еЊвЊ KafkaЪЧгЩLinkedInПЊЗЂВЂПЊдДЕФЗжВМЪНЯћЯЂЯЕЭГЃЌвђЦфЗжВМЪНМАИпЭЬЭТТЪЖјБЛЙуЗКЪЙгУЃЌЯжвбгыCloudera
HadoopЃЌApache StormЃЌApache SparkМЏГЩЁЃБОЮФНщЩмСЫKafkaЕФДДНЈБГОАЃЌЩшМЦФПБъЃЌЪЙгУЯћЯЂЯЕЭГЕФгХЪЦвдМАФПЧАСїааЕФЯћЯЂЯЕЭГЖдБШЁЃВЂНщЩмСЫKafkaЕФМмЙЙЃЌProducerЯћЯЂТЗгЩЃЌConsumer
GroupвдМАгЩЦфЪЕЯжЕФВЛЭЌЯћЯЂЗжЗЂЗНЪНЃЌTopic & PartitionЃЌзюКѓНщЩмСЫKafka
ConsumerЮЊКЮЪЙгУpullФЃЪНвдМАKafkaЬсЙЉЕФШ§жжdelivery guaranteeЁЃ
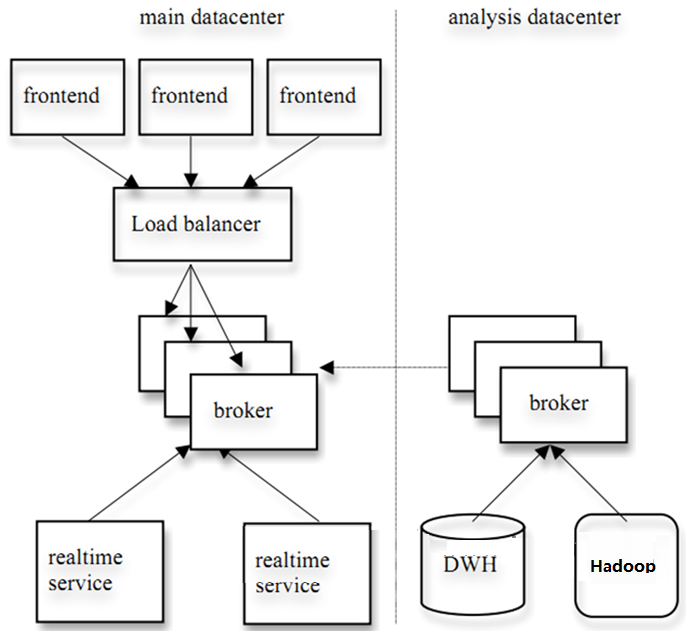
БГОАНщЩм KafkaДДНЈБГОА KafkaЪЧвЛИіЯћЯЂЯЕЭГЃЌдБОПЊЗЂздLinkedInЃЌгУзїLinkedInЕФЛюЖЏСїЃЈActivity
StreamЃЉКЭдЫгЊЪ§ОнДІРэЙмЕРЃЈPipelineЃЉЕФЛљДЁЁЃЯждкЫќвбБЛЖрМвВЛЭЌРраЭЕФЙЋЫО зїЮЊЖржжРраЭЕФЪ§ОнЙмЕРКЭЯћЯЂЯЕЭГЪЙгУЁЃ ЛюЖЏСїЪ§ОнЪЧМИКѕЫљгаеОЕудкЖдЦфЭјеОЪЙгУЧщПізіБЈБэЪБЖМвЊгУЕНЕФЪ§ОнжазюГЃЙцЕФВПЗжЁЃЛюЖЏЪ§ОнАќРЈвГУцЗУЮЪСПЃЈPage
ViewЃЉЁЂБЛВщПДФкШнЗНУцЕФаХЯЂвдМАЫбЫїЧщПіЕШФкШнЁЃетжжЪ§ОнЭЈГЃЕФДІРэЗНЪНЪЧЯШАбИїжжЛюЖЏвдШежОЕФаЮЪНаДШыФГжжЮФМўЃЌШЛКѓжмЦкадЕиЖдетаЉЮФМўНјааЭГМЦЗжЮіЁЃдЫгЊЪ§ОнжИЕФЪЧЗўЮёЦїЕФадФмЪ§ОнЃЈCPUЁЂIOЪЙгУТЪЁЂЧыЧѓЪБМфЁЂЗўЮёШежОЕШЕШЪ§Он)ЁЃдЫгЊЪ§ОнЕФЭГМЦЗНЗЈжжРрЗБЖрЁЃ НќФъРДЃЌЛюЖЏКЭдЫгЊЪ§ОнДІРэвбОГЩЮЊСЫЭјеОШэМўВњЦЗЬиаджавЛИіжСЙиживЊЕФзщГЩВПЗжЃЌетОЭашвЊвЛЬзЩдЮЂИќМгИДдгЕФЛљДЁЩшЪЉЖдЦфЬсЙЉжЇГжЁЃ
ЁЁЁЁ
KafkaМђНщ KafkaЪЧвЛжжЗжВМЪНЕФЃЌЛљгкЗЂВМ/ЖЉдФЕФЯћЯЂЯЕЭГЁЃжївЊЩшМЦФПБъШчЯТЃК
вдЪБМфИДдгЖШЮЊO(1)ЕФЗНЪНЬсЙЉЯћЯЂГжОУЛЏФмСІЃЌМДЪЙЖдTBМЖвдЩЯЪ§ОнвВФмБЃжЄГЃЪ§ЪБМфИДдгЖШЕФЗУЮЪадФм ИпЭЬЭТТЪЁЃМДЪЙдкЗЧГЃСЎМлЕФЩЬгУЛњЦїЩЯвВФмзіЕНЕЅЛњжЇГжУПУы100KЬѕвдЩЯЯћЯЂЕФДЋЪф жЇГжKafka ServerМфЕФЯћЯЂЗжЧјЃЌМАЗжВМЪНЯћЗбЃЌЭЌЪББЃжЄУПИіPartitionФкЕФЯћЯЂЫГађДЋЪф ЭЌЪБжЇГжРыЯпЪ§ОнДІРэКЭЪЕЪБЪ§ОнДІРэ Scale outЃКжЇГждкЯпЫЎЦНРЉеЙ ЮЊКЮЪЙгУЯћЯЂЯЕЭГ Нтёю дкЯюФПЦєЖЏжЎГѕРДдЄВтНЋРДЯюФПЛсХіЕНЪВУДашЧѓЃЌЪЧМЋЦфРЇФбЕФЁЃЯћЯЂЯЕЭГдкДІРэЙ§ГЬжаМфВхШыСЫвЛИівўКЌЕФЁЂЛљгкЪ§ОнЕФНгПкВуЃЌСНБпЕФДІРэЙ§ГЬЖМвЊЪЕЯжетвЛНгПкЁЃетдЪаэФуЖРСЂЕФРЉеЙЛђаоИФСНБпЕФДІРэЙ§ГЬЃЌжЛвЊШЗБЃЫќУЧзёЪиЭЌбљЕФНгПкдМЪјЁЃ
Шпгр гааЉЧщПіЯТЃЌДІРэЪ§ОнЕФЙ§ГЬЛсЪЇАмЁЃГ§ЗЧЪ§ОнБЛГжОУЛЏЃЌЗёдђНЋдьГЩЖЊЪЇЁЃЯћЯЂЖгСаАбЪ§ОнНјааГжОУЛЏжБЕНЫќУЧвбОБЛЭъШЋДІРэЃЌЭЈЙ§етвЛЗНЪНЙцБмСЫЪ§ОнЖЊЪЇЗчЯеЁЃаэЖрЯћЯЂЖгСаЫљВЩгУЕФЁБВхШы-ЛёШЁ-ЩОГ§ЁБЗЖЪНжаЃЌдкАбвЛИіЯћЯЂДгЖгСажаЩОГ§жЎЧАЃЌашвЊФуЕФДІРэЯЕЭГУїШЗЕФжИГіИУЯћЯЂвбОБЛДІРэЭъБЯЃЌДгЖјШЗБЃФуЕФЪ§ОнБЛАВШЋЕФБЃДцжБЕНФуЪЙгУЭъБЯЁЃ
