| вЊЕу
бЇЯАШчКЮдквьЙЙЕФдЫааЛЗОГРяЪЙгУPipeline61ЙмРэЪ§ОнЙмЕР
Pipeline61ЕФШ§ИіжївЊзщМўЃКжДаав§ЧцЁЂЪ§ОнЗўЮёЃЌвдМАвРРЕКЭАцБОЙмРэЦї
здЖЏЛЏАцБОПижЦКЭвРРЕЙмРэЮЊЮвУЧЬсЙЉСЫРњЪЗПЩзЗзйадКЭПЩдйЯжад
БШНЯМИИіЪ§ОнЙмЕРПђМмЃЌШчCrunchЁЂPigЁЂCascadingЁЂFlumeКЭTez
АИР§бЇЯАЃКЪЙгУPipeline61ДІРэШ§жжВЛЭЌИёЪНЕФЪ§ОнЃЈCSVЁЂЮФБОКЭJSONЃЉ
етЦЊЮФеТЯШЪЧГіЯждкIEEE SoftwareдгжОЩЯЃЌIEEE SoftwareЪЧвЛБОЬсЙЉбЯНїПЦММзЪбЖЕФдгжОЁЃЦѓвЕзмЪЧдкПЩППадКЭСщЛюадЗНУцУцСйЬєеНЃЌITОРэКЭММЪѕСьЕМепвРРЕITзЈМвУЧРДЬсЙЉИпГЌЕФНтОіЗНАИЁЃ
Pipeline61ПђМмПЩвдгУгкЮЊвьЙЙЕФдЫааЛЗОГЙЙНЈЪ§ОнЙмЕРЁЃЫќПЩвджигУвбОВПЪ№дкИїИіЛЗОГРяЕФзївЕДњТыЃЌВЂЬсЙЉСЫАцБОПижЦКЭвРРЕЙмРэРДНтОіЕфаЭЕФШэМўЙЄГЬЮЪЬтЁЃ
баОПШЫдБПЊЗЂСЫДѓЪ§ОнДІРэПђМмЃЌШчMapReduceКЭSparkЃЌгУгкДІРэЗжВМдкДѓЙцФЃМЏШКРяЕФДѓЪ§ОнМЏЁЃетаЉПђМмзХЪЕНЕЕЭСЫПЊЗЂДѓЪ§ОнгІгУГЬађЕФИДдгЖШЁЃдкЪЕМЪЕБжаЃЌгаКмЖрЕФецЪЕГЁОАвЊЧѓНЋЖрИіЪ§ОнДІРэКЭЪ§ОнЗжЮізївЕНјааЙмЕРЛЏКЭМЏГЩЁЃР§ШчЃЌЭМЯёЗжЮігІгУвЊЧѓвЛаЉдЄДІРэВНжшЃЌШчЭМЯёНтЮіКЭЬиеїГщШЁЃЌЖјЛњЦїбЇЯАЫуЗЈЪЧећИіЗжЮіСїРяЮЈвЛЕФКЫаФзщМўЁЃВЛЙ§ЃЌвЊЖдвбОПЊЗЂКУЕФзївЕНјааЙмЕРЛЏКЭМЏГЩЃЌвдБужЇГжИќЮЊИДдгЕФЪ§ОнЗжЮіГЁОАЃЌВЂВЛЪЧвЛМўШнвзЕФЪТЁЃЮЊСЫНЋдЫаадквьЙЙдЫааЛЗОГРяЕФЪ§ОнзївЕМЏГЩЦ№РДЃЌПЊЗЂШЫдББиаыаДКмЖрНКЫЎДњТыЃЌШУЪ§ОндкетаЉзївЕМфСїШыСїГіЁЃGoogleЕФвЛЯюбаОПБэУїЃЌвЛИіГЩЪьЕФЯЕЭГПЩФмжЛАќКЌСЫ5%ЕФЛњЦїбЇЯАДњТыЃЌЖјЪЃЯТЕФ95%ЖМЪЧНКЫЎДњТыЁЃ
ЮЊСЫжЇГжЖдДѓЪ§ОнзївЕНјааЙмЕРЛЏКЭМЏГЩЃЌбаОПШЫдБЭЦМіЪЙгУИпМЖЕФЙмЕРПђМмЃЌШчCrunchЁЂPigКЭCascadingЕШЁЃетаЉПђМмДѓЖМЪЧЛљгкЕЅвЛЕФЪ§ОнДІРэдЫааЛЗОГЖјЙЙНЈЕФЃЌВЂвЊЧѓЪЙгУЬиЖЈЕФНгПкКЭБрГЬЗЖЪНРДЙЙНЈЙмЕРЁЃПіЧвЃЌЙмЕРгІгУашвЊВЛЖЯбнЛЏЃЌТњзуаТЕФБфИќКЭашЧѓЁЃетаЉгІгУЛЙгаПЩФмАќКЌИїжжвХСєЕФзщМўЃЌЫќУЧашвЊВЛЭЌЕФдЫааЛЗОГЁЃвђДЫЃЌЮЌЛЄКЭЙмРэетаЉЙмЕРБфЕУЗЧГЃИДдгКЭКФЪБЁЃ
