| 编辑推荐: |
本文主要介绍了DeepSeek
全面指南相关内容。希望对你的学习有帮助。
本文来自于微信公众号子奕话 AI,由火龙果软件Linda编辑,推荐。 |
|
惊呆了!
时隔不到一个月,DeepSeek又一次震动全球AI圈。
2024年底,DeepSeek发布了新一代大语言模型V3,同时宣布开源。
测试结果显示,它的多项评测成绩超越了一些主流开源模型,实现了与GPT-4o和Claude Sonnet
3.5等顶尖模型相媲美的性能,并且还具有成本优势。

和上次不同的是,这次推出的新模型DeepSeek-R1不仅成本低,更是在技术上有了大幅提升。
新模型延续了其高性价比的优势,仅用十分之一的成本就达到了GPT-o1级别的表现。
而且,它还是个【开源模型】。

什么是Deepseek-R1?
深度求索智能助手(DeepSeek-R1)
简介: 深度求索智能助手是由深度求索(DeepSeek)公司开发的人工智能助手,专注于通过自然语言交互提供精准、高效的信息服务与解决方案。基于先进的深度学习技术和多领域知识库,能够处理复杂问题、生成创意内容,并适配多样化场景需求。
特点:
多语言与多领域支持:覆盖科技、教育、文化、生活等领域,支持中英文等多语言交互。
实时信息整合:可联网搜索最新信息,结合知识库提供动态更新的答案(需联网模式下使用)。
逻辑与推理能力:擅长数学计算、代码编写、数据分析等需要逻辑处理的场景。
隐私与安全:对话内容默认不存储,用户隐私保护严格遵循行业规范。
个性化交互:支持上下文理解与长对话,根据用户需求调整回复风格(如简洁/详细、正式/幽默等)。
据介绍,R1模型在技术上实现了重要突破——用纯深度学习的方法让AI自发涌现出推理能力,在数学、代码、自然语言推理等任务上,性能比肩OpenAI的o1模型正式版,该模型同时延续了该公司高性价比的优势。
据了解,深度求索公司R1模型训练成本仅为560万美元,远远低于OpenAI、谷歌、“鼋”公司等美国科技巨头在人工智能技术上投入的数亿美元乃至数十亿美元。
他们是怎么实现的?
英伟达GEAR Lab项目负责人Jim Fan在推特中也提到了,DeepSeek-R1用通过硬编码规则计算出的真实奖励,而避免使用任何RL容易破解的学习奖励模型。
Jim Fan甚至认为,它们做了OpenAI本来应该做的事,开源。

在o1推出之后,推理强化成了业界最关注的方法。一般来说,一个模型在训练过程中只会尝试一种固定训练方法来提升推理能力。
而DeepSeek团队在R1的训练过程中,直接一次性实验了三种截然不同的技术路径:直接强化学习训练(R1-Zero)、多阶段渐进训练(R1)和模型蒸馏,还都成功了。
其中最让人激动的,还是直接强化学习这个路径。因为DeepSeek-R1是首个证明这一方法有效的模型。
Deepseek的出色表现,很大程度源于架构设计创新,其中备受关注的MoE(混合专家架构)大幅提升资源利用效率。
打个比方,就像老板召集全员开会效率低,分小组依次开小会更高效,MoE便是这种细分、高效调用、节约资源的架构。
大公司有钱购置大量算力,为快速出成果,倾向选择传统稳妥路线做产品。OpenAI这类龙头,必然希望行业按其探索的路径发展,它始终保持领先。
Deepseek是后起小厂,资源有限,只能通过技术创新提升模型能力,结果实现了弯道超车。
说了这么多,deepseek到底有多优秀呢? 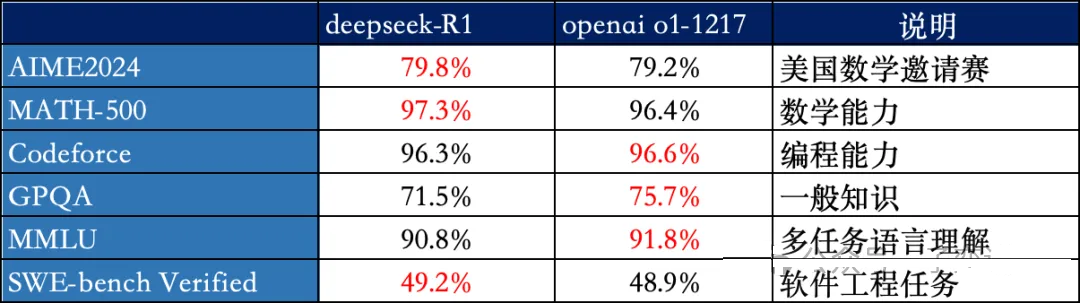
在多项测试中和OpenAI性能相当,各有千秋,但是训练和使用成本都只有OpenAI的5%,两边差了20倍。
实操体验
(热度太高太拥堵了,试了好几天等了好久)
1、文案创作

