| ИїааИївЕЖМдквдОЊШЫЕФЫйЖШЩњГЩЪ§ОнЃЌАќРЈВтађЯЕЭГЩњГЩЕФЛљвђзщЪ§ОнЁЂОпгаГЌИпЧхИёЪНЕФУНЬхКЭгщРжЪ§ОнЃЌвдМАжкЖрДЋИаЦїЩњГЩЕФЮяСЊЭј
(IoT) Ъ§ОнЁЃIBM Cloud Object StorageЃЈIBM COSЃЌвдЧАГЦЮЊ CleversafeЃЉММЪѕЮЊетаЉгІгУЬсЙЉСЫИпШнСПЁЂОМУгааЇЕФДцДЂЁЃЕЋНіДцДЂЪ§ОнЛЙВЛЙЛЃЛЛЙашвЊДгЪ§ОнжаЛёШЁМлжЕЃЛПЩвдЪЙгУСьЯШЕФЪ§ОнЗжЮіДІРэв§Чц
Apache Spark РДЪЕЯжДЫФПЕФЁЃSpark ЕФдЫааЫйЖШЪЧ Hadoop MapReduce
ЕФ 100 БЖЃЌЖјЧвЫќЛЙНсКЯСЫ SQLЁЂСїДІРэКЭИДдгЧщПіЗжЮіЁЃ
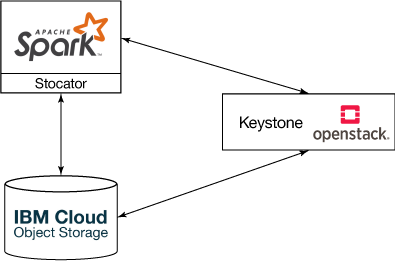
БОЮФНЋНщЩмШчКЮШУ Spark ФмЖд IBM COS жаДцДЂЕФЪ§ОнНјааЗжЮіЁЃЮвУЧНЋНщЩмШчКЮЪЙгУ Stocator
КЭ OpenStack KeystoneЃЌЧАепЪЧвЛИігУзїЧ§ЖЏГЬађЕФПЊдДШэМўЃЌКѓепЬсЙЉСЫЩэЗнбщжЄЙІФмЁЃStocator
РћгУСЫЖдЯѓДцДЂгявхЃЌЖјЧвгывдЧАзЈЮЊДІРэЮФМўЯЕЭГЖјЩшМЦЕФ Spark ДцДЂСЌНгЦїЯрБШЃЌStocator
ЯджјЬсИпСЫадФмЁЃStocator ВЩгУ JOSSЃЈвЛИіПЊдД Java ПЭЛЇЖЫЃЉЩњГЩ HTTP REST
УќСюЃЌетаЉУќСюЭЈЙ§ OpenStack Swift НгПкЗУЮЪ IBM COSЁЃ
ЯТЭМбнЪОСЫ IBM COSЁЂStocator гы OpenStack Keystone жЎМфЕФШ§НЧЙиЯЕЁЃ
АВзАКЭХфжУ Spark
ЯТди SparkЁЃSpark ЭјеОЬсЙЉСЫЙЙНЈЁЂАВзАКЭХфжУ Spark ЕФВйзїЫЕУїЁЃвРОнФњЕФЩшжУЃЌПЩвдНЋ
Spark ХфжУЮЊвЛЬЈЖРСЂЛњЦїЃЌЛђепдкМЏШКЩЯЪЙгУ YARNЁЂMesos Лђ Spark ЕФЖРСЂМЏШКЙмРэЦїЁЃдкЮвУЧЕФЪОР§жаЃЌЮвУЧНсКЯЪЙгУСЫ
IBM COS КЭ Spark 2.0.1ЁЃ
АВзАКЭХфжУ IBM COS
АВзА Cloud Object Storage (COS)ЁЃдкЮвУЧЕФЪОР§жаЃЌЮвУЧЮЊ IBM COS
ЩшжУСЫ Keystone ЩэЗнбщжЄЁЃ
АВзАКЭХфжУ Stocator
ЮЊСЫДг Spark ЗУЮЪ IBM COSЃЌЮвУЧЪЙгУСЫПЊдДЧ§ЖЏГЬађШэМў StocatorЁЃStocator
ЪЧ Spark ЕФИпадФмЕФЖдЯѓДцДЂСЌНгЦїЃЌЫќРћгУСЫЖдЯѓДцДЂгявхЁЃЫќЬсЙЉСЫ OpenStack Swift
API ЕФЭъећЧ§ЖЏГЬађЃЌПЩЧсЫЩЕиРЉеЙЫќРДжЇГжЦфЫћЖдЯѓДцДЂНгПкЁЃЮвУЧРћгУСЫ Stocator ЭЈЙ§Цф
Swift API НЋ Spark гы IBM COS ЯрСЌЕФФмСІЁЃ
вЊЪЙгУ StocatorЃЌЧыЭъГЩвдЯТВНжшЁЃ
1.Дг https://github.com/SparkTC/stocator
ЯТдидДДњТыЃЌЪЙгУ git ИДжЦЛђПЫТЁЫќЁЃ
2.Дг Stocator ЕФФПТМЪфШы mvn clean package
ЈCPall-in-one РДЙЙНЈ StocatorЁЃ
вЊНЋ Spark ХфжУЮЊРћгУ Stocator ЗУЮЪ IBM COSЃЌашвЊЖЈвх Stocator МАЦфЩшжУЁЃгаСНжжХфжУ
Stocator ЕФЗНЗЈЃК
1.ЯђХфжУЮФМўЬэМгВЮЪ§
2.ЯђДњТыЬэМгВЮЪ§
