| 编辑推荐: |
本文将从模型背景、模型介绍、模型应用三个方面,带您一文搞懂Vision
Transformer:视觉Transformer对CNN的降维打击。希望对你的学习有帮助。
本文来自于微信公众号架构师带你玩转AI,由火龙果软件Linda编辑,推荐。 |
|
本文将从模型背景、模型介绍、模型应用三个方面,带您一文搞懂Vision
Transformer:视觉Transformer对CNN的降维打击。
Vision Transformer
—1—
模型背景
Transformer引领NLP格局
在当今的自然语言处理(NLP)领域,Transformer模型凭借其卓越的性能和全面的能力,已经全面碾压了传统的循环神经网络(RNN)模型,成为了无可争议的标杆。
在各种排行榜记录中,Transformer模型都以其出色的性能稳居榜首,彻底改变了NLP领域的研究格局。

NLP模型演进
自然语言处理 (NLP):
NLP是一种机器学习技术,使计算机能够解读、处理和理解人类语言。
自然语言处理NLP
在自然语言处理中,计算机需要处理大量的文本数据,并尝试从中提取有用的信息。这些文本数据可以是书籍、文章、社交媒体帖子、电子邮件、聊天记录等。

NLP 数据集
通过NLP技术,计算机可以执行诸如文本分类、情感分析、机器翻译、问答系统、文本摘要等各种任务。
文本分类:文本分类是NLP中最常见的任务之一,它涉及将文本分配到一个或多个预定义的类别中。例如,新闻文章可以分类为政治、体育、娱乐等类别。
情感分析:情感分析确定文本中表达的情感或观点。这可以是对产品、服务、事件或主题的正面、负面或中性的评价。
机器翻译:机器翻译将一种语言的文本自动转换为另一种语言。这通常涉及复杂的语言建模和序列生成技术。
问答系统:问答系统旨在自动回答用户提出的自然语言问题。这可以包括基于知识库的问答、基于文档的问答或基于对话的问答。
文本摘要:文本摘要旨在生成长文档的简短摘要,以便快速了解文档的主要内容。
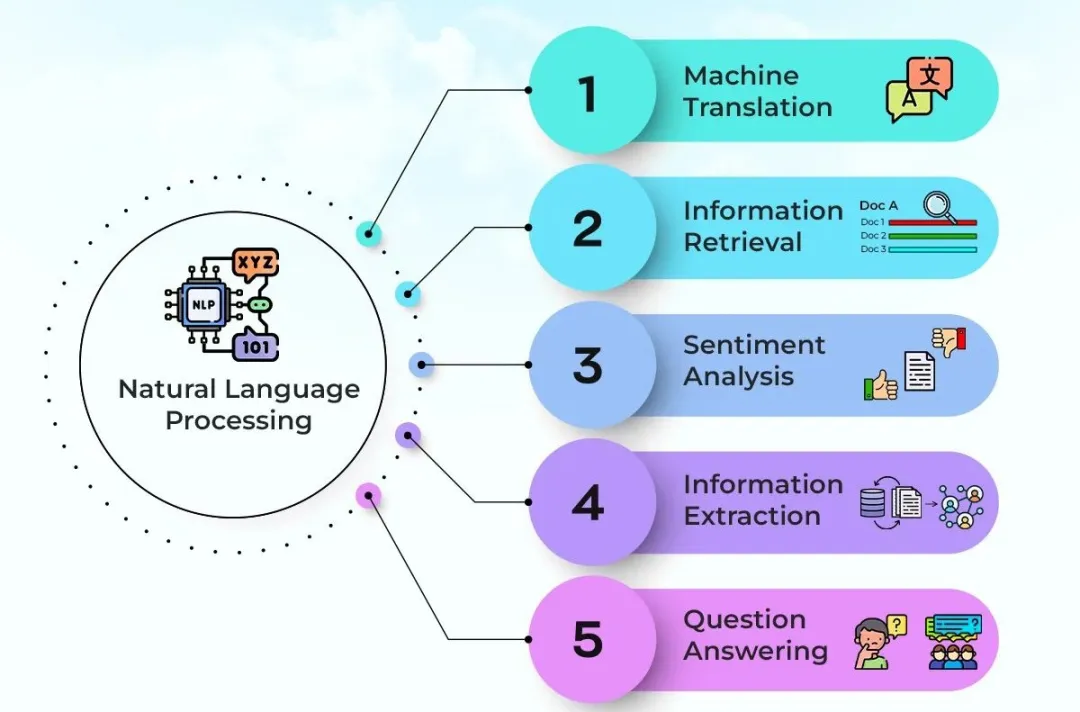
NLP 任务
循环神经网络(Recurrent Neural Network):
RNN是一种特殊的神经网络结构,专门用于处理序列数据。
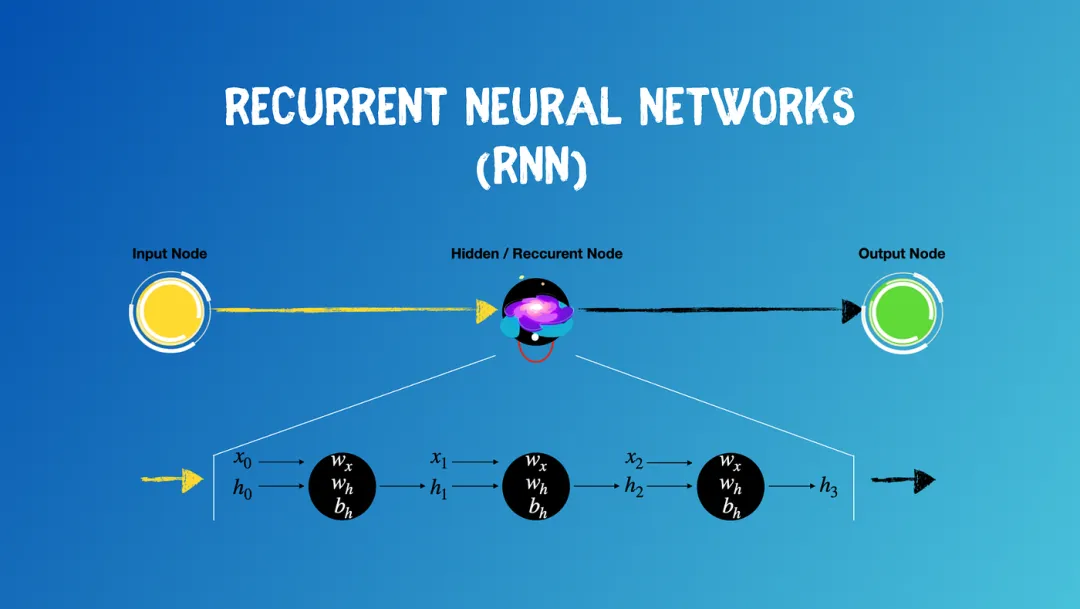
循环神经网络RNN