РЉеЙад вђЮЊЯћЯЂЖгСаНтёюСЫФуЕФДІРэЙ§ГЬЃЌЫљвддіДѓЯћЯЂШыЖгКЭДІРэЕФЦЕТЪЪЧКмШнвзЕФЃЌжЛвЊСэЭтдіМгДІРэЙ§ГЬМДПЩЁЃВЛашвЊИФБфДњТыЁЂВЛашвЊЕїНкВЮЪ§ЁЃРЉеЙОЭЯёЕїДѓЕчСІАДХЅвЛбљМђЕЅЁЃ
СщЛюад & ЗхжЕДІРэФмСІ дкЗУЮЪСПОчдіЕФЧщПіЯТЃЌгІгУШдШЛашвЊМЬајЗЂЛгзїгУЃЌЕЋЪЧетбљЕФЭЛЗЂСїСПВЂВЛГЃМћЃЛШчЙћЮЊвдФмДІРэетРрЗхжЕЗУЮЪЮЊБъзМРДЭЖШызЪдДЫцЪБД§УќЮовЩЪЧОоДѓЕФРЫЗбЁЃЪЙгУЯћЯЂЖгСаФмЙЛЪЙЙиМќзщМўЖЅзЁЭЛЗЂЕФЗУЮЪбЙСІЃЌЖјВЛЛсвђЮЊЭЛЗЂЕФГЌИККЩЕФЧыЧѓЖјЭъШЋБРРЃЁЃ
ПЩЛжИДад ЯЕЭГЕФвЛВПЗжзщМўЪЇаЇЪБЃЌВЛЛсгАЯьЕНећИіЯЕЭГЁЃЯћЯЂЖгСаНЕЕЭСЫНјГЬМфЕФёюКЯЖШЃЌЫљвдМДЪЙвЛИіДІРэЯћЯЂЕФНјГЬЙвЕєЃЌМгШыЖгСажаЕФЯћЯЂШдШЛПЩвддкЯЕЭГЛжИДКѓБЛДІРэЁЃ
ЫГађБЃжЄ дкДѓЖрЪЙгУГЁОАЯТЃЌЪ§ОнДІРэЕФЫГађЖМКмживЊЁЃДѓВПЗжЯћЯЂЖгСаБОРДОЭЪЧХХађЕФЃЌВЂЧвФмБЃжЄЪ§ОнЛсАДееЬиЖЈЕФЫГађРДДІРэЁЃKafkaБЃжЄвЛИіPartitionФкЕФЯћЯЂЕФгаађадЁЃ
ЛКГх дкШЮКЮживЊЕФЯЕЭГжаЃЌЖМЛсгаашвЊВЛЭЌЕФДІРэЪБМфЕФдЊЫиЁЃР§ШчЃЌМгдивЛеХЭМЦЌБШгІгУЙ§ТЫЦїЛЈЗбИќЩйЕФЪБМфЁЃЯћЯЂЖгСаЭЈЙ§вЛИіЛКГхВуРДАяжњШЮЮёзюИпаЇТЪЕФжДааЁЊЁЊЁЊаДШыЖгСаЕФДІРэЛсОЁПЩФмЕФПьЫйЁЃИУЛКГхгажњгкПижЦКЭгХЛЏЪ§ОнСїОЙ§ЯЕЭГЕФЫйЖШЁЃ
вьВНЭЈаХ КмЖрЪБКђЃЌгУЛЇВЛЯывВВЛашвЊСЂМДДІРэЯћЯЂЁЃЯћЯЂЖгСаЬсЙЉСЫвьВНДІРэЛњжЦЃЌдЪаэгУЛЇАбвЛИіЯћЯЂЗХШыЖгСаЃЌЕЋВЂВЛСЂМДДІРэЫќЁЃЯыЯђЖгСажаЗХШыЖрЩйЯћЯЂОЭЗХЖрЩйЃЌШЛКѓдкашвЊЕФЪБКђдйШЅДІРэЫќУЧЁЃ
ГЃгУMessage QueueЖдБШ RabbitMQ RabbitMQЪЧЪЙгУErlangБраДЕФвЛИіПЊдДЕФЯћЯЂЖгСаЃЌБОЩэжЇГжКмЖрЕФавщЃКAMQPЃЌXMPP,
SMTP, STOMPЃЌвВе§вђШчДЫЃЌЫќЗЧГЃжиСПМЖЃЌИќЪЪКЯгкЦѓвЕМЖЕФПЊЗЂЁЃЭЌЪБЪЕЯжСЫBrokerЙЙМмЃЌетвтЮЖзХЯћЯЂдкЗЂЫЭИјПЭЛЇЖЫЪБЯШдкжааФЖгСаХХЖгЁЃЖдТЗгЩЃЌИКдиОљКтЛђепЪ§ОнГжОУЛЏЖМгаКмКУЕФжЇГжЁЃ
Redis RedisЪЧвЛИіЛљгкKey-ValueЖдЕФNoSQLЪ§ОнПтЃЌПЊЗЂЮЌЛЄКмЛюдОЁЃЫфШЛЫќЪЧвЛИіKey-ValueЪ§ОнПтДцДЂЯЕЭГЃЌЕЋЫќБОЩэжЇГжMQЙІФмЃЌЫљвдЭъШЋПЩвдЕБзівЛИіЧсСПМЖЕФЖгСаЗўЮёРДЪЙгУЁЃЖдгкRabbitMQКЭRedisЕФШыЖгКЭГіЖгВйзїЃЌИїжДаа100ЭђДЮЃЌУП10ЭђДЮМЧТМвЛДЮжДааЪБМфЁЃВтЪдЪ§ОнЗжЮЊ128BytesЁЂ512BytesЁЂ1KКЭ10KЫФИіВЛЭЌДѓаЁЕФЪ§ОнЁЃЪЕбщБэУїЃКШыЖгЪБЃЌЕБЪ§ОнБШНЯаЁЪБRedisЕФадФмвЊИпгкRabbitMQЃЌЖјШчЙћЪ§ОнДѓаЁГЌЙ§СЫ10KЃЌRedisдђТ§ЕФЮоЗЈШЬЪмЃЛГіЖгЪБЃЌЮоТлЪ§ОнДѓаЁЃЌRedisЖМБэЯжГіЗЧГЃКУЕФадФмЃЌЖјRabbitMQЕФГіЖгадФмдђдЖЕЭгкRedisЁЃ
