| SparkЪЧвЛИіПьЫйЕФЁЂЭЈгУЕФЗжВМЪНМЦЫуЯЕЭГЃЌЖјЗжВМЪНЕФЬиадОЭвтЮЖзХЃЌБиШЛДцдкНкЕуМфЕФЭЈаХЁЃБОЮФжївЊНщЩмВЛЭЌЕФSparkзщМўжЎМфЪЧШчКЮЭЈЙ§RPCЃЈRemote
Procedure Call) НјааЕуЖдЕуЭЈаХЕФЃЌЗжЮЊШ§ИіеТНкЃК
Spark RPCЕФМђЕЅЪОР§КЭЪЕМЪгІгУЃЛ
Spark RPCФЃПщЕФЩшМЦдРэЃЛ
Spark RPCКЫаФММЪѕзмНсЁЃ
вЛЁЂSpark RPCЕФМђЕЅЪОР§КЭЪЕМЪгІгУ
SparkЕФRPCжївЊдкСНИіФЃПщжаЃК
дкSpark-coreжаЃЌжївЊГадиСЫИќКУЕФЗтзАserverКЭclientЕФзїгУЃЌвдМАКЭscalaгябдЕФШкКЯЃЌЫќвРРЕгкФЃПщorg.apache.spark.spark-network-commonЃЛ
дкorg.apache.spark.spark-network-commonжаЃЌИУФЃПщЪЧjavaгябдБраДЕФЃЌзюаТАцБОЪЧЛљгкnetty4ПЊЗЂЕФЃЌЬсЙЉШЋЫЋЙЄЁЂЖрТЗИДгУI/OФЃаЭЕФSocket
I/OФмСІЃЌSparkЕФДЋЪфавщНсЙЙЃЈwire protocolЃЉвВЪЧздЖЈвхЕФЁЃ
ЮЊСЫИќКУЕФСЫНтSpark RPCЕФФкВПЪЕЯжЯИНкЃЌЮвЛљгкSpark 2.1АцБОГщРыСЫRPCЭЈаХЕФВПЗжЃЌЕЅЖРЦєСЫвЛИіЯюФПЃЌЗХЕНСЫgithubвдМАЗЂВМЕНMavenжабыВжПтзібЇЯАЪЙгУЃЌЬсЙЉСЫБШНЯКУЕФЩЯЪжЮФЕЕЁЂВЮЪ§ЩшжУКЭадФмЦРЙРЁЃЯТУцОЭЭЈЙ§етИіФЃПщЖдSpark
RPCЯШзівЛИіИаадЕФШЯЪЖЁЃ
вдЯТЕФДњТыОљПЩвддкkraps-rpcевЕНЁЃ
1.1 МђЕЅЪОР§
МйЩшЮвУЧвЊПЊЗЂвЛИіHelloЗўЮёЃЌПЭЛЇЖЫПЩвдДЋЪфstringЃЌЗўЮёЖЫЯьгІhiЛђепbyeЃЌВЂechoЛиШЅЪфШыЕФstringЁЃ
ЕквЛВНЃЌЖЈвхвЛИіHelloEndpointМЬГаздRpcEndpointБэУїПЩвдВЂЗЂЕФЕїгУИУЗўЮёЃЌШчЙћМЬГаздThreadSafeRpcEndpointдђБэУїИУEndpointВЛдЪаэВЂЗЂЁЃ
class HelloEndpoint(override
val rpcEnv: RpcEnv) extends RpcEndpoint {
override def onStart(): Unit = {
println("start hello endpoint")
}
override def receiveAndReply(context: RpcCallContext):
PartialFunction[Any, Unit] = {
case SayHi(msg) => {
println(s"receive $msg")
context.reply(s"hi, $msg")
}
case SayBye(msg) => {
println(s"receive $msg")
context.reply(s"bye, $msg")
}
}
override def onStop(): Unit = {
println("stop hello endpoint")
}
}
case class SayHi(msg: String)
case class SayBye(msg: String) |
КЭJavaДЋЭГЕФRPCНтОіЗНАИЖдБШЃЌПЩвдПДГіетРяВЛгУЖЈвхНгПкЛђепЗНЗЈБъЪОЃЈБШШчЭЈГЃЕФidЛђепnameЃЉЃЌЪЙгУscalaЕФФЃЪНЦЅХфНјааЗНЗЈЕФТЗгЩЁЃЫфШЛЕуЖдЕуЭЈаХЕФЦѕдМНЛЛЛЪмжЦгкгябдЃЌетРяОЭЪЧSayHiКЭSayByeСНИіcase
classЃЌЕЋЪЧSpark RPCЖЈЮЛгкФкВПзщМўЭЈаХЃЌЫљвдЮоЩЫДѓбХЁЃ
ЕкЖўВНЃЌАбИеИеПЊЗЂКУЕФEndpointНЛИјSpark RPCЙмРэЦфЩњУќжмЦкЃЌгУгкЯьгІЭтВПЧыЧѓЁЃRpcEnvServerConfigПЩвдЖЈвхвЛаЉВЮЪ§ЁЂserverУћГЦЃЈНіНіЪЧвЛИіБъЪЖЃЉЁЂbindЕижЗКЭЖЫПкЁЃЭЈЙ§NettyRpcEnvFactoryетИіЙЄГЇЗНЗЈЃЌЩњГЩRpcEnvЃЌRpcEnvЪЧећИіSpark
