| 编辑推荐: |
本文主要介绍了深度学习领域的武功传承之法—知识蒸馏相关内容。希望对你的学习有帮助。
本文来自于微信公众号E等于mc平方,由火龙果软件Linda编辑,推荐。 |
|
在金庸武侠小说《天龙八部》中,无崖子,作为逍遥派祖师的二弟子,也是逍遥派的第二任掌门。在接任逍遥派掌门后,因各种纠葛,遭到徒弟丁春秋的暗算,被推下山崖,虽侥幸不死,但几乎全身瘫痪,于是摆下珍珑棋局,希望能找到一个有大智慧的人,传下自己的毕生功力和绝学为自己清理门户。
虚竹本是小少林僧人,武功低微且不通棋艺,因机缘巧合下,落下一子,自填一气导致大片白棋被提,意外破解棋局。无崖子看重虚竹的仁厚心性,决定传功。无崖子以逍遥派秘法"北冥神功"为基础,将自身七十余年的内力通过头顶"百会穴"强行灌入虚竹体内。
其他人纵然是好运在身,那也还得经过一番磨难然后才能练就绝世武学,进而走上巅峰,可是虚竹却完全是“平步青云”!他凭空就得到了逍遥派掌门人七十余年的功力!他甚至不需要自己修炼,就得到了无崖子毕生的功力,让他从一个籍籍无名的小和尚一步登天,蜕变为武林中绝顶高手。而且因内力暴涨,虚竹的相貌从原本的平凡变得神采奕奕,从此走上人生巅峰。
深度学习中的“江湖”
知识蒸馏是一种机器学习技术,目的是将预先训练好的大型模型(即 "教师模型")的学习成果转移到较小的
"学生模型 "中。
在深度学习中,它被用作模型压缩和知识转移的一种形式,尤其适用于大规模深度神经网络。
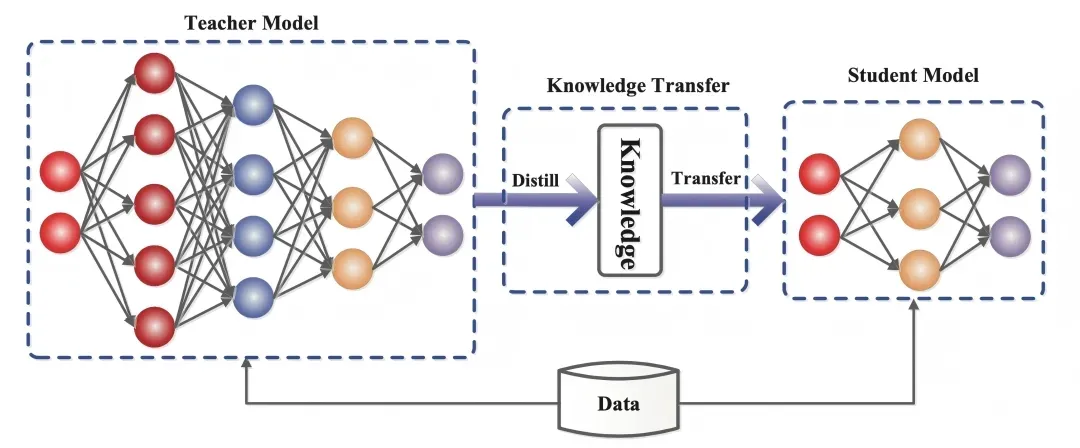
知识蒸馏的本质是知识迁移,模仿教师模型的输出分布,使学生模型继承其泛化能力与推理逻辑。
