| 编辑推荐: |
本文主要介绍了RAG与微调--本地部署大语言模型在车企OEM的效率提升用途相关内容。希望对你的学习有帮助。
本文来自于微信公众号焉知汽车 ,由火龙果软件Linda编辑,推荐。 |
|
一、背景
大语言模型LLM在车企OEM的一条应用线是用在产品上,也就是销售给客户的车辆成品之上。我们可称之为产品线应用。
我们梳理出的LLM产品线应用包括但不限于如下:
1、LLM用在车机上,就是人机智慧问答,这是比较触手可及的。
2、用在自动驾驶系统,比如理想VLA下一代自动驾驶架构,使用LLM作为基座模型,融合空间视觉和人类语言理解。
3、用在车辆智能故障诊断和故障预测。现代车辆,特别是融合计算机系统的软件定义车辆,完全可以说是轮子上的智能计算机,车主或者驾驶员作为用户,很难理解各种原理和术语,只能用模糊描述的人类语言描述问题,车载大语言模型再转换为内部的技术语言来定位和预测车辆故障,并且以人类语言反馈车主或驾驶员。
大语言模型用在车辆本身,最大的障碍还是输入数据的模态不同。经典的大语言模型的基本输入模态是文本化的人类自然语言。而车载数据则以图像视频,点云(激光雷达和超声波雷达),时间序列数据(主要来自TBOX采集车辆状态数据,车速,位置,油门开度,刹车开度等等),有时候还包括声音、振动、电压电流、浓度(比如燃油重卡的尿素浓度,氢能源重卡的氢气浓度)等等物理量。拟人化的文本数据输入属于少数派。
要让大语言模型从人类语言文本迁移到上述非语言的车载数据模态,就意味着对现有大语言模型进行重训练,或者重大结构调整,仅仅是微调是不够的。所谓微调fine
tuning,一般只能在同一模态内适应专门的数据集,而不能跨模态。
而对大语言模型进行重大结构调整后再重新训练,需要极大的算力、专业AI团队和大量资金投入,还有失败风险。存在失败风险也是为什么AI人自嘲自己的工作是炼丹,炼丹可能炼废。
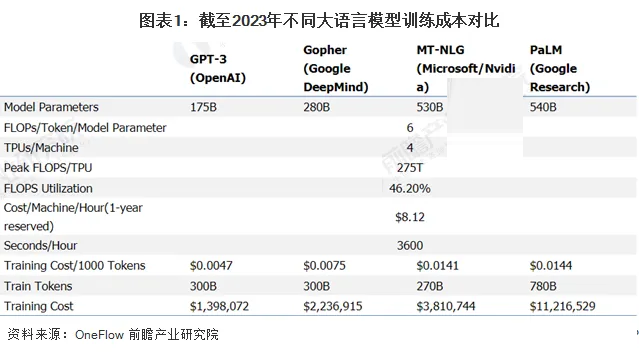
图1 以金钱计算的大语言模型训练成本,图片来自网络
