| 编辑推荐: |
本文从原理、模型演进到代码工程实践,全面探讨了人工智能领域的核心内容。希望对你的学习有帮助。
本文来自于微信公众号大淘宝技术,由火龙果软件Linda编辑,推荐。 |
|
本文从原理、模型演进到代码工程实践,全面探讨了人工智能领域的核心内容。通过深入浅出的讲解,笔者不仅介绍了神经网络的基本原理,还详细阐述了Transformer模型的实现机制及其在自然语言处理(NLP)中的应用。文章结合了实际案例和代码示例,旨在帮助读者理解AI技术的全貌,并能够在实际项目中应用这些知识。
01
初探神经网络(原理)
▐ 神经网络
讨论ChatGPT前,需要从神经网络开始,看最简单的“鹦鹉学舍”是怎么实现的。
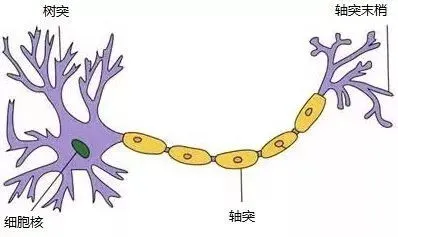
上图就是一个人脑的神经元,由多个树突、轴突和细胞核构成,其中树突用来接收电信号、经细胞核加工(激活)信号、最后由轴突输出电信号,人脑大概860亿个神经元细胞,突触相互连接,形成拓扑结构。
每个神经元大约有1163~11628个突触,突触总量在14~15个数量级,放电频繁大约在400~500Hz,每秒最高计算量大约40万亿次,换算成当前流行词汇,大脑大概等价于100T参数模型(140B逊爆了),而且有别当前大模型中ReLU激活函数,大脑惰性计算是不用算0值的,效率更高。
神经网络就是借鉴了人脑神经元输入、计算、输出架构和拓扑设计,下面以一个求解数学问题的例子,看神经网络的实现原理:
当X为 时,Y为 时,Y为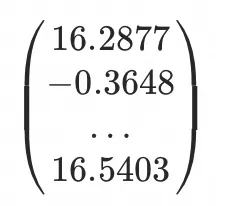 ,通过训练神经网络,以求得X和Y的隐含关系,并给出X为 ,通过训练神经网络,以求得X和Y的隐含关系,并给出X为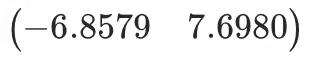 时,Y的值。 时,Y的值。
为了看训练过程,我们提前知道 f(x)=x1*w1+x2*w2+b,其中w1=w2=1, b=6.6260693,实际上是可以任意
f(x)
训练过程如下:
1. 对输入的X,分解成n个向量(举例方便,实际是直接矩阵计算,实现batch),对每个向量的X1和X2元素,假定一个函数
f(x)=x1*w1+x2*w2+b 进行计算(其中w1、w2和b用随机值初始化)。
2. 用假定的 f(x) 计算X,得到结果和样本Y进行比照,如果有差异,调整w1、w2和b的值,重复计算。
3. 直到差异收敛到某个程度后(比如小于1),训练结束。
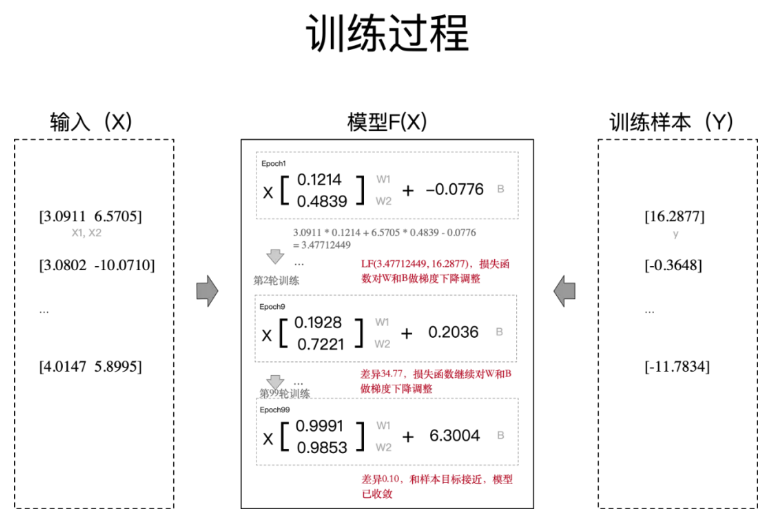
从训练过程看,经过99轮重复计算和调整W/B值后(训练),在100轮通过瞎猜求得 f(x)=x1*0.9991+x2*0.9853+6.3004,用最后一个组数据
X 计算得到的已经很接近样本数据,说明这些参数(模型)在这个场景已经对 f(x) 求得最优解了。

对X (-6.8579 7.6980)进行预测Y为 7.0334,和最初假定(w1=w2=1,b=6.6260693)参数计算得到的结果仅相差0.2左右,预测结束。
上述代码如下:
from
torch import nn
from torch.optim import Adam
import torch
model = nn.Linear(2, 1) # 模型定义,内部是 2 * 1的矩阵
optimizer = Adam(model.parameters(), lr=1e-1)
loss_fn = nn.MSELoss()
## 输入是 10 * 2矩阵,可以理解为10个样本输入,每个样本是一对值组成,譬如:样本A(0.3,0,6)
样本B(0.2,0,8)
## 目标是 10 * 1矩阵,可以理解为10个样本对应的值, 这里简单把每个样本的两个值相加,并加入一个随机变量。
## 对于单个变量, Y = sum[x1,x2] + 随机值, 希望模型能够学会的是
Y = w1 * x1 + w2 * x2,这里的w1, w2就是模型的2*1矩阵的两个值,希望w1、w2最终学为1
input = torch.randn(10,2) * 10
#普朗克常数
bias = 6.6260693
target = torch.add(input.sum(dim=1, keepdim=True),bias)
print('训练样本输入',input,'\n训练样本输入-偏移量', bias,
'\n训练样本目标值', target)
print("\n模型内部参数的初始随机值")
for name, param in model.named_parameters():
print(name, param.data)
print("\n开始训练,会发现差异值越来越小,说明模型在收敛")
for epoch in range(100): # 练习100轮
pred = model(input) # 输入 10*2 乘积模型的 2*1 得到预测值
10*1
loss = loss_fn(pred, target) # 和目标值差异
# 根据差异,修正模型参数。就是调w1, w2两个参数
optimizer.zero_grad()
loss.backward()
optimizer.step()
if epoch%10==9:
print (f"Epoch: {epoch} | loss: {loss:.2f}")
# 拿一对随机值,测下模型, 是否产出值 = sum([x1,x2])
test = torch.randn(1,2) * 10
target = test.sum(dim=1, keepdim=True)
pred = model(test)
print('\n训练完毕,测试模型。\n可以看到预测值和目标值近似,说明模型训练成功\n测试输入:',test,
'模型预测:',pred.detach(), '目标值:', target)
print("\n可以看到经过训练后的模型值w1、w2接近于1")
for name, param in model.named_parameters():
print(name, param.data)
|
▐ 损失函数&梯度下降
在训练过程中,会不断的通过调整W和B参数进行模型构建,进行目标拟合,得出参数过程需要解决两个问题:
如何判断收敛状态
如何参数调整方向和值

参数的调整(加多少,减多少)是通过梯度下降方式实现的,也就是通过求一阶导数,来看函数单调性(一阶导数>0,函数单调递增,函数值随自变量的增大而增大)。

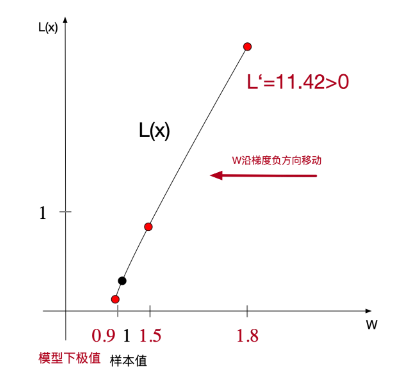
对X (-6.8579 7.6980)进行预测Y为 7.0334,和最
方向确定后,每次迭代调整的值,就变成在w轴上无限趋近极值的导数值 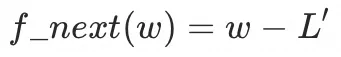
对X (-6.8579 7.6980)进行预测Y为 7.0334,和最,在曲率大的地方大幅快速,小的地方小幅趋近。
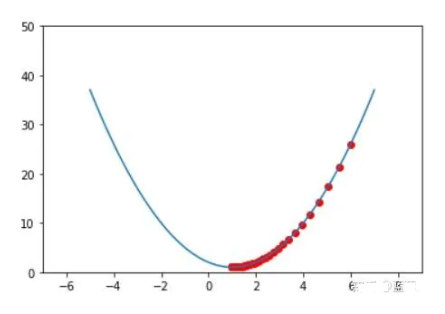
当函数变复杂起来,极值的查找,靠的是初始值运气,不一定每次都能找到最优解。
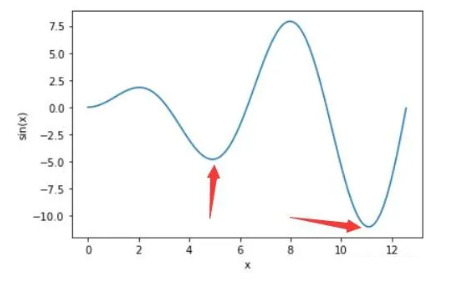
在更复杂的场景,比如上面的二元函数拥有两个主要自变量(x1,x2),在图像上表现如下:
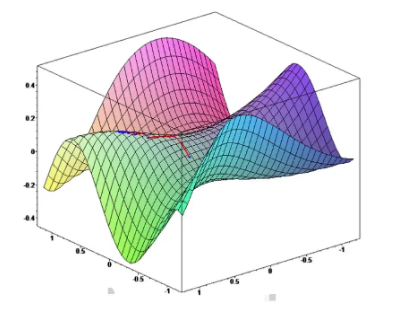
这个时候准确来说 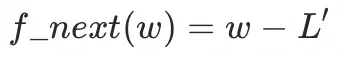 ,L'是多元中w1的偏导。 ,L'是多元中w1的偏导。
无法同时得出w1、w2和b的最优解,也就是全局最优解是无法得出的,最理想的情况就是假定w2和b为最优解的情况下,求w1最优解,然后再已w1最优解和假定b为最优解的情况下,求w2最优解,这样求出来的是局部最优解。
为了防止L'导致迭代幅度过大,会再乘以一个小数,最终 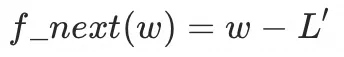 (lr:learning rate,一般设置0.01~0.001)。 (lr:learning rate,一般设置0.01~0.001)。
lr的设定大小会影响效果和成本,简要说设大了会导致每次猜测幅度过大而导致的忽略了很多候选参数,跳过了最优值,这是对训练效果而言,同时对成本也会造成参数选值的震荡(围绕极优值来回摆动)而无法收敛,而设置小了容易在L(w1,w2,b)
函数曲线多凸情况下,陷入局部的极小值,而无法发现整体的极小值,同时也导致了训练时长和深度的增加,也会在局部极小值消耗过多成本。
▐ W 和 B
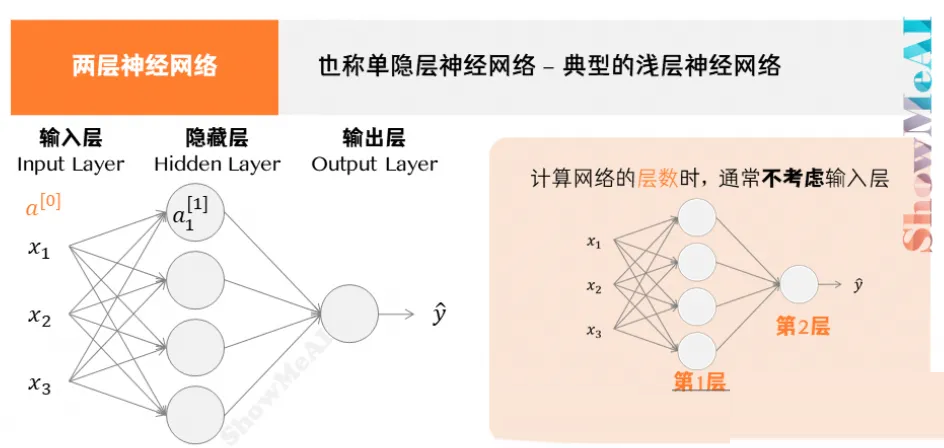
上面的例子是最简单的单层(浅层)神经网络,其中神经元是神经网络中最基本的单元,最小设定就是 f(x)=x*w+b,通过拓扑设计来满足不同输入输出矩阵形状和拟合度(对可能的任意f(x)拟合)。
这个模型对问题求可能的解、接近最优解的解以及最优解,不是函数在数学意义的上解。模型中W代表着权重(weight),B代表着阈值(threshold),当一或者多个input经过一个神经元最终输出一个output过程中,通过W调整不同input做加权,最后通过B控制输出的偏移完成整个计算的抽象。
举个例子,城里正在举办一年一度的动漫展,你在犹豫要不要参加,考虑的因素有天气、价格、有没有同伴,规则是只要天气不好,不管价格和同伴都不去,如果天气还不错,但价格不合适,有朋友也不去。

