| 编辑推荐: |
本文来自于云栖社区,本文主要从Hbase的历史规模开始谈起,进而聊到了应用场景,着重分享了问题和优化,最后对未来进行了展望。
|
|
2017云栖大会Hbase专场,阿里巴巴高级技术专家绝顶带来HBase在阿里搜索推荐中的应用的演讲。本文主要从Hbase的历史规模开始谈起,进而聊到了应用场景,着重分享了问题和优化,最后对未来进行了展望。
以下是经常内容整理:
历史和规模
其实我们做HBase时间很早,搜索只是阿里集团里面做HBase的一个部门。从2010年开始,我们经历了十个以上的版本。我们不推荐使用1.0、1.2版本,一定要使用最新的版本。关于集群规模,总节点数5000+,最大集群节点2000+,日常吞吐:集群超过5000万次/秒、单机峰值超过10万次/秒,我们现在的性能,一个CPU可以支持8000个QPS。
应用场景

HBase在搜索里面是一个核心的存储系统,和计算引擎是紧密结合的,主要关注高吞吐、低毛刺。之前讨论HBase能不能用在在线环境里面?其实HBase的延时从线上情况来看还是比较低的,之所以不能用在线上,因为故障恢复时间比较长。主要服务的是搜索和推荐业务,搜索主要是从线上的数据源里面把淘宝的商品、用户的数据存到HBase,再经过一些数据的清理给搜索引擎来使用。