| 编辑推荐: |
本文主要介绍了MOE架构相关内容。希望对你的学习有帮助。
本文来自于微信公众号程序猿阿三 ,由火龙果软件Linda编辑,推荐。 |
|
01 背景
混合专家模型 (MoE) 的理念起源于 1991 年的论文Adaptive Mixture of
Local Experts。这个概念与集成学习方法相似,旨在为由多个单独网络组成的系统建立一个监管机制。随着
Mixtral 8x7B 的推出, 首次提出一种称为混合专家模型 (Mixed Expert Models,简称
MoE) 的 Transformer 模型架构在LLM领域落地。
在传统机器学习时期,MoE可以参考Ensemble思想进行理解。Ensemble技术统合多个模型的预测结果,并给出一个最终答案,比如如果是一个分类任务,Ensemble模型内可能包含20个独立的分类模型,每个模型都会根据输入返回一个分类预测结果,Ensemble模型最后使用比如Majority
Vote得出最后的预测结果。与Ensemble一样,MoE会训练多个小模型并进行整合,但二者出发点不同:Ensemble统合所有小模型的意见,通过平均或Majority
Vote给出综合的答案,目的是使模型更加General和Robust;MoE将每个任务分配给特定的小模型,每个小模型都是解决某些特定问题的Expert,而MoE将会通过weight
function计算一个权重来将任务给到具体的模型来解决问题,将一个大的问题空间拆分成小的子空间交由不同Expert解决。
MoE模型是一种基于分而治之策略的神经网络架构,它将复杂的问题分解为多个子问题,每个子问题由一个独立的模型(称为专家)进行处理。这些专家模型可以是任意类型的神经网络,如全连接网络、卷积神经网络或循环神经网络等。MoE模型的核心在于如何有效地结合这些专家模型的输出,以得到最终的预测结果。在机器学习时代,也有类似的思想。
02 MOE网络架构
MOE的经典网络架构包含稀疏MoE层和门控网络两个关键部分组成:
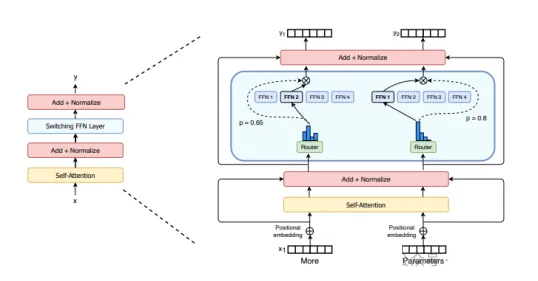
稀疏 MoE 层: 这些层代替了传统 Transformer 模型中的前馈网络 (FFN) 层。MoE
层包含若干“专家”(例如 8 个),每个专家本身是一个独立的神经网络。在实际应用中,这些专家通常是前馈网络
(FFN),但它们也可以是更复杂的网络结构,甚至可以是 MoE 层本身,从而形成层级式的 MoE 结构。
门控网络或路由:决定哪些令牌 (token) 被发送到哪个专家。例如,上图中,“More”这个令牌可能被发送到第二个专家,而“Parameters”这个令牌被发送到第一个专家。有时,一个令牌甚至可以被发送到多个专家。令牌的路由方式是
MoE 使用中的一个关键点,因为路由器由学习的参数组成,并且与网络的其他部分一同进行预训练。
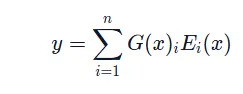
在混合专家模型 (MoE) 中,尽管较大的批量大小通常有利于提高性能,但当数据通过激活的专家时,实际的批量大小可能会减少。
