| 编辑推荐: |
本文将深度对比CNN与Transformer的优劣,探讨混合架构的可能性,并预测未来视觉底层架构的发展方向,带你一探究竟,谁将主宰下一代视觉模型的未来?希望对你的学习有帮助。
本文来自于微信公众号智驻未来,由火龙果软件Linda编辑,推荐。 |
|
导读
在计算机视觉领域,CNN与Transformer的对决已持续十年之久。CNN凭借其强大的归纳偏置和局部特征提取能力,奠定了视觉任务的基础;而Transformer以其全局建模和自注意力机制,迅速崛起并冲击传统格局。如今,两者之间的博弈已进入白热化阶段,混合架构的出现更是让这场竞争充满了变数。本文将深度对比CNN与Transformer的优劣,探讨混合架构的可能性,并预测未来视觉底层架构的发展方向,带你一探究竟,谁将主宰下一代视觉模型的未来?
1. CNN与Transformer的技术原理
1.1 CNN的归纳偏置与局部特征提取
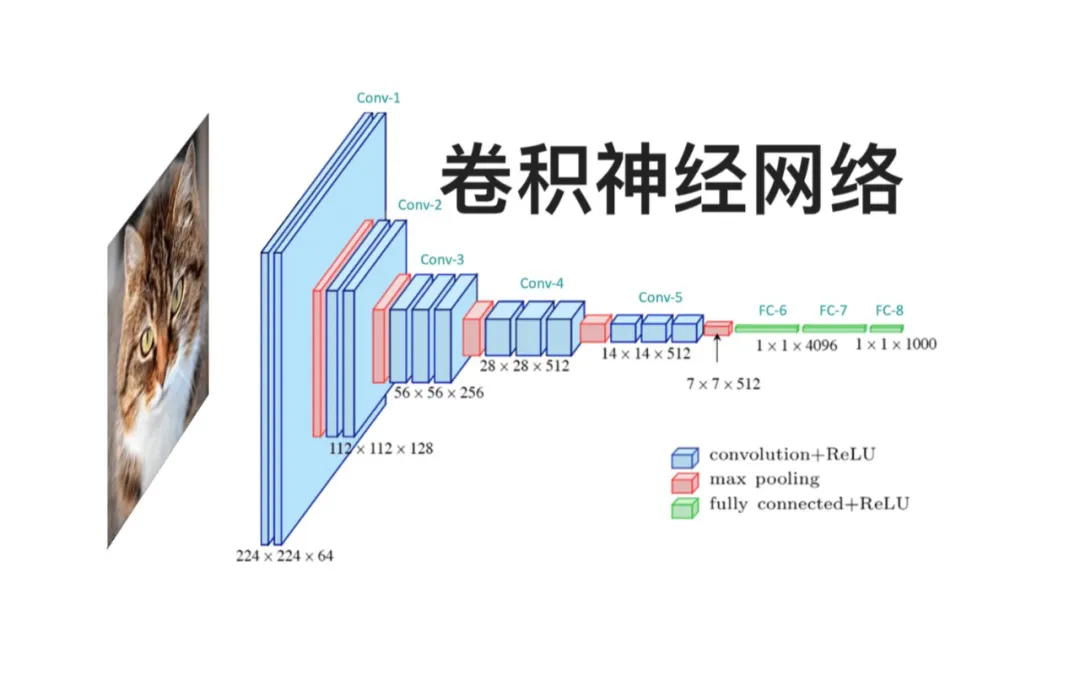
卷积神经网络(CNN)的核心优势在于其归纳偏置和局部特征提取能力,这些特性使其在计算机视觉领域取得了巨大成功。
归纳偏置:CNN通过卷积层和池化层的设计,引入了局部感知野和权值共享的归纳偏置。局部感知野意味着每个神经元只对输入图像的一个局部区域敏感,这种局部性使得CNN能够捕捉图像中的局部特征,如边缘、纹理和形状等。例如,在图像分类任务中,CNN能够通过局部特征的组合来识别物体的整体特征。权值共享则进一步减少了模型的参数数量,提高了模型的泛化能力和计算效率。以LeNet为例,它通过共享卷积核的权重,在手写数字识别任务中取得了优异的性能,同时减少了模型的参数量,使其更容易训练和优化。
局部特征提取:CNN的卷积层通过卷积核在输入图像上滑动,提取局部特征。卷积核的大小和数量决定了模型对局部特征的感知能力和表达能力。例如,较小的卷积核可以捕捉更精细的局部特征,而较大的卷积核则可以捕捉更全局的特征。通过多层卷积层的堆叠,CNN能够逐步提取更高级别的特征,从而实现对图像的深度理解。例如,在VGG网络中,通过使用多个小卷积核的卷积层,模型能够逐步提取从低级到高级的特征,最终实现对图像的准确分类。
1.2 Transformer的全局建模与自注意力机制
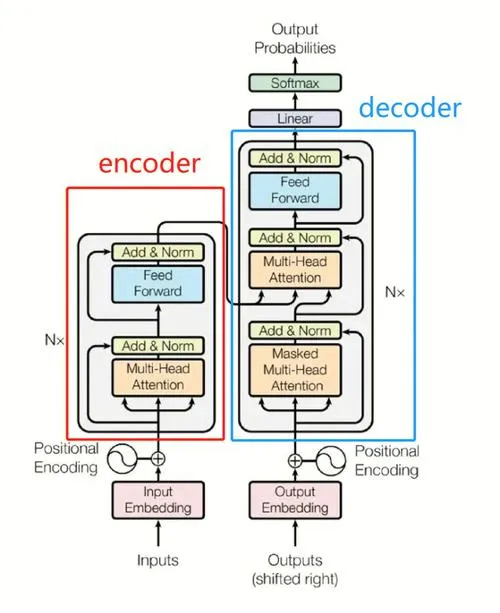
Transformer的核心优势在于其全局建模能力和自注意力机制,这些特性使其在处理长距离依赖和全局信息时表现出色。
全局建模:Transformer通过自注意力机制,能够同时考虑输入序列中的所有位置信息,从而实现全局建模。与CNN的局部感知野不同,Transformer的自注意力机制允许模型在计算每个位置的表示时,动态地关注输入序列中的所有其他位置。这种全局建模能力使得Transformer在处理长距离依赖和全局信息时具有显著优势。例如,在机器翻译任务中,Transformer能够同时考虑源语言句子中的所有单词,从而更好地理解句子的语义结构,生成更准确的翻译结果。