PORSHE是我们的一个机器学习平台,我们会把一些用户行为同步到HBase,同时机器学习平台本身有一些模型和特征的数据,也是存在HBase里,它在机器学习的过程当中会有一些附表的过程,会产生非常大量的吞吐,访问完了以后的数据也会到线上。大家搜索一个手机,前一次搜索的结果会影响后一次搜索的排序,先搜索一款手机,发现这款产品不是想要的,后一次搜索一定会以前面搜索的信息作为参考。
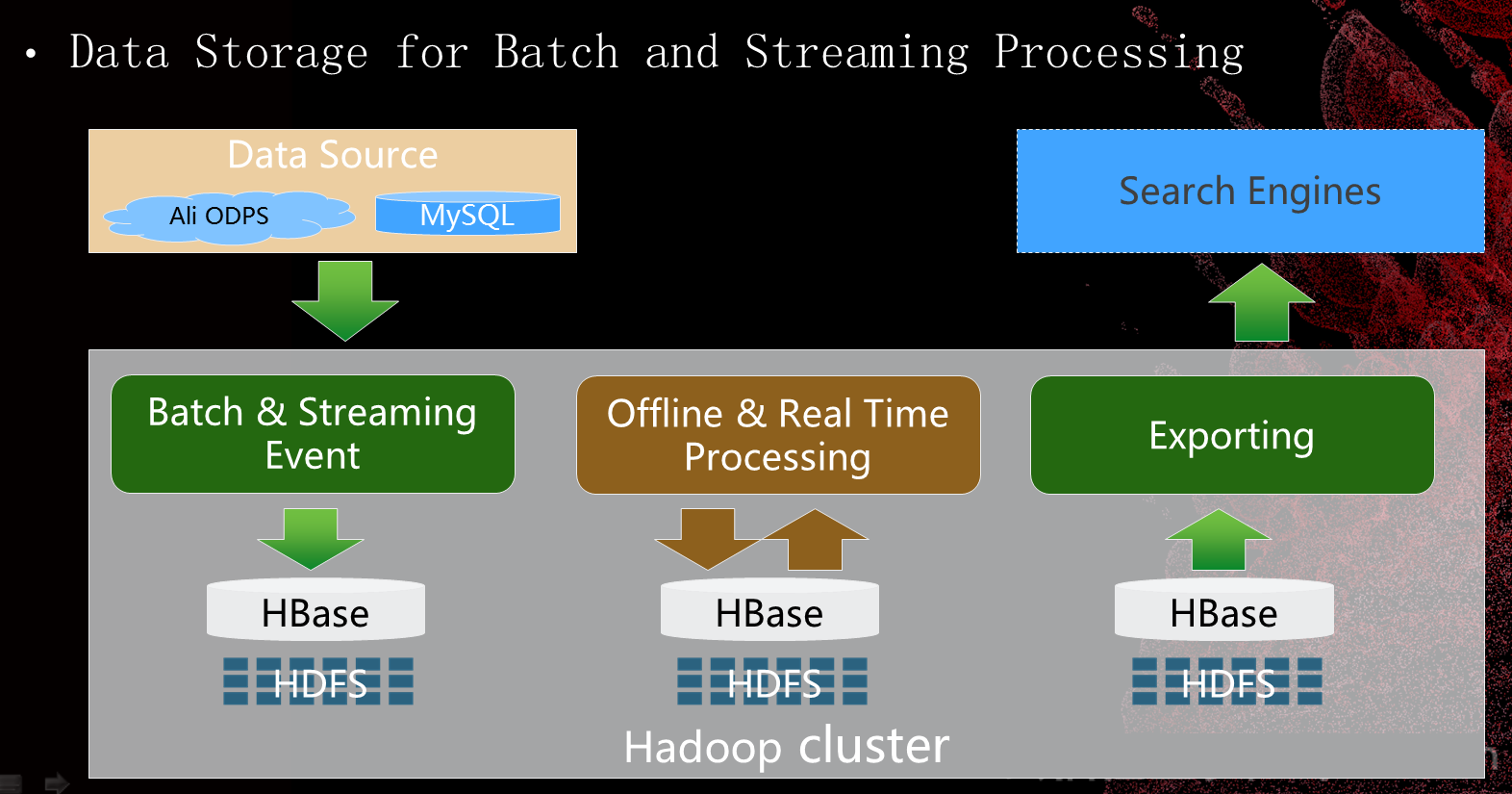
这个图是主搜索,搜索引擎索引构建的过程。这些数据在HBase上面会有一些离线的或者实时的处理,处理完了之后再导出到在线的搜索引擎里来进行对外服务。
>
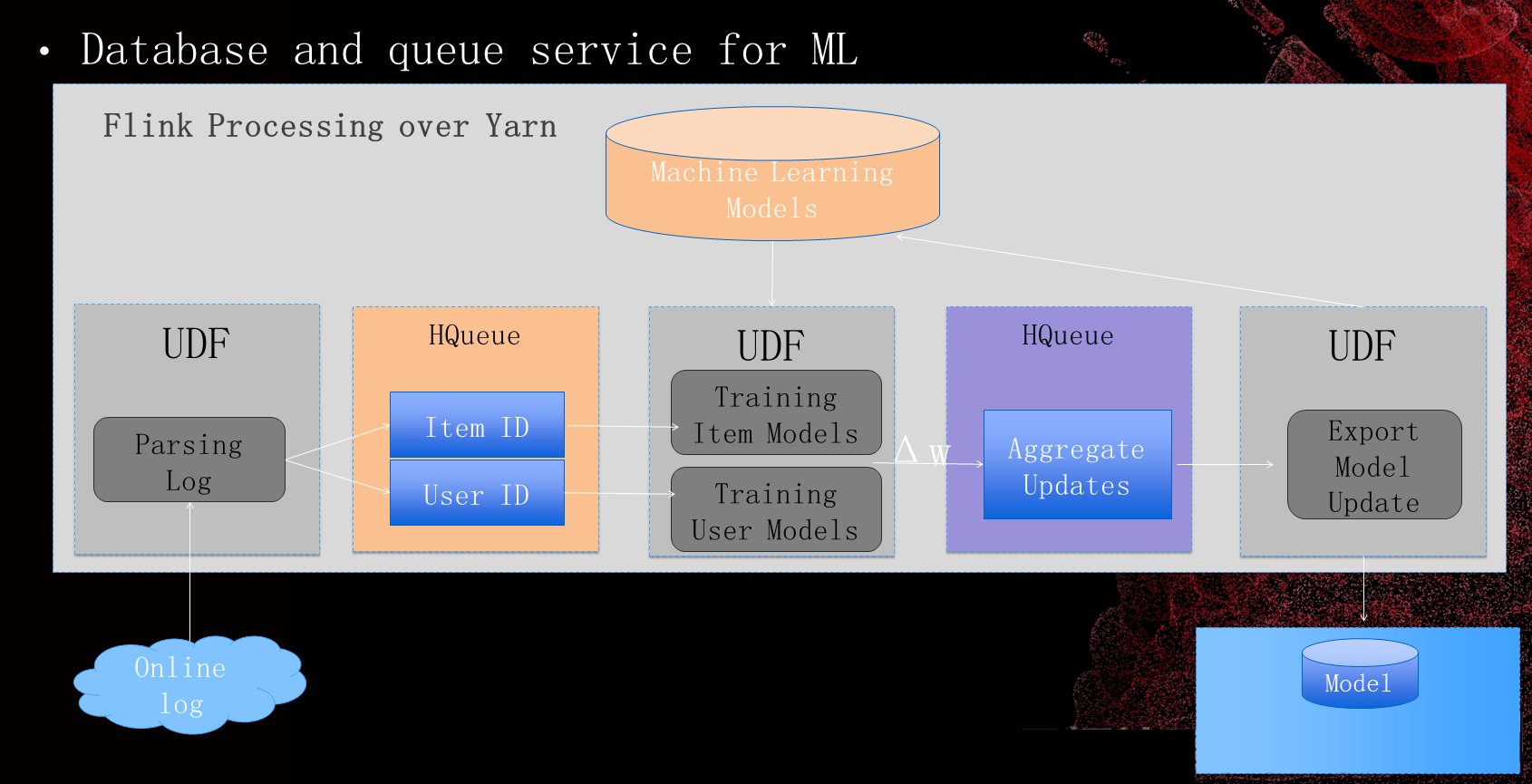
机器学习,在这个里面HBase主要两部分,首先第一个,我们基于HBase做了消息队列的服务。另一方面,存储这些模型以及特征的数据。
问题与优化

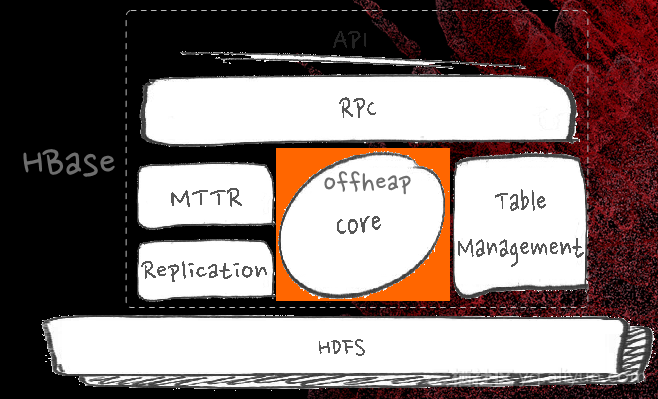
客户和服务端肯定是有RPC的访问,在服务器层面其实有几个大的模块,最重要的当然是CORE,CORE主要来服务读写,另外就是一些分布式服务,包括故障恢复。底下一定会有一个文件系统。这几个部分我们都遇到过问题,也都解决过问题。

