| 编辑推荐: |
本文主要介绍了DeepSeek
MoE相关的技术发展相关内容。希望对你的学习有帮助。
本文来自于微信公众号DataFunTalk,由火龙果软件Linda编辑,推荐。 |
|
前几天临时加了一个任务, 帮着几个兄弟团队做一些DeepSeek-R1满血版的推理优化, 当然现阶段主要是在SGlang和vLLM上做一些简单的调优,
毕竟H20这些卡的资源也挺紧张的. 最近发现SGlang和vLLM两个团队卷的挺厉害的. vLLM 0.7.2增加了Triton
MLA和FusedMoE的优化, 然后比起SGlang还有pp并行的优势. 当然SGlang的pp并行也在开发,
另一方面vLLM的MTP也在开发中, 未来两三周两个框架的性能还有进一步提升的空间.
通过搞了几天推理对DeepSeek MoE有了一些理解, 然后经过DeepSeek团队同学的指正,
原来的对MoE Group Limit的一些理解还是存在错误的, 因此详细来写一篇关于MoE的笔记.
另外, 很多事情还是得在一线把自己手弄脏, 满手是泥的才能体会到很多工程细节上的巧妙之处, 很多人可能就是读读论文,
“不就是MoE么, 我也有呀”, 正是这样的一些问题, 错失了了解很多工程细节里的巧妙.
需要注意的是,DeepSeek这样细粒度的MoE处理, 671B的模型实际激活只有37B, 在分布式推理系统上带来了很多很好玩的做法(正在做一些尝试XD~),
然后训推一体极致化的资源弹性利用,未来进一步演进到Life-time的learning/Training可能会让一些其它玩家感到绝望.
本文结构如下:
1 Transformer模型的优化空间
2 基本的Sparse MoE工作原理
3 专家负载均衡和AuxLoss
4 DeepSeek-V1 MoE
4.1 Fine-Grained Expert Segmentation
4.2 Shared Expert Isolation
4.3 专家负载均衡
5. DeepSeek-v2
5.1 Device-Limited Routing
5.2 通信负载均衡损失
5.3 Token丢弃策略
6. DeepSeek-V3
6.1 Gating函数采用Sigmoid
6.2 专家分组
6.3 无需辅助损失函数的负载均衡
6.4 无需Device-Limit Routing和Token-Drop
6.5 AlltoAll Infra的改动
6.6 推理阶段MOE处理
6.7 对Infra的改进建议
7. 关于MoE演进
|
01
Transformer模型的优化空间
从最早的Transformer架构来看, Attention Block的计算量为, MLP Block的计算量为.
针对模型规模扩大下的算法优化自然就盯着这两个block来做了. 例如针对Attention Block的MHA,DeepSeek
MLA以及Stepfun MFA等. 很多的优化主要是前期针对长文本的优化, 这些内容后面再单独来写一篇吧.
而针对MoE的优化, 开源的生态上主要是以Mistral的Mixtral 8x7B开始的, 但是很遗憾几个大厂一开始的阶段都选择了Dense的MLP...DeepSpeed团队有几个人从微软去了snowflake后还搞了一个DenseMoE,
通过MoE block和Attention Block并联来解决一些通信上的问题,可惜后面似乎也没啥声音了.
其实现在回过来翻看DeepSeek的三篇论文题目, 一脉相承
《DeepSeekMoE: Towards Ultimate Expert Specialization
in Mixture-of-Experts Language Models》
《DeepSeek-V2: A Strong, Economical, and Efficient
Mixture-of-Experts Language Model》
《DeepSeek-V3 Technical Report》
第一篇, 迈向终极的专家专业化的MoE模型, 一开始就选择了稀疏MoE模型的方式, 追求尽量高的性能同时保持更小的激活参数.

但是呢, 已有的工作通常专家数较少, 在训练过程中, 专家的专业度容易被过量的token冲击, 形象的理解就是大量的知识使得专家学到的内容很杂,
导致它承载的信息密度受损, 因此专家的专业度(Expert Specialization)出现问题,
基于这个视角提出了细粒度的专家(Fine-Grained Expert Segmentation)以及通过共享专家(Shared
Expert Isolation)来吸收一些一些共同的知识, 降低其它专家的参数冗余. 最终构建出了如下图所示的模型.
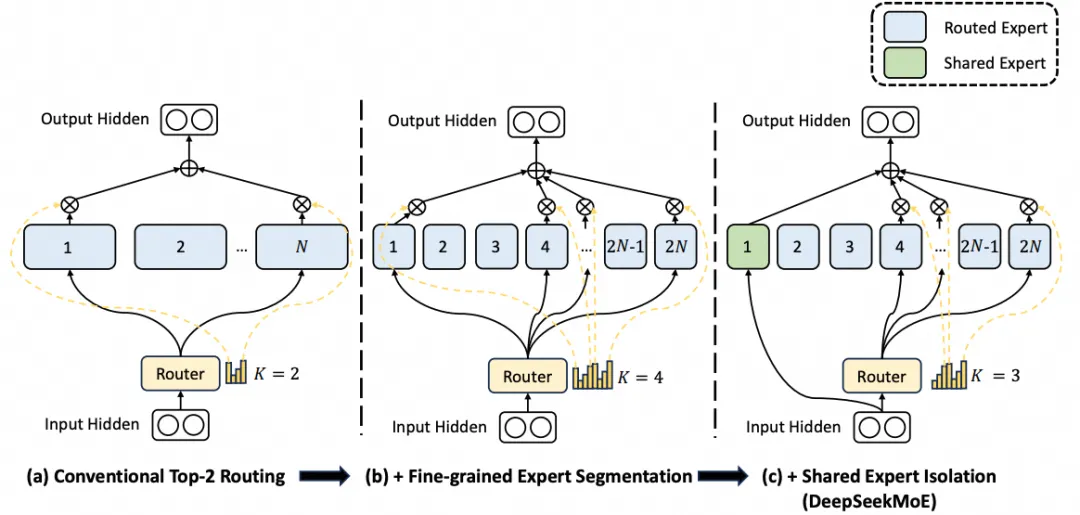
V1的模型构建了64个专家, 并且每个token激活选择6个专家, 同时还配置了2个共享专家.
在第二篇DeepSeek-V2上, 进一步做大做强, 路由专家总数目增加到了160个, 依旧是选择每个token激活选择6个专家,
并配置了2个共享专家. 同时在负载均衡上做了进一步的优化, 并且配合引入MLA实现了”Economical
and Efficient“.
第三篇DeepSeek-V3则是集齐龙珠的一篇, 专家数进一步扩展到256选8, 并且在负载均衡上进一步的优化,
同时还有很多基于Infra的通信优化, 例如训练中的DualPipe还有MoE通信的Offload等,
很好的实现了Cross-Node的A2A通信, 例如文章中3.2.2所介绍的, 考虑到NVLink和IB的带宽比来设计模型,
使用PTX并auto-tune通信的chunk-size来降低L2Cache的使用和对其它SM的影响等.
