| 编辑推荐: |
本文主要介绍了Agent-S:一个类人使用计算机的开放代理框架相关内容。希望对你的学习有帮助。
本文来自于微信公众号Tech For Fun,由火龙果软件Linda编辑,推荐。 |
|
概述
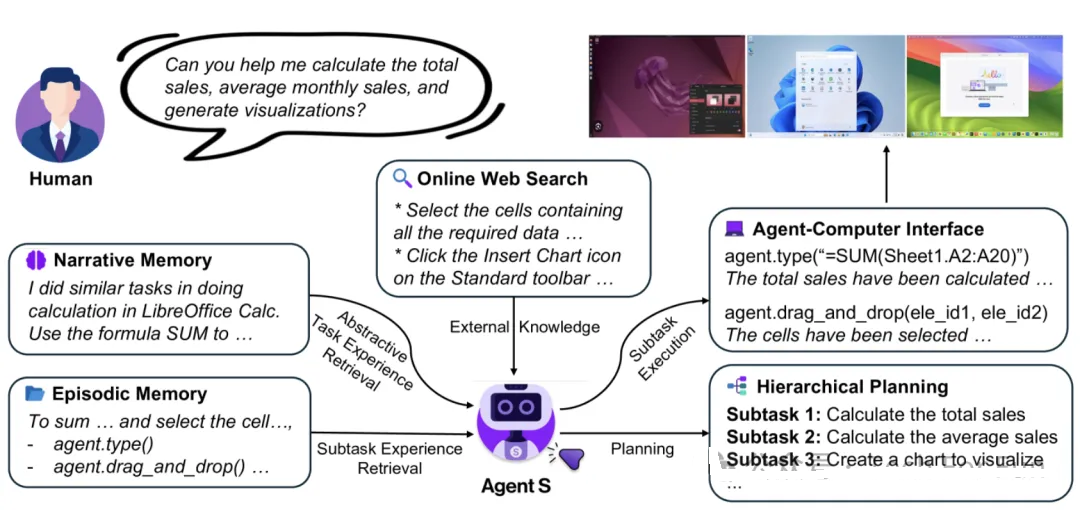
Agent-S 是一个开放的代理框架,可以通过图形用户界面(GUI)与计算机进行自主交互,旨在通过自动化复杂的多步骤任务来改变人机交互。Agent-S
旨在解决计算机任务自动化中的三个关键挑战:获取特定领域的知识、长期任务范围内的规划以及处理动态、非统一的界面。为此,Agent-S
引入了经验增强的分层规划,它可以从多个层次的外部知识搜索和内部经验检索中学习,促进高效的任务规划和子任务执行。
此外,它还采用代理-计算机接口(Agent-Computer Interface,ACI)来更好地激发基于多模态大语言模型(MLLM)的GUI代理的推理和控制能力。OSWorld
基准评估显示,Agent S 的成功率比基准高出 9.37%(相对提高了 83.6%), 展示了 SOTA(state-of-the-art)
性能(即当前最先进的多模态大语言模型能力性能)。综合分析突出了各个组件的有效性,并为未来的改进提供了基础。此外,Agent-S
在新发布的 WindowsAgentArena 基准测试中展示了对不同操作系统的广泛通用性。
首先,大量不断发展的应用程序和网站要求代理拥有专业且最新的领域知识以及从开放世界经验中学习的能力。
其次,复杂的桌面任务通常涉及长期、多步骤的规划,以及必须按特定顺序执行的相互依赖的操作。因此,代理必须创建一个包含中间子目标的清晰计划并跟踪任务进度。
GUI 代理必须导航动态、非统一的界面,在广阔的操作空间内操作时处理大量的视觉和文本信息。
核心概念
MLLM 代理
多模态大语言模型(Multimodal Large Language Models,MLLM)代理。多模态大语言模型(MLLMs)的出现催生了大量将其作为代理系统推理骨干的作品。这些代理通过记忆、结构化规划、工具使用以及在外部环境中行动的能力来增强
LLM。这些代理在各种领域都大有可为,其中包括具身模拟器、视频游戏和科学研究。特别是在软件工程领域提出了
"Agent-Computer" 的概念。提出了一种代理-计算机接口(ACL),使
MLLM 代理能够更高效、更可靠地理解和行动。本文的研究将这些单独的模块扩展并整合到一个新的用于计算机控制的
MLLM 代理框架中。
GUI 代理
MLLM 代理已被应用于在网络和操作系统环境中执行自然语言指令。早期的研究集中于网络导航任务,利用
MLLM 与网络界面进行交互。最近,研究重点转移到了操作系统级环境,从而开发出了一些基准和框架,如
OSWorld、WindowsAgent、WindowsAgentArena 以及 用于桌面控制的DiGIRL