RNN具有记忆功能,能够捕捉序列中的依赖关系。RNN前面所有的输入都对后续的输出产生影响。圆形隐藏层不仅考虑了当前的输入,还综合了之前所有的输入信息,能够利用历史信息来影响未来的输出。
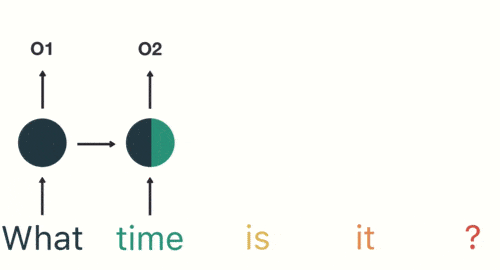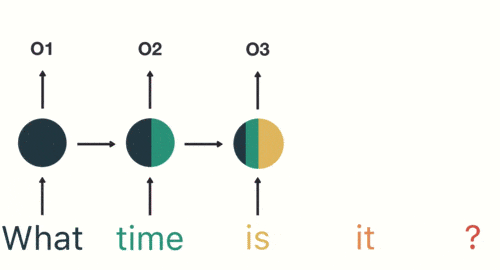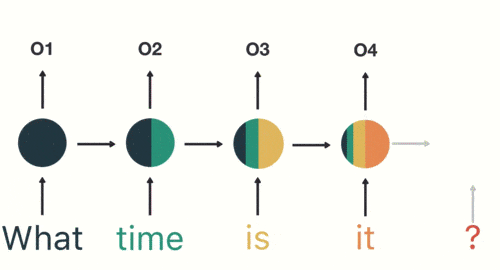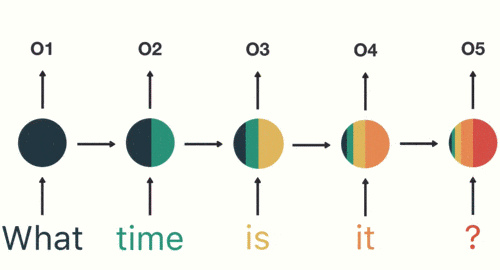
RNN捕捉序列中的依赖关系
循环神经网络(RNN),特别是长短时记忆网络(LSTM)和门控循环单元网络(GRU),已经在序列建模和转换问题中牢固确立了其作为最先进方法的地位,成为NLP领域曾经的王者。
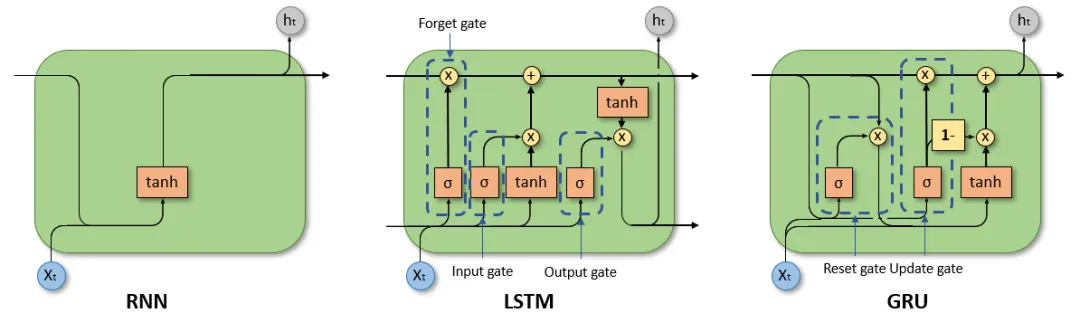
RNN、LSTM、GRU
详细了解循环神经网络RNN:神经网络算法 - 一文搞懂RNN(循环神经网络)
详细了解长短期记忆网络LSTM:神经网络算法 - 一文搞懂LSTM(长短期记忆网络)
Transformer:
Transformer是一种基于自注意力机制的深度学习模型,天生就是为了解决自然语言处理中的序列到序列(sequence-to-sequence)问题而设计的。
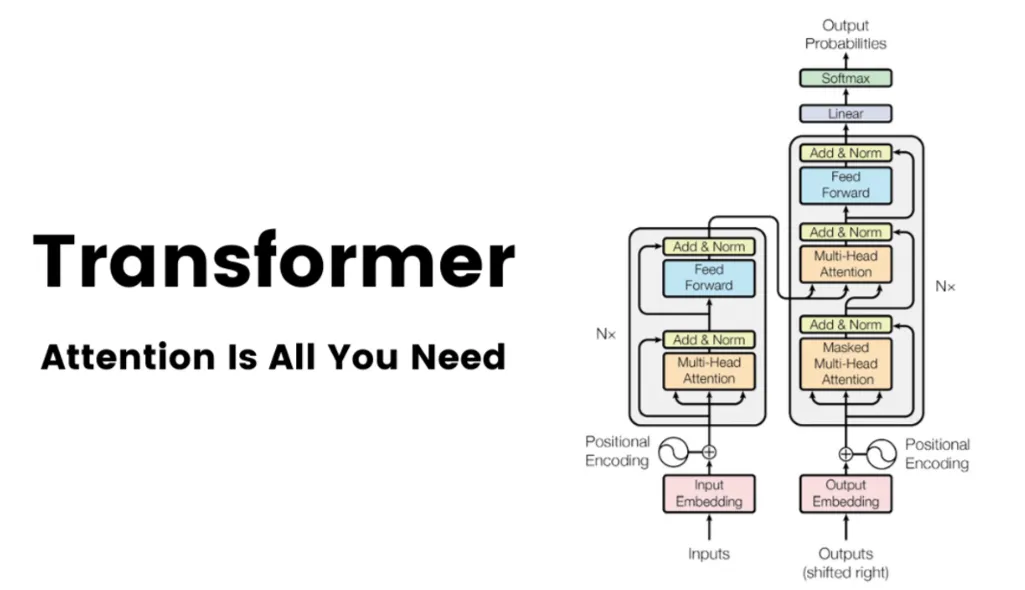
Transformer
论文《Attention Is All You Need》

注意力机制是全部所需
在大多数情况下,注意力机制通常是与循环网络结合使用的。Transformer模型架构,它摒弃了循环结构,转而完全依赖注意力机制来建立输入和输出之间的全局依赖关系。
相较于RNN模型,Transformer模型具有2个显著的优势。
优势一:处理长序列数据。Transformer采用自注意力机制,能够同时处理序列中的所有位置,捕捉长距离依赖关系,从而更准确地理解文本含义。而RNN模型则受限于其循环结构,难以处理长序列数据。
优势二:实现并行化计算。由于RNN模型需要依次处理序列中的每个元素,其计算速度受到较大限制。而Transformer模型则可以同时处理整个序列,大大提高了计算效率。
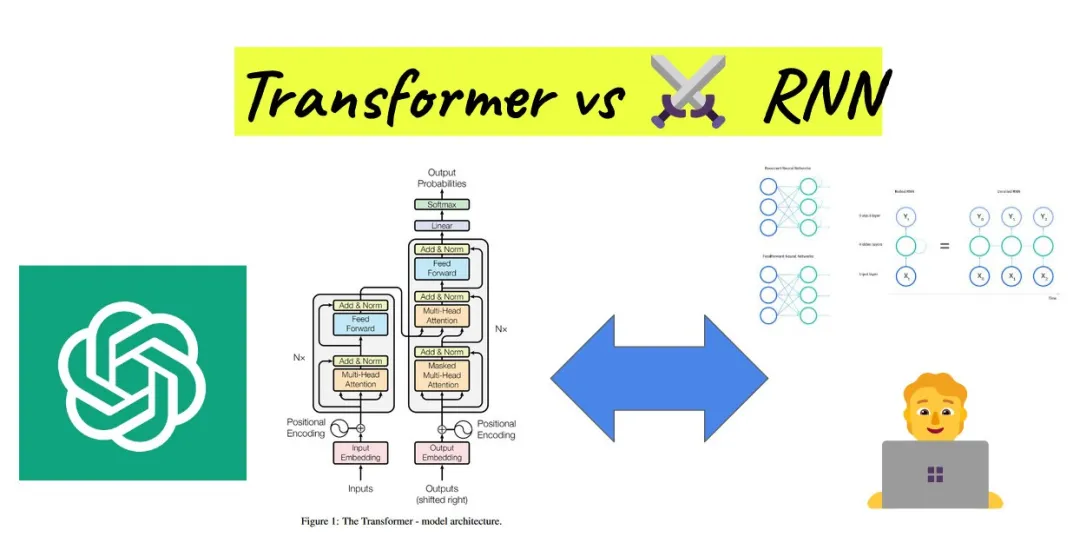
Transformer vs RNN
基于Transformer的模型,以其强大的表示能力,在NLP领域取得了显著的突破。
