| 编辑推荐: |
本文主要介绍了GraphGPT:
大语言模型的图结构指令微调相关内容。希望对你的学习有帮助。
本文来自于微信公众号DataFunSummit,由火龙果软件Linda编辑,推荐。 |
|
01 背景介绍
图(graph)数据由节点和边组成的,以抽象表达实体之间的复杂关系。在我们的生活中有非常多的具体应用,例如推荐系统、社交网络以及药物发现等等。最近,深度学习的新型图神经网络被认为是建模图数据最有力的工具之一。然而,不同于图像像素可以有统一的
RGB 编码表示,自然语言可以由统一的词表向量表示,不同图之间的语义信息大不相同,这使得很难用一个统一的图神经网络来建模所有关系。另一方面,大语言模型通过在大量语料库上训练和加大模型参数的方法,展现出在各种自然语言处理任务上的惊人能力,尤其是利用可迁移的能力可以很好地完成从未见过的任务。
基于上述背景,我们希望让大语言模型能够理解图结构,并直接完成图结构相关的下游任务,例如最基础的 note
classification 和 link prediction。
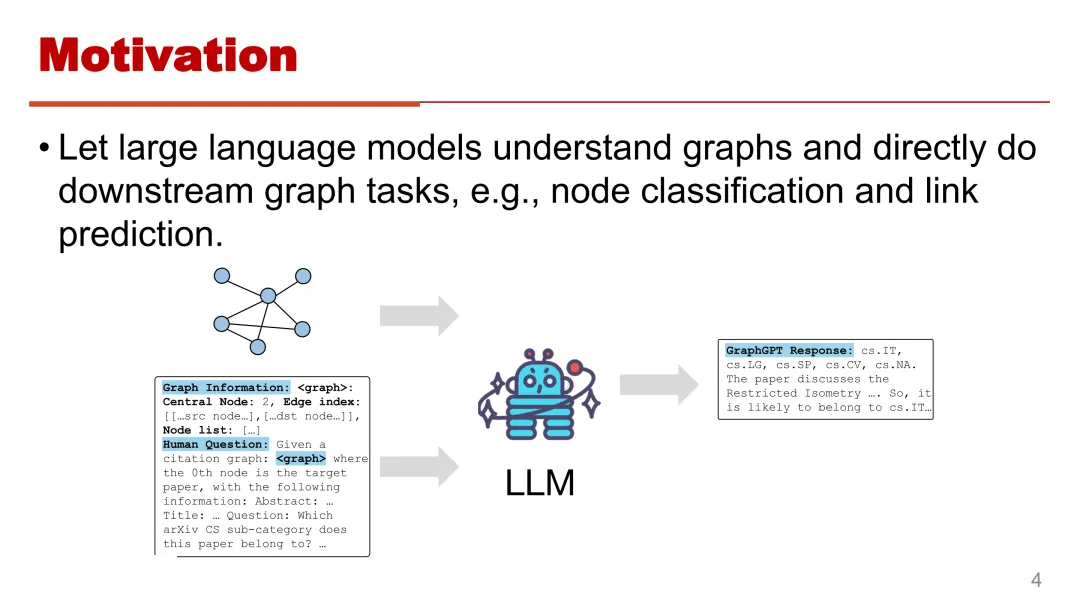
正如图中展示的,我们使用特定的格式将图结构输入给大模型,并输入这张图的背景信息,接着向大模型根据这张图结构进行提问,大模型可以直接给出回答。
然而如何有效地将 LLM 与 graph 结合,有以下几个不可回避的挑战和研究问题:

首先,如何有效地将 graph 输入到 LLM 中,是用自然语言的方式还是其他格式?
第二,如何赋予 LLM 理解 graph 的能力,让 LLM 与 graph 数据进行对齐?
第三,如何赋予大模型逐步推理以适应复杂的图学习下游任务的能力?
总而言之,我们的目标是让LLM 变成一个 zero shot 的 graph learner。
接下来将对上述问题逐一进行解答。
02
GraphGPT 解决方案
1. 如何将 graph 输入 LLM
对于第一个问题,如何将 graph 输入到 LLM 中,主要有三种解决方案。

