| 编辑推荐: |
本文主要介绍了知识蒸馏的相关概念和在扩散模型中的应用场景相关内容。希望对你的学习有帮助。
本文来自于微信公众号腾讯云开发者 ,由火龙果软件Linda编辑,推荐。 |
|
知识蒸馏是什么?扩散模型的蒸馏和一般的蒸馏方法有什么不同?本篇文章简单介绍了一下知识蒸馏的相关概念和在扩散模型中的应用场景,希望可以给相关领域的朋友们提供一些参考。
01
知识蒸馏
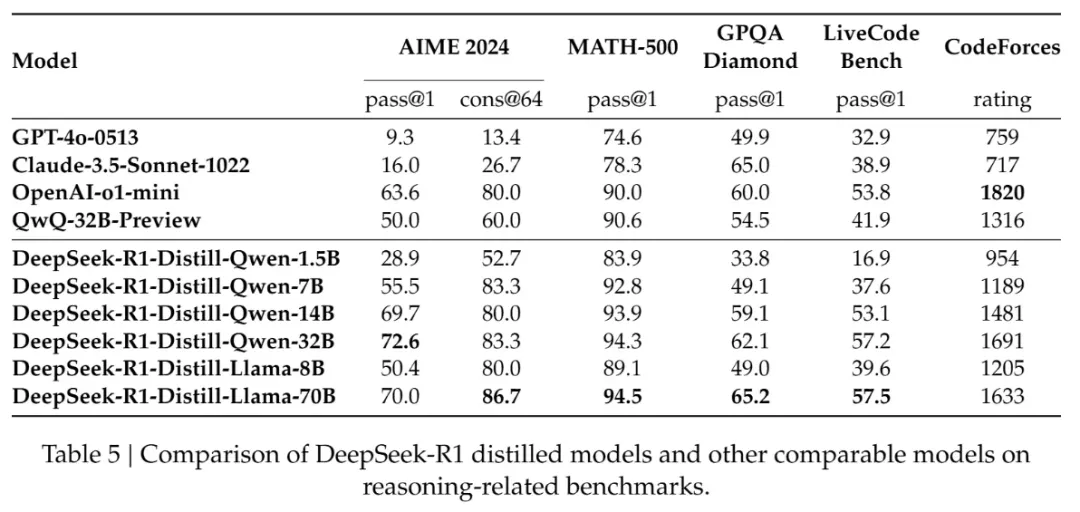
DeepSeek R1 在春节期间公开发表了技术文档,并开源了多个蒸馏模型,其性能甚至可以超越 OpenAI-o1-mini,验证了将
671B 大模型的模型能力通过简单的数据蒸馏可以快速迁移到规模更小的模型的可行性。
那么蒸馏模型和原始模型的区别是什么呢?它们之间又有怎样的关系?为什么使用大模型蒸馏后的小模型能比直接训练有更好的性能?想要解释这些问题就要先从蒸馏原理讲起。
1.1 知识蒸馏的基本概念
知识蒸馏的过程,简单解释就是用教师模型教会学生模型知识。例如在 DeepSeek R1 的例子里,DeepSeek
R1 就是教师模型,用于蒸馏训练的小模型(Qwen 或者 Llama)就是学生模型。知识蒸馏的核心,就是让学生模仿教师的思考过程,而不是简单地背答案。
硬标签 v.s. 软标签
蒸馏训练时,学生模型通常会接收两组不同的答案,分别人工训练集的 GT,也就是硬标签,和教师模型生成的概率分布,也就是软标签:
硬标签就像是正确答案,例如告诉你这张图片是猫还是狗。
软标签则是包含了教师模型的概率分布的更为复杂的答案:“这个图片有80%的概率是猫,但也有20%的可能是狗,因为它们有点像”,于是模型不但知道了答案,还学到了“猫和狗是比较容易混淆的”这个知识。
训练的时候,学生模型既看正确答案(保证正确性)又会看老师的软标签(学习老师的知识),这两个信号会“加权混合”成一个总目标。
那么为什么不全部用软标签呢?