Pipeline61ПђМмжМдкЮЊдквьЙЙЕФдЫааЛЗОГРяЮЌЛЄКЭЙмРэЪ§ОнЙмЕРМѕЩйОЋСІЕФЭЖШыЃЌЖјВЛашвЊжиаДдгаЕФзївЕЁЃЫќПЩвдНЋдЫаадкИїжжЛЗОГРяЕФЪ§ОнДІРэзщМўМЏГЩЦ№РДЃЌАќРЈMapReduceЁЂSparkКЭНХБОЁЃЫќОЁПЩФмжигУЯжгаЕФЪ§ОнДІРэзщМўЃЌПЊЗЂШЫдБОЭУЛгаБивЊжиаТбЇЯАаТЕФБрГЬЗЖЪНЁЃГ§ДЫжЎЭтЃЌЫќЮЊУПИіЙмЕРЕФЪ§ОнКЭзщМўЬсЙЉСЫздЖЏЛЏЕФАцБОПижЦКЭвРРЕЙмРэЁЃ
ЯжгаЕФЙмЕРПђМм
ДѓЖрЪ§гУгкЙЙНЈЙмЕРЛЏДѓЪ§ОнзївЕЕФПђМмЖМЪЧЛљгкЕЅвЛЕФДІРэв§ЧцЖјЙЙНЈЕФЃЈБШШчHadoopЃЉЃЌВЂЪЙгУСЫЭтВПЕФГжОУЛЏЗўЮёЃЈБШШчHadoopЗжВМЪНЮФМўЯЕЭГЃЉРДНЛЛЛЪ§ОнЁЃБэAБШНЯСЫМИжжзюЮЊживЊЕФЙмЕРПђМмЁЃ
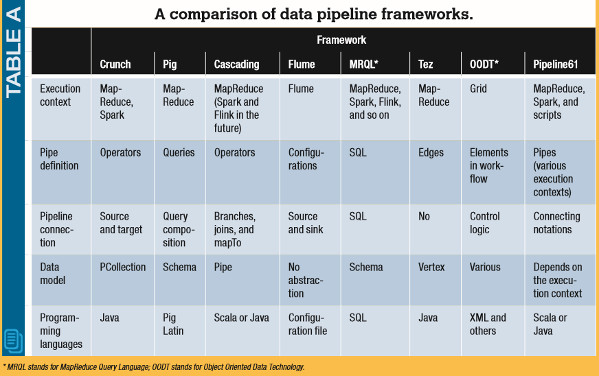
CrunchЖЈвхСЫздМКЕФЪ§ОнФЃаЭКЭБрГЬЗЖЪНЃЌгУгкжЇГжЙмЕРЕФаДШыЃЌВЂдкMapReduceКЭSparkЩЯдЫааЙмЕРзївЕЁЃPigЪЙгУСЫвЛжжЛљгкЪ§ОнСїЕФБрГЬЗЖЪНРДБраДETLЃЈГщШЁЁЂзЊЛЛЁЂМгдиЃЉНХБОЃЌВЂдкжДааЦкБЛзЊЛЛГЩMapReduceзївЕЁЃCascadingЮЊЙмЕРЬсЙЉСЫЛљгкВйзїЗћЕФБрГЬНгПкЃЌВЂжЇГждкMapReduceЩЯдЫааCascadingгІгУЁЃFlumeзюГѕЪЧЮЊЛљгкШежОЕФЙмЕРЖјЩшМЦЕФЃЌгУЛЇЭЈЙ§ХфжУЮФМўКЭВЮЪ§РДДДНЈЙмЕРЁЃMRQLЃЈMapReduceВщбЏгябдЃЉЪЧвЛжжЭЈгУЕФЯЕЭГЃЌгУгкдкИїжждЫааЛЗОГЩЯНјааВщбЏКЭгХЛЏЃЌШчHadoopЁЂSparkКЭFlinkЁЃTezЪЧвЛИіЛљгкгаЯђЮоЛЗЭМЕФгХЛЏПђМмЃЌЫќПЩвдгУгкгХЛЏЪЙгУPigКЭHiveБраДЕФMapReduceЙмЕРЁЃ
Pipeline61гыетаЉПђМмЕФВЛЭЌЕудкгкЃК
жЇГжЖдвьЙЙЕФЪ§ОнДІРэзївЕЃЈMapReduceЁЂSparkКЭНХБОЃЉНјааЙмЕРЛЏКЭМЏГЩЁЃ
жигУЯжгаЕФБрГЬЗЖЪНЃЌЖјВЛЪЧвЊЧѓПЊЗЂШЫдБбЇЯАаТЕФБрГЬЗЖЪНЁЃ
ЬсЙЉздЖЏЛЏЕФАцБОПижЦКЭвРРЕЙмРэЃЌОпБИРњЪЗПЩзЗзйадКЭПЩжиЯжадЃЌетаЉЖдгкЙмЕРЕФГжајПЊЗЂРДЫЕЪЧЗЧГЃживЊЕФЁЃ
