| БрМЭЦМі: |
БОЮФРДздгкcsdn
,ДгFlumeЕФИХФю ЁЂEventЕФИХФюзїЮЊЦ№ЕуЃЌШЛКѓНВНтСЫМмЙЙвЛаЉШежОВЩМЏЃЌДњТыа№ЪіЕШЕШЁЃ |
|
дкОпЬхНщЩмБОЮФФкШнжЎЧАЃЌЯШИјДѓМвПДвЛЯТHadoopвЕЮёЕФећЬхПЊЗЂСїГЬЃК
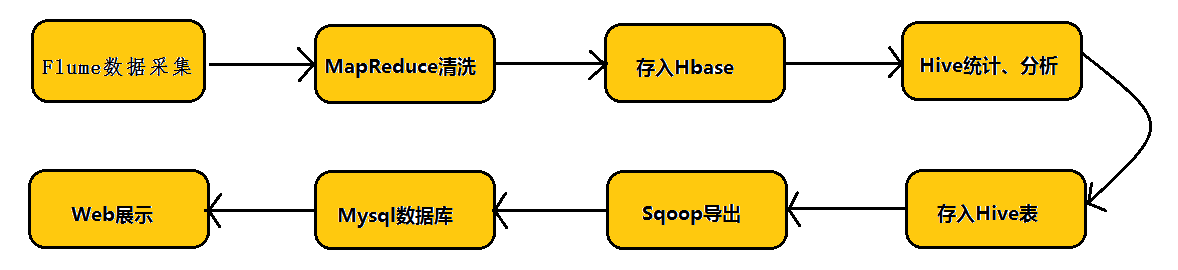
ДгHadoopЕФвЕЮёПЊЗЂСїГЬЭМжаПЩвдПДГіЃЌдкДѓЪ§ОнЕФвЕЮёДІРэЙ§ГЬжаЃЌЖдгкЪ§ОнЕФВЩМЏЪЧЪЎЗжживЊЕФвЛВНЃЌвВЪЧВЛПЩБмУтЕФвЛВНЃЌДгЖјв§ГіЮвУЧБОЮФЕФжїНЧЁЊFlumeЁЃБОЮФНЋЮЇШЦFlumeЕФМмЙЙЁЂFlumeЕФгІгУ(ШежОВЩМЏ)НјааЯъЯИЕФНщЩмЁЃ
ЃЈвЛЃЉFlumeМмЙЙНщЩм
1ЁЂFlumeЕФИХФю

flumeЪЧЗжВМЪНЕФШежОЪеМЏЯЕЭГЃЌЫќНЋИїИіЗўЮёЦїжаЕФЪ§ОнЪеМЏЦ№РДВЂЫЭЕНжИЖЈЕФЕиЗНШЅЃЌБШШчЫЕЫЭЕНЭМжаЕФHDFSЃЌМђЕЅРДЫЕflumeОЭЪЧЪеМЏШежОЕФЁЃ
2ЁЂEventЕФИХФю
дкетРягаБивЊЯШНщЩмвЛЯТflumeжаeventЕФЯрЙиИХФюЃКflumeЕФКЫаФЪЧАбЪ§ОнДгЪ§ОндД(source)ЪеМЏЙ§РДЃЌдкНЋЪеМЏЕНЕФЪ§ОнЫЭЕНжИЖЈЕФФПЕФЕи(sink)ЁЃЮЊСЫБЃжЄЪфЫЭЕФЙ§ГЬвЛЖЈГЩЙІЃЌдкЫЭЕНФПЕФЕи(sink)жЎЧАЃЌЛсЯШЛКДцЪ§Он(channel),Д§Ъ§Онеце§ЕНДяФПЕФЕи(sink)КѓЃЌflumeдкЩОГ§здМКЛКДцЕФЪ§ОнЁЃ
дкећИіЪ§ОнЕФДЋЪфЕФЙ§ГЬжаЃЌСїЖЏЕФЪЧeventЃЌМДЪТЮёБЃжЄЪЧдкeventМЖБ№НјааЕФЁЃФЧУДЪВУДЪЧeventФиЃПЁЊЈCeventНЋДЋЪфЕФЪ§ОнНјааЗтзАЃЌЪЧflumeДЋЪфЪ§ОнЕФЛљБОЕЅЮЛЃЌШчЙћЪЧЮФБОЮФМўЃЌЭЈГЃЪЧвЛааМЧТМЃЌeventвВЪЧЪТЮёЕФЛљБОЕЅЮЛЁЃeventДгsourceЃЌСїЯђchannelЃЌдйЕНsinkЃЌБОЩэЮЊвЛИізжНкЪ§зщЃЌВЂПЩаЏДјheaders(ЭЗаХЯЂ)аХЯЂЁЃeventДњБэзХвЛИіЪ§ОнЕФзюаЁЭъећЕЅдЊЃЌДгЭтВПЪ§ОндДРДЃЌЯђЭтВПЕФФПЕФЕиШЅЁЃ
ЮЊСЫЗНБуДѓМвРэНтЃЌИјГівЛеХeventЕФЪ§ОнСїЯђЭМЃК 
вЛИіЭъећЕФeventАќРЈЃКevent headersЁЂevent bodyЁЂeventаХЯЂ(МДЮФБОЮФМўжаЕФЕЅааМЧТМ)ЃЌШчЯТЫљвдЃК

ЦфжаeventаХЯЂОЭЪЧflumeЪеМЏЕНЕФШеМЧМЧТМЁЃ
3ЁЂflumeМмЙЙНщЩм
flumeжЎЫљвдетУДЩёЦцЃЌЪЧдДгкЫќздЩэЕФвЛИіЩшМЦЃЌетИіЩшМЦОЭЪЧagentЃЌagentБОЩэЪЧвЛИіjavaНјГЬЃЌдЫаадкШежОЪеМЏНкЕуЁЊЫљЮНШежОЪеМЏНкЕуОЭЪЧЗўЮёЦїНкЕуЁЃ
agentРяУцАќКЌ3ИіКЫаФЕФзщМўЃКsourceЁЊ->channelЁЊЈC>sink,РрЫЦЩњВњепЁЂВжПтЁЂЯћЗбепЕФМмЙЙЁЃ
sourceЃКsourceзщМўЪЧзЈУХгУРДЪеМЏЪ§ОнЕФЃЌПЩвдДІРэИїжжРраЭЁЂИїжжИёЪНЕФШежОЪ§Он,АќРЈavroЁЂthriftЁЂexecЁЂjmsЁЂspooling
