| ����������Baqend
Tech Blog�������������Docker Swarm����������������ϲ���͵���Apache Storm��Ⱥ�������Ŀ������˼��Wolfram
Wingerath��֮����Ϊ��������Ȥ�������飬��Tech����������������ֻ����Һ����������ʲô��ʹ��������ʹ����������������ش�˵��
��Ϊһ��Docker��Docker Swarm�����֣��ҿ϶����к֪ܶ�����¡����������ҿ�������Docker�ϲ��𣨼�һ������������������������ϸ���Ȥ����ΪDocker�������칹�Ժ��������⡣һ��������Docker����Ϳ�����һ���������������MongoDB����Redis�ķ������ȶ�����Docker
Swarm��Ⱥ��������ͬ�����£�����Docker�������������Ķ����ַ�����Ⱥ�е�ij����������Docker���������������ȷ�ľ�������㱾��û�еĻ�����Ҳ���ý���������⣬��ΪֻҪ��ͬһDocker�����У���һ̨�����������������Ļ���������ͨ�������ڱ��̳������ᵽ�ģ�ֻҪ��ʹ����overlay���磬�ֲ�ʽ��װҲ��ʵ�֡�
�����ʼ������õ����ҵ�һЩ����������д���ǵ�ʱ���ҵ��Ժ�������˼�����ǰ������Ҫ��װ������һ��ӵ�г���16���ڵ��Apache
Storm��Ⱥ���¡���ʱ�кü������⣬���磬�Ҷ�AWS����̫��Ϥ����ǰ����OpenStack�ģ��������루Stormʹ�õģ�Netty�����������⣬�Լ�AWS���������������⡣��Щ������������OpenStack��ʱ���û���ֹ����������ǻ��������켰������Ԫȥ������ǡ���������Ϊ�������ʹ��Docker����Ͳ���������Щ�鷳����Ϊ��Ļ���ʼ����һ����Docker��
�ص��̳�����
Bagend Cloud����֧�ֲ�ѯ�����������ѯ�Ĺ��ܣ����ǽ�����Apache
Storm���������ӳٵ����ݡ��Ѿ��кü�����Ŀ��������ʵ����Docker�ϲ���������Storm ������wurstmeister/storm-docker��viki-org/storm-docker��������Խ�������������������ƺ���ʹ�����ø��ӡ���Ȼ����չ�Ժ��ײ����������Dz���Ĺؼ������Ǵ�һ��ʼ��ʹ��Dock
Swarm��Ҳ�ܸ��˵ؿ��������չ�����˳��������ϣ��ͨ����ƪ�̳����������ǵľ�����������Լ���������BaqendʵʱAPI����Ȥ����������һ��Dock
Swarm����Ϊ����ĺ�ţ����:-)
�������Swarm���֣��뿴���ǵ�AWS Meetup Docker�õ�Ƭ��
�������ļƻ�
����
���ȣ����ǽ�����һ���IJ����������������е�ÿһ���֡����ţ����ǻ��������TL;DR���������������������ʹ���������õ�ʵ�ýű�����Ȼ�����ǻ��������̵̳ĺ��IJ��֣�һ��������չʾDocker
Swarm��Ⱥ����ڵ�Apache Storm��Ⱥ�IJ�����̡���Ȼ������Ҳ����һЩ��Storm���ر��Dz������ֹԶ�̷������ϵ����ˣ��Լ�Swarm����������manager�ڵ����ֹ����Storm��Ⱥ�����漰���ij��湤����
����������
��ͼ�Dz���ļܹ�ͼ��
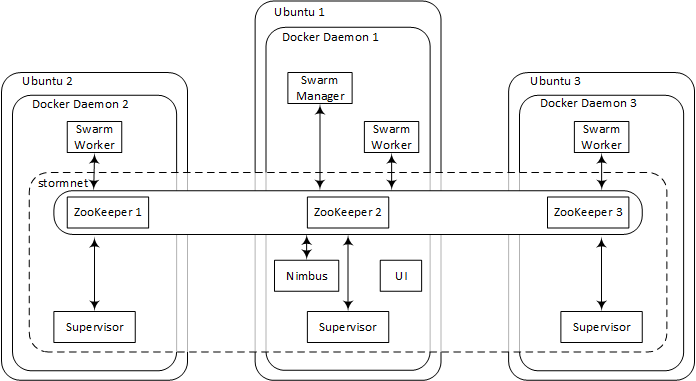
����̨����Ubuntu Server 14.04�Ļ�����ÿ̨��������һ��Docker�ػ����̣�ͬʱÿ̨��װ�м���������������ʼ���ã���ֻ�ܷ�������һ̨������Ubuntu
1�����ܴ�̶�����˵�������ֻ��һ��Docker�ػ����̡�
��װSwarm֮����ᴴ��һ���������磨stormnet����������ͬSwarm�ڵ���Docker�����Ϳ����ͨ���ˡ����գ��㽫������һ�������Storm��Ⱥ�������Ⱥʹ�����е�
ZooKeeper ��ͬЭ������ͨ��stormnetʵ�ֽڵ���ͨ�š���Ȼ���������ÿһ̨���������Էַ���Nimbus��UI������ᰲװ��manager�ڵ��ϣ�Ubuntu
1����
����������Ubuntu 1�����Ĺ������ʣ�������һ������IP�Ϳ��Ŷ˿�8080!����������Ϳ�����Storm������UI�ˡ�
��ϸ�̳�
���Ǹ�����Ubuntu�����������ֱ���zk1.cloud��zk2.cloud��zk3.cloud������ZooKeeper��������manager�ڵ�Ӹ�����˵��������ͬ�Ľ�ɫ������ʹ��manager.swarm��manager.swarm.baqend.com��Ϊmanager�ڵ��˽��IP��ַ����IP��ַ�����ܱ��̳��У�Ubuntu
1ʵ�����ǰ�����ZooKeeper 1������������ɫ������������Լ������ʱ��ʹ�ò�ͬ��������������ɡ���Github��check
out����̳̣���readme.me�У��������Լ������������Ҳ��滻���ǵ�ԭ��������Ȼ����Ϳ������ǵĴ���临��ճ�������ǽ�Ҫʹ�õ���dz������ˡ�
̫��������
������Щ���ſ����������˵������Ҳ����һЩ�ű�����Щ�Dz���Swarm��Storm�����ȫ���ű��ˡ����ǣ�Ϊ�˱������⣬���滹�ǻ���һ����ϸ�IJ��������ġ�
���ԣ�������ϸ��֮ǰ������һ�ݿ���ָ�ϣ�
1.����һ��Ubuntu 14.04������ �C ���dz�֮ΪUbuntu
1 �C Ȼ��ͨ��SSH��������Ȼ��ִ���������check outָ���еĽű�����װDocker��
sudo apt-get install git -y && \
cd /home/ubuntu/ && \
git clone https://github.com/Baqend/tutorial-swarm-storm.git && \
chmod +x tutorial-swarm-storm/scripts/* && \
cd tutorial-swarm-storm/scripts/ && \
sudo bash installDocker.sh && \
sudo usermod -aG docker ubuntu && \
sudo shutdown -h now |
2.�������Զ��ػ����ػ���ʱ�����ɿ��ա�
3.������̨��ոտ��չ��Ļ�����Ubuntu 2��Ubuntu 3����ʹ��һ���Զ���ű�����������Swarm
worker�ڵ㣺
#!/bin/bash
cd /home/ubuntu/ && rm -rf tutorial-swarm-storm && \
git clone https://github.com/Baqend/tutorial-swarm-storm.git && \
cd tutorial-swarm-storm/scripts/ && \
chmod +x ./* && \
./init.sh zk1.cloud,zk2.cloud,zk3.cloud |
ע�⣺����Ҫ�Ѷ��ŷָ������������滻�����Լ�����������
4.���������������������ã����б��еĵ�һ̨����zk1.cloudָ��Ubuntu1��ʣ�µ�zk2.cloud��zk3.cloud�ֱ�ָ��Ubuntu
2��Ubuntu 3������Ҫȷ��manager.swarm.baqend.com��manager.swarm�ֱ𱻽���ΪUbuntu
1�Ĺ���IP��ַ��˽��IP��ַ��
5.ȷ������֮����Ի�����ʣ���Ҫ�˿�2181��2888��3888
��ZooKeeper����2375 ��Docker Swarm����6627 (Storm��Զ�����˲��𣩡�Ϊ�˱�֤�ܴ��ⲿ����Storm
UI�������빫��manager.swarm.baqend.com:8080��
6.�������Ubuntu 1ͬʱ�������д��룬����ZooKeeper
ensemble��Swarm��Storm��
cd /home/ubuntu/tutorial-swarm-storm/scripts/ && \
ZOOKEEPER=zk1.cloud,zk2.cloud,zk3.cloud && \
sudo bash init.sh $ZOOKEEPER manager && \
. swarm.sh $ZOOKEEPER && \
. storm.sh $ZOOKEEPER 3 |
�ٴ����ѣ��ǵð����е��������滻Ϊ���Լ��ġ�
������Ӧ�ÿ��Է���http://manager.swarm.baqend.com:8080�µ�Storm
UI�ˡ�
���⣬������manager�ڵ�������
ʱ���㽫�ῴ��UI��Nimbus������ͬһ̨���������У���Swarm�������ͼ���������ڲ�ͬ�Ļ��������С�
����һ�Σ���һ������
�ã���������������һ����ϸ�IJ��衣Ϊ�˱����ظ��IJ��裬����ֻ��һ̨�����Ͻ�����Щ��������Ȼ��ػ������ա���������ͨ��������մ�������������
�����ǿ�ʼ�ɣ�
1.����Ubuntu 1����ΪUbuntu 14.04��������Ȼ��ͨ��SSH��������ִ��������䰲װDocker��
sudo apt-get update &&
sudo apt-get install apt-transport-https ca-certificates
&& sudo apt-key adv --keyserver hkp://p80.pool.sks-keyservers.net:80
--recv-keys 58118E89F3A912897C070ADBF76221572C52609D \
&& echo "deb https://apt.dockerproject.org/repo ubuntu-trusty main"
| sudo tee -a /etc/apt/sources.list.d/docker.list \
&& sudo apt-get update
&& sudo apt-get purge lxc-docker
&& sudo apt-cache policy docker-engine \
&& sudo apt-get update -y &&
sudo apt-get install -y linux-image-extra-$(uname -r) apparmor docker-engine git make \
&& sudo usermod -aG docker $(whoami)
|
������Docker��װ��ϸ����Կ����
����Docker��ͨ��һ��key�ļ�ȥʶ��ͬ��docker�ػ����̵ģ�����ڿ���֮ǰ������Ҫֹͣdocker�ػ����̣�ɾ�����key�ļ�������Docker�������һ���µ�Key�ļ������ػ�֮ǰ�ǵÿ��ա�
sudo service docker stop \
&& sudo rm /etc/docker/key.json |
ע�⣺����㲻�ڿ���֮ǰɾ�����Key�ļ��������и�������������ɵĻ�������ӵ��ͬ����ʶ������������Swarm��ȺһƬ�ǽ塣
3.�������ֻ ��Ҫ��ͬһ��������һ������������������´�boot��ʱ����ΪSwarm
worker��Ϊ�ˣ��������ı��༭��������nano������һ���ļ� /etc/init.sh��
���ţ����Ǹ������д��룬�����棺
#!/bin/bash<br>
# first script argument: the servers in the ZooKeeper
ensemble:<br>
ZOOKEEPER_SERVERS=$1</p>
<p class="artcon"> # second script argument: the role of this node:<br>
# ("manager" for the Swarm manager node; leave
empty else)<br>
ROLE=$2</p>
<p class="artcon"> # the IP address of this machine:<br>
PRIVATE_IP=$(/sbin/ifconfig eth0 | grep 'inet addr:'
| cut -d: -f2 | awk '{ print $1}')</p>
<p class="artcon"> # define label for the manager node:<br>
if [[ $ROLE == "manager" ]];then LABELS="--label
server=manager";else LABELS="";fi<br>
# define default options for Docker Swarm:<br>
echo "DOCKER_OPTS=\"-H tcp://0.0.0.0:2375
\<br>
-H unix:///var/run/docker.sock \<br>
--cluster-advertise eth0:2375 \<br>
$LABELS \<br>
--cluster-store \<br>
zk://$ZOOKEEPER_SERVERS\"" \<br>
| sudo tee /etc/default/docker</p>
<p class="artcon"> # restart the service to apply new options:</p>
<p class="artcon"> sudo service docker restart</p>
<p class="artcon"> echo "let's wait a little..."<br>
sleep 30</p>
<p class="artcon"> # make this machine join the Docker Swarm cluster:<br>
docker run -d --restart=always swarm join --advertise=$PRIVATE_IP:2375
zk://$ZOOKEEPER_SERVERS<br> |
4.���ڣ�����Ҫ�ػ��ˡ�
���ſ���һ�¡�
5.���ڣ�ͨ�����յľ�������������̨������Ubuntu 2��Ubuntu
3����ʹ������������Ϊ��ʼ/�Զ���ű���
#!/bin/bash<br>
/bin/bash /etc/init.sh \<br>
zk1.cloud,zk2.cloud,zk3.cloud<br> |
ע�⣺�����ʹ�õ���OpenStack�������ű����Լ�Ϊ�Զ���ű����������AWS����Ӧ��Ϊ�û����ݡ�
6.�����Ѿ����չ��Ļ�����Ubuntu 1�������ӻ���������ִ�����´��룺
/bin/bash /etc/init.sh \<br>
zk1.cloud,zk2.cloud,zk3.cloud \<br>
manager<br> |
����ڻ����Ͻ���һ��Swarm worker������֮ΪSwarm��������
7.���������������������ã����б��еĵ�һ��������zk1����ָ��Ubuntu1�ϵĹ�������ʣ�µ�����������zk2����zk3����ָ��������̨�ո������Ļ�������Ubuntu
2��Ubuntu 3������Ҫȷ��manager.swarm.baqend.com��manager.swarm�ֱ𱻽���ΪUbuntu�Ĺ���IP��ַ��˽��IP��ַ��
8.�����ɰ�ȫ���ã�ʹ�˿�2181��2888��3888 ��ZooKeeper����2375
��Docker Swarm����6627 (Storm, Զ�����˲����ϵĻ������Ի�����ʡ������ϣ������ʵ�ִ��ⲿ����Storm
UI����ô����Ҫ����manager.swarm.baqend.com:8080��
��֤�漣��ʱ�̵��ˣ�
����Swarm��Ⱥ
���һ��˳������ô�������Ѿ�������̨Ubuntu��������ÿ�����涼������һ��Docker�ػ����̡�����ͨ��˽�������е�zk1.cloud��manager.swarm����Ubuntu
1������Ҳ���Դ��ⲿͨ��manager.swarm.baqend.com��������8080�˿ڣ����ʡ�����һֱ����̨���������ڣ����ң������ڿ�ʼ����������Ψһ��Ҫ���ʵĻ�����Ϊ�˱�֤Swarm�ڵ�֮���Э��ͨ����������Ҫ����ZooKeeper
ensemble��Swarm��������
1.ͨ��SSH����Ubuntu1�����ſ��ټ��һ�顣���Docker��װ��ȷ���������д��������ʾ��һ�����������е�Docker�������б���ֻ�����Swarm�ģ���
2.�������ǿ�������ķ�����ÿ̨����������һ��ZooKeeper�ڵ㣺
docker -H tcp://zk1.cloud:2375 run -d --restart=always
\
-p 2181:2181 \
-p 2888:2888 \
-p 3888:3888 \
-v /var/lib/zookeeper:/var/lib/zookeeper \
-v /var/log/zookeeper:/var/log/zookeeper \
--name zk1 \
baqend/zookeeper zk1.cloud,zk2.cloud,zk3.cloud 1
docker -H tcp://zk2.cloud:2375 run -d --restart=always
\
-p 2181:2181 \
-p 2888:2888 \
-p 3888:3888 \
-v /var/lib/zookeeper:/var/lib/zookeeper \
-v /var/log/zookeeper:/var/log/zookeeper \
--name zk2 \
baqend/zookeeper zk1.cloud,zk2.cloud,zk3.cloud 2
docker -H tcp://zk3.cloud:2375 run -d --restart=always
\
-p 2181:2181 \
-p 2888:2888 \
-p 3888:3888 \
-v /var/lib/zookeeper:/var/lib/zookeeper \
-v /var/log/zookeeper:/var/log/zookeeper \
--name zk3 \
baqend/zookeeper zk1.cloud,zk2.cloud,zk3.cloud 3 |
ͨ����ȷ˵��-H�������������ǿ����ڲ�ͬ������������ZooKeeper������-p�����ZooKeeperĬ����Ҫ����Щ�˿ڡ�����-v����ͨ����ZooKeeperʹ�õ��ļ���ӳ�䵽��Ӧ�������ļ��У������ڷ�����������������Ȼ���������ԡ��Զ��ŷָ����������б�֪ͨZooKeeper��һ����������Щ�������������е�ÿ���ڵ㶼�����⡣Ψһ�ı�������ZooKeeper��ID���ڶ�������������Ϊ����ÿ���������Dz�һ���ġ�
�����ʹ�����������������ZooKeeper�Ƿ�һ��������
docker -H tcp://zk1.cloud:2375 exec -it zk1 bin/zkServer.sh
status && \
docker -H tcp://zk2.cloud:2375 exec -it zk2 bin/zkServer.sh
status && \
docker -H tcp://zk3.cloud:2375 exec -it zk3 bin/zkServer.sh
status |
�����ļ�Ⱥһ��������ÿ���ڵ㶼��㱨���������ڵ㻹�Ǵӽڵ㡣
Now it��s time to start the Swarm manager: |
�����ǿ���Swarm��������ʱ���ˣ�
docker run -d --restart=always \
--label role=manager \
-p 2376:2375 \
swarm manage zk://zk1.cloud,zk2.cloud,zk3.cloud |
����Swarm��Ⱥ�������С��������DZ������һ�����Docker�ͻ��ˡ������ֻ�뱣֤֮�����е�Docker������䶼ָ��Swarm�����������������Ḻ���ų̣������Ҳ�Υ������Docker�ػ����̡�
cat << EOF | tee -a ~/.bash_profile
# this node is the master and therefore should be able
to talk to the Swarm cluster:
export DOCKER_HOST=tcp://127.0.0.1:2376
EOF
``` export DOCKER_HOST=tcp://127.0.0.1:2376 |
������λ�����ִ�У����ұ�֤�´����ǵ�¼������ʱ���ٴ�ִ�С�
<div class="se-preview-section-delimiter"></div>
|
##�����ȼ��
����һ�ж������������ˡ�����
<div class="se-preview-section-delimiter"></div>
docker info |
���һ��manager�ڵ��ϵļ�Ⱥ״̬����ῴ��3�������е�worker������������
<div class="se-preview-section-delimiter"></div>
Nodes: 3
docker1: zk1.cloud:2375
�� Status: Healthy
�� Containers: 3
�� Reserved CPUs: 0 / 1
�� Reserved Memory: 0 B / 2.053 GiB
�� Labels: executiondriver=native-0.2, kernelversion=3.13.0-40-generic,
operatingsystem=Ubuntu 14.04.1 LTS, server=manager,
storagedriver=devicemapper
�� Error: (none)
�� UpdatedAt: 2016-04-03T15:39:59Z
docker2: zk2.cloud:2375
�� Status: Healthy
�� Containers: 2
�� Reserved CPUs: 0 / 1
�� Reserved Memory: 0 B / 2.053 GiB
�� Labels: executiondriver=native-0.2, kernelversion=3.13.0-40-generic,
operatingsystem=Ubuntu 14.04.1 LTS, storagedriver=devicemapper
�� Error: (none)
�� UpdatedAt: 2016-04-03T15:39:45Z
docker3: zk3.cloud:2375
�� Status: Healthy
�� Containers: 2
�� Reserved CPUs: 0 / 1
�� Reserved Memory: 0 B / 2.053 GiB
�� Labels: executiondriver=native-0.2, kernelversion=3.13.0-40-generic,
operatingsystem=Ubuntu 14.04.1 LTS, storagedriver=devicemapper
�� Error: (none)
�� UpdatedAt: 2016-04-03T15:40:15Z |
����Ҫ����ÿ���ڵ��Status: Healthy��һ�С�����㷢�ֳ�����������״̬������Status:
Pending�������еĽڵ�û����ʾ��������ô��ʹ�����ط���û�б�����ҲӦ������������������������������
<div class="se-preview-section-delimiter"></div>