ZeroMQ ZeroMQКХГЦзюПьЕФЯћЯЂЖгСаЯЕЭГЃЌгШЦфеыЖдДѓЭЬЭТСПЕФашЧѓГЁОАЁЃZMQФмЙЛЪЕЯжRabbitMQВЛЩУГЄЕФИпМЖ/ИДдгЕФЖгСаЃЌЕЋЪЧПЊЗЂШЫдБашвЊздМКзщКЯЖржжММЪѕПђМмЃЌММЪѕЩЯЕФИДдгЖШЪЧЖдетMQФмЙЛгІгУГЩЙІЕФЬєеНЁЃZeroMQОпгавЛИіЖРЬиЕФЗЧжаМфМўЕФФЃЪНЃЌФуВЛашвЊАВзАКЭдЫаавЛИіЯћЯЂЗўЮёЦїЛђжаМфМўЃЌвђЮЊФуЕФгІгУГЬађНЋАчбнетИіЗўЮёЦїНЧЩЋЁЃФужЛашвЊМђЕЅЕФв§гУZeroMQГЬађПтЃЌПЩвдЪЙгУNuGetАВзАЃЌШЛКѓФуОЭПЩвдгфПьЕФдкгІгУГЬађжЎМфЗЂЫЭЯћЯЂСЫЁЃЕЋЪЧZeroMQНіЬсЙЉЗЧГжОУадЕФЖгСаЃЌвВОЭЪЧЫЕШчЙћхДЛњЃЌЪ§ОнНЋЛсЖЊЪЇЁЃЦфжаЃЌTwitterЕФStorm
0.9.0вдЧАЕФАцБОжаФЌШЯЪЙгУZeroMQзїЮЊЪ§ОнСїЕФДЋЪфЃЈStormДг0.9АцБОПЊЪМЭЌЪБжЇГжZeroMQКЭNettyзїЮЊДЋЪфФЃПщЃЉЁЃ
ActiveMQ ActiveMQЪЧApacheЯТЕФвЛИізгЯюФПЁЃ РрЫЦгкZeroMQЃЌЫќФмЙЛвдДњРэШЫКЭЕуЖдЕуЕФММЪѕЪЕЯжЖгСаЁЃЭЌЪБРрЫЦгкRabbitMQЃЌЫќЩйСПДњТыОЭПЩвдИпаЇЕиЪЕЯжИпМЖгІгУГЁОАЁЃ
Kafka/Jafka KafkaЪЧApacheЯТЕФвЛИізгЯюФПЃЌЪЧвЛИіИпадФмПчгябдЗжВМЪНЗЂВМ/ЖЉдФЯћЯЂЖгСаЯЕЭГЃЌЖјJafkaЪЧдкKafkaжЎЩЯЗѕЛЏЖјРДЕФЃЌМДKafkaЕФвЛИіЩ§МЖАцЁЃОпгавдЯТЬиадЃКПьЫйГжОУЛЏЃЌПЩвддкO(1)ЕФЯЕЭГПЊЯњЯТНјааЯћЯЂГжОУЛЏЃЛИпЭЬЭТЃЌдквЛЬЈЦеЭЈЕФЗўЮёЦїЩЯМШПЩвдДяЕН10W/sЕФЭЬЭТЫйТЪЃЛЭъШЋЕФЗжВМЪНЯЕЭГЃЌBrokerЁЂProducerЁЂConsumerЖМдЩњздЖЏжЇГжЗжВМЪНЃЌздЖЏЪЕЯжИКдиОљКтЃЛжЇГжHadoopЪ§ОнВЂааМгдиЃЌЖдгкЯёHadoopЕФвЛбљЕФШежОЪ§ОнКЭРыЯпЗжЮіЯЕЭГЃЌЕЋгжвЊЧѓЪЕЪБДІРэЕФЯожЦЃЌетЪЧвЛИіПЩааЕФНтОіЗНАИЁЃKafkaЭЈЙ§HadoopЕФВЂааМгдиЛњжЦЭГвЛСЫдкЯпКЭРыЯпЕФЯћЯЂДІРэЁЃApache
KafkaЯрЖдгкActiveMQЪЧвЛИіЗЧГЃЧсСПМЖЕФЯћЯЂЯЕЭГЃЌГ§СЫадФмЗЧГЃКУжЎЭтЃЌЛЙЪЧвЛИіЙЄзїСМКУЕФЗжВМЪНЯЕЭГЁЃ
KafkaМмЙЙ Terminology Broker KafkaМЏШКАќКЌвЛИіЛђЖрИіЗўЮёЦїЃЌетжжЗўЮёЦїБЛГЦЮЊbroker Topic УПЬѕЗЂВМЕНKafkaМЏШКЕФЯћЯЂЖМгавЛИіРрБ№ЃЌетИіРрБ№БЛГЦЮЊTopicЁЃЃЈЮяРэЩЯВЛЭЌTopicЕФЯћЯЂЗжПЊДцДЂЃЌТпМЩЯвЛИіTopicЕФЯћЯЂЫфШЛБЃДцгквЛИіЛђЖрИіbrokerЩЯЕЋгУЛЇжЛашжИЖЈЯћЯЂЕФTopicМДПЩЩњВњЛђЯћЗбЪ§ОнЖјВЛБиЙиаФЪ§ОнДцгкКЮДІЃЉ Partition ParitionЪЧЮяРэЩЯЕФИХФюЃЌУПИіTopicАќКЌвЛИіЛђЖрИіPartition. Producer ИКд№ЗЂВМЯћЯЂЕНKafka broker Consumer ЯћЯЂЯћЗбепЃЌЯђKafka brokerЖСШЁЯћЯЂЕФПЭЛЇЖЫЁЃ Consumer Group УПИіConsumerЪєгквЛИіЬиЖЈЕФConsumer GroupЃЈПЩЮЊУПИіConsumerжИЖЈgroup
