| БрМЭЦМі: |
БОЮФРДздгкcnblogsЃЌжївЊНщЩмСЫSparkЕФЖЈвхЃЌМђЕЅЕФСїГЬЃЌдЫааСїГЬМАеЙЪОЃЌЖдгкНсЙћЕФЗжЮіЕШЕШЁЃ
|
|
1ЁЂ SparkдЫааМмЙЙ
1.1 ЪѕгяЖЈвх
lApplicationЃКSpark ApplicationЕФИХФюКЭHadoop MapReduceжаЕФРрЫЦЃЌжИЕФЪЧгУЛЇБраДЕФSparkгІгУГЬађЃЌАќКЌСЫвЛИіDriver
ЙІФмЕФДњТыКЭЗжВМдкМЏШКжаЖрИіНкЕуЩЯдЫааЕФExecutorДњТыЃЛ
lDriverЃКSparkжаЕФDriverМДдЫааЩЯЪіApplicationЕФmain()КЏЪ§ВЂЧвДДНЈSparkContextЃЌЦфжаДДНЈSparkContextЕФФПЕФЪЧЮЊСЫзМБИSparkгІгУГЬађЕФдЫааЛЗОГЁЃдкSparkжагЩSparkContextИКд№КЭClusterManagerЭЈаХЃЌНјаазЪдДЕФЩъЧыЁЂШЮЮёЕФЗжХфКЭМрПиЕШЃЛЕБExecutorВПЗждЫааЭъБЯКѓЃЌDriverИКд№НЋSparkContextЙиБеЁЃЭЈГЃгУSparkContextДњБэDriveЃЛ
lExecutorЃКApplicationдЫаадкWorker НкЕуЩЯЕФвЛИіНјГЬЃЌИУНјГЬИКд№дЫааTaskЃЌВЂЧвИКд№НЋЪ§ОнДцдкФкДцЛђепДХХЬЩЯЃЌУПИіApplicationЖМгаИїздЖРСЂЕФвЛХњExecutorЁЃдкSpark
on YarnФЃЪНЯТЃЌЦфНјГЬУћГЦЮЊCoarseGrainedExecutorBackendЃЌРрЫЦгкHadoop
MapReduceжаЕФYarnChildЁЃвЛИіCoarseGrainedExecutorBackendНјГЬгаЧвНігавЛИіexecutorЖдЯѓЃЌЫќИКд№НЋTaskАќзАГЩtaskRunnerЃЌВЂДгЯпГЬГижаГщШЁГівЛИіПеЯаЯпГЬдЫааTaskЁЃУПИіCoarseGrainedExecutorBackendФмВЂаадЫааTaskЕФЪ§СПОЭШЁОігкЗжХфИјЫќЕФCPUЕФИіЪ§СЫЃЛ
lCluster ManagerЃКжИЕФЪЧдкМЏШКЩЯЛёШЁзЪдДЕФЭтВПЗўЮёЃЌФПЧАгаЃК
StandaloneЃКSparkдЩњЕФзЪдДЙмРэЃЌгЩMasterИКд№зЪдДЕФЗжХфЃЛ Hadoop YarnЃКгЩYARNжаЕФResourceManagerИКд№зЪдДЕФЗжХфЃЛ
WorkerЃКМЏШКжаШЮКЮПЩвддЫааApplicationДњТыЕФНкЕуЃЌРрЫЦгкYARNжаЕФNodeManagerНкЕуЁЃдкStandaloneФЃЪНжажИЕФОЭЪЧЭЈЙ§SlaveЮФМўХфжУЕФWorkerНкЕуЃЌдкSpark
on YarnФЃЪНжажИЕФОЭЪЧNodeManagerНкЕуЃЛ
зївЕЃЈJobЃЉЃКАќКЌЖрИіTaskзщГЩЕФВЂааМЦЫуЃЌЭљЭљгЩSpark ActionДпЩњЃЌвЛИіJOBАќКЌЖрИіRDDМАзїгУгкЯргІRDDЩЯЕФИїжжOperationЃЛ
НзЖЮЃЈStageЃЉЃКУПИіJobЛсБЛВ№ЗжКмЖрзщTaskЃЌУПзщШЮЮёБЛГЦЮЊStageЃЌвВПЩГЦTaskSetЃЌвЛИізївЕЗжЮЊЖрИіНзЖЮЃЛ
ШЮЮёЃЈTaskЃЉЃК БЛЫЭЕНФГИіExecutorЩЯЕФЙЄзїШЮЮёЃЛ