需要强调一点, 并不是说一个模型的区分在是否使用了MoE, 在MoE的细节上还有非常多的差异. 正是这些微小的差异带来了量变.
其实回过头来看, 似乎每一点做起来都没有什么惊艳的地方, 但对于DeepSeek致敬或许有句话非常恰当:“善弈者,通盘无妙手”
其实渣B一直都是都是坚定的在做MoE的优化, 这些工作在2021年就展开了, 例如NetDAM和Ruta分别在片上网络互联和路由算法上进行优化,
在《闲谈镍合约被逼空》中算是对外公开提及过:“例如渣最近在研究的一个东西叫基于复杂网络中心度约束下的超大规模MOE模型及其训练框架对计算机体系结构影响,只是一个数学加工程同时需要考虑的问题,非常有趣。”
可能比DeepSeek更加极致的在推动例如4096选256专家需要的基础设施和体系结构上的优化,
您也可以看到DeepSeeK-v3的论文提到的对未来通信设备的需求. 例如ScaleUP和ScaleOut语义的统一,
其实反过来你想想为什么ScaleOut就不能做LD/ST了呢? NetDAM很早就打了一个样, DSv3提到的通信Kernel对GPU
SM的占用达到了15%, 集合通信Offload NetDAM也有对应的实现, 只是工业界在RDMA的路上卷的太凶了,
几分无奈...
当然有些东西早已埋在芯片里面了, 例如两年多在实现eRDMA的多路径拥塞控制算法的时候, 已经解决掉了incast的问题,
支持128K QP同时多路径转发避免网络上的冲突, 并且接收端能够公平调度, 128-to-1的时候,每个流之间的误差在100Kbps左右,
这个事情Mellanox/Nvidia估计还要几年的时间才能搞定. 正是有这样的基础,所以渣B在《谈谈国产算力支持大模型和MoE/RL算法协同演进方向》中提及这样一个方向
接下来我们从最简单的sparse MoE开始介绍, 然后再逐渐来分析一下DeepSeek每一代MoE的演进.
02
基本的Sparse MoE工作原理
开源生态的第一个MoE模型应该是Mixtral的8x7B. 模型结构如下
from transformers import AutoModelForCausalLM, AutoTokenizer
model = AutoModelForCausalLM.from_pretrained("mistralai/Mixtral-8x7B-Instruct-v0.1")
print(model)
MixtralForCausalLM(
(model): MixtralModel(
(embed_tokens): Embedding(32000, 4096)
(layers): ModuleList(
(0-31): 32 x MixtralDecoderLayer(
(self_attn): MixtralAttention(
...
)
(block_sparse_moe): MixtralSparseMoeBlock(
(gate): Linear(in_features=4096, out_features=8, bias=False)
(experts): ModuleList(
(0-7): 8 x MixtralBLockSparseTop2MLP(
(w1): Linear(in_features=4096, out_features=14336, bias=False)
(w2): Linear(in_features=14336, out_features=4096, bias=False)
(w3): Linear(in_features=4096, out_features=14336, bias=False)
(act_fn): SiLU()
)
)
)
...
|
每个Expert block基本上都是一个标准的结构
class Expert(nn.Module):
def __init__(self, dim: int, inter_dim: int):
super().__init__()
self.w1 = nn.Linear(dim, inter_dim)
self.w2 = nn.Linear(inter_dim, dim)
self.w3 = nn.Linear(dim, inter_dim)
def forward(self, x: torch.Tensor) -> torch.Tensor:
return self.w2(F.silu(self.w1(x)) * self.w3(x))
|
然后sMoE实现如下所示:
class SMoE(nn.Module):
def __init__(self, args):
super().__init__()
self.hidden_dim = args.dim
self.ffn_dim = args.moe_inter_dim
self.num_experts = args.n_routed_experts
self.top_k = args.n_activated_experts
# gating
self.gate = nn.Linear(self.hidden_dim, self.num_experts, bias=False)
self.experts = nn.ModuleList([Expert(self.hidden_dim,self.ffn_dim ) \
for _ in range(self.num_experts)])
|
由于我们要分析Gating函数, 因此SMoE中具体的forward函数我们稍微晚点再说, 这样就构建出了sMoE的结构
args = ModelArgs()
args.dim = 4096
args.inter_dim = 14336
args.n_routed_experts = 8
args.n_activated_experts =2
smoe =SMoE(args)
print(smoe)
MoE(
(gate): Linear(in_features=4096, out_features=8, bias=False)
(experts): ModuleList(
(0-7): 8 x Expert(
(w1): Linear(in_features=4096, out_features=512, bias=True)
(w2): Linear(in_features=512, out_features=4096, bias=True)
(w3): Linear(in_features=4096, out_features=512, bias=True)
)
)
)
|
它的Gating函数计算如下, 通过一个线性层映射到N个专家, 然后通过softmax并取topK获得
tokens = 13
x = torch.randn(1, tokens, args.dim)
scores = F.softmax(smoe.gate(x.view(-1, args.dim)), dim=-1)
weights, indices = torch.topk(scores, smoe.top_k, dim=-1)
|
softmax计算后的score如下所示:
plt.plot(scores.detach().to('cpu')[0].numpy())
plt.plot(scores.detach().to('cpu')[1].numpy())
plt.plot(scores.detach().to('cpu')[2].numpy())
|

indices为所选择的专家编号, 例如Token 0选择专家4,1, Token 1选择了0,6,
Token2选择了2,3
indices.T
tensor([[4, 0, 2, 1, 4, 6, 2, 3, 7, 3, 3, 7, 5],
[1, 6, 3, 0, 2, 3, 1, 0, 2, 0, 0, 6, 7]])
#画图对比如下
r = list()
for i in range(3):
r.append(np.zeros(args.n_routed_experts))
for item in indices[i].numpy():
r[i][item] = 1
plt.plot(r[i])
|
后续的计算如下:
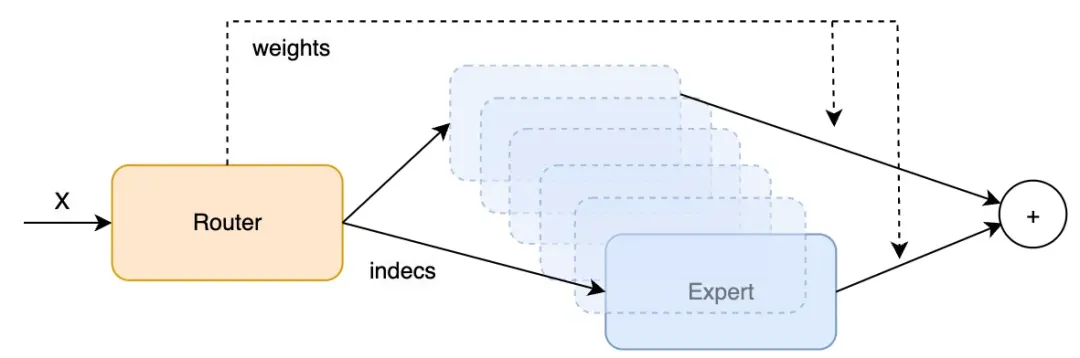
根据输出的indices将token路由到Expert计算完成后乘以weights再汇总求和.
