| 编辑推荐: |
本文主要介绍了DeepSeek+Ragflow搭建个人知识库相关内容。希望对你的学习有帮助。
本文来自于微信公众号coderllch ,由火龙果软件Linda编辑,推荐。 |
|
先说体验感受,利用参数量小的模型借助RAGFlow搭建知识库,有一点点用,但是不多。要想发挥实际作用,对知识库数据的维护需要花很多心思。
一、安装Docker Desktop
由于Docker依赖linux环境,win10以上电脑可以使用wsl来安装linux环境。
什么是WSL?WSL(Windows Subsystem for Linux)是微软开发的一项技术,允许用户在Windows系统中直接运行完整的Linux环境,无需虚拟机。通过操作系统级虚拟化,WSL将Linux子系统无缝嵌入Windows,提供原生Linux命令行工具、软件包管理器及应用程序支持。它具有轻量化、文件系统集成、良好的交互性及开发效率提升等优点,消除了Windows与Linux之间的隔阂,尤其适合开发者和需在Windows平台上使用Linux工具的用户。
1.启用window子系统及虚拟化
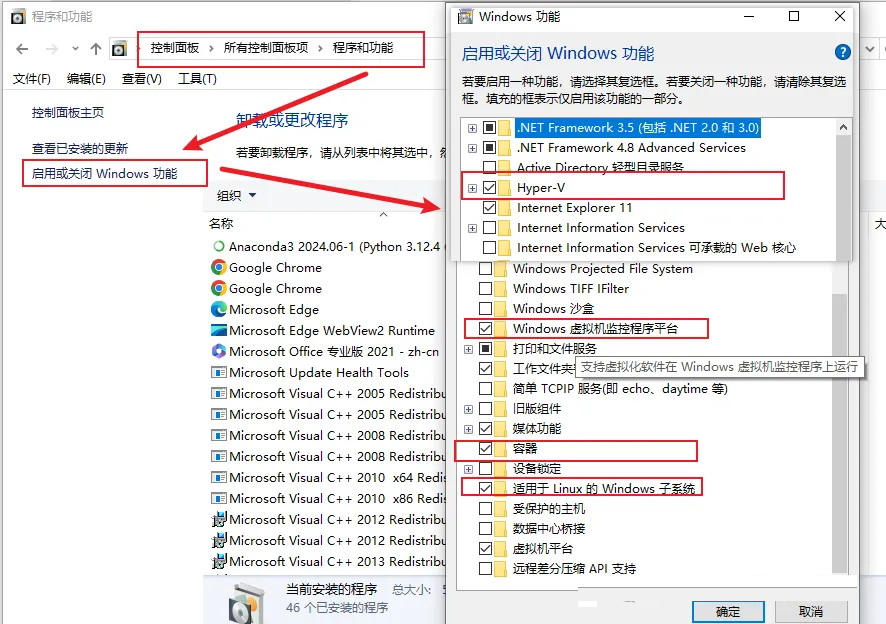
2.Docker Desktop配置
下载地址:https://www.docker.com/
|
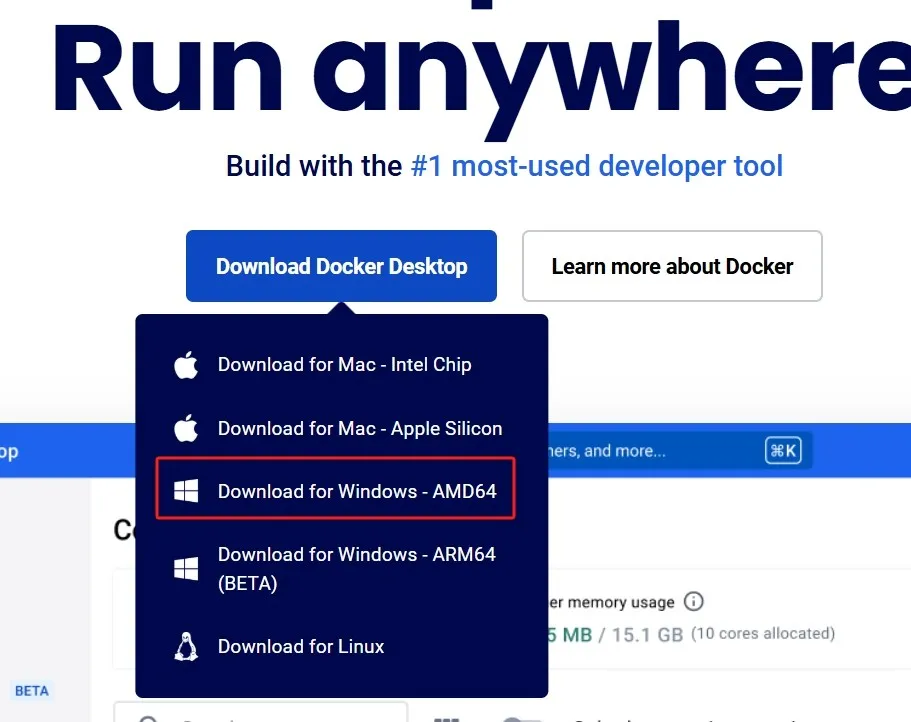
下载完成后,打开安装包一直下一步等待安装结束即可。
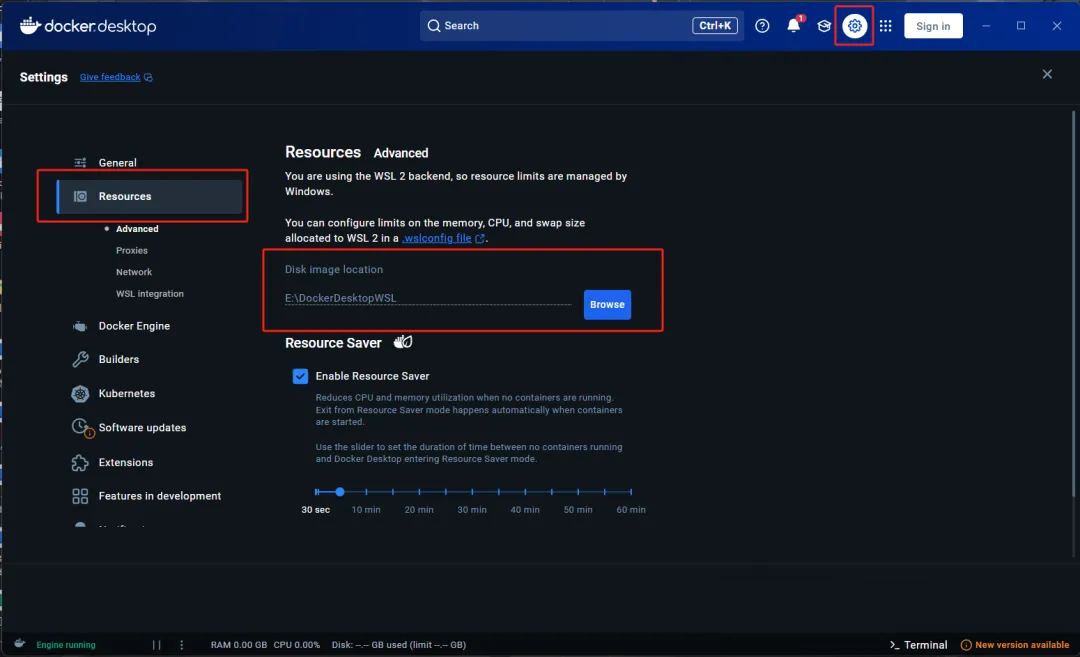
提示:因为安装完成后镜像很大,默认会安装在C盘,建议更改到其他空闲盘。
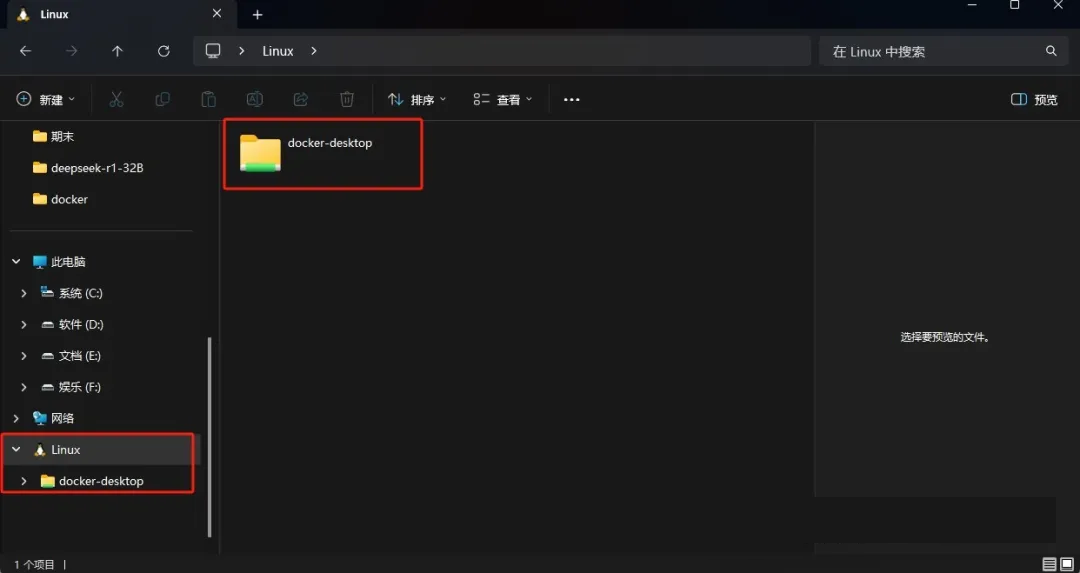
打开docker desktop,会自动弹出cmd窗口,启动wsl下载linux,否则无法运行docker。这一步耐心等待即可。安装完成后,可以在我的电脑查看->linux。