自注意力机制:Transformer的自注意力机制通过计算输入序列中每个位置与其他位置的相关性得分,动态地调整每个位置的表示。具体来说,自注意力机制包括三个关键矩阵:查询(Query)、键(Key)和值(Value)。通过计算查询和键之间的点积,得到相关性得分,然后通过Softmax函数将其归一化为注意力权重,最后将注意力权重与值相乘,得到每个位置的加权表示。这种机制使得模型能够自适应地关注输入序列中更重要的部分,从而提高模型的表达能力和泛化能力。例如,在Vision
Transformer(ViT)中,通过将图像划分为固定大小的图像块,并将这些图像块作为输入序列输入到Transformer中,模型能够利用自注意力机制捕捉图像块之间的全局关系,从而实现对图像的全局建模。
2. CNN与Transformer的性能对比
2.1 计算效率与资源消耗
CNN和Transformer在计算效率与资源消耗方面存在显著差异,这些差异直接影响了它们在实际应用中的适用性。
计算效率:
CNN:CNN的卷积操作具有较高的计算效率。由于其局部感知野和权值共享的特性,CNN在处理图像数据时能够有效地利用硬件加速,尤其是在GPU上。例如,ResNet等现代CNN架构通过优化卷积层的设计,能够在较短的时间内完成训练和推理。根据实验数据,ResNet-50在单个GPU上的训练时间约为1小时,而推理速度可以达到每秒数百张图像。
Transformer:Transformer的自注意力机制虽然能够捕捉全局信息,但计算复杂度较高。其时间复杂度为(\mathcal{O}(n^2d)),其中(n)是序列长度,(d)是特征维度。这使得Transformer在处理大规模数据时需要更多的计算资源。例如,Vision
Transformer(ViT)在处理高分辨率图像时,计算量会显著增加,导致训练和推理速度较慢。根据实验数据,ViT在单个GPU上的训练时间可能超过数小时,推理速度也相对较慢。
资源消耗:
CNN:CNN的资源消耗相对较低,尤其是在模型参数数量和内存占用方面。例如,VGG网络虽然参数较多,但通过优化和量化技术,可以在移动设备上高效运行。
Transformer:Transformer由于其自注意力机制的复杂性,需要更多的内存和存储资源。例如,Swin
Transformer通过引入层次化架构和移动窗口机制,虽然在一定程度上降低了计算复杂度,但仍然需要较大的内存来存储中间计算结果。
2.2 模型精度与泛化能力
CNN和Transformer在模型精度与泛化能力方面各有优势,这些优势取决于具体的应用场景和任务需求。
模型精度:
CNN:CNN在图像分类、目标检测和语义分割等任务中表现出色。例如,在ImageNet竞赛中,CNN架构如ResNet和VGG网络取得了优异的成绩,证明了其在图像识别任务中的高精度。在目标检测任务中,RCNN系列和YOLO系列模型基于CNN实现了高精度的检测。
Transformer:Transformer在处理长距离依赖和全局信息时具有显著优势。例如,Vision
Transformer(ViT)在大规模数据集(如ImageNet-21k)上预训练后,在图像分类任务中达到了与CNN媲美甚至更优的性能。在语义分割任务中,Swin
Transformer通过结合CNN的局部感受野优势,显著提升了分割精度。
泛化能力:
CNN:CNN的归纳偏置使其在处理局部特征时具有较强的泛化能力。例如,ResNet通过引入残差学习,解决了深层网络训练中的梯度消失问题,提高了模型的泛化能力。
