| ЫцзХDTЪБДњЛЅСЊЭјЁЂжЧФмЩшБИМАЦфЫћаХЯЂММЪѕЕФЗЂеЙЃЌЪ§ОнБЌЗЂЪНдіГЄЃЌШчКЮНЋетаЉЪ§ОнНјаагаађЁЂгаНсЙЙЕиЗжРрзщжЏКЭДцДЂЪЧЮвУЧУцСйЕФвЛИіЬєеНЁЃ
ЮЊЪВУДашвЊЪ§ОнНЈФЃ
ШчЙћАбЪ§ОнПДзїЭМЪщЙнРяЕФЪщЃЌЮвУЧЯЃЭћПДЕНЫќУЧдкЪщМмЩЯЗжУХБ№РрЕиЗХжУЃЛШчЙћАбЪ§ОнПДзїГЧЪаЕФНЈжўЃЌЮвУЧЯЃЭћГЧЪаЙцЛЎВМОжКЯРэЃЛШчЙћАбЪ§ОнПДзїЕчФдЮФМўКЭЮФМўМаЃЌЮвУЧЯЃЭћАДеездМКЕФЯАЙпгаКмКУЕФЮФМўМазщжЏЗНЪНЃЌЖјВЛЪЧдуИтЛьТвЕФзРУцЃЌОГЃЮЊеввЛИіЮФМўЖјВЛжЊЫљДыЁЃ
Ъ§ОнФЃаЭОЭЪЧЪ§ОнзщжЏКЭДцДЂЗНЗЈЃЌЫќЧПЕїДгвЕЮёЁЂЪ§ОнДцШЁКЭЪЙгУНЧЖШКЯРэДцДЂЪ§ОнЁЃLinuxЕФДДЪМШЫTorvaldsгавЛЖЮЙигкЁАЪВУДВХЪЧгХауГЬађдБЁБЕФЛАЃКЁАРУГЬађдБЙиаФЕФЪЧДњТыЃЌКУГЬађдБЙиаФЕФЪЧЪ§ОнНсЙЙКЭЫќУЧжЎМфЕФЙиЯЕЁБЃЌЦфВћЪіСЫЪ§ОнФЃаЭЕФживЊадЁЃгаСЫЪЪКЯвЕЮёКЭЛљДЁЪ§ОнДцДЂЛЗОГЕФФЃаЭЃЌФЧУДДѓЪ§ОнОЭФмЛёЕУвдЯТКУДІЁЃ
адФмЃКСМКУЕФЪ§ОнФЃаЭФмАяжњЮвУЧПьЫйВщбЏЫљашвЊЕФЪ§ОнЃЌМѕЩйЪ§ОнЕФI/OЭЬЭТЁЃ
ГЩБОЃКСМКУЕФЪ§ОнФЃаЭФмМЋДѓЕиМѕЩйВЛБивЊЕФЪ§ОнШпгрЃЌвВФмЪЕЯжМЦЫуНсЙћИДгУЃЌМЋДѓЕиНЕЕЭДѓЪ§ОнЯЕЭГжаЕФДцДЂКЭМЦЫуГЩБОЁЃ
аЇТЪЃКСМКУЕФЪ§ОнФЃаЭФмМЋДѓЕиИФЩЦгУЛЇЪЙгУЪ§ОнЕФЬхбщЃЌЬсИпЪЙгУЪ§ОнЕФаЇТЪЁЃ
жЪСПЃКСМКУЕФЪ§ОнФЃаЭФмИФЩЦЪ§ОнЭГМЦПкОЖЕФВЛвЛжТадЃЌМѕЩйЪ§ОнМЦЫуДэЮѓЕФПЩФмадЁЃ
вђДЫЃЌЮугЙжУвЩЃЌДѓЪ§ОнЯЕЭГашвЊЪ§ОнФЃаЭЗНЗЈРДАяжњИќКУЕизщжЏКЭДцДЂЪ§ОнЃЌвдБудкадФмЁЂГЩБОЁЂаЇТЪКЭжЪСПжЎМфШЁЕУзюМбЦНКтЁЃ