RPCЕФКЫаФЫљдкЃЌКѓЮФЛсЯъЯИеЙПЊЃЌЭЈЙ§setupEndpointНЋЁБhello-serviceЁБетИіУћзжКЭЕквЛВНЖЈвхЕФEndpointАѓЖЈЃЌКѓајclientЕїгУТЗгЩЕНетИіEndpointОЭашвЊЁБhello-serviceЁБетИіУћзжЁЃЕїгУawaitTerminationРДзшШћЗўЮёЖЫМрЬ§ЧыЧѓВЂЧвДІРэЁЃ
val config =
RpcEnvServerConfig(new RpcConf(), "hello-server",
"localhost", 52345)
val rpcEnv: RpcEnv = NettyRpcEnvFactory.create(config)
val helloEndpoint: RpcEndpoint = new HelloEndpoint(rpcEnv)
rpcEnv.setupEndpoint("hello-service",
helloEndpoint)
rpcEnv.awaitTermination() |
ЕкШ§ВНЃЌПЊЗЂвЛИіclientЕїгУИеИеЦєЖЏЕФserverЃЌЪзЯШRpcEnvClientConfigКЭRpcEnvЖМЪЧБиаыЕФЃЌШЛКѓЭЈЙ§ИеИеЬсЕНЕФЁБhello-serviceЁБУћзжаТНЈвЛИідЖГЬEndpointЕФв§гУЃЈRefЃЉЃЌПЩвдПДзіЪЧstubЃЌгУгкЕїгУЃЌетРяЪзЯШеЙЪОЭЈЙ§вьВНЕФЗНЪНРДзіЧыЧѓЁЃ
val rpcConf
= new RpcConf()
val config = RpcEnvClientConfig (rpcConf, " hello-client")
val rpcEnv: RpcEnv = NettyRpcEnvFactory.create (config)
val endPointRef: RpcEndpointRef = rpcEnv.setupEndpointRef (RpcAddress ("localhost",
52345), "hell-service")
val future: Future[String] = endPointRef.ask [String] (SayHi("neo"))
future.onComplete {
case scala.util.Success(value) = > println(s"Got
the result = $value")
case scala.util.Failure(e) = > println (s"Got
error: $e")
}
Await.result (future, Duration.apply ("30s")) |
вВПЩвдЭЈЙ§ЭЌВНЕФЗНЪНЃЌдкзюаТЕФSparkжаaskWithRetryЪЕМЪвбИќУћЮЊaskSyncЁЃ
| val result =
endPointRef.askWithRetry [String] (SayBye ("neo")) |
етОЭЪЧSpark RPCЕФЭЈаХЙ§ГЬЃЌЪЙгУЦ№РДвзгУадПЩЯыЖјжЊЃЌЗЧГЃМђЕЅЃЌRPCПђМмЦСБЮСЫSocket
I/OФЃаЭЁЂЯпГЬФЃаЭЁЂађСаЛЏ/ЗДађСаЛЏЙ§ГЬЁЂЪЙгУnettyзіСЫАќЪЖБ№ЃЌГЄСЌНгЃЌЭјТчжиСЌжиЪдЕШЛњжЦЁЃ
1.2 ЪЕМЪгІгУ
дкSparkФкВПЃЌКмЖрЕФEndpointвдМАEndpointRefгыжЎЭЈаХЖМЪЧЭЈЙ§етжжаЮЪНЕФЃЌОйР§РДЫЕБШШчdriverКЭexecutorжЎМфЕФНЛЛЅгУЕНСЫаФЬјЛњжЦЃЌЪЙгУHeartbeatReceiverРДЪЕЯжЃЌетвВЪЧвЛИіEndpointЃЌЫќЕФзЂВсдкSparkContextГѕЪМЛЏЕФЪБКђзіЕФЃЌДњТыШчЯТЃК
| _heartbeatReceiver
= env.rpcEnv.setupEndpoint (HeartbeatReceiver.ENDPOINT_NAME,
new HeartbeatReceiver(this)) |
ЖјЫќЕФЕїгУдкExecutorФкЕФЗНЪНШчЯТЃК
val message
= Heartbeat( executorId, accumUpdates.toArray,
env.blockManager.blockManagerId)
val response = heartbeatReceiverRef.askWithRetry [HeartbeatResponse] (message,
RpcTimeou t(conf, "spark.executor.heartbeatInterval",
"10s")) |
ЖўЁЂSpark RPCФЃПщЕФЩшМЦдРэ