3.Docker Desktop配置
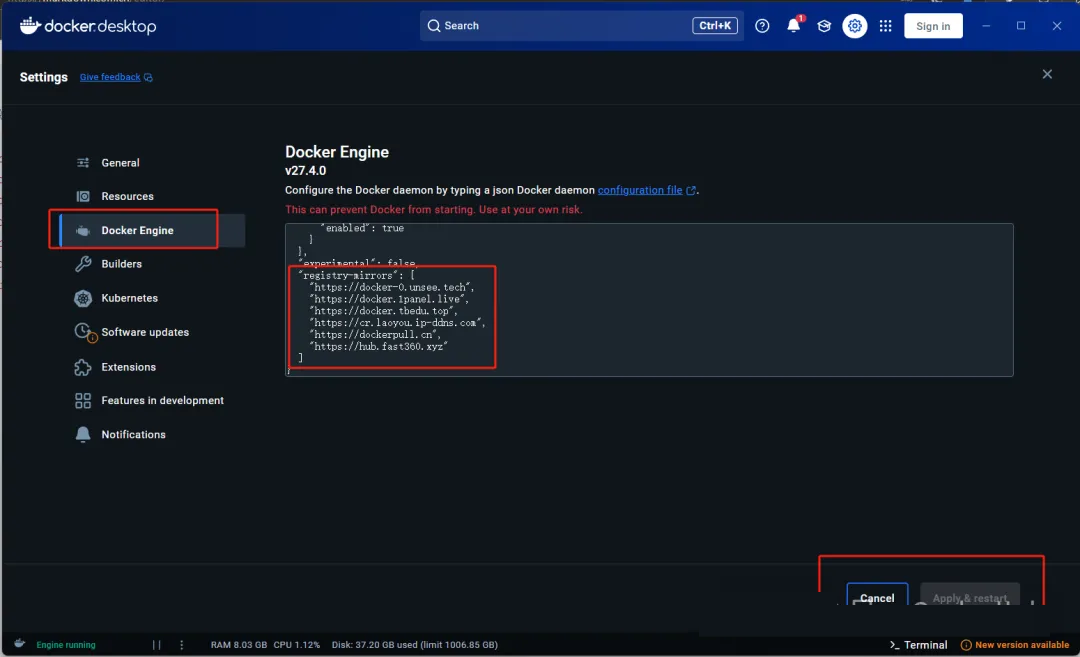
最新可用的国内镜像源可以百度找找。这里提供几个当前还能用的镜像源。
"registry-mirrors": [
"https://docker-0.unsee.tech",
"https://docker.1panel.live",
"https://docker.tbedu.top",
"https://cr.laoyou.ip-ddns.com",
"https://dockerpull.cn",
"https://hub.fast360.xyz"
]
二、部署Ragflow
https://kkgithub.com/infiniflow/ragflow/blob/main/README_zh.md
|
软硬件条件:
CPU >= 4 核
RAM >= 16 GB
Disk >= 50 GB
Docker >= 24.0.0 & Docker Compose >= v2.26.1
1.拉取ragflow
$ git clone https://github.com/infiniflow/ragflow.git
|
这个过程会比较慢,可以用码云转一下github仓库,拉取速度会快很多。
2.进入docker文件夹,利用提前编译好的Docker镜像启动服务器
由于我们需要用到embedding模型,默认的ragflow镜像不自带embedding,这里需要特别注意要手动修改配置。
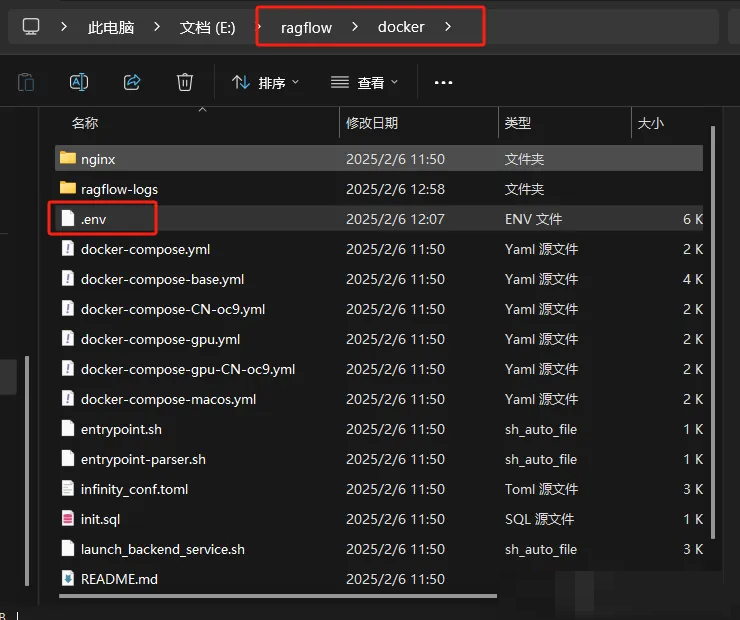
在拉取的ragflow仓库路径下的docker/.env 文件内的RAGFLOW_IMAGE变量,通过设置RAGFLOW_IMAGE=infiniflow/ragflow:v0.16.0来下载