1.2 SparkдЫааЛљБОСїГЬ
SparkдЫааЛљБОСїГЬВЮМћЯТУцЪОвтЭМ
1. ЙЙНЈSpark ApplicationЕФдЫааЛЗОГЃЈЦєЖЏSparkContextЃЉЃЌSparkContextЯђзЪдДЙмРэЦїЃЈПЩвдЪЧStandaloneЁЂMesosЛђYARNЃЉзЂВсВЂЩъЧыдЫааExecutorзЪдДЃЛ
2. зЪдДЙмРэЦїЗжХфExecutorзЪдДВЂЦєЖЏStandaloneExecutorBackendЃЌExecutorдЫааЧщПіНЋЫцзХаФЬјЗЂЫЭЕНзЪдДЙмРэЦїЩЯЃЛ
3. SparkContextЙЙНЈГЩDAGЭМЃЌНЋDAGЭМЗжНтГЩStageЃЌВЂАбTasksetЗЂЫЭИјTask
SchedulerЁЃExecutorЯђSparkContextЩъЧыTaskЃЌTask SchedulerНЋTaskЗЂЗХИјExecutorдЫааЭЌЪБSparkContextНЋгІгУГЬађДњТыЗЂЗХИјExecutorЁЃ
4. TaskдкExecutorЩЯдЫааЃЌдЫааЭъБЯЪЭЗХЫљгазЪдДЁЃ
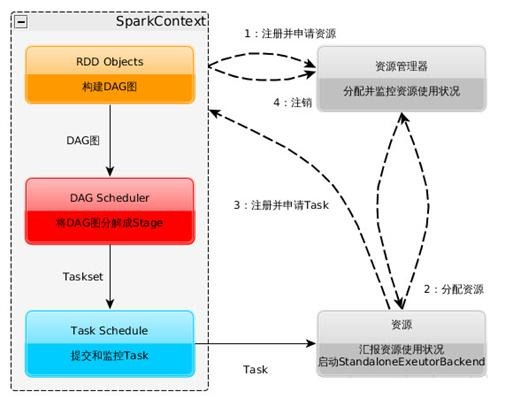
SparkдЫааМмЙЙЬиЕуЃК
lУПИіApplicationЛёШЁзЈЪєЕФexecutorНјГЬЃЌИУНјГЬдкApplicationЦкМфвЛжБзЄСєЃЌВЂвдЖрЯпГЬЗНЪНдЫааtasksЁЃетжжApplicationИєРыЛњжЦгаЦфгХЪЦЕФЃЌЮоТлЪЧДгЕїЖШНЧЖШПДЃЈУПИіDriverЕїЖШЫќздМКЕФШЮЮёЃЉЃЌЛЙЪЧДгдЫааНЧЖШПДЃЈРДздВЛЭЌApplicationЕФTaskдЫаадкВЛЭЌЕФJVMжаЃЉЁЃЕБШЛЃЌетвВвтЮЖзХSpark
ApplicationВЛФмПчгІгУГЬађЙВЯэЪ§ОнЃЌГ§ЗЧНЋЪ§ОнаДШыЕНЭтВПДцДЂЯЕЭГЁЃ
lSparkгызЪдДЙмРэЦїЮоЙиЃЌжЛвЊФмЙЛЛёШЁexecutorНјГЬЃЌВЂФмБЃГжЯрЛЅЭЈаХОЭПЩвдСЫЁЃ
lЬсНЛSparkContextЕФClientгІИУППНќWorkerНкЕуЃЈдЫааExecutorЕФНкЕу)ЃЌзюКУЪЧдкЭЌвЛИіRackРяЃЌвђЮЊSpark
ApplicationдЫааЙ§ГЬжаSparkContextКЭExecutorжЎМфгаДѓСПЕФаХЯЂНЛЛЛЃЛШчЙћЯыдкдЖГЬМЏШКжадЫааЃЌзюКУЪЙгУRPCНЋSparkContextЬсНЛИјМЏШКЃЌВЛвЊдЖРыWorkerдЫааSparkContextЁЃ
lTaskВЩгУСЫЪ§ОнБОЕиадКЭЭЦВтжДааЕФгХЛЏЛњжЦЁЃ
1.2.1 DAGScheduler
DAGSchedulerАбвЛИіSparkзївЕзЊЛЛГЩStageЕФDAGЃЈDirected Acyclic
GraphгаЯђЮоЛЗЭМЃЉЃЌИљОнRDDКЭStageжЎМфЕФЙиЯЕевГіПЊЯњзюаЁЕФЕїЖШЗНЗЈЃЌШЛКѓАбStageвдTaskSetЕФаЮЪНЬсНЛИјTaskSchedulerЃЌЯТЭМеЙЪОСЫDAGSchedulerЕФзїгУЃК

1.2.2 TaskScheduler
DAGSchedulerОіЖЈСЫдЫааTaskЕФРэЯыЮЛжУЃЌВЂАбетаЉаХЯЂДЋЕнИјЯТВуЕФTaskSchedulerЁЃДЫЭтЃЌDAGSchedulerЛЙДІРэгЩгкShuffleЪ§ОнЖЊЪЇЕМжТЕФЪЇАмЃЌетгаПЩФмашвЊжиаТЬсНЛдЫаажЎЧАЕФStageЃЈЗЧShuffleЪ§ОнЖЊЪЇЕМжТЕФTaskЪЇАмгЩTaskSchedulerДІРэЃЉЁЃ
TaskSchedulerЮЌЛЄЫљгаTaskSetЃЌЕБExecutorЯђDriverЗЂЫЭаФЬјЪБЃЌTaskSchedulerЛсИљОнЦфзЪдДЪЃгрЧщПіЗжХфЯргІЕФTaskЁЃСэЭтTaskSchedulerЛЙЮЌЛЄзХЫљгаTaskЕФдЫаазДЬЌЃЌжиЪдЪЇАмЕФTaskЁЃЯТЭМеЙЪОСЫTaskSchedulerЕФзїгУЃК

дкВЛЭЌдЫааФЃЪНжаШЮЮёЕїЖШЦїОпЬхЮЊЃК
Spark on StandaloneФЃЪНЮЊTaskSchedulerЃЛ
YARN-ClientФЃЪНЮЊYarnClientClusterScheduler
YARN-ClusterФЃЪНЮЊYarnClusterScheduler
1.3 RDDдЫаадРэ
ФЧУД RDDдкSparkМмЙЙжаЪЧШчКЮдЫааЕФФиЃПзмИпВуДЮРДПДЃЌжївЊЗжЮЊШ§ВНЃК
1.ДДНЈ RDD ЖдЯѓ
2.DAGSchedulerФЃПщНщШыдЫЫуЃЌМЦЫуRDDжЎМфЕФвРРЕЙиЯЕЁЃRDDжЎМфЕФвРРЕЙиЯЕОЭаЮГЩСЫDAG
3.УПвЛИіJOBБЛЗжЮЊЖрИіStageЃЌЛЎЗжStageЕФвЛИіжївЊвРОнЪЧЕБЧАМЦЫувђзгЕФЪфШыЪЧЗёЪЧШЗЖЈЕФЃЌШчЙћЪЧдђНЋЦфЗждкЭЌвЛИіStageЃЌБмУтЖрИіStageжЎМфЕФЯћЯЂДЋЕнПЊЯњЁЃ

вдЯТУцвЛИіАД A-Z ЪззжФИЗжРрЃЌВщевЯрЭЌЪззжФИЯТВЛЭЌаеУћзмИіЪ§ЕФР§згРДПДвЛЯТ RDD ЪЧШчКЮдЫааЦ№РДЕФЁЃ