ЪзЯШЫЕУїЯТЃЌздSpark 2.0КѓвбОАбAkkaетИіRPCПђМмАўРыГіШЅСЫЃЈЯъЯИМћSPARK-5293ЃЉЃЌдвђКмМђЕЅЃЌвђЮЊКмЖргУЛЇЛсЪЙгУAkkaзіЯћЯЂДЋЕнЃЌФЧУДОЭЛсКЭSparkФкЧЖЕФАцБОВњЩњГхЭЛЃЌЖјSparkвВНіНігУСЫAkkaзіRPCЃЌЫљвд2.0жЎКѓЃЌЛљгкЕзВуЕФorg.apache.spark.spark-network-commonФЃПщЪЕЯжСЫвЛИіРрЫЦAkka
ActorЯћЯЂДЋЕнФЃЪНЕФscalaФЃПщЃЌЗтзАдкСЫcoreРяУцЃЌkraps-rpcвВОЭЪЧАбетИіВПЗжДгcoreРяУцАўРыГіРДЖРСЂСЫвЛИіЯюФПЁЃ
ЫфШЛАўРыСЫAkkaЃЌЕЋЪЧЛЙЪЧбиЯЎСЫActorФЃЪНжаЕФвЛаЉИХФюЃЌдкЯждкЕФSpark RPCжагаШчЯТгГЩфЙиЯЕЁЃ
RpcEndpoint
=> Actor
RpcEndpointRef => ActorRef
RpcEnv => ActorSystem |
ЕзВуЭЈаХШЋВПЪЙгУnettyНјааСЫЬцЛЛЃЌЪЙгУЕФЪЧorg.apache.spark.spark-network-commonетИіФкВПlibЁЃ
2.1 РрЭМЗжЮі
етРяЯШЩЯвЛИіUMLЭМеЙЪОСЫSpark RPCФЃПщФкЕФРрЙиЯЕЃЌАзЩЋЕФЪЧSpark-coreжаЕФscalaРрЃЌЛЦЩЋЕФЪЧorg.apache.spark.spark-network-commonжаЕФjavaРрЁЃ
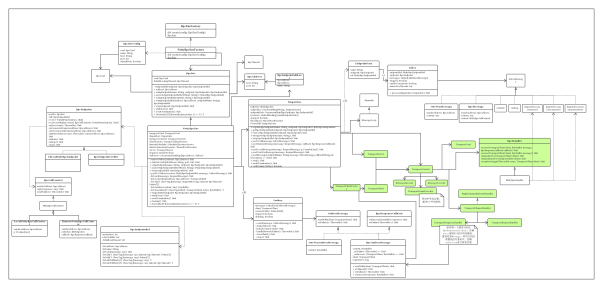
ВЛвЊБЛетеХЭМЫљЯХЕЙЃЌОЙ§ЯТУцЕФНтЪЭЗжЮіЃЌЯраХЖСепПЩвдСьЛсЦфФкКЃЌВЛгУЯИОПЦфЩшМЦЕФКЯРэЖШЃЌSparkЪЧвЛИіЗЂеЙКмПьЁЂВЛЖЯбнНјЕФЯюФПЃЌДњТыВЛЪЧвЛГЩВЛБфЕФЃЌГжајБфЛЏЪЧвЛЖЈЕФЁЃ
RpcEndpointКЭRpcCallContext
ЯШПДзюзѓВрЕФRpcEndpointЃЌRpcEndpointЪЧвЛИіПЩвдЯьгІЧыЧѓЕФЗўЮёЃЌКЭAkkaжаЕФActorРрЫЦЃЌДгЫќЕФЬсЙЉЕФЗНЗЈЧЉУћЃЈШчЯТЃЉПЩвдПДГіЃЌreceiveЗНЗЈЪЧЕЅЯђЗНЪНЕФЃЌПЩвдБШзїUDPЃЌЖјreceiveAndReplyЪЧгІД№ЗНЪНЕФЃЌПЩвдБШзїTCPЁЃЫќЕФзгРрЪЕЯжПЩвдбЁдёадЕФИВИЧетСНИіКЏЪ§ЃЌЮвУЧЕквЛеТЪЕЯжЕФHelloEndpointвдМАSparkжаЕФHeartbeatReceiverЖМЪЧЫќЕФзгРрЁЃ
def receive:
PartialFunction[Any, Unit] = {
case _ => throw new RpcException(self + "
does not implement 'receive'")
}
def receiveAndReply(context: RpcCallContext):
PartialFunction[Any, Unit] = {
case _ => context.sendFailure(new RpcException(self
+ " won't reply anything"))
} |
ЦфжаRpcCallContextЪЧгУгкЗжРыКЫаФвЕЮёТпМКЭЕзВуДЋЪфЕФЧХНгЗНЗЈЃЌетвВПЩвдПДГіSpark
RPCЖргУзщКЯЃЌОлКЯвдМАЛиЕїcallbackЕФЩшМЦФЃЪНРДзіOOГщЯѓЃЌетбљПЩвдАўРывЕЮёТпМ->RPCЗтзАЃЈSpark-coreФЃПщФкЃЉ->ЕзВуЭЈаХЃЈspark-network-commonЃЉШ§епЁЃRpcCallContextПЩвдгУгкЛиИДе§ГЃЕФЯьгІвдМАДэЮѓвьГЃЃЌР§ШчЃК
dreply(response:
Any) // ЛиИДвЛИіmessageЃЌПЩвдЪЧвЛИіcase classЁЃ
sendFailure(e: Throwable) // ЛиИДвЛИівьГЃЃЌПЩвдЪЧExceptionЕФзгРрЃЌгЩгкSpark
RPCФЌШЯВЩгУJavaађСаЛЏЗНЪНЃЌЫљвдвьГЃПЩвдЭъећЕФдкПЭЛЇЖЫЛЙдВЂЧвзїЮЊcause re-throwГіШЅЁЃ |