RAGFlow镜像的 v0.16.0 完整发行版。 在ragflow文件夹下打开cmd窗口运行以下命令:
docker compose -f docker/docker-compose.yml up -d
|
安装ragflow需要的docker镜像,拉取失败说明docker镜像源有问题,需要自行百度查询可用镜像源重新拉取。
如果你遇到 Docker 镜像拉不下来的问题,可以在 docker/.env 文件内根据变量 RAGFLOW_IMAGE
的注释提示选择华为云或者阿里云的相应镜像。
华为云镜像名:swr.cn-north-4.myhuaweicloud.com/infiniflow/ragflow
阿里云镜像名:registry.cn-hangzhou.aliyuncs.com/infiniflow/ragflow
|
拉取成功后,在docker desktop里面就能看到镜像源。
3.在你的浏览器中输入你的服务器对应的IP地址并登录RAGFlow
默认打开ragflow地址http://localhost:80

三、Ragflow使用
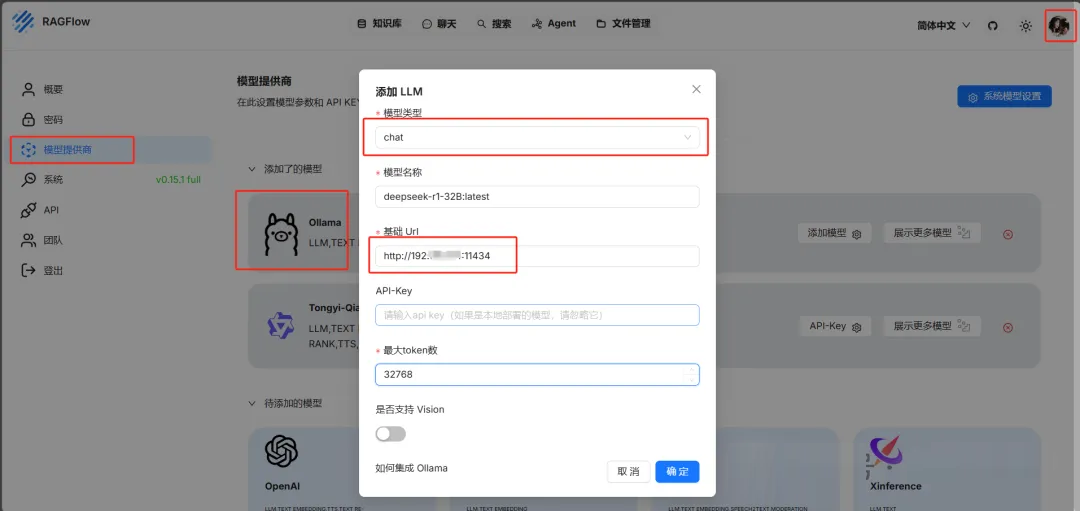
登录ragflow,根据图片内容进行配置。需要注意基础Url需要改为ip:端口号,ollama默认端口11434
1.知识库配置
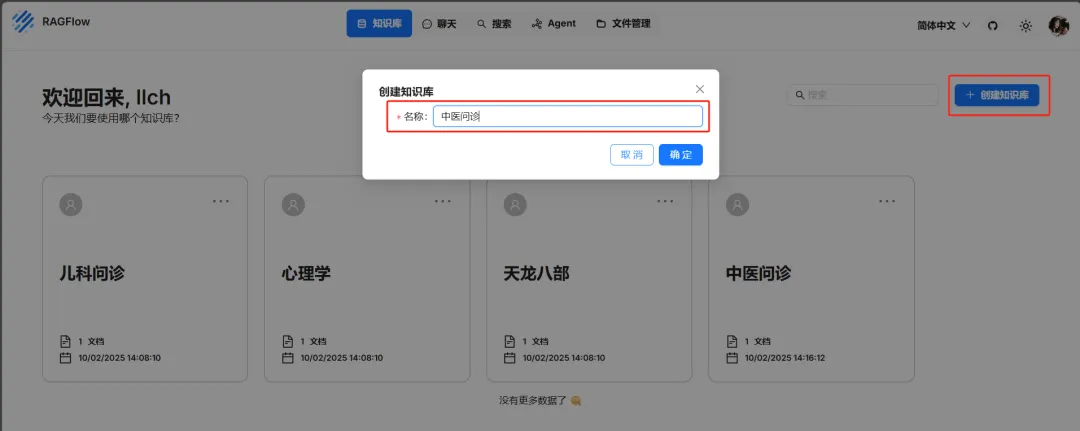
创建知识库,这里使用一份一千条中医问答数据作为测试。

如图进行创建知识库。
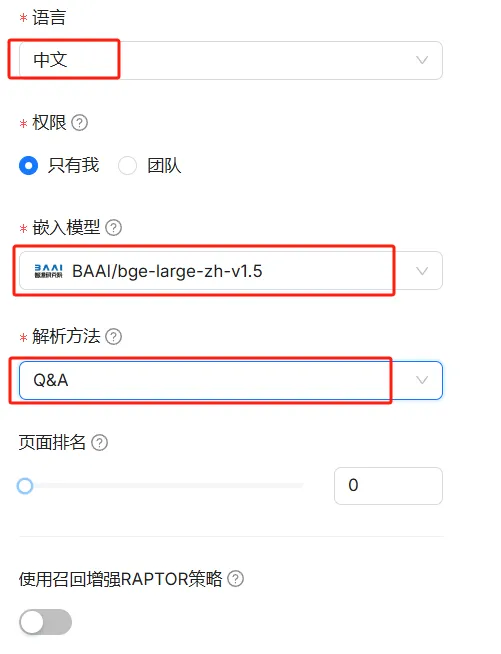
嵌入模型选择默认的即可,解析方法比较重要,因为使用的数据是问答形式,所以选择Q&A类型。解析方法有很多种,网页中都有解释,选择合适的解析方法能够让知识库的回答更加准确。