ВНжш 1 ЃКДДНЈ RDD ЩЯУцЕФР§згГ§ШЅзюКѓвЛИі collect ЪЧИіЖЏзїЃЌВЛЛсДДНЈ RDD жЎЭтЃЌЧАУцЫФИізЊЛЛЖМЛсДДНЈГіаТЕФ
RDD ЁЃвђДЫЕквЛВНОЭЪЧДДНЈКУЫљга RDD( ФкВПЕФЮхЯюаХЯЂ ) ЁЃ
ВНжш 2 ЃКДДНЈжДааМЦЛЎ Spark ЛсОЁПЩФмЕиЙмЕРЛЏЃЌВЂЛљгкЪЧЗёвЊжиаТзщжЏЪ§ОнРДЛЎЗж НзЖЮ (stage)
ЃЌР§ШчБОР§жаЕФ groupBy() зЊЛЛОЭЛсНЋећИіжДааМЦЛЎЛЎЗжГЩСННзЖЮжДааЁЃзюжеЛсВњЩњвЛИі DAG(directed
acyclic graph ЃЌгаЯђЮоЛЗЭМ ) зїЮЊТпМжДааМЦЛЎЁЃ

ВНжш 3 ЃКЕїЖШШЮЮё НЋИїНзЖЮЛЎЗжГЩВЛЭЌЕФ ШЮЮё (task) ЃЌУПИіШЮЮёЖМЪЧЪ§ОнКЭМЦЫуЕФКЯЬхЁЃдкНјааЯТвЛНзЖЮЧАЃЌЕБЧАНзЖЮЕФЫљгаШЮЮёЖМвЊжДааЭъГЩЁЃвђЮЊЯТвЛНзЖЮЕФЕквЛИізЊЛЛвЛЖЈЪЧжиаТзщжЏЪ§ОнЕФЃЌЫљвдБиаыЕШЕБЧАНзЖЮЫљгаНсЙћЪ§ОнЖММЦЫуГіРДСЫВХФмМЬајЁЃ
МйЩшБОР§жаЕФ hdfs://names ЯТгаЫФИіЮФМўПщЃЌФЧУД HadoopRDD жа partitions
ОЭЛсгаЫФИіЗжЧјЖдгІетЫФИіПщЪ§ОнЃЌЭЌЪБ preferedLocations ЛсжИУїетЫФИіПщЕФзюМбЮЛжУЁЃЯждкЃЌОЭПЩвдДДНЈГіЫФИіШЮЮёЃЌВЂЕїЖШЕНКЯЪЪЕФМЏШКНсЕуЩЯЁЃ

2ЁЂSparkдкВЛЭЌМЏШКжаЕФдЫааМмЙЙ
SparkзЂжиНЈСЂСМКУЕФЩњЬЌЯЕЭГЃЌЫќВЛНіжЇГжЖржжЭтВПЮФМўДцДЂЯЕЭГЃЌЬсЙЉСЫЖржжЖрбљЕФМЏШКдЫааФЃЪНЁЃВПЪ№дкЕЅЬЈЛњЦїЩЯЪБЃЌМШПЩвдгУБОЕиЃЈLocalЃЉФЃЪНдЫааЃЌвВПЩвдЪЙгУЮБЗжВМЪНФЃЪНРДдЫааЃЛЕБвдЗжВМЪНМЏШКВПЪ№ЕФЪБКђЃЌПЩвдИљОнздМКМЏШКЕФЪЕМЪЧщПібЁдёStandaloneФЃЪНЃЈSparkздДјЕФФЃЪНЃЉЁЂYARN-ClientФЃЪНЛђепYARN-ClusterФЃЪНЁЃSparkЕФИїжждЫааФЃЪНЫфШЛдкЦєЖЏЗНЪНЁЂдЫааЮЛжУЁЂЕїЖШВпТдЩЯИїгаВЛЭЌЃЌЕЋЫќУЧЕФФПЕФЛљБОЖМЪЧвЛжТЕФЃЌОЭЪЧдкКЯЪЪЕФЮЛжУАВШЋПЩППЕФИљОнгУЛЇЕФХфжУКЭJobЕФашвЊдЫааКЭЙмРэTaskЁЃ
2.1 Spark on StandaloneдЫааЙ§ГЬ
StandaloneФЃЪНЪЧSparkЪЕЯжЕФзЪдДЕїЖШПђМмЃЌЦфжївЊЕФНкЕугаClientНкЕуЁЂMasterНкЕуКЭWorkerНкЕуЁЃЦфжаDriverМШПЩвддЫаадкMasterНкЕуЩЯжаЃЌвВПЩвддЫаадкБОЕиClientЖЫЁЃЕБгУspark-shellНЛЛЅЪНЙЄОпЬсНЛSparkЕФJobЪБЃЌDriverдкMasterНкЕуЩЯдЫааЃЛЕБЪЙгУspark-submitЙЄОпЬсНЛJobЛђепдкEclipsЁЂIDEAЕШПЊЗЂЦНЬЈЩЯЪЙгУЁБnew
SparkConf.setManager(ЁАspark://master:7077ЁБ)ЁБЗНЪНдЫааSparkШЮЮёЪБЃЌDriverЪЧдЫаадкБОЕиClientЖЫЩЯЕФЁЃ
ЦфдЫааЙ§ГЬШчЯТЃК
1.SparkContextСЌНгЕНMasterЃЌЯђMasterзЂВсВЂЩъЧызЪдДЃЈCPU Core КЭMemoryЃЉЃЛ
2.MasterИљОнSparkContextЕФзЪдДЩъЧывЊЧѓКЭWorkerаФЬјжмЦкФкБЈИцЕФаХЯЂОіЖЈдкФФИіWorkerЩЯЗжХфзЪдДЃЌШЛКѓдкИУWorkerЩЯЛёШЁзЪдДЃЌШЛКѓЦєЖЏStandaloneExecutorBackendЃЛ
3.StandaloneExecutorBackendЯђSparkContextзЂВсЃЛ
4.SparkContextНЋApplicaitonДњТыЗЂЫЭИјStandaloneExecutorBackendЃЛВЂЧвSparkContextНтЮіApplicaitonДњТыЃЌЙЙНЈDAGЭМЃЌВЂЬсНЛИјDAG
SchedulerЗжНтГЩStageЃЈЕБХіЕНActionВйзїЪБЃЌОЭЛсДпЩњJobЃЛУПИіJobжаКЌга1ИіЛђЖрИіStageЃЌStageвЛАудкЛёШЁЭтВПЪ§ОнКЭshuffleжЎЧАВњЩњЃЉЃЌШЛКѓвдStageЃЈЛђепГЦЮЊTaskSetЃЉЬсНЛИјTask
SchedulerЃЌTask SchedulerИКд№НЋTaskЗжХфЕНЯргІЕФWorkerЃЌзюКѓЬсНЛИјStandaloneExecutorBackendжДааЃЛ
5.StandaloneExecutorBackendЛсНЈСЂExecutorЯпГЬГиЃЌПЊЪМжДааTaskЃЌВЂЯђSparkContextБЈИцЃЌжБжСTaskЭъГЩЁЃ
6.ЫљгаTaskЭъГЩКѓЃЌSparkContextЯђMasterзЂЯњЃЌЪЭЗХзЪдДЁЃ