因为教师模型也是有可能犯错的!只用软标签,学生模型的上限就是这个教师模型了。
既然教师模型可能出错,为什么不能把和硬标签冲突的错误标签筛选掉呢?
因为软标签是模型生成的,量级通常比硬标签大得多,人工筛选每一个软标签的成本非常大。把软标签和硬标签混合使用并用权重控制比例是更合适的做法。如果教师模型比较值得信任,就可以调大它的权重,反之亦然。
温度参数
如果我们有一个比较精确的教师模型,它的输出可能是比较夸张化的,例如“这个图片有99%的概率是猫,有1%的可能是狗“,因为模型能很好区分猫和狗。但是如果让模型更温柔一些,也许学生模型反而能更好学到两者之间的关系。
这时候会引入温度参数 T 软化概率分布:
T>1 时,概率分布更平滑,保留类别间相对关系(如“猫 vs 狗”的相似性);
T=1 时退化为标准 Softmax。
DeepSeek R1 的蒸馏
在 DeepSeek R1 的实验报告中提到:

仅仅通过蒸馏 DeepSeek R1 的输出就可以让 R1-7N 模型的性能超越 GPT-4o-0513。其他更大的蒸馏模型就更强了。这里的
xxB 指的就是参数量,可以简单理解为参数量越大,模型计算力越强,天赋越好。而后天的训练就是对不同天赋的模型进行教学。DeepSeek
R1 技术报告的蒸馏实验证明,对于天赋相同的模型(参数量和结构一致)用强力的大语言模型进行教学,比直接用人类知识教学更有效。在这里,蒸馏只用了
DeepSeek R1 的模型输出,并不涉及到更复杂的概率分布学习或者提供硬标签,就已经可以达到很好的效果了。
技术报告还提到一个有趣的观察点是,蒸馏后的模型如果继续用强化学习训练一段时间,可以进一步提高模型的性能。虽然他们没有开源这部分模型,不过这是一个很有意思的观察。可能学生在学习了教师模型之后,如果再强化学习一番,可以微调自己的知识结构,让其更适应自身的结构分布。
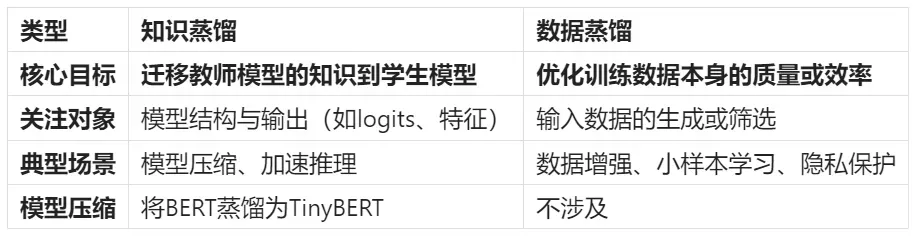
1.2 知识蒸馏 v.s. 数据蒸馏
提了知识蒸馏的概念就顺便讲一下数据蒸馏。知识蒸馏学习的是教师模型的分布,而数据蒸馏侧重于通过数据增强等方法从数据的角度得到更纯净的训练数据来训练学生模型。数据蒸馏一般不涉及模型的压缩,而是对训练数据的精炼。
知识蒸馏和数据蒸馏的主要区别如下:
02
扩散模型的蒸馏和加速
说完了一般意义上的知识蒸馏,让我们回到文生图扩散模型上。和一般的蒸馏是为了压缩模型大小不太一样,在文生图领域里,蒸馏方法更多用在步数的蒸馏上。因为文生图扩散模型在生成图片时通常需要很多步的去噪步骤,我们对扩散模型更大的需求是压缩步数来达到用更少步数生成同样高质量的结果,甚至能达到一步生成。
需要先强调的是,扩散模型的加速不全是基于教师模型蒸馏的,蒸馏只是加速的手段之一。
对于扩散模型的加速,或者更准确地说,推理步骤的压缩,主要可以分为以下几类加速方法。
2.1 确定性加速方法
Consistency Model
以 LCM、LCM-LoRA 为代表的一致性模型加速方法,应该可以算是文生图领域中第一个有较大影响力的加速方法了。LCM
的原理详解推荐一篇博客:https://wrong.wang/blog/20231111-consistency-is-all-you-need/,具体的算法细节不在这里细说。
简单来说,它重构了扩散模型的训练目标。之前模型生成,需要反复修改 n 次(n steps),但是