首先是在RPC的瓶颈和优化。它会有一个单独的返回结果的现场,如果大家在现场有这种经验的话,一个节点上有非常高的并发去访问某一台server,肯定要一个个返回,在那个地方有一把锁,以前是一把同步锁,导致是串型的返回,如果有十个现场同时需要返回的话,一个现场在回写,另外九个在等待。
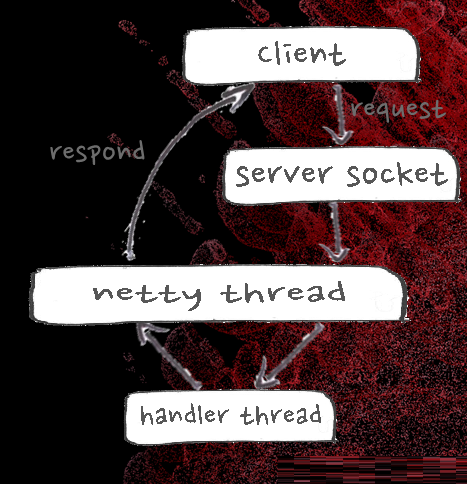
我们后来做了很多优化,发现使用netty的模型是比较好的,Netty可以更高效的复用线程,基于Netty实现HBase
RpcServer,主要好处就是性能好,rpc平均响应时间从0.92ms下降到0.25ms,吞吐能力提高了两倍。
异步与吞吐
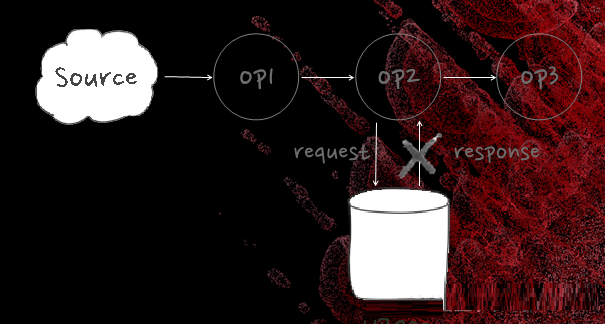
我们在流式的环境下面有一个数据源,流式计算对于实时性的要求很高,接下来有三个算子,HBase这种分布式访问很难去避免有一些秒级毛刺,它发送请求返回时间会比较长。优化手段为基于netty实现non-blocking
client以及基于protobuf的non-blocking Stub/RpcCallback实现callback回调。假如说是同步访问的话,因为你是一个流,在等结果的时候就要等5秒,这个流整个就要阻塞5秒。怎么解决这个问题?这跟你的业务逻辑有关系,你本身的IO逻辑不阻塞主现场,就把IO异步化,主现场就可以往前走,做完了以后把结果回写就可以了。