directoryЁЂnetcatЁЂsequence generatorЁЂsyslogЁЂhttpЁЂlegacyЁЂздЖЈвхЁЃ
channelЃКsourceзщМўАбЪ§ОнЪеМЏРДвдКѓЃЌСйЪБДцЗХдкchannelжаЃЌМДchannelзщМўдкagentжаЪЧзЈУХгУРДДцЗХСйЪБЪ§ОнЕФЁЊЁЊЖдВЩМЏЕНЕФЪ§ОнНјааМђЕЅЕФЛКДцЃЌПЩвдДцЗХдкmemoryЁЂjdbcЁЂfileЕШЕШЁЃ
sinkЃКsinkзщМўЪЧгУгкАбЪ§ОнЗЂЫЭЕНФПЕФЕиЕФзщМўЃЌФПЕФЕиАќРЈhdfsЁЂloggerЁЂavroЁЂthriftЁЂipcЁЂfileЁЂnullЁЂhbaseЁЂsolrЁЂздЖЈвхЁЃ
4ЁЂflumeЕФдЫааЛњжЦ
flumeЕФКЫаФОЭЪЧвЛИіagentЃЌетИіagentЖдЭтгаСНИіНјааНЛЛЅЕФЕиЗНЃЌвЛИіЪЧНгЪмЪ§ОнЕФЪфШыЁЊЁЊsourceЃЌвЛИіЪЧЪ§ОнЕФЪфГіsinkЃЌsinkИКд№НЋЪ§ОнЗЂЫЭЕНЭтВПжИЖЈЕФФПЕФЕиЁЃsourceНгЪеЕНЪ§ОнжЎКѓЃЌНЋЪ§ОнЗЂЫЭИјchannelЃЌchanelзїЮЊвЛИіЪ§ОнЛКГхЧјЛсСйЪБДцЗХетаЉЪ§ОнЃЌЫцКѓsinkЛсНЋchannelжаЕФЪ§ОнЗЂЫЭЕНжИЖЈЕФЕиЗНЁЊ-Р§ШчHDFSЕШЃЌзЂвтЃКжЛгадкsinkНЋchannelжаЕФЪ§ОнГЩЙІЗЂЫЭГіШЅжЎКѓЃЌchannelВХЛсНЋСйЪБЪ§ОнНјааЩОГ§ЃЌетжжЛњжЦБЃжЄСЫЪ§ОнДЋЪфЕФПЩППадгыАВШЋадЁЃ
5ЁЂflumeЕФЙувхгУЗЈ
flumeжЎЫљвдетУДЩёЦцЁЊ-ЦфдвђвВдкгкflumeПЩвджЇГжЖрМЖflumeЕФagentЃЌМДflumeПЩвдЧАКѓЯрМЬЃЌР§ШчsinkПЩвдНЋЪ§ОнаДЕНЯТвЛИіagentЕФsourceжаЃЌетбљЕФЛАОЭПЩвдСЌГЩДЎСЫЃЌПЩвдећЬхДІРэСЫЁЃflumeЛЙжЇГжЩШШы(fan-in)ЁЂЩШГі(fan-out)ЁЃЫљЮНЩШШыОЭЪЧsourceПЩвдНгЪмЖрИіЪфШыЃЌЫљЮНЩШГіОЭЪЧsinkПЩвдНЋЪ§ОнЪфГіЖрИіФПЕФЕиdestinationжаЁЃ

ЃЈЖўЃЉflumeгІгУЁЊШежОВЩМЏ
ЖдгкflumeЕФдРэЦфЪЕКмШнвзРэНтЃЌЮвУЧИќгІИУеЦЮеflumeЕФОпЬхЪЙгУЗНЗЈЃЌflumeЬсЙЉСЫДѓСПФкжУЕФSourceЁЂChannelКЭSinkРраЭЁЃЖјЧвВЛЭЌРраЭЕФSourceЁЂChannelКЭSinkПЩвдздгЩзщКЯЁЊЈCзщКЯЗНЪНЛљгкгУЛЇЩшжУЕФХфжУЮФМўЃЌЗЧГЃСщЛюЁЃБШШчЃКChannelПЩвдАбЪТМўднДцдкФкДцРяЃЌвВПЩвдГжОУЛЏЕНБОЕигВХЬЩЯЁЃSinkПЩвдАбШежОаДШыHDFS,
HBaseЃЌЩѕжСЪЧСэЭтвЛИіSourceЕШЕШЁЃЯТУцЮвНЋгУОпЬхЕФАИР§ЯъЪіflumeЕФОпЬхгУЗЈЁЃ
ЦфЪЕflumeЕФгУЗЈКмМђЕЅЁЊ-ЪщаДвЛИіХфжУЮФМўЃЌдкХфжУЮФМўЕБжаУшЪіsourceЁЂchannelгыsinkЕФОпЬхЪЕЯжЃЌЖјКѓдЫаавЛИіagentЪЕР§ЃЌдкдЫааagentЪЕР§ЕФЙ§ГЬжаЛсЖСШЁХфжУЮФМўЕФФкШнЃЌетбљflumeОЭЛсВЩМЏЕНЪ§ОнЁЃ
ХфжУЮФМўЕФБраДддђЃК
1>ДгећЬхЩЯУшЪіДњРэagentжаsourcesЁЂsinksЁЂchannelsЫљЩцМАЕНЕФзщМў