Consistency Model 要求无论从哪一步开始画,都要能直接预测最终的结果。所以 Consistency
Model 可以用更少的步数生成去噪干净的图片。
Consistency Model 前面接一个 VAE 把图片转化成 latent 就变成了 Latent
Consistency Model(LCM)。又因为这个训练是基于原始模型的微调,所以可以结合 LoRA
的技术,把微调的部分以 LoRA 的形式保存下来,既可以减小模型的大小,还可以和其他风格化 LoRA
进行组合。这也是第一个把加速技术做成 LoRA 模型的成功尝试。
流匹配 Flow Matching
扩散模型之所以需要多步生成,是因为它的 flow 是 curved 的,直接求解会有较大误差,Flow
Matching 的核心思想就是让 Flow 变直,从而可以直接求解。
以上基于确定性模型的加速方式,通常4步以内的结果依然比较糊,要8步才能生成较为清晰的结果。在中提出了一些解释:
在扩散模型的加速过程中,由于要在较少的步骤内完成原本多步的生成任务,优化过程难以精确地逼近教师模型的输出。这意味着学生模型在学习从噪声到样本的映射时,无法准确捕捉到所有细节信息。在图像生成中,可能无法精确还原图像中物体的边缘、纹理等细节,导致生成的图像模糊。
Lipschitz constant 和函数的平滑程度有关,在学生模型中,当尝试减少生成步骤时,模型的结构或参数调整可能会使
Lipschitz constant 降低。较小的 Lipschitz constant 意味着模型在处理输入变化时,输出的变化相对较小且更平滑。这虽然能保证模型的稳定性,但也会使模型在生成样本时丢失一些细节信息,因为它不能对输入的微小变化做出足够敏感的反应。在生成高分辨率图像时,对细节的捕捉需要模型能够对不同的输入特征做出准确且细致的响应,Lipschitz
constant 降低会削弱这种能力,从而使生成的图像变得模糊。
2.2 扩散模型的步数蒸馏
扩散模型的步数蒸馏,指的是在教师模型的指导下,学生模型学会用更少的步数(对应inference steps)生成相似质量的图片。
渐进式蒸馏 Progressive Distillation
渐进式蒸馏方法可以说是最典型的一个步数蒸馏的方法了。
想象你要教一个新手画家(学生模型)快速画画。
原本的画法是:老师(扩散模型)需要画100笔,每一笔都慢慢修正细节(对应扩散模型的100步去噪)。但新手没耐心画100笔,想几笔搞定。这时候就需要“蒸馏”老师的技巧,让新手学会用更少的步骤画出差不多的效果。
怎么教呢?渐进式蒸馏使用了跳步学习的思想:
老师先按老方法画完100笔,但记录下关键中间步骤(比如每隔5笔记录一次)。
然后告诉新手:“别一步一步画了,你直接从第0笔跳到第5笔,再跳到第10笔,跳过这些中间步骤”。
新手练习时,就要模仿老师跳多步后的结果(比如一笔顶老师五笔的效果),这就完成了单次的步数蒸馏(100步->20步)
这时候这个20步模型作为教师模型,再去教下一个学生用更少的步数画出相同的结果,反复练几次,新手就能用很少很少的次数画出老师100笔的效果了。
这个渐进压缩步数的过程就是渐进式蒸馏的核心。
为什么需要渐进蒸馏:
直接学习很难训练,容易模式崩塌。
逐步蒸馏避免误差跳跃过大,积累误差。
(拓展)渐进式蒸馏的数学解释
这段数学解释摘自,虽然我觉得很好理解不过不喜欢看公式的可以直接跳过!