ЯђХфжУЮФМўЬэМгВЮЪ§
вЊДДНЈ core-site.xml ХфжУЮФМўЃЌПЩжДаавдЯТВйзїжЎвЛЃК
1.ЪЙгУ Stocator/conf ФПТМжаЕФ core-site.xml.template
ЮФМў зїЮЊФЃАх
2.ЪЙгУ Keystone Version 2 ХфжУЮФМў
3.ЪЙгУ Keystone Version 3 ХфжУЮФМў
ЪЙгУ Stocator/conf ФПТМжаЕФ core-site.xml.template
ЮФМў
дк Configuration Files ВПЗжЃЌЭЈЙ§ЪфШывдЯТУќСюЃЌЗУЮЪгУгкХфжУЛљгк Keystone
ЕФЩэЗнбщжЄЕФ core-site.xml ЪОР§ЃК
ЧхЕЅ 1. ЗУЮЪ core-site.xml.template ЮФМў
| ofer@beginnings:~$
cd ~/stocator/conf
ofer@beginnings:~/stocator/conf$ cp core-site.xml.template
~/spark-2.0.1/conf/core-site.x |
ЪЙгУ Keystone Version 2 ХфжУЮФМў
Ждгк Keystone Version 2ЃЌПЩвдЪЙгУетИі core-site.xml ВЂАДЧхЕЅЯТЗНЕФЫЕУїНјааЬцЛЛЁЃ
ЧхЕЅ 2. Keystone Version 2 ХфжУЮФМў
| <configuration>
<property>
<name>fs.swift2d.impl</name>
<value>com.ibm.stocator.fs.ObjectStoreFile
System</value>
</property>
<!-- Keystone based authentication -->
<property>
<name>fs.swift2d.service.spark.auth.url</name>
<value>http://your.keystone.server.com:
5000/v2.0/tokens</value>
</property>
<property>
<name>fs.swift2d.service.spark.public</name>
<value>true</value>
</property>
<property>
<name>fs.swift2d.service.spark.tenant</name>
<value>service</value>
</property>
<property>
<name>fs.swift2d.service.spark.password</name>
<value>passw0rd</value>
</property>
<property>
<name>fs.swift2d.service.spark.username</name>
<value>swift</value>
</property>
<property>
<name>fs.swift2d.service.spark.auth.method</name>
<value>keystone</value>
</property>
<property>
<name>fs.swift2d.service.spark.region</name>
<value>IBMCOS</value>
</property>
</configuration> |
1.НЋ your.keystone.server.com ЬцЛЛЮЊ
Keystone ЗўЮёЦїЕФецЪЕЕижЗЁЃ
2.НЋЫљгаЩэЗнбщжЄЦОжЄЃЈtenantЁЂusername КЭ passwordЃЉЬцЛЛЮЊФњЕФЖдЯѓДцДЂЕФгааЇЦОжЄЁЃ
3.ЪЙгУШЋЧђ Keystone ЪБЃЌашвЊИљОнЮЊ IBM COS
ЗУЮЪЖЈвхЕФ Keystone ЕиЧјРДЖЈвх region ЪєадЁЃ
ЪЙгУ Keystone Version 3 ХфжУЮФМў
Ждгк Keystone Version 3ЃЌПЩвдЪЙгУетИі core-site.xml ВЂАДЧхЕЅЯТЗНЕФЫЕУїНјааЬцЛЛЁЃЧыМЧзЁЃЌЖдгк