你的IO逻辑和主流程没有阻塞关系的话,异步化可以很好地解决这个问题。但是如果有关系,其实异步也是有作用的,这个作用体现在哪儿?同步的时候5秒只能处理一个结果,假设我做一百个请求的窗口,都是异步发,等一百个请求都返回的主流程往下走,如果有一个毛刺是5秒,没有关系,在5秒的时间里处理了100个请求,异步吞吐提高100倍,异步是一个挺重要的需求。实现起来,基本上是基于netty,吞吐提高了两倍以上。
毛刺是不可回避的,因为HBase是java写的,这是不能回避的问题。PCIe-SSD的高IO吞吐能力下,读cache的换入换出速率大幅提高。堆上的cache内存回收不及时,导致频繁的CMS
gc甚至fullGC。优化手段为实现读路径E2E的offheap,我们是把社区的2.0的功能复制到我们版本上,我们避免垃圾出现。
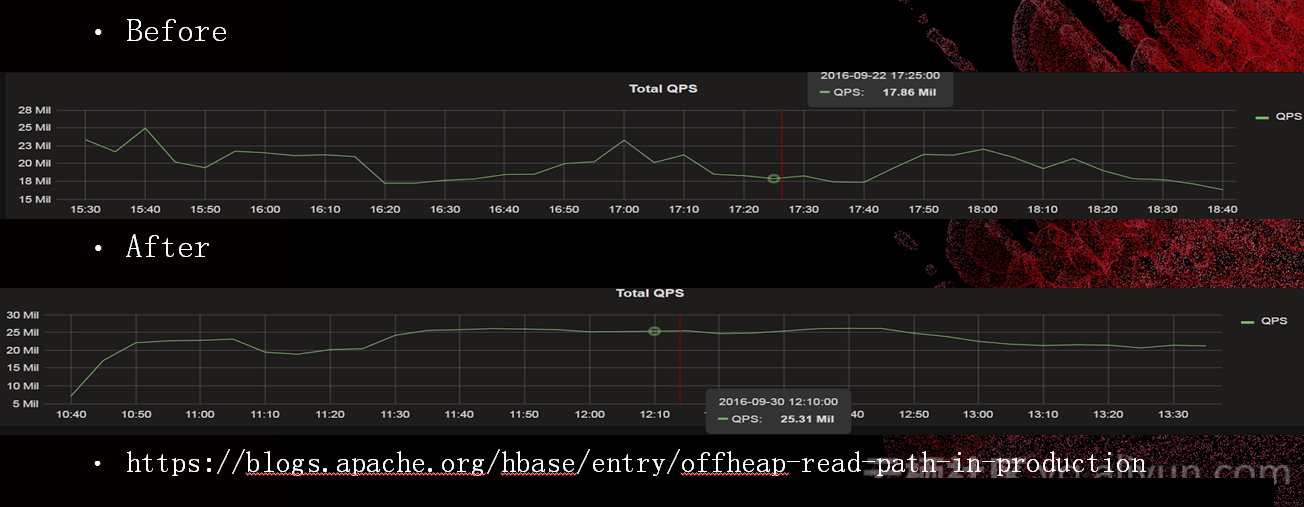
如图,吞吐的曲线波动比较明显,底下平缓很多。
IO隔离和优化
HBase对IO敏感,磁盘打满会造成大量毛刺,如果我们在云上HBase可以自己充分地利用一个物理机器,我们HBase搜索的场景里面,HBase的机器和计算的机器是混合部署的,一个节点上既有HBase的节点,也有spark的节点。这种情况下怎么做到HBase的隔离,计算存储混布,batch作业产生大量的IO。HBase自身一是Flush,一是Compaction。优化手段,利用HDFS的Heterogeneous