第一种方案是不使用图结构,不提供邻居节点的信息,但我们发现即使使用目前效果最好的 ChatGPT,效果也欠佳,这意味着图中邻居的信息可能非常复杂也非常有用。
另一种方法是将基于文本的图结构输入到大语言模型中,文本在提示中描述了连接信息,然而这并没有解决错误的问题,而且使得输入到大语言模型的
token 长度过长,对于大语言模型来说,输入上下文的长度是非常有限的。
最后一种方法就是我们的 GraphGPT。我们可以只用 7B 的参数,有效地输入图,并且让大语言模型从图中学习。同时采用
GraphGPT 的范式,输入 LLM 的 token 也是可控的。
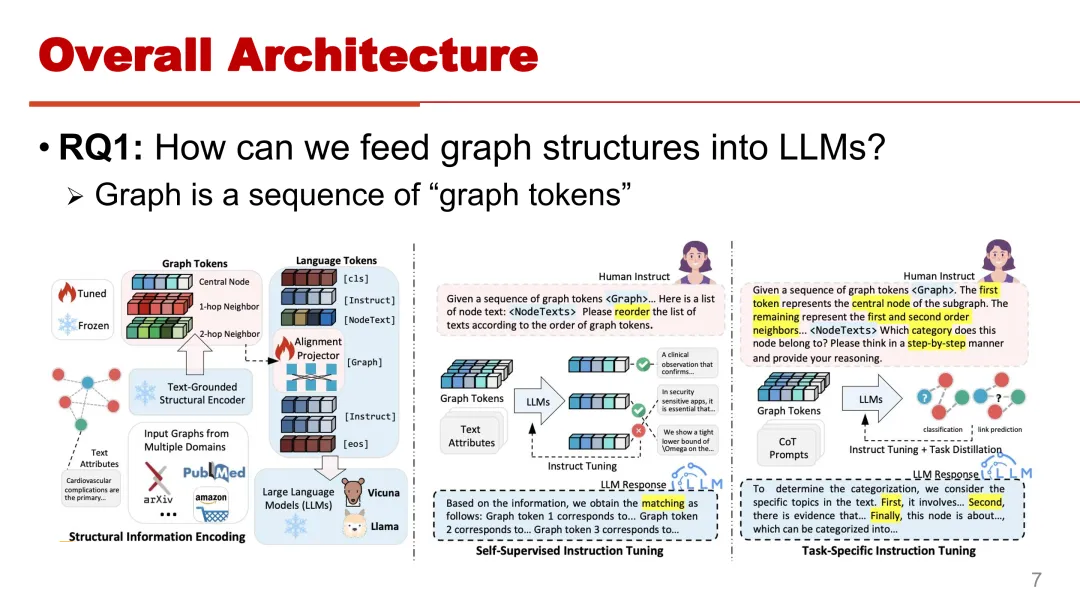
具体地,我们通过引入 graph tokens 来实现,将 graph 数据视为一系列的 graph
tokens。
整体框架如上图所示,图数据通过一个预训练的图编码器进行编码,这里的图编码器可以是任何图神经网络,例如图卷积神经网络
graph,transformer 等等。编码后的 graph embeddings 被输入到 Projector
中以获得 graph tokens。我们将这样得到的 graph tokens 和自然语言 tokens
合并输入给 LLM。以便让 LLM 理解图,并按照文本指令执行下游的任务,也就是进行了图与自然语言的对齐。
GraphGPT 的第一部分是 Text-Graph grounding。