RpcCallContextвВЗжЮЊСЫСНИізгРрЃЌЗжБ№ЪЧLocalNettyRpcCallContextКЭRemoteNettyRpcCallContextЃЌетИіжївЊЪЧПђМмФкВПЪЙгУЃЌШчЙћЪЧБОЕиОЭзпLocalNettyRpcCallContextжБНгЕїгУEndpointМДПЩЃЌЗёдђОЭзпRemoteNettyRpcCallContextашвЊЭЈЙ§RPCКЭдЖГЬНЛЛЅЃЌетЕувВЬхЯжСЫRPCЕФКЫаФИХФюЃЌОЭЪЧШчКЮжДааСэЭтвЛИіЕижЗПеМфЩЯЕФКЏЪ§ЁЂЗНЗЈЃЌОЭЗТЗ№дкБОЕиЕїгУвЛбљЁЃ
СэЭтЃЌRpcEndpointЛЙЬсЙЉСЫвЛЯЕСаЛиЕїКЏЪ§ИВИЧЁЃ
onError
onConnected
onDisconnected
onNetworkError
onStart
onStop
stop
СэЭташвЊзЂвтЯТЃЌЫќЕФвЛИізгРрЪЧThreadSafeRpcEndpointЃЌКмЖрSparkжаЕФEndpointМЬГаСЫетИіРрЃЌSpark
RPCПђМмЖдетжжEndpointВЛзіВЂЗЂДІРэЃЌвВОЭЪЧЭЌвЛЪБМфжЛдЪаэвЛИіЯпГЬдкзіЕїгУЁЃ
ЛЙгавЛИіФЌШЯЕФRpcEndpointНазіRpcEndpointVerifierЃЌУПвЛИіRpcEnvГѕЪМЛЏЕФЪБКђЖМЛсзЂВсЩЯетИіEndpointЃЌвђЮЊПЭЛЇЖЫЕФЕїгУУПДЮЖМашвЊЯШбЏЮЪЗўЮёЖЫЪЧЗёДцдкФГвЛИіEndpointЁЃ
RpcEndpointRef
RpcEndpointRefРрЫЦгкAkkaжаActorRefЃЌЙЫУћЫМвхЃЌЫќЪЧRpcEndpointЕФв§гУЃЌЬсЙЉЕФЗНЗЈsendЕШЭЌгк!,
askЗНЗЈЕШЭЌгк?ЃЌsendгУгкЕЅЯђЗЂЫЭЧыЧѓЃЈRpcEndpointжаЕФreceiveЯьгІЫќЃЉЃЌЬсЙЉfire-and-forgetгявхЃЌЖјaskЬсЙЉЧыЧѓЯьгІЕФгявхЃЈRpcEndpointжаЕФreceiveAndReplyЯьгІЫќЃЉЃЌФЌШЯЪЧашвЊЗЕЛиresponseЕФЃЌДјгаГЌЪБЛњжЦЃЌПЩвдЭЌВНзшШћЕШД§ЃЌвВПЩвдЗЕЛивЛИіFutureОфБњЃЌВЛзшШћЗЂЦ№ЧыЧѓЕФЙЄзїЯпГЬЁЃ
RpcEndpointRefЪЧПЭЛЇЖЫЗЂЦ№ЧыЧѓЕФШыПкЃЌЫќПЩвдДгRpcEnvжаЛёШЁЃЌВЂЧвДЯУїЕФзіБОЕиЕїгУЛђепRPCЁЃ
RpcEnvКЭNettyRpcEnv
РрПтжазюКЫаФЕФОЭЪЧRpcEnvЃЌИеИеЬсЕНСЫетОЭЪЧActorSystemЃЌЗўЮёЖЫКЭПЭЛЇЖЫЖМПЩвдЪЙгУЫќРДзіЭЈаХЁЃ
Ждгкserver sideРДЫЕЃЌRpcEnvЪЧRpcEndpointЕФдЫааЛЗОГЃЌИКд№RpcEndpointЕФећИіЩњУќжмЦкЙмРэЃЌЫќПЩвдзЂВсЛђепЯњЛйEndpointЃЌНтЮіTCPВуЕФЪ§ОнАќВЂЗДађСаЛЏЃЌЗтзАГЩRpcMessageЃЌВЂЧвТЗгЩЧыЧѓЕНжИЖЈЕФEndpointЃЌЕїгУвЕЮёТпМДњТыЃЌШчЙћEndpointашвЊЯьгІЃЌАбЗЕЛиЕФЖдЯѓађСаЛЏКѓЭЈЙ§TCPВудйДЋЪфЕНдЖГЬЖдЖЫЃЌШчЙћEndpointЗЂЩњвьГЃЃЌФЧУДЕїгУRpcCallContext.sendFailureРДАбвьГЃЗЂЫЭЛиШЅЁЃ
Ждclient sideРДЫЕЃЌЭЈЙ§RpcEnvПЩвдЛёШЁRpcEndpointв§гУЃЌвВОЭЪЧRpcEndpointRefЕФЁЃ
RpcEnvЪЧКЭОпЬхЕФЕзВуЭЈаХФЃПщНЛЛЅЕФИКд№ШЫЃЌЫќЕФАщЩњЖдЯѓАќКЌДДНЈRpcEnvЕФЗНЗЈЃЌЧЉУћШчЯТЃК
def create(
name: String,
bindAddress: String,
advertiseAddress: String,
port: Int,
conf: SparkConf,
securityManager: SecurityManager,
numUsableCores: Int,
clientMode: Boolean): RpcEnv = {
val config = RpcEnvConfig(conf, name, bindAddress,
advertiseAddress, port, securityManager,
numUsableCores, clientMode)
new NettyRpcEnvFactory().create(config)
} |
RpcEnvЕФДДНЈгЩRpcEnvFactoryИКд№ЃЌRpcEnvFactoryФПЧАжЛгавЛИізгРрЪЧNettyRpcEnvFactoryЃЌдРДЛЙгаAkkaRpcEnvFactoryЁЃNettyRpcEnvFactory.createЗНЗЈвЛЕЉЕїгУОЭЛсСЂМДдкbindЕФaddressКЭportЩЯЦєЖЏserverЁЃ