(权重举例1、2、4可以保证三因子之和可枚举所有规则,方便设阈值,不是真正权重比例,四因子是1248)
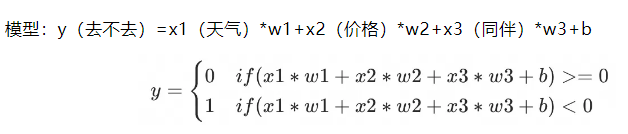
▐ 激活函数
上面例子只需要只输出0和1,但是训练多层网络,不断迭代微调W和B时,只返回0和1是无法实现0到1之间的状态决策逻辑(输出太不敏感了)。
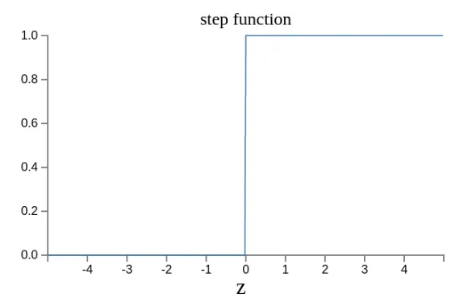
为了让输出能够平滑0到1的中间态,需要对结果进行连续性,对y进行改造成 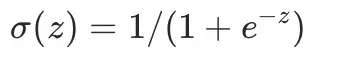 ,改造后,原先[0,1]被转换成(0,1),形成一个连续性结果。 ,改造后,原先[0,1]被转换成(0,1),形成一个连续性结果。
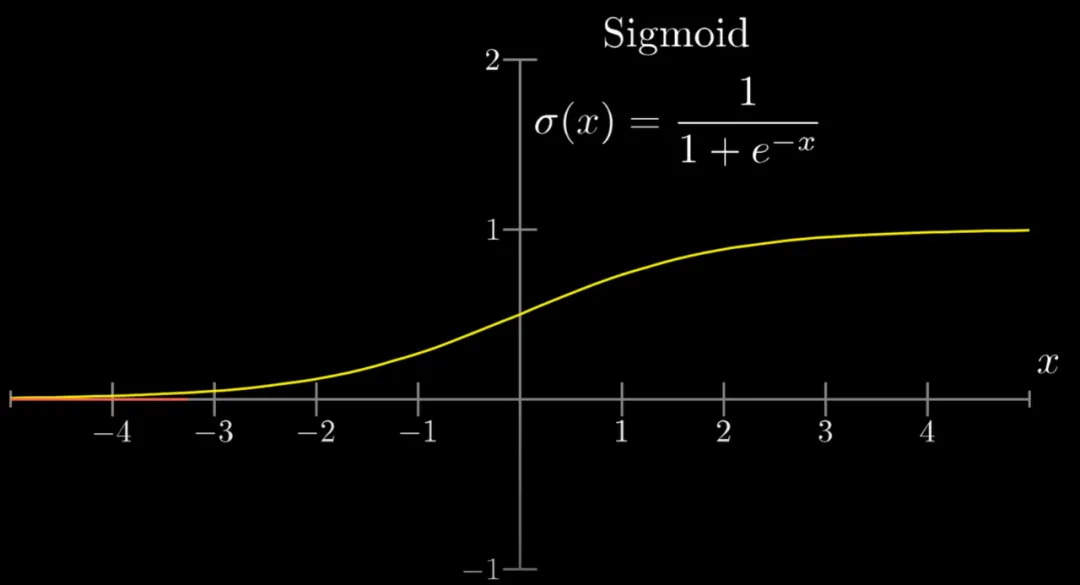
这个就是Sigmoid激活函数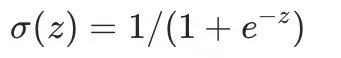 ,优点输出空间在(0, 1),缺点是左右两侧导数趋0,会出现梯度消失(下文讲),不利于训练,其他的主流的激活函数还有ReLU
f(x)= max(0, x),tanh、ELU等函数。 ,优点输出空间在(0, 1),缺点是左右两侧导数趋0,会出现梯度消失(下文讲),不利于训练,其他的主流的激活函数还有ReLU
f(x)= max(0, x),tanh、ELU等函数。
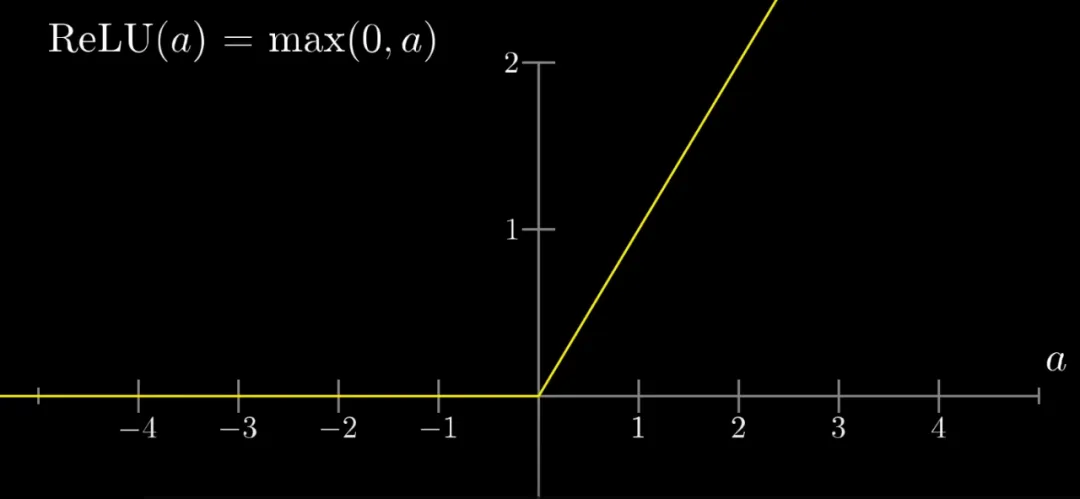
激活函数主要是讲结果非线性化,放大参数对特征识别的灵敏和多样性,不同的激活函数除了非线性转换外,主要的区别是计算效率,解决梯度消失,中心值偏移这些问题。
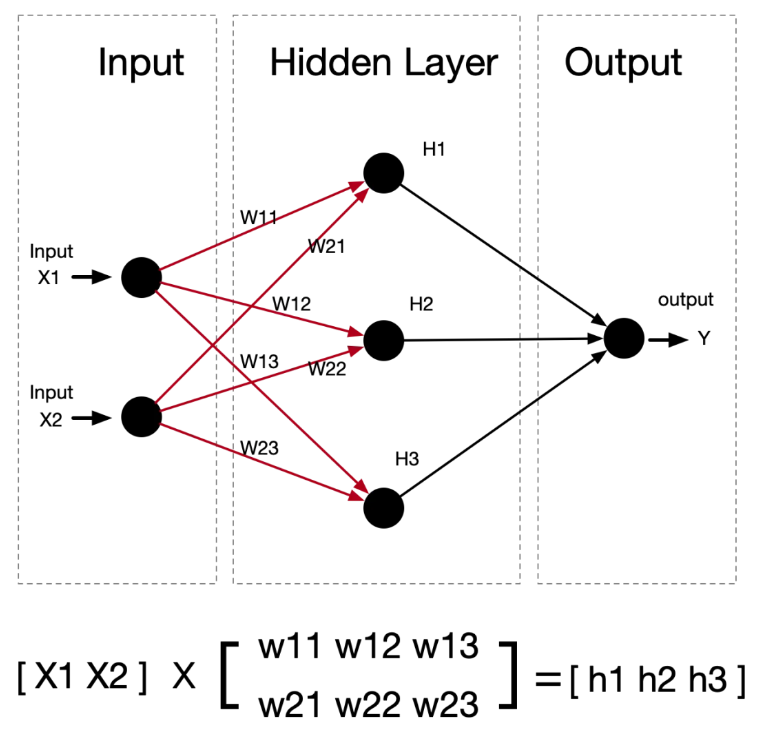
前面的例子是1x2的矩阵输入,1x1的矩阵输出,当输入是多维信息,例如一个人身高、年龄、工作、发量等等的时候,期望输出也是多维,例如感兴趣科目、愿意购买商品等等时,就需要讲神经元重新规划拓扑结构,实现线性变化,形成类似下面复杂的网状结构。
当为了更好的拟合,以及引入运行时中间计算,也会调整拓扑,所以实际上整个网络会变得异常庞大(深层神经网络),例如ChatGPT4有1.8万亿的参数,这里的参数就是指训练后W和B的总和(红线部分),一共1.8万亿。
这些训练后(包括fine-tuning)的参数被全部持久化后,大概代表已经吸收多少知识储备和推理潜力。
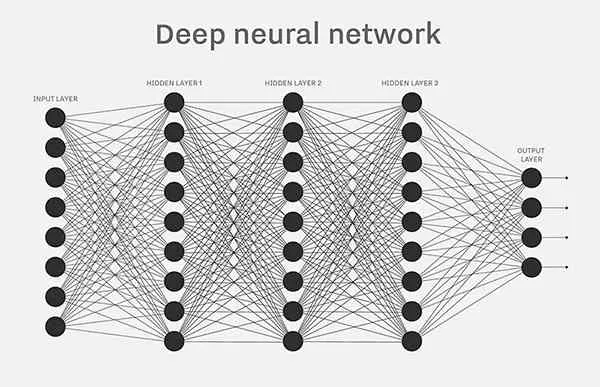
这就是最基础的神经网络实现原理。
02神经网络模型演进(模型)
在此gpt之前,图片识别、NLP等场景已经有成熟的CNN、RNN等神经网络模型,但这两种神经网络存在的两个问题限制了模型应用的突破。
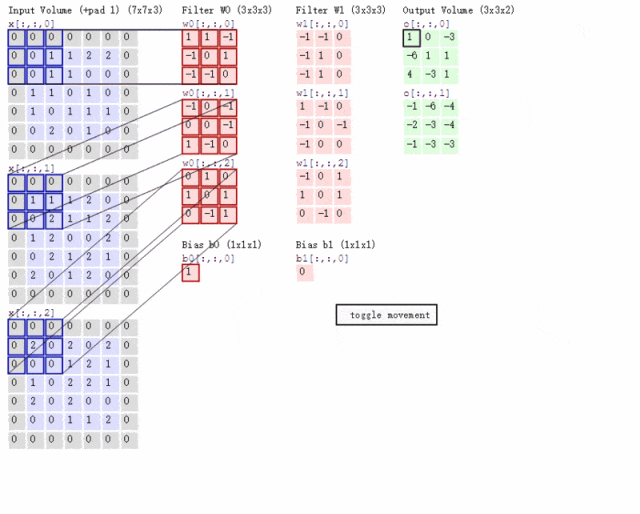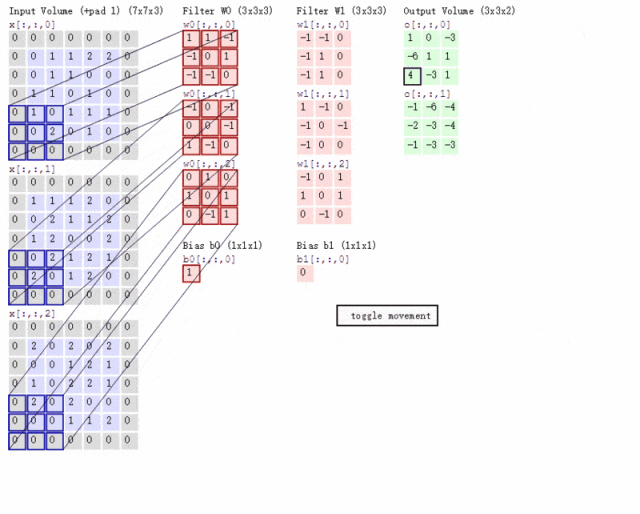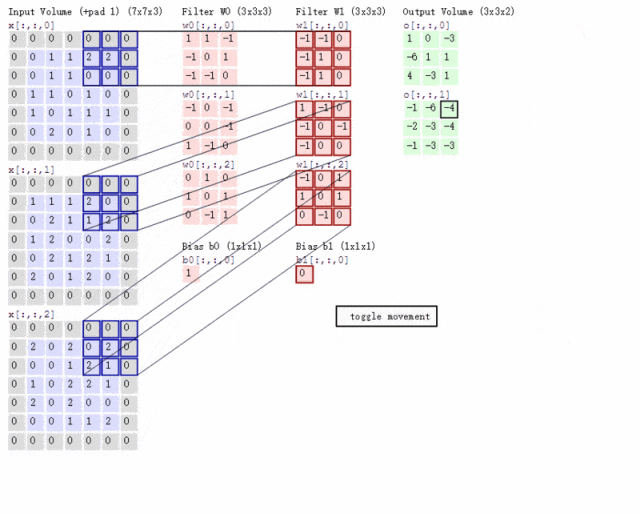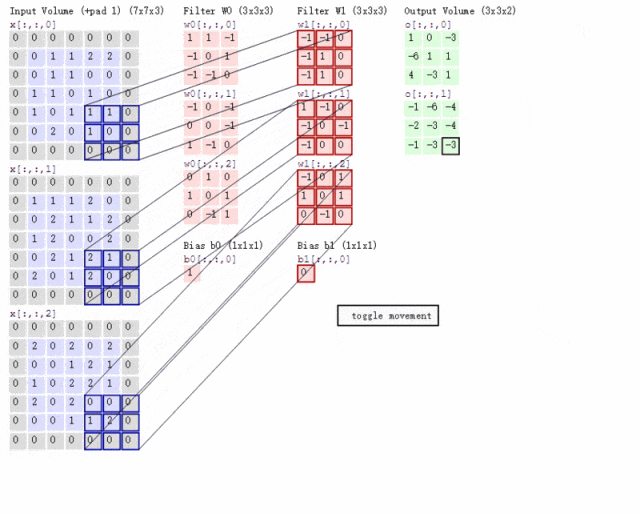
卷积神经网络(Convolutional Neural Networks,CNN)
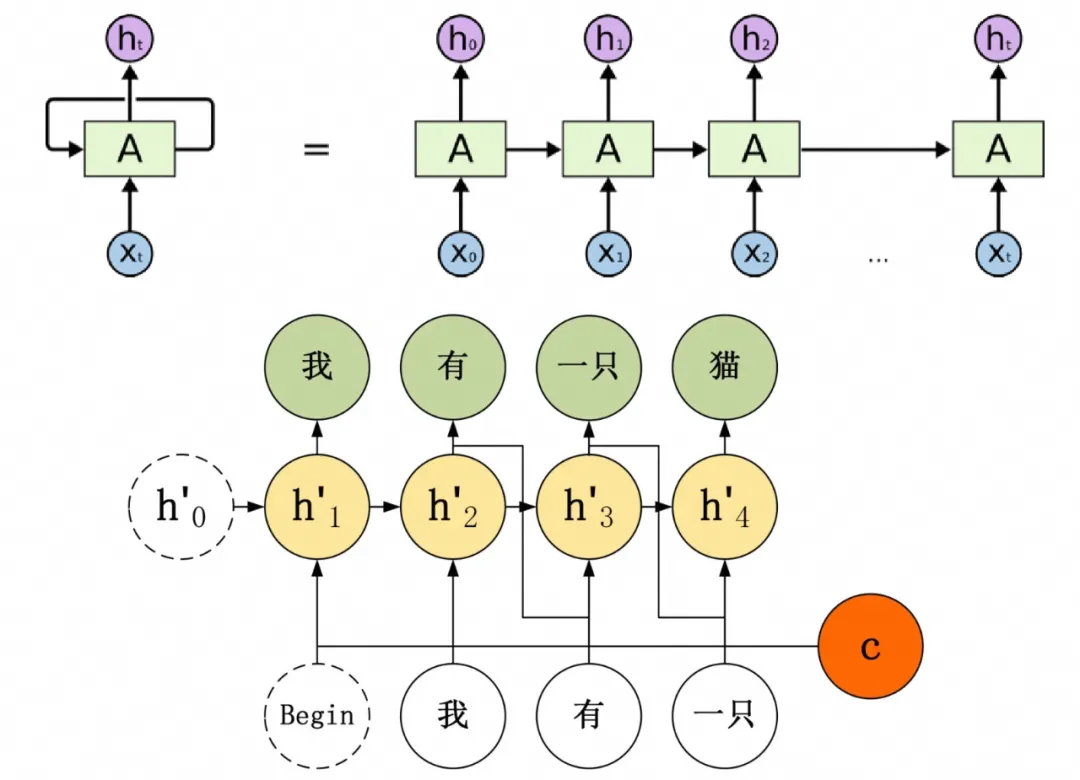
循环神经网络(Recurrent Neural Network, RNN)
CNN和RNN已经具备通过神经网络实现分类、预测能力,但是存在两个典型问题:
1. CNN聚焦局部信息,丢失全局信息。
2. RNN无法并行计算(串行模式理论上确实也可以做到窗口无限大,然后从左到右把全部信息带过来,效率太差)。
在2017年的时候,Google的翻译团队发布了一篇 Attention Is All You Need
论文,提出了Transformer模型,相比CNN和RNN,Transformer在复杂度是最低的,效率极高,他的核心就是
Attention Mechanism(2017年前是有各种百花齐放和CNN、RNN结合的Attention),相比RNN,可以从整文视角看每个词以及这个词在上下文的意义是什么,比如“你太卷了和“把报纸卷起来”。