docker restart $(docker ps -a --no-trunc --filter "label=role=manager"
| awk '{if(NR>1)print $1;}') |
Ȼ���ټ��һ�Σ�����������ܻ�����һ��������Ϣ������������
<div class="se-preview-section-delimiter"></div> |
##����Storm��Ⱥ
����Swarm�Ѿ����������ˣ��㽫Ҫ����һ��������������Խ���е�Swarm�ڵ㣬Ϊ������Storm�齨��ת�������������Supervisor�ڵ㣨��Storm
workers��ɢ����Swarm��Ⱥ�е����нڵ㣬Nimbus��UI����manager�ڵ��ϣ�ÿ̨��������һ����
1.�ȴ�����������stormnet��
<div class="se-preview-section-delimiter"></div>
docker network create --driver overlay stormnet |
Ȼ��ͨ��Docker�����stormnet�Ƿ���ڣ�
<div class="se-preview-section-delimiter"></div>
docker network ls
2.����һ��һ��������Storm�����ÿ��Storm��ص���������һ��cluster=storm��ǣ��������ں���ɱ������Storm��Ⱥʱ�������ɱ����������
���ȣ�����UI
<div class="se-preview-section-delimiter"></div>
docker run \
-d \
--label cluster=storm \
--label role=ui \
-e constraint:server==manager \
-e STORM_ZOOKEEPER_SERVERS=zk1.cloud,zk2.cloud,zk3.cloud
\
--net stormnet \
--restart=always \
--name ui \
-p 8080:8080 \
baqend/storm ui \
-c nimbus.host=nimbus |
��������Nimbus��
<div class="se-preview-section-delimiter"></div>
docker run \
-d \
--label cluster=storm \
--label role=nimbus \
-e constraint:server==manager \
-e STORM_ZOOKEEPER_SERVERS=zk1.cloud,zk2.cloud,zk3.cloud
\
--net stormnet \
--restart=always \
--name nimbus \
-p 6627:6627 \
baqend/storm nimbus \
-c nimbus.host=nimbus |
Ϊ��ȷ����Щ��manager�ڵ������У����Ǽ���һ������������constraint:server==manager��
3.�����ڿ��Է���Storm UI�ˣ��ͺ���������manager�ڵ�������һ�����������manager�ڵ��и�����IP������˿�8080���ţ���Ϳ���������[http://manager.swarm.baqend.com:8080](http://t.umblr.com/redirect?z=http://manager.swarm.baqend.com:8080&t=YWFkOTgxYWRjYzIwYTllYTJkNjA0NTcxYjU4MWZmMWY4NzExMGNmMSxoVEVjU3FkZA==)ͨ�������������Storm��Ⱥ������Ŀǰ��û�������κ�supervisor�ڵ㡣
4.�������������������������supervisor��
<div class="se-preview-section-delimiter"></div>
docker run \
-d \
--label cluster=storm \
--label role=supervisor \
-e affinity:role!=supervisor \
-e STORM_ZOOKEEPER_SERVERS=zk1.cloud,zk2.cloud,zk3.cloud
\
--net stormnet \
--restart=always \
baqend/storm supervisor \
-c nimbus.host=nimbus \
-c supervisor.slots.ports=[6700,6701,6702,6703] |
��Ϊ��������ν�������������supervisor�ڵ㣬�������Dz��ü����κ����������������������ǣ�Ϊ�˷�ֹͬһ̨�����ϵ�������supervisor����������������һ��**affinity���**��affinity:role!=supervisor�������Ҫ�ø����supervior�������͵����Ӹ����Swarm
