| 以下为译文
作为一种灵活性极强的构架风格,时下微服务在各种开发项目中日益普及。在这种架构中,应用程序被按照功能分解成一组松耦合的服务,它们通过REST
APIs相互协作。通过这个设计原则,开发团队可以快速地不断迭代各个独立的微服务。同时,基于这些特性,很多机构可以数倍地提升自己的部署能力。
然而凡事都有两面性,当开发者从微服务架构获得敏捷时,观测整个系统的运行情况成为最大的痛点。如图1所示,多个服务工作联合对用户请求产生响应;在生产环境中,应用程序执行过程中端到端的视图对快速诊断并解决性能退化问题至关重要的,而应用中多达数十的微服务(每个还对应数百个实例)使得理解这点变得非常困难。信息是如何在服务中穿梭流动的?哪里是瓶颈点?如何确定用户体验的延迟是由网络还是调用链中的微服务引起?

与此同时,在云环境下,企业对基于微服务应用的性能分析工具的需求与日俱增,因此IBM Research正在尝试构建基于平台的实时的性能分析工具,它的性质类似于自动缩放和负载平衡等服务。通过捕获和分析应用中微服务的网络通信,服务按非侵入式的方式进行。在云环境中,服务分析需要处理海量来自实时租户应用的通信追踪,进一步发现应用程序拓扑结构,跟踪当服务通过网络微服务时的单个请求等。由于需要运行批处理和实时分析应用,所以Spark被采用。
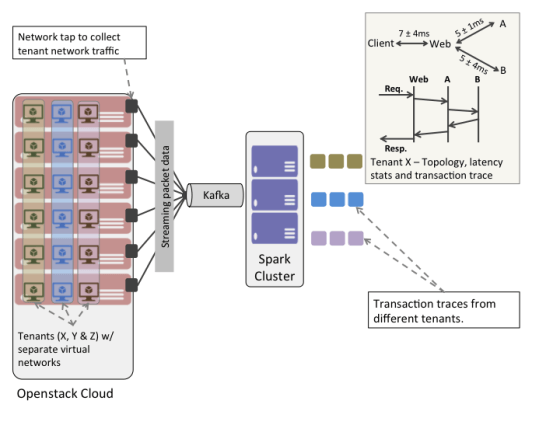
图2所示,这里设置了一个简单实验来描述如何利用Spark进行操作分析。整体的环境是一个OpenStack云,一组基于微服务的应用程序运行在不同租户的网络中,还有一个小型Spark集群。在每个Nova计算主机上安装的软件网络tap来捕获通过租户网络内的网络数据包。从租户网络中捕获的Wire-data被投入Kafka
bus。同时,在Spark应用中编写连接器,获取Kafka的包并对其进行实时分析。
因此,Spark应用被编写试图来回答下列问题:
1. 对终端用户的请求响应时,信息流是如何通过服务的?在IT Operational Analytics领域,这种分析操作通常被称为“事务跟踪”。
2. 在给定时间窗中,应用中各种微服务之间的调用/被调用关系是什么?
3. 在给定时间口中,应用中各种微服务的响应时间是多少?
根据以上问题,这里开发了2个Spark应用程序:1个实时事务跟踪的应用程序和1个批量分析应用来生成应用的通信图和延迟统计。前者基于Spark流抽象,后者则是一组由Spark作业服务器管理的批处理作业。
跟踪不同微服务之间的事务(或请求流)需要根据应用程序中不同微服务之间的请求-响应对创建因果关系。为了完全不受应用程序,这里将该应用当作一个黑盒。因此不妨认为应用程序中没有利用任何全局唯一请求标识符来跟踪跨微服务的用户请求。
为了追踪上文所提的因果关系,这里采用了Aguilera等人在2003 SOSP论文中提出的一种对黑盒分布式系统进行性能分析的方法,并做细微的修改。对于同步的网络服务,论文提出了一种nesting
algorithm,将分布式应用程序表示为一个图,各条边代表节点之间的相互作用。这个nesting algorithm会检查服务之间的调用时间戳,进一步推断其因果关系。简单地说,如果服务A调用服务B,而A在返回响应之前会和服务C通信,那么服务B呼叫C被认为是由A调用B引起的。通过分析一大组消息,这里可以得到服务间有统计性置信度的调用链,并消除可能性较小的选项。论文发表的原始算法旨在离线方式下操作大型的跟踪集。这个用例会修改该算法来操作数据包流的移动窗口,并慢慢逐步完善的拓扑结构推断。
图3显示了事务跟踪应用中作业的部分工作流程。图4显示了在一个租户应用中的事务跟踪,由Spark应用推导。Packet流到达块中,以PCAP格式封装。个体流从Packet流中提取并按滑动窗口分组,即dstreams。在给定的时间窗口内,HTTP请求和请求响应通过对比标准的5个tuple
提取(src_ip、src_port、dest_ip、dest_port, protocol),组成下一个DStream,然后到nesting
algorithm中实现的其余处理管道(未在图中显示)。事务跟踪应用输出结果会存储到时间序列数据存储区中(InfluxDB)。

第二个Spark应用是一个标准批量分析应用程序,在给定的时间窗口产生服务调用图以及调用延迟统计。应用作为标准批处理作业被提交到Spark作业服务器。如图5所示,批量分析应用从InfluxDB分离出独立事务跟踪,并将每个独立事务跟踪转换为<vertex,edge>对的列表。列表被聚集成两个RDDS,一个包含顶点列表,而另一个为边列表。顶点列表根据顶点名称进一步解析。最后,应用程序的调用图在有向图中计算,以及图中每条边延迟时间的统计数据。该图是应用程序时间演变图的一个实例,表示给定时间内的状态。图6和7显示调用图和租户应用延迟时间的统计数据,作为该批次的分析作业输出。
  
通过Spark平台,各种不同类型的分析应用可以同时操作,如利用一个统一的大数据平台进行批量处理、流和图形处理。下一步则是研究系统的可扩展性方面,如通过增加主机线性提升数据提取速度,并同时处理成千上万租户的应用踪迹。后续会继续汇报这方面的进展情况。
|





