| БрМЭЦМі: |
| БОЮФРДздгкВЉПЭ,ВЉжїЖдгкFlume NGЪЕеНзмНсМАЭМНтЃЌАќРЈFlume NGМђЪіЁЂЕЅЕуFlume NGДюНЈЁЂдЫааЁЂИпПЩгУFlume NGДюНЈЁЂFailoverВтЪдЁЂНиЭМдЄРРЕШЕШЁЃ |
|
1.ИХЪі
НёЬьВЙГфвЛЦЊЙигкFlumeЕФВЉПЭЃЌЧАУцдкНВНтИпПЩгУЕФHadoopЦНЬЈЕФЪБКђвХТЉСЫетЦЊЃЌБОЦЊВЉПЭЮЊДѓМвНВЪівдЯТФкШнЃК
- Flume NGМђЪі
- ЕЅЕуFlume NGДюНЈЁЂдЫаа
- ИпПЩгУFlume NGДюНЈ
- FailoverВтЪд
- НиЭМдЄРР
ЯТУцПЊЪМНёЬьЕФВЉПЭНщЩмЁЃ
2.Flume NGМђЪі
Flume NGЪЧвЛИіЗжВМЪНЃЌИпПЩгУЃЌПЩППЕФЯЕЭГЃЌЫќФмНЋВЛЭЌЕФКЃСПЪ§ОнЪеМЏЃЌвЦЖЏВЂДцДЂЕНвЛИіЪ§ОнДцДЂЯЕЭГжаЁЃЧсСПЃЌХфжУМђЕЅЃЌЪЪгУгкИїжжШежОЪеМЏЃЌВЂжЇГжFailoverКЭИКдиОљКтЁЃВЂЧвЫќгЕгаЗЧГЃЗсИЛЕФзщМўЁЃFlume NGВЩгУЕФЪЧШ§ВуМмЙЙЃКAgentВуЃЌCollectorВуКЭStoreВуЃЌУПвЛВуОљПЩЫЎЦНЭиеЙЁЃЦфжаAgentАќКЌSourceЃЌChannelКЭSinkЃЌШ§епзщНЈСЫвЛИіAgentЁЃШ§епЕФжАд№ШчЯТЫљЪОЃК
- SourceЃКгУРДЯћЗбЃЈЪеМЏЃЉЪ§ОндДЕНChannelзщМўжа
- ChannelЃКжазЊСйЪБДцДЂЃЌБЃДцЫљгаSourceзщМўаХЯЂ
- SinkЃКДгChannelжаЖСШЁЃЌЖСШЁГЩЙІКѓЛсЩОГ§ChannelжаЕФаХЯЂ
ЯТЭМЪЧFlume NGЕФМмЙЙЭМЃЌШчЯТЫљЪОЃК