(每层的总计算量、可以并行计算的计算量、长程依赖之间的路径长度)
和前面讲的神经网络一样,transformer也是通过训练(瞎猜)构建f(x),实现包括文本分类(mode1)、生成下个句子预测(mode2)、翻译任务(mode3),下面以GPT2为例,一步步分解实现原理。
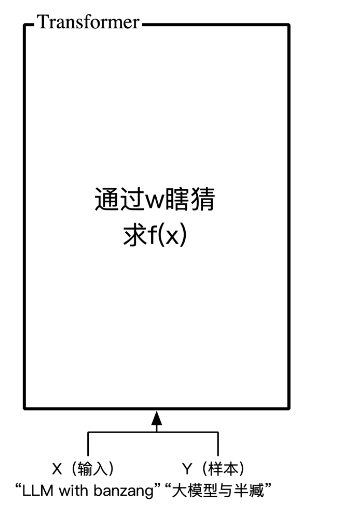
▐ 输入的处理(Embedding)
在计算之前需要对输入进行处理来解决几个问题:
输入可被用于数学计算
编码信息“足够稠密”,能够承载训练过程中,学习的知识图谱
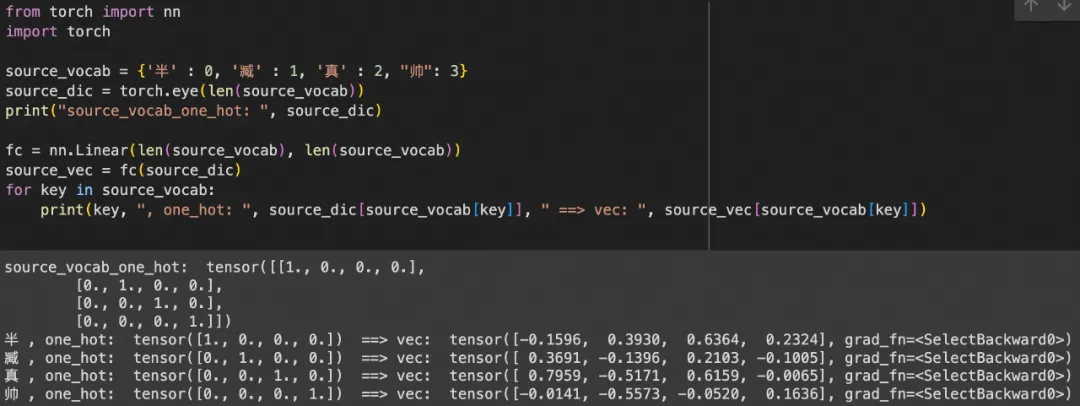
例如对“半”、“臧”、“真”、“帅”这4个词编码形成字典表(也可以“半”=1,“臧”=2,序列编码,one-hot只是为了计算简单)可以解决计算问题,但基于5个维度编码,并且每个元素只有0/1是不够支持训练过程中产生的内容,eg."半"和"臧"连起可以表示一个人名,"真"是形容词等,最简单的解决方法是把维度扩充,再增加词性、关联性维度,当训练内容复杂后,会指数级增加计算量。
所以最适中的方式是控制维度,稠密元素,也就是把[1 0 0 0]降维成[0.39847],也就是“低维稠密”向量化了(实际上降低1维是不够的,gpt2默认时768维)。
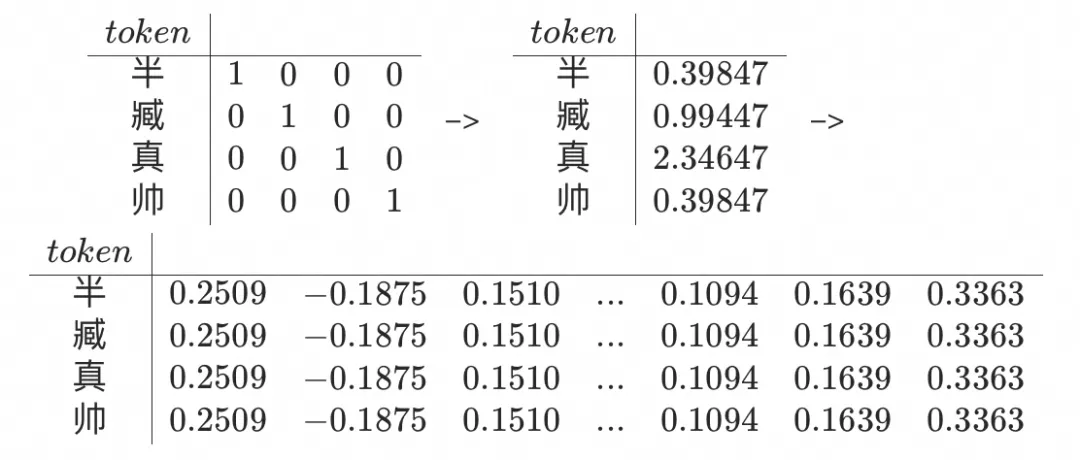
当输入被向量化,可以承载的内容也就变得很多,比如说向量的空间特性,cosine两个向量,可以从空间上判断其相似性,值接近1表示相似,反之依然,0为相交或不相关。
当我们把每个字/词,都向量化后,比如“半”,按照名词、动作、是否王室、阿里4个维度向量化后形成一个[-0.1596,
0.3930, 0.6364, 0.2324]词向量,同样完成“臧”字的词向量,就可以在判断“半”和“臧”之间的在表述一个事物、是否王室成员上存不存在联系。
用斯坦福的GloVe模型embedding后的英文单词编码,用一些可视化方法可以看到:
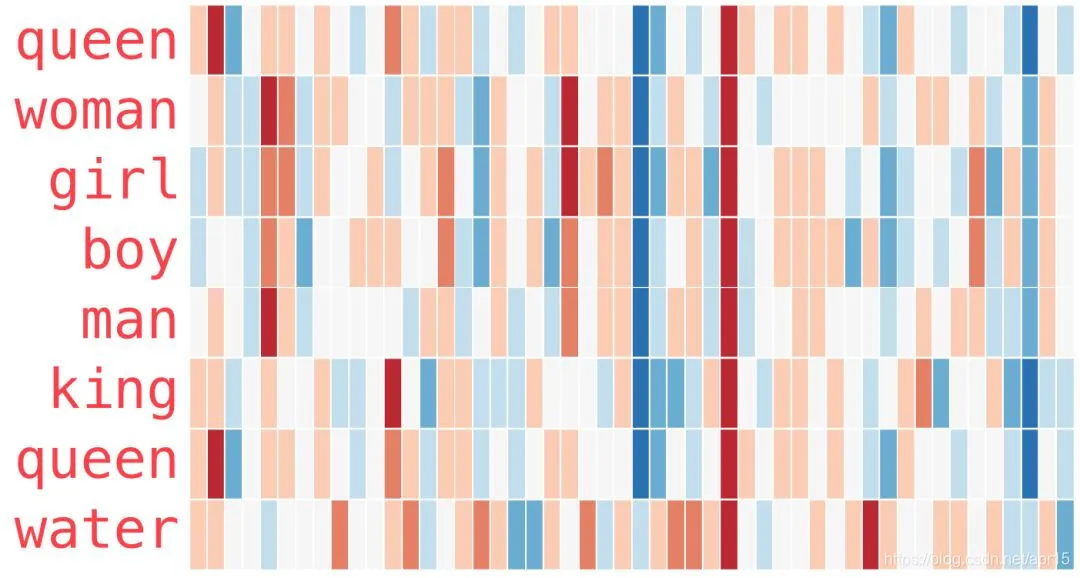
所有这些单词都有一条直的红色列,它们在这个维度上是相似的(名词维度)
“woman”和“girl”在很多地方是相似的,“man”和“boy”也是一样(性别维度)
“boy”和“girl”也有彼此相似的地方,但这些地方却与“woman”或“man”不同。(年龄维度)
所以当我们有了这样一份词向量表后,再去训练模型时,已经包含了词与词之前的某种联系,可以更好的达到训练目标,比如说我们训练一个模型,能够把各种夸张描述的娱乐新闻都转换成“谁干了啥”的时候,先把所有中文进行名字维度、动词维度、名词维度向量化后训练,然后再给予样本进行监督训练,将更准确。
实际上,在tranformer中,虽然不是一定需要这些已经训练好(Pre-training)的向量表,但思路是一样的。
Tranfromer本身就可以训练这样的词向量表,已满足下一个词的预测目标,当我们有明确的训练目标,也不需要这样按照预定目标训练的词向量表,比如说我们自己训练一个类似BERT的模型,通过周围的词来预测完形填空试卷,____是法国的首都,通过一个模型训练词的上下文联系性之后,形成特定的词向量表。
(不仅文字,包括图片、视频、商品等等,一切皆可Embedding,其实就是说Embedding用一个低维稠密的向量“表示”一个对象)
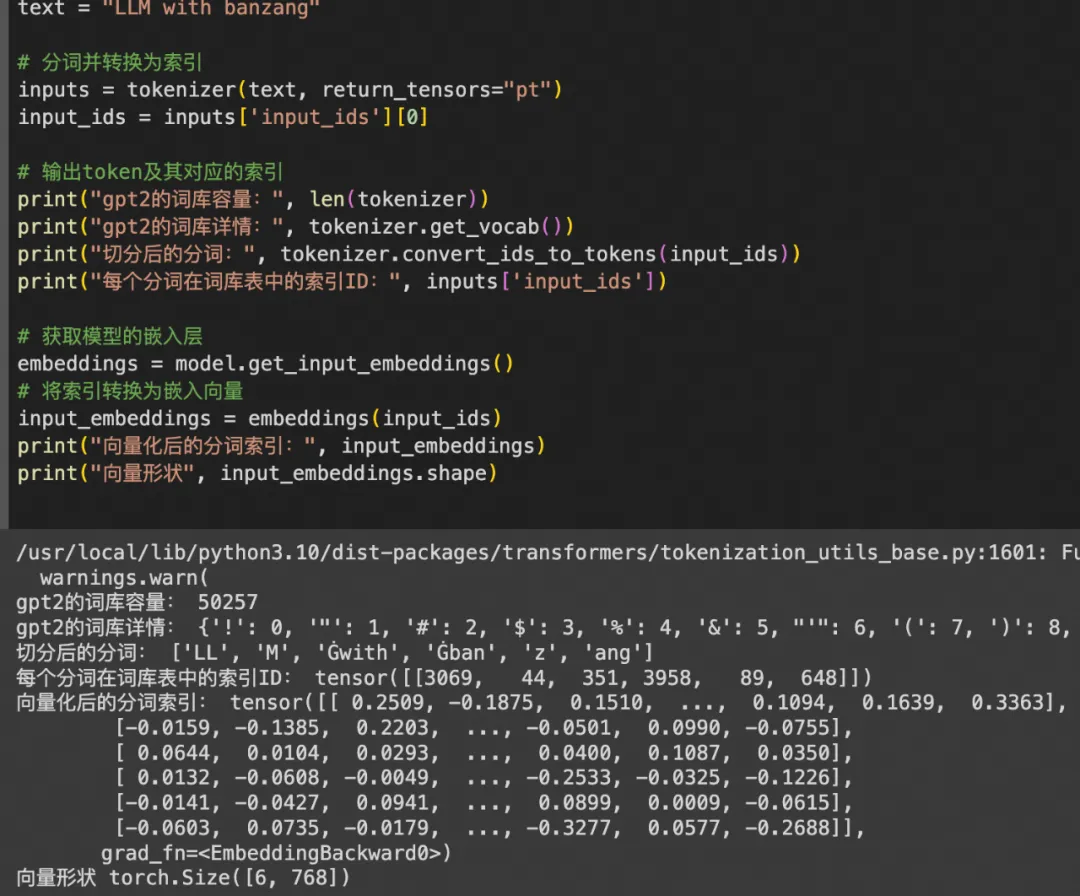
以翻译“LLM with banzang”为例, 在gpt2中,整个Embedding过程如下:
对输入X(LLM with banzang)进行分词:"LL","M","with","ban","z","ang";
查询分词在gpt词库中的索引列表:3069, 44, 351, 3958, 89, 648;
对索引列表向量化:经过一个全连接层(后面讲,可以理解经过 x*w+b ),形成6*768的矩阵。

过程有三点补充说明:
分词有多种方式,广泛使用的子词分割(subword)方式,空间和效率更加平衡,在gpt2使用的是BPE(Byte-Pair
Encoding)。
为什么通过subword分词?
基于单词的分词:因为有running和run,dogs和dog等会形成大量的token,因为没有覆盖全导致标记unk,会降低拟合度。
基于字母的分词:没有意义,比如一个中文字符,包含太多的信息。

基于子词的分词:将不常见的词拆解成多个常见词,tokenization被拆分token和ization,一方面tokenization意义被整体保留,另一方面因为token都是出现频率较高的词,所以整个词汇表会缩减到很小而覆盖全。

向量化不一定非得从头训练产出,也可以使用GloVe这类预训练好,含有某些联系的模型数据。
6*768,768个维度是gpt2默认设置,向量化后的作用在第一部已经说过,不再重复。
Embedding过程代码如下:
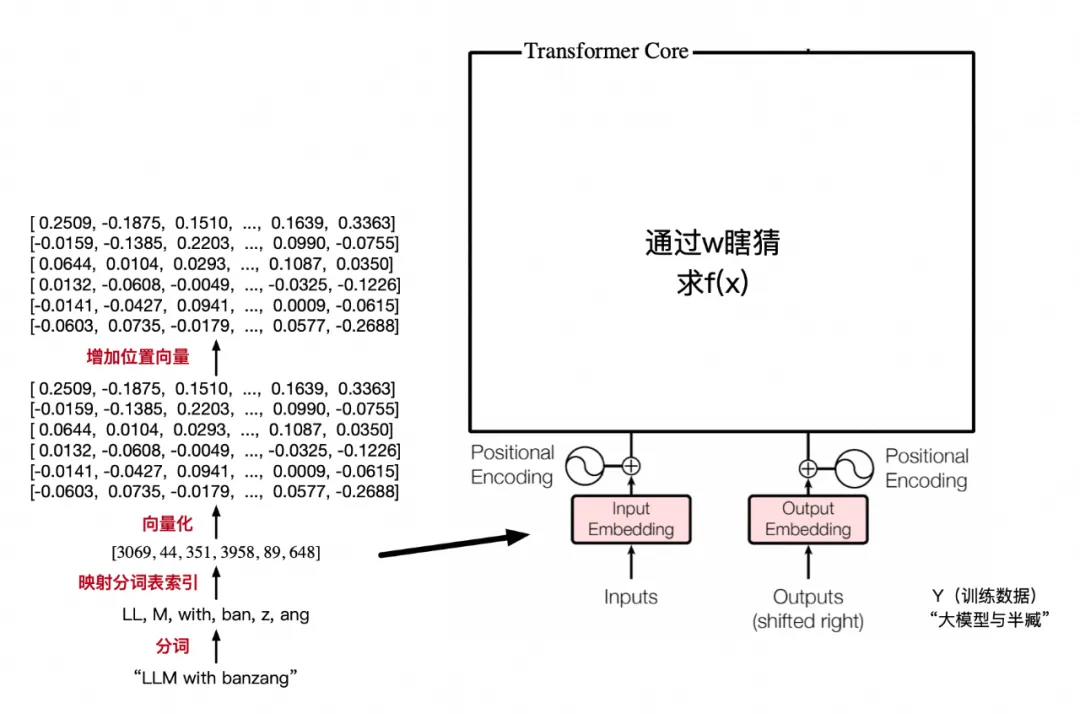
实际上更底层,索引被向量化的过程,还包含两个细节:
索引到向量过程,并没有按论文算法实现,而是直接随机初始了w参数,然后起了一层前馈层训练出768维度的最终值(暴力美学)
出了词向量外,还叠加了词位置向量(position embedding),来解决相同词在不同位置的语意不同,例如“你真狗”,“这是狗,不是豹子”。
论文中词位置向量细节
引入词位置的时候,还需要解决两个问题:
1. 如果是用整数数值表示,推理时可能会遇到比训练时还要长的序列;而且随着序列长度的增加,位置值会越来越大。
2. 如果用[-1,+1]之间进行表示,要解决序列长度不同时,能表示token在序列中的绝对位置;而且在序列长度不同时,也要在不同序列中token的相对位置/距离保持一致。
所以最后的实现是,对奇数维度,sin(词的index去除以10000的2*维度*词向量维度(768)),偶数cos,这样会将不管长度为多少的句子都是固定的长度的位置编码,以及位置编码都会被缩放在[-1,
1]的平滑范围,对模型非常理想的,最重要的是由于正弦和余弦函数的周期性(且是不同周期),对于任意固定偏移量
k,PE(pos+k)可以表示为 PE(pos) 的线性函数。这意味着模型可以很容易地通过学习注意力权重来关注相对位置,因为相对位置的编码可以通过简单的线性变换来获得。即我知道了绝对距离,也能知道相对距离。
最后向量直接相加得出embedding后的值。
上面是transform论文内容,但实际上gpt2没有按照sin和cos去计算,而是直接通过一个前馈层直接训练得出的,然后和词向量直接相加,最终训练过程也不再还原位置信息,而是以这种隐含的方式将位置信息参与后续训练,提高参数拟合度。