ЙиЯЕЪ§ОнПтЯЕЭГКЭЪ§ОнВжПт
E .F .CoddЪЧЙиЯЕЪ§ОнПтЕФБЧзцЃЌЫћЪзДЮЬсГіСЫЪ§ОнПтЯЕЭГЕФЙиЯЕФЃаЭЃЌПЊДДСЫЪ§ОнПтЙиЯЕЗНЗЈКЭЙиЯЕЪ§ОнРэТлЕФбаОПЁЃЫцзХвЛДѓХњДѓаЭЙиЯЕЪ§ОнПтЩЬвЕШэМўЃЈШчOracleЁЂInformixЁЂDB2ЕШЃЉЕФаЫЦ№ЃЌЯжДњЦѓвЕаХЯЂЯЕЭГМИКѕЖМЪЙгУЙиЯЕЪ§ОнПтРДДцДЂЁЂМгЙЄКЭДІРэЪ§ОнЁЃЪ§ОнВжПтЯЕЭГвВВЛР§ЭтЃЌДѓСПЕФЪ§ОнВжПтЯЕЭГвРЭаЧПДѓЕФЙиЯЕЪ§ОнПтФмСІДцДЂКЭДІРэЪ§ОнЃЌЦфВЩгУЕФЪ§ОнФЃаЭЗНЗЈвВЪЧЛљгкЙиЯЕЪ§ОнПтРэТлЕФЁЃЫфШЛНќФъРДДѓЪ§ОнЕФДцДЂКЭМЦЫуЛљДЁЩшЪЉдкЗжВМЪНЗНУцгаСЫЗЩЫйЕФЗЂеЙЃЌNoSQLММЪѕвВдјСїаавЛЪБЃЌЕЋЪЧВЛЙмЪЧHadoopЁЂSparkЛЙЪЧАЂРяАЭАЭМЏЭХЕФMaxComputeЯЕЭГЃЌШдШЛдкДѓЙцФЃЪЙгУSQLНјааЪ§ОнЕФМгЙЄКЭДІРэЃЌШдШЛдкгУTableДцДЂЪ§ОнЃЌШдШЛдкЪЙгУЙиЯЕРэТлУшЪіЪ§ОнжЎМфЕФЙиЯЕЃЌжЛЪЧдкДѓЪ§ОнСьгђЃЌЛљгкЦфЪ§ОнДцШЁЕФЬиЕудкЙиЯЕЪ§ОнФЃаЭЕФЗЖЪНЩЯгаСЫВЛЭЌЕФбЁдёЖјвбЁЃЙигкЗЖЪНЕФЯъЯИЫЕУїКЭЖЈвхЃЌвдМАЦфЫћвЛаЉЙиЯЕЪ§ОнПтЕФРэТлЪЧДѓЪ§ОнСьгђНЈФЃЕФЛљДЁЃЌгааЫШЄЕФЖСепПЩвдВЮПМЯрЙиЕФОЕфЪ§ОнПтРэТлЪщМЎЃЌШчЁЖЪ§ОнПтЯЕЭГИХФюЁЗЁЃ
ДгOLTPКЭOLAPЯЕЭГЕФЧјБ№ПДФЃаЭЗНЗЈТлЕФбЁдё
OLTPЯЕЭГЭЈГЃУцЯђЕФжївЊЪ§ОнВйзїЪЧЫцЛњЖСаДЃЌжївЊВЩгУТњзу3NFЕФЪЕЬхЙиЯЕФЃаЭДцДЂЪ§ОнЃЌДгЖјдкЪТЮёДІРэжаНтОіЪ§ОнЕФШпгрКЭвЛжТадЮЪЬтЃЛЖјOLAPЯЕЭГУцЯђЕФжївЊЪ§ОнВйзїЪЧХњСПЖСаДЃЌЪТЮёДІРэжаЕФвЛжТадВЛЪЧOLAPЫљЙизЂЕФЃЌЦфжївЊЙизЂЪ§ОнЕФећКЯЃЌвдМАдквЛДЮадЕФИДдгДѓЪ§ОнВщбЏКЭДІРэжаЕФадФмЃЌвђДЫЫќашвЊВЩгУвЛаЉВЛЭЌЕФЪ§ОнНЈФЃЗНЗЈЁЃ