Transformer:Transformer的自注意力机制能够捕捉全局信息,使其在处理复杂数据时具有更强的泛化能力。例如,Swin
Transformer通过层次化架构和移动窗口机制,不仅提高了计算效率,还增强了模型的泛化能力。
2.3 数据需求与训练难度
CNN和Transformer在数据需求与训练难度方面也存在显著差异,这些差异影响了它们在实际应用中的选择。
数据需求:
CNN:CNN通常需要大量的标注数据来训练。例如,在ImageNet竞赛中,CNN模型需要使用大规模的标注图像数据集进行训练,以达到较高的精度。然而,CNN在小数据集上也能够通过数据增强和迁移学习等技术取得较好的效果。
Transformer:Transformer由于其强大的建模能力,通常需要更大规模的数据集来训练。例如,Vision
Transformer(ViT)需要在大规模数据集(如ImageNet-21k或更大的JFT-300M)上进行预训练,才能达到较好的性能。然而,Transformer在小数据集上可能会出现过拟合的问题。
训练难度:
CNN:CNN的训练相对较为简单,尤其是在硬件加速和优化算法的支持下。例如,ResNet和VGG网络通过使用ReLU激活函数和批量归一化(BatchNorm)技术,能够有效地加速训练过程。
Transformer:Transformer的训练难度较高,尤其是在处理大规模数据时。例如,Transformer的自注意力机制需要大量的计算资源和内存,导致训练过程较慢。此外,Transformer的训练过程中容易出现梯度爆炸或梯度消失的问题,需要通过特殊的优化技术(如LayerNorm)来解决。
3. Hybrid架构的可能性与优势
3.1 结合CNN与Transformer的混合架构设计
Hybrid架构通过结合CNN和Transformer的优势,旨在克服单一架构的局限性,实现更高效、更强大的视觉模型。这种混合架构的设计思路主要包括以下几种形式:
3.1.1 CNN作为特征提取器,Transformer进行全局建模
一种常见的混合架构是将CNN作为特征提取器,提取图像的局部特征,然后将这些特征输入到Transformer中进行全局建模。例如,DETR(Detection
Transformer)模型就是这种架构的典型代表。在DETR中,CNN(如ResNet)被用来提取图像的特征图,然后这些特征图被展平并输入到Transformer解码器中,用于目标检测和分割任务。这种架构充分利用了CNN在局部特征提取方面的优势,同时借助Transformer的全局建模能力,能够更好地处理目标之间的关系和上下文信息。
3.1.2 Transformer作为特征提取器,CNN进行局部细化
另一种混合架构是将Transformer作为特征提取器,提取图像的全局特征,然后通过CNN进行局部细化。这种架构可以利用Transformer的全局建模能力,同时借助CNN的局部感知能力,进一步提高特征的质量。例如,一些研究将Vision
Transformer(ViT)提取的全局特征输入到卷积层中,通过卷积操作提取更精细的局部特征。这种架构在处理需要同时考虑全局和局部信息的任务时表现出色,例如语义分割和目标检测。