最后把整个embedding过程的工程图贴一下:
▐ 注意力和多头注意力机制(Attention Mechanism&Multi-Head
Attention)
Attention不是Transformer提出的,在2017年以前的时候,各种Attention方式被广泛应用在NLP任务上,例如Bahdanau
Attention等,单都以RNN、CNN结合形式出现,只不过到了2017年的 Attention
Is All You Need 论文发表,解决了上述说的两个核心问题后,才被活跃起来。
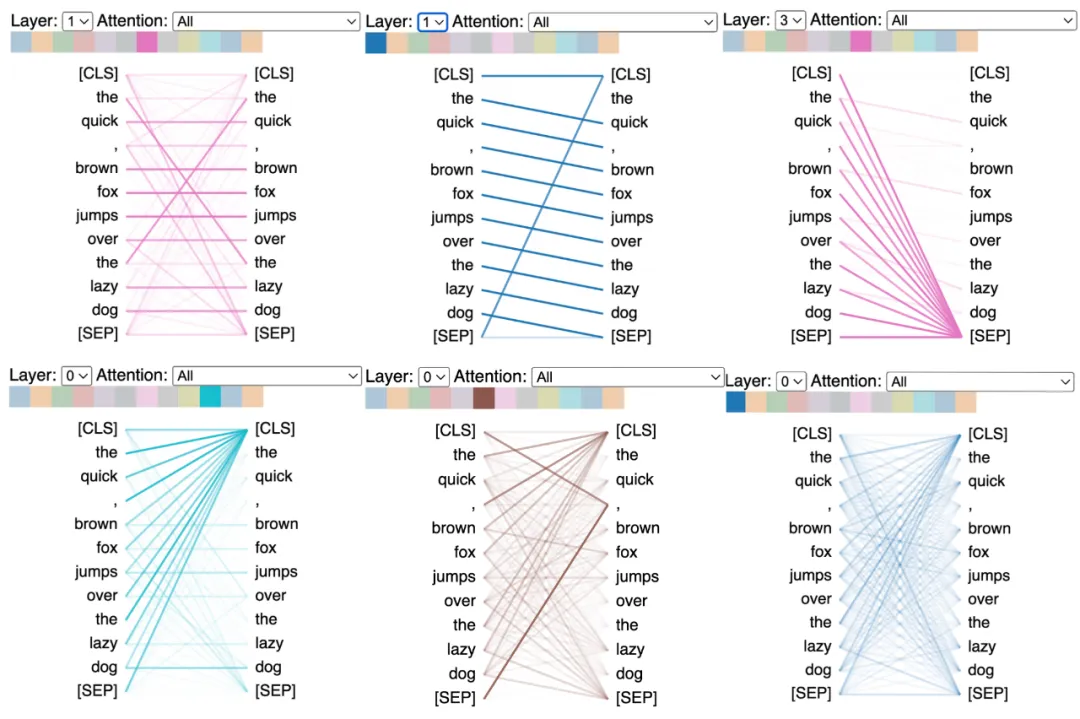
Attention的大概原理,鲁老师的文章,有个例子讲注意力机制是非常生动的,引用一下:
比如看到下面这张图,短时间内大脑可能只对图片中的“锦江饭店”有印象,即注意力集中在了“锦江饭店”处。短时间内,大脑可能并没有注意到锦江饭店上面有一串电话号码,下面有几个行人,后面还有“喜运来大酒家”等信息。

大脑在短时间内处理信息时,主要将图片中最吸引人注意力的部分读出来了,类似下面:

Attention的核心实现就是论文中的公式:
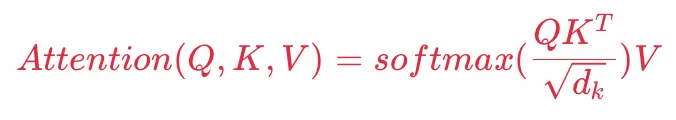
其中Q为查询意图、K为检索内容、V为被查询全部信息,例如上图中:Q为“好奇看看照片是个啥”、K为“招牌的几个字”,V为“整个图片”,通过计算Q和Key的Attention
Score,也就是最吸引人注意力的招牌,解析出招牌对应的值。
这是抽象的说法,还是以翻译“LLM with banzang”为例,分解实现细节。
"LLM with banzang"经过embedding后,形成以下的6*768(seq.len,
embed.dim)矩阵,分别代表着LL、M、with、ban、z、ang这5个token的768维度的向量:

然后分别乘以3个768*768(embed.dim, embed.dim)的Wq、Wk、Wv矩阵,得到的还是3个6*768的矩阵,分别是Q、K、V
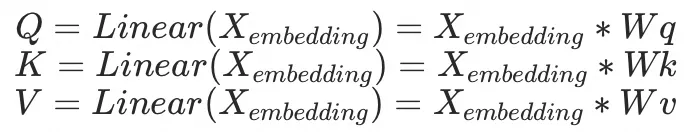
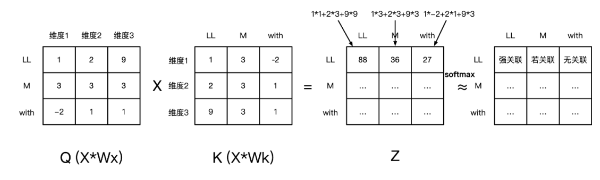
然后将Q和图片相乘(可以简单理解成 矩阵X乘以矩阵X的倒置),得到一个6*6的矩阵Z(seq.len,seq.len),Z代表着
[LL、M、with、ban、z、ang] 每个token之间的向量距离,换个说法就是把输入和输入的倒置矩阵相乘代表着LL、MM、with、ban、zang的token之间两两所有维度叠加后的“相似度”,这个是Attention最核心部分。
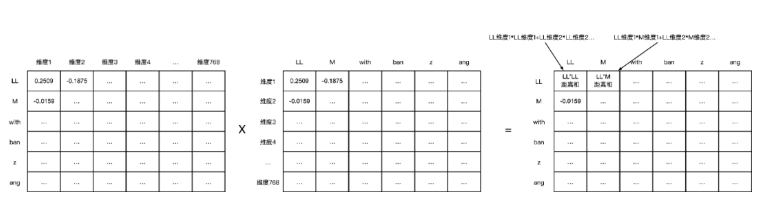
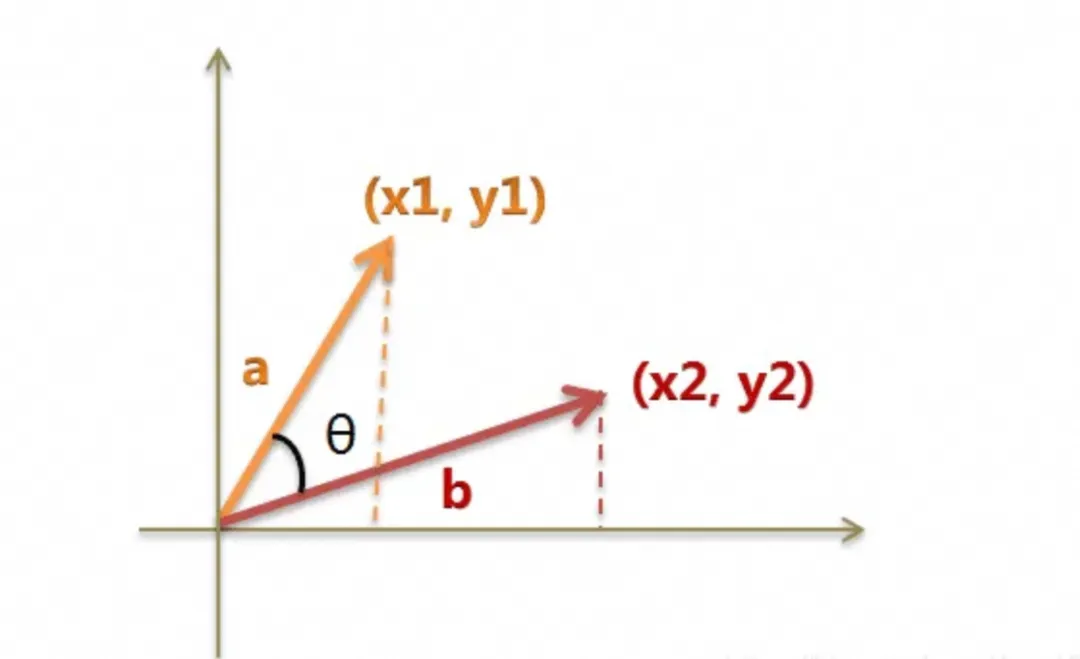
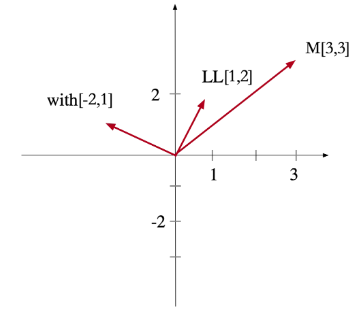
两个矩阵点积表达相似度的数学原理,假设LL、M和with三个向量分别是[1 2] [3 3] [-2
1]映射到象限表后,相似肉眼看夹角度数,如下:
数学定义是向量A和B的顶点距离图片,比如说LL和M的顶点距离是
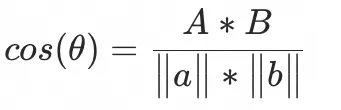
因为cos结果区间是[-1, 1],所以两个矩阵的相似度也就相当于 两个矩阵的点积通过模长和cos给归一成[-1,
1]的值,等价于LL和M两个矩阵相似度,先算点积再归一,比如简化下上面的Q、K、Z矩阵。
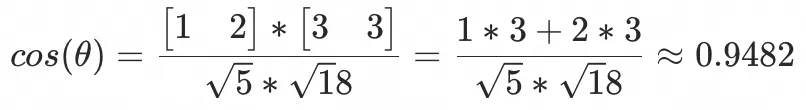
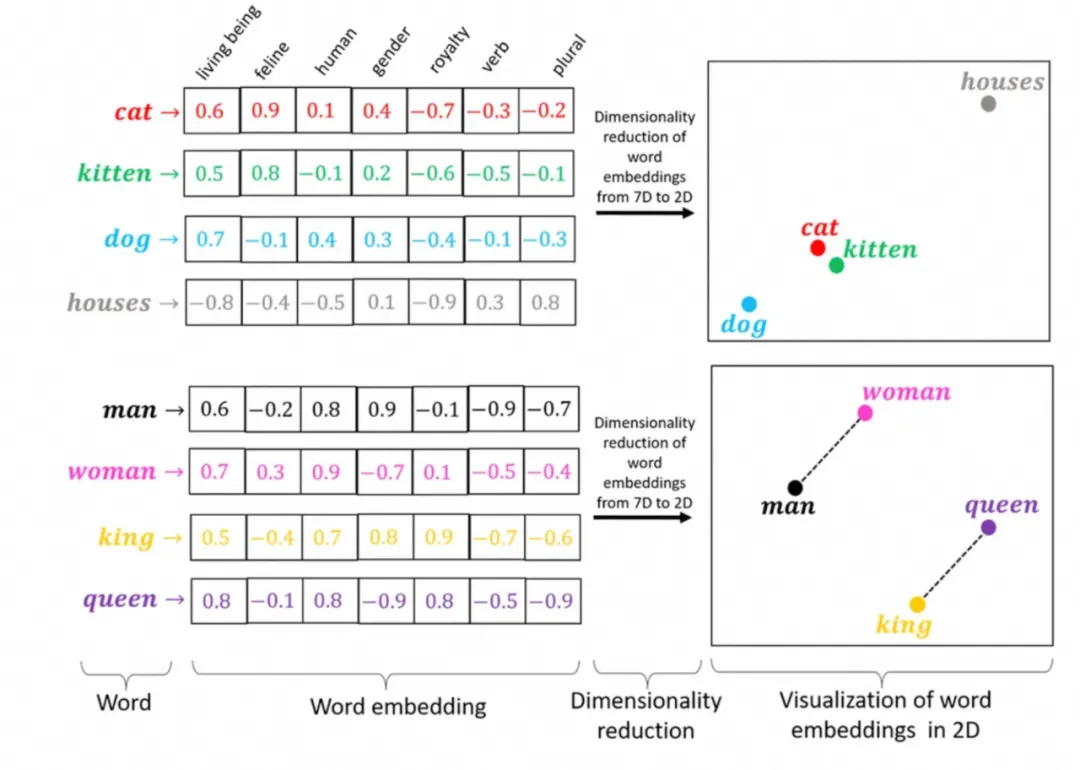
回想下,上一篇讲到的词向量,LL和M、以及M和with之间的相似度是不一样的,经过的训练后,已经包含了某种挂链,比如下图中cat与kitten在所有维度的接近,要高于dog和houses

其中缩放目的是:
避免数值过大,再最后归一的时候会导致梯度消失(vanishing gradients)回归效果差。
归一函数的输入如果太大会导致梯度非常的小,训练会很难。


其中归一函数 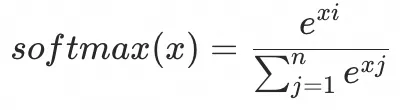 实现很简单,就是对向量中所有元素,指数放大后,算了一个出现概率(指数用e的原因是e的-1次方是0.3679,也在(0,
1)的区间) 实现很简单,就是对向量中所有元素,指数放大后,算了一个出现概率(指数用e的原因是e的-1次方是0.3679,也在(0,
1)的区间)

最后 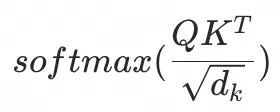 再乘以V矩阵,得到一个6*6的矩阵Z',也就是token两两关系在每个维度下,和token序列的关系度。 再乘以V矩阵,得到一个6*6的矩阵Z',也就是token两两关系在每个维度下,和token序列的关系度。
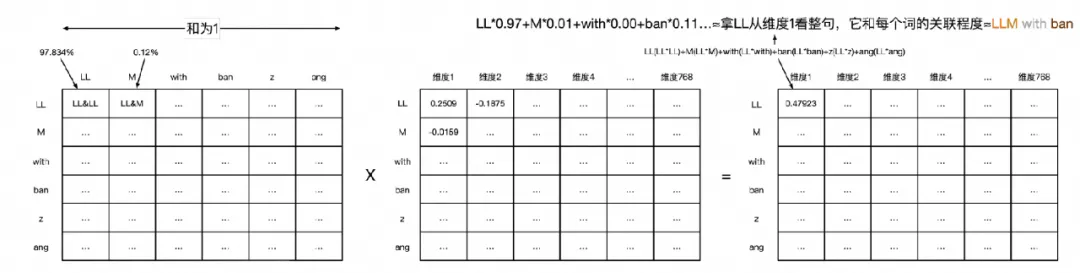
(具体的值实际上不需要理解,我们无法读懂某个参数W和B的值,也无法理解计算后的值,我们只关心这些值之间的关系,是不是预期就够)
图例如下,最后得到的矩阵Z(6*768)如果降维到Z'(6,),第一行代表LL在"LLM
with banzang"整句中和每个词的关联度,比如下图中ll和m紧密度高于with,第二行是M如此类推,实际上如果把6*1的矩阵在softmax后,取某个概率阈值,可以得到"LLM
with banzang"这句中,最重要的两个单词是什么(当然是训练后)。