03
专家负载均衡和AuxLoss
但是专家之间的负载会有明显的不平衡, 这样会导致部分的专家信息过载, 而部分的专家却没有得到足够的训练,
导致专家路由崩塌.
例如我们进一步扩大到256个专家选8个做一个测试
args.n_routed_experts = 256
args.n_activated_experts = 8
smoe1 =SMoE(args)
tokens = 1024
x = torch.randn(1, tokens, args.dim)
scores = F.softmax(smoe1.gate(x.view(-1, args.dim)), dim=-1)
weights, indices = torch.topk(scores, smoe.top_k, dim=-1)
counts = torch.bincount(indices.flatten(), minlength=args.n_routed_experts)
plt.plot(counts.detach().to('cpu').numpy())
|
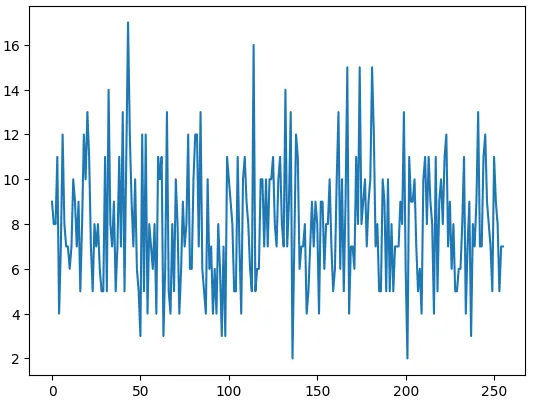
因此, 一个很朴素的想法就是定义一个辅助的损失函数(Aux_Loss), 例如有个token, 个专家,
对于每个专家收到的token的方差之和定义为Loss

avg_counts = counts/tokens
loss = (avg_counts * avg_counts).sum()/args.n_routed_experts
|
但是这样的辅助损失函数并不包含Gating函数的参数, 是无法训练进行梯度更新的, 于是在Google的《GShard》[1]中引入了一个做法,
把平方项的一个分量替代成Gating softmax的均值
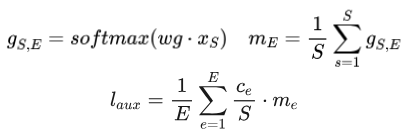
m = scores.mean(dim=0)
avg_counts = counts/tokens
loss_aux = (m * avg_counts).mean()
|
04
DeepSeek-v1 MoE
虽然有了一些负载均衡的算法, 但是在专家数量受限时, 分配给某个特定专家的token可能会涵盖不同类型的知识,
被指定的专家在其参数中将会倾向于学习到差异极大的知识类型,而这些知识难以同时被有效利用。如果每个Token可以被路由到更多的专家,
不同类型的知识就有可能被分解并分别由不同的专家学习。在这种情况下,每个专家仍然可以保持高度的专业化水平,从而促进知识在专家之间的更集中分布。
DeepSeek-V1 MoE的工作主要是如何将专家变得更加细粒度更加专业化(Towards Ultimate
Expert Specialization), 因此做了几个方面的工作:
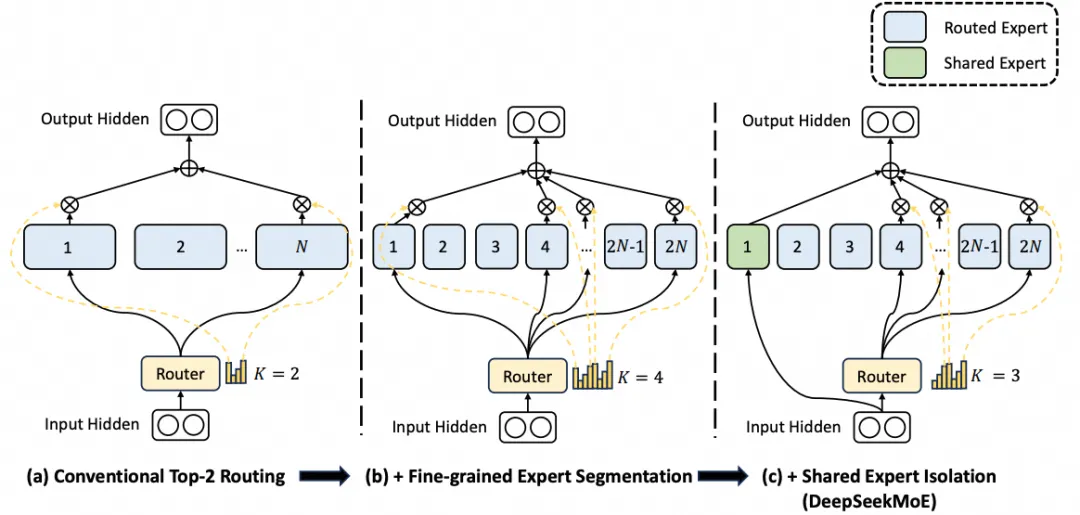
4.1. Fine-Grained Expert Segmentation
在同等专家参数量和计算成本不变的前提下, 对专家进行更细粒度的分割, 这种更精细的专家分割使得激活专家的组合更加灵活且适应性更强.
例如将MoE中的专家FFN分割成个更小的专家, 然后FFN的inter-dim降低到原来的, 相同的计算成本下,
激活专家的数量增加为原来的倍. 例如原来种专家选择, 扩展后可以多达种选择, 这样的组合大幅度的提升了准确性和更有针对性的获取知识的能力.
4.2 Shared Expert Isolation
在传统的路由策略中,分配给不同专家的token可能需要某些共同知识或信息,导致不同专家在各自参数中学习共享知识,从而引发专家参数的冗余。若有专门的共享专家负责捕获和整合不同上下文中的共有知识,其他路由专家的参数冗余将得到缓解,从而构建参数效率更高且专家分工更明确的模型.
为实现这一目标,除细粒度专家分割策略外,Deepseek进一步隔离了个专家作为共享专家。无论路由模块如何分配,每个token均被确定性地分配给这些共享专家。为保持恒定计算成本,其他路由专家中激活的专家数量将减少个。结合共享专家隔离策略后,完整的DeepSeekMoE架构如下
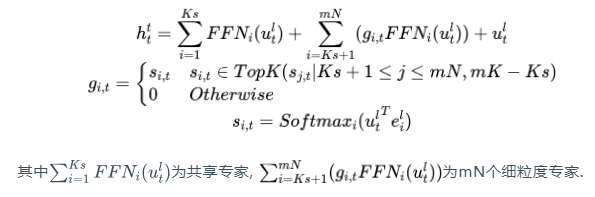
其中为共享专家, 为mN个细粒度专家.