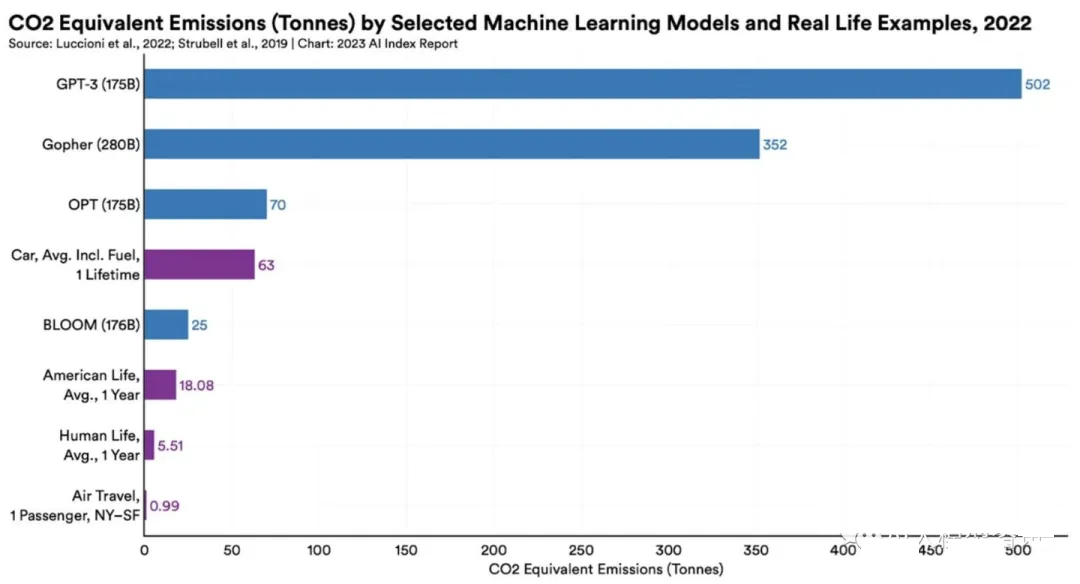
图2 以碳排放计算的大语言模型训练成本,图片来自网络
因此,只有极大研发投入的厂商才供得起对大语言模型进行模态迁移。这就像只有富国才有航空母舰一样。
大语言模型LLM在车企OEM的另一条应用线是用在企业内部,运行在服务器上,用于提高企业运行效率、企业研发效率和企业服务客户的效率。我们可以称之为效率线。
效率线上,主要是企业内部交流,以及企业和客户交流,其数据模态就主要以人类语言为主,而且一般都是文本化了的人类语言。这正是大语言模型的基本模态。
从数据模态匹配度来看,大语言模型在企业效率提升上的应用更直接且成本更低。
因此,大语言模型在车企OEM的应用,应该是产品线应用和效率线应用并举并重。
当然,人工智能和大语言模型在车辆生产和装配线上也有很多应用,本文限于篇幅暂不讨论,后续有机会单独展开这一话题。
二、选择标准--哪些用途值得投
首要需要问一个问题,哪一个更划算?是花钱买一个更好的AI还是自建部署AI系统?
回答也简单而明确:公有知识买AI,私有数据靠部署。
通用模型的强项在于公有知识,但它不知道企业的私有数据,而且出于保密目的,企业也不愿让自己的私有数据为人所知。而且出于成本考虑,通用模型的提供者,比如openAI,也不会为中小企业单独训练私有模型,因为经济上不划算。
举例,在自动驾驶轨迹规划的轨迹平滑化,我们可能用到贝塞尔曲线,那么贝塞尔曲线的原理和数学表达式和源代码,我们最好问公有AI。
但是,问企业内部是否已经购买基于英飞凌芯片的autosar CP软件包?是否已经到位和部署,还是停留在在谈判阶段?这种问题只能靠提取内部信息的私有化AI来回答,而任何公有AI无法回答。
按照这个选择标准,一种私有数据就意味着一种值得投入的用途。数据越重要,这种用途越重要。
比如笔者接触过的某一车企的创新工坊,是把电控的所有c语言嵌入式代码(git库)作为基础数据,喂给本地AI系统,Langchain+llama3实现,然后为开发人员生成可以copy的代码片段。效果是,原来要资深工程师才能胜任的开发,现在中级工程师也能承担。