# Name the components
on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1 |
2>ЯъЯИУшЪіagentжаУПвЛИіsourceЁЂsinkгыchannelЕФОпЬхЪЕЯжЃКМДдкУшЪіsourceЕФЪБКђЃЌашвЊ
жИЖЈsourceЕНЕзЪЧЪВУДРраЭЕФЃЌМДетИіsourceЪЧНгЪмЮФМўЕФЁЂЛЙЪЧНгЪмhttpЕФЁЂЛЙЪЧНгЪмthrift
ЕФЃЛЖдгкsinkвВЪЧЭЌРэЃЌашвЊжИЖЈНсЙћЪЧЪфГіЕНHDFSжаЃЌЛЙЪЧHbaseжаАЁЕШЕШЃЛЖдгкchannel
ашвЊжИЖЈЪЧФкДцАЁЃЌЛЙЪЧЪ§ОнПтАЁЃЌЛЙЪЧЮФМўАЁЕШЕШЁЃ
# Describe/configure
the source
a1.sources.r1.type = netcat
a1.sources.r1.bind = localhost
a1.sources.r1.port = 44444
# Describe the sink
a1.sinks.k1.type = logger
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100 |
3>ЭЈЙ§channelНЋsourceгыsinkСЌНгЦ№РД
# Bind the source
and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1 |
ЦєЖЏagentЕФshellВйзїЃК
flume-ng agent
-n a1 -c ../conf -f ../conf/example.file
-Dflume.root.logger=DEBUG,console |
ВЮЪ§ЫЕУїЃК -n жИЖЈagentУћГЦ(гыХфжУЮФМўжаДњРэЕФУћзжЯрЭЌ)
-c жИЖЈflumeжаХфжУЮФМўЕФФПТМ
-f жИЖЈХфжУЮФМў
-Dflume.root.logger=DEBUG,console ЩшжУШежОЕШМЖ
ОпЬхАИР§ЃК
АИР§1ЃК NetCat SourceЃКМрЬ§вЛИіжИЖЈЕФЭјТчЖЫПкЃЌМДжЛвЊгІгУГЬађЯђетИіЖЫПкРяУцаДЪ§ОнЃЌетИіsourceзщМўОЭПЩвдЛёШЁЕНаХЯЂЁЃ
Цфжа SinkЃКlogger ChannelЃКmemory
flumeЙйЭјжаNetCat SourceУшЪіЃК
Property Name
Default Description
channels ЈC
type ЈC The component type name, needs to be netcat
bind ЈC ШежОашвЊЗЂЫЭЕНЕФжїЛњУћЛђепIpЕижЗЃЌИУжїЛњдЫаазХnetcatРраЭЕФsourceдкМрЬ§
port ЈC ШежОашвЊЗЂЫЭЕНЕФЖЫПкКХЃЌИУЖЫПкКХвЊгаnetcatРраЭЕФsourceдкМрЬ§ |
a) БраДХфжУЮФМўЃК
# Name the components
on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
a1.sources.r1.type = netcat
a1.sources.r1.bind = 192.168.80.80
a1.sources.r1.port = 44444
# Describe the sink
a1.sinks.k1.type = logger
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1 |
b) ЦєЖЏflume agent a1 ЗўЮёЖЫ
| flume-ng agent