4.3 专家负载均衡
如果完全自动的通过学习构建路由策略可能会遇到负载不均衡的问题, 一方面是存在专家路由崩塌的风险, 即模型总是选择少数几个专家,导致其它专家无法进行充分训练,
另一方面,如果专家分布在多个设备上, 还会导致计算负载不均衡从而进一步影响整个集群训练的MFU. 因此DeepSeek做了两方面的工作
4.3.1 专家级负载均衡损失

4.3.2 设备级负载均衡损失

4.3.3 损失超参数
在损失超参数设计上, 专家负载均衡损失参数设置的较小, 而设备负载均衡损失的超参数设置较大用于更好的平衡设备间的负载.
4.3.4 代码实现
HuggingFace上有一段DeepseekMoE的函数[2], 我们注意到MoEGate函数的实现和论文是有一些差异的,
的Token数目是针对一个batch内的所有token进行负载均衡损失计算的. 然后在16B的模型内并没有执行夸设备的Loss函数.
import torch.nn.init as init
import math
batch_size = 5
tokens = 1024
x = torch.randn(batch_size, tokens, args.dim)
gate_weight = nn.Parameter(torch.rand(args.n_routed_experts, args.dim))
init.kaiming_uniform_(gate_weight, a=math.sqrt(5))
### 以整个batch计算
bsz, seq_len, h = x.shape
hidden_states = x.view(-1, h)
logits = F.linear(hidden_states, gate_weight, None)
scores = logits.softmax(dim=-1)
### 选择TopK并归一化
topk_weight, topk_idx = torch.topk(scores, k=args.n_activated_experts,dim=-1, sorted=False)
denominator = topk_weight.sum(dim=-1, keepdim=True) + 1e-20
topk_weight = topk_weight / denominator
|
计算Expert-Level auxiliary loss可配置成两种情况, 默认对Batch内的每个seq进行计算.
scores_for_aux = scores
aux_topk = args.n_activated_experts
topk_idx_for_aux_loss = topk_idx.view(bsz, -1)
alpha=0.001
if seq_aux: ### 基于Batch内每个seq计算(默认行为)
scores_for_seq_aux = scores_for_aux.view(bsz, seq_len, -1)
ce = torch.zeros(bsz, args.n_routed_experts)
ce.scatter_add_(1, topk_idx_for_aux_loss, torch.ones(bsz, seq_len * aux_topk)).div_(seq_len * aux_topk / args.n_routed_experts)
aux_loss = (ce * scores_for_seq_aux.mean(dim = 1)).sum(dim = 1).mean() * alpha
|
另一个需要注意的点是, DeepSeek此时的代码已经考虑到了, 可以定义前面几层采用MLP-Dense,
这样的做法对于模型的稳定性有很大的好处, 避免过早的Attention进入到MoE带来的一些稳定性问题.
但是在公开的DeepSeek-MoE-16B中这个功能是关闭的, 也就是说每一层都是MoE.
class DeepseekDecoderLayer(nn.Module):
def __init__(self, config: DeepseekConfig, layer_idx: int):
self.self_attn = Deepseek_ATTENTION_CLASSES[config._attn_implementation](config=config, layer_idx=layer_idx)
self.mlp = DeepseekMoE(config) if (config.n_routed_experts is not None and \
layer_idx >= config.first_k_dense_replace and layer_idx % config.moe_layer_freq == 0) \
else DeepseekMLP(config)
|
05
DeepSeek-v2
DeepSeek-V2进一步扩大了细粒度专家选择, 采用了路由专家160选6+2个共享专家的做法.
相对于DeepSeek-V1-MoE新增了两个和通信相关的约束.
注: 渣B对于这个问题是持怀疑态度的, 主要原因还是Mellanox的网络设备的影响导致的, QP-Scale太大以及alltoall带来的incast而产生的通信Cost.这个问题解决了应该就不需要太多的限制了.
当然Deepseek有一些测试发现只要分组设备数量大到一定阈值()后和原来的TopK也没性能上的差异了.
5.1 Device-Limited Routing
第一种是设备受限制的路由, 限制MoE相关的通信成本. 主要是在进行专家并行时, 被路由的专家将分布在多个设备上.
当专家数特别大时, 单个Batch内的Token通信将覆盖大量的设备, 导致EP的通信成本增高. 因此,
在DeepSeek-V2上增加了一个约束, 每个Token最多只能被路由到个设备上. 具体来说,对于每个
token,首先选择包含最高亲和力评分专家的个设备。然后,在这些个设备上的专家中执行 top-K 选择。在实践中,发现当
时,设备受限的路由可以实现与无限制的 top-K 路由大致相当的良好性能。
具体代码实现我们可以看一下HuggingFace上的源码[3], Gating函数的计算和以往没有区别,
还是以整个Batch来算softmax, 但是计算精度上采用了FP32
import torch.nn.init as init
import math
batch_size = 5
tokens = 1024
x = torch.randn(batch_size, tokens, args.dim)
gate_weight = nn.Parameter(torch.rand(args.n_routed_experts, args.dim))
init.kaiming_uniform_(gate_weight, a=math.sqrt(5))
### 以整个batch计算
bsz, seq_len, h = x.shape
hidden_states = x.view(-1, h)
### 计算精度采用了FP32
logits = F.linear(hidden_states.type(torch.float32), gate_weight.type(torch.float32), None)
scores = logits.softmax(dim=-1, dtype=torch.float32)
|
然后在做TopK和归一化选择前, 进行了MoE Group的计算, 总共分成了8个Group,然后topk选择的group为3个.
然后对每个Group求最大的Softmax作为Group的scores, 然后再从这里面选择出来个Group
n_group = 8
topk_group = 3
### 基于每个Token分组组内最大的softmax作为Group scores
group_scores = (
scores.view(bsz * seq_len, n_group, -1).max(dim=-1).values
) # [n, n_group]
### 选择M个Group
group_idx = torch.topk(
group_scores, k=topk_group, dim=-1, sorted=False
)[
1
] # [n, top_k_group]
|
然后构建Groupmask, mask后再选择TopK
group_mask = torch.zeros_like(group_scores) # [n, n_group]
group_mask.scatter_(1, group_idx, 1) # [n, n_group]
score_mask = (
group_mask.unsqueeze(-1)
.expand(
bsz * seq_len, n_group, args.n_routed_experts // n_group
)
.reshape(bsz * seq_len, -1)
) # [n, e]
tmp_scores = scores.masked_fill(~score_mask.bool(), 0.0) # [n, e]
topk_weight, topk_idx = torch.topk(
tmp_scores, k=args.n_activated_experts, dim=-1, sorted=False
)
|
查看scores和tmp_scores的分布可以看到其它Group的softmax被mask为0了,
蓝色为原始softmax, 黄色为经过groupmask的值
plt.plot(scores.detach().to('cpu')[1].numpy())
plt.plot(tmp_scores.detach().to('cpu')[1].numpy())
|
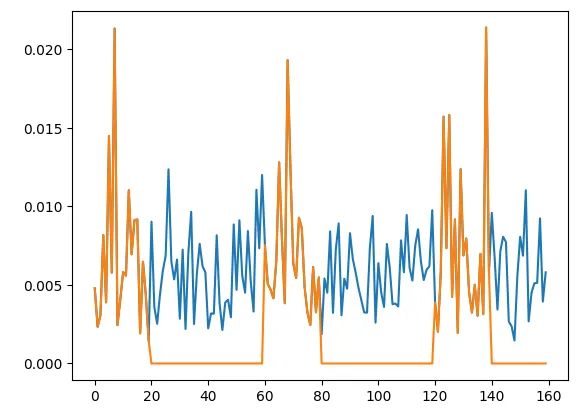
然后在这个基础上再执行topk
topk_weight, topk_idx = torch.topk(
tmp_scores, k=args.n_activated_experts, dim=-1, sorted=False
)
denominator = topk_weight.sum(dim=-1, keepdim=True) + 1e-20
topk_weight = topk_weight / denominator
|
5.2 通信负载均衡损失

5.3 Token丢弃策略
虽然前面新增加了两种负载均衡策略, 但是为了保证训练中的效率避免长尾影响, 会对一个Batch中的Token总数求平均到每个设备上的Token数作为设备容量上限,
当实际容量超出上限时, 对softmax gating scores由高到低排序, 对于超过容量的部分不进行MoE的Expert专家网络计算,
直接送入combine阶段.