为了更有效地将大语言模型与图结构对齐,我们探索了能与大语言模型良好协作的图结构编码的方式,即以对比学习的方式将文本信息融入到图结构编码的这个过程中。直接将带有预训练参数的图编码器集成到
GraphGPT 的这个模型框架中,无缝地整合了图编码器的功能。具体来说,图结构表征和文本表征通过如上图所示的公式,通过对比学习进行不同维度的
Text-Graph Grounding,以得到更好的可以和 LLM 合作的图编码器。
2. 如何赋予 LLM 理解 graph 的能力
第二部分为图指令微调的范式,旨在解决研究问题二,即如何赋予 LLM 理解 graph 的能力,让 LLM
与 Graph 数据对齐。这里的图指令微调范式主要包括两个阶段,第一阶段是使用自监督指令微调这样的机制。
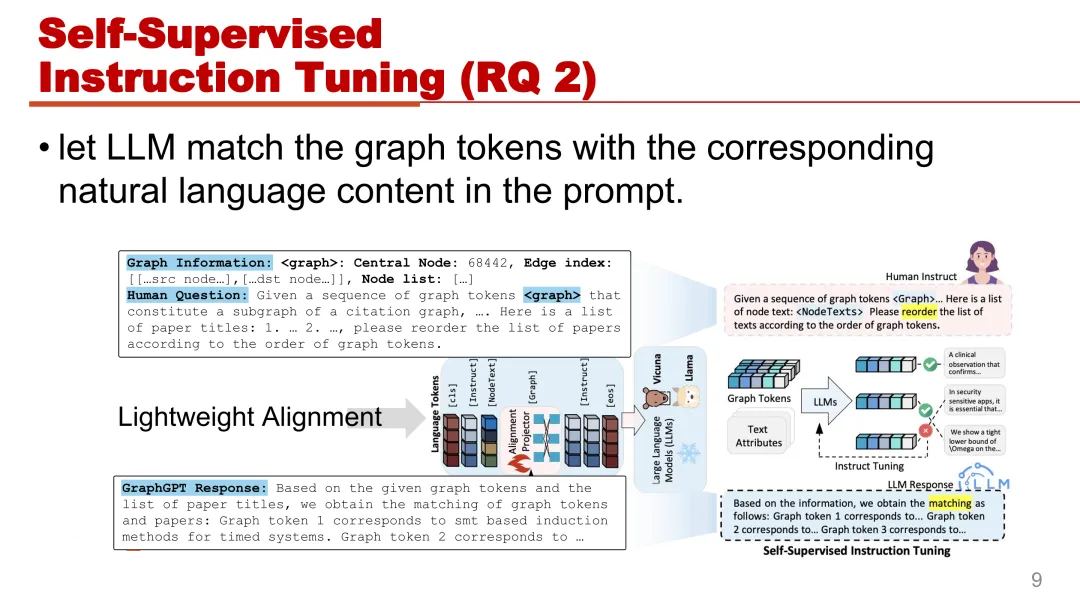
设计了一个结构感知的 graph matching(图匹配)任务,引导 LLM 使用自然语言来区分不同的图节点。这个指令微调在准确地将图节点与对应的文本描述关联方面起到了关键作用,加深了模型对图结构数据的理解。
图 graph matching 任务的指令主要包括两部分,一部分是 graph information(图信息),第二部分是
human question(人类问题)。将图中的每个节点视为中心节点,并执行 h 跳的随机邻居采样,从而得到了一个子图结构。LLM
的自然语言输入是人类问题(human question),在 graph matching 任务中,human
question 包括了一个指示符 graph token 和一个被打乱的节点文本信息列表,
例如在一个论文引用图中,节点的文本信息对应的就是论文的标题。大语言模型在graph matching
任务的目标就是将每一个 graph tokens 与相对应的节点文本信息做对齐。这需要大语言模型,根据
graph token 的顺序重新排列打乱的节点文本信息的列表,有效的将每一个 graph token
与其文本描述关联起来。
为了更高效的优化微调的过程,提出了一种轻量化对齐策略。就是在训练过程中,固定了 LLM 的参数和 graph
encoder 的参数,仅仅关注于优化前文提到的 Projector 的参数。
考虑到 graph matching 的过程是无监督的,这将有可能利用来自不同领域的大量未标注的图数据以增强学习到的
projector 的泛化能力。

在第二阶段,提出了一个特定任务的指令微调范式,即定制模型的推理行为,以满足不同图学习任务的特定约束和要求,例如
node classification 和 link prediction。通过使用任务特定的图指令对
LLM 进行微调,引导模型生成更适合当前图学习任务的回答。进一步提高了模型在处理各种不同图任务时的适应能力和性能。
为了为每个节点生成图信息,我们采用了和第一阶段相同的邻居采样的方法,对于节点分类任务人类指令(包括
graph token 和中心节点特定的文本信息),这个指令提示语言模型基于图结构数据和伴随的文本信息来预测中心节点类别。
在图中可以看到不同任务的指令数据的模板,例如 node classification 和 link
prediction。训练第二阶段采用第一阶段得到的 projector 的参数作为初始参数,
在训练过程中,保持了大语言模型和图编码器的参数不变,仅专注于优化前一阶段的projector 的参数,确保大语言模型进一步与下游任务对齐,增强其理解和解释图结构的能力。
3. 如何赋予大模型逐步推理以适应复杂的图学习下游任务的能力
第三部分,如何赋予大模型逐步推理以适应复杂的图学习下游任务的能力。

