方面要尽可能获取更多的高质量数据。
第二点是在模型方面,模型越大,潜力越大,但是训练成本也越高,在业务落地时要做好权衡。
第三点是在算力方面,大模型的算力需求高,如何利用好有限的算力很关键,比如在选择微调方法的时候,如果算力充足,而且追求在当前任务上更好的性能,那么可以选择全参数微调的策略;如果算力有限,也可以选择高效微调策略,微调少量参数即可达到不错的性能。在选择训练策略时,要考虑数据大小和模型大小,如果只是数据量比较大,那么可以采用数据并行的策略;如果模型比较大,可以采用张量并行或者流水线并行的策略;如果两者都比较大,则应采用混合并行的训练策略。

以上就是本次分享的内容,谢谢大家。
04 Q&A
Q:第一个项目涉及到的机器翻译,机器翻译作为一个非常传统的 NLP 项目,GPT-3.5 对于此类项目已经非常出色。文中第一个项目其实是做了一个专用领域的
SFT,是否与 GPT-3.5 进行过对比?两者的翻译效果有多大的差距,或者这种专用的 SFT 能否解决一些通用无法解决的
case?
A:我们确实是对 ChatGPT 包括 GPT-4 做过一个在中英翻译任务上的对比评测,主要采用自动测评的
BLEU 指标,我们也有一些专业的译员对大模型的翻译结果做过人工评测。从对比结果来看,在 BLEU
指标方面其实大家的差距很小,但是大模型主要强在它的人工感受这块,也就是大模型的翻译结果是更好的,因为它更地道一些、更自然一些。我们最终的盘古大模型的微调效果在人工评测上还是会比ChatGPT
和 GPT-4 略差一些。
|








