| 编辑推荐: |
本文介绍了系统评价——数据指标的规范化处理相关内容。希望对你的学习有帮助。
本文来自于博客园,由火龙果软件Linda编辑,推荐。 |
|
在多指标评价体系中,由于各评价指标的性质不同,通常具有不同的量纲和数量级。当各指标间的水平相差很大时,如果直接用原始指标值进行分析,就会突出数值较高的指标在综合分析中的作用,相对削弱数值水平较低指标的作用。因此,为了保证结果的可靠性,需要对原始指标数据进行规范化处理。目前数据规范化方法有多种,归结起来可以分为直线型方法(如极值法、标准差法)、折线型方法(如三折线法)、曲线型方法(如半正态性分布)。不同的规范化方法,对系统的评价结果会产生不同的影响,然而不幸的是,在数据规范化方法的选择上,还没有通用的法则可以遵循。
!!!数据规范化前要注意数据的属性(极大型、极小型、中间型)以及数据发展变化规律(正指标、负指标)。
一、数据指标为什么要规范化?
数据指标的规划化实质是一种线性变换,线性变换有很多良好的性质,这些性质决定了对数据改变后不会造成“失效”,反而能提高数据的表现,这些性质是归一化/标准化的前提。比如有一个很重要的性质:线性变换不会改变原始数据的数值排序。
数据的量纲不同,数量级差别很大
经过规范化处理后,原始数据转化为无量纲化指标测评值,各指标值处于同一数量级别,可进行综合测评分析。如果直接用原始指标值进行分析,就会突出数值较高的指标在综合分析中的作用,相对削弱数值水平较低指标的作用。
避免数值问题:太大的数会引发数值问题。
平衡各特征的贡献
一些分类器需要计算样本之间的距离(如欧氏距离),例如KNN。如果一个特征值域范围非常大,那么距离计算就主要取决于这个特征,从而与实际情况相悖(比如这时实际情况是值域范围小的特征更重要)。
一些模型求解的需要:加快了梯度下降求最优解的速度
在使用梯度下降的方法求解最优化问题时,规范化后可以加快梯度下降的求解速度,即提升模型的收敛速度。
二、指标预处理——转化为正指标
选取合理的评价指标是综合评价问题的第一步,要考虑四个准则——代表性、确定性、独立性、区别能力。
代表性:各层次指标能最好地表达所代表的层次;
确定性:指标值要确定、可量化,高低在评价中有确切的含义;
独立性 :选定的指标要互相独立,不能相互替代;
区别能力/灵敏性:指标有一定的波动范围。
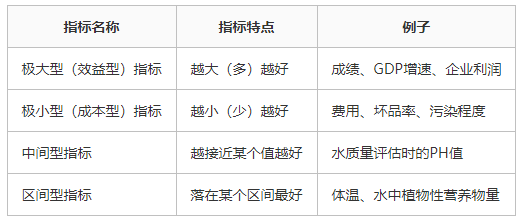
2.1 指标的属性分类
在我们选取的众多评价指标中,有些指标数值越大越好(“极大型”指标),有些指标越小越好(“极小型”指标),有些指标是在一定范围内(“区间型”指标)。
极大型指标:总是期望指标的取值越大越好;
极小型指标:总是期望指标的取值越小越好;
中间型指标:总是期望指标的取值既不要太大,也不要太小为好,即取适当的中间值为最好;
区间型指标:总是期望指标的取值最好是落在某一个确定的区间内为最好。