ЭМжаУшЪіСЫЃЌДгЭтВПЯЕЭГЃЈWeb ServerЃЉжаЪеМЏВњЩњЕФШежОЃЌШЛКѓЭЈЙ§FlumeЕФAgentЕФSourceзщМўНЋЪ§ОнЗЂЫЭЕНСйЪБДцДЂChannelзщМўЃЌзюКѓДЋЕнИјSinkзщМўЃЌSinkзщМўжБНгАбЪ§ОнДцДЂЕНHDFSЮФМўЯЕЭГжаЁЃ
3.ЕЅЕуFlume NGДюНЈЁЂдЫаа
ЮвУЧдкЪьЯЄСЫFlume NGЕФМмЙЙКѓЃЌЮвУЧЯШДюНЈвЛИіЕЅЕуFlumeЪеМЏаХЯЂЕНHDFSМЏШКжаЃЌгЩгкзЪдДгаЯоЃЌБОДЮжБНгдкжЎЧАЕФИпПЩгУHadoopМЏШКЩЯДюНЈFlumeЁЃ
ГЁОАШчЯТЃКдкNNAНкЕуЩЯДюНЈвЛИіFlume NGЃЌНЋБОЕиШежОЪеМЏЕНHDFSМЏШКЁЃ
3.1ЛљДЁШэМў
дкДюНЈFlume NGжЎЧАЃЌЮвУЧашвЊзМБИБивЊЕФШэМўЃЌОпЬхЯТдиЕижЗШчЯТЫљЪОЃК
- Flume http://www.apache.org/dyn/closer.cgi/flume/1.5.2/ apache-flume-1.5.2-bin.tar.gz
JDKгЩгкжЎЧАдкАВзАHadoopМЏШКЪБвбОХфжУЙ§ЃЌетРяОЭВЛзИЪіСЫЃЌШєашвЊХфжУЕФЭЌбЇЃЌПЩВЮПМЁЖХфжУИпПЩгУЕФHadoopЦНЬЈhttp:// www.cnblogs.com/ smartloli/p/4298430.htmlЁЗЁЃ
3.2АВзАгыХфжУ
ЪзЯШЃЌЮвУЧНтбЙflumeАВзААќЃЌУќСюШчЯТЫљЪОЃК
| [hadoop@nna ~]$ tar -zxvf apache-flume-1.5.2-bin.tar.gz |
ЛЗОГБфСПХфжУФкШнШчЯТЫљЪОЃК
export FLUME_HOME=/home/hadoop/flume-1.5.2
export PATH=$PATH:$FLUME_HOME/bin |
flume-conf.properties
#agent1 name
agent1.sources=source1
agent1.sinks=sink1
agent1.channels=channel1
#Spooling Directory
#set source1
agent1.sources.source1.type=spooldir
agent1.sources.source1.spoolDir = /home/hadoop/dir/logdfs
agent1.sources.source1.channels=channel1
agent1.sources.source1.fileHeader = false
agent1.sources.source1.interceptors = i1
agent1.sources.source1.interceptors.i1.type = timestamp
#set sink1
agent1.sinks.sink1.type=hdfs
agent1.sinks.sink1.hdfs.path = /home/hdfs/flume/logdfs
agent1.sinks.sink1.hdfs.fileType=DataStream
agent1.sinks.sink1.hdfs.writeFormat=TEXT
agent1.sinks.sink1.hdfs.rollInterval=1
agent1.sinks.sink1.channel=channel1
agent1.sinks.sink1.hdfs.filePrefix= %Y-%m-%d
#set channel1
agent1.channels.channel1.type=file
agent1.channels.channel1.checkpointDir = /home/hadoop/dir/logdfstmp/point
agent1.channels.channel1.dataDirs = /home/hadoop/dir/logdfstmp |
flume-env.sh
| JAVA_HOME=/usr/java/jdk1.7 |
зЂЃКХфжУжаЕФФПТМШєВЛДцдкЃЌашЬсЧАДДНЈЁЃ
3.3ЦєЖЏ
ЦєЖЏУќСюШчЯТЫљЪОЃК
| flume-ng agent -n agent1 -c conf -f flume-conf.properties - Dflume.root.logger = DEBUG,console |
зЂЃКУќСюжаЕФagent1БэЪОХфжУЮФМўжаЕФAgentЕФNameЃЌШчХфжУЮФМўжаЕФagent1ЁЃflume-conf.propertiesБэЪОХфжУЮФМўЫљдкХфжУЃЌашЬюаДзМШЗЕФХфжУЮФМўТЗОЖЁЃ
3.4аЇЙћдЄРР
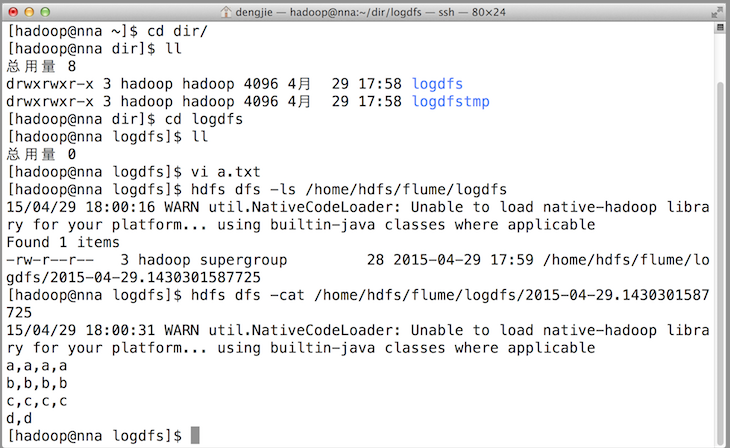


жЎКѓЃЌГЩЙІЩЯДЋКѓБОЕиФПЕФЛсБЛБъМЧЭъГЩЁЃШчЯТЭМЫљЪОЃК

4.ИпПЩгУFlume NGДюНЈ
дкЭъГЩЕЅЕуЕФFlume NGДюНЈКѓЃЌЯТУцЮвУЧДюНЈвЛИіИпПЩгУЕФFlume NGМЏШКЃЌМмЙЙЭМШчЯТЫљЪОЃК