看看成果: 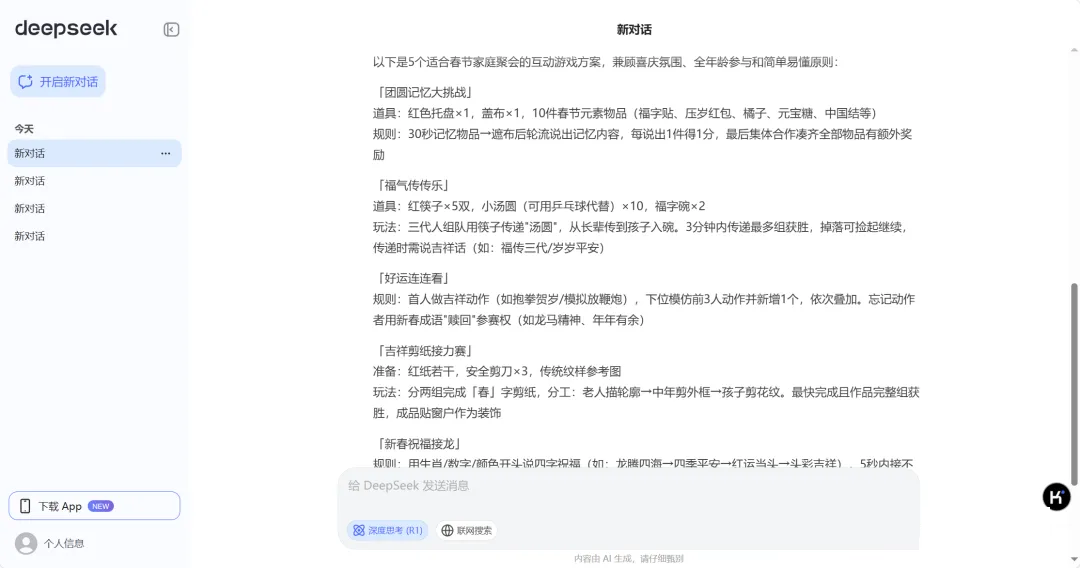
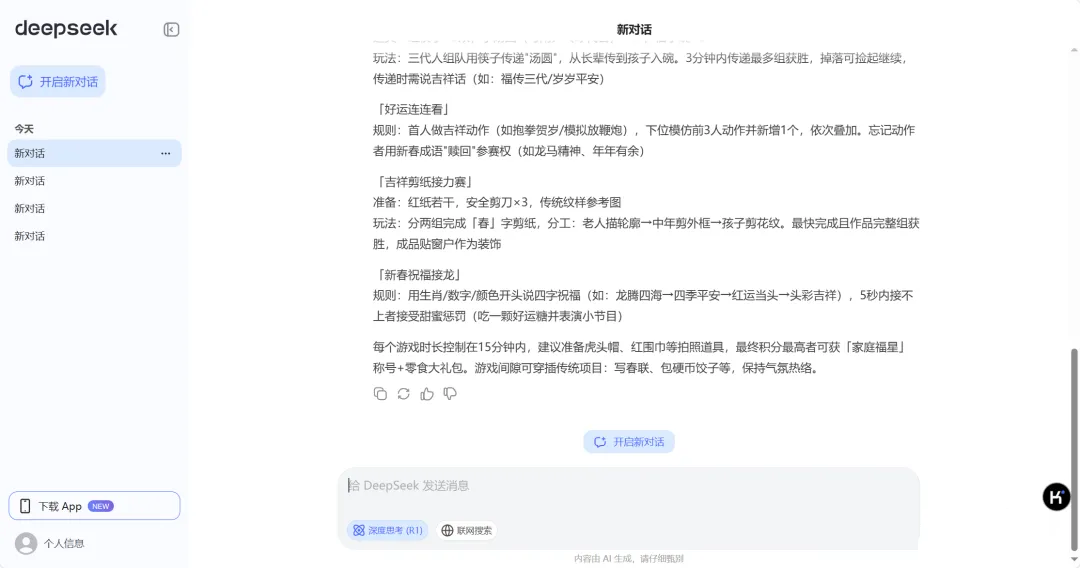
2、代码编写
看看完成效果: 
3、逻辑推理
我上传了2024年高考数学的一道题: 
反馈如下: 
4、惊喜!
R1模型会进行深度思考,而且思考时间比较长,但是很详细的思考过程令我大受震撼!它的逻辑是真的强啊