其实到这个阶段已经开始越做越复杂了, 看上去为了解决这些通信的问题, 打了很多补丁, 并不是很干净.
而且过大的辅助loss还会影响模型的性能, 因此DeepSeek-V3大刀阔斧的砍向了这堆辅助Loss函数.
06
DeepSeek-V3
DeepSeek-V3继续延续原有的细粒度Experts和Shared Expert的架构, 专家数量进一步提升,
V3的Config文件里显示有三个尺寸的模型
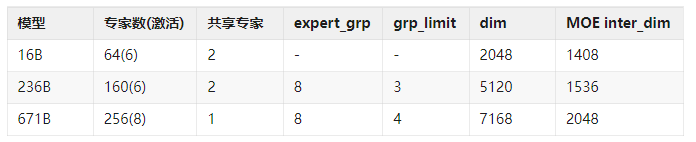
6.1 Gating函数采用Sigmoid
另外从配置文件从看, 在671B模型中, Gating的函数从softmax换成了sigmoid,
并进行了Normalization处理
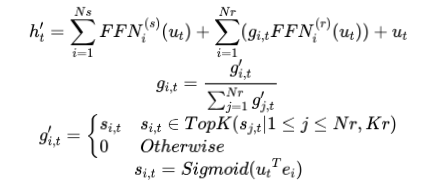
这里个人猜测是在专家数量更大时采用Sigmoid替代Softmax是否为了将专家的scores范围加大,
因为在DeepSeek-V2时已经采用了FP32的精度, 如果更多的专家计算softmax的值会非常小,
导致Gating Scores的区分度和计算误差加大,使得专家选择的误差很大. 因此采用了Sigmoid函数,
同时在Gating上还增加了bias. 参考Github上的代码[4]
class Gate(nn.Module):
def __init__(self, args: ModelArgs):
...
self.weight = nn.Parameter(torch.empty(args.n_routed_experts, args.dim))
### dim 7168是671B的模型, 增加了Bias项
self.bias = nn.Parameter(torch.empty(args.n_routed_experts)) if self.dim == 7168 else None
|
计算score如下
args = ModelArgs()
args.n_routed_experts = 256
args.n_activated_experts = 8
args.n_expert_groups = 8
args.n_limited_groups = 4
args.route_scale = 2.5
args.dim = 6178
batch_size = 7
tokens = 1024
x = torch.randn(batch_size, tokens, args.dim)
### 在Class MoE中将一个Batch的输入全部展平了
x = x.view(-1, args.dim)
gate_weight = nn.Parameter(torch.rand(args.n_routed_experts, args.dim))
gate_bias = nn.Parameter(torch.rand(args.n_routed_experts))
init.kaiming_uniform_(gate_weight, a=math.sqrt(5))
|
如果采用softmax的值域会相对较小
softmax_score = scores.softmax(dim=-1, dtype=torch.float32)
plt.plot(softmax_score.detach().to('cpu')[0][0].numpy())
|
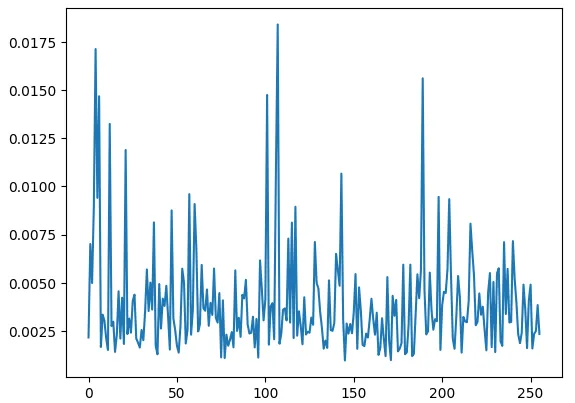
而DeepSeek-V3采用sigmoid如下, 值域在[0,1]
scores = scores.sigmoid()
plt.plot(scores.detach().to('cpu')[0].numpy())
|
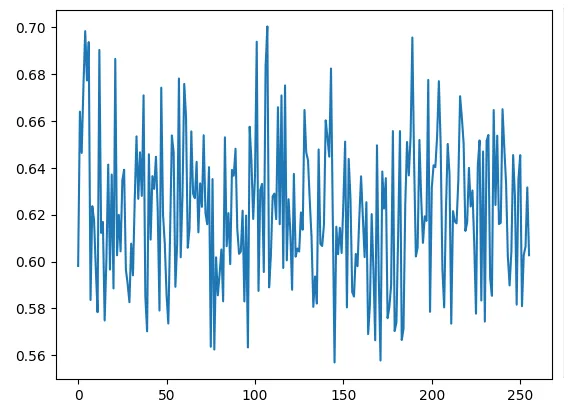
6.2 专家分组
在DeepSeek-V3采用了专家分组, 但是和Device-Limited Routing不同,主要是用于NVLINK和IB的带宽3.2x配比上,Group
Score的计算如下所示
### 保留了一份score用于Weight计算的不带Bias
original_scores = scores
### 在671B模型中还添加了Bias, 这个和负载均衡相关,详细后续章节介绍.
scores = scores + gate_bias
scores = scores.view(x.size(0), args.n_expert_groups, -1)
group_scores = scores.topk(2, dim=-1)[0].sum(dim=-1)
indices = group_scores.topk(args.n_limited_groups, dim=-1)[1]
mask = torch.zeros_like(scores[..., 0]).scatter_(1, indices, True)
scores = (scores * mask.unsqueeze(-1)).flatten(1)
indices = torch.topk(scores, args.n_activated_experts, dim=-1)[1]
### 权重计算采用原始score, bias仅用于路由选择.
weights = original_scores.gather(1, indices)
plt.plot(original_scores.detach().to('cpu')[0].numpy())
plt.plot(scores.detach().to('cpu')[0].numpy())
|
可以看到通过Group限制,将专家约束在了4个Group上.