ЫќвРРЕЕФRpcEnvConfigОЭЪЧвЛИіАќКЌСЫSparkConfвдМАвЛаЉВЮЪ§ЃЈkraps-rpcжаИќУћЮЊRpcConfЃЉЁЃRpcEnvЕФВЮЪ§ЖМашвЊДгRpcEnvConfigжаФУЃЌзюЛљБОЕФhostnameКЭportЃЌЛЙгаИпМЖаЉЕФСЌНгГЌЪБЁЂжиЪдДЮЪ§ЁЂReactorЯпГЬГиДѓаЁЕШЕШЁЃ
ЯТУцПДПДRpcEnvзюГЃгУЕФСНИіЗНЗЈЃК
// зЂВсendpointЃЌБиаыжИЖЈУћГЦЃЌПЭЛЇЖЫТЗгЩОЭППетИіУћГЦРДевendpoint
def setupEndpoint(name: String, endpoint: RpcEndpoint):
RpcEndpointRef
// ФУЕНвЛИіendpointЕФв§гУ
def setupEndpointRef(address: RpcAddress, endpointName:
String): RpcEndpointRef |
NettyRpcEnvгЩNettyRpcEnvFactory.createДДНЈЃЌетЪЧећИіSpark
coreКЭorg.apache.spark.spark-network-commonЕФЧХСКЃЌФкВПleverageЕзВуЬсЙЉЕФЭЈаХФмСІЃЌЭЌЪБАќзАСЫвЛИіРрActorЕФгявхЁЃЩЯУцСНИіКЫаФЕФЗНЗЈЃЌsetupEndpointЛсдкDispatcherжазЂВсEndpointЃЌsetupEndpointRefЛсЯШШЅЕїгУRpcEndpointVerifierГЂЪдбщжЄБОЕиЛђепдЖГЬЪЧЗёДцдкФГИіendpointЃЌШЛКѓдйДДНЈRpcEndpointRefЁЃИќЖрЙигкЗўЮёЖЫЁЂПЭЛЇЖЫЕїгУЕФЯИНкНЋдкЪБађЭМжаВћЪіЃЌетРяВЛдйеЙПЊЁЃ
DispatcherКЭInbox
NettyRpcEnvжаАќКЌDispatcherЃЌжївЊеыЖдЗўЮёЖЫЃЌАяжњТЗгЩЕНе§ШЗЕФRpcEndpointЃЌВЂЧвЕїгУЦфвЕЮёТпМЁЃ
етРяашвЊЯШВћЪіЯТReactorФЃаЭЃЌSpark RPCЕФSocket I/OвЛИіЕфаЭЕФReactorФЃаЭЕФЃЌЕЋЪЧНсКЯСЫActor
patternжаЕФmailboxЃЌПЩЮНЪЧвЛжжЛьКЯЕФЪЕЯжЗНЪНЁЃ
ЪЙгУReactorФЃаЭЃЌгЩЕзВуnettyДДНЈЕФEventLoopзіI/OЖрТЗИДгУЃЌетРяЪЙгУMultiple
ReactorsетжжаЮЪНЃЌШчЯТЭМЫљЪОЃЌДгnettyЕФНЧЖШЖјбдЃЌMain ReactorКЭSub ReactorЖдгІBossGroupКЭWorkerGroupЕФИХФюЃЌЧАепИКд№МрЬ§TCPСЌНгЁЂНЈСЂКЭЖЯПЊЃЌКѓепИКд№еце§ЕФI/OЖСаДЃЌЖјЭМжаЕФThreadPoolОЭЪЧЕФDispatcherжаЕФЯпГЬГиЃЌЫќРДНтёюПЊРДКФЪБЕФвЕЮёТпМКЭI/OВйзїЃЌетбљОЭПЩвдИќscalabeЃЌжЛашвЊЩйЪ§ЕФЯпГЬОЭПЩвдДІРэГЩЧЇЩЯЭђЕФСЌНгЃЌетжжЫМЯыЪЧБъзМЕФЗжжЮВпТдЃЌoffloadЗЧI/OВйзїЕНСэЭтЕФЯпГЬГиЁЃ
еце§ДІРэRpcEndpointЕФвЕЮёТпМдкThreadPoolРяУцЃЌжаМфППReactorЯпГЬжаЕФhandlerДІРэdecodeГЩRpcMessageЃЌШЛКѓЭЖЕнЕНInboxжаЃЌЫљвдcomputeЕФЙ§ГЬдкСэЭтЕФЯТУцНщЩмЕФDispatcherЯпГЬГиРяУцзіЁЃ
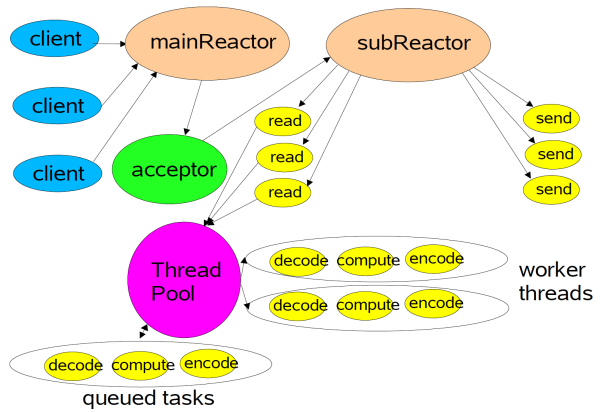
ИеИеЛЙЬсЕНСЫActor patternжаmailboxФЃЪНЃЌSpark RPCзюдчЦ№дДгкAkkaЃЌЫљвдНјЛЏЕНЯждкЃЌШдШЛСЫЪЙгУСЫетИіФЃЪНЁЃетРяОЭНщЩмInboxЃЌУПИіEndpointЖМгавЛИіInboxЃЌInboxРяУцгавЛИіInboxMessageЕФСДБэЃЌInboxMessageгаКмЖрзгРрЃЌПЩвдЪЧдЖГЬЕїгУЙ§РДЕФRpcMessageЃЌПЩвдЪЧдЖГЬЕїгУЙ§РДЕФfire-and-forgetЕФЕЅЯђЯћЯЂOneWayMessageЃЌЛЙПЩвдЪЧИїжжЗўЮёЦєЖЏЃЌСДТЗНЈСЂЖЯПЊЕШMessageЃЌетаЉMessageЖМЛсдкInboxФкВПЕФЗНЗЈФкзіФЃЪНЦЅХфЃЌЕїгУЯргІЕФRpcEndpointЕФКЏЪ§ЃЈЖМЪЧвЛвЛЖдгІЕФЃЉЁЃ