storage功能,对于演示影响非常大的就存在ssd上,如果级别低一点的业务读版本放在ssd上。
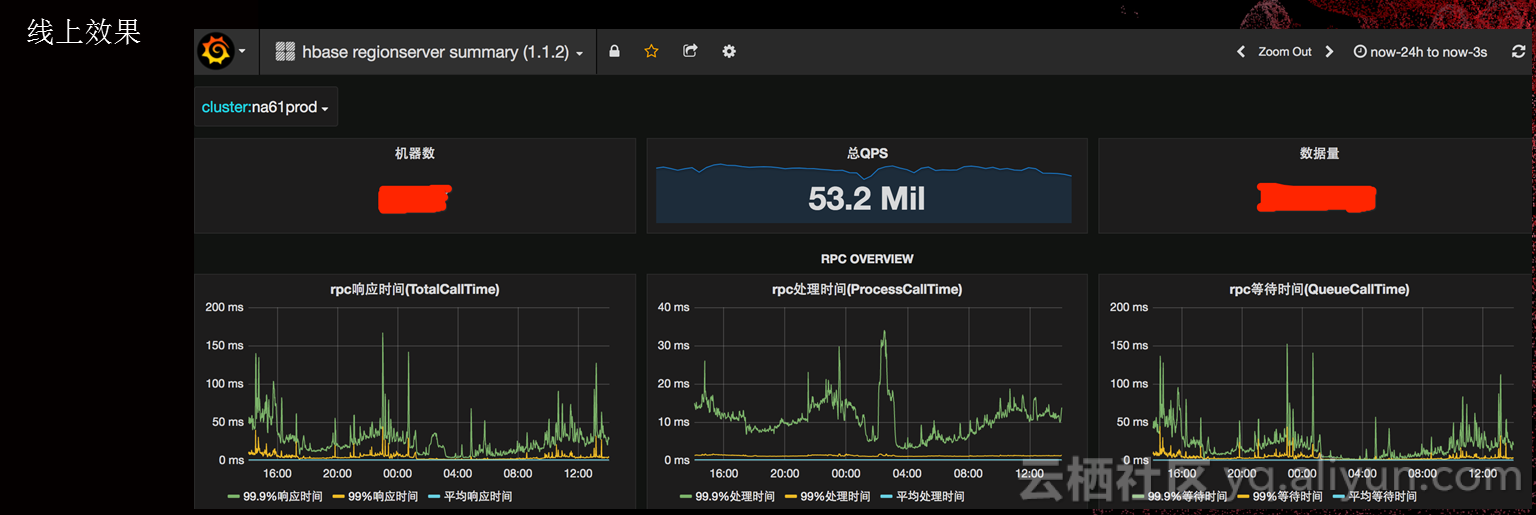
优化手段有Compaction限流、Flush限流、Per-CF Flush。我们的处理时间基本上都是在40毫秒以下,图为两千个集群的情况。我们响应时间99.9%的请求时间都不超过200毫秒,这个数据显示是在集群CPU读到80%的情况下,它是混布的。
IO利用
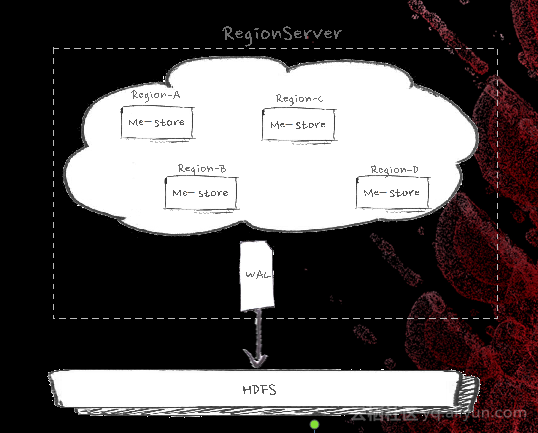
实际问题包括单WAL无法充分使用磁盘TO、HDFS写3份副本、通用机型有12块HDD盘以及SSD的IO能力远远超过HDD,你用不满,那就是浪费,就要优化。优化手段支持多WAL:对region分组并进行合理映射,这个映射关系可以随机映射。支持app间IO隔离,基于Namespace的WAL分组。上线效果全HDD盘下写吞吐提高20%,全SSD盘下写吞吐提高40%;线上写入平均响应延时从0.5ms下降到0.3ms。
开源与未来
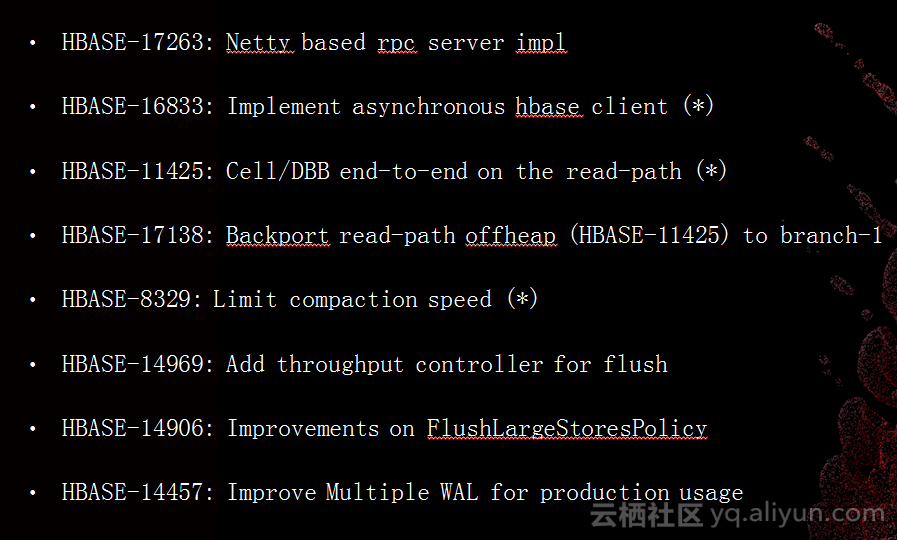