最近大火的DeepSeek团队发布的DeepSeek-R1,其670B参数的大模型通过强化学习与蒸馏技术,成功将能力迁移至7B参数的轻量模型中。
蒸馏后的模型超越同规模传统模型,甚至接近OpenAI的顶尖小模型OpenAI-o1-mini。
在人工智能领域,大型语言模型(如GPT-4、DeepSeek-R1)凭借数千亿级参数,展现出卓越的推理与生成能力。然而,其庞大的计算需求与高昂的部署成本,严重限制了其在移动设备、边缘计算等场景的应用。
如何在不损失性能的前提下压缩模型规模?知识蒸馏(Knowledge Distillation)就是解决这个问题的一种关键技。
知识蒸馏的工作原理
知识蒸馏的工作原理可以概括为以下几个步骤,通过这些步骤,我们可以将一个复杂模型(教师模型)的知识有效地迁移到一个简单模型(学生模型)中,以提高学生模型的性能:
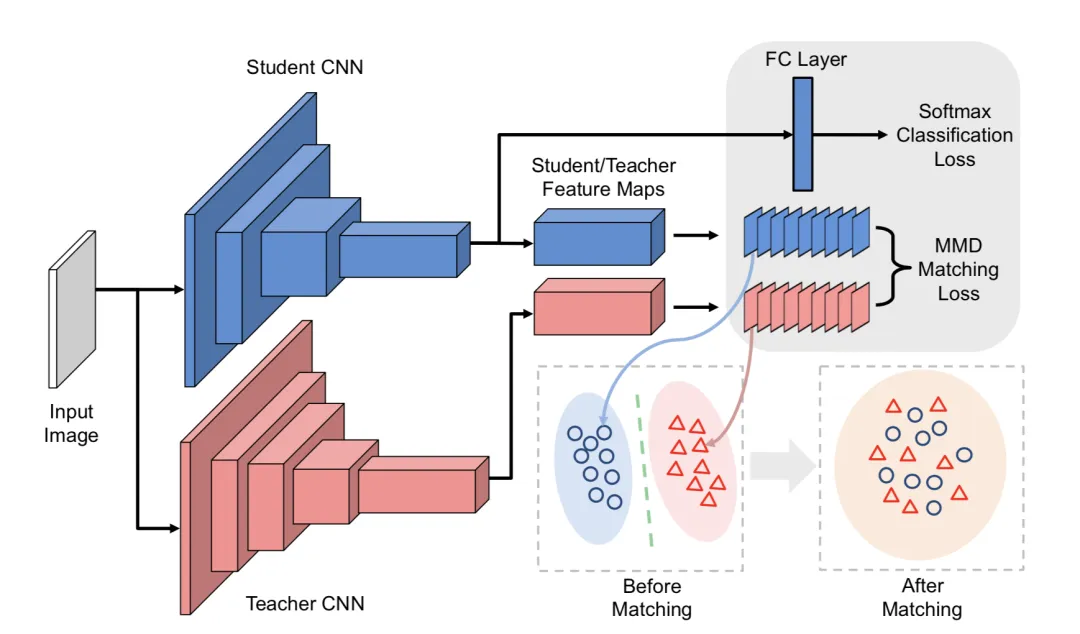 1. 选择教师模型:首先,选择一个已经训练好的深度学习模型作为教师模型,这个模型通常具有较好的泛化性能和表示能力
。
2. 生成软标签:教师模型对训练数据集进行预测,生成软标签(概率分布),这些标签包含了输入数据的丰富信息。
3. 初始化学生模型:接着,选择一个相对简单的模型作为学生模型,并初始化其参数,可以是从教师模型中随机初始化,也可以是使用一些其他策略。
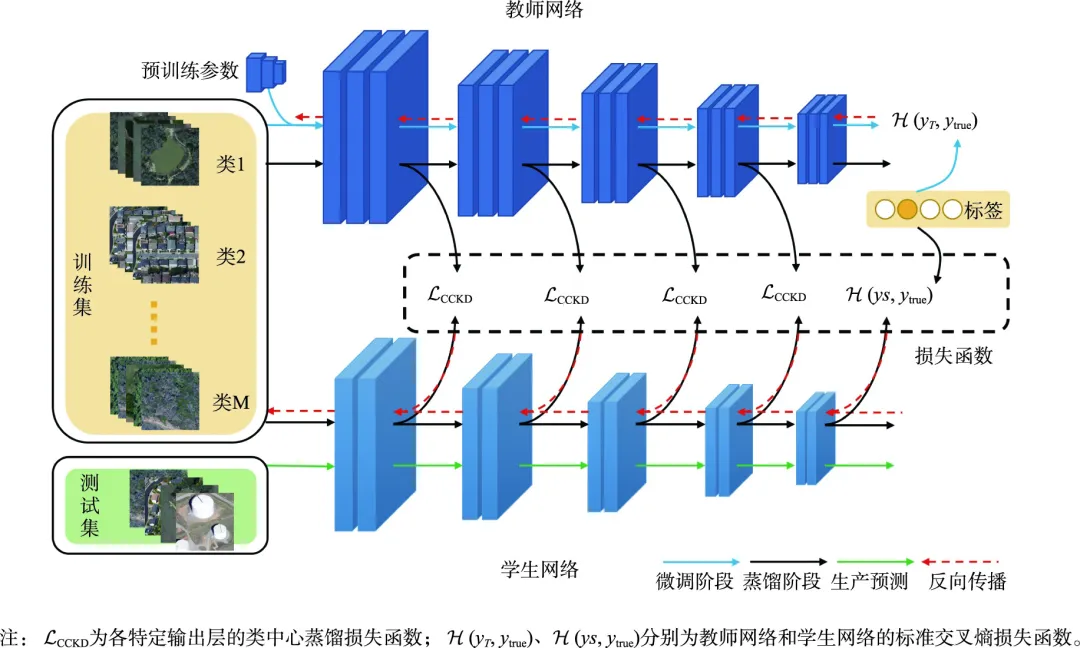
