| 编辑推荐: |
本文主要介绍了当DeepSeek遇上Hadoop时的技术原理与项目实践相关内容。希望对你的学习有帮助。
本文来自于微信公众号数据仓库与Python大数据,由火龙果软件Linda编辑,推荐。 |
|
当DeepSeek遇上Hadoop......
DeepSeek与Hadoop的结合,是一场技术革新的盛宴。DeepSeek,作为一种高效的大模型工具,以其卓越的算法和推理模型分析能力在数据科学领域占据一席之地。而Hadoop,作为大数据处理的基石,以其分布式存储和计算能力处理海量数据集。通过将DeepSeek的深度学习模型部署在Hadoop集群上,我们可以对大规模数据进行实时分析和预测。这使得企业能够快速响应市场变化,做出更加精准的决策。无论是商业智能还是科学研究,DeepSeek与Hadoop的结合都为数据分析带来了新的可能性。
解析Yarn基本架构
资源调度器Yarn,主要由Resource Manager(RM)、Node Manager(NM)、Application
Master(AM)和Container四个部分组成。如图:Yarn组成架构图
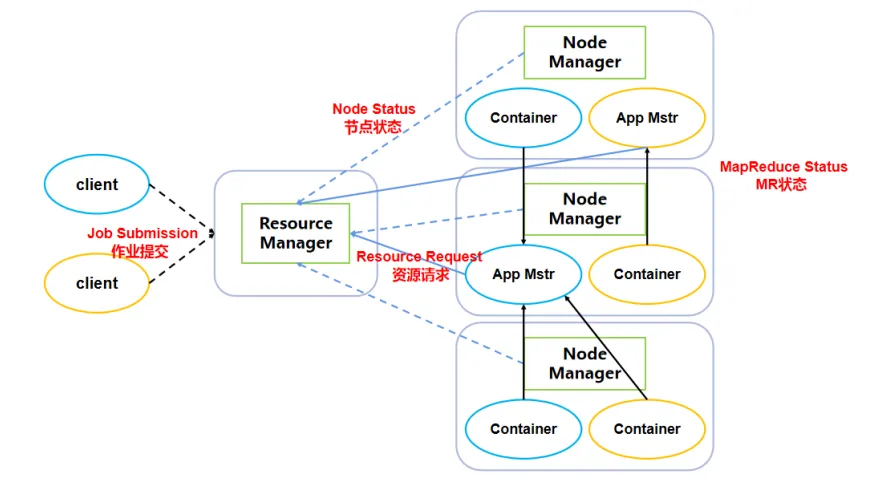
其中,Resource Manager 是整个Hadoop集群中资源的最高管理者。客户端将MapReduce任务提交给Resource
Manager,Resource Manager不断地处理客户端提交的请求。同时,Resource
Manager还在时刻着监控Hadoop集群所有Node Manager节点的状态。
客户端将MapReduce任务提交给Resource Manager后,首先进行资源的分配和调度,然后Resource
Manager会启动Application Master运行这些MapReduce任务。Application
Master上运行在MapReduce任务,并且每隔一段时间向Resource Manager发送MapReduce任务运行的状态信息。Resource
Manager就负责收集并监控Application Master的状态。
其中,Resource Manager的主要作用如下:
(1)处理客户端请求
(2)监控Node Manager
(3)启动或监控Application Master
(4)资源的分配和调度
其中,Node Manager是单个节点上资源的最高管理者。但是Node Manager在分配和管理资源之前,首先要向Resource
Manager申请资源,同时还要每隔一段时间向Resource Manager上报资源使用情况。当Node
Manager收到来自Application Master的资源申请时,就会向Application
Master分配和调度所需资源。
概括地说,Node Manager的主要作用如下:
(1)管理所在节点上的资源
(2)处理来自Resource Manager的命令
(3)处理来自Application Master的命令
其中,Application Master主要负责为每一个任务进行资源的申请、调度和分配。向ResourceManager申请资源,与NodeManager进行交互,监控并汇报任务的运行状态、申请的资源的使用情况和作业的进度等信息。同时,跟踪任务状态和进度,定时向Resource
Manager发送心跳消息,上报资源的使用情况和应用的进度信息。此外,Application Master还负责本作业内的任务的容错。
概括地说,Application Master的主要作用如下:
(1)负责数据的切分
(2)为应用程序申请资源并分配给其包含的任务
(3)任务的监控与容错
Container是Yarn中资源的抽象,它封装了某个Node Manager节点上多维度资源,例如CPU、内存、磁盘、网络等。
剖析Yarn工作机制
在上一小节,我们介绍了Yarn的组成架构,以及每个组成部分的功能。在本小节,我们将详细地介绍Yarn的工作机制,以及每个组成部分具体的作用和功能。如图:Yarn工作机制