nameЃЌШєВЛжИЖЈgroup nameдђЪєгкФЌШЯЕФgroupЃЉЁЃ KafkaЭиЦЫНсЙЙ

ШчЩЯЭМЫљЪОЃЌвЛИіЕфаЭЕФKafkaМЏШКжаАќКЌШєИЩProducerЃЈПЩвдЪЧwebЧАЖЫВњЩњЕФPage
ViewЃЌЛђепЪЧЗўЮёЦїШежОЃЌЯЕЭГCPUЁЂMemoryЕШЃЉЃЌШєИЩbrokerЃЈKafkaжЇГжЫЎЦНРЉеЙЃЌвЛАуbrokerЪ§СПдНЖрЃЌМЏШКЭЬЭТТЪдНИпЃЉЃЌШєИЩConsumer
GroupЃЌвдМАвЛИіZookeeperМЏШКЁЃKafkaЭЈЙ§ZookeeperЙмРэМЏШКХфжУЃЌбЁОйleaderЃЌвдМАдкConsumer
GroupЗЂЩњБфЛЏЪБНјааrebalanceЁЃProducerЪЙгУpushФЃЪННЋЯћЯЂЗЂВМЕНbrokerЃЌConsumerЪЙгУpullФЃЪНДгbrokerЖЉдФВЂЯћЗбЯћЯЂЁЃ
ЁЁЁЁ
Topic & Partition TopicдкТпМЩЯПЩвдБЛШЯЮЊЪЧвЛИіqueueЃЌУПЬѕЯћЗбЖМБиаыжИЖЈЫќЕФTopicЃЌПЩвдМђЕЅРэНтЮЊБиаыжИУїАбетЬѕЯћЯЂЗХНјФФИіqueueРяЁЃЮЊСЫЪЙЕУKafkaЕФЭЬЭТТЪПЩвдЯпадЬсИпЃЌЮяРэЩЯАбTopicЗжГЩвЛИіЛђЖрИіPartitionЃЌУПИіPartitionдкЮяРэЩЯЖдгІвЛИіЮФМўМаЃЌИУЮФМўМаЯТДцДЂетИіPartitionЕФЫљгаЯћЯЂКЭЫїв§ЮФМўЁЃШєДДНЈtopic1КЭtopic2СНИіtopicЃЌЧвЗжБ№га13ИіКЭ19ИіЗжЧјЃЌдђећИіМЏШКЩЯЛсЯргІЛсЩњГЩЙВ32ИіЮФМўМаЃЈБОЮФЫљгУМЏШКЙВ8ИіНкЕуЃЌДЫДІtopic1КЭtopic2
replication-factorОљЮЊ1ЃЉЃЌШчЯТЭМЫљЪОЁЃ

УПИіШежОЮФМўЖМЪЧвЛИіlog entryађСаЃЌУПИіlog entryАќКЌвЛИі4зжНкећаЭЪ§жЕЃЈжЕЮЊN+5ЃЉЃЌ1ИізжНкЕФЁБmagic
valueЁБЃЌ4ИізжНкЕФCRCаЃбщТыЃЌЦфКѓИњNИізжНкЕФЯћЯЂЬхЁЃУПЬѕЯћЯЂЖМгавЛИіЕБЧАPartitionЯТЮЈвЛЕФ64зжНкЕФoffsetЃЌЫќжИУїСЫетЬѕЯћЯЂЕФЦ№ЪМЮЛжУЁЃДХХЬЩЯДцДЂЕФЯћЯЂИёЪНШчЯТЃК message length ЃК 4 bytes (value: 1+4+n) ЁАmagicЁБ value ЃК 1 byte crc ЃК 4 bytes payload ЃК n bytes етИіlog entryВЂЗЧгЩвЛИіЮФМўЙЙГЩЃЌЖјЪЧЗжГЩЖрИіsegmentЃЌУПИіsegmentвдИУsegmentЕквЛЬѕЯћЯЂЕФoffsetУќУћВЂвдЁА.kafkaЁБЮЊКѓзКЁЃСэЭтЛсгавЛИіЫїв§ЮФМўЃЌЫќБъУїСЫУПИіsegmentЯТАќКЌЕФlog
entryЕФoffsetЗЖЮЇЃЌШчЯТЭМЫљЪОЁЃ

вђЮЊУПЬѕЯћЯЂЖМБЛappendЕНИУPartitionжаЃЌЪєгкЫГађаДДХХЬЃЌвђДЫаЇТЪЗЧГЃИпЃЈОбщжЄЃЌЫГађаДДХХЬаЇТЪБШЫцЛњаДФкДцЛЙвЊИпЃЌетЪЧKafkaИпЭЬЭТТЪЕФвЛИіКмживЊЕФБЃжЄЃЉЁЃ 
ЖдгкДЋЭГЕФmessage queueЖјбдЃЌвЛАуЛсЩОГ§вбОБЛЯћЗбЕФЯћЯЂЃЌЖјKafkaМЏШКЛсБЃСєЫљгаЕФЯћЯЂЃЌЮоТлЦфБЛЯћЗбгыЗёЁЃЕБШЛЃЌвђЮЊДХХЬЯожЦЃЌВЛПЩФмгРОУБЃСєЫљгаЪ§ОнЃЈЪЕМЪЩЯвВУЛБивЊЃЉЃЌвђДЫKafkaЬсЙЉСНжжВпТдЩОГ§ОЩЪ§ОнЁЃвЛЪЧЛљгкЪБМфЃЌЖўЪЧЛљгкPartitionЮФМўДѓаЁЁЃР§ШчПЩвдЭЈЙ§ХфжУ$KAFKA_HOME/config/server.propertiesЃЌШУKafkaЩОГ§вЛжмЧАЕФЪ§ОнЃЌвВПЩдкPartitionЮФМўГЌЙ§1GBЪБЩОГ§ОЩЪ§ОнЃЌХфжУШчЯТЫљЪОЁЃ