2.2 Spark on YARNдЫааЙ§ГЬ
YARNЪЧвЛжжЭГвЛзЪдДЙмРэЛњжЦЃЌдкЦфЩЯУцПЩвддЫааЖрЬзМЦЫуПђМмЁЃФПЧАЕФДѓЪ§ОнММЪѕЪРНчЃЌДѓЖрЪ§ЙЋЫОГ§СЫЪЙгУSparkРДНјааЪ§ОнМЦЫуЃЌгЩгкРњЪЗдвђЛђепЕЅЗНУцвЕЮёДІРэЕФадФмПМТЧЖјЪЙгУзХЦфЫћЕФМЦЫуПђМмЃЌБШШчMapReduceЁЂStormЕШМЦЫуПђМмЁЃSparkЛљгкДЫжжЧщПіПЊЗЂСЫSpark
on YARNЕФдЫааФЃЪНЃЌгЩгкНшжњСЫYARNСМКУЕФЕЏадзЪдДЙмРэЛњжЦЃЌВЛНіВПЪ№ApplicationИќМгЗНБуЃЌЖјЧвгУЛЇдкYARNМЏШКжадЫааЕФЗўЮёКЭApplicationЕФзЪдДвВЭъШЋИєРыЃЌИќОпЪЕМљгІгУМлжЕЕФЪЧYARNПЩвдЭЈЙ§ЖгСаЕФЗНЪНЃЌЙмРэЭЌЪБдЫаадкМЏШКжаЕФЖрИіЗўЮёЁЃ
Spark on YARNФЃЪНИљОнDriverдкМЏШКжаЕФЮЛжУЗжЮЊСНжжФЃЪНЃКвЛжжЪЧYARN-ClientФЃЪНЃЌСэвЛжжЪЧYARN-ClusterЃЈЛђГЦЮЊYARN-StandaloneФЃЪНЃЉЁЃ
2.2.1 YARNПђМмСїГЬ
ШЮКЮПђМмгыYARNЕФНсКЯЃЌЖМБиаызёбYARNЕФПЊЗЂФЃЪНЁЃдкЗжЮіSpark on YARNЕФЪЕЯжЯИНкжЎЧАЃЌгаБивЊЯШЗжЮівЛЯТYARNПђМмЕФвЛаЉЛљБОдРэЁЃ
YarnПђМмЕФЛљБОдЫааСїГЬЭМЮЊЃК

ЦфжаЃЌResourceManagerИКд№НЋМЏШКЕФзЪдДЗжХфИјИїИігІгУЪЙгУЃЌЖјзЪдДЗжХфКЭЕїЖШЕФЛљБОЕЅЮЛЪЧContainerЃЌЦфжаЗтзАСЫЛњЦїзЪдДЃЌШчФкДцЁЂCPUЁЂДХХЬКЭЭјТчЕШЃЌУПИіШЮЮёЛсБЛЗжХфвЛИіContainerЃЌИУШЮЮёжЛФмдкИУContainerжажДааЃЌВЂЪЙгУИУContainerЗтзАЕФзЪдДЁЃNodeManagerЪЧвЛИіИіЕФМЦЫуНкЕуЃЌжївЊИКд№ЦєЖЏApplicationЫљашЕФContainerЃЌМрПизЪдДЃЈФкДцЁЂCPUЁЂДХХЬКЭЭјТчЕШЃЉЕФЪЙгУЧщПіВЂНЋжЎЛуБЈИјResourceManagerЁЃResourceManagerгыNodeManagersЙВЭЌзщГЩећИіЪ§ОнМЦЫуПђМмЃЌApplicationMasterгыОпЬхЕФApplicationЯрЙиЃЌжївЊИКд№ЭЌResourceManagerаЩЬвдЛёШЁКЯЪЪЕФContainerЃЌВЂИњзйетаЉContainerЕФзДЬЌКЭМрПиЦфНјЖШЁЃ
2.2.2 YARN-Client
Yarn-ClientФЃЪНжаЃЌDriverдкПЭЛЇЖЫБОЕидЫааЃЌетжжФЃЪНПЩвдЪЙЕУSpark ApplicationКЭПЭЛЇЖЫНјааНЛЛЅЃЌвђЮЊDriverдкПЭЛЇЖЫЃЌЫљвдПЩвдЭЈЙ§webUIЗУЮЪDriverЕФзДЬЌЃЌФЌШЯЪЧhttp://hadoop1:4040ЗУЮЪЃЌЖјYARNЭЈЙ§http://
hadoop1:8088ЗУЮЪЁЃ
YARN-clientЕФЙЄзїСїГЬЗжЮЊвдЯТМИИіВНжшЃК