-n a1 -c ../conf -f ../conf/netcat.conf -Dflume.root.logger=DEBUG,console |
c) ЪЙгУtelnetЗЂЫЭЪ§Он
| telnet 192.168.80.80
44444 big data worldЃЁЃЈwindowsжадЫааЕФЃЉ |
d) дкПижЦЬЈЩЯВщПДflumeЪеМЏЕНЕФШежОЪ§ОнЃК 
АИР§2ЃКNetCat SourceЃКМрЬ§вЛИіжИЖЈЕФЭјТчЖЫПкЃЌМДжЛвЊгІгУГЬађЯђетИіЖЫПкРяУцаДЪ§ОнЃЌетИіsourceзщМўОЭПЩвдЛёШЁЕНаХЯЂЁЃ
Цфжа SinkЃКhdfs ChannelЃКfile (ЯрБШгкАИР§1ЕФСНИіБфЛЏ)
flumeЙйЭјжаHDFS SinkЕФУшЪіЃК 
a) БраДХфжУЮФМўЃК
# Name the components
on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
a1.sources.r1.type = netcat
a1.sources.r1.bind = 192.168.80.80
a1.sources.r1.port = 44444
# Describe the sink
a1.sinks.k1.type = hdfs
a1.sinks.k1.hdfs.path = hdfs://hadoop80:9000/dataoutput
a1.sinks.k1.hdfs.writeFormat = Text
a1.sinks.k1.hdfs.fileType = DataStream
a1.sinks.k1.hdfs.rollInterval = 10
a1.sinks.k1.hdfs.rollSize = 0
a1.sinks.k1.hdfs.rollCount = 0
a1.sinks.k1.hdfs.filePrefix = %Y-%m-%d-%H-%M-%S
a1.sinks.k1.hdfs.useLocalTimeStamp = true
# Use a channel which buffers events in file
a1.channels.c1.type = file
a1.channels.c1.checkpointDir = /usr/flume/checkpoint
a1.channels.c1.dataDirs = /usr/flume/data
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1 |
b) ЦєЖЏflume agent a1 ЗўЮёЖЫ
| flume-ng agent
-n a1 -c ../conf -f ../conf/netcat.conf -Dflume.root.logger=DEBUG,console |
c) ЪЙгУtelnetЗЂЫЭЪ§Он
| telnet 192.168.80.80
44444 big data worldЃЁЃЈwindowsжадЫааЕФЃЉ |
d) дкHDFSжаВщПДflumeЪеМЏЕНЕФШежОЪ§ОнЃК 
АИР§3ЃКSpooling Directory SourceЃКМрЬ§вЛИіжИЖЈЕФФПТМЃЌМДжЛвЊгІгУГЬађЯђетИіжИЖЈЕФФПТМжаЬэМгаТЕФЮФМўЃЌsourceзщМўОЭПЩвдЛёШЁЕНИУаХЯЂЃЌВЂНтЮіИУЮФМўЕФФкШнЃЌШЛКѓаДШыЕНchannleЁЃаДШыЭъГЩКѓЃЌБъМЧИУЮФМўвбЭъГЩЛђепЩОГ§ИУЮФМўЁЃЦфжа
SinkЃКlogger ChannelЃКmemory
flumeЙйЭјжаSpooling Directory SourceУшЪіЃК
Property Name
Default Description
channels ЈC
type ЈC The component type name, needs to be spooldir.