гыPipeline61РрЫЦЃЌApache Object Oriented Data TechnologyЃЈOODTЃЉЪ§ОнеЄИёПђМмжЇГжШУгУЛЇДгвьЙЙЛЗОГжаВЖзНЁЂЖЈЮЛКЭЗУЮЪЪ§ОнЁЃгыPipeline61ЯрБШЃЌOODTЬсЙЉСЫИќОпЭЈгУадЕФШЮЮёЧ§ЖЏЙЄзїСїжДааЙ§ГЬЃЌПЊЗЂШЫдББиаыБраДГЬађРДЕїгУВЛЭЌЕФШЮЮёЁЃЯрЗДЃЌPipeline61зЈзЂгкгыЕБЧАЕФДѓЪ§ОнДІРэПђМмНјааЩюЖШМЏГЩЃЌАќРЈSparkЁЂMapReduceКЭIPythonЁЃOODTЪЙгУСЫЛљгкXMLЕФЙмЕРХфжУЃЌЖјPipeline61ЮЊИїжжБрГЬгябдЬсЙЉСЫБрГЬНгПкЁЃзюКѓЃЌOODTашвЊЮЌЛЄЪ§ОнМЏЕФвЛАуадаХЯЂКЭдЊЪ§ОнЁЃPipeline61ЮЊЙмЕРРяЕФIOЪ§ОнКЭзЊЛЛШЮЮёЬсЙЉСЫЯдЪНЕФРДдДаХЯЂЁЃвђДЫЃЌPipeline61дЩњЕижЇГжРњЪЗЪ§ОнЙмЕРЛђВПЗжЪ§ОнЙмЕРЕФжиаТЩњГЩКЭжиаТжДааЁЃ
вЛИігаШЄЕФР§зг
ЮвУЧЕФР§згЪЧвЛИіЯгвЩМьВтЯЕЭГЃЌЭМ1еЙЪОСЫИУЯЕЭГЕФЪ§ОнДІРэЙмЕРЁЃЯЕЭГЪеМЏРДздИїИіВПУХКЭзщжЏЕФЪ§ОнЃЌБШШчРДздеўИЎЕРТЗЗўЮёВПУХЕФЛњЖЏГЕзЂВсМЧТМЁЂРДздеўИЎЫАЮёВПУХЕФИіШЫЪеШыБЈИцЃЌЛђРДздКНПеЙЋЫОЕФКНГЬМЧТМЁЃРДздВЛЭЌЪ§ОндДЕФМЧТМПЩФмОпгаВЛЭЌЕФИёЪНЃЌШчCSVЁЂЮФБОЁЂJSONЃЌЫќУЧЕФНсЙЙЪЧВЛвЛбљЕФЁЃ

ЭМ1.ЯгвЩМьВтЯЕЭГЕФЪ§ОнДІРэЙмЕРЁЃРДздВЛЭЌВПУХКЭзщжЏЕФЪ§ОнПЩФмОпгаВЛЭЌЕФИёЪНКЭНсЙЙЁЃCSVБэЪОвдЖККХЗжИєЕФЪ§ОнжЕЃЌJSONБэЪОJavaScript
Object NotationЃЌMRБэЪОMapReduceЃЌHDFSЪЧHadoopЗжВМЪНЮФМўЯЕЭГЁЃ
дкЪ§ОнЙмЕРЕФИїИіНзЖЮЃЌВЛЭЌЕФЪ§ОнПЦбЇМвЛђЙЄГЬЪІУЧПЩФмЪЙгУВЛЭЌЕФММЪѕКЭПђМмРДПЊЗЂЪ§ОнДІРэзщМўЃЌБШШчIPythonЁЂMapReduceЁЂRКЭSparkЁЃвЛаЉвХСєЕФзщМўвВПЩвдЭЈЙ§BashНХБОЛђЕкШ§ЗНШэМўНјааМЏГЩЁЃЫљвдЃЌЙмРэКЭЮЌЛЄвьЙЙЛЗОГРяГжајБфЛЏЕФЪ§ОнЙмЕРЪЧвЛИіИДдгЖјГСУЦЕФШЮЮёЁЃЪЙгУаТПђМмЬцДњОЩПђМмЕФДњМлЪЧКмИпЕФЃЌЛђаэИќМгФбвдГаЪмЁЃдкзюЛЕЕФЧщПіЯТЃЌПЊЗЂШЫдБПЩФмашвЊжиаТЪЕЯжЫљгаЕФЪ§ОнДІРэзщМўЁЃ
СэЭтЃЌе§ШчЮвУЧжЎЧАЬсЙ§ЕФФЧбљЃЌЮЊСЫТњзуаТЕФЯЕЭГБфИќашЧѓЃЌЙмЕРгІгУГЬађашвЊБЃГжбнЛЏКЭИќаТЁЃР§ШчЃЌПЩФмЛсгааТЕФЪ§ОндДМгШыНјРДЃЌЛђепЯжгаЕФЪ§ОндДЕФИёЪНКЭНсЙЙЛсЗЂЩњБфИќЃЌЛђепЩ§МЖЗжЮізщМўРДЬсЩ§адФмКЭзМШЗадЁЃетаЉЖМЛсЕМжТЙмЕРзщМўЕФГжајБфЛЏКЭИќаТЁЃдкЙмЕРбнЛЏЙ§ГЬжаЬсЙЉПЩзЗзйадКЭПЩдйЯжадЛсГЩЮЊвЛИіЬєеНЁЃЙмЕРПЊЗЂШЫдБПЩФмЯыМьВщЙмЕРЕФРњЪЗЃЌгУгкБШНЯИќаТЧАКѓгаЪВУДВЛЭЌЁЃСэЭтЃЌШчЙћгаБивЊЃЌУПИіЪ§ОнДІРэзщМўгІИУФмЙЛЛиЙіЕНЩЯвЛИіАцБОЁЃ