Transformer:Vaswani等人首次提出了基于注意力机制的Transformer,用于机器翻译和英语句法结构解析任务。
BERT:Devlin等人介绍了一种新的语言表示模型BERT,该模型通过考虑每个单词的上下文。因为它是双向的,在无标签文本上预训练了一个Transformer。当BERT发布时,它在11个NLP任务上取得了最先进的性能。
GPT:Brown等人在一个包含45TB压缩纯文本数据的数据集上,使用1750亿个参数预训练了一个基于Transformer的庞大模型,称为GPT-3。它在不同类型的下游自然语言任务上取得了强大的性能,而无需进行任何微调。

Transformer模型及其变体
详细了解Transformer中的三种注意力机制:神经网络算法 - 一文搞懂Transformer中的三种注意力机制
详细了解Transformer:神经网络算法 - 一文搞懂Transformer
Computer Vision仍是CNN的天下
虽然Transformer 架构已成为自然语言处理事实上的标准,但其在计算机视觉中的应用仍然有限。在视觉中,要么与卷积网络结合应用,要么用于替换卷积网络的某些组件,同时保持其整体结构不变。
计算机视觉(Computer Vision):
一门研究如何使机器“看”的科学,更进一步地说,就是指用摄影机和计算机代替人眼对目标进行识别、跟踪和测量等机器视觉,并进一步做图像处理,用计算机处理成为更适合人眼观察或传送给仪器检测的图像。

计算机视觉(Computer Vision)
计算机视觉领域的应用广泛且显著,图像识别、目标检测和图像分割是CV的3个主要应用。

计算机视觉领域的应用
图像识别(Image Recognition):准确识别图像中的物体、场景或文字,为图像分类和识别任务提供了强有力的支持。
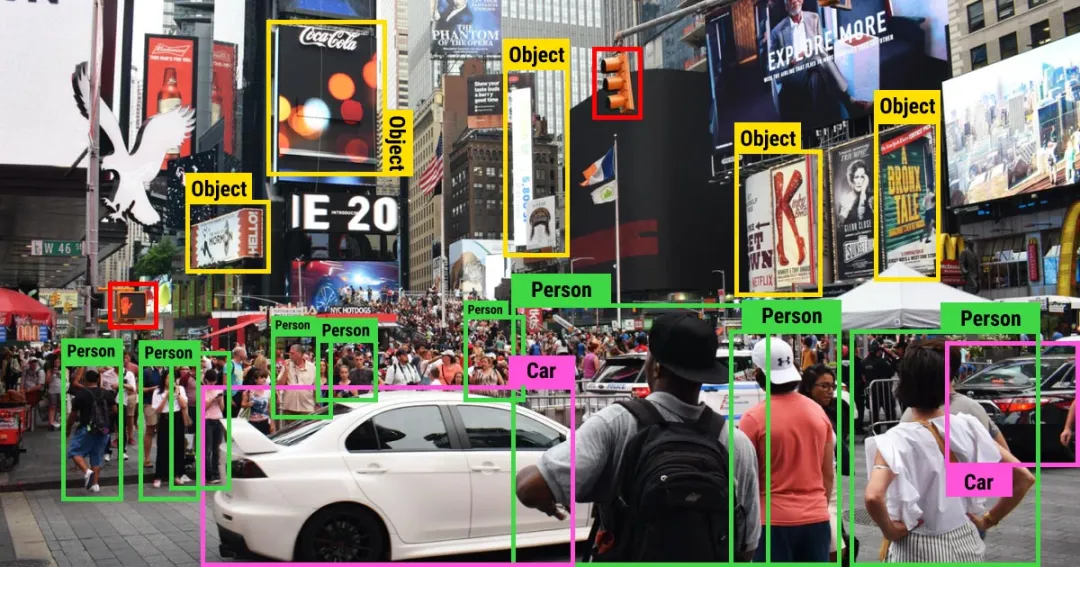
图像识别(Image Recognition)
目标检测(Object Detection):有效地提取图像中的目标特征,实现对图像中多个目标的准确检测和定位。
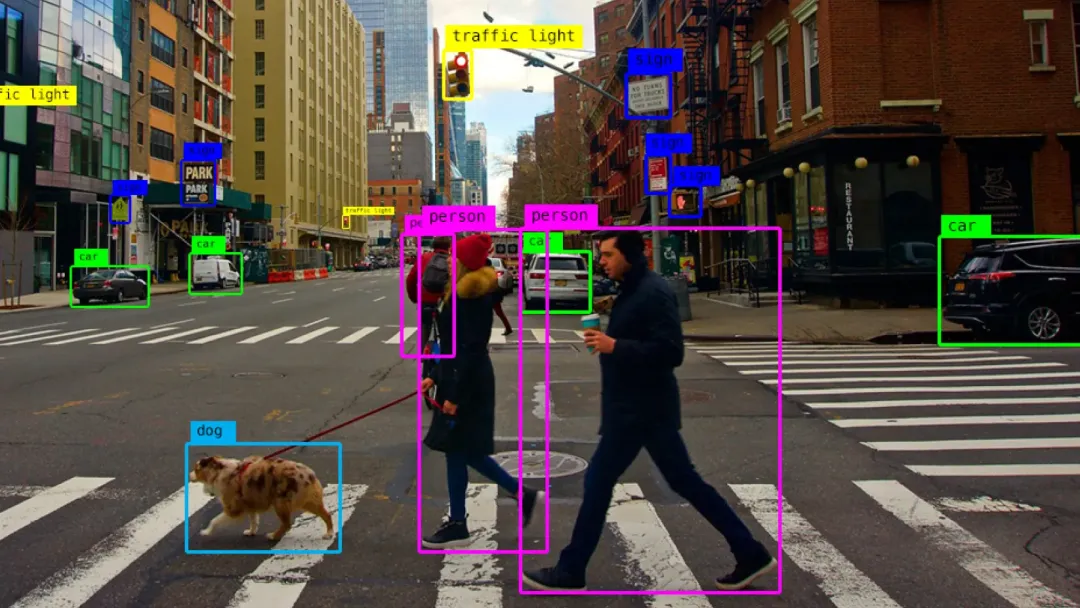
目标检测(Object Detection)
图像分割(Image Segmentation):实现对图像中不同区域的精细分割,为医学影像分析、自动驾驶等领域的应用提供了重要支持。