spoolDir ЈC Spooling Directory SourceМрЬ§ЕФФПТМ
fileSuffix .COMPLETED ЮФМўФкШнаДШыЕНchannelжЎКѓЃЌБъМЧИУЮФМў
deletePolicy never ЮФМўФкШнаДШыЕНchannelжЎКѓЕФЩОГ§ВпТд: never
or immediate
fileHeader false Whether to add a header storing
the absolute path filename.
ignorePattern ^$ Regular expression specifying
which files to ignore (skip)
interceptors ЈC жИЖЈДЋЪфжаeventЕФhead(ЭЗаХЯЂ)ЃЌГЃгУtimestamp |
Spooling Directory SourceЕФСНИізЂвтЪТЯюЃК
ЂйIf a file is
written to after being placed into the spooling
directory, Flume will print an error to its log
file and stop processing.
МДЃКПНБДЕНspoolФПТМЯТЕФЮФМўВЛПЩвддйДђПЊБрМ
ЂкIf a file name is reused at a later time, Flume
will print an error to its log file and stop processing.
МДЃКВЛФмНЋОпгаЯрЭЌЮФМўУћзжЕФЮФМўПНБДЕНетИіФПТМЯТ |
a) БраДХфжУЮФМўЃК
# Name the components
on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
a1.sources.r1.type = spooldir
a1.sources.r1.spoolDir = /usr/local/datainput
a1.sources.r1.fileHeader = true
a1.sources.r1.interceptors = i1
a1.sources.r1.interceptors.i1.type = timestamp
# Describe the sink
a1.sinks.k1.type = logger
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1 |
b) ЦєЖЏflume agent a1 ЗўЮёЖЫ
| flume-ng agent
-n a1 -c ../conf -f ../conf/spool.conf -Dflume.root.logger=DEBUG,console |
c) ЪЙгУcpУќСюЯђSpooling Directory жаЗЂЫЭЪ§Он
| cp datafile
/usr/local/datainput (зЂЃКdatafileжаЕФФкШнЮЊЃКbig data
worldЃЁ) |
d) дкПижЦЬЈЩЯВщПДflumeЪеМЏЕНЕФШежОЪ§ОнЃК 
ДгПижЦЬЈЯдЪОЕФНсЙћПЩвдПДГіeventЕФЭЗаХЯЂжаАќКЌСЫЪБМфДСаХЯЂЁЃ
ЭЌЪБЮвУЧВщПДвЛЯТSpooling DirectoryжаЕФdatafileаХЯЂЁЊ-ЮФМўФкШнаДШыЕНchannelжЎКѓЃЌИУЮФМўБЛБъМЧСЫЃК
[root@hadoop80
datainput]# ls
datafile.COMPLETED |
АИР§4ЃКSpooling Directory SourceЃКМрЬ§вЛИіжИЖЈЕФФПТМЃЌМДжЛвЊгІгУГЬађЯђетИіжИЖЈЕФФПТМжаЬэМгаТЕФЮФМўЃЌsourceзщМўОЭПЩвдЛёШЁЕНИУаХЯЂЃЌВЂНтЮіИУЮФМўЕФФкШнЃЌШЛКѓаДШыЕНchannleЁЃаДШыЭъГЩКѓЃЌБъМЧИУЮФМўвбЭъГЩЛђепЩОГ§ИУЮФМўЁЃ
Цфжа SinkЃКhdfs ChannelЃКfile (ЯрБШгкАИР§3ЕФСНИіБфЛЏ)
a) БраДХфжУЮФМўЃК
# Name the components
on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