Pipeline61
ЮЊСЫНтОіетаЉЬєеНадЮЪЬтЃЌPipeline61ЪЙгУСЫШ§ИіжївЊЕФзщМўЃКжДаав§ЧцДЅЗЂЦїЁЂМрПиЦїЃЌвдМАЙмЕРЙмРэЦїЁЃЪ§ОнЗўЮёЬсЙЉСЫЭГвЛЕФЪ§ОнIOВуЃЌгУгкЭъГЩПндяЕФЪ§ОнНЛЛЛвдМАИїжжВЛЭЌЪ§ОндДжЎМфЕФзЊЛЛЙЄзїЁЃвРРЕКЭАцБОЙмРэЦїЮЊЙмЕРРяЕФЪ§ОнКЭзщМўЬсЙЉСЫздЖЏЛЏЕФАцБОПижЦКЭвРРЕЙмРэЁЃPipeline61ЮЊПЊЗЂШЫдБЬсЙЉСЫвЛЬзЙмРэAPIЃЌЫћУЧПЩвдЭЈЙ§ЗЂЫЭКЭНгЪеЯћЯЂНјааЙмЕРЕФВтЪдЁЂВПЪ№КЭМрПиЁЃ
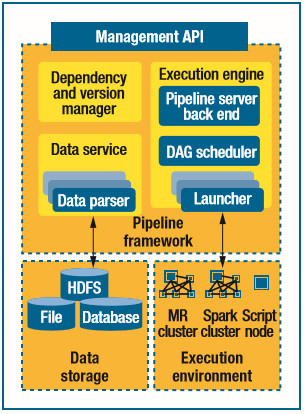
ЭМ2. Pipeline61МмЙЙЁЃPipeline61ПђМмжМдкЮЊдквьЙЙЕФдЫааЛЗОГРяЮЌЛЄКЭЙмРэЪ§ОнЙмЕРМѕЩйОЋСІЕФЭЖШыЃЌЖјВЛашвЊжиаДдгаЕФзївЕЁЃDAGБэЪОгаЯђЮоЛЗЭМЁЃ
PipeФЃаЭ
Pipeline61НЋЙмЕРзщМўБэЪОЮЊpipeЃЌУПИіpipeгавЛаЉЯрЙиСЊЕФЪЕЬхЃК
pipeЕФУћзжБиаыЪЧЮЈвЛЕФЃЌЖјЧввЊгыpipeЕФЙмРэаХЯЂОпгаЯрЙиадЁЃУћзжРяПЩвдАќКЌУќУћПеМфаХЯЂЁЃ
pipeЕФАцБОаХЯЂЛсздЖЏдіГЄЁЃгУЛЇПЩвджДаажИЖЈАцБОЕФpipeЁЃ
ЙмЕРЗўЮёЦїИКд№ЙмРэКЭЮЌЛЄpipeЁЃpipeашвЊжЊЕРЙмЕРЗўЮёЦїЕФЕижЗаХЯЂЃЌдкдЫааЦкМфЃЌЫќПЩвдЯђЙмЕРЗўЮёЦїЗЂЫЭЭЈжЊЯћЯЂЁЃ
ЪфШыКЭЪфГіURLРяАќКЌСЫpipeЕФIOЪ§ОнЫљЪЙгУЕФавщКЭЕижЗЁЃавщБэЪОГжОУЛЏЯЕЭГЕФРраЭЃЌШчHDFSЃЈHadoopЗжВМЪНЮФМўЯЕЭГЃЉЁЂJDBCЃЈJava
Database ConnectivityЃЉЁЂS3ЃЈAmazon Simple Storage ServiceЃЉЁЂЮФМўДцДЂКЭЦфЫћРраЭЕФЪ§ОнДцДЂЯЕЭГЁЃ
IOЪ§ОнЕФЪфШыИёЪНКЭЪфГіИёЪНжИУїСЫЪ§ОнЕФЖСШЁИёЪНКЭаДШыИёЪНЁЃ
дЫааЩЯЯТЮФжИУїСЫдЫааЛЗОГКЭдЫааПђМмЫљашвЊЕФЦфЫћаХЯЂЁЃ
дЫааЩЯЯТЮФгыЪ§ОнДІРэПђМмНєУмЯрЙиЁЃPipeline61ФПЧАгаШ§жжжївЊЕФдЫааЩЯЯТЮФЃК
SparkдЫааЩЯЯТЮФАќКЌСЫвЛИіSparkProcЪєадЃЌИУЪєадЮЊSparkSQLЬсЙЉСЫвЛИізЊЛЛКЏЪ§ЃЌгУгкНЋЪфШыRDDЃЈЕЏадЗжВМЪНЪ§ОнМЏЃЉзЊЛЏГЩЪфГіRDDЃЌЛђепНЋЪфШыDataFrameзЊЛЛГЩЪфГіDataFrameЁЃ
MapReduceдЫааЩЯЯТЮФАќКЌСЫвЛаЉНсЙЙЛЏЕФВЮЪ§ЃЌжИУїСЫMapReduceзївЕЕФMapperЁЂReducerЁЂCombinerКЭPartitionerЁЃПЩвдЪЙгУkey-valueЕФаЮЪНЬэМгЦфЫћВЮЪ§ЁЃ