1. Diffusion 模型的前向扩散过程(Forward Diffusion Process)
扩散模型的核心思想是通过逐步添加噪声,将数据分布(如图像)转化为高斯噪声分布。这一过程称为前向扩散。

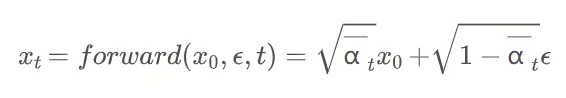

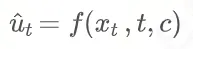
C 是条件。
一般是预测噪声,即 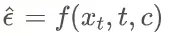 ,于是数据可以这样算出来: ,于是数据可以这样算出来:
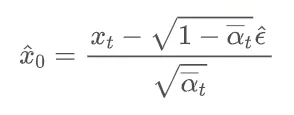
也有一些方法预测数据,即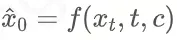 ,也可以算出噪声: ,也可以算出噪声:
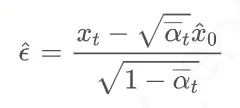
实际意义:
网络的目标是学习如何从噪声中恢复数据,类似于“去雾算法”从模糊图像中恢复清晰图像。
3. 概率流与移动操作(Probability Flow and Move Operation)
扩散模型的生成过程可视为沿着概率流(ODE 轨迹)移动样本。
数学定义:

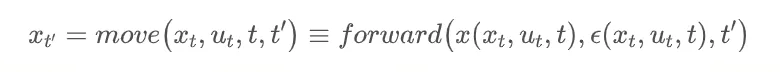

4. 渐进蒸馏(Progressive Distillation)
渐进式地从教师模型学习分布,一旦收敛,学生模型就会作为教师模型进一步进行蒸馏。由于使用了 MSE
作为 loss 来计算教师模型和学生模型的数据分布 loss,在步数压缩到比较小之后,图片会越来越模糊,所以后续会引入对抗
loss。
单个蒸馏过程的数学描述如下:


这个公式主要用于提供加噪样本。
然后,使用 frozen 的教师模型,通过步从生成,这里的是步长间隔。如果步长间隔是50,那就是从1000到0,950、900、850……这样一直生成到0。
第一步:
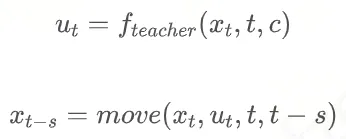
第二步:
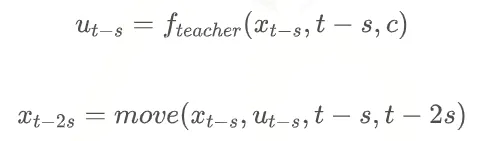
重复直到第 n 步:
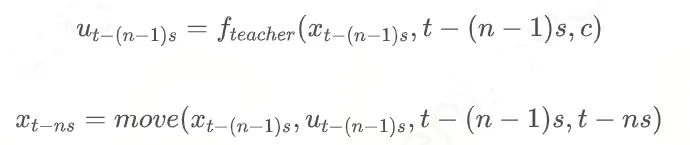
最后的目标是计算出X0。
于是就得到了教师模型的每一个间隔的数据和梯度场的值。
学生模型的学习目标是直接从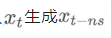 ,比如说 s=50,n=2,那就是直接从1000,900,800,700这样学: ,比如说 s=50,n=2,那就是直接从1000,900,800,700这样学:
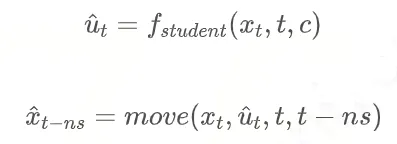
学习的 loss 计算:
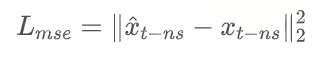
分数蒸馏 Score Distillation
直接的渐进式蒸馏技术,在压缩后几步的时候效果会急剧下降,于是 DMD提出了分数蒸馏的改进方法,通过最小化生成分布与真实分布之间的
KL 散度,确保生成图像与原始扩散模型输出在分布层面一致,从而使得模型画出来的结果也和原始模型一样好。
提到KL散度大家可能会联想到 GAN,这篇文章也提到,对抗蒸馏(下文会解释)的方法一般是引入判别器,区分教师和学生的生成成果,通过对抗
loss 迫使学生欺骗判别器。作者认为:“对抗训练需要复杂的平衡,且容易导致模式崩塌(mode collapse),而分布匹配通过显式的最小化
KL 散度,能更稳定地实现一步生成。
对抗蒸馏 Adversarial Training
对抗训练通常是通过构建一个生成对抗网络(GAN)的架构,其中学生模型作为生成器(Generator,通常用教师模型进行初始化),负责生成样本;另外引入一个判别器(Discriminator),用于区分生成的样本是来自学生模型还是教师模型,从而让学生模型的分布接近教师模型的分布。SDXL-Turbo
采用的蒸馏方案就是 Adversarial Diffusion Distillation(ADD)。
由于引入对抗机制,GAN 方法通常生成质量都会比较接近教师模型,但正如前文所说,GAN 面临着难以训练,且容易模式崩塌的问题。并且
SDXL-Turbo 采用的 D 是传统的图片编码 backbone(DINOv2),不支持 latent
输入,限制了更大分辨率的图片生成,并且只能在 t=0(也就是干净去噪的图片)上使用,无法兼容渐进式的蒸馏方法。
SDXL-Lightning 结合了对抗蒸馏和渐进式蒸馏,采用和 G 一样的网络结构的 D(都是
pre-trained Diffusion Unet)来支持对 t 的输入,先直接把模型从 128
步直接蒸馏到 32 步,然后按照按32->8->4 ->2 ->1的顺序,增加对抗损失进行渐进式蒸馏。
03
对抗后训练 Adversarial Post-Training
为了这一包醋包了一整锅饺子,终于谈到标题的 APT 了!这篇论文同时支持图片和视频的加速,并且只训练一步生成模型,所以从本质上说更像是是在训练一个超级大的
GAN(真的 make GAN great again 了),原始的 diffusion 更多意义是用在初始化模型上(这也是其自称