# The minimum
age of a log file to be eligible for deletion
log.retention.hours=168
# The maximum size of a log segment file. When
this size is reached a new log segment will be
created.
log.segment.bytes=1073741824
# The interval at which log segments are checked
to see if they can be deleted according to the
retention policies
log.retention.check.interval.ms=300000
# If log.cleaner.enable=true is set the cleaner
will be enabled and individual logs can then be
marked for log compaction.
log.cleaner.enable=false |
етРявЊзЂвтЃЌвђЮЊKafkaЖСШЁЬиЖЈЯћЯЂЕФЪБМфИДдгЖШЮЊO(1)ЃЌМДгыЮФМўДѓаЁЮоЙиЃЌЫљвдетРяЩОГ§Й§ЦкЮФМўгыЬсИпKafkaадФмЮоЙиЁЃбЁдёдѕбљЕФЩОГ§ВпТджЛгыДХХЬвдМАОпЬхЕФашЧѓгаЙиЁЃСэЭтЃЌKafkaЛсЮЊУПвЛИіConsumer
GroupБЃСєвЛаЉmetadataаХЯЂЁЊЁЊЕБЧАЯћЗбЕФЯћЯЂЕФpositionЃЌвВМДoffsetЁЃетИіoffsetгЩConsumerПижЦЁЃе§ГЃЧщПіЯТConsumerЛсдкЯћЗбЭъвЛЬѕЯћЯЂКѓЕндіИУoffsetЁЃЕБШЛЃЌConsumerвВПЩНЋoffsetЩшГЩвЛИіНЯаЁЕФжЕЃЌжиаТЯћЗбвЛаЉЯћЯЂЁЃвђЮЊoffetгЩConsumerПижЦЃЌЫљвдKafka
brokerЪЧЮозДЬЌЕФЃЌЫќВЛашвЊБъМЧФФаЉЯћЯЂБЛФФаЉЯћЗбЙ§ЃЌвВВЛашвЊЭЈЙ§brokerШЅБЃжЄЭЌвЛИіConsumer
GroupжЛгавЛИіConsumerФмЯћЗбФГвЛЬѕЯћЯЂЃЌвђДЫвВОЭВЛашвЊЫјЛњжЦЃЌетвВЮЊKafkaЕФИпЭЬЭТТЪЬсЙЉСЫгаСІБЃеЯЁЃ
ЁЁЁЁ
ProducerЯћЯЂТЗгЩ ProducerЗЂЫЭЯћЯЂЕНbrokerЪБЃЌЛсИљОнParititionЛњжЦбЁдёНЋЦфДцДЂЕНФФвЛИіPartitionЁЃШчЙћPartitionЛњжЦЩшжУКЯРэЃЌЫљгаЯћЯЂПЩвдОљдШЗжВМЕНВЛЭЌЕФPartitionРяЃЌетбљОЭЪЕЯжСЫИКдиОљКтЁЃШчЙћвЛИіTopicЖдгІвЛИіЮФМўЃЌФЧетИіЮФМўЫљдкЕФЛњЦїI/OНЋЛсГЩЮЊетИіTopicЕФадФмЦПОБЃЌЖјгаСЫPartitionКѓЃЌВЛЭЌЕФЯћЯЂПЩвдВЂаааДШыВЛЭЌbrokerЕФВЛЭЌPartitionРяЃЌМЋДѓЕФЬсИпСЫЭЬЭТТЪЁЃПЩвддк$KAFKA_HOME/config/server.propertiesжаЭЈЙ§ХфжУЯюnum.partitionsРДжИЖЈаТНЈTopicЕФФЌШЯPartitionЪ§СПЃЌвВПЩдкДДНЈTopicЪБЭЈЙ§ВЮЪ§жИЖЈЃЌЭЌЪБвВПЩвддкTopicДДНЈжЎКѓЭЈЙ§KafkaЬсЙЉЕФЙЄОпаоИФЁЃ дкЗЂЫЭвЛЬѕЯћЯЂЪБЃЌПЩвджИЖЈетЬѕЯћЯЂЕФkeyЃЌProducerИљОнетИіkeyКЭPartitionЛњжЦРДХаЖЯгІИУНЋетЬѕЯћЯЂЗЂЫЭЕНФФИіParitionЁЃParititionЛњжЦПЩвдЭЈЙ§жИЖЈProducerЕФparitition.