三、用途列表
本文经过企业内部讨论各种堵点,把LLM对企业效率提升分为几大部分,包括但不限于如下:
1、一站式工作流程服务:
1.1 最恰当接口人的查询:出差找谁报销,谁是专利接口人,物料找谁领取,等等,一秒便知道;
1.2 各类模版及范文:专利模版和范文,评审文件模版和范文;
1.3 常用信息,比如公司全称,发票抬头、英文名称,详细地址等等。
2、知识共享(研发服务):
笔者认为,以知识共享为基础的研发服务,是LLM对企业效率提升的最重要部分。不夸张的说,员工在企业的生存能力,在于他或她取得工作必须知识的速度和质量。速度是指获取知识的时间成本和精力成本,最好不需要问人,问人就要花费问者和被问者的双重时间精力,最好问机器且光速可达。
质量是指获得的知识高度切题且有用,最好可以直接copy。
不仅希望它给我精确切题地找出来,还希望它给我解释清楚,还把来龙去脉各种渊源都讲清楚,而且不要啰嗦说无关的事情。最好了嚼碎了直接喂。
2.1 基于内部代码库的新开发代码生成
2.2 基于内部用例库的新测试用例的生成
2.3 内部知识文档的快速查询和综合解释,比如某一配件的装配文档,比如某一代码的说明文档,比如HIL硬件在环测试环境的搭建文档。特别的,供应商交付件的说明文档,比如动力链基于MBD模型开发的simulink模型说明文档,快速解释变量名和概念,并帮助读者
2.4 基于内部邮件系统(含内部聊天系统记录)读取所有邮件,得到的各类评审结论,立项结论,项目进展,供应商合同信息等等工作凭据信息,并解释术语和来龙去脉以及支撑原因。
2.5 从公司git代码仓和CI/CD持续集成持续交付系统,获取全部代码提交以及对应提交者审核者。LLM定期自动分析每个审核者和每个开发者的优缺点,给出拟人化语言的改进建议和改进范例。比如某一员工由于缺乏模块化思维,提交的代码总是圈复杂度特别高,不知道如何划分模块减少圈复杂度,本地AI系统会把改进建议和范例发送到他的邮箱。
3、员工衡量
3.1 员工考勤和差旅的拟人化总结;