Keystone Version 3ЃЌЪЙгУ userID КЭ tenantID ДњЬц username
КЭ tenant жЕЁЃ
ЧхЕЅ 3. Keystone Version 3 ХфжУЮФМў
| <configuration>
<property>
<name>fs.swift2d.impl</name>
<value>com.ibm.stocator.fs.ObjectStoreFileSystem
</value>
</property>
<!-- Keystone based authentication -->
<property>
<name>fs.swift2d.service.spark.auth.url</name>
<value>http://your.keystone.server.com:5000/v3
/auth/tokens</value>
</property>
<property>
<name>fs.swift2d.service.spark.public</name>
<value>true</value>
</property>
<property>
<name>fs.swift2d.service.spark.tenant</name>
<value>1c5c9e97c8db488baeca8d667497aef7</value>
</property>
<property>
<name>fs.swift2d.service.spark.password</name>
<value>passw0rd</value>
</property>
<property>
<name>fs.swift2d.service.spark.username</name>
<value>d2a2adb8bd924c2da1545e2e9ee7c4fe</value>
</property>
<property>
<name>fs.swift2d.service.spark.auth.method</name>
<value>keystoneV3</value>
</property>
<property>
<name>fs.swift2d.service.spark.region</name>
<value>IBMCOS</value>
</property>
</configuration> |
1.НЋ your.keystone.server.com ЬцЛЛЮЊ
Keystone ЗўЮёЦїЕФецЪЕЕижЗЁЃ
2.НЋЫљгаЩэЗнбщжЄЦОжЄЃЈtenantЁЂusername КЭ passwordЃЉЬцЛЛЮЊФњЕФЖдЯѓДцДЂЕФгааЇЦОжЄЁЃЧыМЧзЁЃЌЖдгк
Keystone Version 3ЃЌЪЙгУ userID КЭ tenantID ДњЬц username
КЭ tenant жЕЁЃ
3.ЪЙгУШЋЧђ Keystone ЪБЃЌашвЊИљОнЮЊ IBM COS
ЗУЮЪЖЈвхЕФ Keystone ЕиЧјРДЖЈвх region ЪєадЁЃ
дкДњТыжавдБрГЬЗНЪНжИЖЈВЮЪ§
ШчЙћЯВЛЖдкДњТыжажИЖЈВЮЪ§ЃЌПЩвдЪЙгУЯТУцЕФДњТыЪОР§ЃЌЦфжаЕФ SERVICE_NAME ЮЊ sparkЁЃ
ЧхЕЅ 4. ЯђДњТыЬэМгХфжУВЮЪ§
| hconf
= sc._jsc.hadoopConfiguration()
hconf.set("fs.swift2d.impl", "com.ibm.stocator
.fs.ObjectStoreFileSystem")
hconf.set("fs.swift2d.service.spark.auth.url",
"http://your.authentication.server.com/v2.0/tokens")
hconf.set("fs.swift2d.service.spark.public",
"true")
hconf.set("fs.swift2d.service.spark.tenant",
"service")
hconf.set("fs.swift2d.service.spark.username",
"swift")