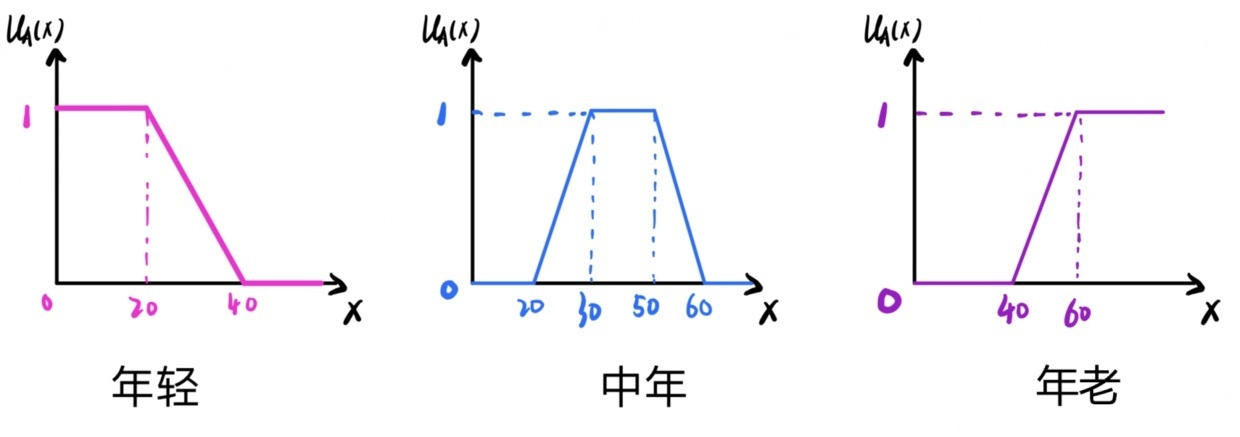
例如我们在期末进行综合测评时,评价指标中有学习成绩、缺课率等,学习成绩这项指标是取值越大越好,是极大型指标,学习成绩越高,综合测评得分相应越高;缺课率这项指标是越小越好,是极小型指标,缺课率越高,综合测评得分越低。因此,我们需要对指标进行一致化处理,将所有的指标转化为极大型指标或者极小型指标。
2.2 指标的转化公式
极大型指标(效益类指标),也就是正指标,不做处理
极小型指标(成本类指标):
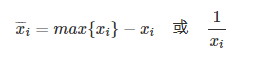
中间型指标:
中间型指标的特点:指标的值既不要太大也不要太小,取某个特定的值最好(例如:评估水质量用到的PH值)
{xi}是 一组中间型指标序列,且最佳的数值为xbest, 那么正向化的公式如下:
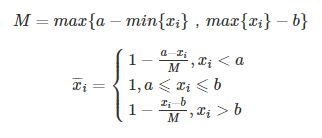
区间型指标:
{xi}是一组区间型指标序列,且最佳的区间为[a,b],那么正向化的公式如下:
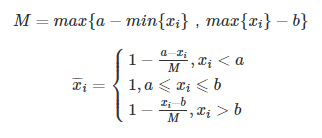
三、数据规范化方法
数据的规范化(normalization)是将数据按比例缩放,使之落入一个小的特定区间。在某些比较和评价的指标处理中经常会用到,去除数据的单位限制,将其转化为无量纲的纯数值,便于不同单位或量级的指标能够进行比较和加权。其中最典型的就是数据的归一化处理,即将数据统一映射到[0,1]区间上,常见的数据归一化的方法有:min-max标准化(Min-max
normalization),z-score标准化(zero-mena normalization,此方法最为常用),模糊量化法。
3.1 min-max规范化(Min-maxnormalization)
也叫离差标准化,是对原始数据的线性变换,使结果落到[0,1]区间,转换函数如下:
对序列x1,x2,...,xn进行变换
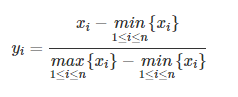
则新序列y1,y2,...,yn∈[0,1]且无量纲,不同类型的数据加权时都要进行规范化处理。
离差标准化
其中max为样本数据的最大值,min为样本数据的最小值。
这种方法有一个缺陷就是当有新数据加入时,可能导致max和min的变化,需要重新定义。
3.2 z-score规范化(zero-meannormalization)
并不是所有数据规范化的结果都映射到[0,1]区间上,其中最常见的标准化方法就是Z标准化,也叫标准差标准化。通过规范化,令数据的平均值为
0,标准化为1的标准化方法,在经济社会、传播学研究中使用普遍,公式如下:
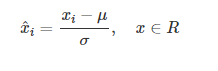