ЕфаЭЕФЪ§ОнВжПтНЈФЃЗНЗЈТл
ERФЃаЭ
Ъ§ОнВжПтжЎИИBill InmonЬсГіЕФНЈФЃЗНЗЈЪЧДгШЋЦѓвЕЕФИпЖШЩшМЦвЛИі3NFФЃаЭЃЌгУЪЕЬхЙиЯЕЃЈEntity
RelationshipЃЌERЃЉФЃаЭУшЪіЦѓвЕвЕЮёЃЌдкЗЖЪНРэТлЩЯЗћКЯ3NFЁЃЪ§ОнВжПтжаЕФ3NFгыOLTPЯЕЭГжаЕФ3NFЕФЧјБ№дкгкЃЌЫќЪЧеОдкЦѓвЕНЧЖШУцЯђжїЬтЕФГщЯѓЃЌЖјВЛЪЧеыЖдФГИіОпЬхвЕЮёСїГЬЕФЪЕЬхЖдЯѓЙиЯЕЕФГщЯѓЁЃЦфОпгавдЯТМИИіЬиЕуЃК
ашвЊШЋУцСЫНтЦѓвЕвЕЮёКЭЪ§ОнЁЃ
ЪЕЪЉжмЦкЗЧГЃГЄЁЃ
ЖдНЈФЃШЫдБЕФФмСІвЊЧѓЗЧГЃИпЁЃ
ВЩгУERФЃаЭНЈЩшЪ§ОнВжПтФЃаЭЕФГіЗЂЕуЪЧећКЯЪ§ОнЃЌНЋИїИіЯЕЭГжаЕФЪ§ОнвдећИіЦѓвЕНЧЖШАДжїЬтНјааЯрЫЦадзщКЯКЭКЯВЂЃЌВЂНјаавЛжТадДІРэЃЌЮЊЪ§ОнЗжЮіОіВпЗўЮёЃЌЕЋЪЧВЂВЛФмжБНггУгкЗжЮіОіВпЁЃ
ЦфНЈФЃВНжшЗжЮЊШ§ИіНзЖЮЁЃ
ИпВуФЃаЭЃКвЛИіИпЖШГщЯѓЕФФЃаЭЃЌУшЪіжївЊЕФжїЬтвдМАжїЬтМфЕФЙиЯЕЃЌгУгкУшЪіЦѓвЕЕФвЕЮёзмЬхИХПіЁЃ
жаВуФЃаЭЃКдкИпВуФЃаЭЕФЛљДЁЩЯЃЌЯИЛЏжїЬтЕФЪ§ОнЯюЁЃ
ЮяРэФЃаЭЃЈвВНаЕзВуФЃаЭЃЉЃКдкжаВуФЃаЭЕФЛљДЁЩЯЃЌПМТЧЮяРэДцДЂЃЌЭЌЪБЛљгкадФмКЭЦНЬЈЬиЕуНјааЮяРэЪєадЕФЩшМЦЃЌвВПЩФмзівЛаЉБэЕФКЯВЂЁЂЗжЧјЕФЩшМЦЕШЁЃ
ERФЃаЭдкЪЕМљжазюЕфаЭЕФДњБэЪЧTeradataЙЋЫОЛљгкН№ШквЕЮёЗЂВМЕФFS-LDMЃЈFinancial