shellдЫааЩЯЯТЮФАќКЌСЫвЛИіНХБОЮФМўЛђепФкСЊЕФУќСюЁЃPythonКЭRНХБОЪЧshell pipeзщМўЕФзгРраЭЃЌЫќУЧПЩвдЪЙгУИќЖргЩЪ§ОнЗўЮёПижЦЕФЪфШыКЭЪфГіЁЃshell
pipeЕФВЛзужЎДІдкгкЃЌПЊЗЂШЫдББиаыЪжЖЏЕиДІРэЪфШыКЭЪфГіЕФЪ§ОнзЊЛЛЁЃ
ЭМ3еЙЪОСЫШчКЮаДвЛИіМђЕЅЕФSparkPipeЁЃЛљБОЩЯЃЌПЊЗЂШЫдБжЛвЊЪЙгУSparkProcНгПкРДАќзАSpark
RDDКЏЪ§ЃЌШЛКѓЪЙгУSparkProcГѕЪМЛЏвЛИіSparkPipeЖдЯѓЁЃ

ЭМ3. ШчКЮаДвЛИіМђЕЅЕФSparkPipeЁЃПЊЗЂШЫдБЪЙгУSparkProcНгПкАќзАSpark RDDКЏЪ§ЃЌШЛКѓЪЙгУSparkProcГѕЪМЛЏвЛИіSparkPipeЖдЯѓЁЃ
Pipeline61ШУПЊЗЂШЫдБПЩвддкТпМВуУцНЋВЛЭЌРраЭЕФpipeЮоЗьЕиМЏГЩЕНвЛЦ№ЁЃЫќЬсЙЉСЫЗНЗЈЃЌгУгкНЋpipeСЌНгЦ№РДаЮГЩЙмЕРЁЃдкНЋpipeСЌНгЦ№РДжЎКѓЃЌЧАвЛИіpipeЕФЪфГіОЭБфГЩСЫЯТвЛИіpipeЕФЪфШыЁЃдкКѓУцЕФАИР§бЇЯАВПЗжЃЌЮвУЧЛсеЙЪОвЛИіИќОпЬхЕФР§згЁЃ
жДаав§Чц
жДаав§ЧцАќКЌСЫШ§ИізщМўЁЃ
ЙмЕРЗўЮёЦїАќКЌСЫЯћЯЂДІРэЦїЃЌгУгкНгЪеКЭДІРэРДздгУЛЇКЭШЮЮёЕФЯћЯЂЁЃгУЛЇПЩвдЭЈЙ§ЗЂЫЭЯћЯЂРДЬсНЛЁЂВПЪ№КЭЙмРэЫћУЧЕФЙмЕРзївЕКЭвРРЕЁЃдЫаажаЕФШЮЮёПЩвдЭЈЙ§ЗЂЫЭЯћЯЂРДБЈИцЫќУЧЕФдЫаазДЬЌЁЃдЫааЪБЯћЯЂвВПЩвдДЅЗЂвЛаЉЪТМўЃЌетаЉЪТМўПЩвддкдЫааЦкМфЕїЖШКЭЛжИДНјГЬЁЃ
гаЯђЮоЛЗЭМЕїЖШЦїБщРњЙмЕРЕФШЮЮёЭМЃЌВЂНЋШЮЮёЬсНЛЕНЯргІЕФдЫааЛЗОГЁЃвЛИіШЮЮёЛсдкЫќЕФЫљгаИИШЮЮёЖМБЛГЩЙІжДаажЎКѓНјШыздМКЕФжДааЕїЖШЦкЁЃ
ШЮЮёЦєЖЏЦїЮЊpipeЦєЖЏжДааНјГЬЁЃФПЧАЃЌPipeline61ЪЙгУСЫШ§жжРраЭЕФШЮЮёЦєЖЏЦїЃК
SparkЦєЖЏЦїЛсГѕЪМЛЏвЛИізгНјГЬЃЌзїЮЊжДааSparkзївЕЕФЧ§ЖЏНјГЬЁЃЫќЛсВЖзНдЫааЪБзДЬЌЕФЭЈжЊЯћЯЂЃЌВЂНЋЭЈжЊЗЂЫЭИјЙмЕРЗўЮёЦїЃЌгУгкМрПиКЭЕїЪдЁЃ
MapReduceЦєЖЏЦїЛсГѕЪМЛЏвЛИізгНјГЬЃЌгУгкЬсНЛгЩpipeжИЖЈЕФMapReduceзївЕЁЃдкНЋжДаазДЬЌЗЂЫЭИјЙмЕРЗўЮёЦїжЎЧАЃЌзгНјГЬЛсЕШД§зївЕжДааЭъБЯЃЌВЛЙмЪЧГЩЙІЛЙЪЧЪЇАмЁЃ