小技巧
Deepseek和其他AI不太一样,不重提示词,讲人话反而更能让它听得懂。
深度体验玩了几天,我总结了三个提示词句式,大家可以去试试。
心法一:角色穿越术——给AI一个精准人设
黄金句式: "你现在是精通______的______,请用______的风格帮我解决______"
实操案例:
情感导师版:"你现在是甄嬛传十级学者,用华妃怼人语气写段劝删渣男微信的台词"
职场生存版:"你现在是精通劳动法的阴阳HR,用表面夸赞实则拒绝的话术帮我回绝加班需求"
进阶技巧: 人设越具体,效果越惊艳!试试叠加"从业10年的资深律师+擅长讲相声的天津人"这类跨界组合,AI会给你意想不到的惊喜回复。
心法二:痛点爆破术——像产品经理一样提需求
黄金句式: "我要实现______,目前有______资源/条件,但存在______阻碍,请给出______解决方案"
实操案例:
创业避坑版:"在五线小城开螺蛳粉店,预算3万,周边3家竞品,如何用差异化策略突围?"
社交话术版:"想优雅拒绝同事借钱,需要5条让对方知难而退又不伤和气的微信模板"
避坑指南: 像对接乙方一样给足背景信息,越详细越容易得到靠谱方案。记住这个要素公式:目标+资源+障碍=精准答案。
心法三:反套路拆解法——三步破解刁钻问题
黄金句式: "如果遇到______的情况,你会如何应对?请分三步说明,每步需包含一个隐藏陷阱及破解策略"
实操案例:
职场PUA版:"老板要求24小时做100张海报,如何体面破局?"
亲子教育版:"孩子说'考不好就去死',怎样回应既保护心理又纠正认知?"
思维训练: 这种提问法能逼出AI的深度思考,特别适合处理两难问题。得到的不仅是答案,更是解决问题的思维框架!
在DeepSeek席卷全球几天之后,就在刚刚,网上已经出现了一波复现DeepSeek的狂潮。
UC伯克利、港科大、HuggingFace等纷纷成功复现,只用强化学习,没有监督微调,30美元就能见证「啊哈时刻」!
全球AI大模型,或许正在进入下一分水岭。 |