Services Logical Data ModelЃЉЃЌЫќЭЈЙ§ЖдН№ШквЕЮёЕФИпЖШГщЯѓКЭзмНсЃЌНЋН№ШквЕЮёЛЎЗжЮЊ10ДѓжїЬтЃЌВЂвдЩшМЦУцЯђН№ШкВжПтФЃаЭЕФКЫаФЮЊЛљДЁЃЌЦѓвЕЛљгкДЫФЃаЭзіЪЪЕБЕїећКЭРЉеЙОЭФмПьЫйТфЕиЪЕЪЉЁЃ
ЮЌЖШФЃаЭ
ЮЌЖШФЃаЭЪЧЪ§ОнВжПтСьгђЕФRalph KimballДѓЪІЫљГЋЕМЕФЃЌЫћЕФThe Data Warehouse
Toolkit-The Complete Guide to Dimensional ModelingЪЧЪ§ОнВжПтЙЄГЬСьгђзюСїааЕФЪ§ОнВжПтНЈФЃЕФОЕфЁЃ
ЮЌЖШНЈФЃДгЗжЮіОіВпЕФашЧѓГіЗЂЙЙНЈФЃаЭЃЌЮЊЗжЮіашЧѓЗўЮёЃЌвђДЫЫќжиЕуЙизЂгУЛЇШчКЮИќПьЫйЕиЭъГЩашЧѓЗжЮіЃЌЭЌЪБОпгаНЯКУЕФДѓЙцФЃИДдгВщбЏЕФЯьгІадФмЁЃЦфЕфаЭЕФДњБэЪЧаЧаЮФЃаЭЃЌвдМАдквЛаЉЬиЪтГЁОАЯТЪЙгУЕФбЉЛЈФЃаЭЁЃЦфЩшМЦЗжЮЊвдЯТМИИіВНжшЁЃ
бЁдёашвЊНјааЗжЮіОіВпЕФвЕЮёЙ§ГЬЁЃвЕЮёЙ§ГЬПЩвдЪЧЕЅИівЕЮёЪТМўЃЌБШШчНЛвзЕФжЇИЖЁЂЭЫПюЕШЃЛвВПЩвдЪЧФГИіЪТМўЕФзДЬЌЃЌБШШчЕБЧАЕФеЫЛЇгрЖюЕШЃЛЛЙПЩвдЪЧвЛЯЕСаЯрЙивЕЮёЪТМўзщГЩЕФвЕЮёСїГЬЃЌОпЬхашвЊПДЮвУЧЗжЮіЕФЪЧФГаЉЪТМўЗЂЩњЧщПіЃЌЛЙЪЧЕБЧАзДЬЌЃЌЛђЪЧЪТМўСїзЊаЇТЪЁЃ
бЁдёСЃЖШЁЃдкЪТМўЗжЮіжаЃЌЮвУЧвЊдЄХаЫљгаЗжЮіашвЊЯИЗжЕФГЬЖШЃЌДгЖјОіЖЈбЁдёЕФСЃЖШЁЃСЃЖШЪЧЮЌЖШЕФвЛИізщКЯЁЃ
ЪЖБ№ЮЌБэЁЃбЁдёКУСЃЖШжЎКѓЃЌОЭашвЊЛљгкДЫСЃЖШЩшМЦЮЌБэЃЌАќРЈЮЌЖШЪєадЃЌгУгкЗжЮіЪБНјааЗжзщКЭЩИбЁЁЃ
бЁдёЪТЪЕЁЃШЗЖЈЗжЮіашвЊКтСПЕФжИБъЁЃ
Data VaultФЃаЭ