shellЦєЖЏЦїЛсДДНЈвЛЯЕСаНјГЬЭЈЕРЃЌгУгкДІРэshellНХБОЛђепгЩshell pipeЫљжИЖЈЕФУќСюЁЃдкетаЉНјГЬНсЪјЛђепШЮКЮвЛИіНјГЬЪЇАмжЎКѓЃЌЯрЙиЕФзДЬЌЯћЯЂНЋБЛЗЂЫЭИјЙмЕРЗўЮёЦїЁЃ
ПЊЗЂШЫдБПЩвдЪЕЯжаТЕФШЮЮёЦєЖЏЦїЃЌгУгкжЇГжаТЕФдЫааЩЯЯТЮФЃК
ПЩвдЪЙгУгЩжДааПђМмЃЈБШШчHadoopКЭSparkЃЉЬсЙЉЕФAPI
дквбОЦєЖЏЕФНјГЬРяГѕЪМЛЏзгНјГЬЃЌВЂжДааГЬађТпМЁЃ
РэТлЩЯЃЌШЮКЮПЩвдЭЈЙ§shellНХБОЦєЖЏЕФШЮЮёЖМПЩвдЪЙгУНјГЬЦєЖЏЦїРДжДааЁЃ
Ъ§ОнЗўЮё
УПИіpipeдкдЫааЦкМфЖМЪЧЖРСЂжДааЕФЁЃpipeИљОнЪфШыТЗОЖКЭИёЪНРДЖСШЁКЭДІРэЪфШыЪ§ОнЃЌВЂНЋЪфГіНсЙћаДШыжИЖЈЕФДцДЂЯЕЭГЁЃЙмРэИїжжIOЪ§ОнЕФавщКЭИёЪНЪЧМўПндяЕФЪТЧщЃЌЖјЧвШнвзГіДэЁЃЫљвдЃЌЪ§ОнЗўЮёЮЊПЊЗЂШЫдБДњРЭСЫетаЉЙЄзїЁЃ
Ъ§ОнЗўЮёЬсЙЉСЫвЛзщЪ§ОнНтЮіЦїЃЌЫќУЧИљОнИјЖЈЕФИёЪНКЭавщдкЬиЖЈдЫааЛЗОГРяЖСШЁКЭаДШыЪ§ОнЁЃР§ШчЃЌЖдгквЛИіSpark
pipeРДЫЕЃЌЪ§ОнЗўЮёЪЙгУдЩњЕФSpark APIРДМгдиЮФМўБОЮФЕНRDDЖдЯѓЃЌЛђепЪЙгУSparkSQL
APIДгJDBCЛђJSONЮФМўМгдиЪ§ОнЕНSpark DataFrameЁЃЖдгкPython pipeРДЫЕЃЌЪ§ОнЗўЮёЪЙгУPython
Hadoop APIМгдиCSVЮФМўЕФЪ§ОнЕНHDFSЃЌВЂзЊЛЛГЩPython DataFrameЁЃЛљБОЩЯЃЌЪ§ОнЗўЮёЪЧНЋЪ§ОнавщКЭИёЪНгГЩфЕНЬиЖЈдЫааЛЗОГЕФЪ§ОнНтЮіЦїЁЃ
ЮвУЧПЩвдРЉеЙЪ§ОнЗўЮёЃЌЪЕЯжВЂзЂВсаТЕФЪ§ОнНтЮіЦїЁЃвЛаЉЪ§ОнНтЮіЙЄОпЃЌШчApache TikaЃЌПЩвдзїЮЊЪ§ОнЗўЮёЕФВЙГфЪЕЯжЁЃ
вРРЕКЭАцБОЙмРэЦї
ЖдгкЙмЕРЙмРэдБРДЫЕЃЌЙмРэКЭЮЌЛЄЙмЕРЩњУќжмЦкЪЧвЛМўКмживЊЕФЪТЧщЃЌЭЌЪБвВКмИДдгЁЃ ЮЊСЫНтОіЙмЕРЙмРэЗНУцДцдкЕФЭДЕуЃЌвРРЕКЭАцБОЙмРэЦїПЩвдАяжњгУЛЇРДЮЌЛЄЁЂИњзйКЭЗжЮіЙмЕРЪ§ОнКЭзщМўЕФРњЪЗаХЯЂЁЃ
вРРЕКЭАцБОЙмРэЦїЮЊУПИіЙмЕРЮЌЛЄСЫШ§жжРраЭЕФаХЯЂЁЃЙмЕРжДааИњзйЙ§ГЬЮЊЙмЕРгІгУГЬађЕФУПвЛИідЫааЪЕР§ЮЌЛЄСЫвЛИіЪ§ОнСїЭМЁЃУПИіЭМЕФНкЕуЖМАќКЌСЫЪЕР§зщМўЕФдЊЪ§ОнЃЌБШШчЦєЖЏЪБМфЁЂНсЪјЪБМфКЭдЫаазДЬЌЁЃ
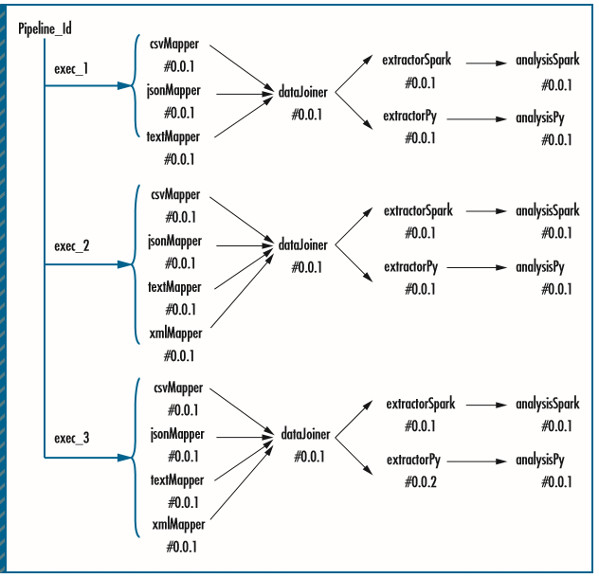
ЭМ4. дкPipeline61жаЮЌЛЄЕФРњЪЗКЭвРРЕаХЯЂЃЌЕквЛВПЗжЁЃЙмЕРжДааИњзйЙ§ГЬЮЊЙмЕРгІгУГЬађЕФУПвЛИідЫааЪЕР§ЮЌЛЄСЫвЛИіЪ§ОнСїЭМЁЃ