worker�ڵ㣨Ubuntu 4��Ubuntu 5�ȵȣ���
5.��һ��Storm UI��ȷ��������Supervisor�����С�
<div class="se-preview-section-delimiter"></div> |
##��Զ�̣����˲���
����ͨ����manager������ͬһ�����е�����һ̨װ��Docker�ػ����̵ķ������������������硣������Ĵ����У�������Ŀǰʹ�õ�Ŀ¼�У�����fatjar��һ����Ϊtopology.jar���ļ���
<div class="se-preview-section-delimiter"></div>
docker -H tcp://127.0.0.1:2375 run \
-it \
--rm \
-v $(readlink -m topology.jar):/topology.jar \
baqend/storm \
-c nimbus.host=manager.swarm \
jar /topology.jar \
main.class \
topologyArgument1 \
topologyArgument2 |
**ע�⣺**������������һ��Docker�������������ˣ�����ɾ��������������-H
tcp://127.0.0.1:2375������ȷ�����������㵱ǰʹ�õĻ����������ġ������Docker
Swarm�Լ������ţ�����Ϳ��ܻ�ʧ�ܣ���Ϊ�����������������Ͽ����Ҳ�����Ҫ�������ļ���
���⣬readlink -m topology.jar��Ϊtopology.jar����һ������·������Ϊ����֧�����·����������Ҳ����ֱ���ṩһ������·����
| <div
class="se-preview-section-delimiter"></div>
##Killing A Topology
<div class="se-preview-section-delimiter"></div>
|
##��ֹһ������
����ͨ����Storm web UI�����Ӷ���ֹһ�����ˣ�����Ҳ����ͨ������ķ�ʽ�������������е����˽���runningTopology��
<div class="se-preview-section-delimiter"></div>
docker run \
-it \
--rm \
baqend/storm \
-c nimbus.host=manager.swarm \
kill runningTopology |
�˴�������Ҫ��������-H ...����Ϊ���������Ƕ����ģ����������κ��ļ���
<div class="se-preview-section-delimiter"></div> |
##�ص�Storm��Ⱥ
����ÿ����Storm��ص���������һ��cluster=storm��ǩ������������������ֹ���е�������
div class="se-preview-section-delimiter"></div>
docker rm -f $(docker ps -a --no-trunc --filter "label=cluster=storm"
| awk '{if(NR>1)print $1;}')
��` |
��Ҫ���ǰ�ȫ�ԣ�
�����ڴ˽̳���ʾ���������Docker���ö�ڵ��ZooKeeper��Ϊ�˸߿����Ժ��ݴ�������һ���ֲ�ʽStorm��Ⱥ��Ϊ�˲�������̳̹��ָ��ӣ��������������TLS����Docker
Swarm�IJ��֡����������Docker Swarm���ڹؼ���ҵ��Ӧ���У������������������Щ����
Baqend������ʹ��Apache Storm�ģ�
��������Storm���������ṩ���ӳٵ�����ѯ�Ͳ�ѯ���棺
������ѯ
������APP����������ѯ��Apache Storm�ܽ������������ѯ���������д����������ҽ�������ȶԣ�ÿ��дһ������ʱ������ע���������ѯ����֮�ȶԡ���ȻStormһֱ�ڸ������в�ѯ�Ľ���������ܷ����µ����������µ�ƥ���ƥ�������������ڱ���շ�����ʱ��֪ͨ�㡣
��ѯ����
���ڲ�ѯ������˵����������Щ֪ͨ�������û���ʧЧ��Baqend Cloud��һ�κ������ȵ�TTL������һ����ѯ�����һ������������Զ��û���IJ�ѯ�����Ч��������Storm�����ǵ�ƥ�������ӳٽ�Ϊ�����룬������������ݵĻ�ȡ�ٶ�������ߡ� |