classетвЛВЮЪ§РДжИЖЈЃЌИУclassБиаыЪЕЯжkafka.producer.PartitionerНгПкЁЃБОР§жаШчЙћkeyПЩвдБЛНтЮіЮЊећЪ§дђНЋЖдгІЕФећЪ§гыPartitionзмЪ§ШЁгрЃЌИУЯћЯЂЛсБЛЗЂЫЭЕНИУЪ§ЖдгІЕФPartitionЁЃЃЈУПИіParitionЖМЛсгаИіађКХ,ађКХДг0ПЊЪМЃЉ
import kafka.producer.Partitioner;
import kafka.utils.VerifiableProperties;
public class JasonPartitioner<T> implements
Partitioner {
public JasonPartitioner(VerifiableProperties verifiableProperties)
{}
@Override
public int partition(Object key, int numPartitions)
{
try {
int partitionNum = Integer.parseInt((String) key);
return Math.abs(Integer.parseInt((String) key)
% numPartitions);
} catch (Exception e) {
return Math.abs(key.hashCode() % numPartitions);
}
}
} |
ШчЙћНЋЩЯР§жаЕФРрзїЮЊpartition.classЃЌВЂЭЈЙ§ШчЯТДњТыЗЂЫЭ20ЬѕЯћЯЂЃЈkeyЗжБ№ЮЊ0ЃЌ1ЃЌ2ЃЌ3ЃЉжСtopic3ЃЈАќКЌ4ИіPartitionЃЉЁЃ
public void
sendMessage() throws InterruptedException{
ЁЁЁЁfor(int i = 1; i <= 5; i++){
ЁЁЁЁ List messageList = new ArrayList<KeyedMessage<String,
String>>();
ЁЁЁЁ for(int j = 0; j < 4; j++ЃЉ{
ЁЁЁЁ messageList.add(new KeyedMessage<String,
String>("topic2", String.valueOf(j),
String.format("The %d message for key %d",
i, j));
ЁЁЁЁ }
ЁЁЁЁ producer.send(messageList);
}
ЁЁЁЁproducer.close();
} |
дђkeyЯрЭЌЕФЯћЯЂЛсБЛЗЂЫЭВЂДцДЂЕНЭЌвЛИіpartitionРяЃЌЖјЧвkeyЕФађКХе§КУКЭPartitionађКХЯрЭЌЁЃЃЈPartitionађКХДг0ПЊЪМЃЌБОР§жаЕФkeyвВДг0ПЊЪМЃЉЁЃЯТЭМЫљЪОЪЧЭЈЙ§JavaГЬађЕїгУConsumerКѓДђгЁГіЕФЯћЯЂСаБэЁЃ

Consumer Group ЃЈБОНкЫљгаУшЪіЖМЪЧЛљгкConsumer hight level APIЖјЗЧlow level APIЃЉЁЃ ЪЙгУConsumer high level APIЪБЃЌЭЌвЛTopicЕФвЛЬѕЯћЯЂжЛФмБЛЭЌвЛИіConsumer
GroupФкЕФвЛИіConsumerЯћЗбЃЌЕЋЖрИіConsumer GroupПЩЭЌЪБЯћЗбетвЛЯћЯЂЁЃ

етЪЧKafkaгУРДЪЕЯжвЛИіTopicЯћЯЂЕФЙуВЅЃЈЗЂИјЫљгаЕФConsumerЃЉКЭЕЅВЅЃЈЗЂИјФГвЛИіConsumerЃЉЕФЪжЖЮЁЃвЛИіTopicПЩвдЖдгІЖрИіConsumer
GroupЁЃШчЙћашвЊЪЕЯжЙуВЅЃЌжЛвЊУПИіConsumerгавЛИіЖРСЂЕФGroupОЭПЩвдСЫЁЃвЊЪЕЯжЕЅВЅжЛвЊЫљгаЕФConsumerдкЭЌвЛИіGroupРяЁЃгУConsumer
GroupЛЙПЩвдНЋConsumerНјааздгЩЕФЗжзщЖјВЛашвЊЖрДЮЗЂЫЭЯћЯЂЕНВЛЭЌЕФTopicЁЃ ЪЕМЪЩЯЃЌKafkaЕФЩшМЦРэФюжЎвЛОЭЪЧЭЌЪБЬсЙЉРыЯпДІРэКЭЪЕЪБДІРэЁЃИљОнетвЛЬиадЃЌПЩвдЪЙгУStormетжжЪЕЪБСїДІРэЯЕЭГЖдЯћЯЂНјааЪЕЪБдкЯпДІРэЃЌЭЌЪБЪЙгУHadoopетжжХњДІРэЯЕЭГНјааРыЯпДІРэЃЌЛЙПЩвдЭЌЪБНЋЪ§ОнЪЕЪББИЗнЕНСэвЛИіЪ§ОнжааФЃЌжЛашвЊБЃжЄетШ§ИіВйзїЫљЪЙгУЕФConsumerЪєгкВЛЭЌЕФConsumer