我们从闭源的 GPT 3.5 蒸馏得到思维链(Chain-of-Thought)。使得 GraphGPT
能够生成高质量的准确的回答,并增强了模型步推理能力,同时避免增加参数,对于论文引用图中的节点分类任务,将节点表示的论文摘要和标题以及分类任务的描述作为输入的一部分,使用
GPT 3.5 进行逐步推理,通过顺序思考的方式得到最终答案,并将生成的思维链指令数据与之前为特定任务设计的指令集成。进行图指令微调,使得我们微调得到的
GraphGPT 也拥有了像 GPT 3.5 一样的逐步推理能力。
4. 实验
接下来是一些实验结果。
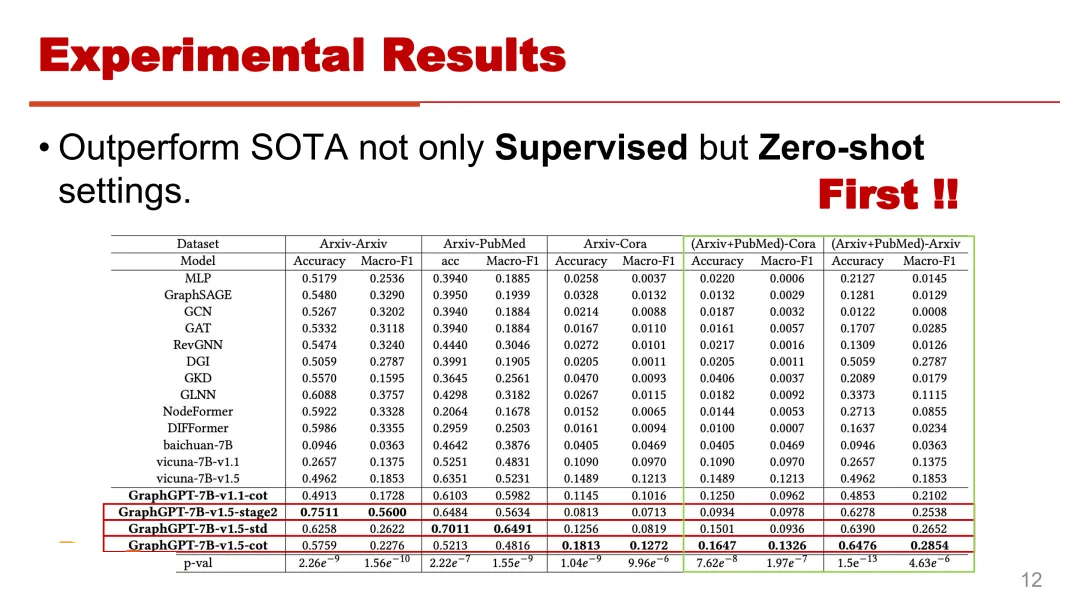
在总体性能方面,GraphGPT 在有监督和零样本场景都稳定超越了各种最先进的基线模型。值得注意的是,我们也是很早就提出了
Graph 领域进行 zero-shot 测试的一个工作。最近开发的强大的基于 GNN 的模型,例如
Nodeformer 和 GKD 这样的模型中,虽然在 supervised setting 下都展现出良好的结构建模能力,当他们被转移到没有进一步训练的新数据时,性能都出现显著下降。相比之下,GraphGPT
不仅在监督任务中超越了所有最先进的方法,而且在 zero-short 图学习场景中,实现了显著的两到十倍的准确率提升。
可以看到第一阶段指令微调的自监督graph matching 这个任务,对于增 GraphGPT 的
zero-shot 迁移能力起到了非常关键的作用。第一阶段的重点就是将编码了丰富结构的 Graph
token 与 nature language token 进行对齐,这种对齐使得模型能够更深入地理解
graph 数据固有的结构特性。如果没有指令微调 graph matching 任务,只进行特定任务的指令微调,那么模型会更容易在特定的数据上过拟合,向其他数据的迁移能力就不够好。由
STD 和 COT 的这两个变体表示使用思维链蒸馏对更复杂的图学习任务有更大的帮助,比如 STD 标准指令数据微调的模型,在转移到较简单任务比如只有三个类的
PubMed 数据集上,可以取得非常显著的效果,然而当其应用于更多分类的复杂任务比如 Cora,有
70 个类别的复杂任务时,其性能只是中等。
接着,针对模型的泛化能力,我们首先研究了数据量对 GraphGPT 迁移能力的影响。上图中可以看出,使用
Arxiv 和 PubMed 数据组合进行训练,并在 Cora 上进行 zero-shot 测试,结果显示,通过结合较小的
PubMed 数据集,GraphGPT 在 Cora 上的性能获得了非常显著的提高。相比之下,单独在
Arxiv 和 Pub Med 上训练基于 GNN 的模型,其迁移能力就有所下降。我们进一步验证了
Arxiv 和 PubMed 这样组合的指令数据,在原始 Arxiv 上的数据性能。结果显示大多数传统基于
GNN 的方法在 Arxiv 上经过迭代训练性能显著下降了,相比之下 GraphGPT 的性能反而变得更好。我们将这一现象归因于基于
GNN 的模型中发生了灾难性遗忘问题,即在较小的 PubMed 的数据上训练之后,其在 Arxiv
上的建模能力受到了损害。