和用于移动环境 AndroidWorld。这些操作系统级任务提供了更广泛的控制能力,超越了网络导航中单一浏览器上下文的限制。在方法上,早期的GUI代理采用了强化学习的行为克隆、上下文中的轨迹示例、依赖状态的离线体验和可重复使用的技能生成。与此同时,针对视频游戏和操作系统的GUI代理提出了不同的认知架构实例。本文的工作贡献了独特的模块,如经验增强的分层规划和用于GUI控制的
ACI,并与新颖的持续记忆更新框架相集成。
AI代理的检索增强生成(RAG)
RAG 通过使用可靠的最新外部知识来增强输入,从而提高了 MLLM 推断的可靠性。同样,MLLM 代理也受益于任务示例检索、状态感知指南和过去的经验。本文对经验的使用有三个不同点:
分层规划既利用了完整任务经验,也利用了子任务经验;
完整任务经验被总结为抽象的文本奖励,用于子任务规划;
子任务经验在存储到记忆之前,由自我评估者进行评估和注解。
Agent-S 框架概览
Agent-S 是一个新颖的框架,它在一个闭环中整合了三种主要策略,以处理复杂的基于GUI的操作系统控制任务:经验增强型分层规划、叙事记忆和情节记忆的持续更新,以及对GUI进行精确感知和操作的代理-计算机接口。
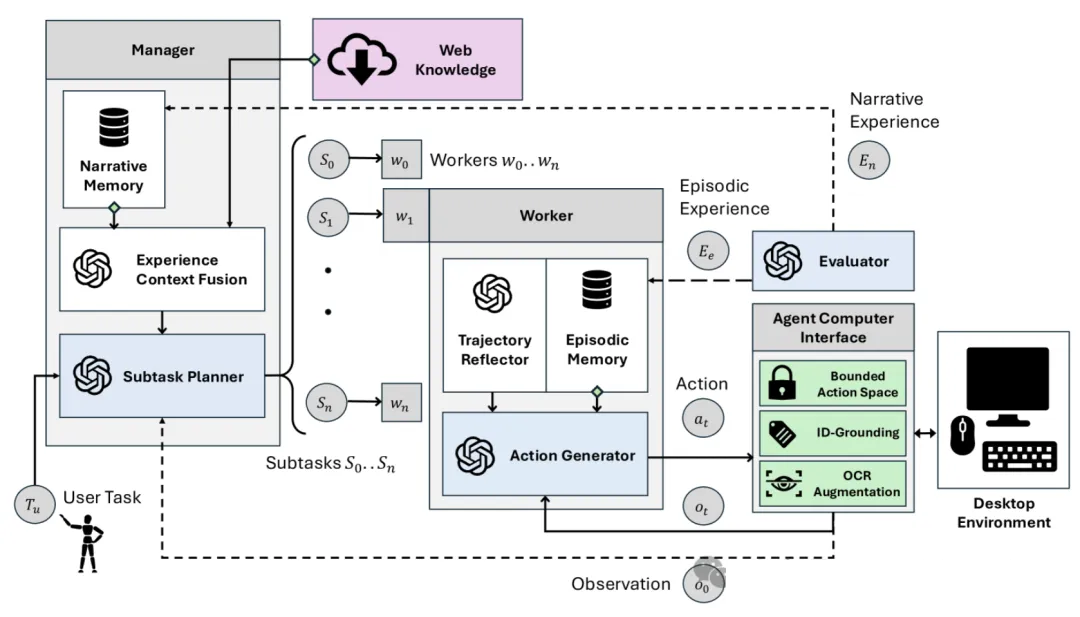
经验增强型分层规划
Manager:融合外部知识和内部经验进行规划
Manager G 是系统中的主要规划生成模块。它接收来自用户的任务
Tu 和来自 ACI 的初始环境观察结果 O₀M(注解可访问树 + 屏幕截图)作为输入。Manager
根据用户指令及其观察结果,以 “如何做 X ”的格式制定一个观察感知查询 Q。该查询用于两种类型的检索。首先,该查询用于通过
Perplexica 搜索引擎进行在线网络搜索,以获取外部知识。然后,使用相同的查询从管理者自己的叙事记忆
Mn中检索类似的任务经验总结。检索基于查询嵌入的相似性。
叙事记忆包括成功和失败的轨迹总结,其中的具体操作被删除,成为抽象的完整任务经验
Enu。成功/失败由自我评价器评估 S 模块进行评估,无需任何人工反馈或基本真实信息。这种两步式检索为管理器提供了规划任务所需的一般和特定领域知识。检索过程的输出结果将通过
“经验上下文融合” 子模块融合为一个单一的融合指南:
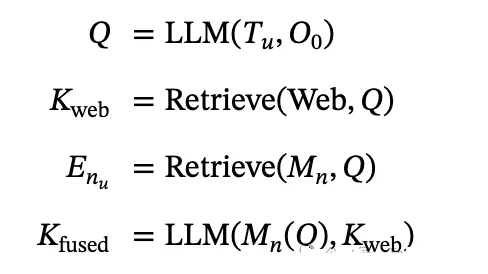
然后,Manager 的子任务规划子模块利用融合知识 Kfused,制定出一个详细的、按拓扑排序的子任务队列
⟨S0 ...Sn⟩ 来完成用户指令。Manager 还会为每个子任务生成相关的上下文 Csi 为每个子任务
Si 包括对完成子任务有用的附加信息。
Worker:从子任务经验和轨迹反思中学习

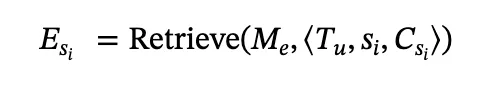