GroupМДПЩЁЃЯТЭМЪЧKafkaдкLinkedinЕФвЛжжМђЛЏВПЪ№ЪОвтЭМЁЃ
ЯТУцетИіР§згИќЧхЮњЕиеЙЪОСЫKafka Consumer GroupЕФЬиадЁЃЪзЯШДДНЈвЛИіTopic
(УћЮЊtopic1ЃЌАќКЌ3ИіPartition)ЃЌШЛКѓДДНЈвЛИіЪєгкgroup1ЕФConsumerЪЕР§ЃЌВЂДДНЈШ§ИіЪєгкgroup2ЕФConsumerЪЕР§ЃЌзюКѓЭЈЙ§ProducerЯђtopic1ЗЂЫЭkeyЗжБ№ЮЊ1ЃЌ2ЃЌ3ЕФЯћЯЂЁЃНсЙћЗЂЯжЪєгкgroup1ЕФConsumerЪеЕНСЫЫљгаЕФетШ§ЬѕЯћЯЂЃЌЭЌЪБgroup2жаЕФ3ИіConsumerЗжБ№ЪеЕНСЫkeyЮЊ1ЃЌ2ЃЌ3ЕФЯћЯЂЁЃШчЯТЭМЫљЪОЁЃ

Push vs. PullЁЁЁЁ зїЮЊвЛИіЯћЯЂЯЕЭГЃЌKafkaзёбСЫДЋЭГЕФЗНЪНЃЌбЁдёгЩProducerЯђbroker pushЯћЯЂВЂгЩConsumerДгbroker
pullЯћЯЂЁЃвЛаЉlogging-centric systemЃЌБШШчFacebookЕФScribeКЭClouderaЕФFlumeЃЌВЩгУpushФЃЪНЁЃЪТЪЕЩЯЃЌpushФЃЪНКЭpullФЃЪНИїгагХСгЁЃ pushФЃЪНКмФбЪЪгІЯћЗбЫйТЪВЛЭЌЕФЯћЗбепЃЌвђЮЊЯћЯЂЗЂЫЭЫйТЪЪЧгЩbrokerОіЖЈЕФЁЃpushФЃЪНЕФФПБъЪЧОЁПЩФмвдзюПьЫйЖШДЋЕнЯћЯЂЃЌЕЋЪЧетбљКмШнвздьГЩConsumerРДВЛМАДІРэЯћЯЂЃЌЕфаЭЕФБэЯжОЭЪЧОмОјЗўЮёвдМАЭјТчгЕШћЁЃЖјpullФЃЪНдђПЩвдИљОнConsumerЕФЯћЗбФмСІвдЪЪЕБЕФЫйТЪЯћЗбЯћЯЂЁЃ ЖдгкKafkaЖјбдЃЌpullФЃЪНИќКЯЪЪЁЃpullФЃЪНПЩМђЛЏbrokerЕФЩшМЦЃЌConsumerПЩзджїПижЦЯћЗбЯћЯЂЕФЫйТЪЃЌЭЌЪБConsumerПЩвдздМКПижЦЯћЗбЗНЪНЁЊЁЊМДПЩХњСПЯћЗбвВПЩж№ЬѕЯћЗбЃЌЭЌЪБЛЙФмбЁдёВЛЭЌЕФЬсНЛЗНЪНДгЖјЪЕЯжВЛЭЌЕФДЋЪфгявхЁЃ
ЁЁЁЁ
Kafka delivery guarantee гаетУДМИжжПЩФмЕФdelivery guaranteeЃК
At most once ЯћЯЂПЩФмЛсЖЊЃЌЕЋОјВЛЛсжиИДДЋЪф At least one ЯћЯЂОјВЛЛсЖЊЃЌЕЋПЩФмЛсжиИДДЋЪф Exactly once УПЬѕЯћЯЂПЯЖЈЛсБЛДЋЪфвЛДЮЧвНіДЋЪфвЛДЮЃЌКмЖрЪБКђетЪЧгУЛЇЫљЯывЊЕФЁЃ ЕБProducerЯђbrokerЗЂЫЭЯћЯЂЪБЃЌвЛЕЉетЬѕЯћЯЂБЛcommitЃЌвђЪ§replicationЕФДцдкЃЌЫќОЭВЛЛсЖЊЁЃЕЋЪЧШчЙћProducerЗЂЫЭЪ§ОнИјbrokerКѓЃЌгіЕНЭјТчЮЪЬтЖјдьГЩЭЈаХжаЖЯЃЌФЧProducerОЭЮоЗЈХаЖЯИУЬѕЯћЯЂЪЧЗёвбОcommitЁЃЫфШЛKafkaЮоЗЈШЗЖЈЭјТчЙЪеЯЦкМфЗЂЩњСЫЪВУДЃЌЕЋЪЧProducerПЩвдЩњГЩвЛжжРрЫЦгкжїМќЕФЖЋЮїЃЌЗЂЩњЙЪеЯЪБУнЕШадЕФжиЪдЖрДЮЃЌетбљОЭзіЕНСЫExactly
onceЁЃНижЙЕНФПЧА(Kafka 0.8.2АцБОЃЌ2015-03-04)ЃЌетвЛFeatureЛЙВЂЮДЪЕЯжЃЌгаЯЃЭћдкKafkaЮДРДЕФАцБОжаЪЕЯжЁЃЃЈЫљвдФПЧАФЌШЯЧщПіЯТвЛЬѕЯћЯЂДгProducerЕНbrokerЪЧШЗБЃСЫAt
least onceЃЌПЩЭЈЙ§ЩшжУProducerвьВНЗЂЫЭЪЕЯжAt most onceЃЉЁЃ НгЯТРДЬжТлЕФЪЧЯћЯЂДгbrokerЕНConsumerЕФdelivery guaranteeгявхЁЃЃЈНіеыЖдKafka