1.Spark Yarn ClientЯђYARNЕФResourceManagerЩъЧыЦєЖЏApplication
MasterЁЃЭЌЪБдкSparkContentГѕЪМЛЏжаНЋДДНЈDAGSchedulerКЭTASKSchedulerЕШЃЌгЩгкЮвУЧбЁдёЕФЪЧYarn-ClientФЃЪНЃЌГЬађЛсбЁдёYarnClientClusterSchedulerКЭYarnClientSchedulerBackendЃЛ
2.ResourceManagerЪеЕНЧыЧѓКѓЃЌдкМЏШКжабЁдёвЛИіNodeManagerЃЌЮЊИУгІгУГЬађЗжХфЕквЛИіContainerЃЌвЊЧѓЫќдкетИіContainerжаЦєЖЏгІгУГЬађЕФApplicationMasterЃЌгыYARN-ClusterЧјБ№ЕФЪЧдкИУApplicationMasterВЛдЫааSparkContextЃЌжЛгыSparkContextНјааСЊЯЕНјаазЪдДЕФЗжХЩЃЛ
3.ClientжаЕФSparkContextГѕЪМЛЏЭъБЯКѓЃЌгыApplicationMasterНЈСЂЭЈбЖЃЌЯђResourceManagerзЂВсЃЌИљОнШЮЮёаХЯЂЯђResourceManagerЩъЧызЪдДЃЈContainerЃЉЃЛ
4.вЛЕЉApplicationMasterЩъЧыЕНзЪдДЃЈвВОЭЪЧContainerЃЉКѓЃЌБугыЖдгІЕФNodeManagerЭЈаХЃЌвЊЧѓЫќдкЛёЕУЕФContainerжаЦєЖЏЦєЖЏCoarseGrainedExecutorBackendЃЌCoarseGrainedExecutorBackendЦєЖЏКѓЛсЯђClientжаЕФSparkContextзЂВсВЂЩъЧыTaskЃЛ
5.ClientжаЕФSparkContextЗжХфTaskИјCoarseGrainedExecutorBackendжДааЃЌCoarseGrainedExecutorBackendдЫааTaskВЂЯђDriverЛуБЈдЫааЕФзДЬЌКЭНјЖШЃЌвдШУClientЫцЪБеЦЮеИїИіШЮЮёЕФдЫаазДЬЌЃЌДгЖјПЩвддкШЮЮёЪЇАмЪБжиаТЦєЖЏШЮЮёЃЛ
6.гІгУГЬађдЫааЭъГЩКѓЃЌClientЕФSparkContextЯђResourceManagerЩъЧызЂЯњВЂЙиБездМКЁЃ
2.2.3 YARN-Cluster
дкYARN-ClusterФЃЪНжаЃЌЕБгУЛЇЯђYARNжаЬсНЛвЛИігІгУГЬађКѓЃЌYARNНЋЗжСНИіНзЖЮдЫааИУгІгУГЬађЃКЕквЛИіНзЖЮЪЧАбSparkЕФDriverзїЮЊвЛИіApplicationMasterдкYARNМЏШКжаЯШЦєЖЏЃЛЕкЖўИіНзЖЮЪЧгЩApplicationMasterДДНЈгІгУГЬађЃЌШЛКѓЮЊЫќЯђResourceManagerЩъЧызЪдДЃЌВЂЦєЖЏExecutorРДдЫааTaskЃЌЭЌЪБМрПиЫќЕФећИідЫааЙ§ГЬЃЌжБЕНдЫааЭъГЩЁЃ
YARN-clusterЕФЙЄзїСїГЬЗжЮЊвдЯТМИИіВНжшЃК

1. Spark Yarn ClientЯђYARNжаЬсНЛгІгУГЬађЃЌАќРЈApplicationMasterГЬађЁЂЦєЖЏApplicationMasterЕФУќСюЁЂашвЊдкExecutorжадЫааЕФГЬађЕШЃЛ
2. ResourceManagerЪеЕНЧыЧѓКѓЃЌдкМЏШКжабЁдёвЛИіNodeManagerЃЌЮЊИУгІгУГЬађЗжХфЕквЛИіContainerЃЌвЊЧѓЫќдкетИіContainerжаЦєЖЏгІгУГЬађЕФApplicationMasterЃЌЦфжаApplicationMasterНјааSparkContextЕШЕФГѕЪМЛЏЃЛ
3. ApplicationMasterЯђResourceManagerзЂВсЃЌетбљгУЛЇПЩвджБНгЭЈЙ§ResourceManageВщПДгІгУГЬађЕФдЫаазДЬЌЃЌШЛКѓЫќНЋВЩгУТжбЏЕФЗНЪНЭЈЙ§RPCавщЮЊИїИіШЮЮёЩъЧызЪдДЃЌВЂМрПиЫќУЧЕФдЫаазДЬЌжБЕНдЫааНсЪјЃЛ
4. вЛЕЉApplicationMasterЩъЧыЕНзЪдДЃЈвВОЭЪЧContainerЃЉКѓЃЌБугыЖдгІЕФNodeManagerЭЈаХЃЌвЊЧѓЫќдкЛёЕУЕФContainerжаЦєЖЏЦєЖЏCoarseGrainedExecutorBackendЃЌCoarseGrainedExecutorBackendЦєЖЏКѓЛсЯђApplicationMasterжаЕФSparkContextзЂВсВЂЩъЧыTaskЁЃетвЛЕуКЭStandaloneФЃЪНвЛбљЃЌжЛВЛЙ§SparkContextдкSpark
ApplicationжаГѕЪМЛЏЪБЃЌЪЙгУCoarseGrainedSchedulerBackendХфКЯYarnClusterSchedulerНјааШЮЮёЕФЕїЖШЃЌЦфжаYarnClusterSchedulerжЛЪЧЖдTaskSchedulerImplЕФвЛИіМђЕЅАќзАЃЌдіМгСЫЖдExecutorЕФЕШД§ТпМЕШЃЛ
5. ApplicationMasterжаЕФSparkContextЗжХфTaskИјCoarseGrainedExecutorBackendжДааЃЌCoarseGrainedExecutorBackendдЫааTaskВЂЯђApplicationMasterЛуБЈдЫааЕФзДЬЌКЭНјЖШЃЌвдШУApplicationMasterЫцЪБеЦЮеИїИіШЮЮёЕФдЫаазДЬЌЃЌДгЖјПЩвддкШЮЮёЪЇАмЪБжиаТЦєЖЏШЮЮёЃЛ
6. гІгУГЬађдЫааЭъГЩКѓЃЌApplicationMasterЯђResourceManagerЩъЧызЂЯњВЂЙиБездМКЁЃ
2.2.4 YARN-Client гы YARN-Cluster ЧјБ№
РэНтYARN-ClientКЭYARN-ClusterЩюВуДЮЕФЧјБ№жЎЧАЯШЧхГўвЛИіИХФюЃКApplication
MasterЁЃдкYARNжаЃЌУПИіApplicationЪЕР§ЖМгавЛИіApplicationMasterНјГЬЃЌЫќЪЧApplicationЦєЖЏЕФЕквЛИіШнЦїЁЃЫќИКд№КЭResourceManagerДђНЛЕРВЂЧыЧѓзЪдДЃЌЛёШЁзЪдДжЎКѓИцЫпNodeManagerЮЊЦфЦєЖЏContainerЁЃДгЩюВуДЮЕФКЌвхНВYARN-ClusterКЭYARN-ClientФЃЪНЕФЧјБ№ЦфЪЕОЭЪЧApplicationMasterНјГЬЕФЧјБ№ЁЃ
YARN-ClusterФЃЪНЯТЃЌDriverдЫаадкAM(Application
Master)жаЃЌЫќИКд№ЯђYARNЩъЧызЪдДЃЌВЂМрЖНзївЕЕФдЫаазДПіЁЃЕБгУЛЇЬсНЛСЫзївЕжЎКѓЃЌОЭПЩвдЙиЕєClientЃЌзївЕЛсМЬајдкYARNЩЯдЫааЃЌвђЖјYARN-ClusterФЃЪНВЛЪЪКЯдЫааНЛЛЅРраЭЕФзївЕЃЛ
YARN-ClientФЃЪНЯТЃЌApplication MasterНіНіЯђYARNЧыЧѓExecutorЃЌClientЛсКЭЧыЧѓЕФContainerЭЈаХРДЕїЖШЫћУЧЙЄзїЃЌвВОЭЪЧЫЕClientВЛФмРыПЊЁЃ