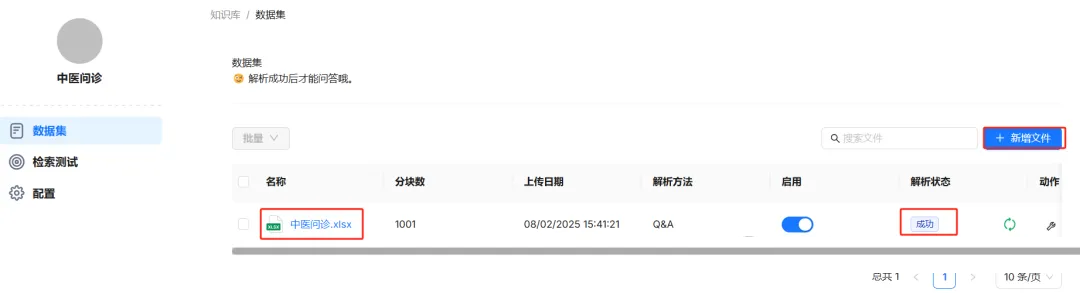
点击新增文件,将中医问诊数据集进行进行上传,等待系统解析完成。这个过程会比较慢,错误的解析方法也会导致解析失败。
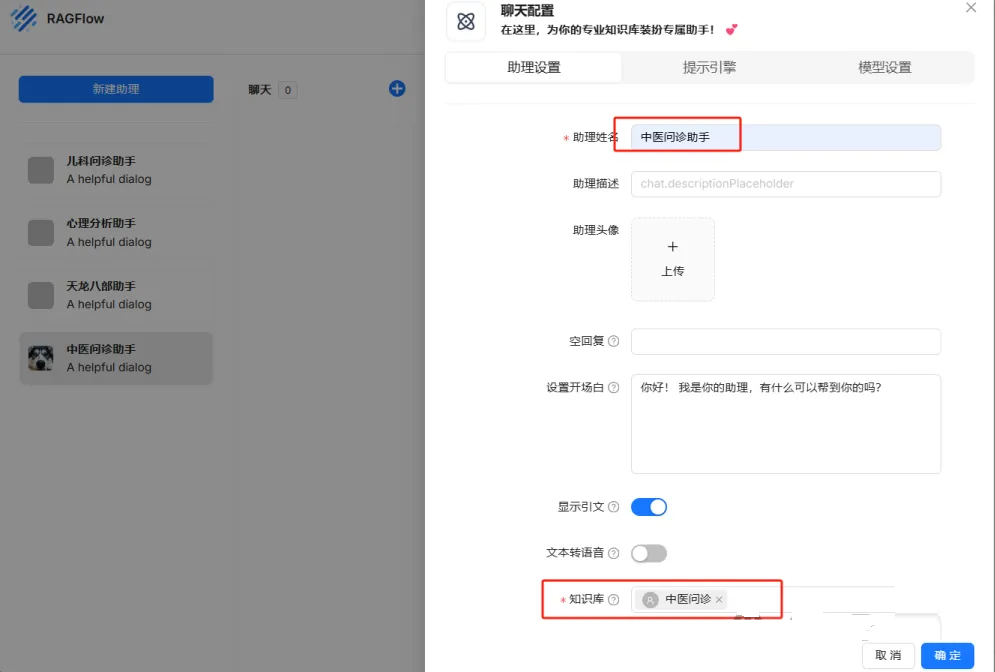
2.创建中医问诊聊天助手
聊天模块选择新建助理,知识库选择上一步新建的中医问诊。
模型设置中选择ollama已下载模型,我选择deepseek-r1:32b模型进行测试。每个参数在网站里都有解释,这里自由度设置为精确,尽可能让大模型从知识库里回答问题,减少自由发挥。
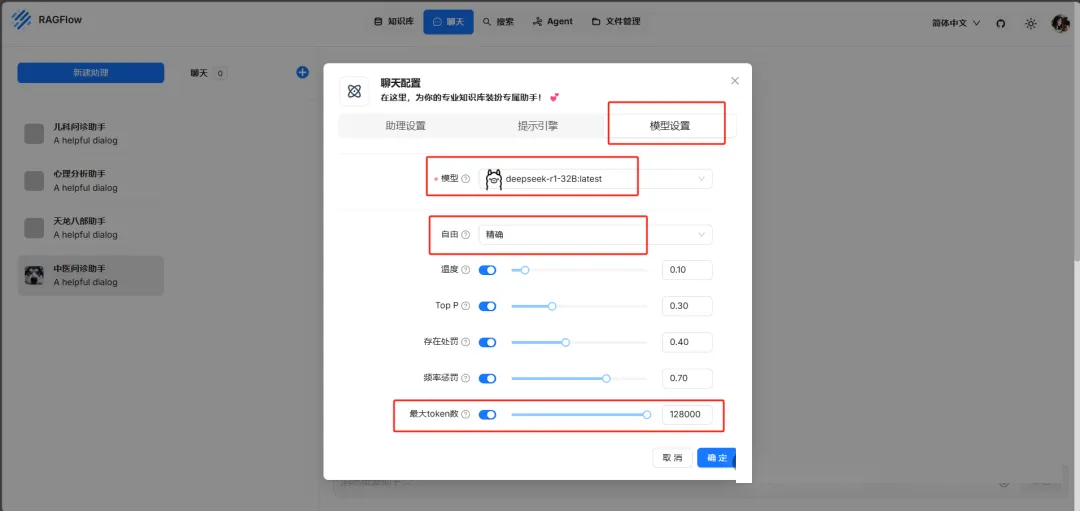
点击确定,新建聊天。测试一下看看效果吧。


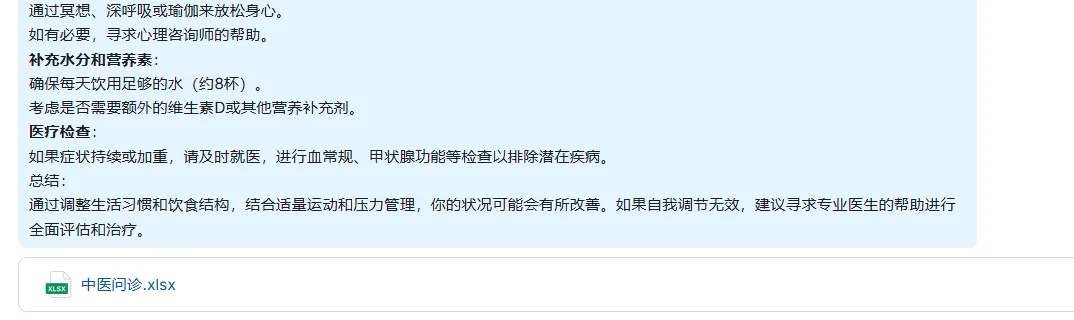
效果粗略看还可以,聊天助手还可以标注出知识库的来源。