3.2 员工交付件量化,代码提交量,图纸提交量,文档提交量,装配工作量,交付质量等等自动化报告。
这部分笔者的团队关注较少,所以所列不多。
4、客户服务
4.1 后市场服务:后市场服务系统致力于让售后维修数据价值最大化,细致记录车辆维修全流程数据和对应原因,进而归纳形成专属知识库。本地AI通过对数据的深度挖掘分析,能为每次售后维修自动推送相似案例,售后工程师能迅速获取类似维修案例及解决方案。
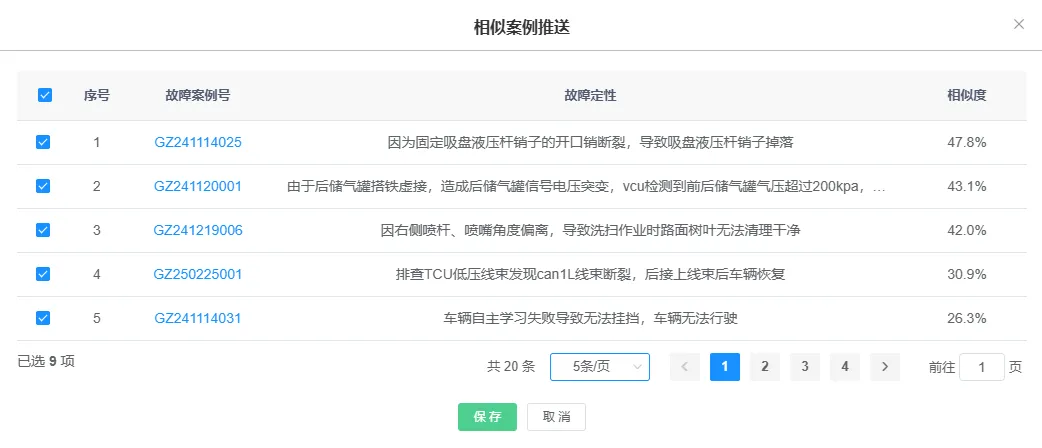
图3 相似案例聚类和推送,图片来自壹为汽车
另外,本文规划的后市场服务系统,还会综合行业、季节、车辆TBOX数据,以及服务网点折扣方案等等大数据信息,精准推送给车主或司机最优惠的维修和保养方案。最大化后市场给车企带来的经济效益。
比如,某燃油重卡企业,会根据车辆发动机运行状态判断润滑油剩余量,并及时推荐车主或司机最近的(最优路线规划)、最优惠(价格折扣金融)的服务站及时添加相关物料。
又比如,对新能源车,本地AI系统会读取BMS系统对电芯健康度的持续跟踪数据,对于荷电量特别低的电芯(简单说就是充不进去电的电芯),提示用户及时更换,并且会根据车辆位置和服务销售策略推荐最佳更换地点和价格。
4.2 营销宣传:自动化结合本企业信息和业界新闻,生成营销文案。这个可说的不多。
5、前沿技术情报综合和解释
5.1 基于arxiv预印本文库的论文爬虫和自动要点总结和技术原理诠释;
5.2 基于高价值微信公众号的技术文章(非新闻类)合集获取和自动要点总结和以及技术原理诠释;
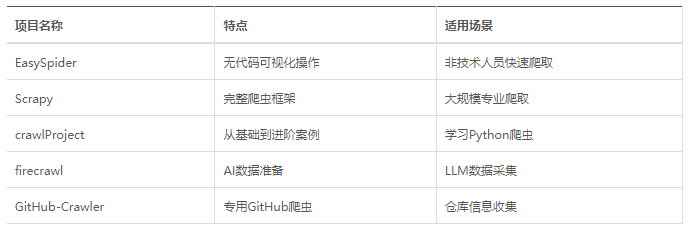
5.3 github爬虫(github提供官方API)和最新开源项目(自动驾驶,电控建模,车管平台,效率工具等等)爬取,根据项目readme和源码最准确的说明用途和优缺点。
常见爬虫总结如下:
四、方法论---如何让通用大语言模型适应私有数据
明确了价值和用途, 剩下的当然是如何做到。主要的方法是对已有大模型在本地进行RAG和微调。