回顾下Attention机制, 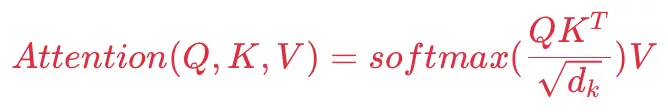 ,整个过程如下: ,整个过程如下:
这部分独立的流程的实现被称为Encoder module。
实际上transformer论文中,一次查询可以是并行的,也就是第一维是batch,然后第二维seq.len,第三维是把embed.dim拆成了n份(论文中是12份,任意份都可以,但我怀疑12是一个经验值),然后第四维是n份后的token维度,还是按照上面例子从(6,
768)最终变换成(4, 12, 6, 64),再加上一个linear后,拼接成最终的(4, 12,
6, 768),这里的12就是多头(Multi-Head)概念。
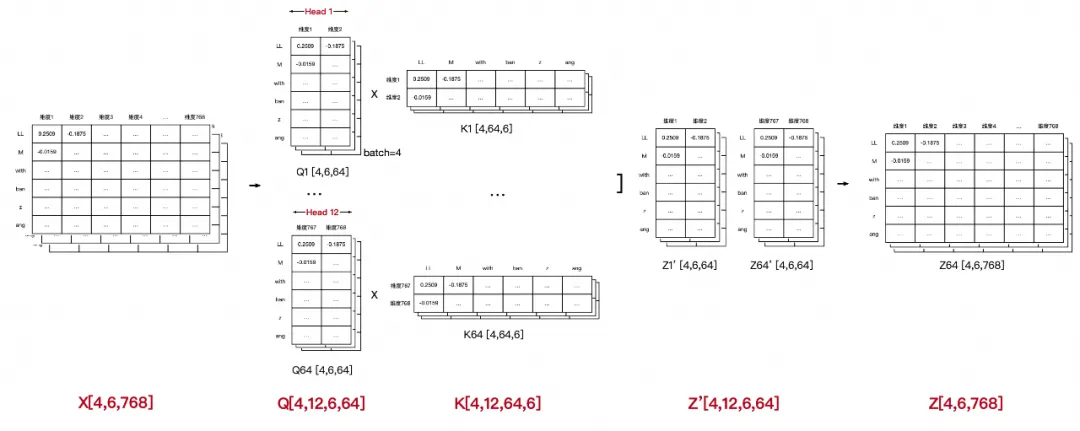
多头在工程上的意义在于:
比起单头,多头可以在不同维度空间聚焦信息处理,也可以降低单头在聚合多维度时的不稳定。
拟合度更好,单头的
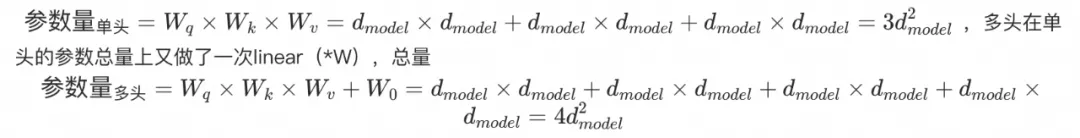
▐ 残差网络(Residual Network,ResNet)& 前馈网络(FeedForward
Neural Network, FFNN)
前面输入的X从embedding开始,到多头QKV,再还原Z,经过了多层的网络,每经过一层就会增加训练的性能要求,梯度下降的特别多,会剑走偏锋,第一部里Loss
Function中梯度下降中,和LR类似,会跳过最优值,或者在最优值附近震荡,反复消耗资源,有个可视化训练的小工具很有意思建议大家玩耍一下。
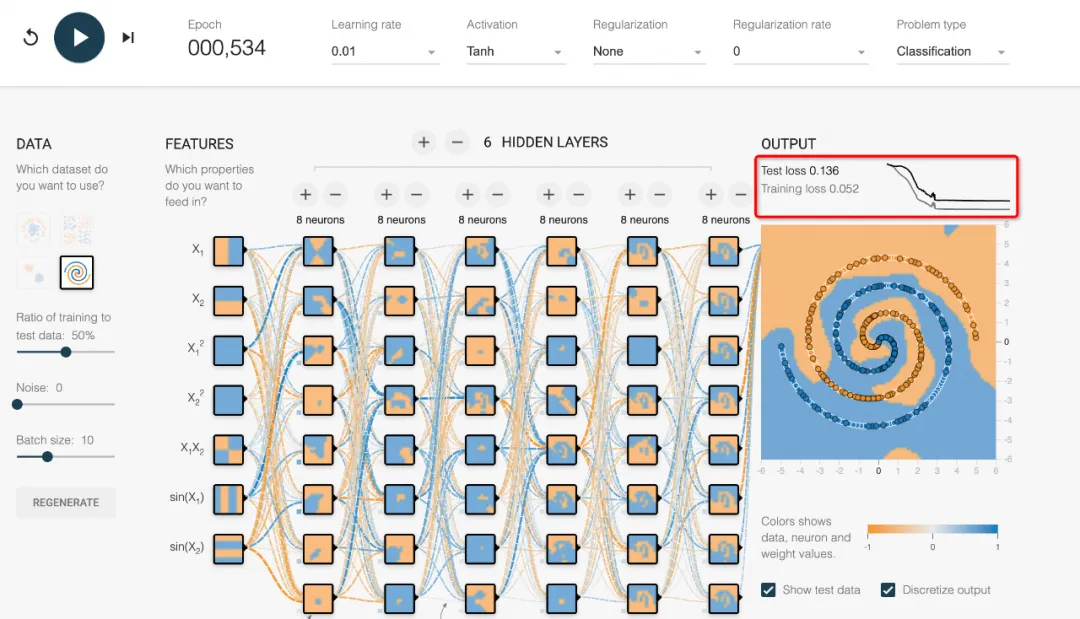
(在选择这个识别银河系一样的黄绿点范围的时候,我们增加了6个隐藏层后,traning loss在反复横跳,训练过程非常的长)
2015年微软亚洲研究院提出了基于CNN架构的ResNet,在transformer中可以借鉴来解决这个“退化”问题,核心是引入了“跳跃连接”或“捷径连接”(训练场景,梯度直接反向传播最原始层),将输入除了做为X给每层外,还跳过这层网络直接和这层输出Y叠加,让后面的层可以学习到这层处理和原始输入的差异,而不是直接上层处理结果Y,这种设计允许网络学习到恒等映射(identity
mapping),即输出与输入相同,从而使得网络可以通过更简单的路径来学习到正确的映射关系。
X和Y因为维度相同,这里叠加就是直接相加, ,但每层的输出其实是对X不同维度和力度的调整,需归一成正态分布后再相加,实现原理也很简单: ,但每层的输出其实是对X不同维度和力度的调整,需归一成正态分布后再相加,实现原理也很简单:
1. 求矩阵每行所有列的均值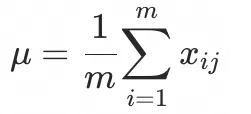 (例如上面例子,取LL的768维度的均值) (例如上面例子,取LL的768维度的均值)
2. 算出每行所有列的方差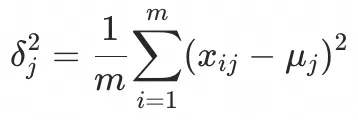
3. 最后用矩阵每行每列,减去这行的均值,再除以这行的标准差(��是一个小的常数,防止除0),然后再引入a和b训练参数,抵消这个过程的损失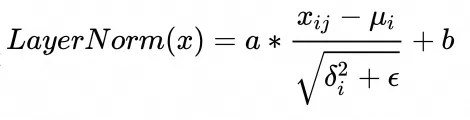
经过ADD和Norm后,Transformer的第一段处理基本结束,因为前面都是线性处理,需要再增加一个非线性层进行变化,让结果更丰富(或者让训练能够有一定的“基因突变”),这层非常的简单就是在第一部中讲的最简单的单向神经网络(f(x)=x*w+b),然后再过一次Norm。
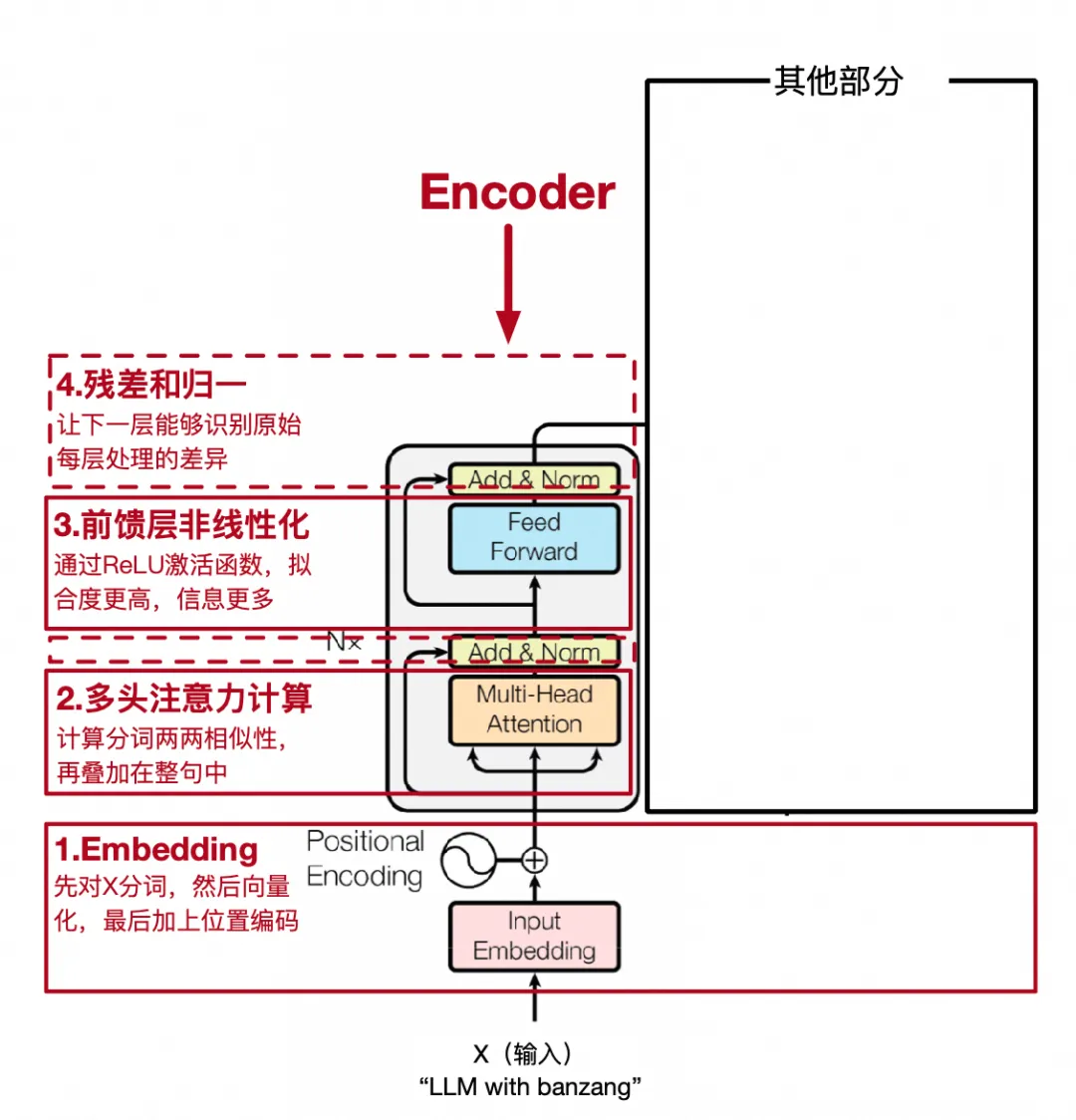
小结一下第一阶段的所有流程,见下图,这个流程在tranformer里被独立出一个模块,叫encoder,至此tranformer具备识别一个句子中每个词和整句的关联性,也就是每次token都包含了全部token信息以及关联度。
▐ 训练过程
Transformer仅一个Encoder模块就可以工作,可以处理信息抽取、识别、主体识别等任务,比如
BERT(Bidirectional Encoder Representations from Transformers)是只使用了Encoder,可以从给定的文本段落中找到并提取出回答问题的文本片段,目标是识别或检索信息,而不是生成新的文本序列。
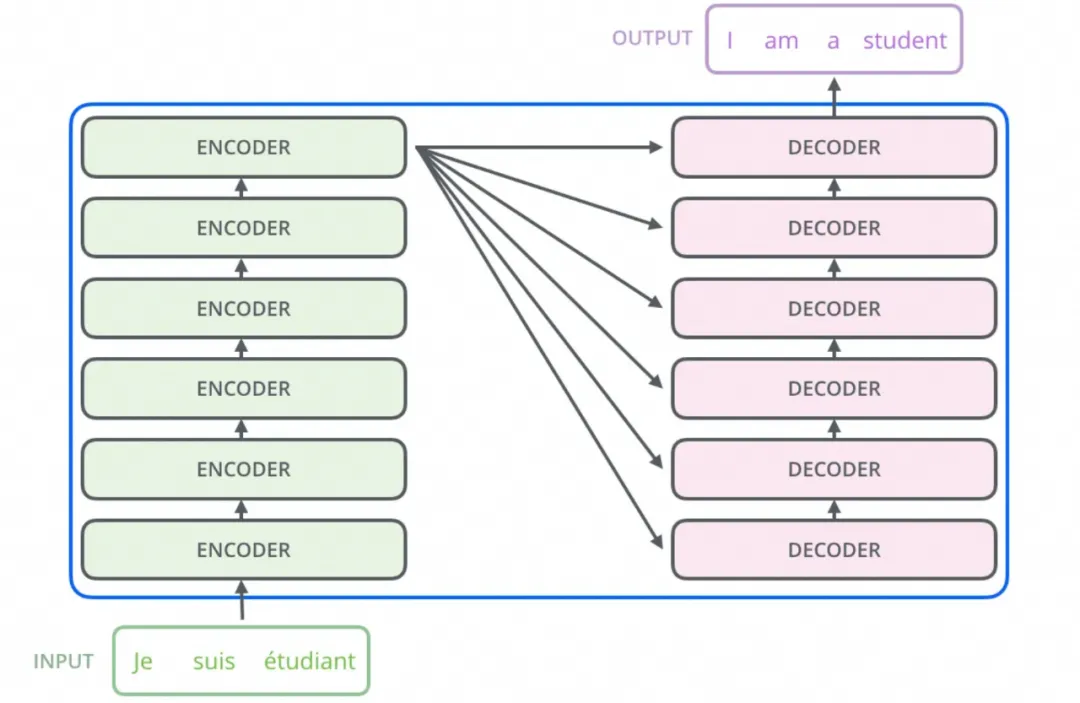
实际上,只通过Encoder直接连接一个全连接层去求 f(x) 也不是不可以,但不连接其他模块性能会差很多,同时也没有办法实现并行训练(Teacher
Forcing方式),所以又设计了Decoder模块,这两种模块的组合可以实现下面的场景:
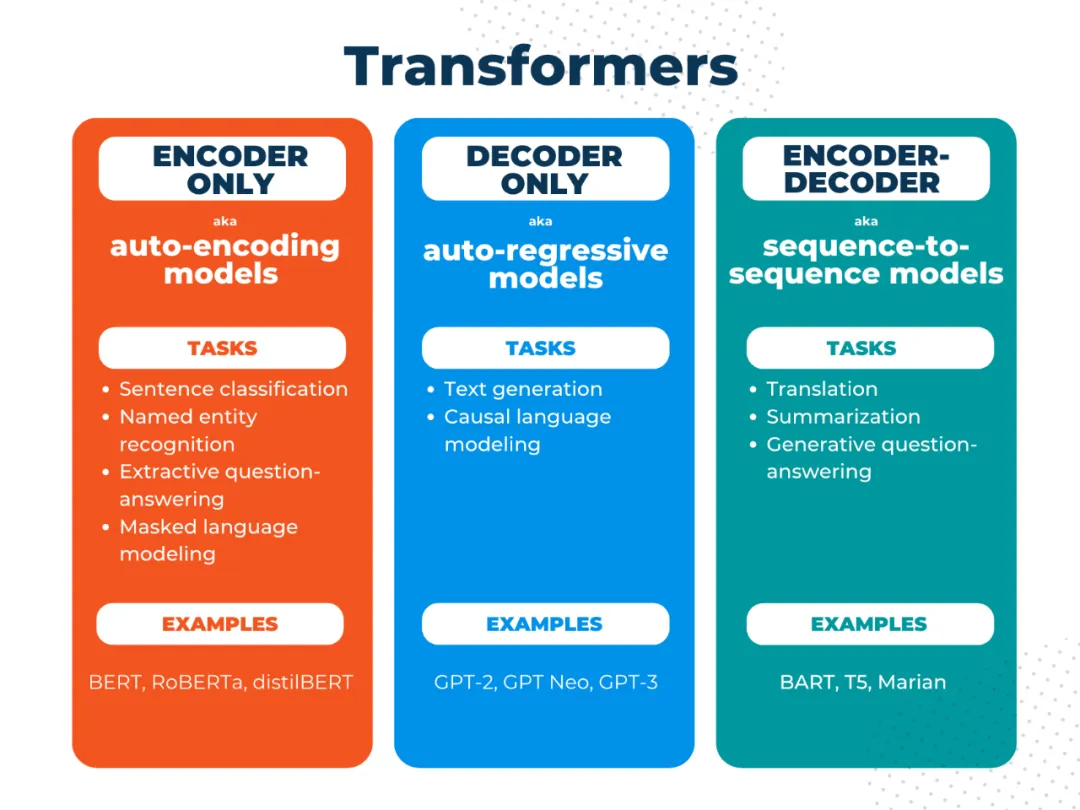
文本分类(仅使用Encoder模块),label=f(tokens)
下一个token预测(仅使用Decoder模块),next_token=f(token)。比如给定一些词,做出下一个词的预测,而且是逐字向后推测
文本翻译(Encoder+Decoder模块),中文=f(英文)
通过最初“LLM with banzang”翻译的例子,上面已经完成了token之间的关注力计算,下面从观察训练过程了解Decoder的构成。
整个训练过程还是求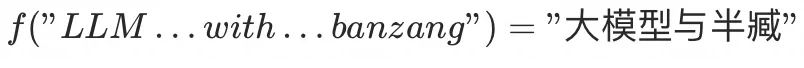 ,即输入"LL、M、with、ban、z、ang"(此时的输入相比Encoder已经包含了token之间的相互关注信息),调整参数计算出结果和"大模型、与、半臧"比较,loss收敛后结束,但实现上有两个特别的点: ,即输入"LL、M、with、ban、z、ang"(此时的输入相比Encoder已经包含了token之间的相互关注信息),调整参数计算出结果和"大模型、与、半臧"比较,loss收敛后结束,但实现上有两个特别的点:
第一个是在训练时词序引入了,翻译是以“大”、“大模型”、“大模型与”、“大模型与半臧”这样的顺序进行输出的,这样token之间的注意力加上词序的训练,在翻译(预测)场景会更贴合上下文场景,变得准确。
但是在技术上,引入词序会导致训练任务必须得到前一个任务的输出结果做输入进行串行,无法并行执行,所以transformer引入mask来解决这个问题,具体是把本来串行的任务,通过直接将完整的预期结果按词序做了mask覆盖,分成多个可以并行执行的任务。
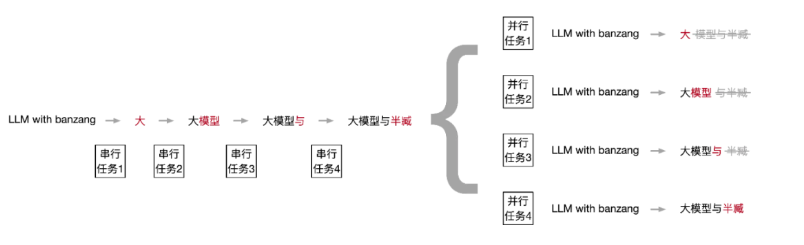
mask的主要实现就是对样本输入做了右上三角形的掩码(覆盖了一个非常小的数,可以让softmax归一后趋0),在做Decoder的QKV的时候忽略了。