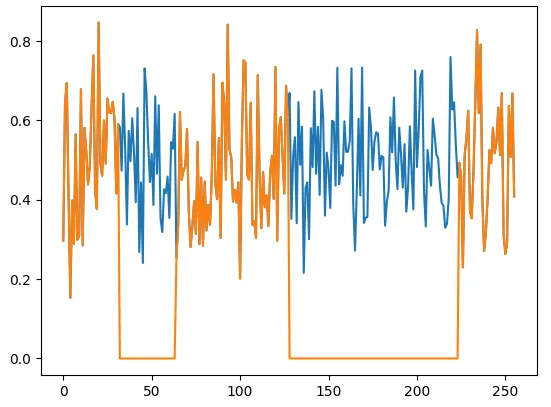
最后对weight归一化处理并增加了一个route-scale=2.5放大系数
weights /= weights.sum(dim=-1, keepdim=True)
weights *= self.route_scale
|
6.3 无需辅助损失函数的负载均衡
DeepSeek-V3最大的变化就是干掉了辅助损失函数, 虽然AuxLoss出现是为了负载均衡, 但是过大的AuxLoss还会进一步损害模型的性能,
为了在负载均衡和模型性能之间实现更好的权衡,DeepSeek采用了一种非常巧妙的无辅助损失的负载均衡策略,
即在Gating score中为每个专家增加了一个Bias项.
需要注意的是, Bias仅用于路由计算, 最终的weight还是采用原始的sigmoid(代码中的Original_score).
同时在训练过程中会持续监控每个batch的负载均衡情况, 在每一个step结束时, 如果某个专家负载过高,会将其对应的偏置项减少r;如果某个专家负载不足,则会将其对应的偏置项增加r,其中r
是一个称为偏置更新速度的超参数。通过这种动态调整,DeepSeek-V3 在训练过程中保持了均衡的专家负载,并且相比仅通过纯辅助损失来促进负载均衡的模型,取得了更好的性能。
另一方面为了防止单个序列内出现极端的不平衡, 还引入了一种seq粒度的辅助损失补偿.
6.4 无需Device-Limit Routing和Token-Drop
由于无需辅助损失函数的负载均衡已经做的不错了, 就没有使用DeepSeek-V2中的Token-Drop.
对于Device-Limit Routing应该是DualPipe和其它一些overlap策略就可以解决了.

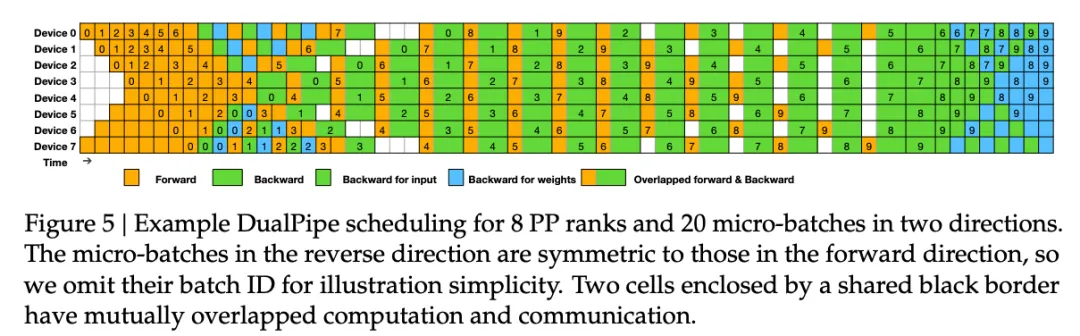
因此原先基于DeepSeek-V2的Device-Limit Routing的Group概念来看待DeepSeek-V3的Group概念时不对的.
6.5 AlltoAll Infra的改动
为了保证DualPipe的足够高的计算性能, DeepSeek构造了一个高性能的跨节点的all-to-all通信Kernel(包含了Dispatch和Combine)来减少专门用于通信的SM数量.
它和MoE Gating算法以及集群的网络拓扑结构协同设计. 跨机网络上DeepSeek采用的400Gbps
IB互联, 节点内H800的NVLINK带宽为160GB/s(单向, 虽然理论值标称为200GB/s但是实际集合通信NCCL大概就能跑到双向334GB/s差不多160GB/s单向).
因此NVLINK : IB的带宽比值大概是3.2x
专家创建如下
world_size = N
rank = M
class MoE(nn.Module):
self.n_routed_experts = args.n_routed_experts
self.n_local_experts = args.n_routed_experts // world_size
self.n_activated_experts = args.n_activated_experts
### 计算本地所要创建的Expert
self.experts_start_idx = rank * self.n_local_experts
self.experts_end_idx = self.experts_start_idx + self.n_local_experts
self.gate = Gate(args)
### 本地专家只创建根据worldsize和Rank计算出来的一个区间
self.experts = nn.ModuleList([Expert(args.dim, args.moe_inter_dim) if self.experts_start_idx <= i < self.experts_end_idx else None
for i in range(self.n_routed_experts)])
### Shared Expert
self.shared_experts = MLP(args.dim, args.n_shared_experts * args.moe_inter_dim)
|
然后在foward阶段根据Gating函数计算出的indices进行dispatch, 但是github给出的代码并没有dispatch相关的内容
def forward(self, x: torch.Tensor) -> torch.Tensor:
shape = x.size()
x = x.view(-1, self.dim)
weights, indices = self.gate(x)
y = torch.zeros_like(x)
counts = torch.bincount(indices.flatten(), minlength=self.n_routed_experts).tolist()
### 这里仅计算了Local Expert, 应该是推理阶段的代码, 训练dispatch没有实现.
for i in range(self.experts_start_idx, self.experts_end_idx):
if counts[i] == 0:
continue
expert = self.experts[i]
idx, top = torch.where(indices == i)
y[idx] += expert(x[idx]) * weights[idx, top, None]
z = self.shared_experts(x)
### 结果是会combine做allreduce的
if world_size > 1:
dist.all_reduce(y)
return (y + z).view(shape)
|
但是论文里写了, 为了有效利用 IB 和 NVLink 的不同带宽,将每个 token 的分发限制在最多
4 个节点,从而减少 IB 流量。对于每个 token,在其路由决策确定后,它会首先通过 IB 被传输到目标节点中具有相同节点内索引的
GPU 上。一旦到达目标节点,会努力确保它能够立即通过 NVLink 转发到托管目标专家的具体 GPU
上,而不会被后续到达的 token 阻塞。通过这种方式,IB 和 NVLink 的通信完全重叠,每个
token 可以高效地选择每个节点平均 3.2 个专家,而不会因 NVLink 带来额外开销。
虽然当前选择的是8个专家, 但是在保持相同通信成本的情况下,它可以将这一数量扩展到最多 13 个专家(4
节点 × 3.2 专家/节点). 但是这种策略还是需要花费20个SM用于进行通信.