3ЁЂSparkдкВЛЭЌМЏШКжаЕФдЫаабнЪО
дквдЯТдЫаабнЪОЙ§ГЬжаашвЊЦєЖЏHadoopКЭSparkМЏШКЃЌЦфжаHadoopашвЊЦєЖЏHDFSКЭYARNЃЌЦєЖЏЙ§ГЬПЩвдВЮМћЕкШ§НкЁЖSparkБрГЬФЃаЭЃЈЩЯЃЉ--ИХФюМАShellЪдбщЁЗЁЃ
3.1 StandaloneдЫааЙ§ГЬбнЪО
дкSparkМЏШКЕФНкЕужаЃЌ40%ЕФЪ§ОнгУгкМЦЫуЃЌ60%ЕФФкДцгУгкБЃДцНсЙћЃЌЮЊСЫФмЙЛжБЙлИаЪмЪ§ОндкФкДцКЭЗЧФкДцЫйЖШЕФЧјБ№ЃЌдкИУбнЪОжаНЋЪЙгУДѓаЁЮЊ1GЕФSogou3.txtЪ§ОнЮФМўЃЈВЮМћЕкШ§НкЁЖSparkБрГЬФЃаЭЃЈЩЯЃЉ--ИХФюМАShellЪдбщЁЗЕФ3.2ВтЪдЪ§ОнЮФМўЩЯДЋЃЉЃЌЭЈЙ§ЖдБШЕУЕНВюОрЁЃ
3.1.1 ВщПДВтЪдЮФМўДцЗХЮЛжУ
ЪЙгУHDFSУќСюЙлВьSogou3.txtЪ§ОнДцЗХНкЕуЕФЮЛжУ
$cd /app/hadoop/hadoop-2.2.0/bin
$hdfs fsck /sogou/SogouQ3.txt -files
-blocks -locations
ЭЈЙ§ПЩвдПДЕНИУЮФМўБЛЗжИєЮЊ9ИіПщЗХдкМЏШКжа

3.1.2ЦєЖЏSpark-Shell
ЭЈЙ§ШчЯТУќСюЦєЖЏSpark-ShellЃЌдкбнЪОЕБжаУПИіExecutorЗжХф1GФкДц
$cd /app/hadoop/spark-1.1.0/bin
$./spark-shell --master spark://hadoop1:7077 --executor-memory
1g
ЭЈЙ§SparkЕФМрПиНчУцВщПДExecutorsЕФЧщПіЃЌПЩвдЙлВьЕНга1ИіDriver КЭ3ИіExecutorЃЌЦфжаhadoop2КЭhadoop3ЦєЖЏвЛИіExecutorЃЌЖјhadoop1ЦєЖЏвЛИіExecutorКЭDriverЁЃдкИУФЃЪНЯТDriverжадЫааSparkContectЃЌвВОЭЪЧDAGShedulerКЭTaskShedulerЕШНјГЬЪЧдЫаадкНкЕуЩЯЃЌНјааStageКЭTaskЕФЗжХфКЭЙмРэЁЃ

3.1.3дЫааЙ§ГЬМАНсЙћЗжЮі
ЕквЛВН ЖСШЁЮФМўКѓМЦЫуЪ§ОнМЏЬѕЪ§ЃЌВЂМЦЫуЙ§ГЬжаЪЙгУcache()ЗНЗЈЖдЪ§ОнМЏНјааЛКДц
val sogou=sc.textFile ("hdfs://hadoop1: 9000/sogou/ SogouQ3.txt")
sogou.cache()
sogou.count()
ЭЈЙ§вГУцМрПиПЩвдПДЕНИУзївЕЗжЮЊ8ИіШЮЮёЃЌЦфжавЛИіШЮЮёЕФЪ§ОнРДдДгкСНИіЪ§ОнЗжЦЌЃЌЦфЫћЕФШЮЮёИїЖдгІвЛИіЪ§ОнЗжЦЌЃЌМДЯдЪО7ИіШЮЮёЛёШЁЪ§ОнЕФРраЭЮЊЃЈNODE_LOCALЃЉЃЌ1ИіШЮЮёЛёШЁЪ§ОнЕФРраЭЮЊШЮКЮЮЛжУЃЈANYЃЉЁЃ