总之, 在混合专家模型 (MoE) 中,我们将传统 Transformer 模型中的每个前馈网络
(FFN) 层替换为 MoE 层,其中 MoE 层由两个核心部分组成: 一个门控网络和若干数量的专家。
03 MOE网络架构优点
训练快:与稠密模型相比,参数更少, 预训练速度更快。混合专家方法适用于处理大规模数据集,能够有效地应对数据量巨大和特征复杂的挑战。这是因为它可以并行处理不同的子任务,充分利用计算资源,提高模型的训练速度。
推理快:与具有相同参数数量的模型相比,具有更快的 推理速度,由于只有少数专家模型被激活,大部分模型处于未激活状态,混合专家模型具有很高的稀疏性。这种稀疏性带来了计算效率的提升,因为只有特定的专家模型对当前输入进行处理,减少了计算的开销。
扩展性好:允许模型在保持计算成本不变的情况下增加参数数量,这使得它能够扩展到非常大的模型规模,如万亿参数模型。因为专家模型可以相互独立训练,可以复用训练资源。
多任务学习能力(强):MoE在多任务学习中具备很好的新能,MoE在多任务学习中具备很好的新能(比如Switch
Transformer在所有101种语言上都显示出了性能提升,证明了其在多任务学习中的有效性)。
04 MOE网络架构的劣势
虽然MOE架构有诸多优势,但是并不是尽善尽美,MOE架构有以下缺点:
训练稳定性方面:虽然 MoE 能够实现更高效的计算预训练,但它们在微调阶段往往面临泛化能力不足的问题,长期以来易于引发过拟合现象。
推理硬件要求方面: MoE 模型虽然可能拥有大量参数,但在推理过程中只使用其中的一部分,这使得它们的推理速度快于具有相同数量参数的稠密模型。然而,这种模型需要将所有参数加载到内存中,因此对内存的需求非常高。以
Mixtral 8x7B 这样的 MoE 为例,需要足够的 VRAM 来容纳一个 47B 参数的稠密模型。之所以是
47B 而不是 8 x 7B = 56B,是因为在 MoE 模型中,只有 FFN 层被视为独立的专家,而模型的其他参数是共享的。
模型复杂性方面:MoE的设计相对复杂,需要更多的工程努力来实现和优化。
05 MOE网络架构的特点
稀疏性: 采用了条件计算的思想。在传统的稠密模型中,所有的参数都会对所有输入数据进行处理。相比之下,稀疏性允许我们仅针对整个系统的某些特定部分执行计算。这意味着并非所有参数都会在处理每个输入时被激活或使用,而是根据输入的特定特征或需求,只有部分参数集合被调用和运行。
混合专家模型中令牌的负载均衡:所有的令牌都被发送到只有少数几个受欢迎的专家,那么训练效率将会降低。在通常的混合专家模型
(MoE) 训练中,门控网络往往倾向于主要激活相同的几个专家。这种情况可能会自我加强,因为受欢迎的专家训练得更快,因此它们更容易被选择。为了缓解这个问题,引入了一个
辅助损失,旨在鼓励给予所有专家相同的重要性。这个损失确保所有专家接收到大致相等数量的训练样本,从而平衡了专家之间的选择。
06 MOE网络架构应用
继MOE架构思想提出,很多MOE模型落地应用出来。