DispatcherжаАќКЌвЛИіMessageLoopЃЌЫќЖСШЁLinkedBlockingQueueжаЕФЭЖЕнRpcMessageЃЌИљОнПЭЛЇЖЫжИЖЈЕФEndpointБъЪЖЃЌевЕНEndpointЕФInboxЃЌШЛКѓЭЖЕнНјШЅЃЌгЩгкЪЧзшШћЖгСаЃЌЕБУЛгаЯћЯЂЕФЪБКђздШЛзшШћЃЌвЛЕЉгаЯћЯЂЃЌОЭПЊЪМЙЄзїЁЃDispatcherЕФThreadPoolИКд№ЯћЗбетаЉMessageЁЃ
DispatcherЕФThreadPoolЫќЪЙгУВЮЪ§spark.rpc.netty.dispatcher.numThreadsРДПижЦЪ§СПЃЌШчЙћkill
-3 УПИіSpark driverЛђепexecutorНјГЬЃЌЖМЛсПДЕНNИіdispatcherЯпГЬЃК
| "dispatcher-event-loop-0"
#26 daemon prio=5 os_prio=31 tid=0x00007f8877153800
nid=0x7103 waiting on condition [0x000000011f78b000] |
ФЧУДСэЭтЕФЮЪЬтЪЧЫЛсЕїгУDispatcherЗжЗЂMessageЕФЗНЗЈФиЃПД№АИЪЧRpcHandlerЕФзгРрNettyRpcHandlerЃЌетОЭЪЧReactorжаЕФЯпГЬзіЕФЪТЧщЁЃRpcHandlerЪЧЕзВуorg.apache.spark.spark-network-commonЬсЙЉЕФhandlerЃЌЕБдЖГЬЕФЪ§ОнАќНтЮіГЩЙІКѓЃЌЛсЕїгУетИіhandlerзіДІРэЁЃ
етбљОЭЭъГЩСЫвЛИіЭъШЋвьВНЕФСїГЬЃЌNetwork IOЭЈаХгЩЕзВуИКд№ЃЌШЛКѓгЩDispatcherЗжЗЂЃЌжЛвЊDispatcherжаЕФInboxMessageЕФСДБэзуЙЛДѓЃЌФЧУДОЭПЩвдШУDispatcherжаЕФThreadPoolТ§Т§ЯћЛЏЯћЯЂЃЌКЭЕзВуЕФIOНтёюПЊРДЃЌЭъШЋдкЖРСЂЕФЯпГЬжаЭъГЩЃЌвЛЕЉЭъГЩEndpointФкВПвЕЮёТпМЃЌРћгУRpcCallContextЛиЕїРДзіЯћЯЂЕФЗЕЛиЁЃ
Outbox
NettyRpcEnvжаАќКЌвЛИіConcurrentHashMap[RpcAddress, Outbox]ЃЌУПИідЖГЬEndpointЖМЖдгІвЛИіOutboxЃЌетКЭЩЯУцInboxвЃЯрКєгІЃЌЪЧвЛИіmailboxЫЦЕФЪЕЯжЗНЪНЁЃ
КЭInboxРрЫЦЃЌOutboxФкВПАќКЌвЛИіOutboxMessageЕФСДБэЃЌOutboxMessageгаСНИізгРрЃЌOneWayOutboxMessageКЭRpcOutboxMessageЃЌЗжБ№ЖдгІЕїгУRpcEndpointЕФreceiveКЭreceiveAndReplyЗНЗЈЁЃ
NettyRpcEnvжаЕФsendКЭaskЗНЗЈЛсЕїгУжИЖЈЕижЗOutboxжаЕФsendЗНЗЈЃЌЕБдЖГЬСЌНгЮДНЈСЂЪБЃЌЛсЯШНЈСЂСЌНгЃЌШЛКѓШЅЯћЛЏOutboxMessageЁЃ
ЭЌбљЃЌвЛИіЮЪЬтЪЧOutboxжаЕФsendЗНЗЈШчКЮНЋЯћЯЂЭЈЙ§Network IOЗЂЫЭГіШЅЃЌШчЙћЪЧaskЗНЗЈгжЪЧШчКЮЖСШЁдЖГЬЯьгІЕФФиЃПД№АИЪЧsendЗНЗЈЭЈЙ§org.apache.spark.spark-network-commonДДНЈЕФTransportClientЗЂЫЭГіШЅЯћЯЂЃЌгЩReactorЯпГЬИКд№ађСаЛЏВЂЧвЗЂЫЭГіШЅЃЌУПИіMessageЖМЛсЗЕЛивЛИіUUIDЃЌгЩЕзВуРДЮЌЛЄвЛИіЗЂЫЭГіШЅЯћЯЂгыЦфCallbackЕФHashMapЃЌЕБNettyЪеЕНЭъећЕФдЖГЬRpcResponseЪБКђЃЌЛиЕїЯьгІЕФCallbackЃЌзіЗДађСаЛЏЃЌНјЖјЛиЕїSpark
coreжаЕФвЕЮёТпМЃЌзіPromise/FutureЕФdoneЃЌЩЯВуЭЫГізшШћЁЃ
етвВЪЧвЛИівьВНЕФЙ§ГЬЃЌЗЂЫЭЯћЯЂЕНOutboxКѓЃЌжБНгЗЕЛиЃЌNetwork IOЭЈаХгЩЕзВуИКд№ЃЌвЛЕЉRPCЕїгУГЩЙІЛђепЪЇАмЃЌЖМЛсЛиЕїЩЯВуЕФКЏЪ§ЃЌзіЯргІЕФДІРэЁЃ