дкДцДЂМрПиНчУцжаЃЌЮвУЧПЩвдПДЕНЛКДцЗнЪ§ЮЊ3ЃЌДѓаЁЮЊ907.1MЃЌЛКДцТЪЮЊ38%

дЫааНсЙћЕУЕНЪ§ОнМЏЕФЪ§СПЮЊ1000ЭђБЪЪ§ОнЃЌзмЙВЛЈЗбСЫ352.17Уы

ЕкЖўВН дйДЮЖСШЁЮФМўКѓМЦЫуЪ§ОнМЏЬѕЪ§ЃЌДЫДЮМЦЫуЪЙгУЛКДцЕФЪ§ОнЃЌЖдБШЧАКѓ
ЭЈЙ§вГУцМрПиПЩвдПДЕНИУзївЕЛЙЪЧЗжЮЊ8ИіШЮЮёЃЌЦфжа3ИіШЮЮёЪ§ОнРДздФкДцЃЈPROCESS_LOCALЃЉЃЌ3ИіШЮЮёЪ§ОнРДздБОЛњЃЈNODE_LOCALЃЉЃЌЦфЫћ2ИіШЮЮёЪ§ОнРДздШЮКЮЮЛжУЃЈANYЃЉЁЃШЮЮёЫљКФЗбЕФЪБМфЖрЩйХХађЮЊЃКANY>
NODE_LOCAL> PROCESS_LOCALЃЌЖдБШПДГіЪЙгУФкДцЕФЪ§ОнБШЪЙгУБОЛњЛђШЮКЮЮЛжУЕФЫйЖШжСЩйЛсПь2ИіЪ§СПМЖЁЃ

ећИізївЕЕФдЫааЫйЖШЮЊ34.14УыЃЌБШУЛгаЛКДцЬсИпСЫвЛИіЪ§СПМЖЁЃгЩгкИеВХР§згжаЪ§ОнжЛЪЧВПЗжЛКДцЃЈЛКДцТЪ38%ЃЉЃЌШчЙћЭъШЋЛКДцЫйЖШФмЙЛЕУЕННјвЛВНЬсЩ§ЃЌДгетЬхбщЕНSparkЗЧГЃКФФкДцЃЌВЛЙ§вВЙЛПьЁЂЙЛЗцРћЃЁ

3.2 YARN-ClientдЫааЙ§ГЬбнЪО
3.2.1 ЦєЖЏSpark-Shell
ЭЈЙ§ШчЯТУќСюЦєЖЏSpark-ShellЃЌдкбнЪОЕБжаЗжХф3ИіExecutorЁЂУПИіExecutorЮЊ1GФкДц
$cd /app/hadoop/spark -1.1.0/bin
$./spark-shell --master YARN-client
--num-executors 3 --executor-memory 1g
ЕквЛВН АбЯрЙиЕФдЫааJARАќЩЯДЋЕНHDFSжа

ЭЈЙ§HDFSВщПДНчУцПЩвдПДЕНдк /user/hadoop/.sparkStaging/гІгУБрКХЃЌВщПДЕНетаЉЮФМўЃК

ЕкЖўВН ЦєЖЏApplication MasterЃЌзЂВсExecutor
гІгУГЬађЯђResourceManagerЩъЧыЦєЖЏApplication MasterЃЌдкЦєЖЏЭъГЩКѓЛсЗжХфCotainerВЂАбетаЉаХЯЂЗДРЁИјSparkContextЃЌSparkContextКЭЯрЙиЕФNMЭЈбЖЃЌдкЛёЕУЕФContainerЩЯЦєЖЏExecutorЃЌДгЯТЭМПЩвдПДЕНдкhadoop1ЁЂhadoop2КЭhadoop3ЗжБ№ЦєЖЏСЫExecutor
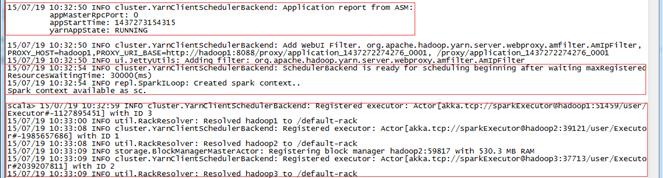
ЕкШ§ВН ВщПДЦєЖЏНсЙћ
YARN-ClientФЃЪНжаЃЌDriverдкПЭЛЇЖЫБОЕидЫааЃЌетжжФЃЪНПЩвдЪЙЕУSpark ApplicationКЭПЭЛЇЖЫНјааНЛЛЅЃЌвђЮЊDriverдкПЭЛЇЖЫЫљвдПЩвдЭЈЙ§webUIЗУЮЪDriverЕФзДЬЌЃЌФЌШЯЪЧhttp://hadoop1:4040ЗУЮЪЃЌЖјYARNЭЈЙ§http://
hadoop1:8088ЗУЮЪЁЃ
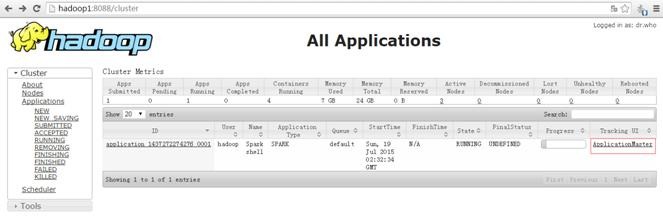

3.2.2 дЫааЙ§ГЬМАНсЙћЗжЮі
ЕквЛВН ЖСШЁЮФМўКѓМЦЫуЪ§ОнМЏЬѕЪ§ЃЌВЂМЦЫуЙ§ГЬжаЪЙгУcache()ЗНЗЈЖдЪ§ОнМЏНјааЛКДц
val sogou=sc.textFile ("hdfs://hadoop1:9000/ sogou/SogouQ3.txt")
sogou.cache()
sogou.count()
ЭЈЙ§вГУцМрПиПЩвдПДЕНИУзївЕЗжЮЊ8ИіШЮЮёЃЌЦфжавЛИіШЮЮёЕФЪ§ОнРДдДгкСНИіЪ§ОнЗжЦЌЃЌЦфЫћЕФШЮЮёИїЖдгІвЛИіЪ§ОнЗжЦЌЃЌМДЯдЪО7ИіШЮЮёЛёШЁЪ§ОнЕФРраЭЮЊЃЈNODE_LOCALЃЉЃЌ1ИіШЮЮёЛёШЁЪ§ОнЕФРраЭЮЊШЮКЮЮЛжУЃЈRACK_LOCALЃЉЁЃ