如果能够将知识库数据整合处理好,体验效果还是不错的,这只是32b的模型,如果人人都能部署的671b呢?真是对未来充满期待。
3.多测试几个知识库,一起看看效果吧
天龙八部小说:
问题1:
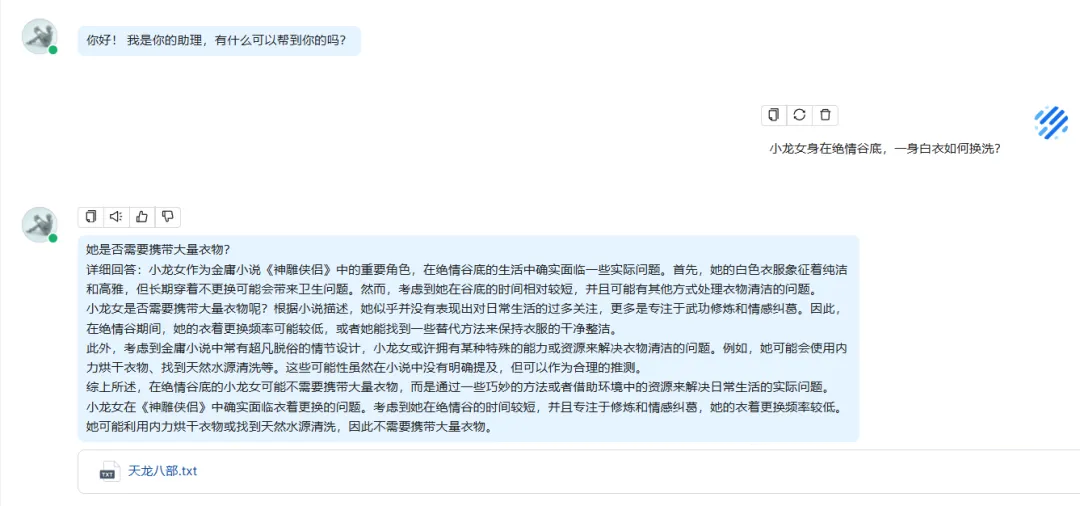
问题2:
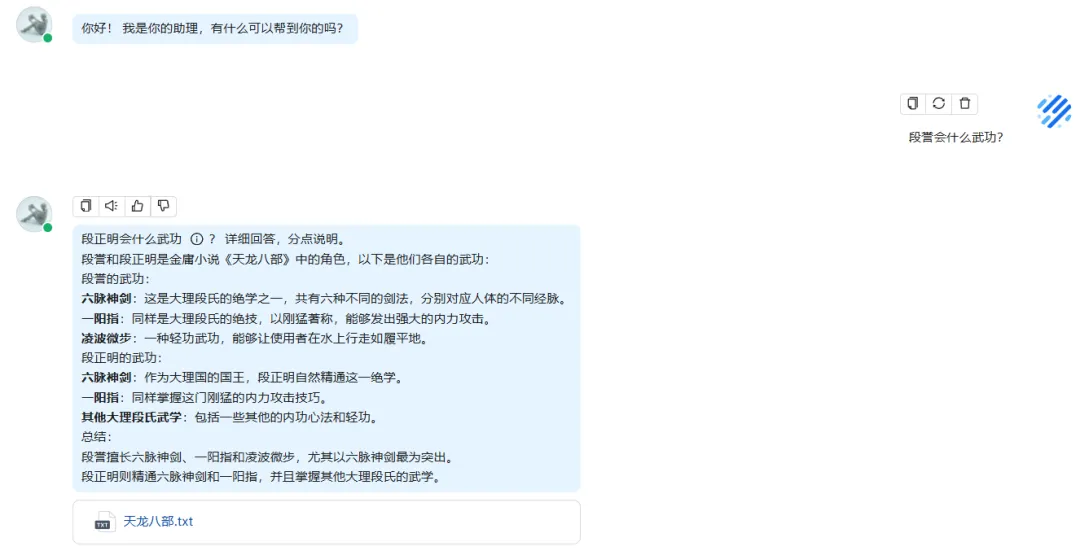
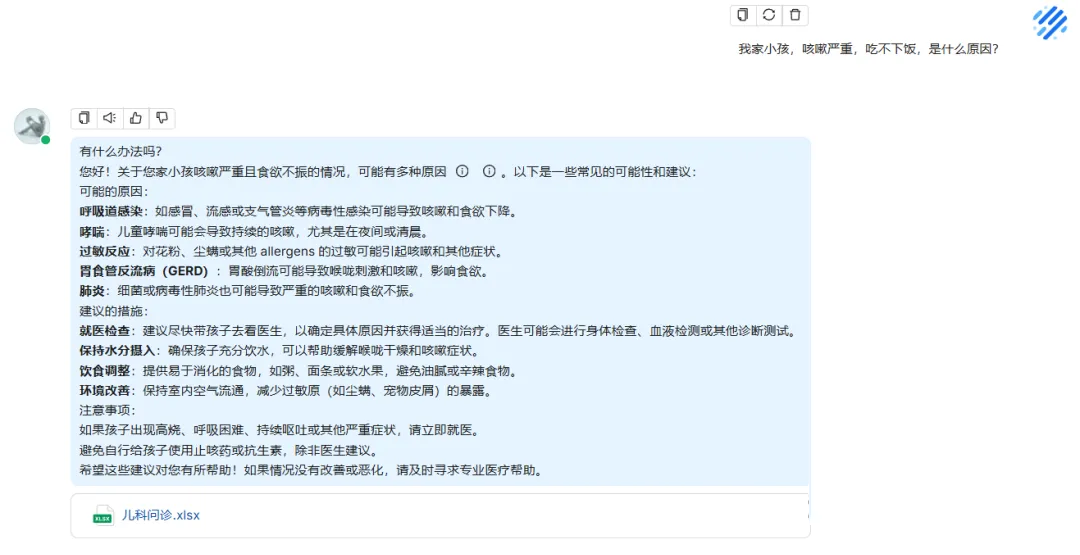
儿科问诊数据一千条:
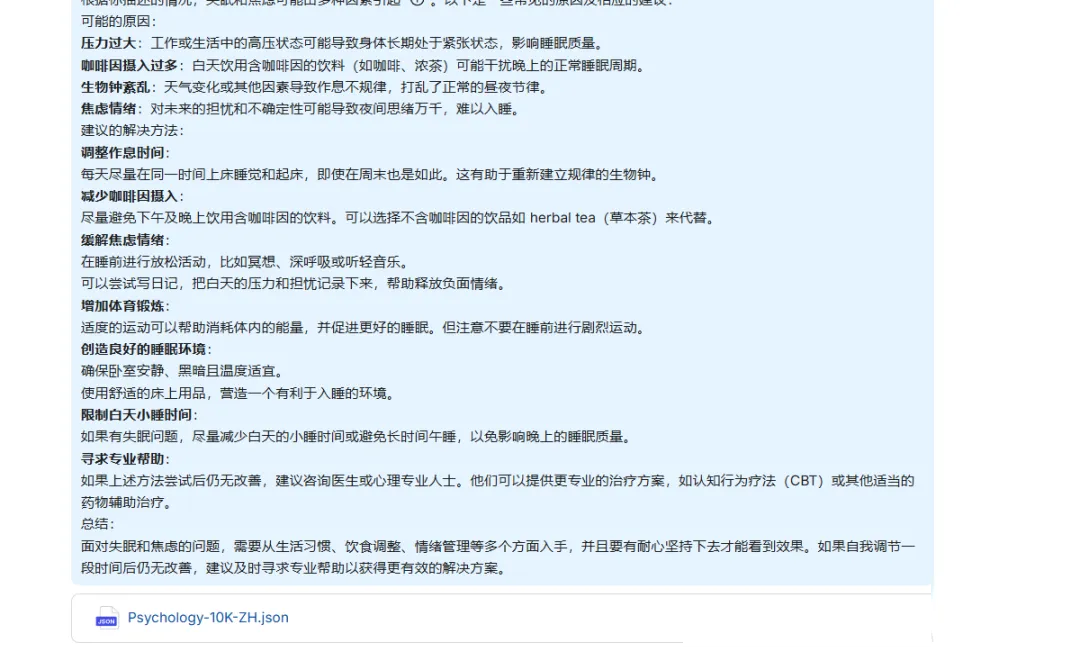
心理学数据一万条:

四、最后
利用Deepseek+Ragflow搭建的知识库过程还是比较简单,正常跟着流程走不容易出错。如果投喂的数据经过整合处理,那么反馈的结果还是有一定的实际意义。
当前个人能部署的模型参数太少,尚处于体验阶段。相信不久的将来,大模型不断发展,个人能部署性能更强大的模型。 | 