a1.sources.r1.type = spooldir
a1.sources.r1.spoolDir = /usr/local/datainput
a1.sources.r1.fileHeader = true
a1.sources.r1.interceptors = i1
a1.sources.r1.interceptors.i1.type = timestamp
# Describe the sink
# Describe the sink
a1.sinks.k1.type = hdfs
a1.sinks.k1.hdfs.path = hdfs://hadoop80:9000/dataoutput
a1.sinks.k1.hdfs.writeFormat = Text
a1.sinks.k1.hdfs.fileType = DataStream
a1.sinks.k1.hdfs.rollInterval = 10
a1.sinks.k1.hdfs.rollSize = 0
a1.sinks.k1.hdfs.rollCount = 0
a1.sinks.k1.hdfs.filePrefix = %Y-%m-%d-%H-%M-%S
a1.sinks.k1.hdfs.useLocalTimeStamp = true
# Use a channel which buffers events in file
a1.channels.c1.type = file
a1.channels.c1.checkpointDir = /usr/flume/checkpoint
a1.channels.c1.dataDirs = /usr/flume/data
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1 |
b) ЦєЖЏflume agent a1 ЗўЮёЖЫ
| flume-ng agent
-n a1 -c ../conf -f ../conf/spool.conf -Dflume.root.logger=DEBUG,console |
c) ЪЙгУcpУќСюЯђSpooling Directory жаЗЂЫЭЪ§Он
| cp datafile
/usr/local/datainput (зЂЃКdatafileжаЕФФкШнЮЊЃКbig data
worldЃЁ) |
d) дкПижЦЬЈЩЯПЩвдВЮПДsinkЕФдЫааНјЖШШежОЃК 
d) дкHDFSжаВщПДflumeЪеМЏЕНЕФШежОЪ§ОнЃК 

ДгАИР§1гыАИР§2ЁЂАИР§3гыАИР§4ЕФЖдБШжаЮвУЧПЩвдЗЂЯжЃКflumeЕФХфжУЮФМўдкБраДЕФЙ§ГЬжаЪЧЗЧГЃСщЛюЕФЁЃ
АИР§5ЃКExec SourceЃКМрЬ§вЛИіжИЖЈЕФУќСюЃЌЛёШЁвЛЬѕУќСюЕФНсЙћзїЮЊЫќЕФЪ§ОндД
ГЃгУЕФЪЧtail -F fileжИСюЃЌМДжЛвЊгІгУГЬађЯђШежО(ЮФМў)РяУцаДЪ§ОнЃЌsourceзщМўОЭПЩвдЛёШЁЕНШежО(ЮФМў)жазюаТЕФФкШн
ЁЃ Цфжа SinkЃКhdfs ChannelЃКfile
етИіАИСаЮЊСЫЗНБуЯдЪОExec SourceЕФдЫаааЇЙћЃЌНсКЯHiveжаЕФexternal tableНјааРДЫЕУїЁЃ
a) БраДХфжУЮФМўЃК
# Name the components
on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
a1.sources.r1.type = exec
a1.sources.r1.command = tail -F /usr/local/log.file
# Describe the sink
a1.sinks.k1.type = hdfs
a1.sinks.k1.hdfs.path = hdfs://hadoop80:9000/dataoutput
a1.sinks.k1.hdfs.writeFormat = Text
a1.sinks.k1.hdfs.fileType = DataStream
a1.sinks.k1.hdfs.rollInterval = 10
a1.sinks.k1.hdfs.rollSize = 0
a1.sinks.k1.hdfs.rollCount = 0
a1.sinks.k1.hdfs.filePrefix = %Y-%m-%d-%H-%M-%S