RAG(检索增强生成)和微调(Fine-Tuning)是两种提升大语言模型(LLM)性能的主流方法,实际上,对于中小企业,这也是唯二负担得起的本地化私有LLM部署和调整的方法。
RAG的原理很简单,直观说,就是给问题添加附加信息(来自私有文档),把检索到的相关附加信息和原始问题作为一个整体,喂给训练好的AI来回答。附加信息就把私有文档数据带进去了。原始AI的任何权重和结构都不需要改变,所以成本最低。
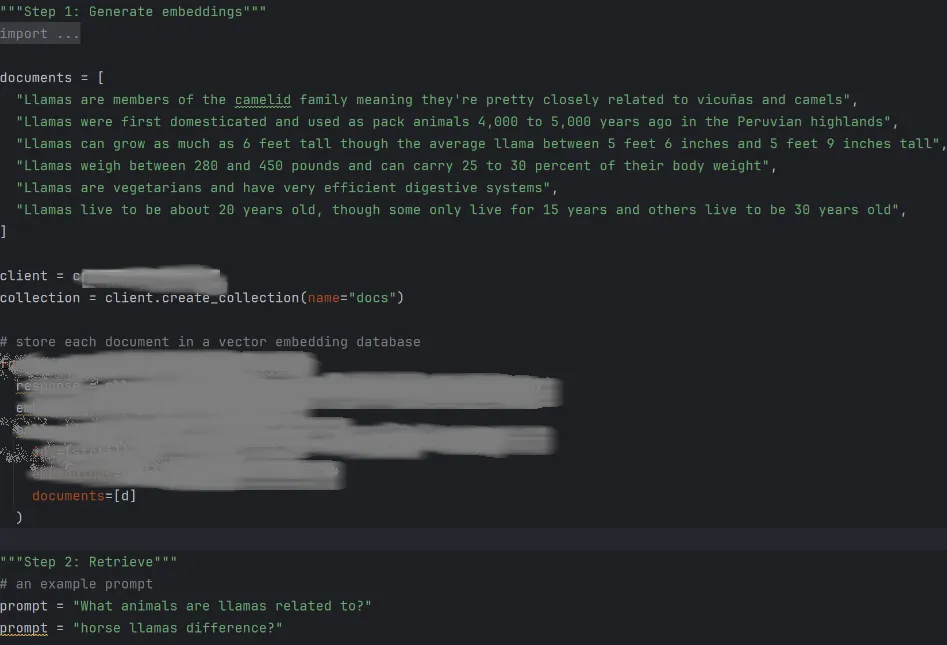
图4笔者服务器的RAG实验代码,IDE是PyCharm,模糊了一些核心代码
微调要复杂一些,之所以叫微调,是保持原始AI模型的权重都不变,但是为原始AI增加旁路网络,或者在尾部增加新的几层神经网络层,用需要适配的私有数据做训练数据来训练增加了旁路或者尾部层的AI模型,仅仅更新新增部分的权重来适应新数据。
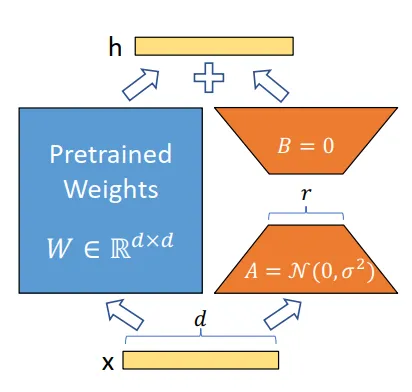
图5 旁路微调,学名叫Lora,图片来自网络
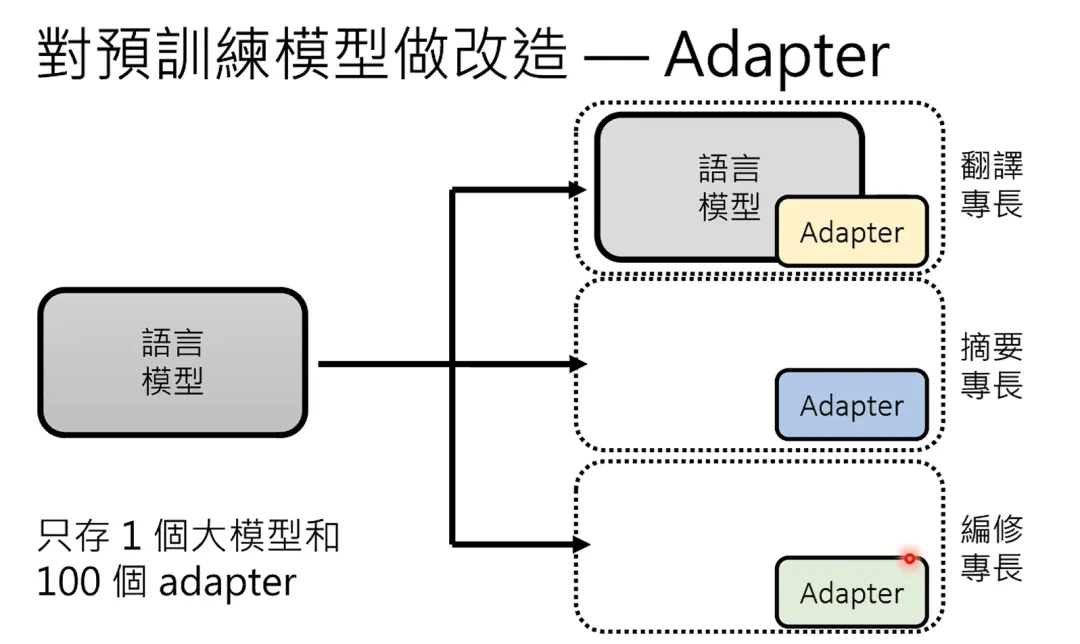
图6 尾部微调,图片来自网络
当然,当然除了RAG和微调两种,还有指令学习、提示学习等等技术帮助大模型学习新的数据,是一个非常活跃的、迅速发展的领域,本文不能穷尽。
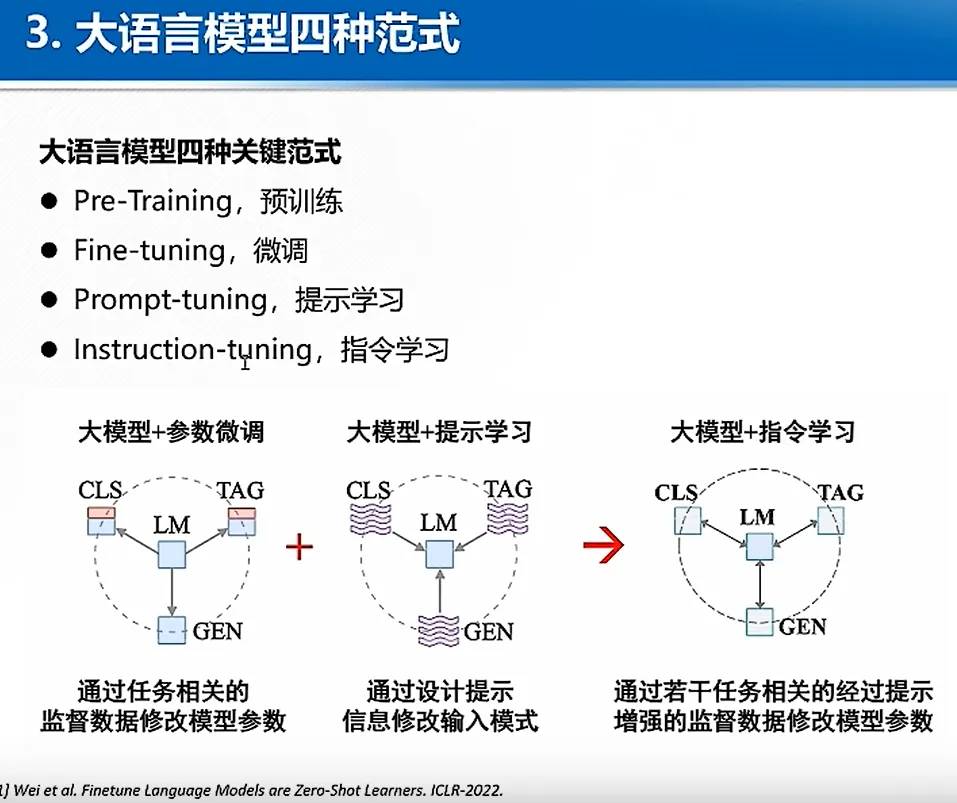
图7 大模型的常见范式,图片来自网络
1. 二者核心原理对比
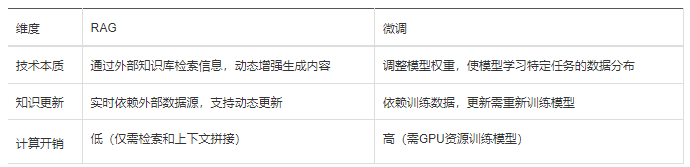
2. 二者效果对比
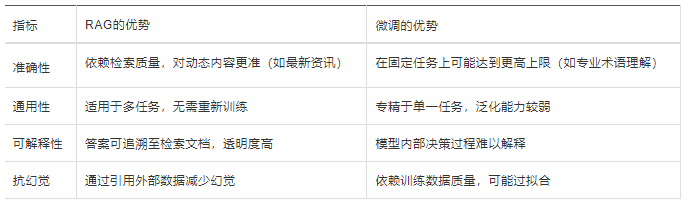
3. 适用场景建议
选择RAG:经常需要实时更新知识(如客服问答、新闻摘要),数据分散且无标注(企业文档库);
选择微调:任务模式固定且数据充足(如专业知识报告生成),数据不经常变而且数据很丰富,而且需深度适配领域术语或风格(法律合同分析)