consumer high level APIЃЉЁЃConsumerдкДгbrokerЖСШЁЯћЯЂКѓЃЌПЩвдбЁдёcommitЃЌИУВйзїЛсдкZookeeperжаБЃДцИУConsumerдкИУPartitionжаЖСШЁЕФЯћЯЂЕФoffsetЁЃИУConsumerЯТвЛДЮдйЖСИУPartitionЪБЛсДгЯТвЛЬѕПЊЪМЖСШЁЁЃШчЮДcommitЃЌЯТвЛДЮЖСШЁЕФПЊЪМЮЛжУЛсИњЩЯвЛДЮcommitжЎКѓЕФПЊЪМЮЛжУЯрЭЌЁЃЕБШЛПЩвдНЋConsumerЩшжУЮЊautocommitЃЌМДConsumerвЛЕЉЖСЕНЪ§ОнСЂМДздЖЏcommitЁЃШчЙћжЛЬжТлетвЛЖСШЁЯћЯЂЕФЙ§ГЬЃЌФЧKafkaЪЧШЗБЃСЫExactly
onceЁЃЕЋЪЕМЪЪЙгУжагІгУГЬађВЂЗЧдкConsumerЖСШЁЭъЪ§ОнОЭНсЪјСЫЃЌЖјЪЧвЊНјааНјвЛВНДІРэЃЌЖјЪ§ОнДІРэгыcommitЕФЫГађдкКмДѓГЬЖШЩЯОіЖЈСЫЯћЯЂДгbrokerКЭconsumerЕФdelivery
guarantee semanticЁЃ ЖСЭъЯћЯЂЯШcommitдйДІРэЯћЯЂЁЃетжжФЃЪНЯТЃЌШчЙћConsumerдкcommitКѓЛЙУЛРДЕУМАДІРэЯћЯЂОЭcrashСЫЃЌЯТДЮжиаТПЊЪМЙЄзїКѓОЭЮоЗЈЖСЕНИеИевбЬсНЛЖјЮДДІРэЕФЯћЯЂЃЌетОЭЖдгІгкAt
most once ЖСЭъЯћЯЂЯШДІРэдйcommitЁЃетжжФЃЪНЯТЃЌШчЙћдкДІРэЭъЯћЯЂжЎКѓcommitжЎЧАConsumer crashСЫЃЌЯТДЮжиаТПЊЪМЙЄзїЪБЛЙЛсДІРэИеИеЮДcommitЕФЯћЯЂЃЌЪЕМЪЩЯИУЯћЯЂвбОБЛДІРэЙ§СЫЁЃетОЭЖдгІгкAt
least onceЁЃдкКмЖрЪЙгУГЁОАЯТЃЌЯћЯЂЖМгавЛИіжїМќЃЌЫљвдЯћЯЂЕФДІРэЭљЭљОпгаУнЕШадЃЌМДЖрДЮДІРэетвЛЬѕЯћЯЂИњжЛДІРэвЛДЮЪЧЕШаЇЕФЃЌФЧОЭПЩвдШЯЮЊЪЧExactly
onceЁЃЃЈБЪепШЯЮЊетжжЫЕЗЈБШНЯЧЃЧПЃЌБЯОЙЫќВЛЪЧKafkaБОЩэЬсЙЉЕФЛњжЦЃЌжїМќБОЩэвВВЂВЛФмЭъШЋБЃжЄВйзїЕФУнЕШадЁЃЖјЧвЪЕМЪЩЯЮвУЧЫЕdelivery
guarantee гявхЪЧЬжТлБЛДІРэЖрЩйДЮЃЌЖјЗЧДІРэНсЙћдѕбљЃЌвђЮЊДІРэЗНЪНЖржжЖрбљЃЌЮвУЧВЛгІИУАбДІРэЙ§ГЬЕФЬиадЁЊЁЊШчЪЧЗёУнЕШадЃЌЕБГЩKafkaБОЩэЕФFeatureЃЉ ШчЙћвЛЖЈвЊзіЕНExactly onceЃЌОЭашвЊаЕїoffsetКЭЪЕМЪВйзїЕФЪфГіЁЃОЕфЕФзіЗЈЪЧв§ШыСННзЖЮЬсНЛЁЃШчЙћФмШУoffsetКЭВйзїЪфШыДцдкЭЌвЛИіЕиЗНЃЌЛсИќМђНрКЭЭЈгУЁЃетжжЗНЪНПЩФмИќКУЃЌвђЮЊаэЖрЪфГіЯЕЭГПЩФмВЛжЇГжСННзЖЮЬсНЛЁЃБШШчЃЌConsumerФУЕНЪ§ОнКѓПЩФмАбЪ§ОнЗХЕНHDFSЃЌШчЙћАбзюаТЕФoffsetКЭЪ§ОнБОЩэвЛЦ№аДЕНHDFSЃЌФЧОЭПЩвдБЃжЄЪ§ОнЕФЪфГіКЭoffsetЕФИќаТвЊУДЖМЭъГЩЃЌвЊУДЖМВЛЭъГЩЃЌМфНгЪЕЯжExactly
onceЁЃЃЈФПЧАОЭhigh level APIЖјбдЃЌoffsetЪЧДцгкZookeeperжаЕФЃЌЮоЗЈДцгкHDFSЃЌЖјlow
level APIЕФoffsetЪЧгЩздМКШЅЮЌЛЄЕФЃЌПЩвдНЋжЎДцгкHDFSжаЃЉ змжЎЃЌKafkaФЌШЯБЃжЄAt least onceЃЌВЂЧвдЪаэЭЈЙ§ЩшжУProducerвьВНЬсНЛРДЪЕЯжAt
most onceЁЃЖјExactly onceвЊЧѓгыЭтВПДцДЂЯЕЭГазїЃЌавдЫЕФЪЧKafkaЬсЙЉЕФoffsetПЩвдЗЧГЃжБНгЗЧГЃШнвзЕУЪЙгУетжжЗНЪНЁЃ |