3.1.3 层次化混合架构
层次化混合架构将CNN和Transformer的特性结合在一起,形成一个多层次的特征提取和建模框架。例如,Swin
Transformer通过引入层次化的架构,将自注意力限制在局部滑动窗口内计算,并通过移动窗口机制实现跨区域的信息交流。这种架构不仅结合了CNN的局部感受野优势,还保留了Transformer的全局建模能力,显著提升了模型的计算效率和在多种视觉任务上的性能。
4. 未来视觉模型的发展趋势
4.1 视觉模型的底层架构发展方向
未来视觉模型的底层架构将朝着更加高效、灵活和综合的方向发展,以满足不断增长的视觉任务需求和计算资源限制。
4.1.1 混合架构的进一步融合与优化
混合架构(Hybrid Architecture)结合了CNN的局部特征提取能力和Transformer的全局建模能力,已经成为视觉模型的重要发展方向。未来,混合架构将更加注重以下方面的优化:
层次化特征提取:通过设计更复杂的层次化结构,模型可以同时提取局部和全局特征,并在不同层次之间进行有效的信息交互。例如,Swin
Transformer的层次化架构通过局部滑动窗口内的自注意力机制和移动窗口机制,实现了局部和全局信息的有效结合。未来,这种层次化设计可能会进一步深化,以更好地处理复杂视觉任务。
动态特征选择:未来的混合架构可能会引入动态机制,根据输入图像的内容和任务需求,自适应地选择使用CNN或Transformer进行特征提取。这种动态选择机制可以提高模型的灵活性和效率,减少不必要的计算。
轻量化设计:为了在移动设备和边缘计算场景中应用,混合架构将更加注重轻量化设计。通过减少模型参数数量、优化计算流程和采用高效的量化技术,混合架构可以在保持性能的同时,降低计算资源消耗。
4.1.2 Transformer架构的持续创新
Transformer架构在视觉领域的应用将继续深化,未来可能会出现以下创新方向:
多模态融合:Transformer架构将不仅仅局限于处理单一模态的视觉数据,而是会与语言、声音等其他模态数据进行深度融合。例如,CLIP模型通过将图像和文本特征进行对比学习,实现了图像与文本的跨模态检索。未来,Transformer架构可能会进一步扩展到多模态任务中,如视觉问答(VQA)、图像字幕生成等。
稀疏注意力机制:为了提高Transformer的计算效率,稀疏注意力机制将成为研究热点。稀疏注意力机制通过限制注意力的计算范围,减少计算复杂度,同时保留关键信息。例如,一些研究提出了稀疏Transformer架构,通过稀疏连接的方式,显著降低了计算资源消耗。
自适应建模能力:未来的Transformer架构将更加注重自适应建模能力,能够根据输入数据的特性动态调整模型的结构和参数。这种自适应能力可以提高模型的泛化能力和鲁棒性,使其在不同场景下都能表现出色。
4.1.3 CNN架构的现代化改进
尽管Transformer在视觉领域取得了显著进展,但CNN架构仍然具有不可替代的优势。未来,CNN架构将通过以下方式进行现代化改进:
更深的网络结构:通过引入残差学习、注意力机制等技术,CNN架构将能够构建更深的网络,从而提取更高级别的特征。例如,ResNet通过残差连接解决了深层网络训练中的梯度消失问题。未来,CNN可能会进一步探索更深的网络结构,以提高模型性能。