ЭЈЙ§дЫааШежОПЩвдЙлВьЕНдкЫљгаШЮЮёНсЪјЕФЪБКђЃЌгЩ YARNClientSchedulerЭЈжЊYARNМЏШКШЮЮёдЫааЭъБЯЃЌЛиЪезЪдДЃЌзюжеЙиБеSparkContextЃЌећИіЙ§ГЬКФЗб108.6УыЁЃ

ЕкЖўВН ВщПДЪ§ОнЛКДцЧщПі
ЭЈЙ§МрПиНчУцПЩвдПДЕНЃЌКЭStandaloneвЛбљ38%ЕФЪ§ОнвбОЛКДцдкФкДцжа

ЕкШ§ВН дйДЮЖСШЁЮФМўКѓМЦЫуЪ§ОнМЏЬѕЪ§ЃЌДЫДЮМЦЫуЪЙгУЛКДцЕФЪ§ОнЃЌЖдБШЧАКѓ
sogou.count()
ЭЈЙ§вГУцМрПиПЩвдПДЕНИУзївЕЛЙЪЧЗжЮЊ8ИіШЮЮёЃЌЦфжа3ИіШЮЮёЪ§ОнРДздФкДцЃЈPROCESS_LOCALЃЉЃЌ4ИіШЮЮёЪ§ОнРДздБОЛњЃЈNODE_LOCALЃЉЃЌ1ИіШЮЮёЪ§ОнРДздЛњМмЃЈRACK_LOCALЃЉЁЃЖдБШдкФкДцжаЕФдЫааЫйЖШзюПьЃЌЫйЖШБШдкБОЛњвЊПьжСЩй1ИіЪ§СПМЖЁЃ
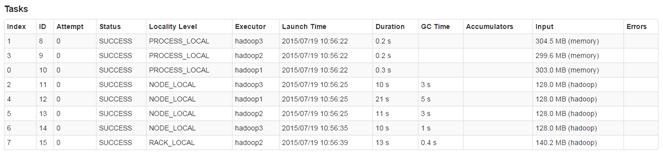
YARNClientClusterSchedulerЬцДњСЫStandaloneФЃЪНЯТЕУTaskSchedulerНјааШЮЮёЙмРэЃЌдкШЮЮёНсЪјКѓЭЈжЊYARNМЏШКНјаазЪдДЕФЛиЪеЃЌзюКѓЙиБеSparkContectЁЃВПЗжЛКДцЪ§ОндЫааЙ§ГЬКФЗбСЫ29.77УыЃЌБШУЛгаЛКДцЫйЖШЬсЩ§ВЛЩйЁЃ

3.3 YARN-ClusterдЫааЙ§ГЬбнЪО
3.3.1 дЫааГЬађ
ЭЈЙ§ШчЯТУќСюЦєЖЏSpark-ShellЃЌдкбнЪОЕБжаЗжХф3ИіExecutorЁЂУПИіExecutorЮЊ512MФкДц
$cd /app/hadoop/spark-1.1.0
$./bin/spark-submit --master YARN-cluster --class
class3.SogouResult --executor-memory 512m LearnSpark.jar
hdfs://hadoop1:9000 /sogou/SogouQ3.txt hdfs://hadoop1:9000/ class3/output2
ЕквЛВН АбЯрЙиЕФзЪдДЩЯДЋЕНHDFSжаЃЌЯрЖдгкYARN-ClientЖрСЫLearnSpark.jarЮФМў

етаЉЮФМўПЩвддкHDFSжаевЕНЃЌОпЬхТЗОЖЮЊ http://hadoop1:9000
/user/hadoop/.sparkStaging/гІгУБрКХ ЃК

ЕкЖўВН YARNМЏШКНгЙмдЫаа
ЪзЯШYARNМЏШКжагЩResourceManagerЗжХфContainerЦєЖЏSparkContextЃЌВЂЗжХфдЫааНкЕуЃЌгЩSparkConextКЭNMНјааЭЈбЖЃЌЛёШЁContainerЦєЖЏExecutorЃЌШЛКѓгЩSparkContextЕФYarnClusterSchedulerНјааШЮЮёЕФЗжЗЂКЭМрПиЃЌзюжедкШЮЮёжДааЭъБЯЪБгЩYarnClusterSchedulerЭЈжЊResourceManagerНјаазЪдДЕФЛиЪеЁЃ

3.3.2 дЫааНсЙћ
дкYARN-ClusterФЃЪНжаУќСюНчУцжЛИКд№гІгУЕФЬсНЛЃЌSparkContextКЭзївЕдЫааОљдкYARNМЏШКжаЃЌПЩвдДгhttp://
hadoop1:8088ВщПДЕНОпЬхдЫааЙ§ГЬЃЌдЫааНсЙћЪфГіЕНHDFSжаЃЌШчЯТЭМЫљЪОЃК

4ЁЂЮЪЬтНтОі
4.1 YARN-ClientЦєЖЏБЈДэ
дкНјааHadoop2.X 64bitБрвыАВзАжагЩгкЪЙгУЕН64ЮЛащФтЛњЃЌАВзАЙ§ГЬжаГіЯжЯТЭМДэЮѓЃК
[hadoop@hadoop1 spark-1.1.0]$ bin/spark-shell --master
YARN-client --executor-memory 1g --num-executors 3
Spark assembly has been built with Hive, including
Datanucleus jars on classpath
Exception in thread " main" java.lang.Exception:
When running with master 'YARN-client' either HADOOP_CONF_DIR
or YARN_CONF_DIR must be set in the environment.
at org.apache.spark.deploy .SparkSubmitArguments.checkRequiredArguments (SparkSubmitArguments.scala:182)
at org.apache.spark.deploy .SparkSubmitArguments.<init> (SparkSubmitArguments.scala:62)
at org.apache.spark.deploy .SparkSubmit$.main (SparkSubmit.scala:70)
at org.apache.spark.deploy.SparkSubmit.main (SparkSubmit.scala)

|