spark-network-commonжаЕФРр
етРяднВЛзіЙ§ЖрЕФеЙПЊЃЌЖМЪЧЛљгкNettyЕФЗтзАЃЌгааЫШЄЕФЖСепПЩвдздаадФЖСдДТыЃЌЕБШЛЛЙПЩвдВЮПМЮвжЎЧАПЊдДЕФNavi-pbrpcПђМмЕФДњТыЃЌЦфдРэЪЧЛљБОЯрЭЌЕФЁЃ
2.2 ЪБађЭМЗжЮі
ЗўЮёЦєЖЏ
ЛАВЛЖрЪіЃЌжБНгЩЯЭМЁЃ
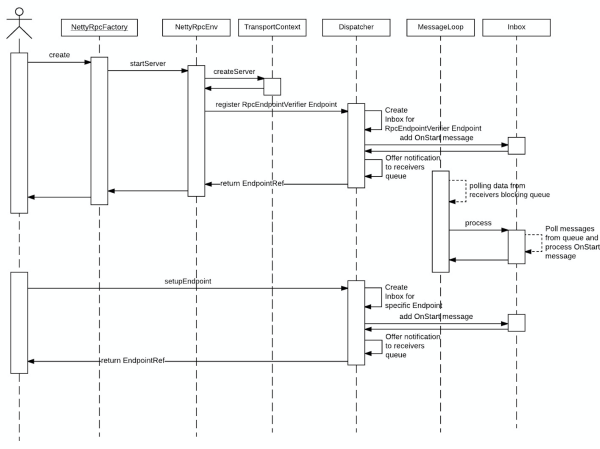
ЗўЮёЖЫЯьгІ
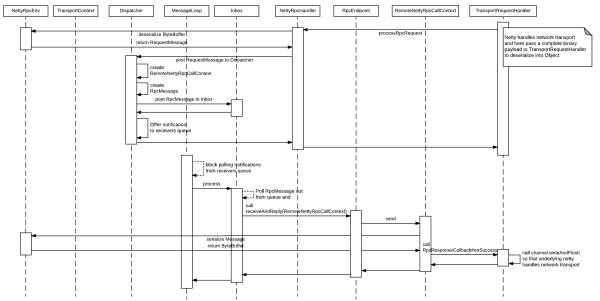
ЕквЛНзЖЮЃЌIOНгЪеЁЃTransportRequestHandlerЪЧnettyЕФЛиЕїhandlerЃЌЫќЛсИљОнwire
formatЃЈЯТЮФЛсНщЩмЃЉНтЮіКУвЛИіЭъећЕФЪ§ОнАќЃЌНЛИјNettyRpcEnvзіЗДађСаЛЏЃЌШчЙћЪЧRPCЕїгУЛсЙЙдьRpcMessageЃЌШЛКѓЛиЕїRpcHandlerЕФЗНЗЈДІРэRpcMessageЃЌФкВПЛсЕїгУDispatcherзіRpcMessageЕФЭЖЕнЃЌЗХЕНInboxжаЃЌЕНДЫНсЪјЁЃ
ЕкЖўНзЖЮЃЌIOЯьгІЁЃMessageLoopЛёШЁДјДІРэЕФRpcMessageЃЌНЛИјDispatcherжаЕФThreadPoolзіДІРэЃЌЪЕМЪОЭЪЧЕїгУRpcEndpointЕФвЕЮёТпМЃЌЭЈЙ§RpcCallContextНЋЯћЯЂађСаЛЏЃЌЭЈЙ§ЛиЕїКЏЪ§ЃЌИцЫпTransportRequestHandlerетгавЛИіЯћЯЂДІРэЭъБЯЃЌЯьгІЛиШЅЁЃ
етРяЧыжиЕуЬхЛсвьВНДІРэДјРДЕФБуРћЃЌЪЙгУReactorКЭActor mailboxЕФНсКЯЕФФЃЪНЃЌНтёюСЫЯћЯЂЕФЛёШЁвдМАДІРэТпМЁЃ
ПЭЛЇЖЫЧыЧѓ
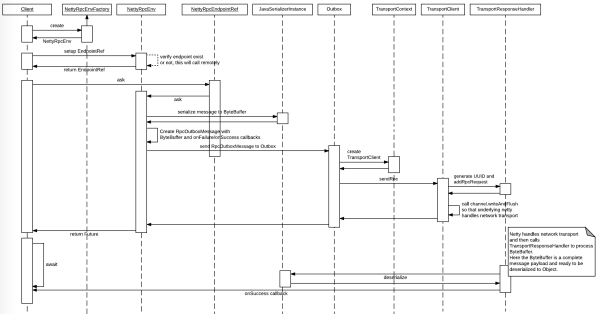
ПЭЛЇЖЫвЛАуашвЊЯШНЈСЂRpcEnvЃЌШЛКѓЛёШЁRpcEndpointRefЁЃ
ЕквЛНзЖЮЃЌIOЗЂЫЭЁЃРћгУRpcEndpointRefзіsendЛђепaskЖЏзїЃЌетРявдsendЮЊР§ЃЌsendЛсЯШНјааЯћЯЂЕФађСаЛЏЃЌШЛКѓЭЖЕнЕНжИЖЈЕижЗЕФOutboxжаЃЌOutboxШчЙћЗЂЯжСЌНгЮДНЈСЂдђЯШГЂЪдНЈСЂСЌНгЃЌШЛКѓЕїгУЕзВуЕФTransportClientЗЂЫЭЪ§ОнЃЌжБНгЭЈЙ§ИУnettyЕФAPIЭъГЩЃЌЭъГЩКѓМДПЩЗЕЛиЃЌетРяЗЕЛиСЫUUIDзїЮЊЯћЯЂЕФБъЪЖЃЌгУгкЯТвЛИіНзЖЮЕФЛиЕїЃЌЪЙгУЕФНЧЖШРДЫЕПЩвдЗЕЛивЛИіFutureЃЌПЭЛЇЖЫПЩвдзшШћЛђепМЬајзіЦфЫћВйзїЁЃ
ЕкЖўЃЌIOНгЪеЁЃTransportResponseHandlerНгЪеЕНдЖГЬЕФЯьгІКѓЃЌЛсЯШзіЗДађСаКХЃЌШЛКѓЛиЕїЕквЛНзЖЮЕФFutureЃЌЭъГЩЕїгУЃЌетИіЙ§ГЬШЋВПдкReactorЯпГЬжаЭъГЩЕФЃЌЭЈЙ§FutureзіЯпГЬМфЕФЭЈжЊЁЃ
Ш§ЁЂSpark RPCКЫаФММЪѕзмНс
Spark RPCзїЮЊRPCДЋЪфВубЁдёTCPавщЃЌзіПЩППЕФЁЂШЋЫЋЙЄЕФbinary streamЭЈЕРЁЃ
зівЛИіИпадФм/scalableЕФRPCЃЌашвЊФмЙЛТњзуЕквЛЃЌЗўЮёЖЫОЁПЩФмЖрЕФДІРэВЂЗЂЧыЧѓЃЌЕкЖўЃЌЭЌЪБОЁПЩФмЖЬЕФДІРэЭъБЯЁЃCPUКЭI/OжЎЧАЬьШЛДцдкзХВювьЃЌЭјТчДЋЪфЕФбгЪБВЛПЩПиЃЌCPUзЪдДБІЙѓЃЌЯЕЭГНјГЬ/ЯпГЬзЪдДБІЙѓЃЌЮЊСЫОЁПЩФмБмУтSocket
I/OзшШћЗўЮёЖЫКЭПЭЛЇЖЫЕїгУЃЌгавЛаЉФЃЪНЃЈpatternЃЉЪЧПЩвдгІгУЕФЁЃSpark RPCЕФI/O
ModelгЩгкВЩгУСЫNettyЃЌвђДЫЪЙгУЕФЕзВуЕФI/OЖрТЗИДгУЃЈI/O MultiplexingЃЉЛњжЦЃЌетРяПЩвдЭЈЙ§spark.rpc.io.modeВЮЪ§ЩшжУЃЌВЛЭЌЕФЦНЬЈЪЙгУЕФММЪѕВЛЭЌЃЌР§ШчlinuxЪЙгУepollЁЃ
ЯпГЬФЃаЭВЩгУMulti-Reactors + mailboxЕФвьВНЗНЪНРДДІРэЃЌдкЩЯЮФжавбОНщЩмЙ§ЁЃ