更高效的卷积操作:为了提高计算效率,CNN架构将探索更高效的卷积操作,如深度可分离卷积(Depthwise
Separable Convolution)和动态卷积(Dynamic Convolution)。这些卷积操作可以在减少计算量的同时,保持或提高模型性能。
与Transformer的深度结合:CNN架构将更加积极地与Transformer架构结合,通过引入Transformer的自注意力机制,增强CNN的全局建模能力。例如,ConvNeXt通过借鉴Transformer的设计理念,如更深的网络、LayerNorm替代BatchNorm、大卷积核等,证明了纯CNN通过现代设计也能媲美Transformer性能。
4.2 新技术对视觉模型的影响
新技术的不断涌现将对视觉模型的发展产生深远影响,以下是一些关键新技术及其潜在影响:
4.2.1 量子计算与视觉模型
量子计算的发展为视觉模型的训练和推理提供了新的可能性。量子计算具有并行计算的优势,能够在短时间内处理大量数据,从而显著提高模型的训练速度和推理效率。例如,量子卷积神经网络(QCNN)和量子Transformer(QTransformer)的研究已经在理论上取得了一些进展,未来可能会在实际应用中展现出巨大的潜力。
4.2.2 生成式对抗网络(GAN)与视觉模型
生成式对抗网络(GAN)在图像生成、超分辨率重建和数据增强等任务中表现出色。未来,GAN与视觉模型的结合将更加紧密,通过生成高质量的训练数据和增强模型的生成能力,进一步提升视觉模型的性能。例如,一些研究将GAN生成的图像用于数据增强,显著提高了模型在小数据集上的性能。
4.2.3 自监督学习与视觉模型
自监督学习通过利用无标注数据进行预训练,能够显著减少对标注数据的依赖,提高模型的泛化能力。未来,自监督学习将成为视觉模型的重要发展方向,通过设计更有效的预训练任务和对比学习机制,进一步提升模型的性能。例如,DINO(self-distillation
with no labels)通过无标签的自蒸馏方法,训练学生模型从局部视角推断全局上下文信息。
4.2.4 知识蒸馏与视觉模型
知识蒸馏通过将大模型的知识迁移到小模型中,能够显著提高小模型的性能,同时减少计算资源消耗。未来,知识蒸馏将在视觉模型中得到广泛应用,通过设计更有效的蒸馏策略和适配器,进一步提升模型的效率和性能。
4.2.5 边缘计算与视觉模型
随着边缘计算技术的发展,视觉模型将越来越多地部署在边缘设备上,如智能手机、无人机和物联网设备。为了满足边缘计算的低功耗、低延迟要求,视觉模型将更加注重轻量化设计和高效推理。例如,MobileNet等轻量化CNN架构已经在边缘设备上取得了广泛应用。未来,Transformer架构也将通过量化和优化技术,逐步应用于边缘计算场景。
综上所述,CNN与Transformer的十年缠斗并非简单的竞争,而是相互促进、相互融合的过程。未来,混合架构将成为视觉模型的重要发展方向,新技术的融合将进一步推动视觉模型的性能提升和应用拓展。在这一过程中,研究者们需要不断探索和创新,以应对日益复杂的视觉任务需求,推动计算机视觉领域的发展迈向新的高度。 | 





 订阅
订阅