Post-Training 的原因)。所以也会有 GAN 的各种优缺点,例如难以训练,容易 mode
collapse,文本控制能力稍弱,生成图片质量更真实,和——快,因为 GAN 天然就是 one-step
的。所以这篇论文的主要 contribution 就是介绍它们用的各种方法来阻止 mode collapse,想办法把这个超大
GAN(DiT version)训练出来。
先总结一下之前方法的缺点:SDXL-Lightning 和 DMD 等基于蒸馏的方法,需要用教师模型生成大量数据,这对于视频数据来说
cost 尤其大,并且模型的上限就是教师模型。DMD2 和 ADD 结合了对抗和分数蒸馏,其中对抗训练使用真实数据,分数蒸馏使用教师模型。而
UFO-Gen 进一步只是用真实的数据做对抗,直接摆脱了对教师模型的依赖。但 UFO-Gen 使用的判别器是
1B 的卷积网络。APT 改为使 DiT 作为生成器和判别器的 backbone,并提出了多个技巧使得训练稳定,避免
mode collaps。
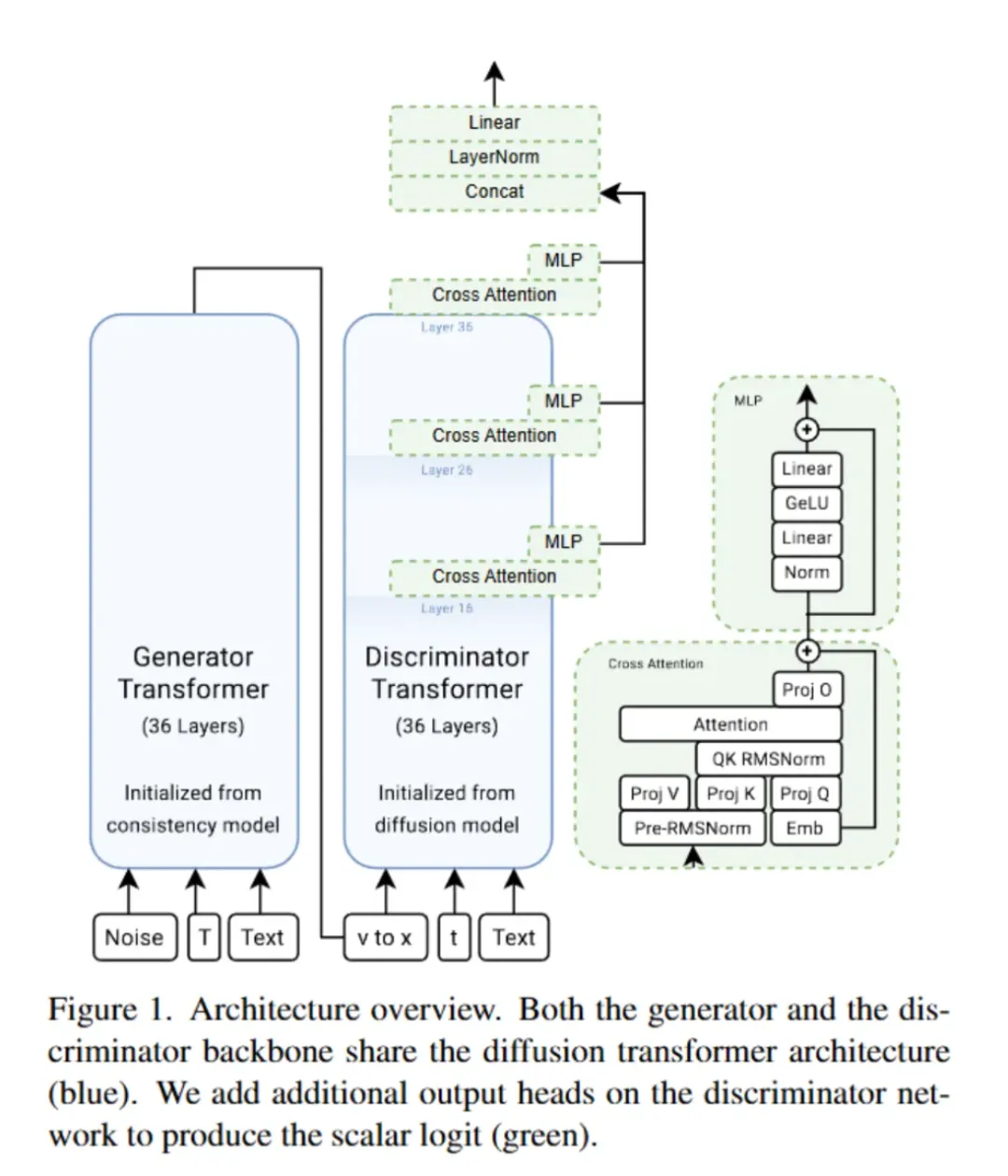
首先,论文利用预训练的扩散模型(如 diffusion transformer,DiT)对 GAN
的生成器和判别器进行初始化。相比 UFO-Gen 使用的 1B 卷积网络,APT 使用了 8B 的
Transformer,判别器的性能更强。
在训练开始前,先通过 LCM 之类的确定性蒸馏方法(Deterministic methods),对生成器进行初始化。此时生成器虽然一步生成比较模糊,但是是个好的开始,后续会用对抗训练增加生成的质量。而判别器则用原始的预训练模型进行权重初始化,因为作者发现使用原扩散模型权重初始化比用蒸馏模型权重效果更好。
模型的训练遵循对抗优化的思路,在 min - max 博弈中交替训练生成器和判别器。生成器努力生成能欺骗判别器的样本,判别器则尽力区分真实样本和生成样本。从而让生成器的分布逐渐接近真实分布。
GAN 非常难训练且容易 mode collaps,为了稳定训练过程,还引入一个近似 R1 正则化损失(R1
不支持 FSDP、checkpointing、flash attention 这些,所以文章里做了一个近似
R1,同样可以达到目标)。
在这样的对抗训练过程中,生成器不断优化,学习生成更逼真的样本。经过训练后,最终的一步生成任务由 GAN
的生成器执行。生成器在对抗训练中学习到了真实数据的分布特征,具备了直接生成样本的能力,而不再依赖扩散模型迭代去噪的过程。
3.1 (拓展)APT 论文原理详解
又是公式环节,不爱看的朋友就跳过吧!