Schema DeclarationКЭађСаЛЏЗНУцЃЌSpark RPCФЌШЯВЩгУJava native
serializationЗНАИЃЌжївЊДгМцШнадКЭJVMЦНЬЈФкВПзщМўЭЈаХЃЌвдМАscalaгябдЕФШкКЯПМТЧЃЌЫљвдВЛОпБИПчгябдЭЈаХЕФФмСІЃЌадФмЩЯвВВЛЪЧзЗЧѓМЋжТЃЌФПЧАЛЙУЛгаЪЙгУKyroЕШИќКУађСаЛЏадФмКЭЪ§ОнДѓаЁЕФЗНАИЁЃ
авщНсЙЙЃЌSpark RPCВЩгУЫНгаЕФwire formatШчЯТЃЌВЩгУheadr+payloadЕФзщжЏЗНЪНЃЌheaderжаАќРЈећИіframeЕФГЄЖШЃЌmessageЕФРраЭЃЌЧыЧѓUUIDЁЃЮЊНтОіTCPеГАќКЭАыАќЮЪЬтЃЌвдМАзщжЏГЩЭъећЕФMessageЕФТпМЖМдкorg.apache.spark.network.protocol.MessageEncoderжаЁЃ

ЪЙгУwireshakeОпЬхЗжЮівЛЯТЁЃ
ЪзЯШПДвЛИіRPCЧыЧѓЃЌОЭЪЧЕїгУЕквЛеТЫЕЕФHelloEndpointЃЌПЭЛЇЖЫЕїгУЗжСНИіTCP SegmentДЋЪфЃЌетЪЧвђЮЊSparkЪЙгУnettyЕФЪБКђheaderКЭbodyЗжБ№writeAndFlushГіШЅЁЃ
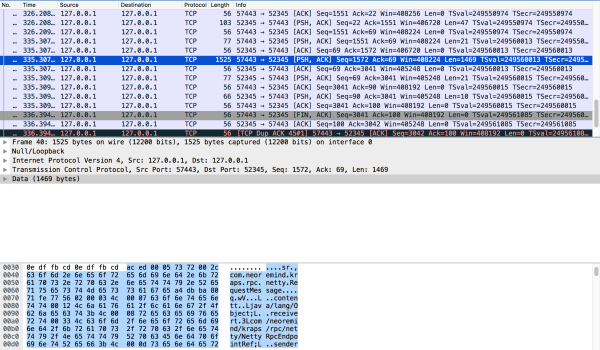
ЯТЭМЪЧЕквЛИіTCP segmentЃК
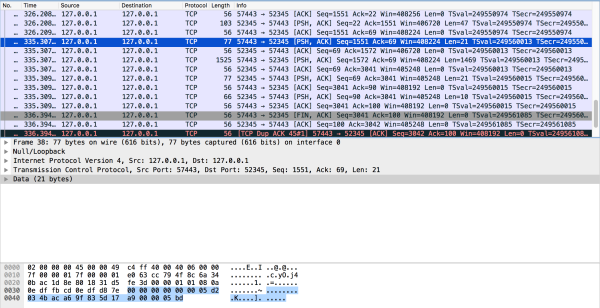
Р§згжаРЖЩЋЕФВПЗжЪЧheaderЃЌЭЗжаЕФзжНкНтЮіШчЯТЃК
| 00 00 00 00
00 00 05 d2 // ЪЎНјжЦ1490ЃЌЪЧећИіframeЕФГЄЖШ |
03вЛИізжНкБэЪОЕФЪЧRpcRequestЃЌУЖОйЖЈвхШчЯТЃК
RpcRequest(3)
RpcResponse(4)
RpcFailure(5)
StreamRequest(6)
StreamResponse(7)
StreamFailure(8),
OneWayMessage(9)
User(-1) |
УПИізжНкЕФвтвхШчЯТЃК
4b ac a6 9f
83 5d 17 a9 // 8ИізжНкЪЧUUID
05 bd // ЪЎНјжЦ1469ЃЌpayloadГЄЖШ |
ОпЬхЕФPayloadОЭГЄЯТУцетИібљзгЃЌПЩвдПДГіЪЙгУJava native serializationЃЌвЛИіМђЕЅЕФEchoЧыЧѓОЭга1469ИізжНкЃЌЛЙЪЧКмДѓЕФЃЌађСаЛЏЕФаЇТЪВЛИпЁЃЕЋЪЧSpark
RPCЖЈЮЛФкВПЭЈаХЃЌВЛЪЧвЛИіЭЈгУЕФRPCПђМмЃЌВЂЧвЪЙгУЕФСПЗЧГЃаЁЃЌЫљвдетЕуЯћКФвВОЭПЩвдКіТдСЫЃЌЛЙгаSpark
Structured StreamingЪЙгУИУађСаЛЏЗНЪНЃЌЦфадФмЛЙЪЧПЩвдТњзувЊЧѓЕФЁЃ
СэЭтЃЌзїепдкkraps-rpcжаЛЙИјSpark-rpcзіСЫвЛДЮадФмВтЪдЃЌОпЬхПЩвдВЮПМgithubЁЃ
змНс
зїепДгКУЦцЕФНЧЖШРДЩюЖШЭкОђСЫЯТSpark RPCЕФФкФЛЃЌВЂЧвДг2.1АцБОЕФSpark coreжаЖРСЂГіСЫвЛИізЈУХЕФЯюФПKraps-rpcЃЌЗХЕНСЫgithubвдМАЗЂВМЕНMavenжабыВжПтзібЇЯАЪЙгУЃЌЬсЙЉСЫБШНЯКУЕФЩЯЪжЮФЕЕЁЂВЮЪ§ЩшжУКЭадФмЦРЙРЃЌдкећКЯkraps-rpcЛЙЗЂЯжСЫвЛИіаЁЕФИФНјЕуЃЌИјSparkЬсСЫвЛИіPRЁЊЁЊ[SPARK-21701]ЃЌвбОБЛmergeЕНСЫжїИЩЃЌЫуЪЧcontributeЩчЧјСЫЃЈ10086ИіПЊаФЃЉЁЃ
НгзХЩюШыЦЪЮіСЫSpark RPCФЃПщФкЕФРрзщжЏЙиЯЕЃЌЪЙгУUMLРрЭМКЭЪБађЭМАяжњЖСепИќКУЕФРэНтвЛаЉКЫаФЕФИХФюЃЌАќРЈRpcEnvЃЌRpcEndpointЃЌRpcEndpointRefЕШЃЌвдМАI/OЕФЩшМЦФЃЪНЃЌАќРЈI/OЖрТЗИДгУЃЌReactorКЭActor
mailboxЕШЃЌетРяЛЙЪЧжиЕуЬсЯТSpark RPCЕФЩшМЦембЇЃЌРћгУnettyЧПДѓЕФSocket I/OФмСІЃЌЙЙНЈвЛИівьВНЕФЭЈаХПђМмЁЃзюКѓЃЌДгTCPВуЕФsegmentЖўНјжЦНЧЖШЗжЮіСЫwire
protocolЁЃ |