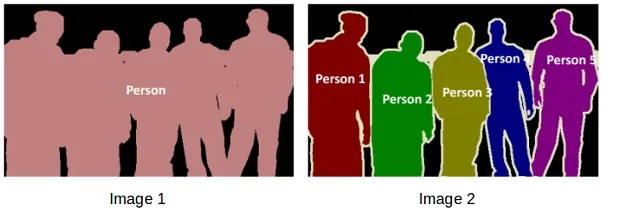
图像分割(Image Segmentation)
卷积神经网络(Convolutional Neural Network):
CNN是一种包含卷积计算且具有深度结构的前馈神经网络,具有强大的图像和序列数据处理能力,广泛应用于图像识别、计算机视觉等领域。
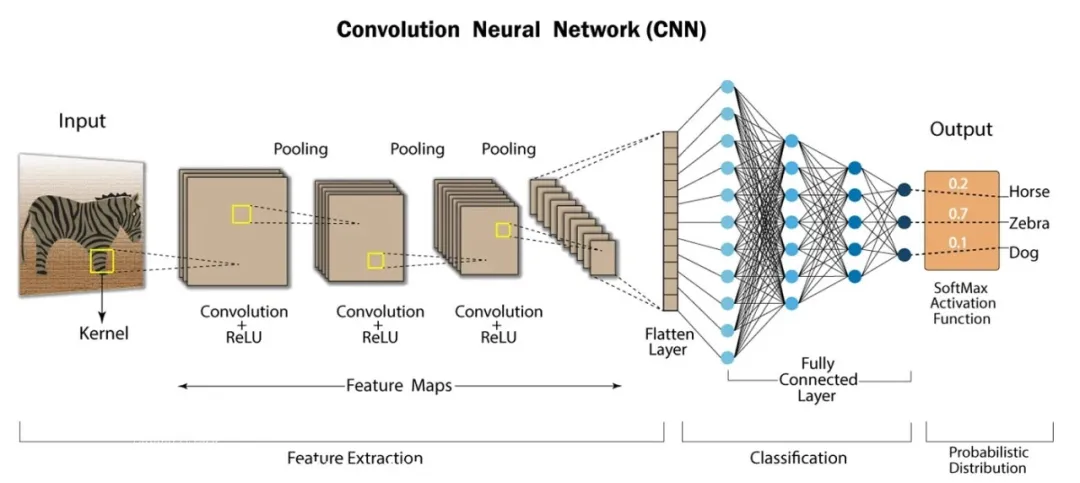
卷积神经网络CNN
CNN的网络结构:通常包括卷积层、池化层(也称为下采样层或子采样层)和全连接层三部分。
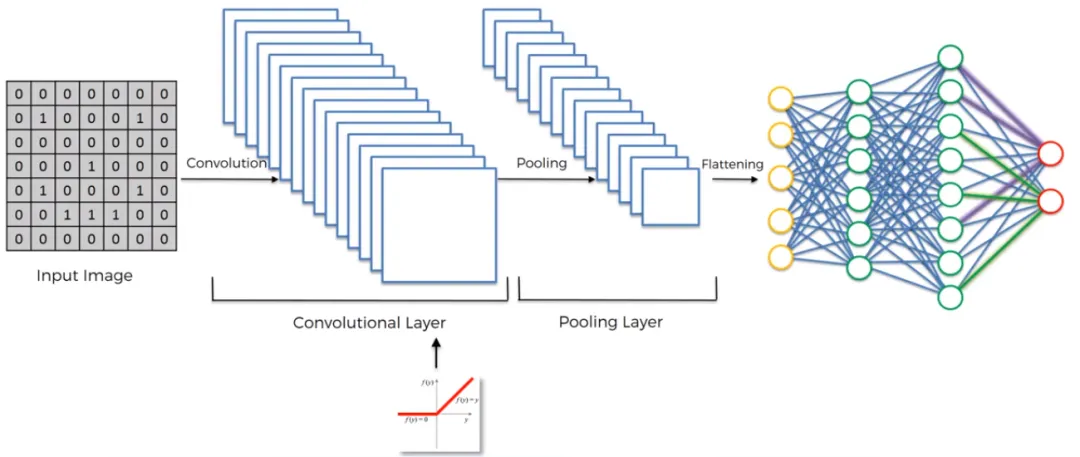
CNN的网络结构
CNN的工作原理:通过卷积层提取图像局部特征,池化层降低数据维度,全连接层进一步提取高级特征并进行分类。
卷积层:通过卷积核的过滤提取出图片中局部的特征,类似初级视觉皮层进行初步特征提取。

使用一个过滤器(卷积核)来过滤图像的各个小区域,从而得到这些小区域的特征值。
池化层:下采样实现数据降维,大大减少运算量,避免过拟合。
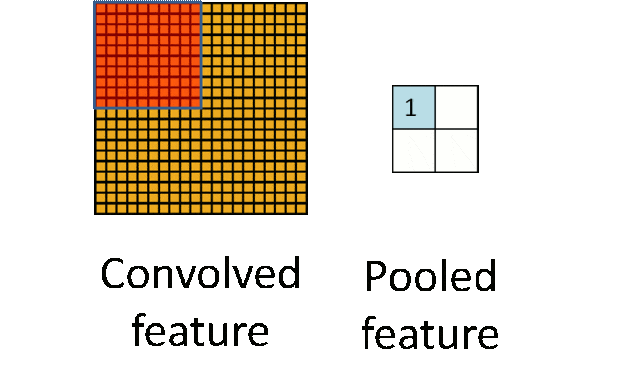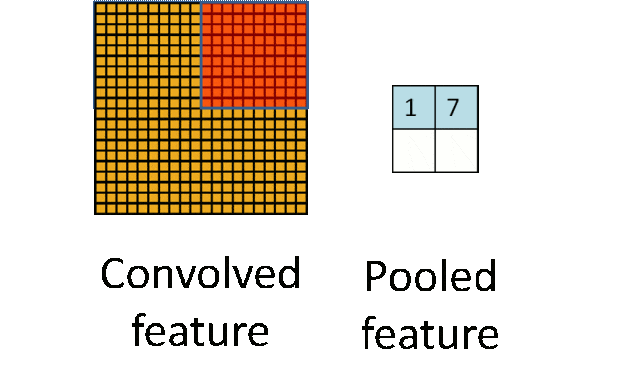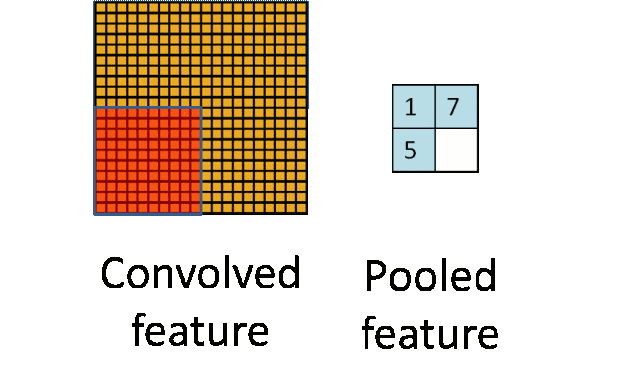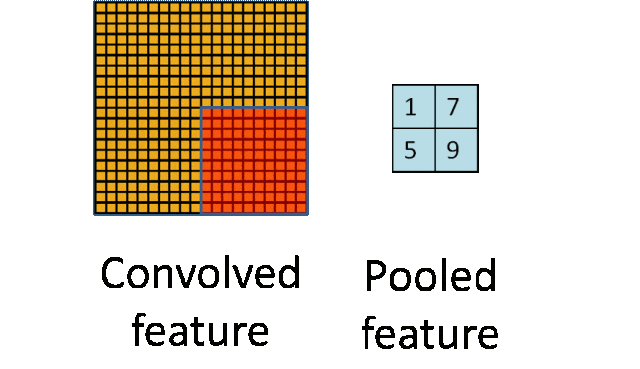 原始是20×20的,进行下采样,采样为10×10,从而得到2×2大小的特征图。
全连接层:经过卷积层和池化层处理过的数据输入到全连接层,得到最终想要的结果。
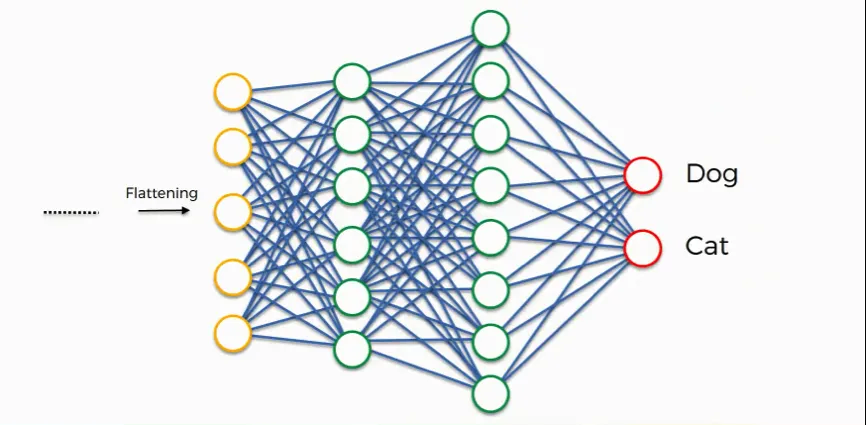
全连接层输出结果
详细了解卷积神经网络CNN:神经网络算法 - 一文搞懂CNN(卷积神经网络)
—2—
模型介绍
Vision Transformer(ViT)是一种革命性的深度学习模型,它彻底改变了传统计算机视觉领域处理图像的方式。

Vision Transformer
Vit模型在论文 An Image is Worth 16x16 Words: Transformers
for Image Recognition at Scale中提出。这是第一篇在 ImageNet
上成功训练 Transformer 编码器的论文,与熟悉的卷积架构相比,取得了非常好的结果。