Loss
GAN 的 loss 计算就是 min-max 博弈,生成器的 loss
是努力让生成的数据骗过判别器,也就是要最小化LG,让它以为是真的。判别器一方面是要真实的数据计算出来
loss 尽量小,另一方面生成器生成的数据要让 loss 尽量大(1-这部分 loss)小。所以最终的计算是:
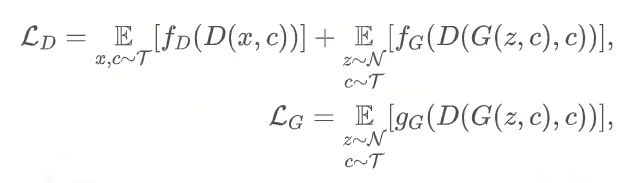

Generator
先使用蒸馏方法训练一个初步的模型(类似于一个 LCM),这个模型单步可以生成一个较为模糊的结果,可以用于进一步训练强化效果。接下来就在基于这个
LCM 进行对抗让它和真实数据对抗产生更强更真实的数据。

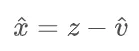
还是一个预测噪声的网络,只不过是一步去噪,而且这个会很模糊,不过没关系只是初始化。所以最终的 G 的初始化就是:
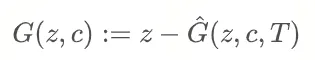
对抗训练时,只用 T(final timestep)作为输入。这相当于只看最初的去噪结果,因为是 one
step 生成,所以如果输入的时候 t=T 就相当于只做了第一步的去噪。只优化这个部分,让 t=T
时变成一个超级强的 GAN 生成器,本来模糊的图片可以变得很锐。
Discriminator
D 和 G 采用了相同结构的 DiT,但是从16、26、36层增加了 Qformer head。Qformer
就是一个 Q 是 learnable 的 transformer 模块,因为是 learnable
所以可以有效提取特征。
文章里提到,使用原扩散模型权重初始化比用蒸馏模型权重效果更好。猜测可能是因为蒸馏模型初始化的 D
太强了,都来自同一个模型,D 太懂 G 了,分布很好学到,G 无法与之抗衡?
Regularized Discriminator
原始的 R1 正则化是对鉴别器中针对真实数据 x 的梯度进行惩罚,也就是让它不要出现变化得特别剧烈。原始的
R1 要计算两次梯度:
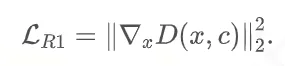

由于需要对 D 做 R1 regularization,但 R1 不支持 FSDP、checkpointing、flash
attention 这些工具,所以文章采取了一个近似 R1 的计算。近似后的 R1 其实就是在原始数据上加一个扰动,然后计算这个扰动带来的差,从而用这个来估算梯度,这样不需要在
backward 的时候计算两次梯度,于是上面那些工具都可以支持计算了。
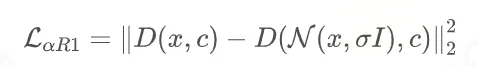
04
结语
知识蒸馏是一种有效的压缩模型的手段,而在文生图扩散模型领域里,通常用于步数的压缩。在 APT 这篇论文中提到的方法,使用真实的数据直接做对抗,并且是直接训练
1 step 的生成模型,模型加速改进到这一步,其实已经和教师模型几乎没有关系了(只用来初始化)和蒸馏这个概念也没有太大关系,但模型的加速发展历史和加速蒸馏有着莫大的联系的,故有此文。
| 