对于一个MapReduce程序,用户首先将该程序的jar提交到客户端所在的节点。由于是Yarn的上游发起的行为,不属于Yarn,因此我们在图中使用了标号0来标记此次行为。以下的所有步骤均是Yarn的工作机制。
1.申请Application
Resource Manager的主要作用之一就是负责处理客户端发来的请求。当用户首先将一个MapReduce程序的jar提交到客户端所在的节点后,位于该节点上的YarnRunner会向整个Hadoop集群中资源的最高管理者Resource
Manager发送一次请求,申请一个Application。在这里,我们将一个MapReduce程序看作一个job。
2.分配资源提交路径
当Resource Manager接收到客户端发送来的Application申请后,Resource
Manager会为客户端分配一个Application资源提交的路径,以及Application编号application_id。该资源提交路径实质为HDFS分布式文件系统的目录,也就是说Yarn会利用HDFS为job程序的运行提供存储资源。
3.提交运行资源
当Resource Manager会为客户端分配一个Application资源提交的路径后,客户端会向该路径提交job运行所需要的所有资源,例如job.split、job.xml和MapReduce程序的jar包。job.split表示切片的规划,job.xml表示job运行时的配置文件。
4.申请运行MRAppmaster
当客户端会向Application资源提交路径提交job运行所需要的所有资源后,客户端会再次向Resource
Manager发送一次申请,申请运行MRAppmaster。
5.初始化Task
当Resource Manager接收到客户端发送来的运行MRAppmaster申请后,Resource
Manager会将该申请初始化为一个Task,并将该Task放入FIFO调度队列中,等待任务调度。
6.领取Task任务
当Task放入FIFO调度队列后,等待任务调度。Resource Manager除了能够处理来自客户端的请求外,还能够监控Node
Manager的资源使用情况和状态。当Resource Manager监控到某个Node Manager正处于空闲状态并资源充足,Resource
Manager会从FIFO调度队列的头部拉取Task任务,然后分配给Node Manager。此时,单个节点上资源的最高管理者Node
Manager就会从FIFO调度队列的头部领取Task任务,然后处理该Task任务。
7.创建容器Container
当Node Manager就会从FIFO调度队列的头部领取Task任务后,Node Manager会将运行该Task任务所需的cpu、ram等资源和MRAppmaster封装到一个Container中。
8.下载job资源到本地
Container中的MRAppmaster实质上就是Application Master。Application
Master主要负责为每一个job任务进行资源的申请、调度和分配。当Application Master去运行job任务时,首先要去下载job的切片信息、job运行时的配置文件以及job运行的MapReduce程序jar包。
9 .申请运行MapTask容器
当MRAppmaster将job资源下载完毕后,MRAppmaster会向Resource Manager申请运行MapTask容器。Resource
Manager接收到客户端发送来的运行MapTask容器申请后,会将该申请初始化为一个MapTask,并将该Task放入FIFO调度队列中。当Resource
Manager监控到某个Node Manager正处于空闲状态并资源充足,Resource Manager会从FIFO调度队列的头部拉取MapTask任务,然后分配给Node