在通信Kernel实现中, 还采用了Hopper的Warpspecialization的能力, 将20
个 SM 划分为 10 个Channel, dispatch过程中 IB Send, IB to NVLINK和NVLINK接收分别由不同的warp处理,
然后分配给每个通信任务的warp数量还会根据SM的工作负载动态调节. 同样在combine过程中转发和reduce累加也合并在算子中,
并且也能动态的进行工作负载调节.
另一方面是通信Kernel和计算Kernel的overlap, 这里采用了一些PTX指令和自动调整chunksize的方式,
降低L2Cache的占用和对其它SM的影响.
6.6 推理阶段MOE处理
在推理阶段, MoE的通信也值得关注, 最小部署集为40台H800构成的320 GPU, 每个GPU只负责一个Expert,
累计需要256个GPU, 然后剩下64个GPU作为Redundant experts和shared
expert. 此时AlltoAll的通信采用直接经过IB传输的方式进行, 并采用了IBGDA来降低延迟和提升通信效率.
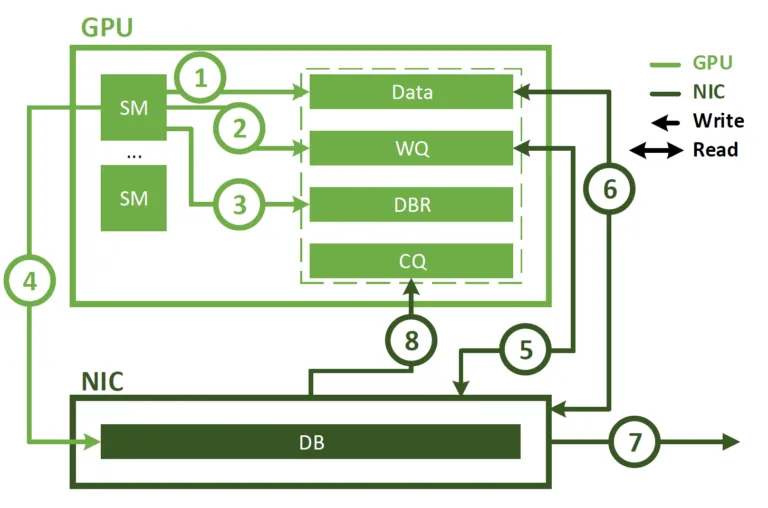
6.7 对Infra的改进建议
其实有几个问题DeepSeek和渣B的看法是一致的, 一方面是NVLINK和RDMA语义的割裂,导致通信上的复杂度很高.
然后H800的132个SM有20个SM用于通信开销太大, 希望能够Offload, 然后Offload的时候希望能够在combine阶段把reduce也一起做了.

在网卡上提供Memory Interface支持LD/ST语义
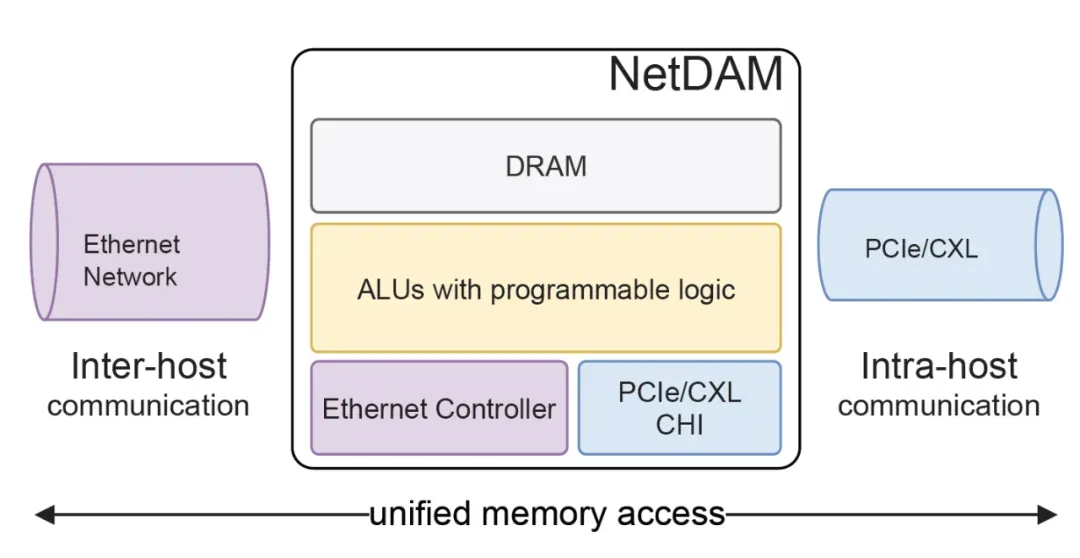
这样就时一个统一的网络了, 并不需要刻意去区分ScaleUP和ScaleOut
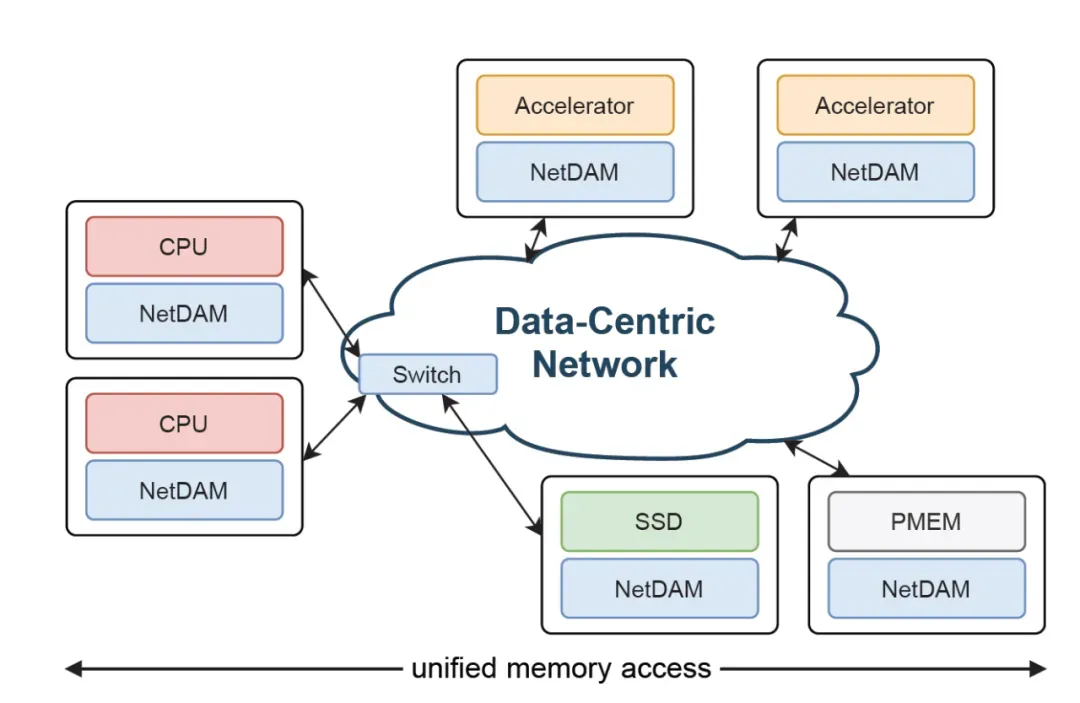
然后支持reduce在网计算的功能当年也做好了
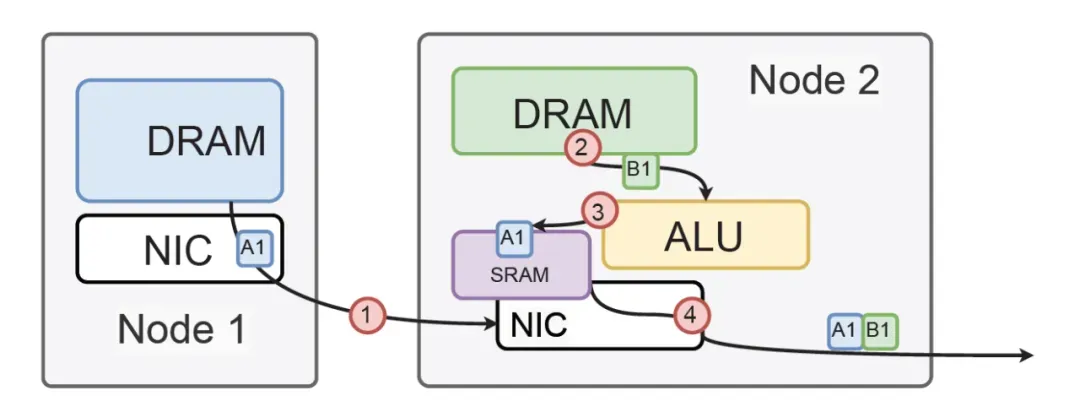
吐个槽, 我真的不是很明白一群人去搞UEC/UAL还有各种国内的ScaleUP标准干嘛... 然后针对MoE的dispatch阶段,
对Fabric的拥塞控制的问题最近两三年也全部解决干净了, 等过段时间专利出来吧,大家就懂了. 然后网络和MoE