ЭМжаЃЌЮвУЧПЩвдПДГіЃЌFlumeЕФДцДЂПЩвджЇГжЖржжЃЌетРяжЛСаОйСЫHDFSКЭKafkaЃЈШчЃКДцДЂзюаТЕФвЛжмШежОЃЌВЂИјStormЯЕЭГЬсЙЉЪЕЪБШежОСїЃЉЁЃ
4.1НкЕуЗжХф
FlumeЕФAgentКЭCollectorЗжВМШчЯТБэЫљЪОЃК
| УћГЦЁЁ |
HOST |
НЧЩЋ |
| Agent1 |
10.211.55.14 |
Web Server |
| Agent2 |
10.211.55.15 |
Web Server |
| Agent3 |
10.211.55.16ЁЁ |
Web Server |
| Collector1 |
10.211.55.18 |
AgentMstr1 |
| Collector2 |
10.211.55.19 |
AgentMstr2 |
ЭМжаЫљЪОЃЌAgent1ЃЌAgent2ЃЌAgent3Ъ§ОнЗжБ№СїШыЕНCollector1КЭCollector2ЃЌFlume NGБОЩэЬсЙЉСЫFailoverЛњжЦЃЌПЩвдздЖЏЧаЛЛКЭЛжИДЁЃдкЩЯЭМжаЃЌга3ИіВњЩњШежОЗўЮёЦїЗжВМдкВЛЭЌЕФЛњЗПЃЌвЊАбЫљгаЕФШежОЖМЪеМЏЕНвЛИіМЏШКжаДцДЂЁЃЯТУцЮвУЧПЊЗЂХфжУFlume NGМЏШК
4.2ХфжУ
дкЯТУцЕЅЕуFlumeжаЃЌЛљБОХфжУЖМЭъГЩСЫЃЌЮвУЧжЛашвЊаТЬэМгСНИіХфжУЮФМўЃЌЫќУЧЪЧflume-client.propertiesКЭflume-server.propertiesЃЌЦфХфжУФкШнШчЯТЫљЪОЃК
#agent1 name
agent1.channels = c1
agent1.sources = r1
agent1.sinks = k1 k2
#set gruop
agent1.sinkgroups = g1
#set channel
agent1.channels.c1.type = memory
agent1.channels.c1.capacity = 1000
agent1.channels.c1.transactionCapacity = 100
agent1.sources.r1.channels = c1
agent1.sources.r1.type = exec
agent1.sources.r1.command = tail -F /home/hadoop/dir/logdfs/test.log
agent1.sources.r1.interceptors = i1 i2
agent1.sources.r1.interceptors.i1.type = static
agent1.sources.r1.interceptors.i1.key = Type
agent1.sources.r1.interceptors.i1.value = LOGIN
agent1.sources.r1.interceptors.i2.type = timestamp
# set sink1
agent1.sinks.k1.channel = c1
agent1.sinks.k1.type = avro
agent1.sinks.k1.hostname = nna
agent1.sinks.k1.port = 52020
# set sink2
agent1.sinks.k2.channel = c1
agent1.sinks.k2.type = avro
agent1.sinks.k2.hostname = nns
agent1.sinks.k2.port = 52020
#set sink group
agent1.sinkgroups.g1.sinks = k1 k2
#set failover
agent1.sinkgroups.g1.processor.type = failover
agent1.sinkgroups.g1.processor.priority.k1 = 10
agent1.sinkgroups.g1.processor.priority.k2 = 1
agent1.sinkgroups.g1.processor.maxpenalty = 10000 |
зЂЃКжИЖЈCollectorЕФIPКЭPortЁЃ
#set Agent name
a1.sources = r1
a1.channels = c1
a1.sinks = k1
#set channel
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# other node,nna to nns
a1.sources.r1.type = avro
a1.sources.r1.bind = nna
a1.sources.r1.port = 52020
a1.sources.r1.interceptors = i1
a1.sources.r1.interceptors.i1.type = static
a1.sources.r1.interceptors.i1.key = Collector
a1.sources.r1.interceptors.i1.value = NNA
a1.sources.r1.channels = c1
#set sink to hdfs
a1.sinks.k1.type=hdfs
a1.sinks.k1.hdfs.path = /home/hdfs/flume/logdfs
a1.sinks.k1.hdfs.fileType=DataStream
a1.sinks.k1.hdfs.writeFormat=TEXT
a1.sinks.k1.hdfs.rollInterval=1
a1.sinks.k1.channel=c1
a1.sinks.k1.hdfs.filePrefix=%Y-%m-%d |
зЂЃКдкСэвЛЬЈCollectorНкЕуЩЯаоИФIPЃЌШчдкNNSНкЕуНЋАѓЖЈЕФЖдЯѓгаnnaаоИФЮЊnnsЁЃ
4.3ЦєЖЏ
дкAgentНкЕуЩЯЦєЖЏУќСюШчЯТЫљЪОЃК
| flume-ng agent -n agent1 -c conf -f flume-client.properties -Dflume.root.logger = DEBUG,console |
зЂЃКУќСюжаЕФagent1БэЪОХфжУЮФМўжаЕФAgentЕФNameЃЌШчХфжУЮФМўжаЕФagent1ЁЃflume-client.propertiesБэЪОХфжУЮФМўЫљдкХфжУЃЌашЬюаДзМШЗЕФХфжУЮФМўТЗОЖЁЃ
дкCollectorНкЕуЩЯЦєЖЏУќСюШчЯТЫљЪОЃК
| flume-ng agent -n a1 -c conf -f flume-server.properties -Dflume.root.logger = DEBUG,console |
зЂЃКУќСюжаЕФa1БэЪОХфжУЮФМўжаЕФAgentЕФNameЃЌШчХфжУЮФМўжаЕФa1ЁЃflume-server.propertiesБэЪОХфжУЮФМўЫљдкХфжУЃЌашЬюаДзМШЗЕФХфжУЮФМўТЗОЖЁЃ
5.FailoverВтЪд
ЯТУцЮвУЧРДВтЪдЯТFlume NGМЏШКЕФИпПЩгУЃЈЙЪеЯзЊвЦЃЉЁЃГЁОАШчЯТЃКЮвУЧдкAgent1НкЕуЩЯДЋЮФМўЃЌгЩгкЮвУЧХфжУCollector1ЕФШЈжиБШCollector2ДѓЃЌЫљвдCollector1гХЯШВЩМЏВЂЩЯДЋЕНДцДЂЯЕЭГЁЃШЛКѓЮвУЧkillЕєCollector1ЃЌДЫЪБгаCollector2ИКд№ШежОЕФВЩМЏЩЯДЋЙЄзїЃЌжЎКѓЃЌЮвУЧЪжЖЏЛжИДCollector1НкЕуЕФFlumeЗўЮёЃЌдйДЮдкAgent1ЩЯДЮЮФМўЃЌЗЂЯжCollector1ЛжИДгХЯШМЖБ№ЕФВЩМЏЙЄзїЁЃОпЬхНиЭМШчЯТЫљЪОЃК