 一张图片胜过16x16的文字:适用于大规模图像识别的转换器
模型思路
ViT的核心思路是将图像视为一系列的“视觉单词”或“令牌”(tokens),而不是连续的像素数组。
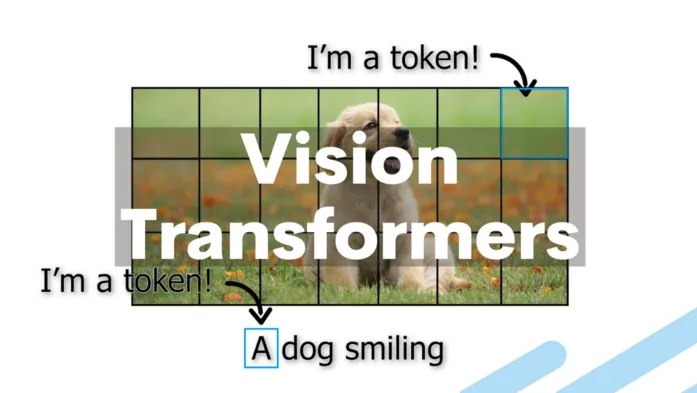
Vision Transformer
图像块(Image Patches):
ViT首先将输入图像切分为多个固定大小的图像块(patches)。
这些图像块被线性嵌入到固定大小的向量中,类似于NLP中的单词嵌入。
每个图像块都被视为一个独立的“视觉单词”或“令牌”,并用于后续的Transformer层中进行处理。
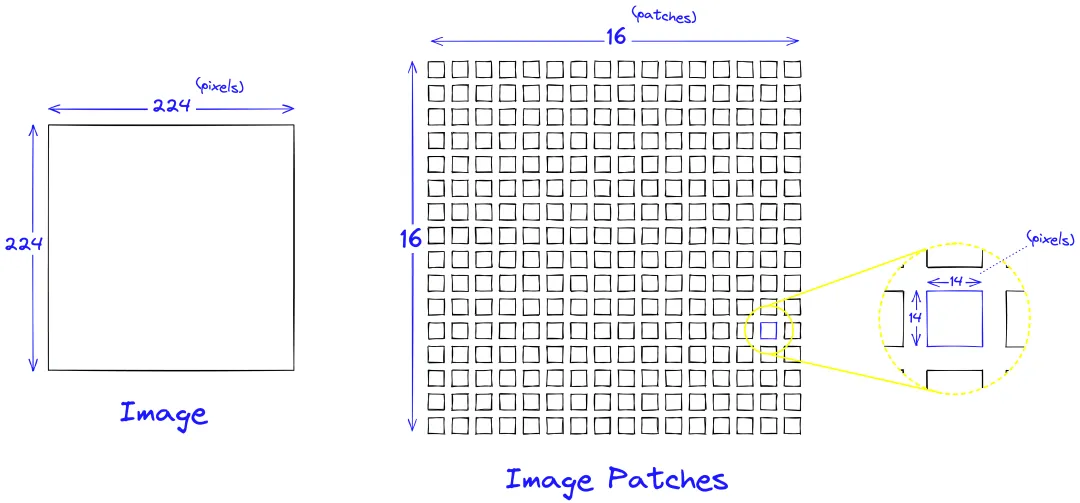 图像块(Image Patches)
模型架构
Vision Transformer(ViT)的架构图:
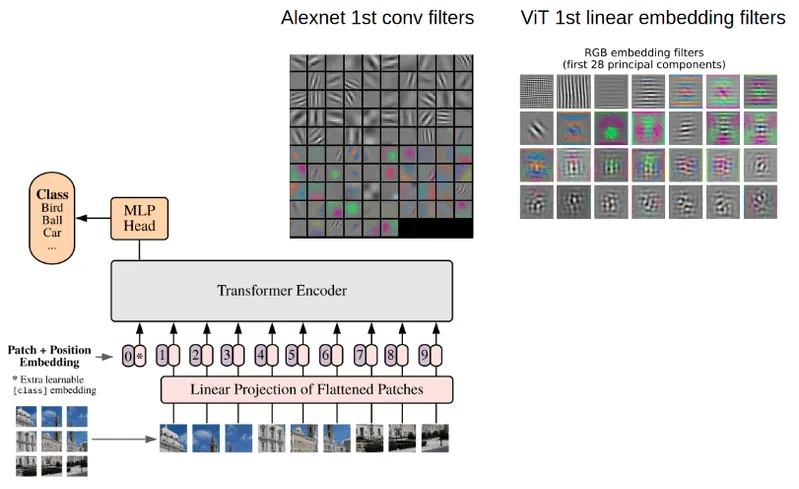
ViT的架构如图所示:
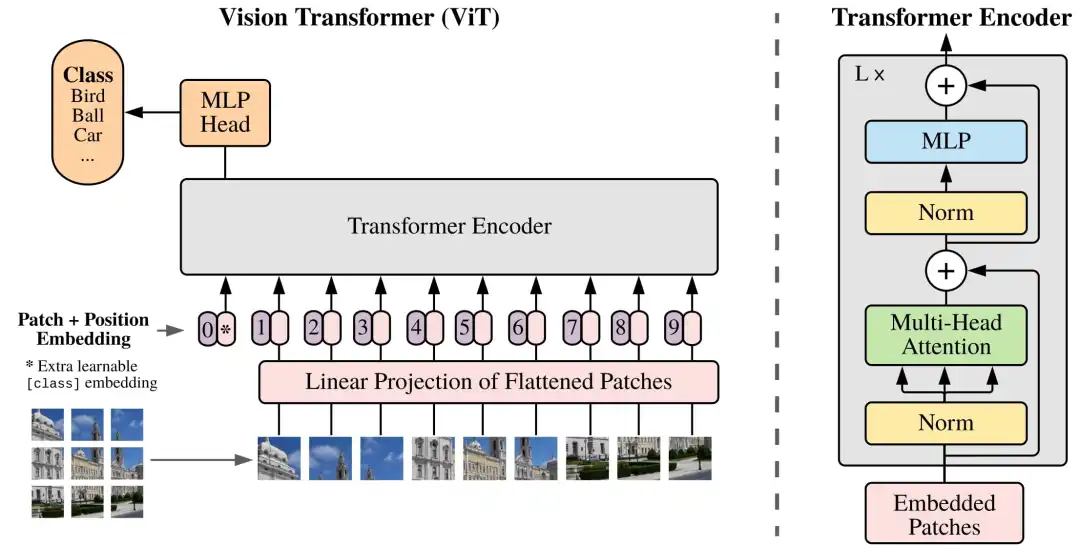 ViT的架构图
Vision Transformer(ViT)的核心模块:
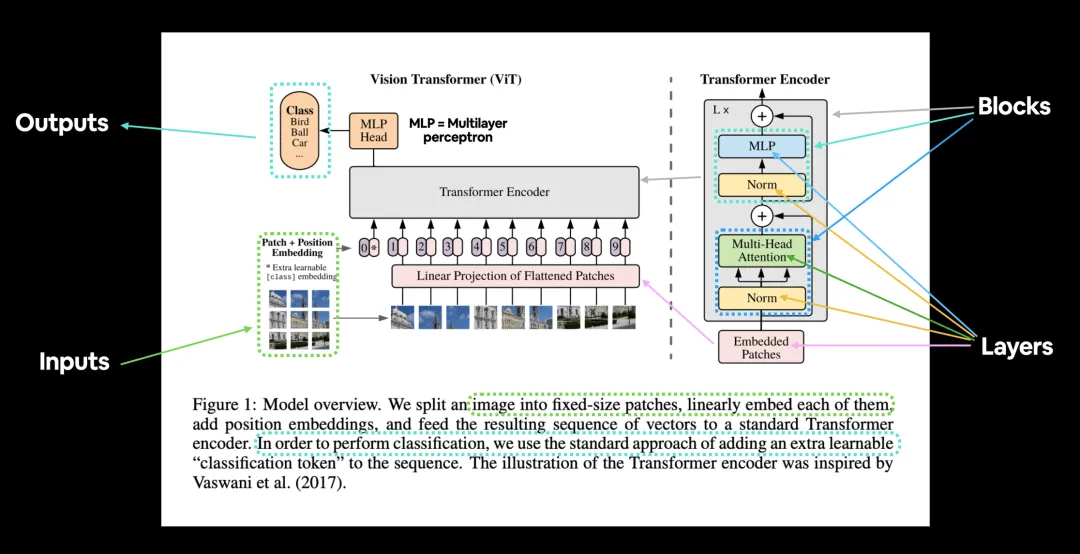
ViT的核心组件分为5部分:Patch Embeddings,Position Embeddings,Classification
Token,Linear Projection of Flattened Patches,以及Transformer
Encoder。
Patch Embeddings:如上图虚线的左半部分,我们将图片分成固定大小的图像块patches(如图左下9×9的图像),将它们线性展开。
Position Embeddings:Position embeddings加到图像块中是为了保留位置信息的。
Classification Token:为了完成分类任务,除了以上九个图像块,我们还在序列中添加了一个*的块0,叫额外的学习的分类标记Classification
Token。
Linear Projection of Flattened Patches:图像分割为固定大小的图像块(patches)后,将每个图像块展平(flatten)为一维向量,并通过一个线性变换(即线性投影层或嵌入层)将这些一维向量转换为固定维度的嵌入向量(patch
embeddings)。