子任务经验 Esi 和反思由 Worker 中的行动生成器子模块用于生成单一的结构化响应--由上一行动状态检查、观察分析、语义下一行动和基础下一行动组成。这种结构化响应允许代理生成一个模板化的思维链,用于改进推理,并产生一个单一的定位行动
aj。该行动被传递给 ACI,ACI 在桌面环境中实现该行动。一旦 Worker 推理出子任务已经完成,它就会生成一个特殊的定位动作
DONE,表示子任务成功结束。在这种情况下,分层操作会被重置,管理器会根据中间环境配置重新扫描一组新的子任务。
自我评价者:将经验总结为文字奖励
自我评价器 S 负责生成经验总结,作为 Manager 和 Worker
模块的文字奖励 r。在 Worker 以 DONE 信号成功结束一个情景的情况下,评价器会观察整个情景,并以总结
Worker 完成该子任务的策略的形式生成学习内容。这一策略会反馈到 “Worker” 的情景记忆中。在用户提供的完整任务结束时(以成功完成所有子任务或达到最大步数限制为标志),评价器会以总结整个任务完成过程的形式生成学习信号。该总结被反馈并保存在
Manager的叙事记忆 MU 中。观察、分层行动生成以及奖励的过程以文本总结的形式更新了 Manager
和 Worker 的内部记忆,这与经典的分层强化学习过程如出一辙,只不过是将检索作为一种学习策略。
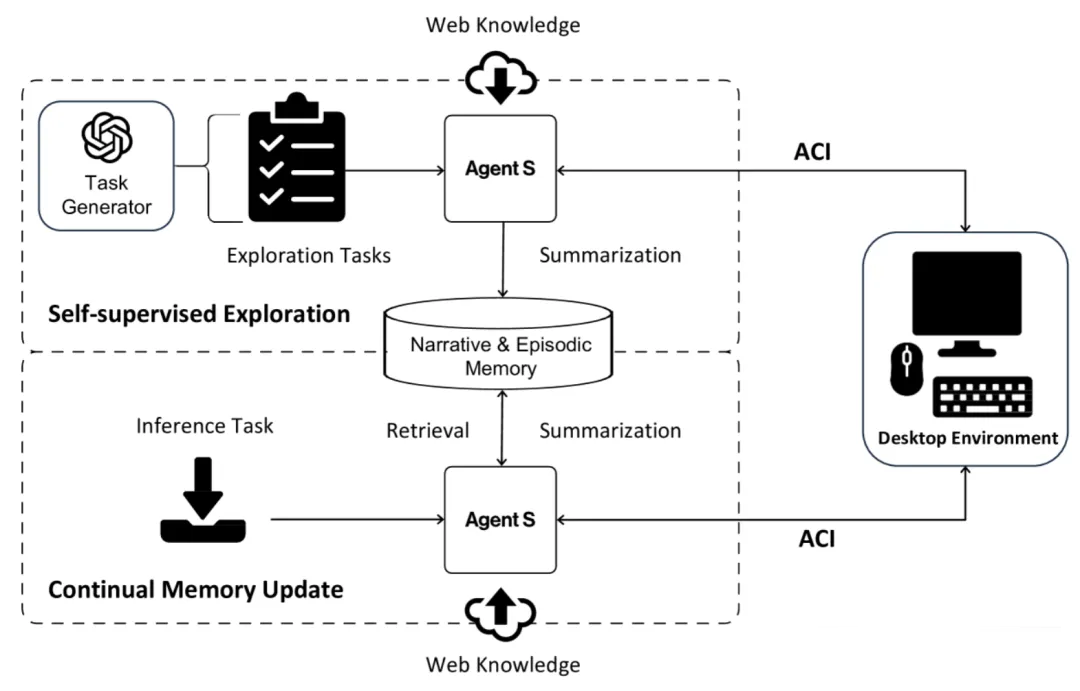
记忆构建和更新
通过自我监督探索构建初始记忆
为了引导叙事记忆 Mn 和情节记忆 Me,Agent-S 在一组合成生成的任务上进行自我监督探索。它采用两种方法创建两种类型的随机探索任务:独立于环境的任务和环境感知任务。对于独立于环境的任务,利用任务生成器,从
OSWorld 和 WindowsAgentArena 中使用的各种应用程序生成前 50 个最常见的任务。对于环境感知任务,采用
OSWorld 和 WindowsAgentArena 中任务的初始环境,并提示任务生成器根据环境生成不同的任务。这两类任务都由探索任务组成。然后,在这些任务上运行
Agent-S ,只获取网络知识 Kweb,并收集完整任务(叙事经验 En )和子任务经验(情节经验
Ee ),分别用于叙事记忆和情节记忆。存储在叙事记忆 Mn 中的关键是查询 Q,而对于外显记忆 Me,关键是查询
Q 与子任务信信。通过这一过程,初始记忆就构好了。
持续记忆更新
当Agent-S 与新任务交互时,它会不断更新叙事记忆 Mn 和情节记忆
Me。因此,即使在初始探索完成后,代理仍会在遇到和尝试更新、更新颖的任务时继续学习。这一过程使代理在推理过程中也能学习,并有效地将学到的知识用于新任务。
代理-计算机接口
目前的桌面环境是为适应两种不同的用户类型而设计的:(1) 人类用户,他们可以实时感知和响应微妙的视觉变化;(2)
软件程序,通过脚本和应用程序接口 (API) 执行预定义的任务。然而,这些界面对于负责GUI控制和基本键盘鼠标操作的