Manager。
10 .领取MapTask任务,创建MapTask容器
当Node Manager就会从FIFO调度队列的头部领取MapTask任务后,Node Manager会将运行该MapTask任务所需的cpu、ram等资源和jar包封装到一个Container中。
11.发送程序启动脚本
当Node Manager将运行MapTask任务所需的cpu、ram等资源和jar包封装到一个Container后,MRAppmaster会向Node
Manager发送程序启动脚本,启动MapTask。
12.申请运行ReduceTask容器
当Node Manager运行完MapTask任务后,MRAppmaster会向Resource
Manager申请资源来运行ReduceTask容器。
13.获取分区数据
当MRAppmaster向Resource Manager申请资源来运行ReduceTask容器后,ReduceTask容器会向MapTask容器获取相应分区的数据。
14.注销MRAppmaster
当ReduceTask容器会向MapTask容器获取相应分区的数据,并运行完ReduceTask后,MRAppmaster向Resource
Manager发出注销请求。Resource Manager接收到注销请求后,会立马注销MRAppmaster,并释放相关资源。
作业提交全过程
在上一小节,本文介绍了Yarn的工作机制,以及每个步骤的详细说明。在本小节,我们将详细地介绍MapReduce作用提交的全过程。
1.MapReduce作业提交
当用户首先将一个MapReduce程序的jar提交到客户端所在的节点后,客户端Client调用job.waitForCompletion方法,向整个集群提交MapReduce作业。位于该节点上的YarnRunner会向整个Hadoop集群中资源的最高管理者Resource
Manager发送一次请求,申请一个Application。Resource Manager会为客户端分配一个Application资源提交的路径,以及Application编号application_id。
客户端会向该路径提交job运行所需要的所有资源,例如切片的规划、job运行时的配置文件和MapReduce程序的jar包。客户端Client提交完资源后,向Resource
Manager申请运行MrAppMaster。
2.MapReduce作业初始化
当Resource Manager收到客户端Client的请求后,Resource Manager会将该申请初始化为一个Task,并将该Task放入FIFO调度队列中。Resource
Manager监控到某个Node Manager正处于空闲状态并资源充足,Resource Manager会从FIFO调度队列的头部拉取Task任务,然后分配给Node
Manager。
当Node Manager就会从FIFO调度队列的头部领取Task任务后,Node Manager会将运行该Task任务所需的cpu、ram等资源和MRAppmaster封装到一个Container中。MRAppmaster会去下载job的切片信息、job运行时的配置文件以及job运行的MapReduce程序jar包。
3.任务分配
当MRAppmaster将job资源下载完毕后,MRAppmaster会向Resource Manager申请运行MapTask容器。Resource
Manager接收到客户端发送来的运行MapTask容器申请后,会将该申请初始化为一个MapTask,并将该Task放入FIFO调度队列中。
当Resource Manager监控到某个Node Manager正处于空闲状态并资源充足,Resource
Manager会从FIFO调度队列的头部拉取MapTask任务,然后分配给Node Manager。