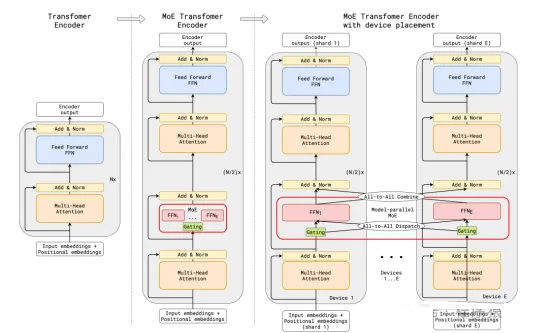
GShard
谷歌使用GShard尝试将 Transformer 模型的参数量扩展到超过 6000 亿。GShard
将在编码器和解码器中的每个前馈网络 (FFN) 层中的替换为使用 Top-2 门控的混合专家模型 (MoE)
层。
Switch Transformers
尽管混合专家模型 (MoE) 显示出了很大的潜力,但它们在训练和微调过程中存在稳定性问题。Switch
Transformers 是一项非常激动人心的工作,它深入研究了这些话题。作者甚至在 Hugging
Face上发布了一个1.6万亿参数的MoE,拥有 2048个专家,你可以使用transformers
库来运行它。Switch Transformers 实现了与 T5-XXL 相比 4 倍的预训练速度提升。
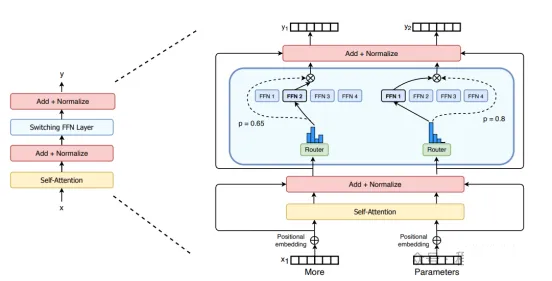
就像在 GShard 中一样,作者用混合专家模型 (MoE) 层替换了前馈网络 (FFN) 层。Switch
Transformers 提出了一个 Switch Transformer 层。
DeepSeek-MoE
国产开源的 MoE 模型,在 huggingface 上开源的模型包含164亿参数,共 64个路由专家、2个共享专家,每个令牌会匹配6个专家。
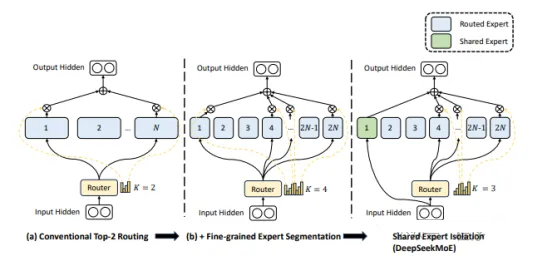
DeepSeek-MoE 引入了“细粒度/垂类专家”和“共享专家”的概念。
“细粒度/垂类专家” :通过细粒度专家切分 (Fine-Grained Expert Segmentation)
将一个 FFN 切分成 mmm 份。尽管每个专家的参数量小了,但是能够提高专家的专业水平。
“共享专家”:掌握更加泛化或公共知识的专家,从而减少每个细粒度专家中的知识冗余,共享专家的数量是固定的且总是处于被激活的状态。
LLaMA-MoE
LLaMA-MoE 是基于 LLaMA2 的一个 MoE 模型。类似MoEfication,LLaMA-MoE-v1
将 LLaMA2 模型中的前馈网络层 FFNs 分割为包含多个专家的 MoE,这导致LLaMA-MoE-v1中一个专家的参数比其他
MoE 模型要更小些。
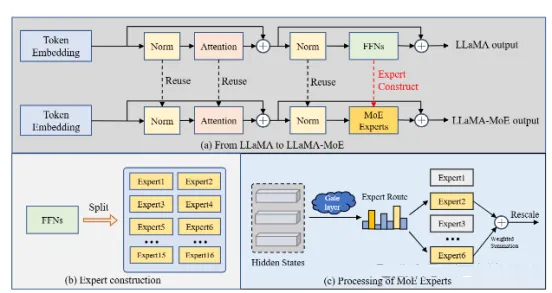
LLaMA-MoE-v1 实现了经典的 TopK 噪声门控,类似 Switch Transformer
中提出的单专家门控。
其他
除了上述的MoE模型应用,还有一众开源或者非开源的MoE模型。
开源:Megablocks、Fairseq、OpenMoE等,非开源有NLLB MoE,Mixtral
8x7B (Mistral)等。
07 总结
MoE为企业带来平衡算力成本和计算效率、加快万亿/十万亿模型参数规模扩展、提升大模型实用性等机遇。对于大模型部署成本有些吃力的情况,MOE提供另外一种思路,本身LLM发展道路上,一直有专而精的方向和大而全的方向。
| 





 订阅
订阅