Data VaultЪЧDan LinstedtЗЂЦ№ДДНЈЕФвЛжжФЃаЭЃЌЫќЪЧERФЃаЭЕФбмЩњЃЌЦфЩшМЦЕФГіЗЂЕувВЪЧЮЊСЫЪЕЯжЪ§ОнЕФећКЯЃЌЕЋВЛФмжБНггУгкЪ§ОнЗжЮіОіВпЁЃЫќЧПЕїНЈСЂвЛИіПЩЩѓМЦЕФЛљДЁЪ§ОнВуЃЌвВОЭЪЧЧПЕїЪ§ОнЕФРњЪЗадЁЂПЩзЗЫнадКЭдзгадЃЌЖјВЛвЊЧѓЖдЪ§ОнНјааЙ§ЖШЕФвЛжТадДІРэКЭећКЯЃЛЭЌЪБЫќЛљгкжїЬтИХФюНЋЦѓвЕЪ§ОнНјааНсЙЙЛЏзщжЏЃЌВЂв§ШыСЫИќНјвЛВНЕФЗЖЪНДІРэРДгХЛЏФЃаЭЃЌвдгІЖддДЯЕЭГБфИќЕФРЉеЙадЁЃData
VaultФЃаЭгЩвдЯТМИВПЗжзщГЩЁЃ
HubЃКЪЧЦѓвЕЕФКЫаФвЕЮёЪЕЬхЃЌгЩЪЕЬхkeyЁЂЪ§ОнВжПтађСаДњРэМќЁЂзАдиЪБМфЁЂЪ§ОнРДдДзщГЩЁЃ
LinkЃКДњБэHubжЎМфЕФЙиЯЕЁЃетРягыERФЃаЭзюДѓЕФЧјБ№ЪЧНЋЙиЯЕзїЮЊвЛИіЖРСЂЕФЕЅдЊГщЯѓЃЌПЩвдЬсЩ§ФЃаЭЕФРЉеЙадЁЃЫќПЩвджБНгУшЪі1:1ЁЂ1:nКЭn:nЕФЙиЯЕЃЌЖјВЛашвЊзіШЮКЮБфИќЁЃЫќгЩHubЕФДњРэМќЁЂзАдиЪБМфЁЂЪ§ОнРДдДзщГЩЁЃ
SatelliteЃКЪЧHubЕФЯъЯИУшЪіФкШнЃЌвЛИіHubПЩвдгаЖрИіSatelliteЁЃЫќгЩHubЕФДњРэМќЁЂзАдиЪБМфЁЂРДдДРраЭЁЂЯъЯИЕФHubУшЪіаХЯЂзщГЩЁЃ
Data VaultФЃаЭБШERФЃаЭИќШнвзЩшМЦКЭВњГіЃЌЫќЕФETLМгЙЄПЩЪЕЯжХфжУЛЏЁЃЭЈЙ§Dan LinstedtЕФБШгїИќФмРэНтData
VaultЕФКЫаФЫМЯыЃКHubПЩвдЯыЯѓГЩШЫЕФЙЧМмЃЌФЧУДLinkОЭЪЧСЌНгЙЧМмЕФШЭДјЃЌЖјSatelliteОЭЪЧЙЧМмЩЯУцЕФбЊШтЁЃПДШчЯТЪЕР§ЃЈРДздData
Vault Modeling GuideЃЌзїепHans HultgrenЃЉЃЌШчЭМ1ЫљЪОЁЃ
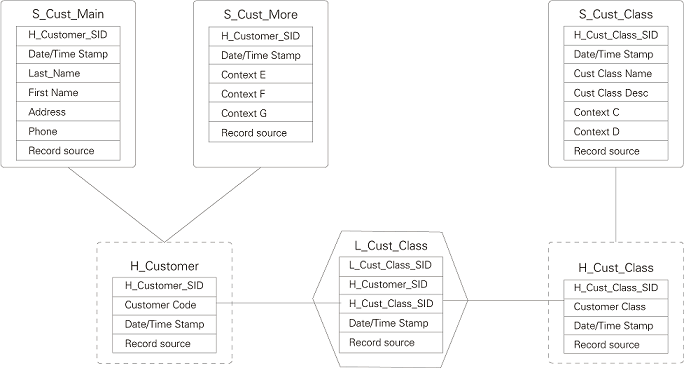
ЭМ1 Data VaultФЃаЭЪЕР§
AnchorФЃаЭ