当Node Manager就会从FIFO调度队列的头部领取MapTask任务后,Node Manager会将运行该MapTask任务所需的cpu、ram等资源和jar包封装到一个Container中。
4.任务运行
当Node Manager将运行MapTask任务所需的cpu、ram等资源和jar包封装到一个Container后,MRAppmaster会向Node
Manager发送程序启动脚本,启动MapTask。当Node Manager运行完MapTask任务后,MRAppmaster会向Resource
Manager申请资源来运行ReduceTask容器。当MRAppmaster向Resource Manager申请资源来运行ReduceTask容器后,ReduceTask容器会向MapTask容器获取相应分区的数据。
当ReduceTask容器会向MapTask容器获取相应分区的数据,并运行完ReduceTask后,MRAppmaster向Resource
Manager发出注销请求。Resource Manager接收到注销请求后,会立马注销MRAppmaster,并释放相关资源。
5.进度和状态更新
Yarn中运行的所有任务会将其进度和状态(包括counter)返回给MRAppmaster, 客户端Client每秒向MRAppmaster请求进度更新,
展示给用户。
6.作业完成
客户端每间隔5秒将通过执行waitForCompletion()函数来检查作业的完成进度。时间间隔可以通过mapreduce.client.completion.pollinterval来设置。作业完成之后,
MRAppmaster和Container会清理工作状态。为了便于用户管理和维护作业,作业历史服务器将存储作业的全部信息。
资源调度器分类
oop3.2.2默认的资源调度器是Capacity Scheduler。
1.FIFO调度器
FIFO调度器按照到达时间对job作业进行排序,先到达队列的job作业优先获得资源服务,并优先执行,如图1所示。
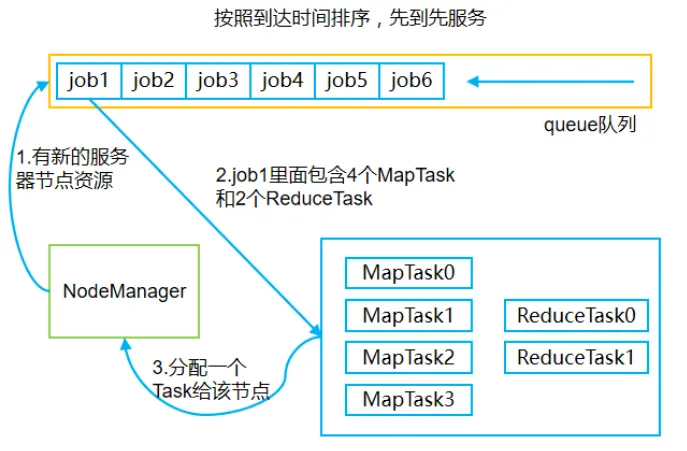
当MRAppmaster向Resource Manager提交job作业后,Resource Manager会将Task插入到queue队列中。由于是FIFO调度器,Resource
Manager会优先处理queue头部的job。当Resource Manager监控到有新的服务器节点资源时,Resource
Manager会从FIFO调度队列的头部拉取job1。job1里面包含4和MapTask进程和2个ReduceTask进程。Resource
Manager会将一个Task分配给Node Manager。
2.容量调度器
Capacity Scheduler也称容量调度器,Hadoop3.2.2默认的资源调度器就是Capacity
Scheduler。容量调度器内部具有多个queue队列,因此具有比FIFO调度器更高的并行性,如图2所示。
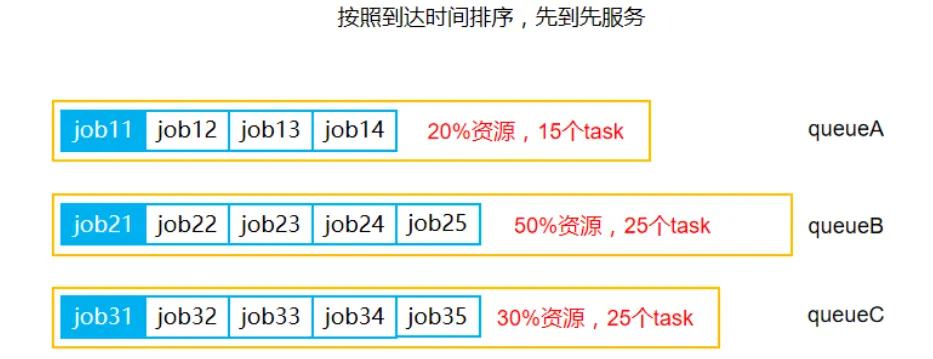
容量调度器内部拥有多个队列存储job,每个队列可以配置一定的资源量,并且每一个队列采取FIFO调度策略。容量调度器通过限制每一个用户上传作业所使用的资源量,避免某个作业占用队列中的所有资源。计算每一个队列中实际运行的任务数量与其理应获得的计算资源的比值,比值最小的队列也称为最闲的队列。
当Resource Manager监控到有新的服务器节点资源时,容量调度器会优先选择最闲的队列。在每一个队列中,按照job优先级和提交时间,同时考虑用户的资源量限制和内存限制对队列中的job进行排序。容量调度器内部的多个队列同时安排任务的先后顺序依次执行。例如图2中的三个队列,job11、job21和job31分别排在队列的最前面,所以先运行,而三个队列是并行执行。
3.公平调度器
Fair Scheduler也称公平调度器,其内部具有多个queue队列,因此具有比FIFO调度器更高的并行性,如图3所示。