我们进一步探究了混合不同指令微调数据对模型的影响。在确保指令条目数量一致的情况下,我们混合了不同类型的指令数据,包括
50% 的标准指令(STD)和 50% 的 Chain-of-Thought 指令数据,以及 Node
classification 混合 link prediction 数据。
结果如上图所示,有效的数据混合的方法,可以显著的提高 GraphGPT 在各种设置下的性能。添加 Link
prediction 指令后,显著提高了模型在 Node classification 中的性能。在加入
Node classification 之后,Link prediction 性能也超过了原有的模型。
在混合了不同任务的指令后,模型展现出了可以有效处理各种图学习任务,并将知识转移到其他未见数据之上的迁移能力。

接下来是消融实验,我们先采用了变体 without GS,讨论了将图结构纳入到 LLM 中的好处。在这个背景中,我们直接采用了
LLM 基座在三个数据上进行节点分类,而不纳入图结构信息,结果显示 GraphGPT 明显优于缺乏结构信息的基座模型。这表明提出的
Graph Instruction Tuning 的范式使得 LMM 能够更有效的处理 Graph
结构信息。
通过使用默认的图结构编码器(Graph Encoder)进行编码,进行有监督和零样本预测,来评估 LLM
推理能力对 GraphGPT 的影响。这个变体被称为 without LR。实验结果表明,整合了 LLM
的 GraphGPT 显著提高了 Graph Encoder 的性能,特别是在 zero shot
场景下,表明 LLM 注入了丰富的语义,其建模能力可以显著提高 GraphGPT 的迁移能力。
我们也进行了模型训练效率的研究。我们在一个四卡的 40G A100 环境中对冻结和微调 LLM 参数方面进行了比较,该研究分析在训练时间、微调参数和
GPT 占用这三个方面的时间和空间效率。在相同的实验条件下微调 LLM 参数时,即使我们把Batchsize
设为 1,也会遇到 GPU 内存不足的问题。然而,使用我们提出的轻量化的微调策略,即使使用 Batchsize
为 2,训练过程中也会非常稳定。此外,与全量微调 LLM 相比,我们提出的微调策略参数量减少了 50
倍以上。
在推理效率方面,通过与百川 7B 和 vicuna 7B 进行对比,评估了 GraphGPT 的推理速度和准确率。实验使用单张
40G100 进行测试。测量了在 Arxiv 和 Cora 数据集上的推理时间。结果表示 GraphGPT
展现出了非常卓越的效率和准确率。

最后是模型案例研究。实验使用的是 Arxiv 数据,对 ChatGPT 和 GraphGPT 使用了不同类别的指令,包括仅使用节点内容(标题和摘要);第二种是带有基于文本的图结构的描述;第三种是本文使用的
graph instruction。结果表明,尽管 GraphGPT 的参数量非常大,但仅基于节点文本信息或者带有基于文本的图结构进行预测仍然是非常困难的,尤其是对于处理具有高度交叉学科特性的论文。
相比之下 GraphGPT 可以始终提供非常准确的预测,并提供合理的解释,这是因为GraphGPT
接受了一个带有 103 个节点的子图结构,允许它从邻近节点的引文关系中获取非常丰富的结构信息。
03
思考与展望
首先,在图学习领域如何构造图学习领域的基础模型一直是一个悬而未定的问题,这是由于不同图结构的语义存在较大区别,无法用一个统一的模型进行跨数据、多任务的图结构建模,若利用大语言模型强大的语言建模能力,同时用图指定微调的方法使大语言模型拥有了结构理解能力,我们认为可以作为图基础模型的一个可行的发展方向。
另外,由于不同图结构之间的结构关系无法像 NLP 中一样,转化为统一词向量表示或者 CV 像素表示,如何定义和开发
data-centric 的图学习也一直没有定论。我们在实验中发现 GraphGPT 可以在混合多种数据的情况下彰显出更强的准确率、泛化率和多任务能力,从而缓解传统图神经网络的灾难性遗忘问题。
最后,我们也在一直更新我们的 github 仓库,最近更新了在两张
3090GPU(24G)上就可以高效训练 GraphGPT 的脚本。
|






 订阅
订阅