Transformer Encoder:由多个堆叠的层组成,每层包括多头自注意力机制(MSA)和全连接的前馈神经网络(MLP
block)。
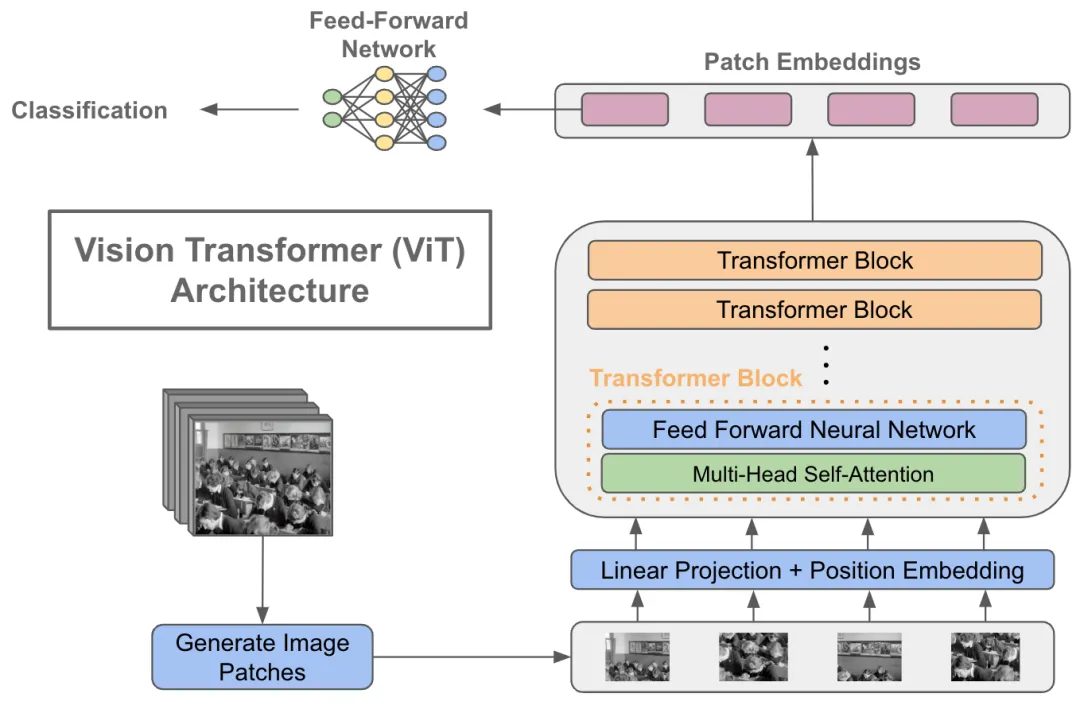 ViT的Transformer Encoder
Vision Transformer(ViT)的工作流程:
将图像分割为固定大小的图像块(patches),将其转换为Patch Embeddings,添加位置编码信息,通过包含多头自注意力和前馈神经网络的Transformer编码器处理这些嵌入,最后利用分类标记进行图像分类等任务。

ViT的工作流程
模型演进
Vision Transformer(ViT)的发展历程:
Transformer及其视觉变种(如Vision Transformer,简称ViT)发展历程中的关键节点进行的总结,并用红色标记了与视觉任务相关的模型。
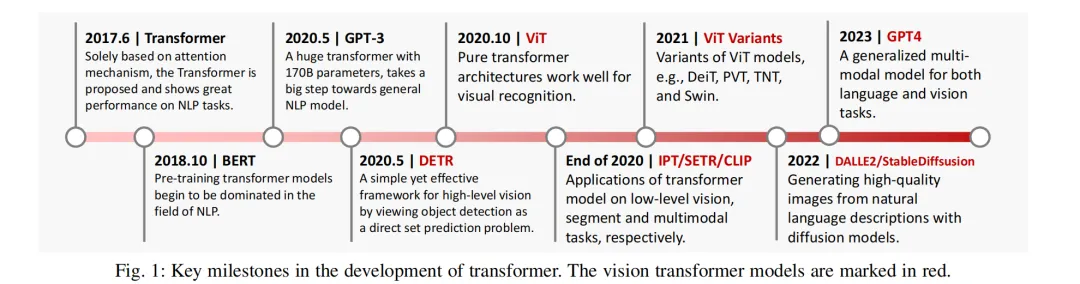
ViT的发展历程
DETR(Detection Transformer):DETR是一个基于Transformer架构的端到端目标检测模型,由Facebook
AI Research(FAIR)提出。它采用全局上下文来预测图像中的目标,而无需使用先前的候选框或区域建议网络。

DETR
Swin Transformer:Swin Transformer是一种新型的Transformer架构,专为计算机视觉任务而设计。它引入了基于移动窗口的自注意力机制,并采用了层级式的特征表达方式,使得模型在计算复杂度和性能之间取得了平衡。
Swin Transformer
DALL-E2(Data-Augmented Language-Image Embedding):DALLE是OpenAI开发的一个基于Transformer的生成模型,旨在生成与文本描述相匹配的图像。它结合了自然语言处理和计算机视觉的技术,通过训练大量的文本-图像对来学习从文本描述到图像的映射关系。
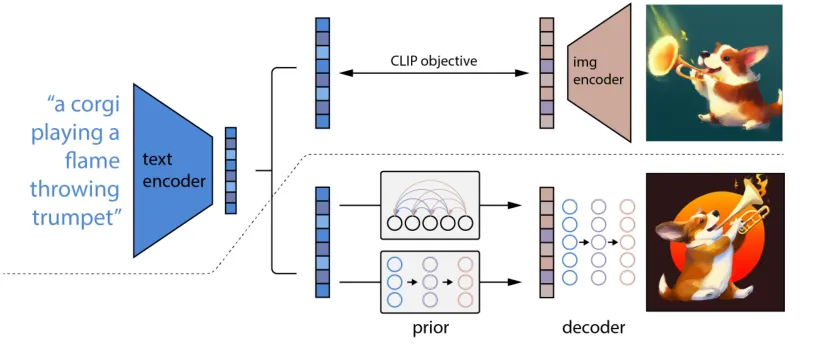
DALL-E2
Stable Diffusion:Stable Diffusion是一种基于潜在扩散模型的文本到图像生成模型。它能够根据任意文本输入生成高质量、高分辨率、高逼真的图像。Stable
Diffusion采用了更加稳定、可控和高效的方法来生成图像,因此在图像生成领域有着广泛的应用前景。