a1.sinks.k1.hdfs.useLocalTimeStamp = true
# Use a channel which buffers events in file
a1.channels.c1.type = file
a1.channels.c1.checkpointDir = /usr/flume/checkpoint
a1.channels.c1.dataDirs = /usr/flume/data
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1 |
b)дкhiveжаНЈСЂЭтВПБэЁЊЈChdfs://hadoop80:9000/dataoutputЕФФПТМЃЌЗНБуВщПДШежОВЖЛёФкШн
hive> create
external table t1(infor string)
> row format
delimited
> fields terminated by '\t'
> location '/dataoutput/';
OK
Time taken: 0.284 seconds |
c) ЦєЖЏflume agent a1 ЗўЮёЖЫ
| flume-ng agent
-n a1 -c ../conf -f ../conf/exec.conf -Dflume.root.logger=DEBUG,console |
d) ЪЙгУechoУќСюЯђ/usr/local/datainput жаЗЂЫЭЪ§Он
d) дкHDFSКЭHiveЗжБ№жаВщПДflumeЪеМЏЕНЕФШежОЪ§ОнЃК 
hive> select
* from t1;
OK
big data
Time taken: 0.086 seconds |
e)ЪЙгУechoУќСюЯђ/usr/local/datainput жадкзЗМгвЛЬѕЪ§Он
| echo big data
world! >> log.file |
d) дкHDFSКЭHiveдйДЮЗжБ№жаВщПДflumeЪеМЏЕНЕФШежОЪ§ОнЃК 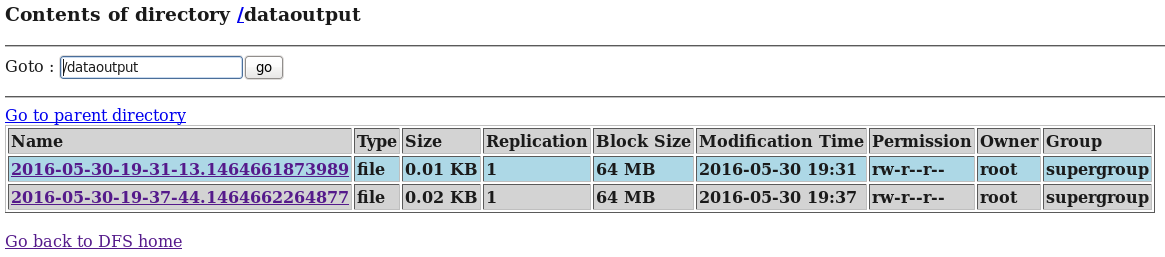

hive> select
* from t1;
OK
big data
big data world!
Time taken: 0.511 seconds |
змНсExec sourceЃКExec sourceКЭSpooling Directory SourceЪЧСНжжГЃгУЕФШежОВЩМЏЕФЗНЪНЃЌЦфжаExec
sourceПЩвдЪЕЯжЖдШежОЕФЪЕЪБВЩМЏЃЌSpooling Directory SourceдкЖдШежОЕФЪЕЪБВЩМЏЩЯЩдгаЧЗШБЃЌОЁЙмExec
sourceПЩвдЪЕЯжЖдШежОЕФЪЕЪБВЩМЏЃЌЕЋЪЧЕБFlumeВЛдЫааЛђепжИСюжДааГіДэЪБЃЌExec sourceНЋЮоЗЈЪеМЏЕНШежОЪ§ОнЃЌШежОЛсГіЯжЖЊЪЇЃЌДгЖјЮоЗЈБЃжЄЪеМЏШежОЕФЭъећадЁЃ
АИР§6ЃКAvro SourceЃКМрЬ§вЛИіжИЖЈЕФAvro ЖЫПкЃЌЭЈЙ§Avro ЖЫПкПЩвдЛёШЁЕНAvro
clientЗЂЫЭЙ§РДЕФЮФМў ЁЃМДжЛвЊгІгУГЬађЭЈЙ§Avro ЖЫПкЗЂЫЭЮФМўЃЌsourceзщМўОЭПЩвдЛёШЁЕНИУЮФМўжаЕФФкШнЁЃ
Цфжа SinkЃКhdfs ChannelЃКfile
(зЂЃКAvroКЭThriftЖМЪЧвЛаЉађСаЛЏЕФЭјТчЖЫПкЈCЭЈЙ§етаЉЭјТчЖЫПкПЩвдНгЪмЛђепЗЂЫЭаХЯЂЃЌAvroПЩвдЗЂЫЭвЛИіИјЖЈЕФЮФМўИјFlumeЃЌAvro
дДЪЙгУAVRO RPCЛњжЦ)
Avro SourceдЫаадРэШчЯТЭМЃК 
flumeЙйЭјжаAvro SourceЕФУшЪіЃК
Property Name
Default Description
channels ЈC
type ЈC The component type name, needs to be avro
bind ЈC ШежОашвЊЗЂЫЭЕНЕФжїЛњУћЛђепipЃЌИУжїЛњдЫаазХARVOРраЭЕФsource