其中μ为样本均值, σ为样本标准差。
优点:
保留数据真实距离,维持标准化前数据分布,缩放均为等比例缩放。
标准化后数据的平均值为0,标准化为1。
对极值不敏感。
缺点:
标准化后数据不在固定范围内,如用作指标体系计算还需要进一步标准化。
样本标准化后值不稳定,受样本平均值和标准差影响;当添加新样本时,旧样本的标准化值一定发生变化。
3.3 Sigmoid 函数规范化
如果数据呈现中间集中的分布,同时需要将区分中心部分的差距,可以使用 Sigmod 函数进行标准化,公式如下:
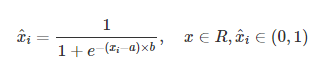
其中系数a为需要区分部分中心的值,系数b为需要区分的程度。
优点:
扭曲了原数据,扩大(加强)了某个中心附近的样本值之间的差距,缩小(减弱)了距离该中心较远的样本值之间的差距。
对极小值和极大值均完全不敏感。
样本标准化后的值稳定,不受样本最大值和最小值的影响。
缺点:
对距离中心较远的样本值之间的差距 非常 不敏感。
3.4 归一化处理
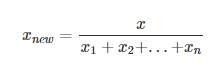
对正数进行变换,使结果落到[0,1]区间,其将数值的绝对值变成相对值关系
3.5 模数单位化
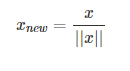
将每个样本的特征向量除以其长度,即对样本特征向量的长度进行归一化,长度的度量常使用的是L2 norm(欧氏距离),有时也会采用L1
norm。
四、几种规范化方法的比较
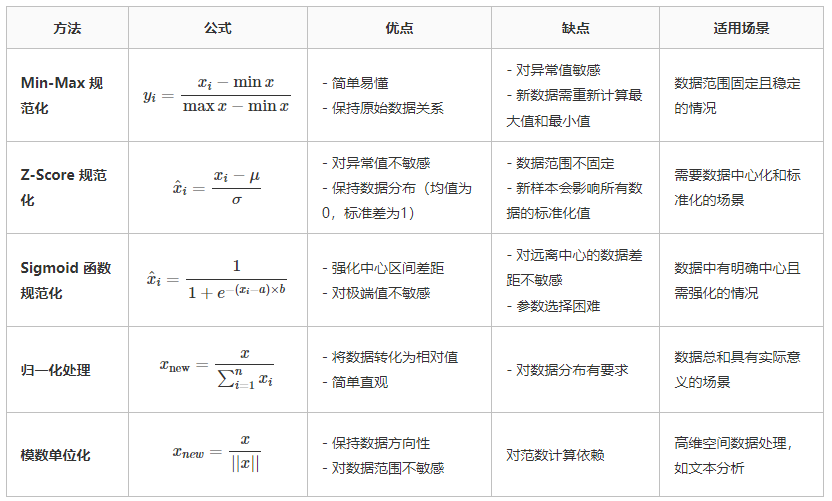
总的来说,规范化/归一化/标准化的目的是为了获得某种“无关性”——偏置无关、尺度无关、长度无关……当规范化/归一化/标准化方法背后的物理意义和几何含义与当前问题的需要相契合时,其对解决该问题就有正向作用,反之,就会起反作用。所以,“何时选择何种方法”取决于待解决的问题,即problem-dependent。
总结
评价是现代社会各领域的一项经常性的工作,是科学做出管理决策的重要依据。随着人们研究领域的不断扩大,所面临的评价对象日趋复杂,如果仅依据单一指标对事物进行评价往往不尽合理,必须全面地从整体的角度考虑问题,多指标综合评价方法应运而生。评价往往是由多个评价指标构成的,而这些评价指标往往具有不同的属性、数量级和单位,这导致我们无法对不同的指标进行比较、加权、求和等种种后续操作。假设各个指标之间的水平相差很大,此时直接使用原始指标进行分析时,数值较大的指标,在评价模型中的绝对作用就会显得较为突出和重要,而数值较小的指标,其作用则可能就会显得微不足道。因此,为了消除不同评价指标之间存在的差异,统一比较的标准,就需要对数据进行标准化处理,消除不同指标之间因属性不同而带来的影响,从而使结果更具有可比性。
|






 订阅
订阅