Stable Diffusion
—3—模型应用
High/Mid-level Vision
最近,将Transformer用于高级/中级计算机视觉任务。如目标检测,分割,姿态估计和车道检测的兴趣日益增长。
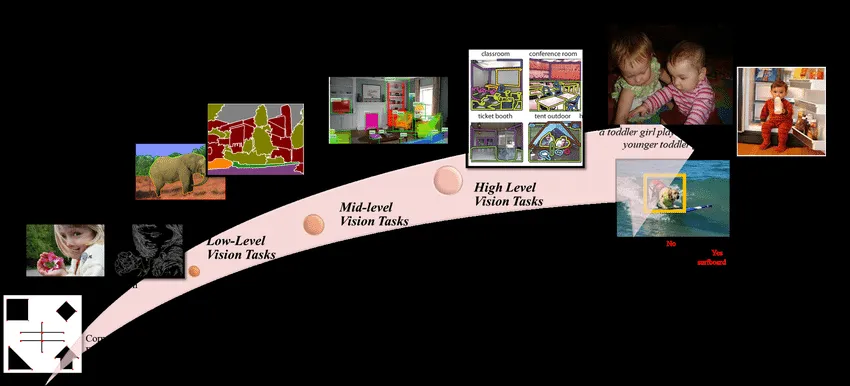
Vision Task Level
通用目标检测(Generic Object Detection):
基于Transformer的目标检测器以其独特的优势能力、创新的融合策略以及显著的性能提升,成为了当前目标检测领域的研究热点。
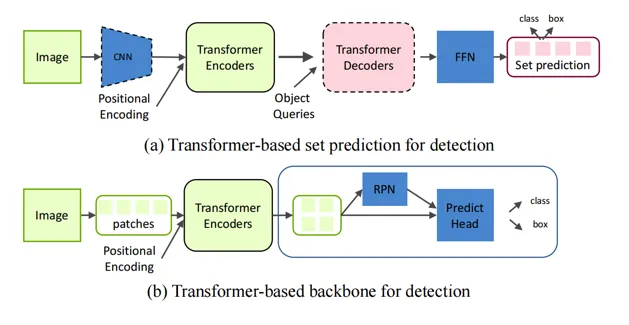
Generic Object Detection
传统与变革: 传统的目标检测器长期依赖卷积神经网络(CNNs)进行构建,但近年来,基于Transformer的目标检测器因其独特的优势而受到了广泛的关注和研究。
自注意力机制与模块增强:一些创新的目标检测方法开始尝试结合Transformer的自注意力机制,并针对性地强化现代检测器的特定模块,如特征融合模块和预测头。这种跨领域的融合尝试为目标检测领域带来了新的活力和可能性。
分类与特点: 基于Transformer的目标检测方法主要可以分为两大类。一类是基于Transformer的集合预测方法,这类方法通过Transformer的集合预测机制来提升目标检测的准确性;另一类是基于Transformer的主干方法,这类方法则将Transformer作为整个检测框架的核心主干,利用Transformer的强大特征提取能力来提升检测效果。
性能优势: 与传统的基于CNN的检测器相比,基于Transformer的检测器在准确率和运行速度方面都展现出了显著的优势。这主要得益于Transformer模型在处理全局依赖关系和长距离特征捕捉方面的独特能力。
分割(Segmentation):
分割是计算机视觉领域的一个重要话题,广泛涵盖了全景分割、实例分割、语义分割和医学图像分割等。视觉Transformer在分割领域也展现出了令人印象深刻的潜力。
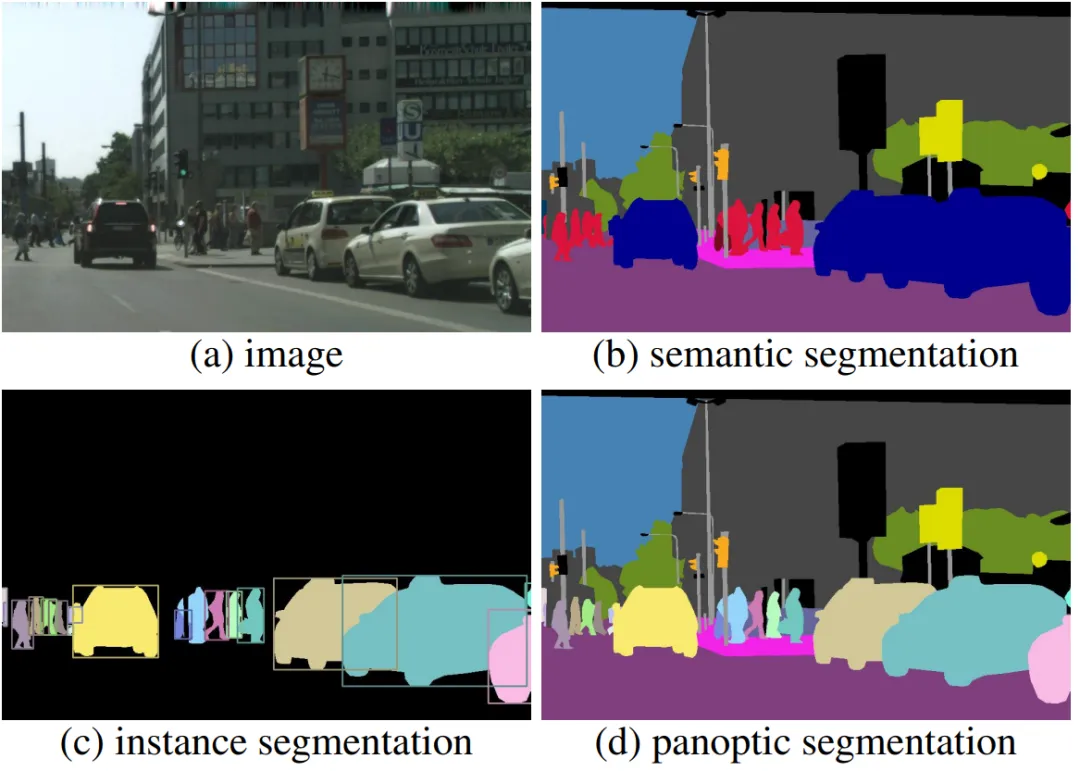 Segmentation的四种分类
全景分割Transformer:DETR不仅限于目标检测,还可以轻松迁移到其他任务,如全景分割。它考虑目标对象与全局图像上下文之间的关系,并直接并行输出最终的预测集合。