port ЈC ШежОашвЊЗЂЫЭЕНЕФЖЫПкКХЃЌИУЖЫПквЊгаARVOРраЭЕФsourceдкМрЬ§ |
1)БраДХфжУЮФМў
# Name the components
on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
a1.sources.r1.type = avro
a1.sources.r1.bind = 192.168.80.80
a1.sources.r1.port = 4141
# Describe the sink
a1.sinks.k1.type = hdfs
a1.sinks.k1.hdfs.path = hdfs://hadoop80:9000/dataoutput
a1.sinks.k1.hdfs.writeFormat = Text
a1.sinks.k1.hdfs.fileType = DataStream
a1.sinks.k1.hdfs.rollInterval = 10
a1.sinks.k1.hdfs.rollSize = 0
a1.sinks.k1.hdfs.rollCount = 0
a1.sinks.k1.hdfs.filePrefix = %Y-%m-%d-%H-%M-%S
a1.sinks.k1.hdfs.useLocalTimeStamp = true
# Use a channel which buffers events in file
a1.channels.c1.type = file
a1.channels.c1.checkpointDir = /usr/flume/checkpoint
a1.channels.c1.dataDirs = /usr/flume/data
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1 |
b) ЦєЖЏflume agent a1 ЗўЮёЖЫ
| flume-ng agent
-n a1 -c ../conf -f ../conf/avro.conf -Dflume.root.logger=DEBUG,console |
c)ЪЙгУavro-clientЗЂЫЭЮФМў
| flume-ng avro-client
-c ../conf -H 192.168.80.80 -p 4141 -F /usr/local/log.file |
зЂЃКlog.fileЮФМўжаЕФФкШнЮЊЃК
[root@hadoop80
local]# more log.file
big data
big data world! |
d) дкHDFSжаВщПДflumeЪеМЏЕНЕФШежОЪ§ОнЃК 


ЭЈЙ§ЩЯУцЕФМИИіАИР§ЃЌЮвУЧПЩвдЗЂЯжЃКflumeХфжУЮФМўЕФЪщаДЪЧЯрЕБСщЛюЕФЁЊ-ВЛЭЌРраЭЕФSourceЁЂChannelКЭSinkПЩвдздгЩзщКЯЃЁ
зюКѓЖдЩЯУцгУЕФМИИіflume sourceНјааЪЪЕБзмНсЃК
Ђй NetCat SourceЃКМрЬ§вЛИіжИЖЈЕФЭјТчЖЫПкЃЌМДжЛвЊгІгУГЬађЯђетИіЖЫПкРяУцаДЪ§ОнЃЌетИіsourceзщМў
ОЭПЩвдЛёШЁЕНаХЯЂЁЃ
ЂкSpooling Directory SourceЃКМрЬ§вЛИіжИЖЈЕФФПТМЃЌМДжЛвЊгІгУГЬађЯђетИіжИЖЈЕФФПТМжаЬэМгаТЕФЮФ
МўЃЌsourceзщМўОЭПЩвдЛёШЁЕНИУаХЯЂЃЌВЂНтЮіИУЮФМўЕФФкШнЃЌШЛКѓаДШыЕНchannleЁЃаДШыЭъГЩКѓЃЌБъМЧ
ИУЮФМўвбЭъГЩЛђепЩОГ§ИУЮФМўЁЃ
ЂлExec SourceЃКМрЬ§вЛИіжИЖЈЕФУќСюЃЌЛёШЁвЛЬѕУќСюЕФНсЙћзїЮЊЫќЕФЪ§ОндД
ГЃгУЕФЪЧtail -F fileжИСюЃЌМДжЛвЊгІгУГЬађЯђШежО(ЮФМў)РяУцаДЪ§ОнЃЌsourceзщМўОЭПЩвдЛёШЁЕНШежО(ЮФМў)жазюаТЕФФкШн
ЁЃ
ЂмAvro SourceЃКМрЬ§вЛИіжИЖЈЕФAvro ЖЫПкЃЌЭЈЙ§Avro ЖЫПкПЩвдЛёШЁЕНAvro clientЗЂЫЭЙ§РДЕФЮФМў
ЁЃМДжЛвЊгІгУГЬађЭЈЙ§Avro ЖЫПкЗЂЫЭЮФМўЃЌsourceзщМўОЭПЩвдЛёШЁЕНИУЮФМўжаЕФФкШнЁЃ
|