ЙмЕРвРРЕИњзйЙ§ГЬ(ЭМ5a)ЮЊУПИіЙмЕРзщМўЕФВЛЭЌАцБОЮЌЛЄзХРњЪЗдЊЪ§ОнЁЃЫќНЋУПИізщМўЕФвРРЕаХЯЂБЃДцГЩЪїзДНсЙЙЁЃБЃДцдкЪїжаЕФдЊЪ§ОнАќКЌСЫзюНќИќаТЕФУћзжЁЂАцБОЁЂзїепЁЂЪБМфДСЃЌвдМАдЫаавРРЕАќЁЃ
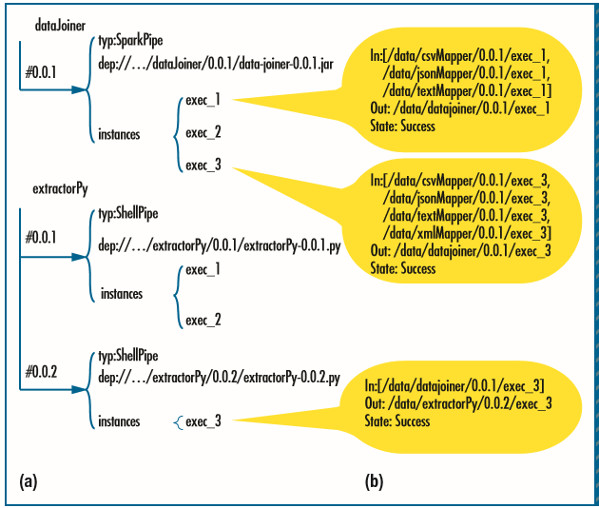
ЭМ5. дкPipeline61жаЮЌЛЄЕФРњЪЗКЭвРРЕаХЯЂЃЌЕкЖўВПЗжЁЃ(a) ЙмЕРвРРЕИњзйЙ§ГЬЮЊУПИіЙмЕРзщМўЕФВЛЭЌАцБОЮЌЛЄзХРњЪЗдЊЪ§ОнЁЃ(b)
Ъ§ОнПьееАќКЌСЫЙмЕРгІгУГЬађУПвЛИідЫааЪЕР§ЕФЪфШыЪфГіЮЛжУКЭбљБОЪ§ОнЁЃ
Ъ§ОнПьееЃЈЭМ5bЃЉАќКЌСЫЙмЕРгІгУГЬађУПвЛИідЫааЪЕР§ЕФЪфШыЪфГіЮЛжУКЭбљБОЪ§ОнЁЃ
Pipeline61гУЛЇПЩвдЭЈЙ§етаЉРњЪЗаХЯЂРДЗжЮіЙмЕРРњЪЗЃЌВЂЭЈЙ§жиаТдЫааОЩАцБОЕФЙмЕРРДжиаТЩњГЩРњЪЗНсЙћЁЃ
АИР§бЇЯА
вдЯТЕФАИР§бЇЯАеЙЪОСЫPipeline61ЕФаЇТЪКЭгХЪЦЁЃЪОР§ЪЙгУСЫРДздВЛЭЌзщжЏЕФШ§жжИёЪНЕФЪ§ОндДЃЌАќРЈCSVЁЂЮФБОКЭJSONЁЃСНзщЪ§ОнПЦбЇМвЪЙгУЩйСПЪжаДЕФMapReduceКЭPythonГЬађРДЖдећЬхЪ§ОнМЏНјааЗжЮіЁЃЮвУЧв§ШыСЫЮвУЧЕФЙмЕРПђМмЃЌгУгкздЖЏжДааЙмЕРШЮЮёКЭЙмЕРЙмРэЁЃЭМ6еЙЪОСЫЮвУЧЪЧШчКЮдкPipeline61РяжИЖЈЙмЕРЕФЁЃ

ЭМ6. дкPipeline61РяжИЖЈЙмЕРЁЃдкЯрЙиЕФАИР§бЇЯАРяЃЌСНзщЪ§ОнПЦбЇМвЪЙгУЩйСПЪжаДЕФMapReduceКЭPythonГЬађРДЖдећЬхЪ§ОнМЏНјааЗжЮіЁЃ
ЪзЯШЃЌЮвУЧжИЖЈСЫШ§жжЪ§ОнгГЩфЦїЁЊЁЊcsvMapperЁЂjsonMapperКЭtextMapperЁЊЁЊгУгкДІРэВЛЭЌИёЪНЕФЪфШыЪ§ОнЁЃЮвУЧжИЖЈСЫШ§ИіMapReduce
pipeЃЌВЂНЋШ§жжmapperЗжБ№зїЮЊЪ§ОнНтЮіЦїДЋЕнНјШЅЁЃ
НгЯТРДЃЌЮвУЧЪЙгУRDDКЏЪ§DataJoinerProcжИЖЈСЫвЛИіНазїdataJoinerЕФSpark
pipeЃЌгУгкзщКЯШ§жжmapperЕФЪфГіНсЙћЁЃ
зюКѓЃЌЮвУЧжИЖЈСЫСНзщЗжЮіpipeзщМўЃЌДгdataJoinerФЧРяЯћЗбЪфГіНсЙћЁЃвђЮЊУПИіЗжЮіЗжжЇЙизЂВЛЭЌЕФЪфШыЬиеїЃЌЮвУЧЮЊУПИіЗжЮізщМўЬэМгСЫвЛИіЬиеїГщШЁЦїЁЃШЛКѓЮвУЧНЋетСНИіЗжЮізщМўЪЕЯжЮЊPython
pipeКЭSpark pipeЁЃзюКѓЃЌЮвУЧЪЙгУСЌНгВйзїНЋетаЉpipeСЌНгдквЛЦ№ЃЌзщГЩСЫећЬхЕФЪ§ОнСїЁЃ