4. 定义损失函数和辅助损失:定义损失函数来衡量学生模型输出和教师模型软标签之间的差异。常用的损失函数包括Kullback-Leibler
(KL) 散度和交叉熵。除了模仿教师模型的输出,学生模型还可能需要直接学习真实标签,以确保其准确性。
5. 温度调整:使用温度参数调整软标签的平滑程度,温度较高时,概率分布更加平滑,有助于学生模型学习到更泛化的特征;温度较低时,概率分布更接近真实标签,有助于学生模型学习到更具体的信息。
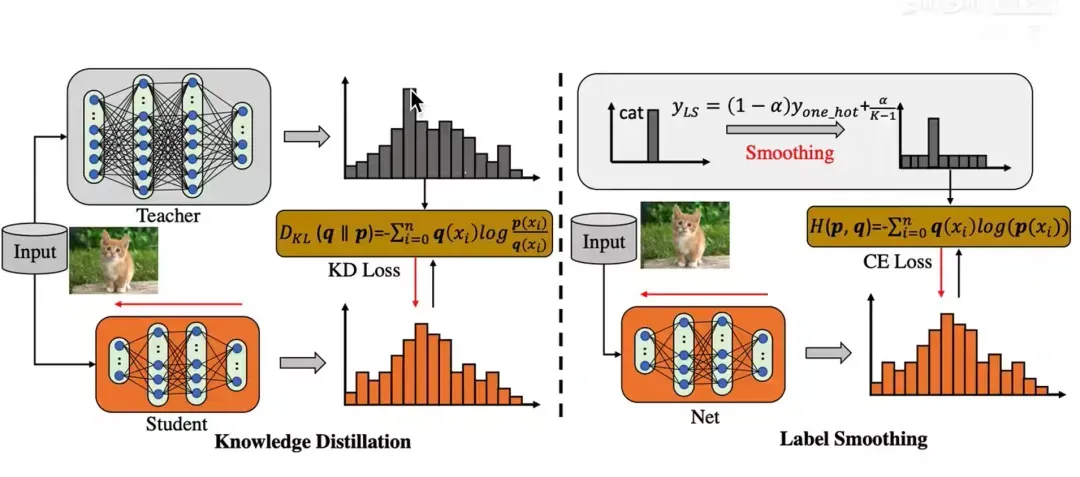
温度参数调整软标签的平滑程度
6. 优化与评估:使用损失函数指导学生模型的训练。在训练过程中,学生模型尝试模仿教师模型的软标签输出,同时学习如何正确分类训练数据,并不断评估和优化学生模型的性能。
随着AI技术的普及,越来越多的应用场景需要在资源受限的设备上运行高效的模型。如移动设备和嵌入式系统,对计算资源有严格的限制。
大型深度学习模型往往需要大量的计算能力和存储空间,不适合这些环境。
知识蒸馏可以将大型模型中的知识迁移到小型模型,使小型模型在保持较低计算成本(减少标注数据和计算资源需求)的同时,实现接近大型模型的性能。
在需要实时或近实时反馈的应用中,小型模型由于其较低的延迟特性,可以更快地进行推理。
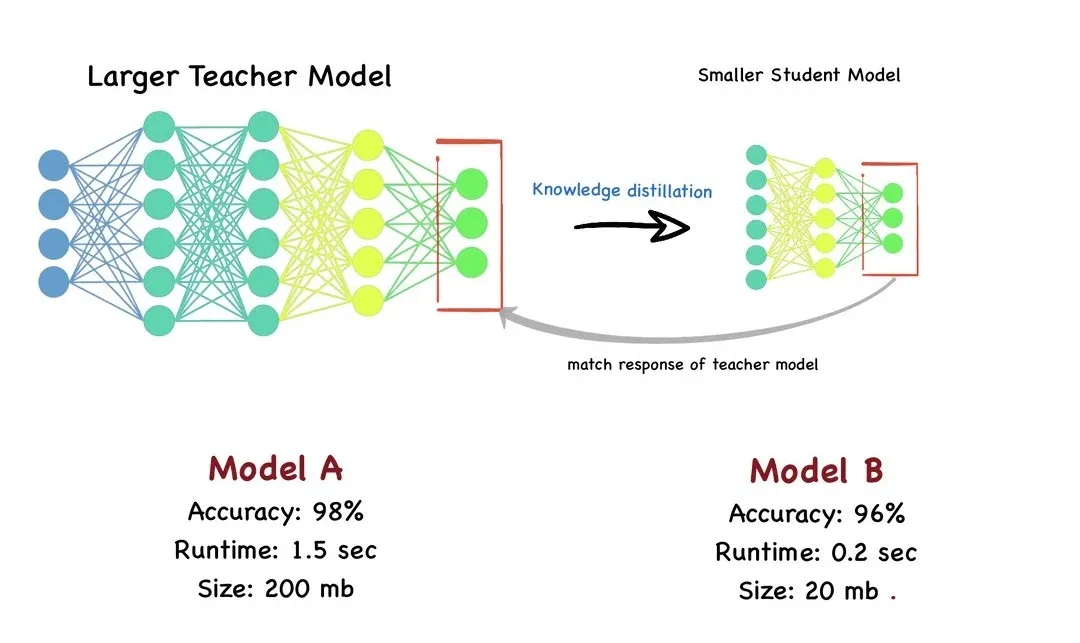
例如,DeepSeek推出的新模型DeepSeek-R1在数学、编程和推理等关键领域的表现能与OpenAI的最强推理模型相媲美,且训练费用仅为OpenAI最新大模型的二十分之一,引发海外AI圈的广泛讨论。
|






 订阅
订阅