我们在阿里做开源的人态度都是非常开放的,我这里列出了之前讲的所有优化,打“星”号是我们和社区一起开发,没有打“星”号都是我们自己做的。我们不会做完了以后立刻反馈给社区,基本上通过双十一的验证之后才会反馈给社区。当然,如果用云HBase就可以立刻看得到。
HBase2.0已经提出来非常长时间,目前的计划是今年圣诞节发布,要作为一个圣诞礼物给大家。2.0主要是有几个方面的内容:
有新的AssignmentManager,会有一个状态机,而且在ZK上不再存储中间状态数据。我们会看到更平稳的GC,更少的毛刺,并且大大减少写放大。基本上先进的数据库都是基于LSM的,写放大好不好决定数据库好不好,最主要就是控制写放大,HBase在这方面也做了IN—memory
Lsm,给不同的应用分组,一组只服务一个表或者一批表,实际上在运维上会有很好的提升。
未来,我们有很多思考:
写路径优化与重构,SSD现在发展得非常快,随着机型的更新,写吞吐跟不上硬件的发展,阶段拆分+异步处理与回写,测试环境下吞吐可提高3倍以上,当然这只是原型,并没有上线去做。
MTTR的优化,HBase的恢复时间比较长。是不是可以有更好的设计?能不能优化到秒级,这也是很重要的。
响应时间的平稳性,HBase底层可以有很多的文件系统,但是不管是什么文件系统,它都是一个外部的系统,你访问它的时候就有可能产生毛刺和不好的相应延时,如何更好的规避HDFS毛刺的影响。
|