任务并行后,同时任务也变成了“Teacher Forcing”方式,可以让loss收敛更快。
Teacher Forcing
RNN模型逐字推测训练过程,产生大量预测分支计算,比如“大”->[模型(90%)、小(4%)、量(1%)...],可能在某个迭代会推测出下个词是“小”,倒置推测从大模型走向大小变量的分支,越走越远,loss收敛不了。
Teacher Forcing概念是仍正常推测训练,但下个token不采纳推测实际结果,按照训练样本直接指定正确值,进行下个token预测。
在transformer中,完整token序列参与训练,但屏蔽每个token后面信息,形成可并行执行任务,每个token序列推测过程无视其他任务推测结果,采用训练样本值进行前序context推测下个token。
另外一个特别点是Decoder含有两层注意力,第一层是和Encoder一样的实现(自注意力),接受来自训练文本的真实输出,形成token的相互关注信息,第二层注意力QKV中Q来自上一个Decoder,KV并非由上一层Decoder结果计算来的,而是来自Encoder的KV结果(非同源,非自注意力),这样的设计是将来自Encoder的训练文本输入和训练真实输出(按词序mask)的相互关注都整合在一起预测被mask的值。
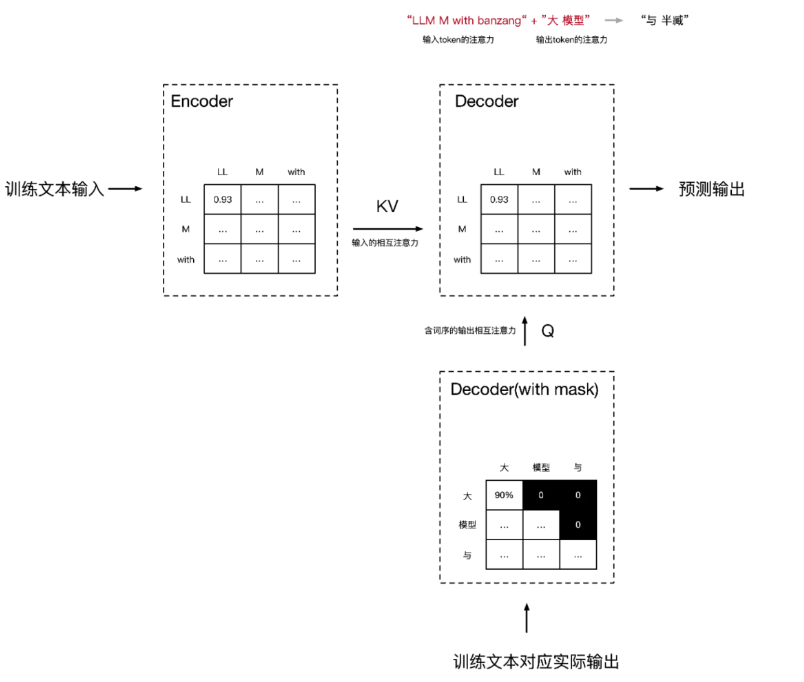
论文中Encoder和Decoder是可以堆叠的,即输入通过堆叠n层Encoder(论文中使用了2/4/6/8层,只有6层效果最好,但实际在只有一行训练样本场景下,n_layers=1是效果最好的)处理后在传递到n层Deocder继续处理,同时每层Deocder的KV都来自最后一层的Encoder的输出。
整个训练过程如下:
1. 训练文本(输入/输出)['LLM with banzang', '大模型和半臧']的输入['LLM
with banzang']进行分词和embedding
2. Encoder计算训练文本输入X的Self-AttentionScore,形成输入X的token间关注信息带入Decoder
3. 训练文本(输入/输出)['LLM with banzang', '大模型和半臧']的输出['大模型和半臧']进行分词和embedding
4. 第一层Decoder对训练文本输出X'进行右上三角形MASK遮盖操作后进行Self-AttentionScore,形成输出X'从左往右词序的token间关注信息(即只能了解过去信息,无法提前知道未来词序,因为要预测),事实上形成了训练输出长度为m(图片)的并行任务
5. 第二层Decoder将第一层Deocder输出的结果做为输入Q,使用Encoder的KV参数,拼接训练输入和输出再次做AttentionScore
6. 预测下一个结果和训练输出对比后,反向传播调整各层参数,直到Loss收敛到预期结果。
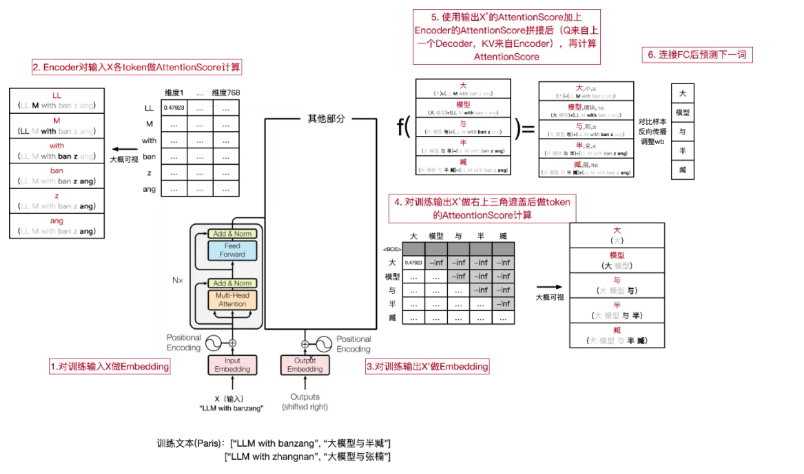
小结一下流程:
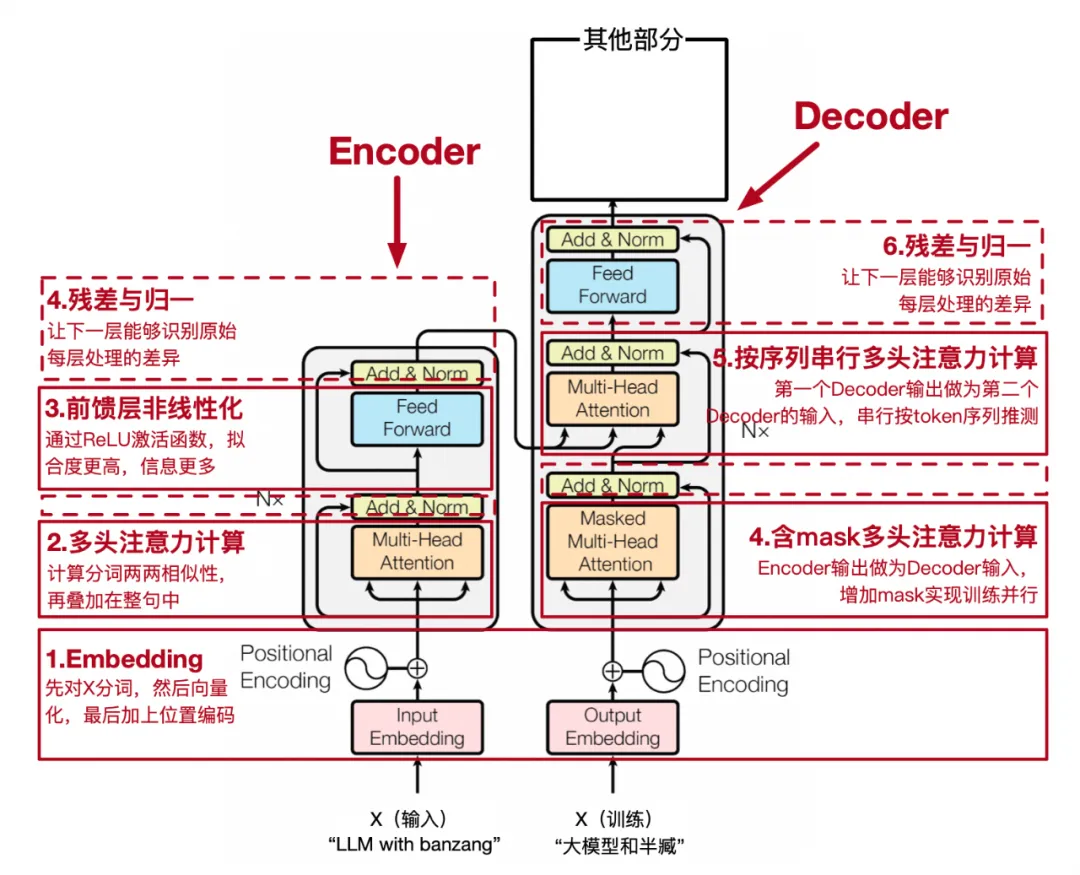
▐ 预测过程
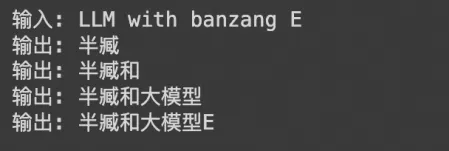
相比训练过程,切换到预测模式后,原本训练的并行输入由最后一个Decoder输出取代,然后开始串行循环,直至<EOS>标记结束。就和RNN一样,逐一预测到底,例如:
LL -> LLM
LLM -> LLM with
LLM with -> LLM with ban
LLM with ban -> LLM with banz
LLM with banz -> LLM with banzang
实际上预测下一个token是按照softmax后概率挑选的,在串行循环时,选取不同概率的词会形成不同的预测分支,例如:

预测结果因概率挑选以及前馈层的非线性激活函数,将整个预测变的更加丰富,有点像基因突变,可能未来会产生艺术创造的价值,当前基于transfomer的各个模型都有会有多个预测输出分支待采用。
▐ 输出的处理
当输入X被Encoder和Decoder*2处理完后,形成token_size*embedding_size大小的矩阵,每行代表着一个token,每列是这个token在不同维度的某个magic
number,最后再经过一个全连接层(Linear Layer,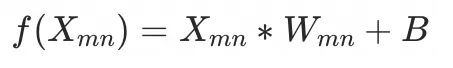 ),对输入矩阵做线形变化成token_size*logits_size,同时引入训练参数做拟合,再经过一个softmax归一,拟合每个token在字典表中最高概率的index,拿index还原最终token。 ),对输入矩阵做线形变化成token_size*logits_size,同时引入训练参数做拟合,再经过一个softmax归一,拟合每个token在字典表中最高概率的index,拿index还原最终token。
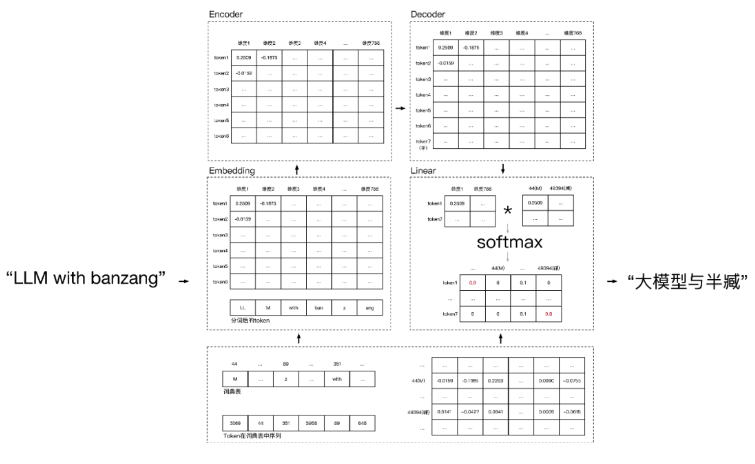
至此Transformer整个工作流程全部结束,图例回顾:
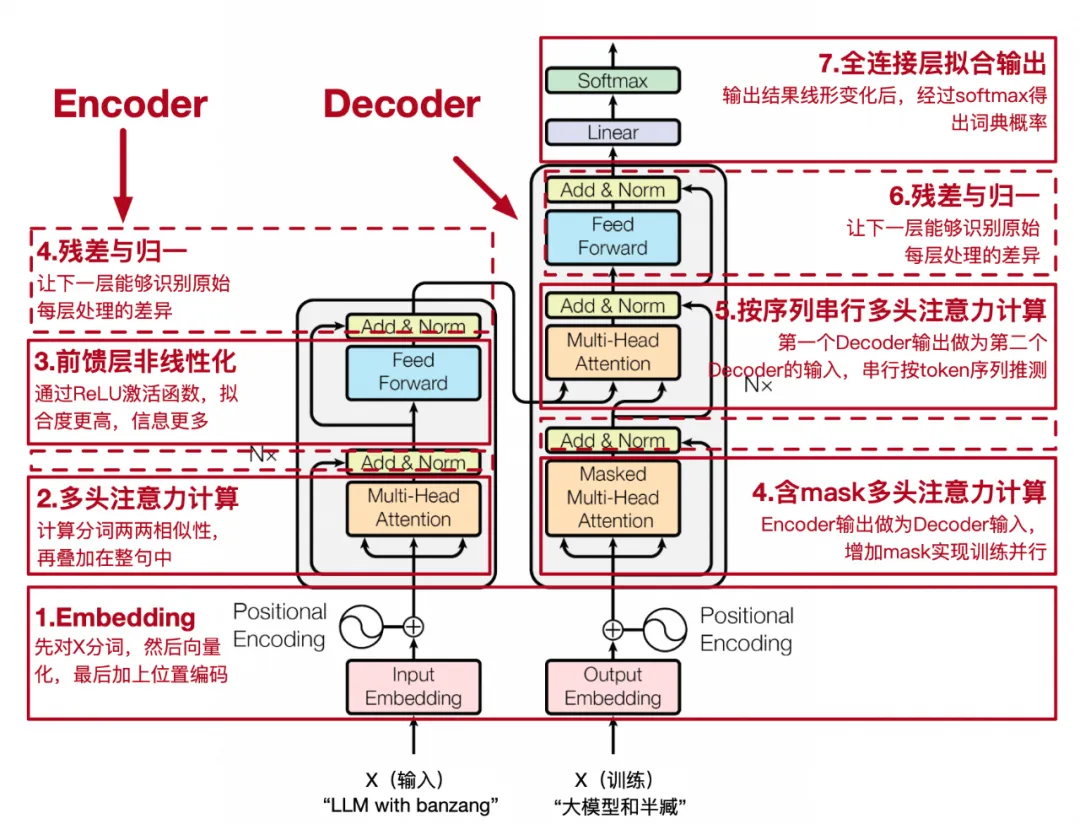
03工程代码实现及开源模型使用(工程)
▐ 案例通过Transformer模型的实现
上面贯穿的翻译“LLM with banzang”翻译案例,完整的代码实现如下(参考了https://adaning.github.io/posts/63679.html#toc-heading-16):
import torch
from torch import nn
from torch import optim
from torch.utils import data as Data
import numpy as np
d_model = 6 # Embedding的大小
max_len = 1024 # 输入序列的最长大小
d_ff = 12 # 前馈神经网络的隐藏层大小, 一般是d_model的四倍
d_k = d_v = 3 # 自注意力中K和V的维度, Q的维度直接用K的维度代替,
因为这二者必须始终相等
n_layers = 1 # Encoder和Decoder的层数
n_heads = 8 # 自注意力多头的头数
p_drop = 0.1 # propability of dropout
# 对encoder_input的PAD(0)做Mask,可以支持对训练样本打掩码
def get_attn_pad_mask(seq_q, seq_k):
batch, len_q = seq_q.size()
batch, len_k = seq_k.size()
# we define index of PAD is 0, if tensor equals
(zero) PAD tokens
pad_attn_mask = seq_k.data.eq(0).unsqueeze(1)
# [batch, 1, len_k]
return pad_attn_mask.expand(batch, len_q,
len_k) # [batch, len_q, len_k]
# 在deocder_input做上三角掩码
def get_attn_subsequent_mask(seq):
attn_shape = [seq.size(0), seq.size(1), seq.size(1)]
# [batch, target_len, target_len]
subsequent_mask = np.triu(np.ones(attn_shape),
k=1) # [batch, target_len, target_len]
subsequent_mask = torch.from_numpy(subsequent_mask)
return subsequent_mask # [batch, target_len,
target_len]
# 做encoder_input添加位置编码
class PositionalEncoding(nn.Module):
def __init__(self, d_model, dropout=.1,
max_len=1024):
super(PositionalEncoding, self).__init__()
self.dropout = nn.Dropout(p=p_drop)
positional_encoding = torch.zeros(max_len,
d_model) # [max_len, d_model]
position = torch.arange(0, max_len).float().unsqueeze(1)
# [max_len, 1]
div_term = torch.exp(torch.arange(0, d_model,
2).float() *
(-torch.log(torch.Tensor([10000])) / d_model))
# [max_len / 2]
positional_encoding[:, 0::2] = torch.sin(position
* div_term) # even
positional_encoding[:, 1::2] = torch.cos(position
* div_term) # odd
# [max_len, d_model] -> [1, max_len,
d_model] -> [max_len, 1, d_model]
positional_encoding = positional_encoding.unsqueeze(0).transpose(0,
1)
# register_buffer能够申请一个缓冲区中的常量, 并且它不会被加入到计算图中,
也就不会参与反向传播.
self.register_buffer('pe', positional_encoding)
def forward(self, x):
# x: [seq_len, batch, d_model]
# we can add positional encoding to x directly,
and ignore other dimension
x = x + self.pe[:x.size(0), ...]
return self.dropout(x)
# Encoder和Deocder后的前馈层(含归一层)
class FeedForwardNetwork(nn.Module):
def __init__(self):
super(FeedForwardNetwork, self).__init__()
self.ff1 = nn.Linear(d_model, d_ff)
# 线性变化还原
self.ff2 = nn.Linear(d_ff, d_model)
self.relu = nn.ReLU()
self.dropout = nn.Dropout(p=p_drop)
self.layer_norm = nn.LayerNorm(d_model)
def forward(self, x):
x = self.ff1(x)
x = self.relu(x)
x = self.ff2(x)
return self.layer_norm(x)
# 多头注意力(含归一层)
class MultiHeadAttention(nn.Module):
def __init__(self, n_heads=8):
super(MultiHeadAttention, self).__init__()
# do not use more instance to implement multihead
attention
# it can be complete in one matrix
self.n_heads = n_heads
# we can't use bias because there is no
bias term in formular
# 多头放在同一个矩阵计算
self.W_Q = nn.Linear(d_model, d_k * n_heads,
bias=False)
self.W_K = nn.Linear(d_model, d_k * n_heads,
bias=False)
self.W_V = nn.Linear(d_model, d_v * n_heads,
bias=False)
self.fc = nn.Linear(d_v * n_heads, d_model,
bias=False)
self.layer_norm = nn.LayerNorm(d_model)
def forward(self, input_Q, input_K, input_V,
attn_mask):
'''
To make sure multihead attention can be used
both in encoder and decoder,
we use Q, K, V respectively.
input_Q: [batch, len_q, d_model]
input_K: [batch, len_k, d_model]
input_V: [batch, len_v, d_model]
'''
residual, batch = input_Q, input_Q.size(0)
# [batch, len_q, d_model] -- matmul W_Q
--> [batch, len_q, d_q * n_heads] -- view
-->
# [batch, len_q, n_heads, d_k,] -- transpose
--> [batch, n_heads, len_q, d_k]
Q = self.W_Q(input_Q).view(batch, -1, n_heads,
d_k).transpose(1, 2) # [batch, n_heads, len_q,
d_k]
K = self.W_K(input_K).view(batch, -1, n_heads,
d_k).transpose(1, 2) # [batch, n_heads, len_k,
d_k]
V = self.W_V(input_V).view(batch, -1, n_heads,
d_v).transpose(1, 2) # [batch, n_heads, len_v,
d_v]
attn_mask = attn_mask.unsqueeze(1).repeat(1,
n_heads, 1, 1) # [batch, n_heads, seq_len,
seq_len]
# prob: [batch, n_heads, len_q, d_v] attn:
[batch, n_heads, len_q, len_k]
prob, attn = ScaledDotProductAttention()(Q,
K, V, attn_mask)
prob = prob.transpose(1, 2).contiguous()
# [batch, len_q, n_heads, d_v]
prob = prob.view(batch, -1, n_heads * d_v).contiguous()
# [batch, len_q, n_heads * d_v]
output = self.fc(prob) # [batch, len_q,
d_model]
return self.layer_norm(residual + output),
attn
# 点积,QKV
class ScaledDotProductAttention(nn.Module):
def __init__(self):
super(ScaledDotProductAttention, self).__init__()
def forward(self, Q, K, V, attn_mask):
'''
Q: [batch, n_heads, len_q, d_k]
K: [batch, n_heads, len_k, d_k]
V: [batch, n_heads, len_v, d_v]
attn_mask: [batch, n_heads, seq_len, seq_len]
nbsp; '''
scores = torch.matmul(Q, K.transpose(-1, -2))
/ np.sqrt(d_k) # [batch, n_heads, len_q, len_k]
# -1e9是用很大的负数,使得其在Softmax中可以被忽略,实现mask效果
scores.masked_fill_(attn_mask, -1e9)
attn = nn.Softmax(dim=-1)(scores) # [batch,
n_heads, len_q, len_k]
prob = torch.matmul(attn, V) # [batch, n_heads,
len_q, d_v]
return prob, attn
# Encoder层,可以构建多层Encoder,由多头注意力和前馈层构成
class EncoderLayer(nn.Module):
def __init__(self):
super(EncoderLayer, self).__init__()
self.encoder_self_attn = MultiHeadAttention()
self.ffn = FeedForwardNetwork()
def forward(self, encoder_input, encoder_pad_mask):
'''
encoder_input: [batch, source_len, d_model]
encoder_pad_mask: [batch, n_heads, source_len,
source_len]
encoder_output: [batch, source_len, d_model]
attn: [batch, n_heads, source_len, source_len]
'''
encoder_output, attn = self.encoder_self_attn(encoder_input,
encoder_input, encoder_input, encoder_pad_mask)
encoder_output = self.ffn(encoder_output)
# [batch, source_len, d_model]
return encoder_output, attn
# Encoder
class Encoder(nn.Module):
def __init__(self):
super(Encoder, self).__init__()
self.source_embedding = nn.Embedding(source_vocab_size,
d_model)
self.positional_embedding = PositionalEncoding(d_model)
self.layers = nn.ModuleList([EncoderLayer()
for layer in range(n_layers)])
def forward(self, encoder_input):
# encoder_input: [batch, source_len]
encoder_output = self.source_embedding(encoder_input)
# [batch, source_len, d_model]
encoder_output = self.positional_embedding(encoder_output.transpose(0,
1)).transpose(0, 1) # [batch, source_len,
d_model]
encoder_self_attn_mask = get_attn_pad_mask(encoder_input,
encoder_input) # [batch, source_len, source_len]
encoder_self_attns = list()
for layer in self.layers:
# encoder_output: [batch, source_len, d_model]
# encoder_self_attn: [batch, n_heads, source_len,
source_len]
encoder_output, encoder_self_attn = layer(encoder_output,
encoder_self_attn_mask)
encoder_self_attns.append(encoder_self_attn)
return encoder_output, encoder_self_attns
# Decoder层,可以构建多层Decoder,由多头注意力和前馈层构成
class DecoderLayer(nn.Module):
def __init__(self):
super(DecoderLayer, self).__init__()
self.decoder_self_attn = MultiHeadAttention()
self.encoder_decoder_attn = MultiHeadAttention()
self.ffn = FeedForwardNetwork()
def forward(self, decoder_input, encoder_output,
decoder_self_mask, decoder_encoder_mask):
'''
decoder_input: [batch, target_len, d_mdoel]
encoder_output: [batch, source_len, d_model]
decoder_self_mask: [batch, target_len, target_len]
decoder_encoder_mask: [batch, target_len,
source_len]
'''
# masked mutlihead attention
# Q, K, V all from decoder it self
# decoder_output: [batch, target_len, d_model]
# decoder_self_attn: [batch, n_heads, target_len,
target_len]
decoder_output, decoder_self_attn = self.decoder_self_attn(decoder_input,
decoder_input, decoder_input, decoder_self_mask)
# Q from decoder, K, V from encoder
# decoder_output: [batch, target_len, d_model]
# decoder_encoder_attn: [batch, n_heads, target_len,
source_len]
decoder_output, decoder_encoder_attn = self.encoder_decoder_attn(decoder_output,
encoder_output, encoder_output, decoder_encoder_mask)
decoder_output = self.ffn(decoder_output)
# [batch, target_len, d_model]
return decoder_output, decoder_self_attn,
decoder_encoder_attn
# Decoder
class Decoder(nn.Module):
def __init__(self):
super(Decoder, self).__init__()
self.target_embedding = nn.Embedding(target_vocab_size,
d_model)
self.positional_embedding = PositionalEncoding(d_model)
self.layers = nn.ModuleList([DecoderLayer()
for layer in range(n_layers)])
def forward(self, decoder_input, encoder_input,
encoder_output):
'''
decoder_input: [batch, target_len]
encoder_input: [batch, source_len]
encoder_output: [batch, source_len, d_model]
'''
decoder_output = self.target_embedding(decoder_input)
# [batch, target_len, d_model]
decoder_output = self.positional_embedding(decoder_output.transpose(0,
1)).transpose(0, 1) # [batch, target_len,
d_model]
decoder_self_attn_mask = get_attn_pad_mask(decoder_input,
decoder_input) # [batch, target_len, target_len]
decoder_subsequent_mask = get_attn_subsequent_mask(decoder_input)
# [batch, target_len, target_len]
decoder_encoder_attn_mask = get_attn_pad_mask(decoder_input,
encoder_input) # [batch, target_len, source_len]
decoder_self_mask = torch.gt(decoder_self_attn_mask
+ decoder_subsequent_mask, 0)
decoder_self_attns, decoder_encoder_attns
= [], []
for layer in self.layers:
# decoder_output: [batch, target_len, d_model]
# decoder_self_attn: [batch, n_heads, target_len,
target_len]
# decoder_encoder_attn: [batch, n_heads, target_len,
source_len]
decoder_output, decoder_self_attn, decoder_encoder_attn
= layer(decoder_output, encoder_output, decoder_self_mask,
decoder_encoder_attn_mask)
decoder_self_attns.append(decoder_self_attn)
decoder_encoder_attns.append(decoder_encoder_attn)
return decoder_output, decoder_self_attns,
decoder_encoder_attns
class Transformer(nn.Module):
def __init__(self):
super(Transformer, self).__init__()
self.encoder = Encoder()
self.decoder = Decoder()
self.fc = nn.Linear(d_model, target_vocab_size,
bias=False)
def forward(self, encoder_input, decoder_input):
'''
encoder_input: [batch, source_len]
decoder_input: [batch, target_len]
'''
# encoder_output: [batch, source_len, d_model]
# encoder_attns: [n_layers, batch, n_heads,
source_len, source_len]
encoder_output, encoder_attns = self.encoder(encoder_input)
# decoder_output: [batch, target_len, d_model]
# decoder_self_attns: [n_layers, batch, n_heads,
target_len, target_len]
# decoder_encoder_attns: [n_layers, batch,
n_heads, target_len, source_len]
decoder_output, decoder_self_attns, decoder_encoder_attns
= self.decoder(decoder_input, encoder_input,
encoder_output)
decoder_logits = self.fc(decoder_output) #
[batch, target_len, target_vocab_size]
# decoder_logits: [batch * target_len, target_vocab_size]
return decoder_logits.view(-1, decoder_logits.size(-1))
class Tokenizer:
def __init__(self, sentences):
super(Tokenizer, self).__init__()
self.sentences = sentences
def get_source_vocab(self):
return self.source_vocab
def get_target_vocab(self):
return self.target_vocab
def convert_token_to_ids(self):
source_inputs = " ".join([sentences[i][0]
for i in range(len(sentences))]).replace('E',
'').split()
source_inputs.insert(0, 'E')
self.source_vocab = {k: v for v, k in enumerate(source_inputs)}
target_inputs = " ".join([sentences[i][1]
for i in range(len(sentences))]).replace('E',
'').replace('S', '').split()
target_inputs.insert(0, 'E')
target_inputs.insert(1, 'S')
self.target_vocab = {k: v for v, k in enumerate(target_inputs)}
encoder_inputs, decoder_inputs, decoder_outputs
= [], [], []
for i in range(len(sentences)):
encoder_input = [self.source_vocab[word] for
word in sentences[i][0].split()]
decoder_input = [self.target_vocab[word] for
word in sentences[i][1].split()]
decoder_output = [self.target_vocab[word]
for word in sentences[i][2].split()]
encoder_inputs.append(encoder_input)
decoder_inputs.append(decoder_input)
decoder_outputs.append(decoder_output)
return torch.LongTensor(encoder_inputs), torch.LongTensor(decoder_inputs),
torch.LongTensor(decoder_outputs)
def convert_ids_to_source_sentences(self,
ids, split_word=' '):
return split_word.join([key for key in self.source_vocab][ids[i].item()]
for i in range(len(ids)))
def convert_ids_to_target_sentences(self,
ids, split_word=' '):
return split_word.join([key for key in self.target_vocab][ids[i].item()]
for i in range(len(ids)))
# 训练
device = torch.device('cuda' if torch.cuda.is_available()
else 'cpu')
epochs = 400
lr = 1e-1
model = Transformer().to(device)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(),
lr=lr)
sentences = [
# Encoder的输入 Decoder的输入(teaching force) #Decoder的输出(样本值)
['LLM with banzang E', 'S 半臧 和 大模型', '半臧 和
大模型 E']
]
tokenizer = Tokenizer(sentences)
encoder_inputs, decoder_inputs, decoder_outputs
= tokenizer.convert_token_to_ids()
dataset = Seq2SeqDataset(encoder_inputs, decoder_inputs,
decoder_outputs)
data_loader = Data.DataLoader(dataset, 2,
True)
source_vocab_size = len(tokenizer.get_source_vocab())
target_vocab_size = len(tokenizer.get_target_vocab())
for epoch in range(epochs):
for encoder_input, decoder_input, decoder_output
in data_loader:
encoder_input = encoder_input.to(device)
decoder_input = decoder_input.to(device)
decoder_output = decoder_output.to(device)
output = model(encoder_input, decoder_input)
loss = criterion(output, decoder_output.view(-1))
print('Epoch:', '%04d' % (epoch + 1), 'loss
=', '{:.6f}'.format(loss), '\t预测:', tokenizer.convert_ids_to_target_sentences(output.max(dim=1,
keepdim=False)[1].data), '\t(训练样本:', tokenizer.convert_ids_to_target_sentences(decoder_output.view(-1).data),
')')
optimizer.zero_grad()
loss.backward()
optimizer.step()
# 预测
output_len = len(decoder_outputs.squeeze(0))
for encoder_input, decoder_input, decoder_output
in data_loader:
encoder_input = encoder_input.to(device)
decoder_input = torch.zeros(1, output_len).type_as(encoder_input.data)
# 从"S"开始,source_vocab={'E':0, 'S':1,
...}
next_symbol = 1
print('输入:', tokenizer.convert_ids_to_source_sentences(encoder_input.data.squeeze(0)))
for i in range(output_len):
decoder_input[0][i] = next_symbol
output = model(encoder_input, decoder_input)
prob = output.max(dim=1, keepdim=False)[1]
next_symbol = prob.data[i].item()
print('输出:', tokenizer.convert_ids_to_target_sentences(prob.data[:i+1],
''))
if next_symbol == 0:
break
|
训练过程(在400轮的时候,已经收敛):