4. 综合性能数据
混合方案效果最佳:据报道,RAG+微调联合使用可使准确率提升11%。
企业偏好:70%的案例中RAG因成本低、易维护成为首选 。
5、总结
RAG:灵活、低成本,适合动态知识需求。
微调:专精、高性能,适合稳定垂直领域。
最佳实践:根据任务复杂度、数据状态和预算权衡,或结合两者优势。
五、总结
高科技企业的人力成本占总运营成本的占比非常高。以笔者原来在某央企车企技术中心工作时,有权限接触内部报告的数据,人力成本占总成本的50%(一年总成本5个亿,其中2.5亿人力成本)。由于技术中心的运营成本不包括生产线的产线工人,基本是硕士及以上的研发人员,所以人力成本占比特别高。
根据行业研究,高科技企业(如IT、软件开发、人工智能等)人力成本通常占总运营成本的 40%-60%。部分技术密集型领域(如尖端研发或初创企业)可能高达
70%,因核心依赖高技能人才。
而具体到高科技车辆OEM(原始设备制造商)的人力成本占总运营成本的比例通常在 15%-30% 之间,具体比例受企业技术密集度、生产自动化水平和区域劳动力成本差异影响。
传统车的人力成本占比约20%-25%(如福特、通用),其中包括产线相对低的收入拉低了总体占比。
而新势力车企因研发投入高(占营收10%+),人力成本可能达25%-30%,其中同样包括产线相对低的收入拉低了总体占比。
未来趋势是随着AI和自动化普及,生产端人力成本占比或下降(产线机器人的普及),但高技能人才(如软件工程师,算法工程师,AI工程师等等)需求将持续推高研发人力成本。
大语言模型提升企业效率,本质其实就是在提高人力成本的使用效率和性价比,让高成本的高科技人才聚焦于高科技工作,人尽其用,物有所值。试想一下,一位百万年薪的总工花费一上午核心时间(头脑最清醒的时段)和一群高科技人才沟通对齐初中水平的琐事细节,口干舌燥,讲完后也没有更多精力从事复杂研究了。而这仅仅是因为高科技人才无法直观通俗地获取企业内部信息和知识,只好把总工当成人肉AI来用,这种低效场景当然会令CEO心碎。 | 