AnchorЖдData VaultФЃаЭзіСЫНјвЛВНЙцЗЖЛЏДІРэЃЌLars. R?nnb?ckЕФГѕждЪЧЩшМЦвЛИіИпЖШПЩРЉеЙЕФФЃаЭЃЌЦфКЫаФЫМЯыЪЧЫљгаЕФРЉеЙжЛЪЧЬэМгЖјВЛЪЧаоИФЃЌвђДЫНЋФЃаЭЙцЗЖЕН6NFЃЌЛљБОБфГЩСЫk-vНсЙЙЛЏФЃаЭЁЃЮвУЧПДвЛЯТAnchorФЃаЭЕФзщГЩЁЃ
AnchorsЃКРрЫЦгкData VaultЕФHubЃЌДњБэвЕЮёЪЕЬхЃЌЧвжЛгажїМќЁЃ
AttributesЃКЙІФмРрЫЦгкData VaultЕФSatelliteЃЌЕЋЪЧЫќИќМгЙцЗЖЛЏЃЌНЋЦфШЋВПk-vНсЙЙЛЏЃЌвЛИіБэжЛгавЛИіAnchorsЕФЪєадУшЪіЁЃ
TiesЃКОЭЪЧAnchorsжЎМфЕФЙиЯЕЃЌЕЅЖРгУБэРДУшЪіЃЌРрЫЦгкData VaultЕФLinkЃЌПЩвдЬсЩ§ећЬхФЃаЭЙиЯЕЕФРЉеЙФмСІЁЃ
KnotsЃКДњБэФЧаЉПЩФмЛсдкЖрИіAnchorsжаЙЋгУЕФЪєадЕФЬсСЖЃЌБШШчадБ№ЁЂзДЬЌЕШетжжУЖОйРраЭЧвБЛЙЋгУЕФЪєадЁЃ
дкЩЯЪіЫФИіЛљБОЖдЯѓЕФЛљДЁЩЯЃЌгжПЩвдЯИЛЎЗжЮЊРњЪЗЕФКЭЗЧРњЪЗЕФЃЌЦфжаРњЪЗЕФЛсвдЪБМфДСМгЖрЬѕМЧТМЕФЗНЪНМЧТМЪ§ОнЕФБфЧЈРњЪЗЁЃ
AnchorФЃаЭЕФДДНЈепвдДЫЗНЪНРДЛёШЁМЋДѓЕФПЩРЉеЙадЃЌЕЋЪЧвВЛсдіМгЗЧГЃЖрЕФВщбЏjoinВйзїЁЃДДНЈепЕФЙлЕуЪЧЃЌЪ§ОнВжПтжаЕФЗжЮіВщбЏжЛЪЧЛљгквЛаЁВПЗжзжЖЮНјааЕФЃЌРрЫЦгкСаДцДЂНсЙЙЃЌПЩвдДѓДѓМѕЩйЪ§ОнЩЈУшЃЌДгЖјЖдВщбЏадФмгАЯьНЯаЁЁЃвЛаЉгаЪ§ОнБэВУМєЃЈTable
EliminationЃЉЬиадЕФЪ§ОнПтШчMariaDBЕФГіЯжЃЌЛЙЛсДѓСПМѕЩйjoinВйзїЁЃЕЋЪЧЪЕМЪЧщПіЪЧВЛЪЧШчДЫЃЌЛЙгаД§ЩЬШЖЁЃЯТУцЪЧвЛИіAnchorФЃаЭЭМЃЈРДздAnchor
Modeling-Agile Information Modeling in Evolving Data
EnvironmentsЃЌзїепLars. R?nnb?ckЃЉЃЌШчЭМ2ЫљЪОЁЃ
ЭМ2 AnchorФЃаЭЭМ
АЂРяАЭАЭЪ§ОнФЃаЭЪЕМљзлЪі