用于实例分割的Transformer:VisTR是一个基于Transformer的视频实例分割框架。它将视频实例分割任务视为一个直接的端到端并行序列解码/预测问题。VisTR通过预测视频中每个实例的掩码序列,实现了高效的实例分割。
语义分割Transformer:SETR是一个基于Transformer的语义分割框架。它利用Transformer的自注意力机制来捕获全局上下文信息,从而提高了语义分割的性能。
用于医学图像分割的Transformer:Cell-DETR是一个基于注意力的细胞检测变换器,专门用于医学图像中的细胞实例分割。它通过预测各个对象实例,提高了后验数据处理的实验信息产量,并使在线监测实验和闭环最佳实验设计变得可行。Cell-DETR在医学图像分割领域展现出了巨大的潜力。
姿态估计(Pose Estimation):
人体姿势和手部姿势估计是吸引研究界广泛关注的基础性课题。关节姿势估计类似于一个结构化预测任务,旨在从输入的RGB/D图像中预测关节坐标或网格顶点。利用Transformer来建模人体姿势和手部姿势的全局结构信息。
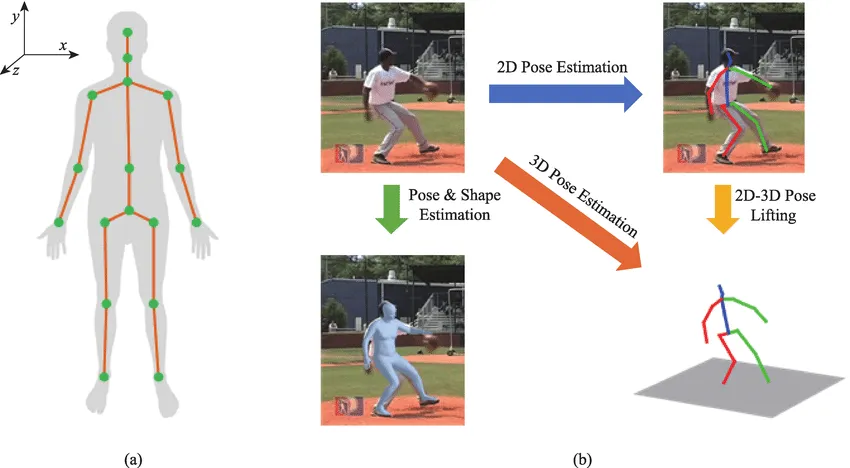
姿态估计(Pose Estimation)
手部姿势估计的Transformer:HOT-Net是一种用于3D手目标姿态估计的网络。它结合了Transformer和CNN的优点,能够从输入的RGB/D图像中直接预测3D手姿态。
人体姿势估计的Transformer:METRO是一种网格Transformer,它使用CNN提取图像特征,并通过将模板人体网格连接到图像特征来执行位置编码。这种架构能够预测3D人体姿态和网格,特别关注于人体关节和网格顶点的三维坐标。
车道检测(Lane Detection):
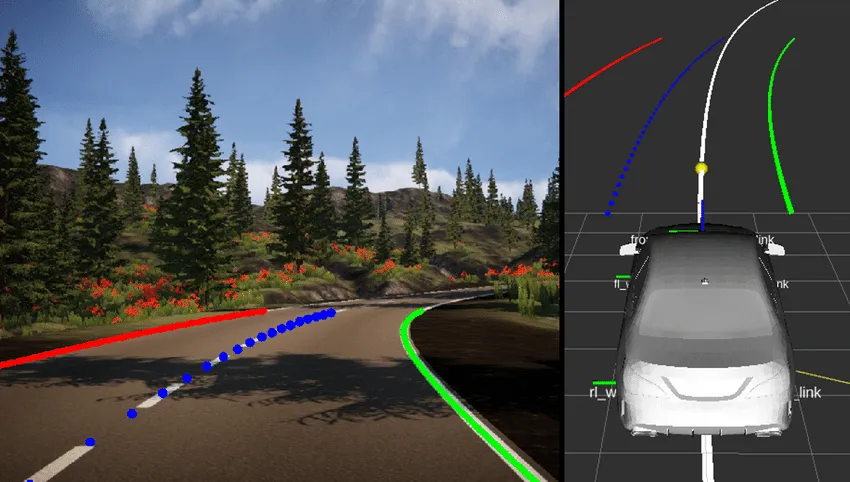
车道检测(Lane Detection)
LSTR是一个结合了Transformer网络和CNN的车道检测方法,通过全局上下文的学习和匈牙利损失的优化,实现了高精度、高速度和轻量级的车道检测性能。同时,引入的Transformer编码器结构进一步提升了上下文特征的提取效率,特别适用于细长和长距离的车道线检测。
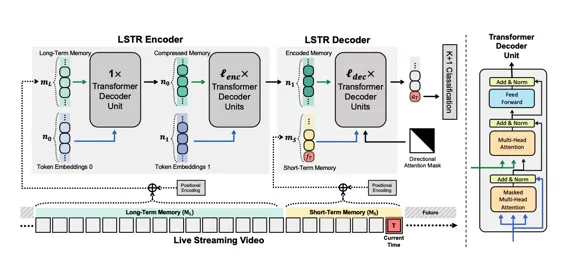
LSTR
|