Gating的协同设计也有了一些想法以及去年前年也申请了几个专利~~
07
关于MoE演进
继续推导下一代模型, 例如hidden-state带来的dim进一步扩大, 然后专家数进一步扩大,
例如构建n_routed_experts=2048/4096, 然后activated_experts
= 16/32/64会如何? 如何分组, 如何限制通信域? 进一步拷问, 如果这个时候用一些国产卡替代Experts的运算又该如何?
当然我们要考虑国产卡的显存带宽和容量的影响以及自身浮点算力的影响, 我们来假设一个稍微极致一点的情况,
假设我们构建一个集群, 用少量的H800配合一大堆国产卡做训练?
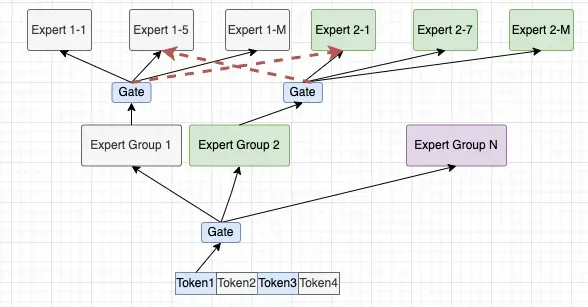
此时Gating函数的一些设计上就很有趣了, 当然可以延续Expert Group的分组, 在Gating函数输出<grp_id,
expert_id> , 同样去部分的构造locality. 也就是前段时间提到的一个做法《一个关于MoE的猜想》
进一步这些国产卡的算力相对较低时, 针对MLP的大矩阵乘法还是有点吃力的, 那么应该如何优化? 同时伴随着多模态和Reasoning模型Context越来越长,
如何在这种模式下能够更好的隐藏通信延迟? 那么是否可以对Hidden-state dim拆分, 构造成多个小的MLP然后做完了再concat?
然后查阅了一下资料, 微软韦福如老师他们做MultiHead MoE[5]已经蛮久了.
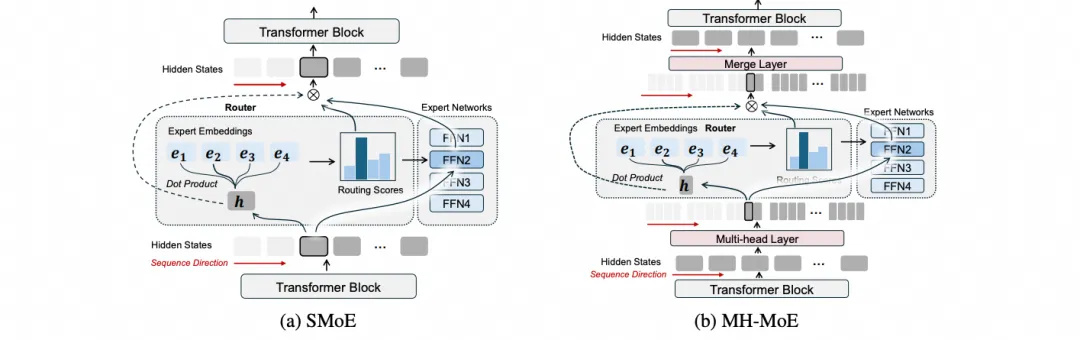
特别来说MH-MoE对于多模态的场景下, 或许还有更多意想不到的优势, 例如MH-MOE另一篇论文[6]中的例子
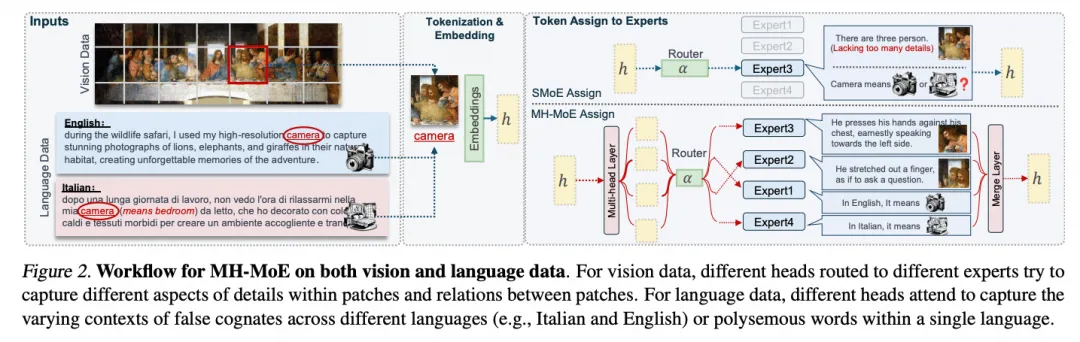
结论: 当我们把一些通信的效率问题解决了(当然解决这些问题压根不需要什么ScaleUP网络, 只要抑制好长尾和Overlap好通信延迟,
事实上已经解决了XD). 结合原来假设的MoEG做两级Gating的想法, 整个Token做一个Gating,
然后dispatch到一个Group, 然后再Group内再做一次MultiHead MoE的Gating,
data locality/Hierarchy都有了保障. | |