预测过程:
具体代码实现有兴趣学习或者在解疑过程可以仔细参考,所有抽象过程全部在上述文字描述中,重点行做了中文注释,需要补充说明的有两点内容:
代码中Encoder和Deocder有Layer的实现,意思是Encoder或者Decoder可以堆叠执行,Encoder堆叠后的输出统一提供给每个Decoder(论文中使用了2/4/6/8层,只有6层效果最好,但实际在只有一行训练样本场景下,n_layers=1是效果最好的)
#第一层的Encoder的输出会做为第二层Encoder的输入
for layer in self.layers:
encoder_output, encoder_self_attn
= layer(encoder_output, encoder_self_attn_mask)
encoder_self_attns.append(encoder_self_attn)
|
包括多头n_heads = 8的实现,也不是对input拆分成8份分别计算,而是和Layer一样直接合并在一个矩阵中做一次计算(并行实现)
▐ 通过开源模型处理实际案例
大淘宝技术项目需求管理中,有一环是维护每个需求的子技术PM,但这个字段并不是必填,容易被漏填,案例目标:
通过训练已经存在的“子技术PM”需求列表(1000+),求出剩余(1000+)需求的“子技术PM”字段
不必再从头写一份训练代码,得益于"HUB"潮流,可以通过https://huggingface.co/获取大量的开源模型及训练数据(甚至可以快速体验效果),比如我们选择一个可以处理中文的文本分类模型:
Hugging Face Transformers 是一个开源 Python 库,其提供了数以千计的预训练
transformer 模型,可广泛用于自然语言处理 (NLP) 、计算机视觉、音频等各种任务。它通过对底层
ML 框架 (如 PyTorch、TensorFlow 和 JAX) 进行抽象,简化了 transformer
模型的实现,从而大大降低了 transformer 模型训练或部署的复杂性。
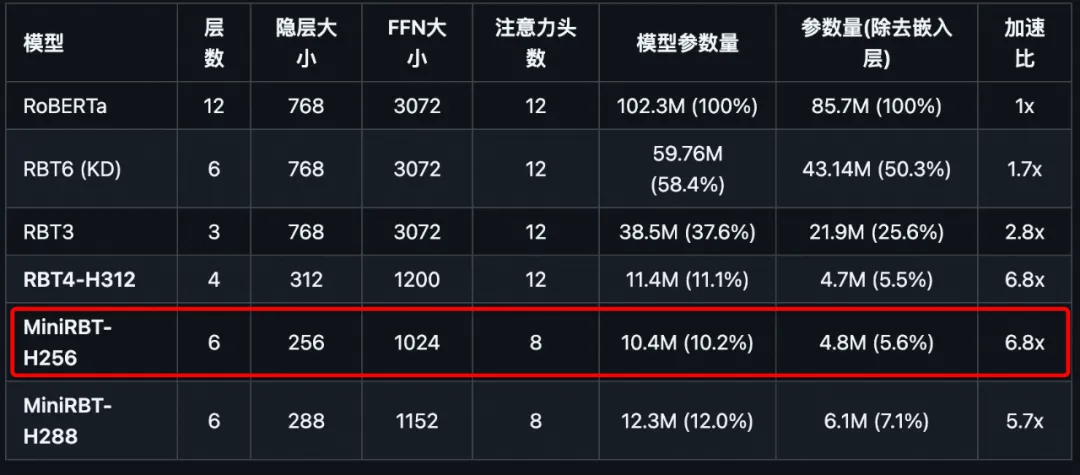
选择的是“哈工大讯飞联合实验室(HFL)”的MiniRBT,hfl/minirbt-h288
目前预训练模型存在参数量大,推理时间长,部署难度大的问题,为了减少模型参数及存储空间,加快推理速度,我们推出了实用性强、适用面广的中文小型预训练模型MiniRBT,我们采用了如下技术:
全词掩码技术:全词掩码技术(Whole Word Masking)是预训练阶段的训练样本生成策略。简单来说,原有基于WordPiece的分词方式会把一个完整的词切分成若干个子词,在生成训练样本时,这些被分开的子词会随机被mask(替换成[MASK];保持原词汇;随机替换成另外一个词)。而在WWM中,如果一个完整的词的部分WordPiece子词被mask,则同属该词的其他部分也会被mask。更详细的说明及样例请参考:Chinese-BERT-wwm,本工作中我们使用哈工大LTP作为分词工具。
两段式蒸馏:相较于教师模型直接蒸馏到学生模型的传统方法,我们采用中间模型辅助教师模型到学生模型蒸馏的两段式蒸馏方法,即教师模型先蒸馏到助教模型(Teacher
Assistant),学生模型通过对助教模型蒸馏得到,以此提升学生模型在下游任务的表现。并在下文中贴出了下游任务上两段式蒸馏与一段式蒸馏的实验对比,结果表明两段式蒸馏能取得相比一段式蒸馏更优的效果。
构建窄而深的学生模型。相较于宽而浅的网络结构,如TinyBERT结构(4层,隐层维数312),我们构建了窄而深的网络结构作为学生模型MiniRBT(6层,隐层维数256和288),实验表明窄而深的结构下游任务表现更优异。
MiniRBT目前有两个分支模型,分别为MiniRBT-H256和MiniRBT-H288,表示隐层维数256和288,均为6层Transformer结构,由两段式蒸馏得到。同时为了方便实验效果对比,我们也提供了TinyBERT结构的RBT4-H312模型下载。
在CoLab上使用huggingface非常简单,如下:
import torch
from transformers import AdamW, AutoTokenizer,
AutoModelForSequenceClassification
from torch.utils.data import Dataset, DataLoader
from tqdm.auto import tqdm
checkpoint = "hfl/minirbt-h288"
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
model = AutoModelForSequenceClassification.from_pretrained(checkpoint,
num_labels=3)
device = torch.device('cuda' if torch.cuda.is_available()
else 'cpu')
model.to(device)
# 1. 训练和评估数据准备
class TrainDataset(Dataset):
def __init__(self, sentences):
self.sentences = sentences
def __len__(self):
return len(self.sentences)
def __getitem__(self, idx):
return sentences['train'][idx][0], sentences['train'][idx][1],
sentences['train'][idx][2]
class ValidationDataset(Dataset):
def __init__(self, sentences):
self.sentences = sentences
def __len__(self):
return len(self.sentences)
def __getitem__(self, idx):
return sentences['validation'][idx][0], sentences['validation'][idx][1],
sentences['validation'][idx][2]
def data_collator(batch):
sentence ,labels = [],[]
for item in batch:
sentence.append([item[0], item[1]])
labels.append(item[2])
inputs = tokenizer(sentence, padding=True,
truncation=True, return_tensors="pt")
inputs['labels'] = torch.tensor(labels)
return inputs
# 2. 准备训练和评估数据
sentences = {
"train": [
["I have a green apple", "apple",
0],
["I have a black apple", "apple",
1],
["I have a red apple", "apple",
2],
["I have a red banner", "banner",
2]
],
"validation": [
["I have a black apple", "apple",
1],
["I have a green banner", "banner",
0]
]
}
# 3. 评估模型
import evaluate
from transformers import TrainingArguments
from transformers import Trainer
import numpy as np
def compute_metrics(eval_preds):
metric = evaluate.load("glue", "mrpc")
logits, labels = eval_preds
predictions = np.argmax(logits, axis=-1)
return metric.compute(predictions=predictions,
references=labels)
training_args = TrainingArguments("test-trainer",
evaluation_strategy="epoch")
trainer = Trainer(
model,
training_args,
train_dataset = TrainDataset(sentences),
eval_dataset = ValidationDataset(sentences),
data_collator = data_collator,
tokenizer = tokenizer,
compute_metrics=compute_metrics
)
trainer.train()
# 4. 进行训练
train_dataset = TrainDataset(sentences)
train_dataloader = DataLoader(train_dataset,
shuffle=True, batch_size=8, collate_fn=data_collator)
num_epochs = 10
progress_bar = tqdm(range(num_epochs))
model.train()
# 观测指标
metric = evaluate.load("glue", "mrpc")
optimizer = AdamW(model.parameters(), lr=5e-5)
for epoch in range(num_epochs):
for batch in train_dataloader:
optimizer.zero_grad()
output = model(**batch)
loss, logits = output[:2]
loss.backward()
optimizer.step()
predictions = torch.argmax(logits, dim=-1)
metric.add_batch(predictions=predictions,
references=batch["labels"])
# 过程日志
print(f"Epoch {epoch + 1}, Loss: {loss.item()}")
progress_bar.update(1)
# 观测指标结果
metric.compute()
# 5. 预测
model.eval()
sentences = ["I have a black banner",
"banner"]
logits = model(**tokenizer(sentences[0],
sentences[1], return_tensors="pt")).logits
pred = torch.argmax(logits,dim=-1)
print(pred)
|
代码整体分五个部分:
模型引入:
AutoModelForSequenceClassification.from_pretrained(checkpoint,
num_labels=3)(num_labels在案例中,等于“子技术PM”的去重数)
checkpoint = "hfl/minirbt-h288"
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
model = AutoModelForSequenceClassification.from_pretrained(checkpoint,
num_labels=3)
|
训练样本准备:分成两部分Train和Validation两个训练集,每个训练集分成三个维度,前两个是文本的两个普通维度,最后一个是lables表明了文本的分类,在案例中就是“子技术PM”值
模型评估:使用Transformer的高级工具Trainer,看模型对数据的准确性指标(evaluate需要安装,预设了指标)

训练:同样对整个训练结束增加指标观测(evaluation_strategy="epoch"),tqdm实现进度条
预测:
因为数据安全的原因,没有办法把案例的需求数据进行上传,所以需要在本地执行,Colab提供代码在本机执行的能力,前提需要安装Jupyter,具体步骤参考https://research.google.com/colaboratory/local-runtimes.html
连接本地执行后,运行时会出现一些问题:
1. 依赖的包通过pip,按错误提示在本机上挨个安装一遍,比如说 pip install torch
2. 通过hugginface在线引入的模型,可能会遇到网络连接问题,遇到的话,下载模型到本地https://huggingface.co/docs/transformers/installation#offline-mode
3. Trainer包可能出现依赖版本问题,指标观察部分可以注释掉,包括trainer.train()、metric.compute()
本地执行的代码:
import torch
from transformers import AdamW, AutoTokenizer,
AutoModelForSequenceClassification
from torch.utils.data import Dataset, DataLoader
from tqdm.auto import tqdm
from datasets import load_dataset
device = 'mps' if torch.backends.mps.is_available()
else 'cpu'
class UniqueLabelsDataset(Dataset):
def __init__(self, data, labels):
self.data = data
self.labels = labels
def __len__(self):
return len(self.data)
def __getitem__(self, idx):
return self.labels[idx], pre_process_input(self.data[idx].values())
# 训练和评估数据准备
def data_collator(batch):
sentence, labels = [],[]
for l, item in batch:
sentence.append(item)
labels.append(l.item())
inputs = tokenizer(sentence, padding=True,
truncation=True, return_tensors="pt")
inputs['labels'] = torch.tensor(labels)
return inputs
def pre_process_input(inputs):
return f" ".join([str(value).replace('
', '') for value in inputs])
# 准备训练和评估数据
'''
{
'标题': Value(dtype='string', id=None),
'需求指派人': Value(dtype='string', id=None),
'***': Value(dtype='int64', id=None),
'***': Value(dtype='string', id=None),
'***': Value(dtype='string', id=None),
'***': Value(dtype='string', id=None),
'子需求技术pm': Value(dtype='int64', id=None),
'team_alias': Value(dtype='string', id=None)}
'''
train_dataset = load_dataset("csv",
data_files = "./tt_l_demands.csv",
delimiter=",")['train']
labels_vocab, unique_labels = torch.unique(torch.tensor(train_dataset['子需求技术pm']),
return_inverse=True)
num_labels = len(labels_vocab)
train_dataset.remove_columns(["子需求技术pm"])
train_dataloader = DataLoader(UniqueLabelsDataset(train_dataset,
unique_labels), shuffle=True, batch_size=64,
collate_fn=data_collator)
# 初始化模型
checkpoint = "/Users/nanzhang/minirbt-h288"
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
model = AutoModelForSequenceClassification.from_pretrained(checkpoint,
num_labels=num_labels)
model.to(device)
from transformers import get_scheduler
# 进行训练
num_epochs = 100
# 显示训练进度,dynamic_ncols=True保持在一行
progress_bar = tqdm(range(num_epochs), dynamic_ncols=True)
# lr从 1e-1 的预热,爬坡到 5e-5
num_training_steps = num_epochs * len(train_dataloader)
lr_scheduler = get_scheduler(
"linear",
optimizer=optimizer,
num_warmup_steps=1e-1,
num_training_steps=num_training_steps,
)
model.train()
# 观测指标
optimizer = AdamW(model.parameters(), lr=5e-5)
for epoch in range(num_epochs):
for batch in train_dataloader:
batch = {k: v.to(device) for k, v in batch.items()}
output = model(**batch)
loss, logits = output[:2]
loss.backward()
optimizer.step()
lr_scheduler.step()
optimizer.zero_grad()
# 显示进度
#print(f"Epoch {epoch + 1}, Loss: {loss.item()}")
progress_bar.set_postfix(loss=loss.item())
progress_bar.update(1)
# 持久化训练好的参数
model.save_pretrained('./model')
tokenizer.save_pretrained('./model')
# 预测
sentences = ["***", '407080', '407080',
'2722', '4066', '淘天项目', '50932674', '***']
input = tokenizer(pre_process_input(sentences),
padding=True, truncation=True, return_tensors="pt")
input.to(device)
logits = model(**input).logits
pred = torch.argmax(logits,dim=-1)
print(labels_vocab[pred.item()])
|
和colab上的代码有一些不同,补充说明几点,剩余大家看代码理解:
1. device = 'mps' if torch.backends.mps.is_available()
else 'cpu',是启用M3的GPU加速
2. 训练的数据结构中,“子需求技术PM”字段是labels,即“分类值”,训练目标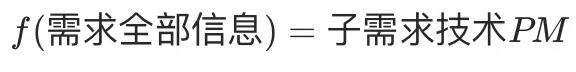
{
'标题': Value(dtype='string', id=None),
'需求指派人': Value(dtype='string', id=None),
'***': Value(dtype='int64', id=None),
'***': Value(dtype='string', id=None),
'***': Value(dtype='string', id=None),
'子需求pd': Value(dtype='string', id=None),
'子需求技术pm': Value(dtype='int64', id=None),
'***': Value(dtype='string', id=None)
}
|
lr_scheduler,是预热LR值,保持动态的LR(1e-1到5e-5范围),加速收敛
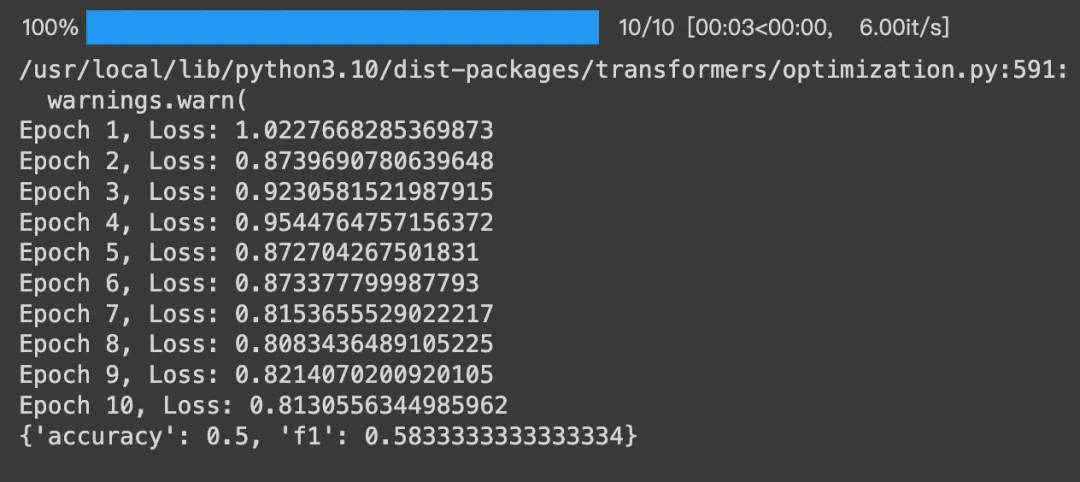
大概训练100轮后,loss收敛到预期目标:

最后拿了一条没有填写技术子PM的数据做输入后,给出了预期团队,但非预测同学的结果(还算可以,训练样本太少)

04结语
本文从神经网络的基本原理出发,逐步深入探讨了神经网络模型的演进,特别是Transformer模型的实现原理及其在自然语言处理领域的应用。通过对神经网络的输入处理、注意力机制、残差网络、前馈网络等关键组件的详细解析,以及实际的代码实现,读者可以全面理解AI模型的工作机制。此外,文章还介绍了如何利用开源模型进行实际任务的开发,为读者提供了从理论到实践的完整指南。希望本文能够帮助读者更好地掌握AI技术,激发对技术的热情,推动AI领域的发展。
|