дкетИіГЁОАРяЃЌШчЙћЪЙгУЯжгаЕФЙмЕРПђМмЃЌБШШчCrunchКЭCascadingЃЌФЧУДПЊЗЂШЫдБашвЊжиаТЪЕЯжЫљгаЕФЖЋЮїЁЃетбљзіДцдкЗчЯеЃЌвВЗЧГЃКФЪБЁЃЫќВЛНіЖджигУвбгаЕФMapReduceЁЂPythonЛђshellНХБОГЬађдьГЩЯожЦЃЌЖјЧввВЖдЪ§ОнЗжЮіПђМмЃЈШчIPythonКЭRЃЉЕФЪЙгУдьГЩдМЪјЁЃ
ЯрЗДЃЌPipeline61зЈзЂгкЙмРэКЭЙмЕРЛЏвьЙЙЕФЙмЕРзщМўЃЌЫљвдЫќПЩвдЯджјЕиМѕЩйМЏГЩаТОЩЪ§ОнДІРэзщМўЫљашвЊЕФЭЖШыЁЃ
ЙмЕРКѓајЕФПЊЗЂКЭИќаТвВЛсДгPipeline61ЕФАцБОКЭвРРЕЙмРэжаЛёЕУКУДІЁЃР§ШчЃЌШчЙћПЊЗЂШЫдБЯывЊИќаТвЛИізщМўЃЌЫћУЧПЩвдДгЪ§ОнПьееРњЪЗжаЛёЕУзщМўзюаТЕФЪфШыКЭЪфГібљБОЁЃШЛКѓЃЌЫћУЧЛљгкбљБОЪ§ОнЪЕЯжКЭВтЪдаТЕФГЬађЃЌШЗБЃаТАцБОзщМўВЛЛсЖдЙмЕРдьГЩЦЦЛЕЁЃ
дкНЋИќаТЙ§ЕФзщМўЬсНЛЕНЩњВњЛЗОГжЎЧАЃЌПЊЗЂШЫдБПЩвдЮЊаТзщМўжИЖЈвЛИіаТЕФЙмЕРЪЕР§ЃЌВЂНЋЫќЕФЪфГіНсЙћгыЩњВњЛЗОГЕФАцБОНјааБШНЯЃЌЖде§ШЗадНјааЫЋжиМьВщЁЃГ§ДЫжЎЭтЃЌШчЙћаТзщМўдкВПЪ№жЎКѓГіЯжДэЮѓЃЌЙмЕРЙмРэЦїПЩвдКмШнвзЕиЛиЙіЕНЧАвЛИіАцБОЁЃЙмЕРЗўЮёЦїздЖЏЮЌЛЄзХУПИізщМўЕФРњЪЗЪ§ОнКЭвРРЕЃЌЫљвдПЩвдЪЕЯжЛиЙіЁЃ
етжжDevOpsЗчИёЕФжЇГжЖдгкЮЌЛЄКЭЙмРэЙмЕРгІгУГЬађРДЫЕЪЧКмгавтвхЕФЃЌЖјЯжгаЕФЙмЕРПђМмКмЩйЛсЬсЙЉетаЉжЇГжЁЃ
ВЛЙ§Pipeline61вВДцдкВЛзуЁЃЫќВЛМьВщИїИіЪ§ОнДІРэПђМмЪ§ОнНсЙЙЕФМцШнадЁЃЕНФПЧАЮЊжЙЃЌПЊЗЂШЫдБдкНјааЙмЕРПЊЗЂЪБЃЌБиаыЪжЖЏЖдУПИіpipeЕФЪфШыКЭЪфГіНјааЪжЖЏВтЪдЃЌШЗБЃвЛИіpipeЕФЪфГіПЩвдзїЮЊЯТвЛИіpipeЕФЪфШыЁЃЮЊСЫНтОіетИіЮЪЬтЃЌЮвУЧДђЫуЪЙгУЯжгаЕФНсЙЙЦЅХфЃЈschema-matchingЃЉММЪѕЁЃ
ЕБШЛЃЌдкЙмЕРдЫааЦкМфЃЌДѓВПЗжжаМфНсЙћашвЊБЛаДЕНЕзВуЕФЮяРэЪ§ОнДцДЂЃЈШчHDFSЃЉРяЃЌгУгкСЌНгВЛЭЌдЫааЩЯЯТЮФЕФpipeЃЌЭЌЪББЃжЄЙмЕРзщМўЕФПЩППадЁЃвђДЫЃЌPipeline61ЕФЙмЕРдЫааБШЦфЫћПђМмвЊТ§ЃЌвђЮЊЦфЫћПђМмЖРСЂдЫаадквЛИіЕЅЖРЕФЛЗОГжаЃЌВЛашвЊгыЭтВПЯЕЭГМЏГЩЁЃЮвУЧПЩвдЭЈЙ§жЛБЃДцживЊЕФЪ§ОнРДНтОіетИіЮЪЬтЁЃВЛЙ§ЃЌеташвЊдкПЩППадКЭРњЪЗЙмРэЭъећаджЎМфзіГіШЈКтЁЃ |