АЂРяАЭАЭМЏЭХКмдчОЭвбОАбДѓЪ§ОнзїЮЊЦфеНТдФПБъЪЕЪЉЃЌЖјЧвЦфИїИівЕЮёвВЗЧГЃвРРЕЪ§ОнжЇГХдЫгЊЃЌФЧУДАЂРяАЭАЭОПОЙВЩШЁКЮжжЗНЗЈЙЙНЈздМКЕФЪ§ОнВжПтФЃаЭФиЃПАЂРяАЭАЭЕФЪ§ОнВжПтФЃаЭНЈЩшОРњСЫЖрИіЗЂеЙНзЖЮЁЃ
ЕквЛИіНзЖЮЃКЭъШЋгІгУЧ§ЖЏЕФЪБДњЃЌАЂРяАЭАЭЕФЕквЛДњЪ§ОнВжПтЯЕЭГЙЙНЈдкOracleЩЯЃЌЪ§ОнЭъШЋвдТњзуБЈБэашЧѓЮЊФПЕФЃЌНЋЪ§ОнвдгыдДНсЙЙЯрЭЌЕФЗНЪНЭЌВНЕНOracleЃЈГЦзїODSВуЃЉЃЌЪ§ОнЙЄГЬЪІЛљгкODSЪ§ОнНјааЭГМЦЃЌЛљБОУЛгаЯЕЭГЛЏЕФФЃаЭЗНЗЈЬхЯЕЃЌЭъШЋЛљгкЖдOracleЪ§ОнПтЬиадЕФРћгУНјааЪ§ОнДцДЂКЭМгЙЄЃЌВПЗжВЩгУвЛаЉЮЌЖШНЈФЃЕФЛКТ§БфЛЏЮЌЗНЪННјааРњЪЗЪ§ОнДІРэЁЃетЪБКђЕФЪ§ОнМмЙЙжЛгаСНВуЃЌМДODS+DSSЁЃ
ЕкЖўИіНзЖЮЃКЫцзХАЂРяАЭАЭвЕЮёЕФПьЫйЗЂеЙЃЌЪ§ОнСПвВдкЗЩЫйдіГЄЃЌадФмГЩЮЊвЛИіНЯДѓЕФЮЪЬтЃЌвђДЫв§ШыСЫЕБЪБMPPМмЙЙЬхЯЕЕФGreenplumЃЌЭЌЪБАЂРяАЭАЭЕФЪ§ОнЭХЖгвВдкзХЪжНјаавЛЖЈЕФЪ§ОнМмЙЙгХЛЏЃЌЯЃЭћЭЈЙ§вЛаЉФЃаЭММЪѕИФБфбЬДбЪНЕФПЊЗЂФЃаЭЃЌЯћГ§вЛаЉШпгрЃЌЬсЩ§Ъ§ОнЕФвЛжТадЁЃРДздДЋЭГаавЕЕФЪ§ОнВжПтЙЄГЬЪІПЊЪМГЂЪдНЋЙЄГЬСьгђБШНЯСїааЕФERФЃаЭ+ЮЌЖШФЃаЭЗНЪНгІгУЕНАЂРяАЭАЭМЏЭХЃЌЙЙНЈГівЛИіЫФВуЕФФЃаЭМмЙЙЃЌМДODLЃЈВйзїЪ§ОнВуЃЉ+BDLЃЈЛљДЁЪ§ОнВуЃЉ+IDLЃЈНгПкЪ§ОнВуЃЉ+ADLЃЈгІгУЪ§ОнВуЃЉЁЃODLКЭдДЯЕЭГБЃГжвЛжТЃЛBDLЯЃЭћв§ШыERФЃаЭЃЌМгЧПЪ§ОнЕФећКЯЃЌЙЙНЈвЛжТЕФЛљДЁЪ§ОнФЃаЭЃЛIDLЛљгкЮЌЖШФЃаЭЗНЗЈЙЙНЈМЏЪаВуЃЛADLЭъГЩгІгУЕФИіадЛЏКЭЛљгкеЙЯжашЧѓЕФЪ§ОнзщзАЁЃдкДЫЦкМфЃЌЮвУЧдкЙЙНЈERФЃаЭЪБгіЕНСЫБШНЯДѓЕФРЇФбКЭЬєеНЃЌЛЅСЊЭјвЕЮёЕФПьЫйЗЂеЙЁЂШЫдБЕФПьЫйБфЛЏЁЂвЕЮёжЊЪЖЙІЕзЕФВЛЙЛШЋУцЃЌЕМжТERФЃаЭЩшМЦГйГйВЛФмВњГіЁЃжСДЫЃЌЮвУЧвВЕУЕНСЫвЛИіОбщЃКдкВЛЬЋГЩЪьЁЂПьЫйБфЛЏЕФвЕЮёУцЧАЃЌЙЙНЈERФЃаЭЕФЗчЯеЗЧГЃДѓЃЌВЛЬЋЪЪКЯШЅЙЙНЈERФЃаЭЁЃ
ЕкШ§ИіНзЖЮЃКАЂРяАЭАЭМЏЭХЕФвЕЮёКЭЪ§ОнЛЙдкЗЩЫйЗЂеЙЃЌетЪБКђгРДСЫвдHadoopЮЊДњБэЕФЗжВМЪНДцДЂМЦЫуЦНЬЈЕФПьЫйЗЂеЙЃЌЭЌЪБАЂРяАЭАЭМЏЭХзджїбаЗЂЕФЗжВМЪНМЦЫуЦНЬЈMaxComputeвВдкНєТрУмЙФЕиНјаазХЁЃЮвУЧдкгЕБЇЗжВМЪНМЦЫуЦНЬЈЕФЭЌЪБЃЌвВПЊЪМНЈЩшздМКЕФЕкШ§ДњФЃаЭМмЙЙЃЌетЪБКђашвЊевЕНМШЪЪКЯАЂРяАЭАЭМЏЭХвЕЮёЗЂеЙЃЌгжФмГфЗжРћгУЗжВМЪНМЦЫуЦНЬЈФмСІЕФЪ§ОнФЃаЭЗНЪНЁЃЮвУЧбЁдёСЫвдKimballЕФЮЌЖШНЈФЃЮЊКЫаФРэФюЕФФЃаЭЗНЗЈТлЃЌЭЌЪБЖдЦфНјааСЫвЛЖЈЕФЩ§МЖКЭРЉеЙЃЌЙЙНЈСЫАЂРяАЭАЭМЏЭХЕФЙЋЙВВуФЃаЭЪ§ОнМмЙЙЬхЯЕЁЃ
Ъ§ОнЙЋЙВВуНЈЩшЕФФПЕФЪЧзХСІНтОіЪ§ОнДцДЂКЭМЦЫуЕФЙВЯэЮЪЬтЁЃАЂРяАЭАЭМЏЭХЕБЯТвбОЗЂеЙЮЊЖрИіBUЃЌИїИівЕЮёВњЩњХгДѓЕФЪ§ОнЃЌВЂЧвЪ§ОнУПФъвдНќ2.5БЖЕФЫйЖШдкдіГЄЃЌЪ§ОнЕФдіГЄдЖдЖГЌЙ§вЕЮёЕФдіГЄЃЌДјРДЕФГЩБОПЊЯњвВЪЧЗЧГЃСюШЫЕЃгЧЕФЁЃ
АЂРяАЭАЭЪ§ОнЙЋЙВВуНЈЩшЕФжИЕМЗНЗЈЪЧвЛЬзЭГвЛЛЏЕФМЏЭХЪ§ОнећКЯМАЙмРэЕФЗНЗЈЬхЯЕЃЈдкФкВПетвЛЬхЯЕГЦЮЊЁАOneDataЁБЃЉЃЌЦфАќРЈвЛжТадЕФжИБъЖЈвхЬхЯЕЁЂФЃаЭЩшМЦЗНЗЈЬхЯЕвдМАХфЬзЙЄОпЁЃ |