- HDFSМЏШКжаЩЯДЋЕФlogФкШндЄРР

- Collector1хДЛњЃЌCollector2ЛёШЁгХЯШЩЯДЋШЈЯо

- жиЦєCollector1ЗўЮёЃЌCollector1жиаТЛёЕУгХЯШЩЯДЋЕФШЈЯо

6.НиЭМдЄРР
ЯТУцЮЊДѓМвИНЩЯHDFSЮФМўЯЕЭГжаЕФНиЭМдЄРРЃЌШчЯТЭМЫљЪОЃК


7.змНс
дкХфжУИпПЩгУЕФFlume NGЪБЃЌашвЊзЂвтвЛаЉЪТЯюЁЃдкAgentжаашвЊАѓЖЈЖдгІЕФCollector1КЭCollector2ЕФIPКЭPortЃЌСэЭтЃЌдкХфжУCollectorНкЕуЪБЃЌашвЊаоИФЕБЧАFlumeНкЕуЕФХфжУЮФМўЃЌBindЕФIPЃЈЛђHostNameЃЉЮЊЕБЧАНкЕуЕФIPЃЈЛђHostNameЃЉЃЌзюКѓЃЌдкЦєЖЏЕФЪБКђЃЌжИЖЈХфжУЮФМўжаЕФAgentЕФNameКЭХфжУЮФМўЕФТЗОЖЃЌЗёдђЛсГіДэЁЃ
8.НсЪјгя
етЦЊВЉПЭОЭКЭДѓМвЗжЯэЕНетРяЃЌШчЙћДѓМвдкбаОПбЇЯАЕФЙ§ГЬЕБжагаЪВУДЮЪЬтЃЌПЩвдМгШКНјааЬжТлЛђЗЂЫЭгЪМўИјЮвЃЌЮвЛсОЁЮвЫљФмЮЊФњНтД№ЃЌгыО§ЙВУуЃЁ
|