hconf.set("fs.swift2d.service.spark.auth.method",
"keystone")
hconf.set("fs.swift2d.service.spark.password",
"passw0rd")
hconf.set("fs.swift2d.service.spark.region",
"IBMCOS") |
Бэ 1 ЖдУПИіВЮЪ§НјааСЫЫЕУїЁЃ
Бэ 1. ХфжУВЮЪ§

ЦєЖЏЦєгУСЫ Stocator ЕФ Spark
дкРћгУ Stocator Дг Spark ЗУЮЪ IBM COS ЖдЯѓжЎЧАЃЌашвЊОВЬЌЕиНЋ Spark
КЭ Stocator жиаТБрвыЕНвЛЦ№ЃЌЛђепЖЏЬЌЕиНЋ Stocator ЕФПтДЋЕнИј SparkЁЃ
вЊРћгУдДДњТыжиаТБрвы Spark РДАќКЌ Stocator Ч§ЖЏГЬађЃЌЧыВЮдФ github ЩЯЕФ Stocator
ДцДЂПт жаЕФЫЕУїЁЃ
вЊЭЈЙ§ Stocator ЕФЖРСЂ jar ПтЪЙгУ SparkЃЌЖјВЛжиаТБрвыЫќЃЌПЩвдЪЙгУ ЈCjars
бЁЯюдЫаа SparkЁЃдкЮвУЧЕФЛЗОГжаЃЌЮвУЧЪЙгУСЫ 1.0.8 АцЕФ StocatorЃЌЫљвдЖРСЂ jar
ПтЕФУћГЦЮЊ stocator-1.0.8-SNAPSHOT-jar-with-dependencies.jarЁЃдкЮвУЧЕФЪОР§ЛЗОГжаЃЌДЋЕнИј
Spark ЕФбЁЯюАќРЈЃКЈCjars stocator-1.0.8-SNAPSHOT-jar-with-dependencies.jarЁЃ
| ofer@beginnings:~$
~/spark-2.0.1/bin/spark-shell \
--jars stocator-1.0.8-SNAPSHOT-jar-with-dependencies.jar
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 2.0.1
/_/
Using Scala version 2.11.8 (OpenJDK 64-Bit Server
VM, Java 1.7.0_111)
Type in expressions to have them evaluated.
Type :help for more information.
scala> |
Дг Spark ЗУЮЪ IBM COS ЖдЯѓ
дк Spark ЩЯЦєгУ Stocator КѓЃЌОЭПЩвдЪЙгУФЃЪН swift2d://<container>.<service>/
Дг Spark ЗУЮЪ IBM COS ЖдЯѓЁЃswift2d ЙиМќзжИцЫп Spark ЪЙгУФФИіЧ§ЖЏГЬађРДЗУЮЪДцДЂЁЃЫќБэУїФње§дкЪЙгУ
Stocator ЗУЮЪвЛИіЖдЯѓДцДЂЁЃШнЦїКЭЗўЮёНЋдкЯТвЛНкжаИќЯъЯИЕиНщЩмЁЃ
Р§ШчЃЌвдЯТ Python ДњТыДг IBM COS ЖСШЁвЛИіУћЮЊ data.json ЕФ JSON ЖдЯѓЃЌВЂНЋЫќзїЮЊвЛИіУћЮЊ
data.parquet ЕФ Parquet ЖдЯѓаДЛиЁЃ
ЧхЕЅ 6. ЗУЮЪ IBM COS ЖдЯѓ
| df
= sqlContext.read.json("swift2d://vault.spark/data.jsonЁБ)
df.write.parquet("swift2d://vault.spark/data.parquetЁБ) |
ВтЪд Spark гы IBM COS жЎМфЕФСЌНг
ЮЊСЫВтЪд Spark гы IBM COS жЎМфЕФСЌНгЃЌЮвУЧЪЙгУСЫвЛЖЮМђЕЅЕФ Python НХБОЃЌИУНХБОНЋЕЅвЛСаБэ
ЕФ 6 ИідЊЫиЗжВМдк Spark МЏШКЩЯЃЌНЋЪ§ОнаДШы Parquet ЖдЯѓжаЃЌзюКѓЖСЛиИУЖдЯѓЁЃParquet
ЖдЯѓЕФУћГЦБЛзїЮЊВЮЪ§ДЋШыНХБОжаЁЃ