MLLM 代理来说是不够的。这些代理以不同的模式运行:它们以缓慢、不连续的时间间隔做出响应,缺乏内部坐标系统,无法有效处理每次轻微鼠标移动或键盘输入后的细粒度反馈。从为软件工程代理开发的
ACI 中汲取灵感,创建一种新型 ACI,以弥合 MLLM 代理的独特操作限制与开放式GUI控制任务要求之间的差距。
感知与定位
目前的 MLLM 可以有效推理图像中的某些元素和特征,但由于缺乏内部坐标系,它们无法直接精确定位图像中的特定元素。在GUI操作中,代理需要不断与精细的UI元素进行交互,而之前的研究表明,定位是这些代理的一个重要瓶颈。然而,桌面环境提供了一个易于解析的可访问树,其中包含UI中几乎每个元素的坐标信息。因此,ACI
设计采用了双输入策略,每种输入都有不同的目的。代理使用图像输入来观察环境的明显细节,例如弹出窗口、按钮状态、检查上一步操作是否有效,以及推理下一步操作。可访问性树输入用于推理下一步操作,更重要的是,用于确定环境中的特定元素。为此,为可访问树中的每个元素都打上独特的整数标签,以便代理在引用这些元素时使用。此外,之前的研究试图利用可访问树中的信息来增强图像,而本文利用图像中的细节来增强可访问树。为此,在图像上运行一个
OCR 模块,并解析截图中的文本块。然后,如果可访问树中还没有可交互的UI元素,就将这些块添加到可访问树中。为了检查现有元素,会对树中的所有元素进行交并比(Intersection
over Union,IOU)匹配。
具有并发反馈的受限行动空间
桌面自动化传统上依赖于应用程序接口和脚本,但采用这些作为操作将意味着一个由任意可执行代码组成的无限制组合操作空间。这并不适合键盘鼠标级GUI自动化代理,因为它有损安全性和精确性。代码块可能包含多个连续动作,使代理既无法控制单个步骤,也无法从单个步骤中获得反馈。为了确保代理生成的操作能安全可靠地传递到环境中,并产生清晰及时的反馈,ACI
设计包含了一个有边界的操作空间。该空间包括点击、键入和热键等基本动作。代理可以通过标记的 ID 来指代不同的元素,而
ACI 会将这些 ID 转换为 ⟨primitive - ID⟩ 信息转化为可执行的 Python
代码。此外,每个时间步骤只允许代理执行一个离散动作,这样它就能观察到来自环境的即时反馈。这些动作也足够粗略,以考虑到
MLLM 缓慢、无状态的特性,例如,代理可以直接移动并点击一个元素,而不是小幅度地移动鼠标。
未来工作
在现有计算机控制 MLLM 代理研究中,一个尚未涉及的关键指标是完成任务所需的代理步骤数和实际时间。虽然本文的工作重点是显著提高任务性能,但未来的工作可以考虑GUI控制的最短路径导航问题,并评估各种代理在时间和准确性方面的帕累托最优性。本文使用了最先进的
GPT-4o 和 Claude-3.5-sonnet 模型。不过,未来的工作可以将体验式学习和代理计算机界面的理念扩展到更小的、开源的
MLLMs 上,并对其进行微调,以缩小差距。
|