公平调度器支持多队列多用户,每个队列可以配置一定的资源量,并且同一个队列采中作业公平共享队列中的所有资源。
例如图3中,公平调度器中有三个队列:queueA、queueB和queueC。每一个队列中的job按照优先级分配资源,优先级越高分配的资源越多,但是每个job都会分配到资源以确保公平。在一定的资源下,每一个job实际得到的计算资源和理应得到的计算资源存在一种差距,这称为缺额。在同一个队列中,资源缺额较大的job,会首先得到计算资源,并得到运行的机会。作业是按照缺额的高低来先后执行,在图12.5中可以看出多个作业并行执行。
任务的推测执行
在管理学中,有一个非常著名的木桶原理:一只水桶能装多少水取决于它最短的那块木板。对于一个MapReduce作业,它可能由若干个Map任务和Reduce任务构成。考虑到硬件老化、软件Bug等因素,某些Map任务或者Reduce任务可能运行非常慢,会拖慢整个作业的完成时间。因此,与木桶原理类似,MapReduce作业完成时间取决于最慢的任务完成时间。
对于执行最慢的任务,Yarn资源调度器给出了一种解决方案,即任务推测执行机制。在MapReduce作业执行过程中,Yarn检测到执行异常缓慢的任务,比如某个任务运行速度远慢于任务平均速度。并且,当前的MapReduce作业或者job已完成的Task必须不小于5%。Yarn会为该任务开启一个相同的任务,同时执行。谁先运行完,则采用谁的结果。值得注意的是,每个Task只能有一个备份任务。概括地说,任务的推测执行机制有三个前提:
(1)每个Task只能有一个备份任务;
(2)当前Job已完成的Task必须不小于0.05(5%);
(3)在mapred-site.xml文件中,设置推测执行参数为开启状态。
此外,在一些情况下,不能启用Yarn的推测执行机制。
(1)任务间存在严重的负载倾斜
某个Task需要处理的数据较多,工作量大导致运行时间较长。如果Yarn为其开启一个备份任务,那么该备份任务的执行时间会更长。
(2)需要向数据库中写数据的任务
对于需要向数据库中写数据的任务,即使运行速度再慢,也不能为其开启一个备份任务,否则无法保证数据的一致性。
任务推测执行原理
为了能够清楚地讲述任务推测执行原理,本文首先引出三个公式,同时说明公式中提到的英文符号的含义。假如某一个时刻currentTimestamp,任务T的执行进度为progress,则可通过一定的算法推测出该任务的推测运行时间estimateRunTime和最终完成时刻estimateEndTime。同时,我们假设任务T的开始运行时刻为taskStartTime。另一方面,我们假设运行完成任务T的平均时间为averageRunTime,如果此时为该任务开启一个备份任务,则可推测出它可能的最终完成时刻为estimateEndTime_backup。
任务T的推测执行时间,可以由下面的公式计算得出。
estimateRunTime = ( currentTimestamp - taskStartTime
) / progress
任务T的最终完成时刻,可以由下面的公式计算得出。
estimateEndTime = estimateRunTime + taskStartTime
任务T的备份任务最终完成时刻,可以由下面的公式计算得出。
estimateEndTime_backup = currentTimestamp + averageRunTime
根据上述的三个公式,我们来讲解任务推测执行的原理。Yarn资源调度器总是选择(estimateRunTime
- estimateEndTime_backup)差值最大的任务,并为之开启备份任务。如果大量任务同时开启了备份任务,必然会造成资源浪费。为了防止这种情况的发生,Yarn资源调度器为每一个作业设置了同时启动的备份任务数目的上限。在本质上,任务推测执行机制采取了以时间换空间的策略,在同一时刻开启多个相同任务处理相同的数据,使这些任务竞争以降低数据处理的时间。但是,这种方式会消耗大量的计算资源。
| 