ИУЪ§ОнЯдЪОСЫСНДЮЃКЕквЛДЮЪЧдкаДШыЖдЯѓДцДЂжЎЧАЃЌгыЦфФЃЪНвЛЦ№ЯдЪОЃЛЕкЖўДЮЪЧдкДгЖдЯѓДцДЂЖСЛижЎКѓЁЃ
ЧхЕЅ 7. ВтЪдСЌНгЕФ Python НХБО
| from
pyspark import SparkContext
from pyspark.sql import SQLContext
from pyspark.sql.types import *
import sys
sc = SparkContext()
sqlContext = SQLContext(sc)
if (len(sys.argv) != 2):
print "ERROR: This program takes object
name as input"
sys.exit(0)
objectName = sys.argv[1]
myList = [[1,'a'],[2,'b'],[3,'c'],[4,'d'],[5,'e'],[6,'f']]
parallelList = sc.parallelize(myList).collect()
schema = StructType([StructField('column1',
IntegerType(), False),
StructField('column2', StringType(), False)])
df = sqlContext.createDataFrame(parallelList,
schema)
df.printSchema()
df.show()
dfTarget = df.coalesce(1)
dfTarget.write.parquet("swift2d://vault.spark/"
+ objectName)
dfRead = sqlContext.read.parquet("swift2d://vault.spark/"
+ objectName)
dfRead.show()
print "Done!" |
вЊдЫааИУНХБОЃЌЧыЭъГЩвдЯТВНжшЃК
1.НЋДњТывдЮФМў sniff.test.py ЕФаЮЪНБЃДцдк ЧхЕЅ
7 жаЁЃ
2.ДДНЈвЛИіУћЮЊ vault ЕФШнЦїЁЃ
3.НЋЗўЮёЃЈurl жаЕФШнЦїУћГЦКѓЯдЪОЕФДЪгяЃЉЩшжУЮЊ core-site.xml
ЮФМўжаЖЈвхЕФ SERVICE_NAMEЃЈЧыМЧзЁЃЌЮвУЧЕФЪОР§жаЪЙгУСЫ sparkЃЉЁЃ
4.ЗЂГівдЯТУќСюЃЌЦфжаЕФ testing.parquet ЪЧвЊДДНЈВЂЖСШЁЕФЖдЯѓЕФУћГЦЃКspark-submit
--jars stocator-1.0.8-SNAPSHOT-jar-with-dependencies.jar
sniff.test.py testing.parquetЁЃ
ФњЛсдк IBM COS жаПДЕНвЛИі testing.parquet ЖдЯѓЃЌвдМАвдЯТ Spark ЪфГіЃК
ЧхЕЅ 8. ШЗШЯвбСЌНгЕФ Spark НсЙћ
| root
|-- column1: integer (nullable = false)
|-- column2: string (nullable = false)
+-------+-------+
|column1|column2|
+-------+-------+
| 1| a|
| 2| b|
| 3| c|
| 4| d|
| 5| e|
| 6| f|
+-------+-------+
+-------+-------+
|column1|column2|
+-------+-------+
| 1| a|
| 2| b|
| 3| c|
| 4| d|
| 5| e|
| 6| f|
+-------+-------+
Done! |
НсЪјгя
ЭЈЙ§ХфжУ SparkЁЂStocator КЭ IBM Cloud Object Storage РДаЭЌЙЄзїЃЌПЩвдЪЙгУЖдЯѓДцДЂгявхИќПьЕиЗУЮЪКЭЗжЮіДцДЂЕФЪ§ОнЃЌЖјЮоашЪЙгУЮЊДІРэЮФМўЯЕЭГЩшМЦЕФОЩЪНДцДЂСЌНгЦїЁЃ
|








